网易严选全能选手召回表征算法实践

分享嘉宾:潘胜一 网易严选 算法专家 ,严选人工智能部搜索推荐负责人。团队负责的业务包括搜索、推荐、内外部广告、用户模型等。
编辑整理:许建军
出品平台:DataFunTalk
导读: 本文主要分享 “全能选手” 召回表征算法实践。首先简单介绍下业务背景:
网易严选人工智能部,主要有三个方向:NLP、搜索推荐、供应链,我们主要负责搜索推荐。搜索推荐与营销端的业务场景密切相关,管理着严选最大的流量入口。我们团队的主要目标是优化转化率和GMV相关指标,具体业务是搜索、推荐、广告 ( 包含内部资源位广告以及外部的DPS广告 )。
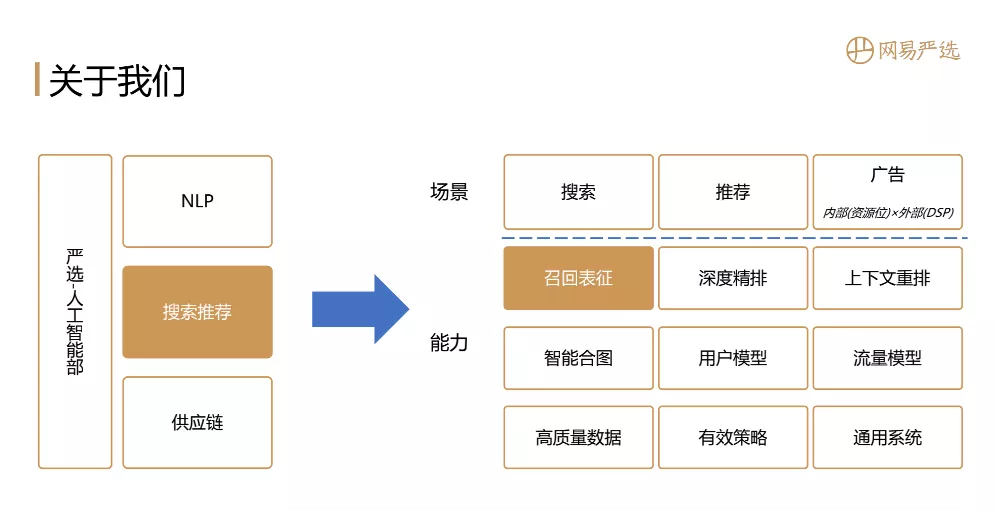
如图所示,在这些个性化场景下是我们具备的能力矩阵。刚接到邀请的时候我是想聊一聊在严选业务场景下的个性化相关事情,但是我们业务基本都做了2~3年,想在短时间聊完,只能介绍我们做了哪些工作以及取得什么样的业务价值。但是每个人的业务场景差异较大,我们这边最优的实现方案在其他场景可能并不是最优方案,大家听完之后,可能没有太大的收获。与其这样,还不如聚焦在一个小模块上详细聊一下,所以今天就选召回表征这个部分,也就引出了本次分享主题:“全能选手"召回表征算法实践,主要内容包括:
- 问题定义:召回表征究竟是要解决什么问题
- 模型价值:召回表征的价值或收益是什么
- 迭代实现:一步步迭代演化的过程
- 业务落地:业务落地的案例
01 问题定义
1. 模型目标
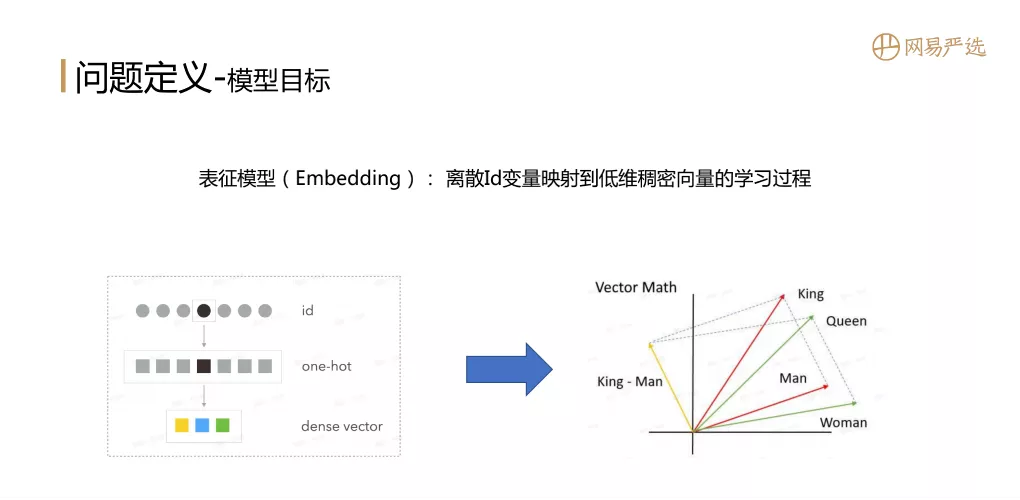
首先说一下问题的定义,就是模型的目标是想做什么?表征模型 ( Embedding ):是将离散id变量映射到低维稠密向量的学习过程。用离散id做特征时一般先做one-hot编码,然后再映射成dense vector。Embedding的目标是在大数据中体现相关性的主体,通过Embedding向量表征学习到主体的向量信息,使用向量度量公式也能体现出主体间的相关性,比如右边这个例子,红色线表示King和Man,假如这个King和Man都已经训练出一个向量表征的结果,我们希望King和Man的内积要大于Queen和Man的內积,这样就得到一个Embedding的目标。
2. 数据处理
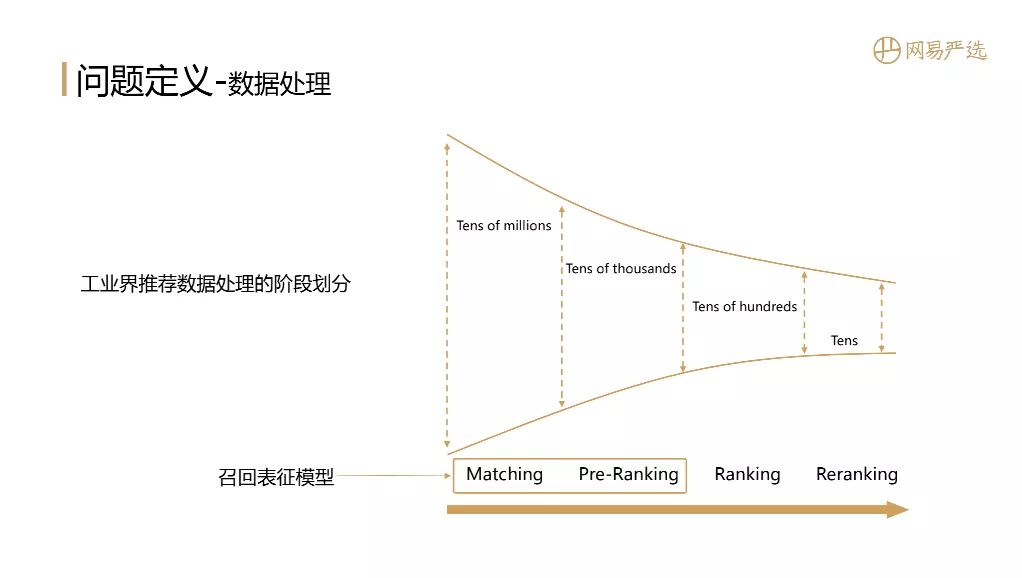
其实Embedding是一个非常通用的模型用于主体的学习和表达,它在NLP、搜索、推荐、图像中都有广泛应用。那么到具体业务场景在搜索推荐中Embedding到底是如何发挥作用的?下面这个图是一个非常经典的工业界推荐数据处理的阶段划分,从左到右是一个数据逐层递减的过程,依次是召回 ( Matching )、粗排 ( Pre-Ranking )、精排 ( Ranking )、重排 ( Reranking )。那我们的召回表征模型的作用范围主要是召回和粗排两个阶段,它在搜索推荐中起到基石的作用。
3. 模型能力
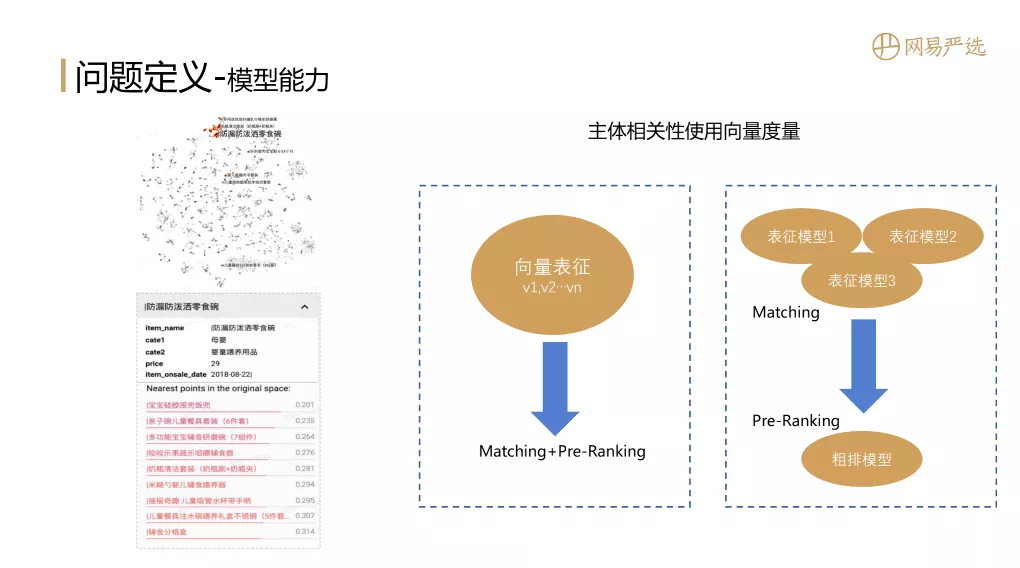
当模型训练出来后,主体的相关性是可以用向量相似度来衡量的,下图是一些item的表征形式,如果几个item相似,那么他们的距离就比较小,内积比较大,比如和零食碗相似的都是一些相同类目下的商品。如果我们只有一个向量表征模型,那么模型的Embedding既可用于召回,也可以利用两个item的Embedding向量內积来作为粗排的依据,这样召回和粗排两个场景可以一次搞定。但是大多数情况下会存在多种表征模型,每种表征模型都会去做召回,这种情况下需要引入粗排模型将多个表征模型的召回结果进行合并、排序。用于合并的粗排能力可以策略结合蒸馏模型,这里先不展开介绍。
02 模型价值
表征模型为什么值得深入去做?
1. 应用场景广泛
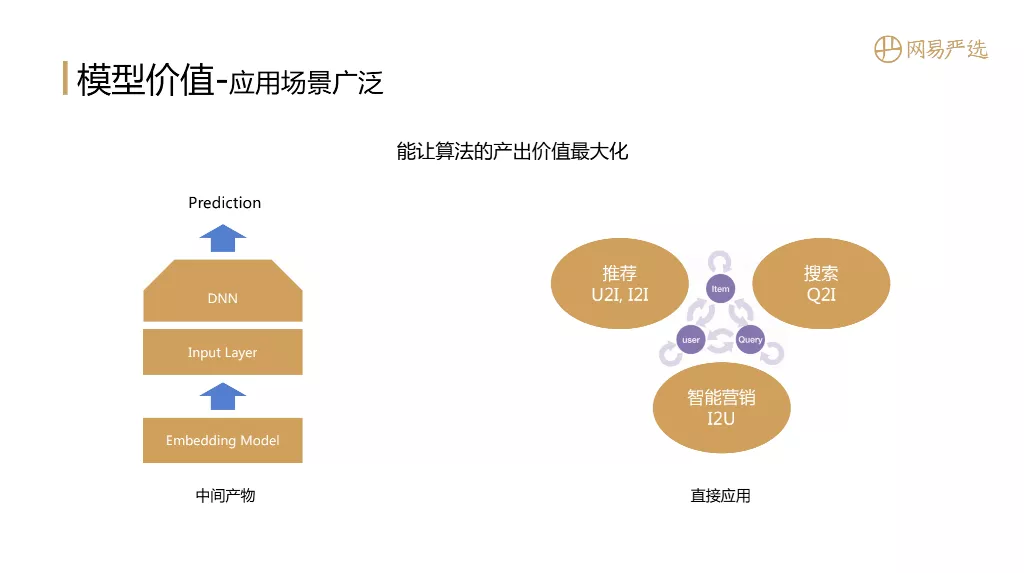
接下来介绍表征模型为什么值得深入去做?它能产生什么价值?问题答案跟文章标题密切相关:Embedding是一个全能选手,应用非常广泛,能让算法产出价值最大化。应用场景包括:
- 中间产物:Embedding结果作为精排模型向量特征的初始化权重。
- 排序呈现:拿到主体Embedding的向量,计算內积完成召回、排序的功能。
- 场景复用:端到端的场景使用,例如推荐中U2I、I2I的召回、粗排,搜索中的Q2I语义匹配,智能营销上的I2U精准触达。
2. 工程方案成熟

Embedding向量已经有了,还需要向量搜索引擎来将向量推到线上使用,具备online的响应能力。基于向量搜索引擎提供的接口可以找到与给定向量内积最大的或距离最近的TopN个向量。第一个是Facebook较早提出的Faiss的方案,第二个是Google提出的SCANN的方案;这两个方案都很好,能大幅降低工程门槛。
3. 技术发展快速

向量表征是学术圈的热点,不断推陈出新,特别是GCN ( 图卷积神经网络 )、GNN ( 图神经网络 ) 都很火,学术界每年都发表很多paper。学术研究快速发展附带的技术红利能给业务带来增量价值。接下来我们会从两个方向去聊向量表征的模型,一个是序列模型SeqModel,另一个是图网络模型,这两种模型都能解决向量表征的问题。那在选择模型的时候到底该选两类模型的哪一个?这个是与产品数据是强相关的,如果产品数据具有时间强相关性,用序列模型效果肯定不会差;如果产品数据的节点比较稀疏,需要用邻域节点做信息协同建模,这时候建议尝试下GNN。图数据几乎可以纳入任何场景产生的数据关系,所以GNN是一个普适性很高的通用模型方案,但是并不意味着在所有场景GNN都比序列模型好,实验出真知不同场景下需要多种方案对比。接下来基于我们搜索推荐业务场景的结论,与大家分享下序列模型和GNN模型的迭代。
03 迭代实现
1. 聚焦Item Embedding
严选业务中用户量是远远大于Item量的,User Embedding因为用户量很大行为又比较稀疏实验的效果不太好,所以我们初始阶段先聚焦Item Embedding,Item量较少所以落地成本较低,关联数据稠密所以表征效果较好。
① SeqModel优化
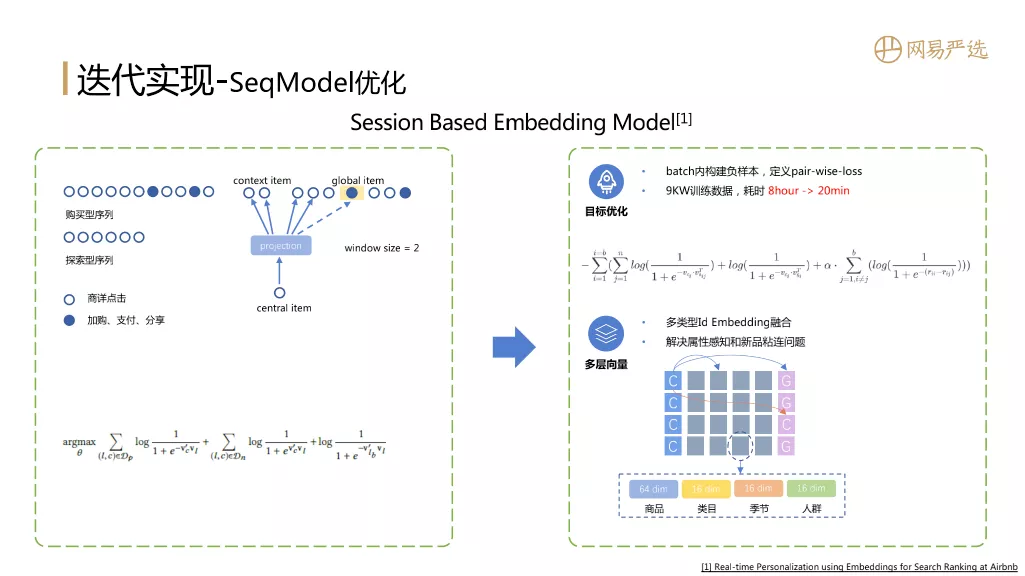
第一个模型是我们自定义并优化的Session Based Embedding Model,它的主要思路来自Aribnb的一篇Embedding论文 ( 这篇论文写的非常好,建议大家了解一下 )。这个模型的主要思路就是构建类似word2vec的序列,关注序列数据上下文时间窗口中向量的相关性。图中的每一个圈代表一个item,多个圈构成一个行为序列,行为序列来自用户在一段连续时间内的行为数据。传统的word2vec只会关注上下文的信息,这篇论文的关键思路提出global item,跳出了序列模型窗口的限制。Global item指的是序列数据中一些重要的节点 ( 图示中实心节点 ),比如用户的加购、支付、分享等行为。Global item 打破模型窗口的限制,使Item向量能学到一些high order connection信息,大幅提升序列模型的表征效果。
在此之上,我们做了一些loss function的优化,包括去除负采样的过程、在batch内构建pair-wise loss,能大幅提升训练速度;同时也引入多层向量,多层向量是side-info embedding的思路,对Item做向量表征的时候不仅仅利用它的id类特征,还会引入商品的属性、类目、适用季节、适用人群等特征以进一步提升向量表征的效果,同时还能缓解新Item冷启动表征的问题。
② GCN定义
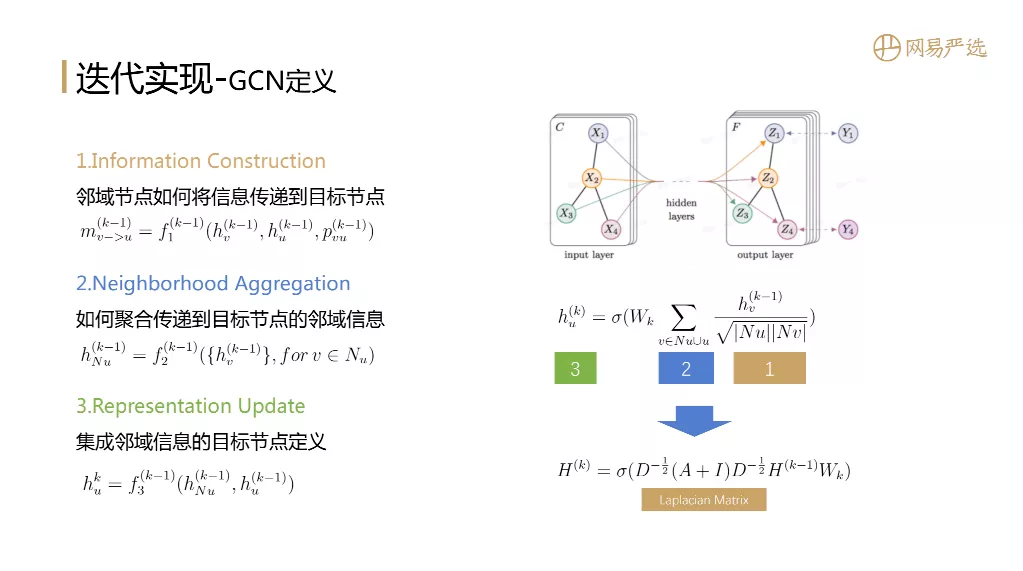
接下来聊一下学术界的热点GCN/GNN模型,图神经网络一般会有三个阶段的定义:
- 如何将邻域节点的信息传递给目标节点
- 如何聚合传递到目标节点的邻域信息
- 集成邻域信息的目标节点定义
目前很多关于GNN的paper,都会有关于这三个阶段的定义,图右边是GCN的一个示意图,图中的公式就对应三个阶段,而且非常巧妙是这个公式可以转化为矩阵运算形式,可充分利用GPU的算力。但是这个矩阵结点数是 ( #users+#items ) × ( #users+#items ),size大到工业界难落地。
③ GraphSage可落地
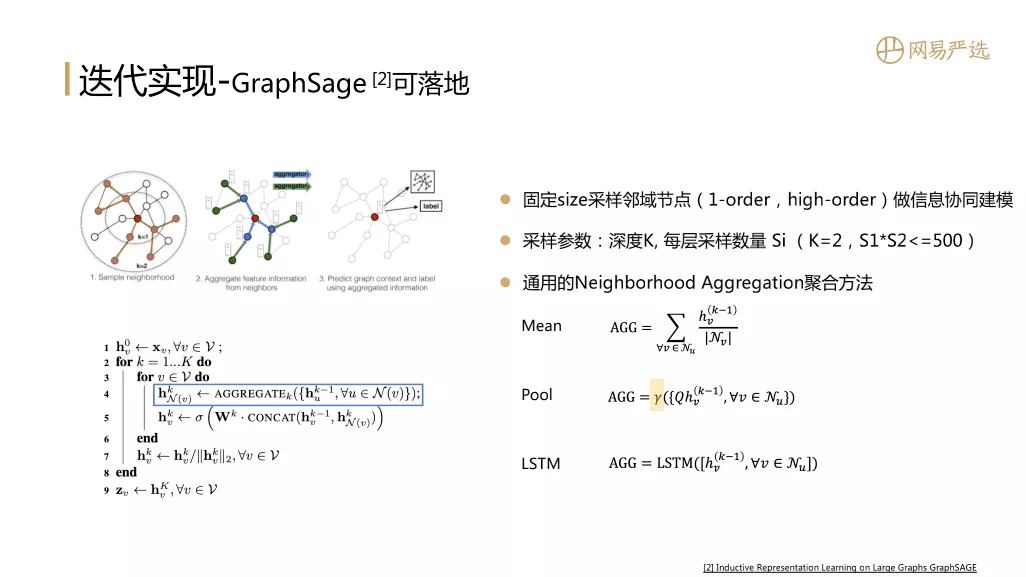
GraphSage是基于采样思路降低落地难度,用采样代替矩阵计算的过程。采样深度 ( 一般深度不会超过2 ) 对应迭代次数,多次迭代能获得高阶领域信息来做信息协同建模,同时可以调整每次迭代采样的数量。这个模型最大贡献提供了一种通用的Neighborhood Aggregation聚合方法,可以采用mean的方式进行聚合,或者引入池化层,也可以引入LSTM进行序列的聚合。
④ LightGCN的压缩数据尝试
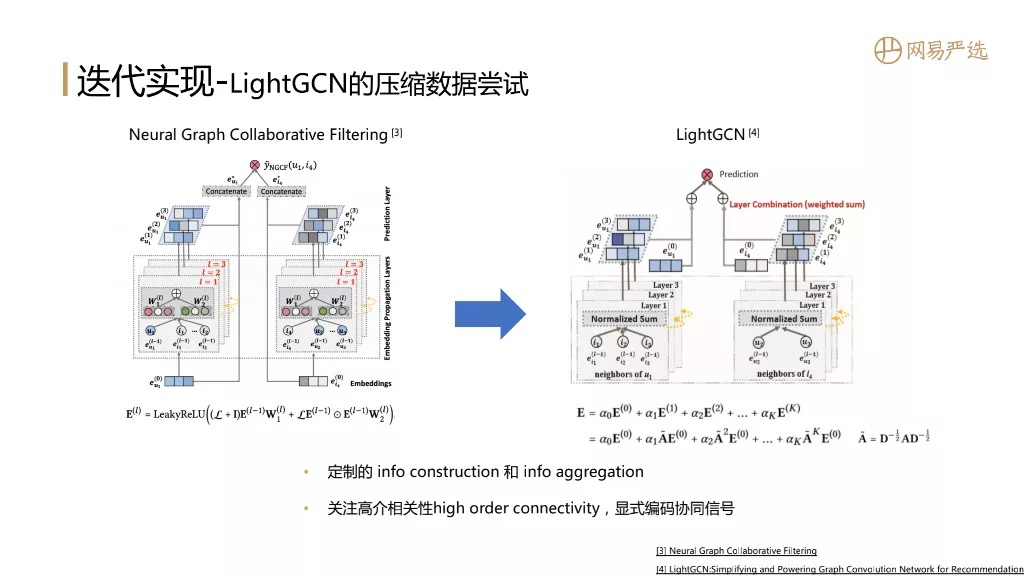
GCN需要一个大矩阵计算过程,相比工程化的思路二者效果有多少差异?能否缩减现有数据实现GCN和其他模型做一个对比?所以我们就实现了一个LightGCN,主要是参考了图中的两篇论文。两篇论文出自同一团队,论文定制信息的构建和聚合过程,能够捕捉结点的高阶相关性,显式的编码协同信号。一般GCN的网络深度不会超过2,而这里的LightGCN能做到三层,这里面的节点已经涵盖了user、item。本文最后会对所有的效果做一下对比。从知识表达上这两篇论文写得很好,大家可以去研读下,会对GCN有更好的认知。
2. 获取User Embedding
我们第一阶段获取到Item Embedding,怎么由Item Embedding得到User Embedding?主要是两种思路:策略的方法和模型的方法。
① 策略快速落地
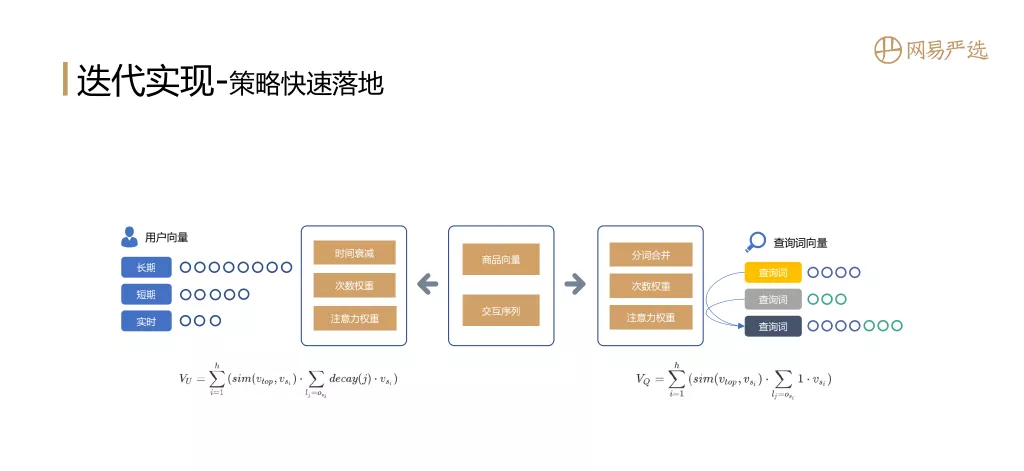
策略是能快速落地的方案,是一个很好很稳定的baseline。我们可以利用已知的商品隐向量和session中用户的交互行为序列,基于时间衰减、次数权重和注意力机制来得到用户的向量表征。同样的在搜索场景下也可以通过查询词的分词合并、次数权重、注意力权重得到查询词的向量表征。
② 经典DNN
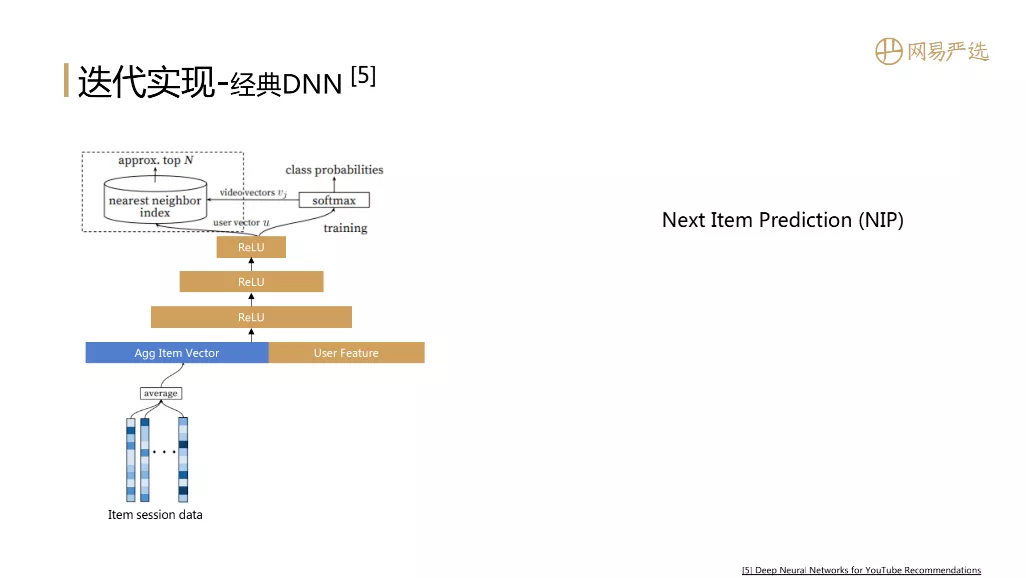
接下来还有一个经典模型DNN,直接通过模型得到用户的向量。参考图中YouTube的这篇经典论文,模型本质上是一个有监督的NextItemPrediction训练过程,用户的Item session data,做一个简单average聚合,再加上user feature作为深度模型的输入特征数据。输入特征数据经过层层传播,到达最后一层得到用户向量,用户向量和item向量做softmax,完成一个概率分布的预测,也就得到了模型的loss。模型训练完成后同时得到User和Item的向量表示。
③ 学习session表征
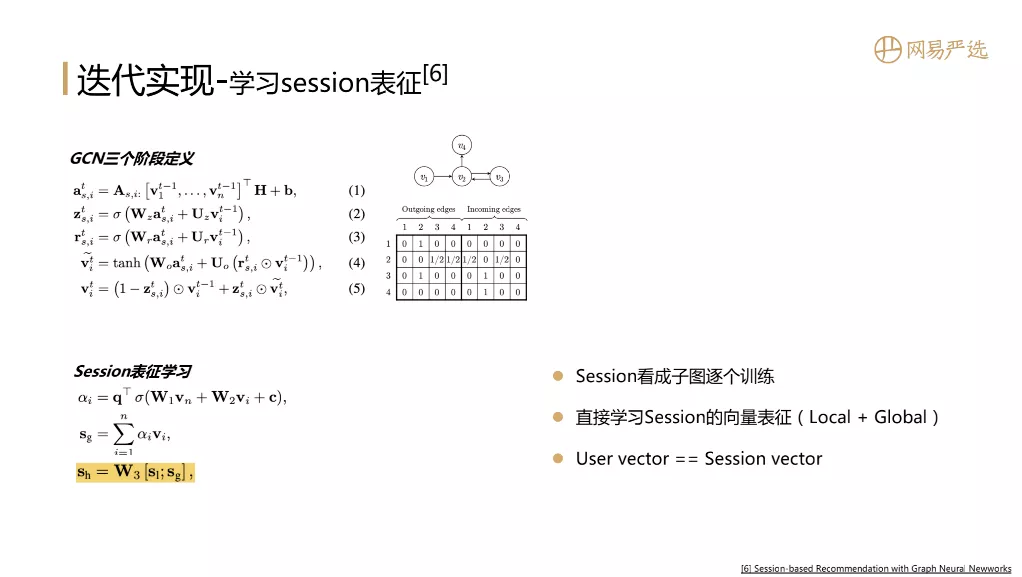
我们当然希望通过图模型得到用户的向量。用户的行为基于session来表示的,如果有一个方法能直接对session进行向量表示,那就可以直接得到行为序列下的用户向量。下图中的论文就是通过学习session向量的表示来解决这个问题,它同时也有GCN三个阶段的定义,在定义过程中还引入了门的参数来设置最终向量的表示过程。最有价值的点是它做了session的表征学习,在训练过程中每个session看成子图进行逐个训练,然后用local向量 ( session中最后一个item向量 ) 加上global向量 ( session中其他item向量经过attention聚合得到一个global向量 ) 来作为session向量,最后用session向量来代表用户向量。在离线评估中这个模型的效果是较为突出的。
④ 多个用户向量
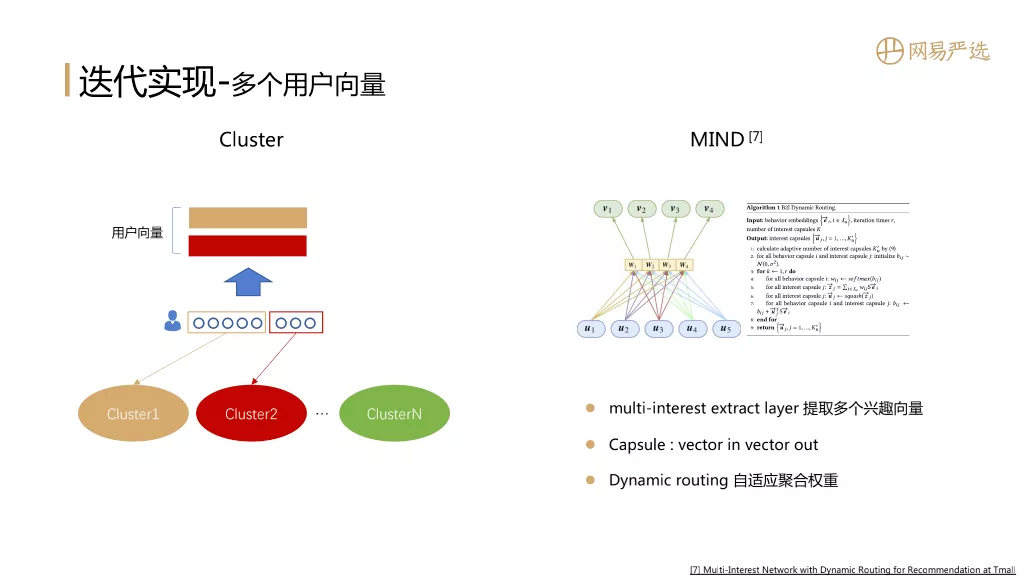
我们之前一直用单个向量对用户进行表征,那么能不能用多个用户向量对用户的兴趣进行表征呐?答案是可以的,因为如果用户的兴趣比较广泛,用一个向量进行表征会存在信息丰富度的丢失,而用多个向量来表示用户,效果可能会更好。
第一种思路是聚类方法:先将item K-means聚类得到多个cluster,每个cluster有一个向量表征。用户行为序列中的商品如果涉及多个cluster,就将属于相同cluster的向量聚合表征用户。聚合的方法可以和cluster向量计算权重后按位相加,用户向量个数等于序列中所属cluster的个数。
第二种思路是MIND:它利用胶囊网络来形成多个兴趣向量,结构中有一个multi-interest extract layer负责提取多个兴趣向量,图示中u1、u2是用户行为序列中item的向量,他们作为胶囊网络的输入,v1、v2是用户的多个兴趣向量也是胶囊网络的输出。同时胶囊网络还支持动态路由,多次迭代自适应的得到聚合权重。
3. 效果对比
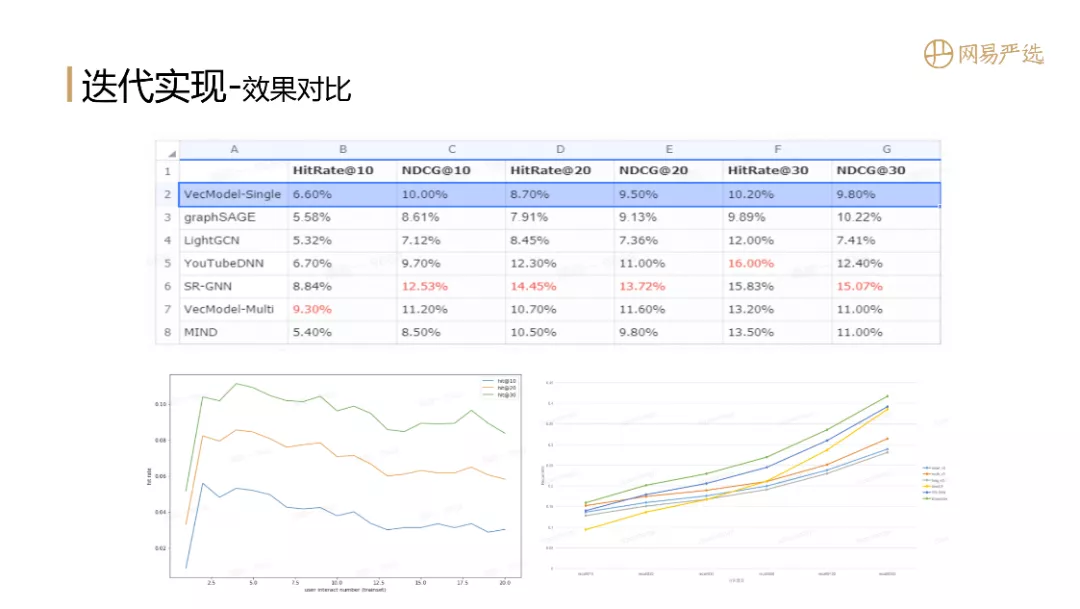
接下来我们对这几种网络模型做一个对比,对比的指标是HitRate和NDCG。我们采用VecModel-Single ( 序列模型Session Based Embedding Model ) 作为基线模型。
在我们场景数据中,graphSAGE作为GCN的一个工业落地实现指标并不突出,在NDCG@30时略微超出基线模型。LightGCN是通过缩减数据来适配目前已有的最大锅,进而生产出最大的饼;LightGCN以矩阵方式去做向量表征学习,相比基线模型效果也不是特别突出,只在个别指标HitRate@30上有一些提升。YouTubeDNN在4个指标上都有较为明显的提升。SR-GNN是直接对session做用户向量表征,通过模型参数学习求得用户向量,也是目前离线效果最好的模型。VecModel-Multi是在序列模型的基础上,增加聚类的用户多兴趣向量表示,MIND是基于胶囊网络的多兴趣向量模型;在我们数据实验中,VecModel-Multi要比MIND的效果更好。
左下图是不同用户行为分组的模型效果,X轴是用户的行为数量,Y轴是HitRate。刚开始用户没有行为时无法感知用户偏好,模型效果是比较差的 ( User Type Embedding实现NIP )。当用户有1、2个行为之后,效果指标大幅提升。这也比较好理解,因为新用户来到一个场景产生初始行为时兴趣是比较聚焦的,但是随着用户行为数量增多,仅仅用向量模型做召回和排序,指标就会下降,这时候就需要接精排、重排模型去进一步提升业务效果。右下图是多个模型在HitRate@N的效果,其中绿色曲线为使用策略将多个模型结果融合后的表现,可以看到只是做了简单的合并,相比于其他单一模型就有明显提升。后续还可以采用粗排模型合并各个表征模型的结果,效果应该还会有提升 ( 用于合并的粗排模型还在进行中 )。
04 业务落地
1. 外物皆向量
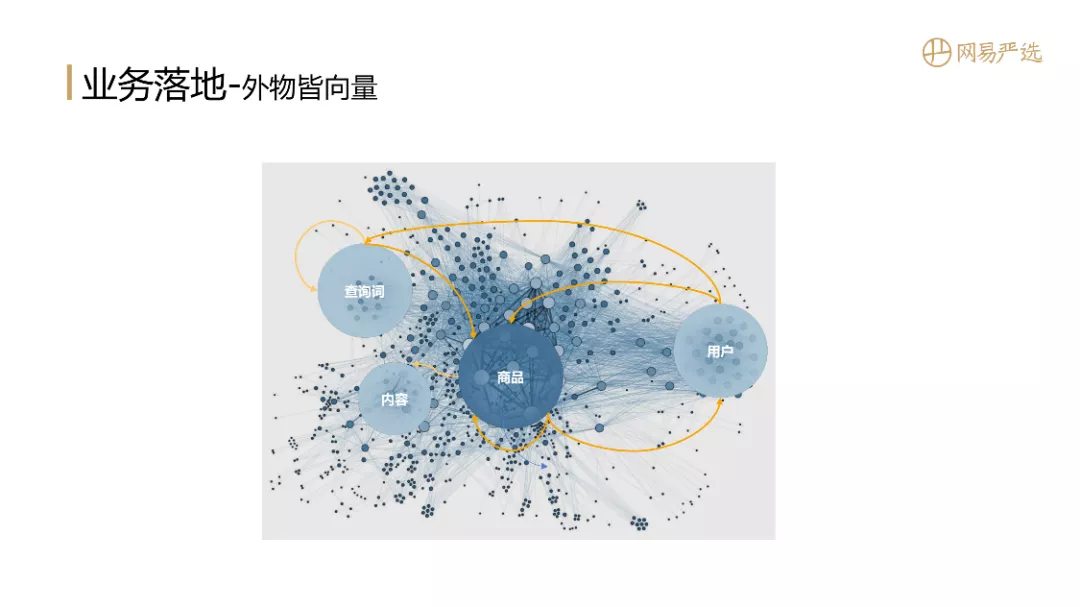
接下来我们聊一下业务上是怎么落地的,外物皆向量是Facebook提出来口号,如果我们做好了一整套向量体系之后,那么业务场景中所有的主体都可以向量化,再去做U2I、I2I、Q2I的召回就非常方便。
2. 服务示意
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BD%91%E6%98%93%E4%B8%A5%E9%80%89%E5%85%A8%E8%83%BD%E9%80%89%E6%89%8B%E5%8F%AC%E5%9B%9E%E8%A1%A8%E5%BE%81%E7%AE%97%E6%B3%95%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


