美团点评效果广告实验配置平台的设计与实现
转载自 美团点评技术团队
一. 背景
效果广告的主要特点之一是可量化,即广告系统的所有业务指标都是可以计算并通过数字进行展示的。因此,可以通过业务指标来表示广告系统的迭代效果。那如何在全量上线前确认迭代的结果呢?通用的方法是采用AB实验(如图1)。所谓AB实验,是指单个变量具有两个版本A和B的随机实验。在实际应用中,是一种比较单个(或多个)变量多个版本的方法,通常是通过测试受试者对多个版本的反应,并确定多个版本中的哪个更有效。Google工程师在2000年进行了首次AB实验,试图确定在其搜索引擎结果页上显示的最佳结果数。到了2011年,Google进行了7,000多次不同的AB实验。现在很多公司使用“设计实验”的方法来制定营销决策,期望在实验样本上可以得到积极的转化结果,并且随着工具和专业知识在实验领域的发展,AB实验已成为越来越普遍的一种做法。
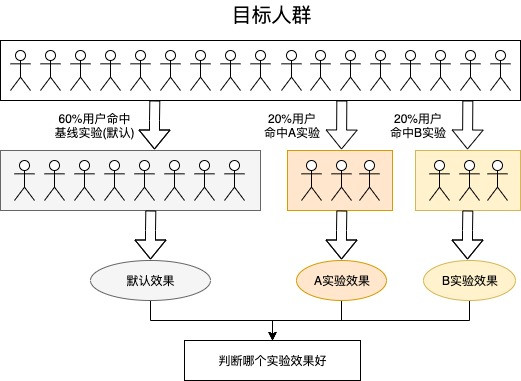 图1 什么是AB实验
图1 什么是AB实验
我们都知道,机器学习在广告投放中的作用是举足轻重的,广告收入的提升离不开算法模型的优化迭代,因此算法模型的迭代也需要进行AB实验。除了算法模型的迭代之外,工程中较大规模的重构和优化也需要AB实验来验证效果的有效性和正确性。此外,目前在大部分应用中,应用参数配置采用最多是单键值的配置方式,这种配置方式的确满足了大部分配置的需要,但是在结合业务需求的情况下,使用起来可能会很乏力。
因此,我们需要搭建一个平台(Wedge),来满足算法、工程在迭代过程中的实验需求,并且满足在不同流量下应用参数配置的需求。
二. 方案设计
目标
Wedge平台的目标如下:
-
支持各类算法实验场景,可灵活支持后续的功能扩展。
-
实验配置、使用、效果回收等全链路对使用者透明,降低解释成本。
-
提供不同流量下应用参数的配置,降低参数解析成本。
-
支持版本控制,可快速回滚。
-
提供简洁、易用的操作界面。
设计思路
在《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》中,Google给出了一套通用的分层实验解决方案。我们以此为蓝本,结合美团点评效果广告的LBS特性,针对不同的业务场景,实现了更适合日常迭代的实验配置框架。目前,该框架已在搜索广告投放系统上全量上线。
实验分类
基于Google分层实验平台,结合实际需求进行了以下实验分类。
根据实验种类分类
-
水平实验:类似于Overlapping Layer中的实验,是属于同个“层”的实验,实验是互斥的,在同一“层”上实验可以理解为是同一种实验,例如:关键词“层”表示这一层的实验都是关键词相关的,该层上存在实验H1和H2,那么流量绝对不会同时命中H1和H2。
-
垂直实验:类似于Non-overlapping Layer中的实验,分布于不同“层”之间,实验是不互斥的,例如在关键词“层”和CTR“层”上在相同的分桶上配置了实验V1和V2,那么流量可以同时命中V1和V2。
-
条件实验:表示进入某“层”的实验需要满足某些条件,水平实验和垂直实验都可以是条件实验。
根据流量类别分类
这种分类主要了为了用户体验,使平台在操作上更加的简单、易用:
-
普通实验:最基本的实验,根据流量类别进行配置。
-
引用实验:流量分类是整个配置中心基础,但实际上存在一些实验是跨流量了,而引用实验则可以配置在不同的流量种类中。
-
全局实验:可以理解为特殊的引用实验,全局实验在所有流量上都生效。
架构图
图2为整体架构图,比较便于大家理解,我们可以看到整体架构分为四层:
-
Web层:提供平台UI,负责应用参数配置、实验配置、实验效果查看以及其他。
-
服务层:提供权限控制、实验管理、拉取实验效果等功能。
-
存储层:主要是数据存储功能。
-
业务层:业务层结合SDK完成获取实验参数和获取应用参数的功能。
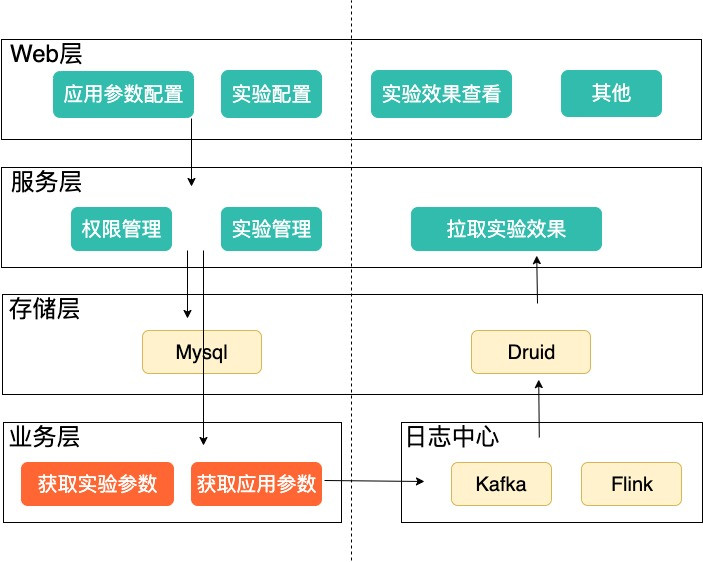 图2 架构图
图2 架构图
三. 模型设计
1. 分流模型
实验模型
如图3所示,整体模型分为以下几个部分:
-
App:表示一个应用,不同的应用对应的实验配置完全不同,首先从App上进行区分可以更加明确实验的归属。
-
Scene:表示某一类流量的集合,例如:搜索、美食筛选、到综筛选等,在这些流量上配置的实验互不干扰。
-
Layer:表示某一层(种)实验的集合。例如可以将在matching上做的实验放入Matching Layer中。流量命中时依次进入每个Layer获取实验配置参数,此时的Layer更像一个抽象概念,与具体的业务或者逻辑相关。
-
条件Layer:是一种更加精细的流量控制方式,表示某一流量的某个或者某几个参数在满足一定条件下才会进行实验。进一步说就是相同Scene下,某一流量的参数A满足条件一时,采用一种实验配置策略;满足条件二时,采用另一种实验配置策略,那可以分为两层,如图3所示的Layer_3和Layer_4。例如:某流量需要在城市北京单独做实验,这种情况下,可以分为参数相同但是先决条件(即城市)互斥的两个Layer。此时的Layer在抽象的基础上更加的具体化。
-
Exp:表示具体实验,包括实验的分桶、实验参数、是否为垂直流量等等。
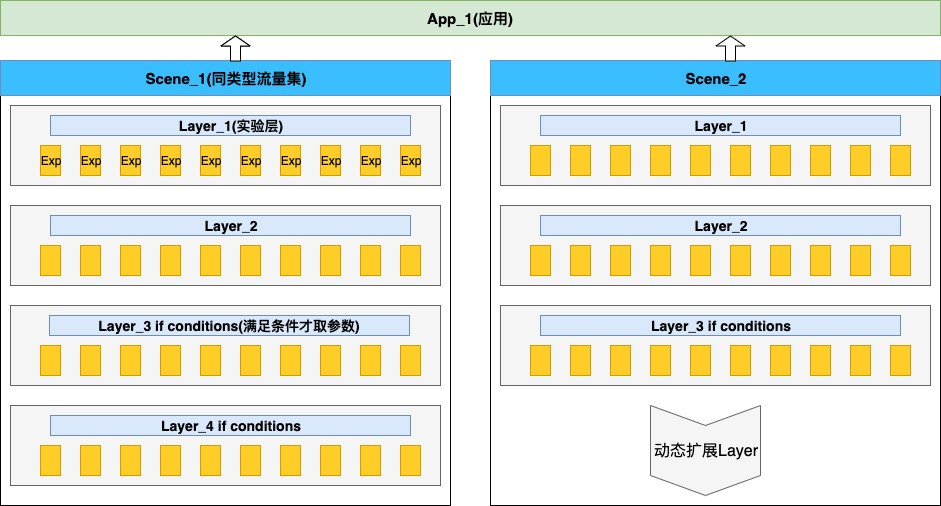 图3 实验模型
图3 实验模型
水平、垂直分流模型
如图4所示,水平、垂直分流模型分为以下两个部分:
-
仅包含水平实验 : 最基础的实验需求,全部实验独占一个Layer,每个实验覆盖若干个桶,例如图4中的Layer_1,将流量分为10份,包含三个实验,这三个实验分别占用3、3、4份流量。
-
同时包含水平、垂直实验:一个Layer中同时包含垂直、水平两种类型的实验。例如图4中的Layer_2和Layer_3,将最后的4份流量用来做垂直实验,包含两个垂直实验,分别是Exp_6和Exp_7。
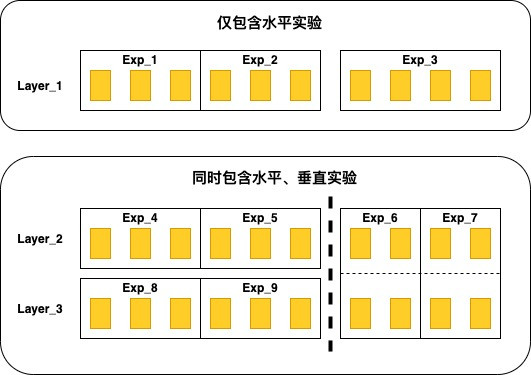 图4 水平、垂直分流模型
图4 水平、垂直分流模型
2. 实验命中模型
实验命中模型是指,当一个请求过来时,返回全局统一的实验参数。所有的请求都会平均地落入每一个分桶中,并且不同的Layer之间能够保证流量的正交。
名词解释
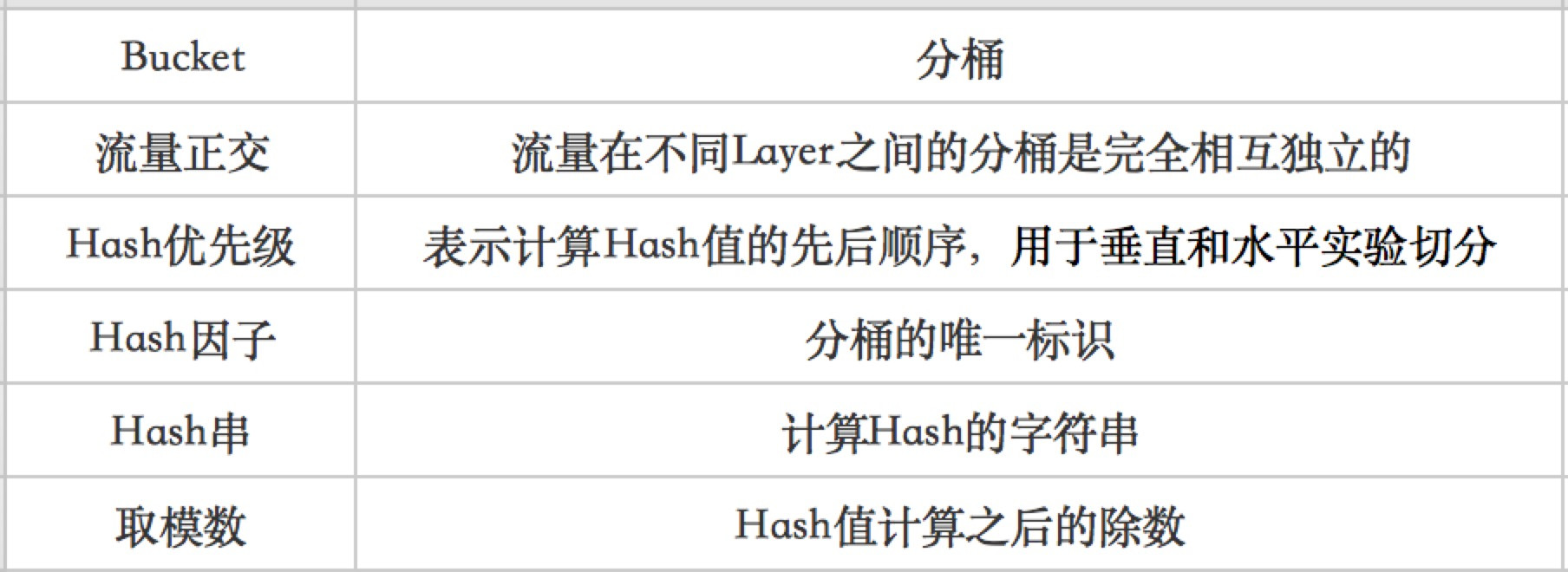
-
Hash优先级:在实验命中过程中,第一次Hash首先判断命中垂直流量,如果没有命中,则进行第二次Hash再判断水平流量。
-
Hash因子:目前美团侧一般情况下为uuid,点评侧为dpid。
-
垂直流量Hash串:Hash因子+scene_id。
-
水平流量Hash串:Hash因子+scene_id+layer_id+layer_name。
-
取模数:在Hash过程中,垂直流量按照总Bucket(默认取值100)取模;水平流量按照总Bucket数减去垂直流量Bucket数取模。这样的命中模型能保证无论是垂直的Bucket,还是水平的Bucket都是全局的1%。
实例解析
以最复杂的流量分配为例,如图5,水平、垂直流量各占全局50%流量。
水平流量上包含两个实验:Exp_1、Exp_2各占全局20%流量,还有10%流量未分配实验,垂直流量与水平流量相同。
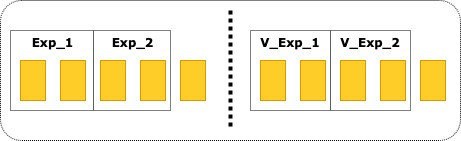 图5 流量分配示例
图5 流量分配示例
典型实验命中如图6所示:
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BE%8E%E5%9B%A2%E7%82%B9%E8%AF%84%E6%95%88%E6%9E%9C%E5%B9%BF%E5%91%8A%E5%AE%9E%E9%AA%8C%E9%85%8D%E7%BD%AE%E5%B9%B3%E5%8F%B0%E7%9A%84%E8%AE%BE%E8%AE%A1%E4%B8%8E%E5%AE%9E%E7%8E%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


