网易云音乐实时数仓进阶之路
导读:本篇文章是[ 2021年网易云音乐实时计算平台发展和挑战]的姊妹篇,由网易云音乐数据平台开发专家大愚分享,为大家介绍云音乐实时数仓技术改造以及未来的一些规划。
云音乐从2018年开始搭建实时计算平台,经过两年的发展实时计算已经渗透到云音乐的各个业务当中:
-
运营需要实时的统计报表做精细化的运营
-
算法同学需要实时的特征数据来提升推荐效果、需要实时的AB数据来降低试错成本
-
搜索需要实时索引数据来提升线上搜索的效果
-
业务开发需要实时的监控数据来第一时间响应线上的问题
……
发展到今天我们已经拥有开发者160+,线上任务运行任务数500+,单Kafka的峰值流量超过了400W+QPS,实时集群机器数量130+,而这还仅仅是开始,单单2020年Q1这段时间我们整体的机器以及任务的增量都超过了100%。
业务的飞速发展,开发水平的层次不齐,整体也暴露出了越来越多的问题,平台运维的压力也越来越大,如何服务好业务,提升开发者的开发效率;如何做好运维工作,保障整体平台的稳定性,都是摆在我们面前的问题。
初版我们遇到的问题
2018年我们发布了第一版的实时计算平台,整体基于Flink1.7版本开发,提供SQL和JAR包两种开发方式。JAR包任务比较简单,用户基于官方依赖库开发,上传即可;SQL方式我们采用了Antrl自定义了自己的一套SQL语法,实现了DDL、SET、CREATE FUNCTION、DIM JOIN 等语义,实现了流表的创建、属性设置、函数创建、以及维表JOIN等功能,然后集成FLINK1.7本身SQL的能力实现了一套SQL的开发能力,其整体架构如下:
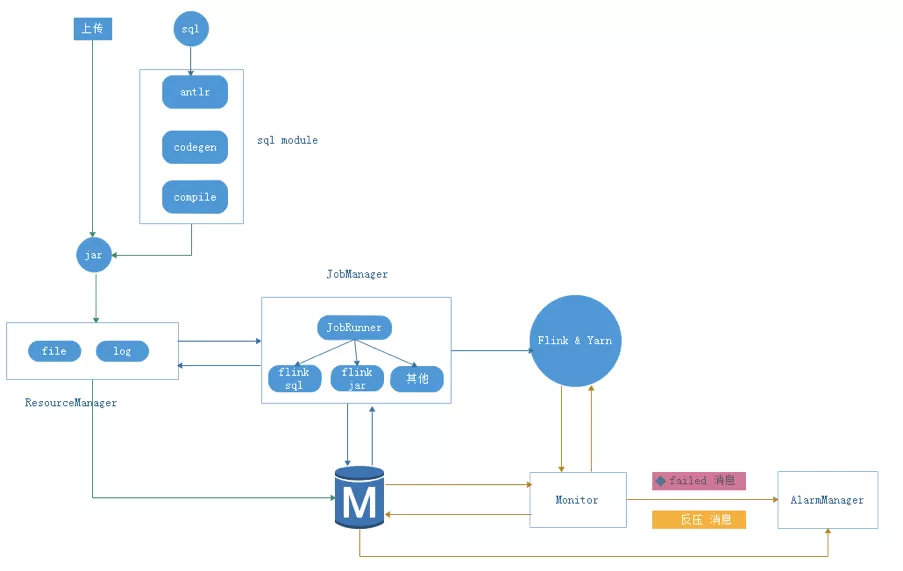
和目前业界很多的流计算平台一样,用户在使用SQL开发时需要先定义DDL,然后使用SQL定义开发逻辑,具体可以参考阿里云或者sloth目前公开出来的实时计算平台的版本,基本使用方式差不多。在业务初期这套架构很好的满足了我们业务的发展,很好的解决了很多问题,但是随着业务越来越大,我们也发现了很多问题:
数据理解问题
在每次开发任务前,开发都需要了解以下几个问题
- 需要的数据从哪里来?需要去了解数据源信息,了解数据源的读取方式
- 需要了解数据格式是什么,如何去解析
- 了解数据的具体的schema以及业务意义
整个开发流程复杂冗长,缺乏统一的一个地方让我们查询这些信息,而且整个过程缺乏复用的能力,每个人如果需要读取相同的数据都要重复的去了解一遍,成本太高而且容易出错。
任务管控问题
- 老版本的开发基本还是基于数据源的开发方式,整体难以管控。如果数据源做了迁移,需要去一个个的找到相关的任务然后一个个的修改,整体复杂冗长很难运维;
- 血缘追踪问题,老版本的任务缺乏统一的数据源管理,导致很难做血缘的track和追踪,如果一个源头数据发生变化很难track下游任务评估其影响范围;
- Jar包任务缺乏统一的风格、版本的控制,导致平台需要支持不同版本的FLINK版本,平台的开发成本越来越高,需要适配不同版本的不同配置,整体的运维成本也随之增加。整体对JAR包任务的管控基本为0我们不清楚用户的任务干什么的,属于什么级别的任务,血缘追踪也变得非常困难,整体平台的能力和一些最佳实践也很难快速的赋能给用户。
SQL易用性问题
老版本的SQL实现是在原生SQL的基础上做了一层Antlr包装,自定义了一些我们自己的语法,由于经验的缺乏以及当时Flink的SQL还处于初期的问题,整体设计上存在一些问题,使用也有很多限制。如一些语法和业界普遍使用的SQL语法存在很多出入,唯表JOIN的实现存在很多限制等,整体上和官方语法有一些出入,学习成本也偏高。
新版实时数仓改造
随着我们整体平台服务生态完善,以及FLINK本身的发展,我们在2019年底开始做底层技术的改造,开发有元数据体系的SQL开发框架,希望解决上面提到几个问题,提升平台的稳定性。
通过统一的元数据管理来解决数据理解问题,整体架构如下:
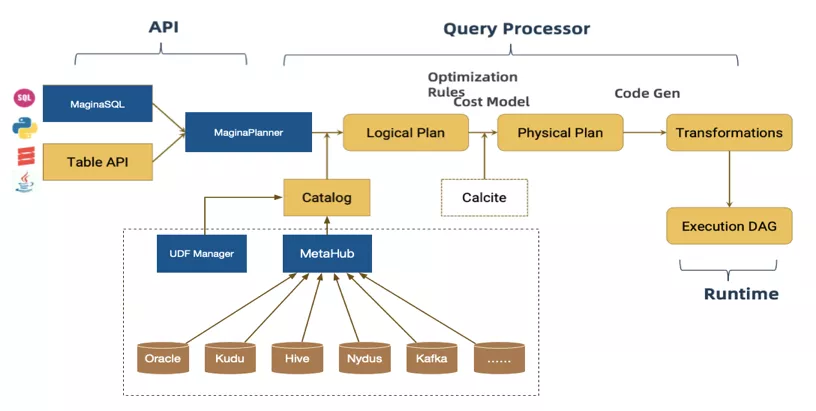
MetaHub元数数据中心是我们服务生态里面统一的元数据服务,其整体架构如下:
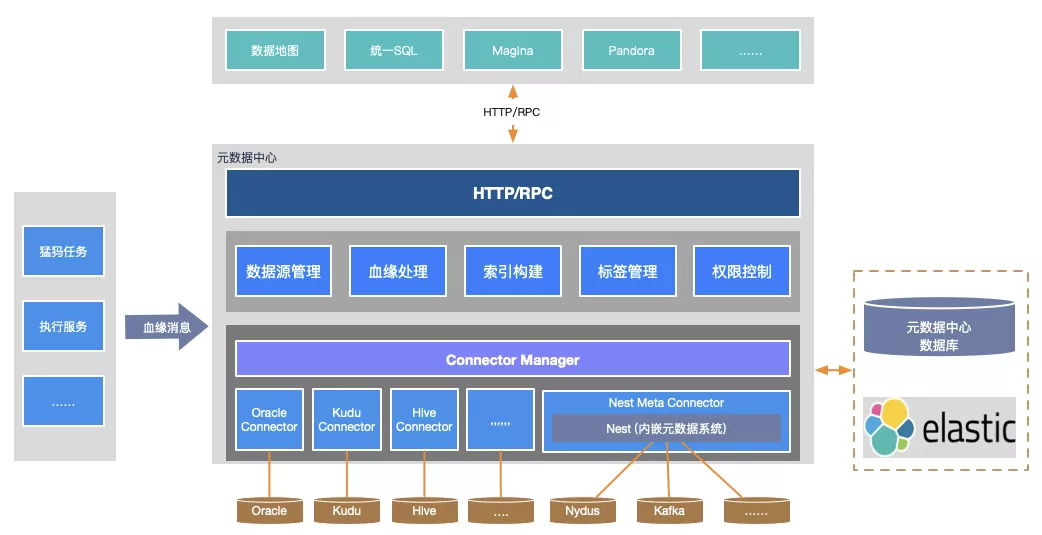
元数据中心在我们数据平台的整个服务生态中功能类似于Apache Altas,但是功能比Altas更加完善,详细在这里不做太多详细的介绍,简单介绍下源数据中心关键的几个功能:
- 采用元数据下推的方式管理Oracle、Kudu 、Hive、ES、HBase 等等自身拥有元数据系统的数据源,且可以通过插件的方式扩展管理几乎所有我们使用的数据源;
- 拥有独立的元数据系统Nest用来管理Kafka、Nydus等没有元数据体系的存储中间件,Nest的整体实现参考了HIVE的元数据系统;
- 拥有统一类型系统,在扩展数据源开发插件时,插件中需要实现相应数据源到元数据中心类型系统的映射方法;外部系统在接入元数据中心系统时不需要考虑不同数据源的类型问题,只需要关心元数据中心本身的一套类型系统即可;
- 拥有元数据检索功能,方便查找想要的数据;
- 拥有需要血缘追踪模块,只需要向元数据中心上传任务的上下游关系,就可以快速的活动整个的血缘信息。
Flink从1.9开始提供了全新的Catalog API,外部的Calalog可以很方便的插拔式的接入Flink,我们希望基于这套全新的CatalogAPI,将Flink和元数据中心打通,将元数据中心作为Flink SQL的元数据管理系统,为了实现这一想法我们实现了自己MaginaCatalog,我们主要做了以下几个事情:
类型系统转换:因为元数据中心有一套自己的类型系统,我们只需要实现元数据中心这套类型系统到Flink类型系统的转换就可以实现任何元数据中心支持数据源的Table的Schema到Flink Table Schema的转换。
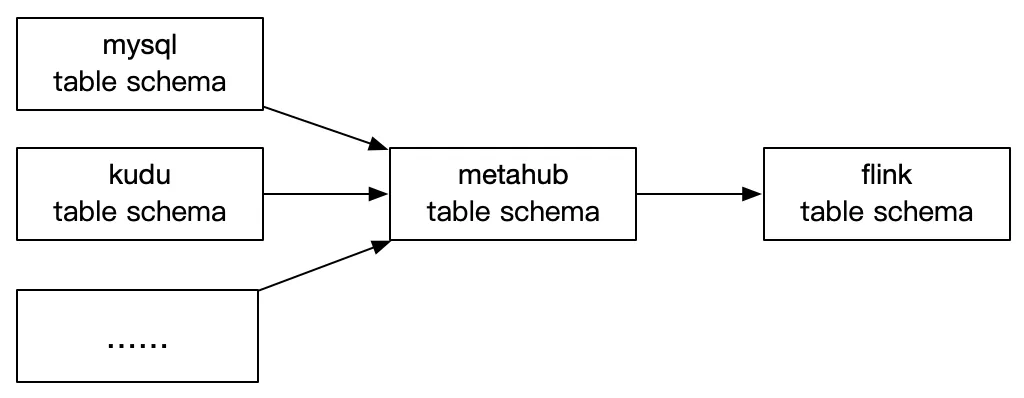
整体大部分的工作元数据中心都帮我们Cover掉了,实现比较简单。
数据源属性转换:连接信息属性转换,Flink每一种Connector都有自己的一套properties系统和元数据中心中的连接的属性信息基本都不相同。如mysql的连接地址在元数据中心的key叫url但是在Flink中JDBC的Connector的连接地址的属性叫connector.url,我们需要做一些key的转换,这块工作相对繁碎一点,但是实现起来相对简单。
Table Connector:目前官方提供的Table Connector的还不是很完善,我们根据我们需求完善了HBase、Kudu、Nydus、Redis、DDB等Connector。
完成以上工作以后,整体就基本实现我们的想法;在一个Flink任务的开发中基本涉及的数据源主要有三类:
- 流式数据:来自kafka或者 nydus,可以作为源端和目标端
- 维表JOIN数据:来自HBase、Redis、JDBC等,这个取决于我们自己实现了哪些
- 落地数据源:一般为Mysql、Hbase、Kudu、JDBC等,在流处理模式下一般作为目标端
对于流式数据,我们使用元数据中心自带的元数据系统Nest登记管理;对于维表以及落地数据源等落地数据源,可以直接通过元数据中心获取库表Schema信息,无需额外的Schema登记,只需要一次性登记下数据源连接信息即可,整体对应我们系统中数仓模块的元数据管理、数据源登记两个页面。
数据访问: 利用flink catalog提供的API,我们通过catalog、db、table三个元素来定位一张表,catalog相当于数据源的标识,db和table和其它数据库系统类似表示库和表,如我们访问截图hive_da_music数据源的music_dwd库中的user_play_fact表,只需要使用hive_da_music.music_dwd.user_play_fact访问即可,其中music_dwd.user_play_fact不需要额外登记直接使用的就是hive_da_music这个hive库中的DB和Table。
DEMO:
SET 'ods_rtrs_ab_log.connections.group.id' = 'hzwangeli2013_ab_rtrs_user_group_hour_rt_v2';
SET 'magina.sql.state.idleTime' = '14h';
SET 'table.exec.mini-batch.enabled' = 'true';
SET 'table.exec.mini-batch.allow-latency' = '60s';
SET 'table.exec.mini-batch.size' = '100000';
CREATE VIEW rtrs_log AS
SELECT
from_unixtime(`timestamp`, 'YYYY-MM-dd') as dt,
'all' as os,
sceneid,
parent_exp,
cast(from_unixtime(`timestamp`, 'HH') as int) as `hour`,
`timestamp` log_time,
`exp`,
cast(exp_type as int) exp_type,
abs(cast(userid as bigint)) userid,
'0' trace_id
FROM iplay_ods.ods_rtrs_ab_log
WHERE `timestamp` <= UNIX_TIMESTAMP() + 10
AND `timestamp` >= UNIX_TIMESTAMP() - 12 * 3600
AND abs(cast(userid as bigint)) > 0
AND sceneid IS NOT NULL
AND parent_exp IS NOT NULL
AND `exp` IS NOT NULL
AND exp_type IS NOT NULL;
INSERT INTO `music_kudu_online`.`music_kudu_internal`.`ab_rtrs_user_group_hour_rt_v2`
SELECT
dt,
os,
sceneid,
parent_exp,
`hour`,
`exp`,
exp_type,
userid,
trace_id,
count(1) pv,
min(log_time) min_time,
max(log_time) max_time
FROM rtrs_log
GROUP BY dt, os, sceneid, parent_exp, `hour`, `exp`, exp_type, userid, trace_id
- 通过SET语句配置ods_rtrs_ab_log流表的groupid、状态的过期时间
- iplay_ods.ods_rtrs_ab_log:一张流表,进行了额外的登记,没有指定catalog,是因为流表的Catalog是默认的无需额外的指定
- music_kudu_online.music_kudu_internal.ab_rtrs_user_group_hour_rt_v2: 是一张kudu表只需要登记kudu的数据源地址即可,music_kudu_internal.ab_rtrs_user_group_hour_rt_v2是kudu的表名,因为kudu本身没有库概念,这里我们做了一点特殊处理,在此不做额外的赘述
- 和普通数据库系统一样,只需要简单一个INSERT INTO语句就完成了流数据往Kudu的写入操作
对于JAR包任务,我们还提供了一个实时数仓的SDK,用户通过这套SDK可以通过SQL加DataStreamAPI的方式进行混合编程,大大降低了开发成本,用户不需要关心数据源的真实的连接信息,只需要关注catalog和库表即可,如:
public class CodeDemo extends MaginaBase {
protected void run(String args[]) throws Exception {
Table table = session.sql("SET 'ods_music_ua_queue_3.connections.group.id' = 'skd_jww_test';\\n" +
"select os from magina_dw_online.music_ods.ods_music_ua_queue_3 where os = 'pc';").get();
DataStream<Row> result = toDataStream(table);
result.print()
}
}
读取数据非常的简单明了无需关注太多的数据源连接信息、类型信息,只需要继承我们的基础类即可。
前端优化
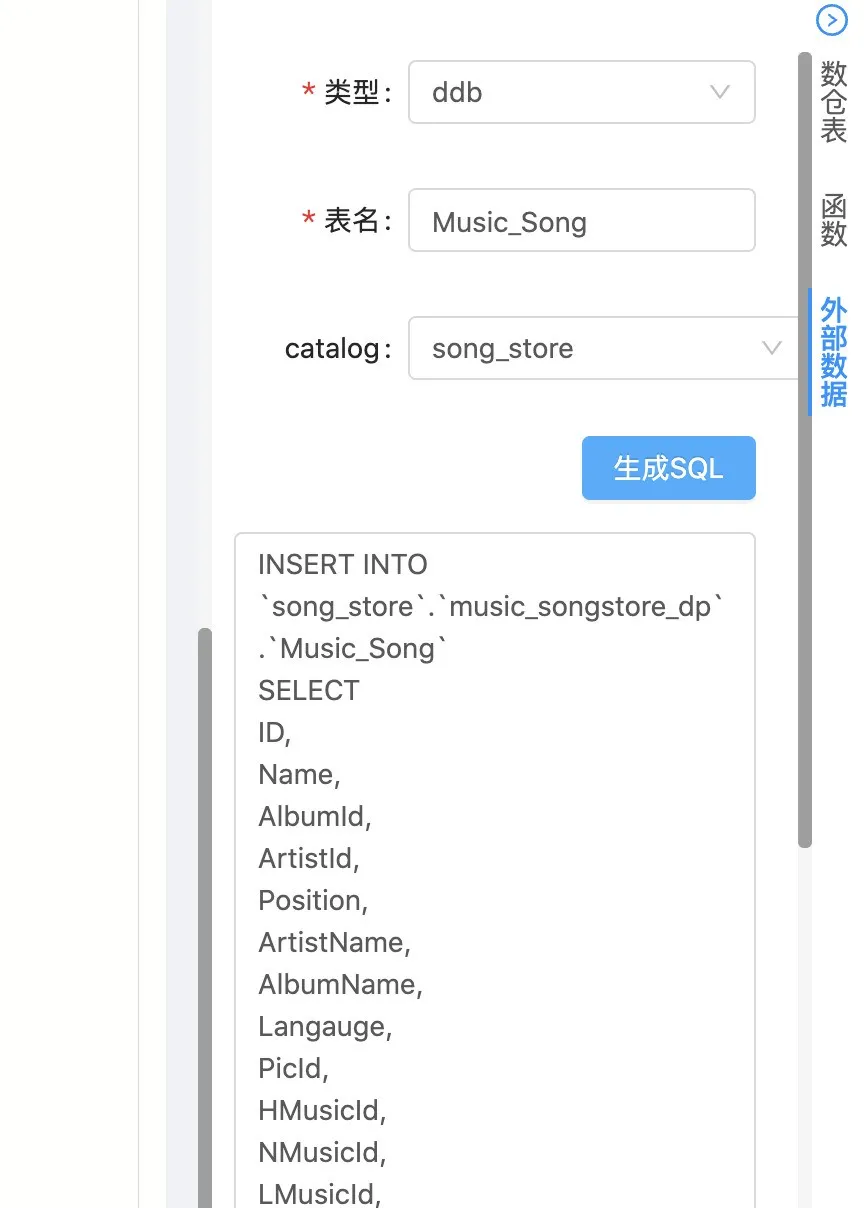
元数据的搜索和代码生成功能,方便用户查找的想要外部表,并生成相应的SQL代码
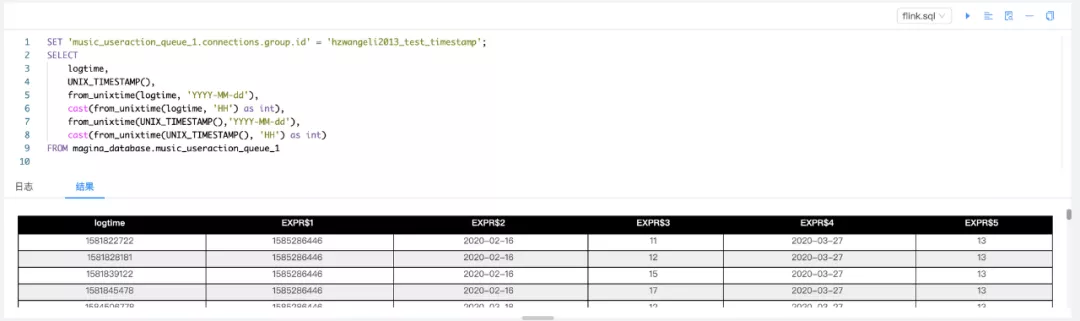
debug功能:我们参考了flink on zeppelin的实现,实现了一套自己的debug服务,用户可以通过debug获取结果。
为了方便一些特殊数据端的写入,以及方便我们后续跳出SQL规范枷锁,做一些额外的功能我们还开发了SINK输出组件,用户只需要简单的勾勾选选就可以�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BD%91%E6%98%93%E4%BA%91%E9%9F%B3%E4%B9%90%E5%AE%9E%E6%97%B6%E6%95%B0%E4%BB%93%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


