美团搜索多业务商品排序探索与实践
美团点评技术团队 稿
引言
美团的使命是“帮大家吃得更好,生活更好”,我们给广大消费者提供买菜、优选、闪购、外卖、到店餐饮、酒店旅游、休闲娱乐等各类商品和服务。首页搜索是美团 App 上十分重要的模块,每天服务于数千万用户。随着美团零售商品类业务的不断发展,美团搜索在商品类业务上的相关技术也在不断迭代,排序模块作为整个搜索系统的重要组成部分,极大地影响着用户最终的搜索体验。
近些年,深度学习在排序领域得到广泛的应用,本文分享了美团搜索在零售商品类业务上的排序经验。内容主要分为以下三个部分:第一部分,我们对商品搜索多业务排序面临的挑战进行简单的介绍;第二部分会介绍商品搜索相关排序技术的一些实践经验;最后一部分是总结与展望。
搜索排序的挑战
美团搜索多业务商品排序,面临的挑战主要包括以下几个方面:
- 各业务供给和履约差异较大,采用统一模型对各类业务商品进行统一的混合排序建模,模型兼顾不同业务的共性和特性难度大。
- 不同业务的消费频次和业务规模不同,导致各业务在模型训练数据中的分布差异较大。
- 排序结果进行业务聚合展示情况下,业务间的顺序和首位业务结果展示数目共同影响着用户的搜索体验,两者独立优化只可能得到体验目标的次优解,由于两者的任务差异大,进行联合优化难度较大。
下面主要介绍我们在商品多业务排序上针对上述挑战点所做的一些探索与实践。
排序探索与实践
混排建模
在美团搜索商品多业务排序场景下,排序需要对不同商品业务:闪购、买菜、优选、团好货等进行统一混合排序,不同业务之间既有共性也有自己的特性。下面介绍我们针对商品多业务排序相关的一些实践。
图1 多业务商品排序示意图
多子塔结构
此前,我们在商家多业务排序场景中已经积累了很多的实践经验,详情可参考《 多业务建模在美团搜索排序中的实践》一文,所以直接将多子塔结构应用到商品多业务排序场景。商品混排的 item 集合涵盖五个业务,模型结构中具有五个子塔:闪购子网络、买菜子网络、外卖子网络、优选子网络和团好货子网络;与此同时,我们引入 ESMM[2] 模型结构来更好的学习下单信息。整体模型结构如下图 2 所示:
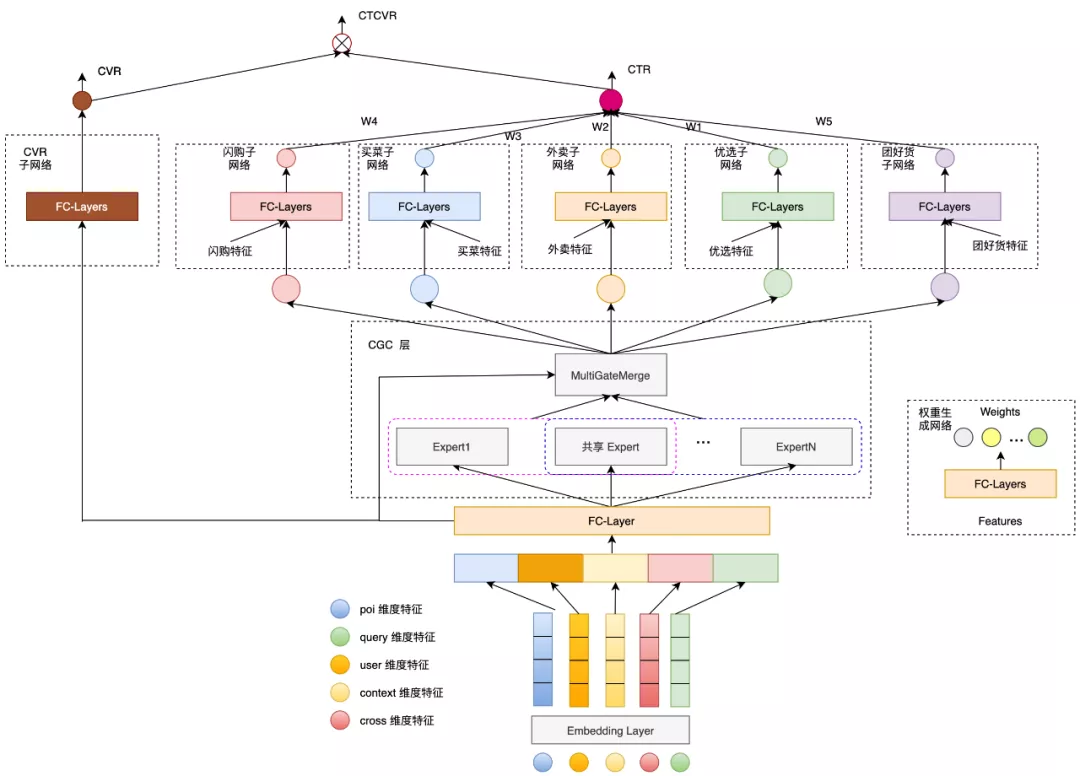
图2 多子塔模型结构示意图
实践表明,模型离线指标相比基线提升明显;经过线上 AB 实验测试,点击率提升了 20BP(基点),访购率提升了 37BP。
多业务特征选择
目前在多业务子塔结构中,我们采用了一个大的特征候选集来兼顾各业务的需求:底层特征输入是闪购、买菜、外卖、优选、团好货多个业务的特征并集,业务之间互相缺失的特征给予默认值。这种实现,导致特征的数量繁多且杂乱,可能会给模型的训练带来很多的噪声。例如对于优选业务,实际可能只有10%的特征起到作用,剩下90%的特征对这个业务来说就是噪声。
目前,业界提出的相关特征选择方案,如 AutoFIS [20]、AutoFeature [21] 等等,都是针对单个场景、单个模型来选择的,而我们的目的是针对一个特征集合,让模型学会不同场景下特征重要性的不同。因此,这些方案无法直接应用到我们的场景中。为了缓解上述提到的问题,我们初步尝试了一些方法用于多业务的特征选择。
Group Lasso 正则化
Group Lasso [3] 是 Lasso 的一个扩展。Group Lasso 首先对特征进行分组,然后对组内的特征采用 L2 正则化,组间的特征集合采用 L1 正则化。由于 L1 正则化的稀疏性,因此最后产出的特征集合是稀疏的,也就达到了特征选择的目的。形式化表述,我们在训练目标中加入下述公式(1)正则项:
\min \mathcal{L}_{grls} = \lambda_1 \sum_{k=1}^{K} ||\theta_k||_2 + \lambda_2 ||\theta||_1 (1)
其中 K 为特征组的数目, 为第 k 组特征的 Embedding 矩阵, \lambda_1和 \lambda_2 为权重超参数。在上式中,我们对所有特征集合应用 L1 正则化,从而产出一个稀疏的解,也就达到了我们特征选择的目的。
该版模型相比多子塔模型,离线 NDCG 基本持平。
特征选择门
在上述 Group Lasso 方案中,虽然我们达到了特征选择的目的,但选出的特征对应不同业务的权重是相同的。在多业务排序场景下,不同特征对不同业务的重要性显然不一样,例如“配送时间”这个特征对闪购业务比较重要,但对于团好货影响不是很大。为了分业务建模特征重要性,我们借鉴 Group Lasso 的思想,提出了一个自适应多业务特征选择模块。
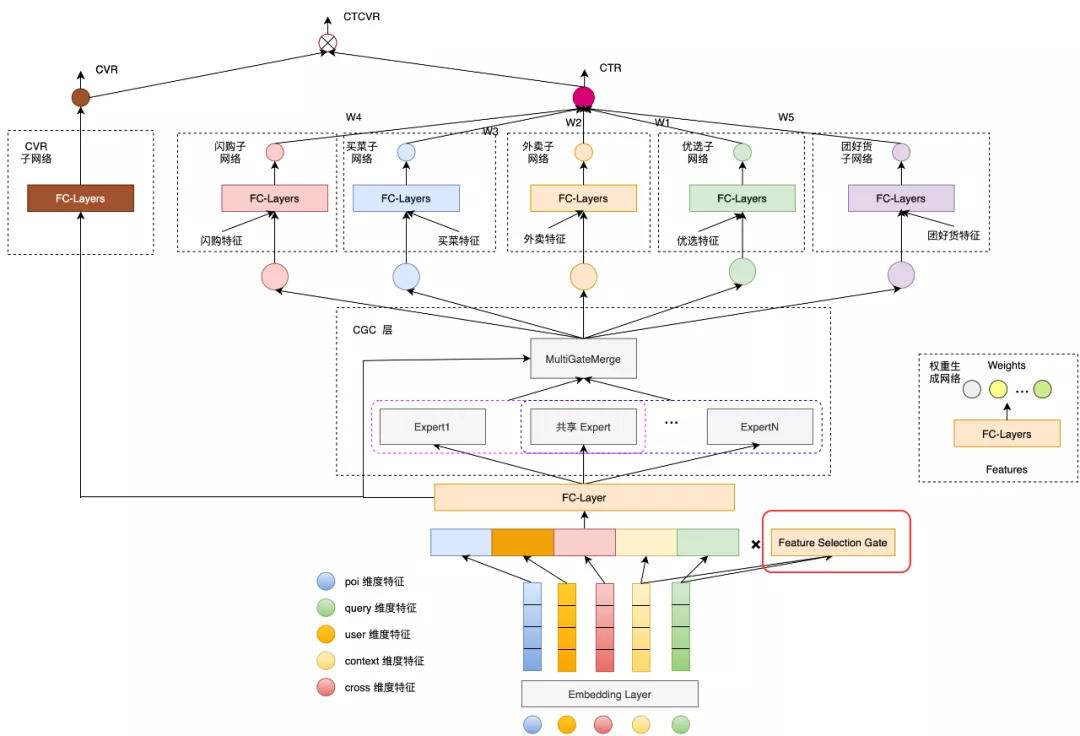 图3 多子塔特征选择门结构
图3 多子塔特征选择门结构
整体模型结构如上图 3 所示,我们通过一个特征选择门来计算每个特征的权重。特征选择门将 Query 以及上下文相关信息的 Embedding 表征经过一层线性映射以及 Softmax 激活函数,得到归一化的特征的权重向量:
g_t = softmax(W_t x_{query} + b_t) (2)
其中g_t \in R^{h_2} 是第 t 个业务的特征权重向量, W_t \in R^{h_2 \times h_1}是第t 个业务的投影矩阵,b_t \in R^{h_2}是对应的 Bias 向量。而后用这个权重向量点乘经过 Embedding 编码后的模型输入:
\hat{x}_{t} = g_t \odot x = \sum_{k=1}^{K} g_{t,k} x_{k} (3)
对于不同的业务,我们用不同的门控 g_t 乘上输入,从而达到了分业务加权的目的。
这版模型相比 Group Lasso 正则化版本,离线 NDCG 提升了 16BP。
多业务概率图模型及训练
在特征选择门方案中,我们针对不同的业务选用了不同的门控来实现自适应特征选择。但是该方案有一个关键的问题:训练和推理阶段,我们怎么知道该选用哪个业务的门控向量 g_t ?因此,模型首先需要能够识别当前请求的意图。
此外,多塔子结构的实践本质是想让业务更好地学出自己的特性。在图 2 和图 3 所示的多业务结构中,如果调参不当,很容易出现退化或者模式坍塌的现象。一个极端情况是,所有子塔中只有一个子塔得到了充分的训练,模型所有的输出都依赖于这个子塔,这与我们多业务建模的初衷相违背。
为了实现意图识别以及更好地训练多业务子塔,我们接着提出了一个概率图的框架,用一个隐变量 z来学习用户当前需求对应到每个业务的分布,系统性地用一个概率图将输入、业务、以及输出联系起来。模型结构示意图如下图 4 所示,我们在模型中额外引入一个先验网络p 和一个后验网络q ,先验网络的目标是根据用户、查询词、上下文等输入信息预测采用哪个子塔,即建模p(z|x) ,后验网络的目标是根据输入以及用户的行为来建模后验概率p(z|x,y) 。训练目标是优化条件概率分布的一个证据下界(Evidence Lower Bound):
\begin{aligned} \log p(y|x) &= \log \int_z p(y|x,z) p(z|x) dz \\ &\geq E_{q(z|x,y)} [\log p(y|x,z)] - D_{KL}[q(z|x,y) || p(z|x)] \end{aligned} (4)
这个公式第一项表示的含义是在训练时,我们从后验网络中拿到对应业务的分布z ,然后根据 z 来判断模型走哪个子塔并进行训练。第二项表示的含义是让先验网络和后验网络的输出尽可能接近,从而在推理阶段也能够根据先验塔的输出来判断走哪个子塔。这个后验网络只会在训练阶段使用。在具体实现上,我们将后验网络简化成一个规则决策模型:根据用户的行为反馈来预测对应的业务。
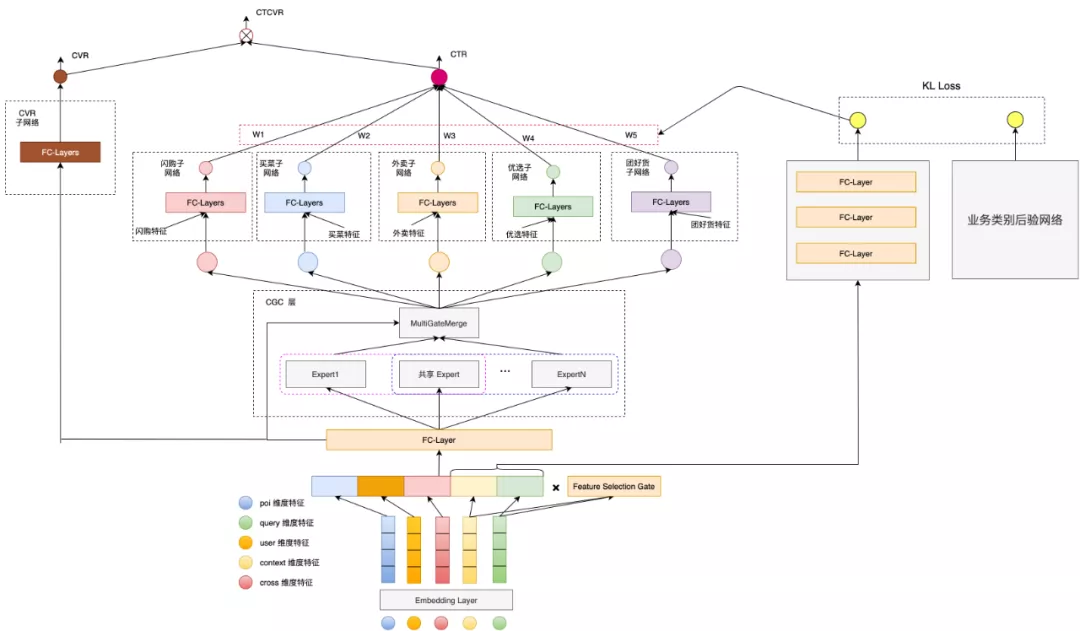
图4 多业务概率图模型
引入概率图建模后离线 NDCG 提升了 39BP;最终我们将该版本进行线上 AB 测试:线上点击率提升了 25BP。
在多业务建模方面,除了上面的工作我们还陆续尝试了使用 Uncertainty 对分业务 Loss 进行加权[4]、多业务 Hierarchy 结构[5] 等,但均没有取得明显效果提升。
此外,我们也调研了阿里妈妈近期提出的 Star[6] 模型,Star 模型主要有以下几点贡献:1. 提出了一个星形(Star)的架构;2. 提出了分片归一化(Partitioned Normalization)的方案;(3)将域的信息显式加入到输出中(辅助网络)。我们尝试过将分片归一化、辅助网络的方案应用到我们的场景中,但均没有取得明显的效果。
聚合建模
当对各业务结果进行如图 5 所示的聚合展示时,聚块的位置顺序和聚块大小(即聚块内 item 的数量)共同决定用户的搜索体验。过去很长一段时间的技术方案是先使用排序模型预测业务的先后顺序,然后根据业务预测分数的相对差值通过人工规则来设置聚块大小。这种方案将聚块顺序和聚块大小分两步进行串行建模,距用户体验最优解存在较大差距;其次,聚块排序与聚块大小的串行耦合会降低模型的迭代效果:前者的模型迭代替换,会导致后者规则相关的阈值设定不再合适。
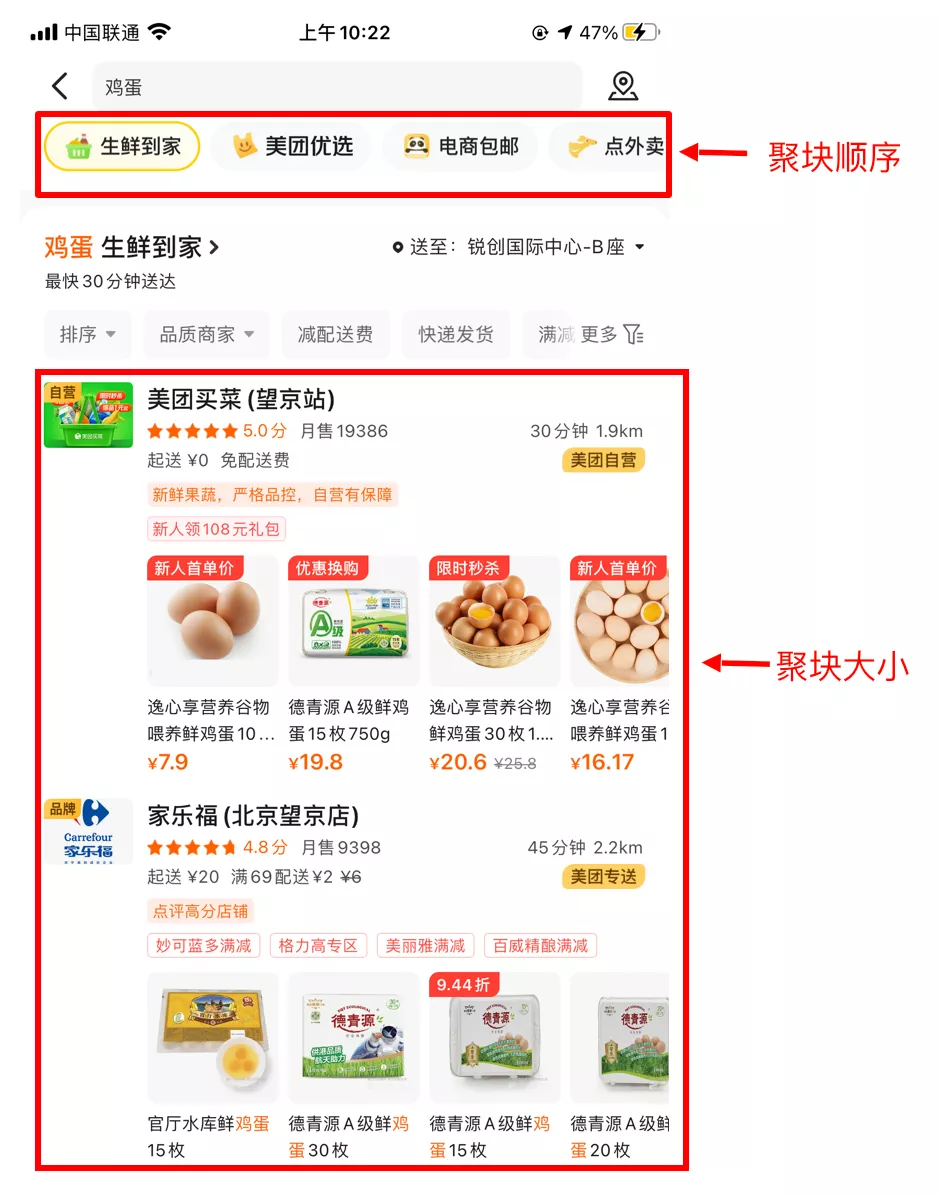
图5 结果聚合展示示意图
针对聚合展示样式带来的技术挑战,我们提出 GSRM (Grouping Search Results Model) 模型,该模型结构如下图 6 所示。这是一个多任务模型,同时进行聚块位置和大小的预测。聚块位置预测任务我们建模成 CTR 预估的分类问题,输出结果代表业务偏好强弱进行聚块的的位置排序;聚块大小预测任务我们建模成一个回归问题,输出聚块展示结果数。模型的底层输入特征包含查询词维度、用户维度、上下文维度、item 维度、以及各个维度的交叉特征。下面重点介绍两个工作:第一个是用户行为序列建模,第二个是聚块大小预测建模。
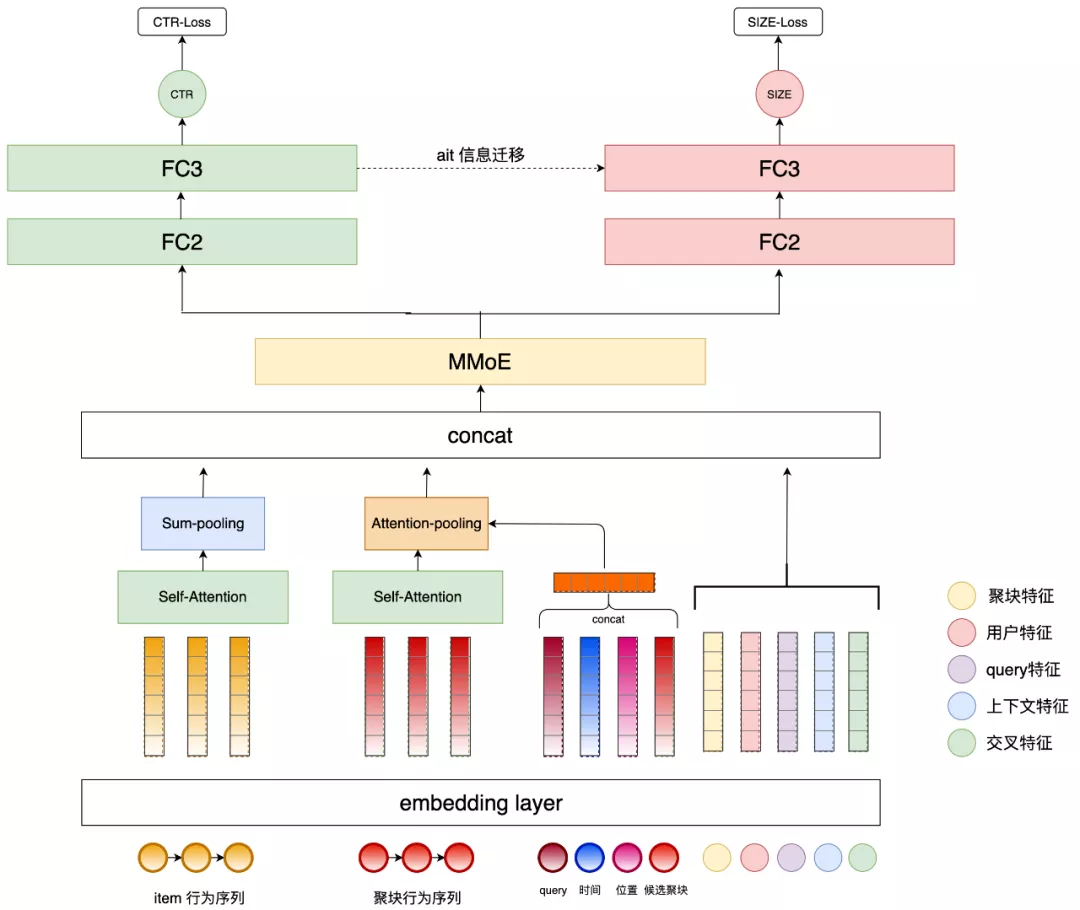 图6 聚块展示模型示意图
图6 聚块展示模型示意图
异构双序列建模
众所周知,在深度学习 CTR 预估时代,在模型中引入用户行为序列特征能够极大提升模型的效果。业界关于端到端行为序列建模的工作,主要分为以下三类:第一类是基于注意力机制的模型,代表性工作如 DIN[7]、DIEN[8]、DSIN[9] 以及 BST[10] 等等;第二类是基于记忆网络的模型,代表性工作如 HPMN[11] 和 MIMN[12];第三类是基于检索的模型,代表性工作如 UBR4CTR[13] 和 SIM[14]。这些工作对美团搜索多业务商品排序有很大的落地实践指导。
考虑到在聚合展示样式下,用户的行为具有异构性:用户既与聚块发生交互行为,也与聚块内的 item 发生交互行为,所以该业务排序场景相比业界大部分排序场景的用户行为序列建模不同,它属于异构行为序列建模。如上图 6 的模型结构所示,模型使用了用户的 item 行为序列和聚块行为序列,其中我们使用更加丰富的用户全美团 App 业务序列来替换美团搜索聚块行为序列。
得益于我们在美团搜索商家个性化排序上积累的实践经验(参见《 Transformer 在美团搜索排序中的实践》一文),两种序列都首先通过 Self-Attention 方式进行编码,得到一个更好的 Embedding 表示;然后对 item 行为序列直接进行 Sum-pooling,对聚块序列进行 Attention-pooling;考虑到在美团 O2O 场景下,用户的业务偏好兴趣与时间和地点有极强的关系,我们将查询词、时间和位置等上下文信息和候选聚块一同作为 Attention 中的 Target 来更好的刻画不同时空场景下用户的兴趣。
模型补充 Context-Aware 的异构双序列建模,离线 NDCG 提升了 10BP;线上 AB 测试也取得稳定正向的效果:点击率提升了 12BP,访购率提升了 9BP。
为了深入理解行为序列建模的效果,我们对 Context-Aware 部分的 Attention 权重进行可视化如下图 7 所示,发现对于用户最终发生行为的聚块,对应到行为序列中同类别聚块的权重也更大,说明 Context-Aware 能较好捕获用户当前请求的兴趣,在抽取兴趣时能够较好抑制其他行为的噪声。
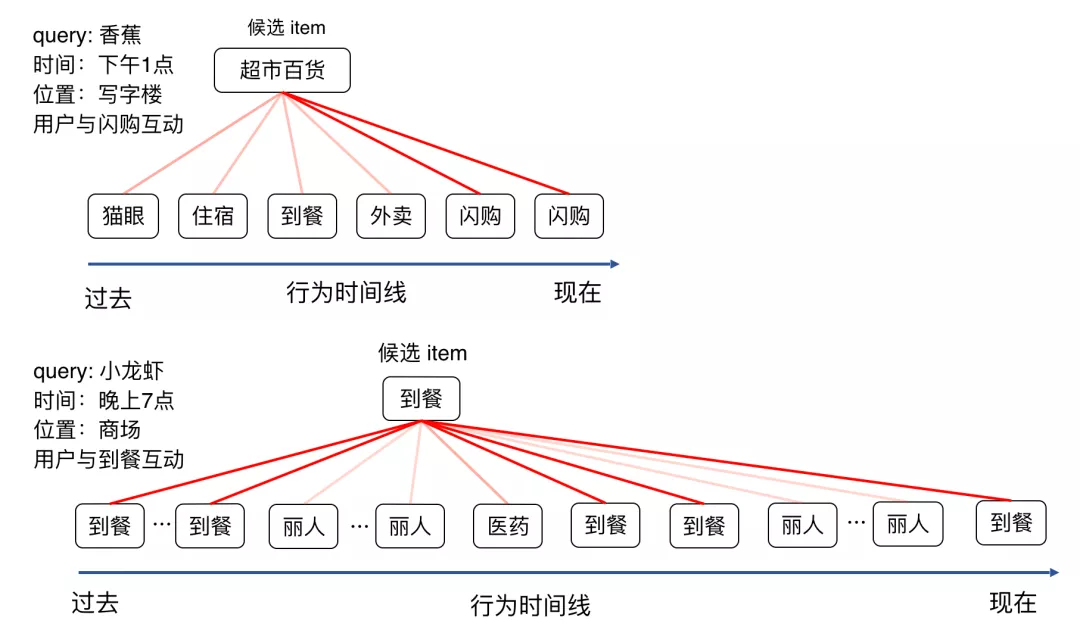
图7 Target-Attention 权重示意图
聚块大小预测建模
针对聚块大小预测的回归任务,考虑到和之前的预估分类任务差异较大,我们在特征共享层采用目前业界常用的 MMoE[16] 多任务参数共享结构,同时从业务场景来看,当偏好预估认为某个业务很强时,应该给与相对多的业务结果数,所以我们借鉴了 AITM[17] 的工作,迁移偏好预估塔中的隐藏层信息到聚块大小预估塔中,整体模型如上图 6 所示。
模型训练损失函数如公式 (5) 所示,其中 pos 表示聚块的位置信息。
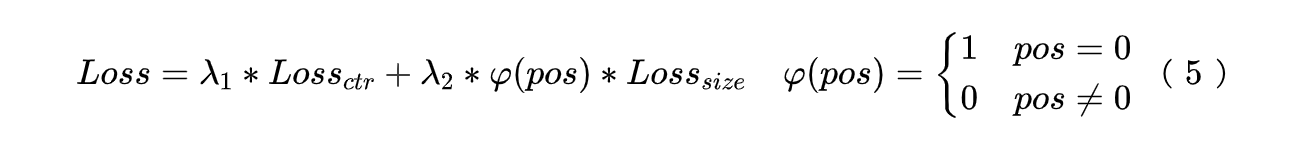
其中偏好预估损失函数 Loss_{ctrr}采用 LambdaLoss[18],如下面公式(6)所示:
Loss_{ctr}=\sum_{y_{i} >y_{j}}^{}\Delta NDCG(i,j)log_{2}(1+e^{-\sigma (\hat{y_{i}}-\hat{y_{j}})}) (6)
聚块大小预估损失函数Loss_{size} 采用 HuberLoss[19],如下面公式(7)所示:
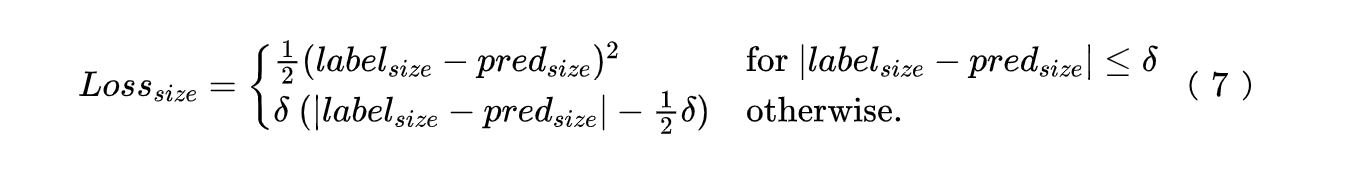
两个损失函数的权重 \lambda_1 和 \lambda_2 根据人工经验设定。针对聚块大小 Loss,考虑到实际我们只调整首位的聚块大小,所以聚块大小 Loss 只对首位聚块生效。其中的 label_{size} 会依据用户的行为反馈进行适当设计:当用户点击“查看更多”或者“聚块标题”时,会对线上历史展示个数适当放大;当用户在非首位下单时,会对首位聚块大小进行适当缩小;当用户在首位下单时,会综合考虑用户的浏览个数、最后点击位置以及历史展示大小进行调整。
对聚块大小进行联合预测,离线 NDCG持平,线上 AB 测试结果:访购率提升了 3BP。
总结和展望
本文介绍了我们在多业务商品排序上的探索与实践经验。关于多业务统一排序,基于过去商家多业务排序的经验,继续从特征选择、引入概率图模型优化模型训练来持续提升多子塔结构的效果。可以看出,我们的工作具有较好的延续性和迭代性;同时当结果采用聚合展示样式时,我们采用 GSRM 聚合模型技术策略来与之适配。这些工作也都取得了不错的效果。
未来,我们会在以下几个方面展开进一步的工作:
- 针对如何使模型更好地学习不同业务的特性和共性,将在特征自适应选择和参数共享两个方面持续迭代模型结构。
- 针对上层的业务子塔结构,不同的业务可能适用不同的参数量,将结合 AutoML 技术对多业务结构中的子网络进行优化。
- 针对目前人工设计多任务 Loss 权重带来的调参工作量�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BE%8E%E5%9B%A2%E6%90%9C%E7%B4%A2%E5%A4%9A%E4%B8%9A%E5%8A%A1%E5%95%86%E5%93%81%E6%8E%92%E5%BA%8F%E6%8E%A2%E7%B4%A2%E4%B8%8E%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


