网易迁移在网易传媒的实践

作者: 易同学
引言:把基于mapreduce的离线hiveSQL任务迁移到sparkSQL,不但能大幅缩短任务运行时间,还能节省不少计算资源。最近我们也把组内2000左右的hivesql任务迁移到了sparkSQL,这里做个简单的记录和分享,本文偏重于具体条件下的方案选择。
迁移背景
-
SQL任务运行慢
Hive SQL处理任务虽然较为稳定,但是其时效性已经达瓶颈,无法再进一步提升,同一个SQL,Hive比Spark执行的时间更长。
-
Spark SQL的发展远超HSQL
随着 Spark 以及其社区的不断发展,Spark SQL 本身技术也在不断成熟,Spark在技术架构和性能上都展示出Hive无法比拟的优势。
迁移方案设计
在迁移过程中,首先需要确认如何解决执行引擎sql语法不兼容以及执行结果不一致的问题。常用的做法是在执行引擎层面进行兼容,用户无感知,这是较为理想的方法。但对于我们来说,这是一个不可选项,组内基本工作在顶层业务层面,没有对底层spark引擎特别熟的同事,数科同事也不会对我们的祖传代码负责,所以我们只能通过修改业务sql代码解决兼容性问题。
确定了修改SQL代码的兼容方式后,接下来便需要在此基础上确定以下问题的解决方法:
- 如何将任务执行引擎切换为spark
- 如何测试任务,并验证数据一致性
- 如何自动化处理
这些问题明显是与任务的具体运行形式相关的,所以有必要先介绍下现有的hiveSQL的运行方式。现有的hiveSQL任务主要以shell脚本的方式提交,脚本代码结构如下所示:
|
|
脚本的好处在于可以通过git管理代码的变更、通过IDE搜索代码引用,坏处在于没有和公司的中台进行整合,很多功能用不上。
如何将任务执行引擎切换为spark,是分歧最大的地方。
第一种选择是直接将SQL任务迁移到公司中台上,这样可以直接在平台选择执行引擎,让平台帮我们屏蔽掉任务的运行细节。这个方法也不是不行,但工作量和难度都很大,很快就被排除了。为控制工作量,保持任务仍以脚本的形式运行是必须的,所以SQL任务的提交方式也只能通过shell命令。如何在shell中提交sparkSQL也有2个选择,第一种是直接在我们的az调度机上部署spark客户端,然后通过本地的spark客户端运行任务,另一种则是通过beeline将SQL提交到类似于hiveserver的服务上。考虑之后,我们选择了第二种,具体来说,是使用了网易有数姚老师、尤老师等大佬的作品kyuubi。
选择kyuubi的决定是非常正确的。首先,因为我们希望使用抽象的sparkSQL运行服务,把SQL扔给它就完了,业务代码和spark部署、任务运行环境等细节完全解耦,kyuubi在这方面非常合适。其次kyuubi本身的功能要远超Spark Thrift Server,主要集中在可以隔离不同的SQL任务、支持高可用、自动优化任务等方面,能让用户偷懒的组件就是好组件。最后的原因是在人员合作方面,使用kyuubi等于找到了一个稳定的背锅侠,出了问题直接让数科spark团队处理就完了,沟通非常直接,如果使用的是spark客户端或中台的SQL运行功能,中间可能隔着好几个人。
反映到具体代码细节上,我们首先编写了一个名为sparkUtils.sh的脚本,里面定义了所有与sparkSQL相关的实用函数,比如runSql、setResource等,这样其他脚本只需要source一下这个脚本,然后将hive -e改为runSql就可以将任务执行方式改为spark。
在解决如何运行任务后,接下来便是解决如何测试任务的问题。由于没有隔离的测试环境,所以在测试任务时,必须将任务代码无害化,包括替换insert的表为临时表、注释任何可能影响线上数据的操作。这样一来,同一个脚本,我们至少需要有3个版本:线上的hiveSQL版、未上线的sparkSQL版、无害化的使用sparkSQL运行的测试版,而且我们需要在他们之间同步代码更改,比如测试途中,线上版有更改,那么我们需要将更改合并到sparksql版和测试版,如果测试中发现不兼容问题,需要先在sparksql版上修改,然后合并到测试版,最后上线操作则是使用sparksql版覆盖线上版。整个过程基本以git版本管理为核心。
为确定任务是否可上线,必须计算出数据的一致程度。这里的采用的方法比较简单,先计算测试表分区和线上表分区相同的数据条数,然后算出一致度,比如线上分区数据是2条,测试分区数据是8条,相同数据是1条,那么一致度是(1*2)/(2+8)=0.2。为方便确定哪些列的数据不一致,我们计算了列hash。
切换执行引擎、测试、上线的方案都确定后,最后一个问题便是如何实现自动化处理,毕竟有2000个任务,全靠人工处理工作量太大。但由于shell脚本代码并不是结构化的数据,全自动处理也不现实,线上数据出问题的锅可背不起。
所以我们制定的策略是半自动化,人工审核代码修改,其他部分尽可能自动化,特别是测试和计算数据一致性部分。总的工作流如下图所示:
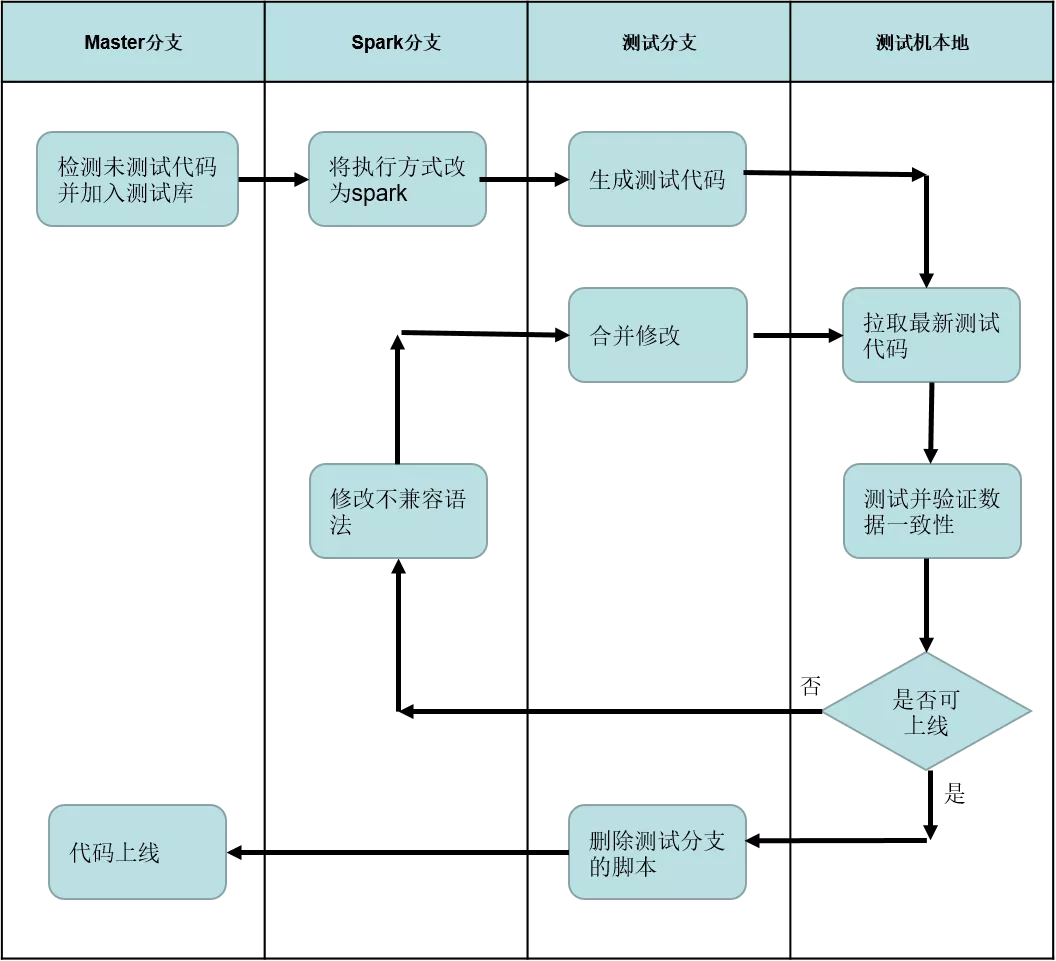
除了3个代码分支,这里多了一个测试机,用于自动化测试并计算数据一致性。各步骤具体介绍如下:
- 检测未测试代码:通过公司中台api获取有调度的脚本,拷贝到测试库,完全自动化;
- 执行方式切换为spark:自动化处理,人工审核后提交;
- 生成测试代码:通过正则匹配insert语句,替换为临时表,并在之前插入创建临时表语句,注释其他影响线上数据的操作。自动化处理,人工审核提交;
- 拉取代码、测试、计算一致程度:完全自动化,测试后本地生成一个csv的测试报告;
- 判断是否可上线:人工审核;
- 修改不兼容语法:基本靠人工修改,一些简单的参数替换可自动化;
- 合并修改:人工处理,不过基本可以自动合并;
- 删除测试代码,代码上线:自动处理,人工审核提交。
迁移成果
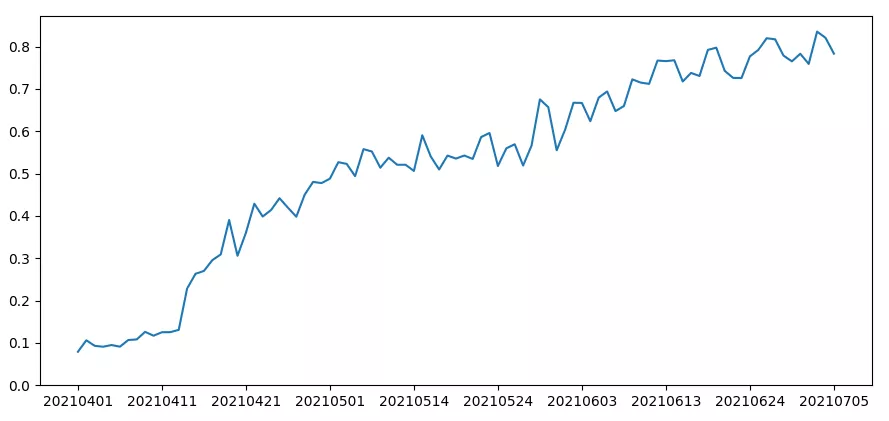
如下图所示,在2个月的时间内,我们spark程序所使用的资源从10%左右上升到了80%左右。
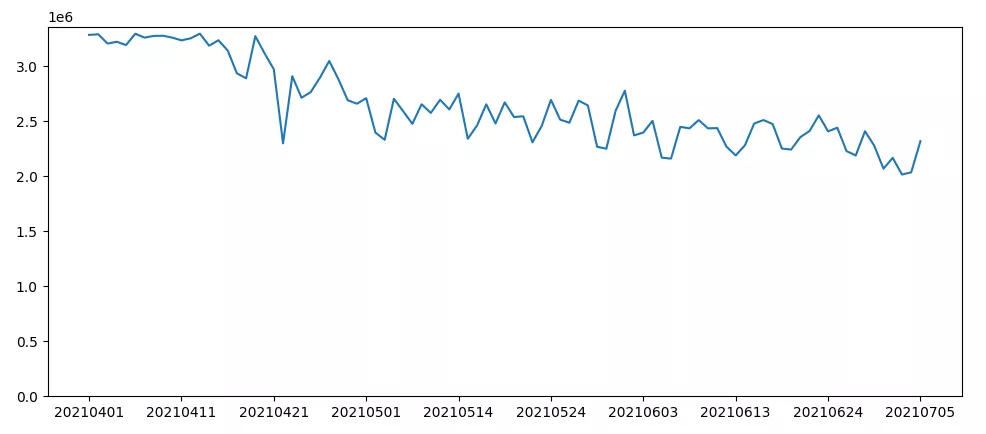
CPU累计使用(CPU核数*分钟)的变化曲线如下所示。由于迁移过程中也下线了不少任务,所以CPU总量的下降不光是迁移的功劳。
任务迁移前后的运行情况如下图所示,横轴代表任务运行时间,纵轴代表任务累计CPU使用(CPU核数*分钟)。这里共选取了600多个任务,蓝色的点代表迁移前MapReduce的运行情况,红色点代表迁移后sparkSQL的运行情况。根据统计,迁移后平均运行时间节省70%,CPU累计使用平均节省35%。
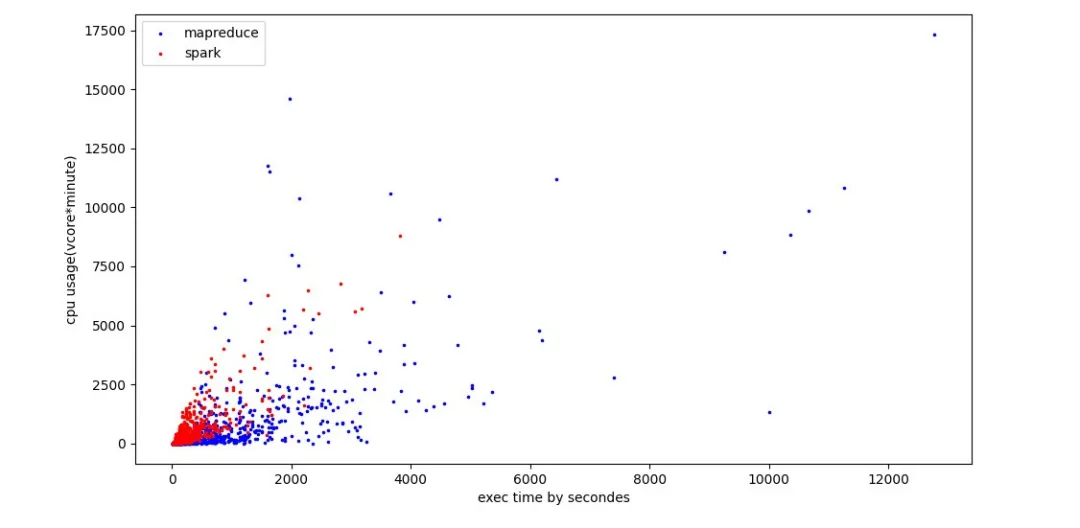
总的来看,收益超过预期,特别是在运行时间方面。
总结
回顾整个方案的设计过程,实际上没有太多选择的余地,在没法在spark引擎层做兼容的前提,和以脚本提交任务的现状下,只能选择基于git版本管理的自动化迁移流程。
方案能这么顺利�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BD%91%E6%98%93%E8%BF%81%E7%A7%BB%E5%9C%A8%E7%BD%91%E6%98%93%E4%BC%A0%E5%AA%92%E7%9A%84%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


