综述基于知识图谱的推荐系统综述
基于知识图谱的推荐系统综述

作者信息
Elesdspline
目前从事NLP与知识图谱相关工作。
导语
本文是2020年针对知识图谱作为辅助信息用于推荐系统的一篇综述。 知识图谱对于推荐系统不仅能够进行更精确的个性化推荐,而且对推荐也是具有可解释性的,有迹可循。
本文汇总了近些年来知识图谱辅助推荐系统的一些研究工作,并按不同的方法进行划分类别( 下图 是我根据论文画出的大纲方法类别图);除此之外,汇总了不同场景下的知识图谱数据集,涵盖7个场景;最后阐述了未来的一些可研究方向及趋势。
 基于知识图谱的推荐方法## 一、背景知识
基于知识图谱的推荐方法## 一、背景知识
推荐系统已经广泛应用在实际生活中的很多场景,特别是个性化推荐系统已经有越来越多的研究工作和落地实践,但是仍然面临着一些问题,例如数据稀疏、冷启动等问题。
近年来,利用知识图谱作为辅助信息生成推荐已经引起了人们相当大的兴趣,这种方法不仅可以缓解上述问题,更准确的进行个性化推荐,而且可以对推荐的结果也是可解释的,是有迹可循的。
下面我们将分别来看一下这两方面。
1.1 推荐系统
推荐系统在实际生活中已经有很多的应用场景,比如我们所熟知的电影、音乐、POI、新闻、教育、书籍,购物等。
推荐系统的目的旨在为 user (用户) 推荐一个(或一系列)未观测的 item (物品,电影,新闻等)。基本步骤如下:
- 学习 user 和 item 的向量表示 和 .
- 根据 1 中的 user 和 item 向量表示,计算表示 user 对 item 的偏好得分,得分函数可以采用內积、DNN等。
- 基于 2 中计算的得分,进行排序推荐。
推荐系统主要包含以下三种方法:
- Collaborative Filtering (CF): 基于协同过滤的推荐系统,协同过滤算法是从相似度度量出发,考虑 user 或者 item 之间的相似度进行相关推荐,它比较常用的两种方法是基于内存(memory-based)和基于模型(model-based)的两种方法。
- Content-based Filtering (CB):基于内容的推荐系统,与基于协同过滤从全局 user 和 item 的交互数据中学习他们的向量表示相比,基于内容的推荐方法从 item 的内容中学习 user 和 item 的表示。它认为 user 可能对与他们过去交互过的 item 中相似的 item 感兴趣。
- Hybrid Method:混合推荐系统,CF 方法容易遇到冷启动或者交互矩阵数据稀疏的问题,而混合推荐系统可以利用基于内容的推荐系统中的 user 和 item 信息来缓解这一问题。混合推荐系统通过将 user 和 item 的内容信息,即用户辅助信息和物品辅助信息整合到 CF 的框架中,可以获得更好的推荐性能。
1.2 基于知识图谱的推荐系统
近段时间,基于知识图谱的推荐系统(KG-based recommendation system, KGRS)引起研究者的广泛兴趣,主要是把知识图谱作为辅助信息整合到推荐系统中,这样的做法带来两个方面的优势, 其一是能够提高推荐系统的准确性,其二是能够为推荐系统提供可解释性。
准确性:知识图谱可以用来表示实体之间的关系,可以将 item 及其属性信息映射到知识图谱中,以理解 item 之间的相互关系,此外,还可以将 user 和 user 的辅助信息整合到知识图谱中,更准确地捕捉 user 和 item 之间的关系以及 user 的偏好。
下图所示是一个基于知识图谱的推荐系统,我们来简单看一下,KG 中包含了电影(圆形代表)、用户,演员和导演(人头像代表)以及电影风格(摄影机代表)这几种实体节点,实体之间又包含了几种不同的关系,通过这个知识图谱, 给 Bob 推荐了两部电影 “Avatar”《阿凡达》和 “Blood Diamond”《血钻》。 看图能够看出,电影和用户之间有着不同的潜在关系,有助于提高推荐的准确性。
 KGRS 可解释性: 基于 KG 的推荐系统的另一个优点是推荐结果具有可解释性。在上面的图中,通过遵循图谱中的关系序列,我们可以知道向 Bob 推荐这两部电影的原因。例如, 推荐《阿凡达》的一个原因是,《阿凡达》与 Bob 之前看过的“Interstellar”《星际穿越》属于同一类型风格的电影。
KGRS 可解释性: 基于 KG 的推荐系统的另一个优点是推荐结果具有可解释性。在上面的图中,通过遵循图谱中的关系序列,我们可以知道向 Bob 推荐这两部电影的原因。例如, 推荐《阿凡达》的一个原因是,《阿凡达》与 Bob 之前看过的“Interstellar”《星际穿越》属于同一类型风格的电影。
下图中列出了一些流行的知识图谱,根据所涵盖知识的范围,这些知识图谱可分为两类,一类是 cross-domain 的知识图谱,另一类是 domain-specific 的知识图谱,也就是说一类是包含知识广的通用型知识图谱,一类是包含特定领域知识的垂直领域知识图谱。
 Cross-domain and specific-domain KG下面我们将看一下知识图谱如何作为推荐系统的辅助信息?是怎么应用的?以及有哪些代表性的Model。
Cross-domain and specific-domain KG下面我们将看一下知识图谱如何作为推荐系统的辅助信息?是怎么应用的?以及有哪些代表性的Model。
二、Methods
通过对最近研究的相关调研,发现基于 KG 的推荐系统对 KG 的应用有三种方式:
- 基于 Embeddig 的方法(The embedding-based method)
- 基于路径的方法(The path-based method)
- 联合的方法(The unified method)
我们接下来将在各小节了解一下对应的方法,在这之前,先给出下面的一章图片,列出相关的符号和概念。

2.1 基于Embeddig的方法
基于 Embedding 的方法通常直接使用来自知识图谱的信息来丰富 item 或 user 的表示。为了充分利用 KG 的信息,需要应用KGE/KRL算法将 KG 中的实体和关系映射到低维向量空间。KGE 算法可分为两类:基于翻译的模型,如 TransE、TransH、TransR、TransD等;语义匹配模型,如 DistMult等。
根据 KG 是否包含 user,又将这类方法分为两部分,即 item graph 和 user-item graph。
2.1.1 使用 item graph
在该方法中,KG 由 item 及其相关属性组成,这些属性是从数据集或外部知识库中提取的。我们将这样的图命名为 item graph。注意,user 不包括在 item graph 中。
这类方法利用 KGE 等模型对 item graph 编码获取更加丰富的 item embedding,然后结合 item 的多种信息构成完整的 item 表示,例如 user-item 交互矩阵信息、KG 信息、item 属性信息、item 内容信息等。然后再单独计算 user 的表示(可以从交互矩阵中获取)和得分函数。
得分函数的公式如下,其中 user 和 item 的向量表示分别为 和 .目的是计算 user 选择 item 的可能性大小,然后排序之后返回相应的 item。 这里的 f 可以是內积、DNN等。
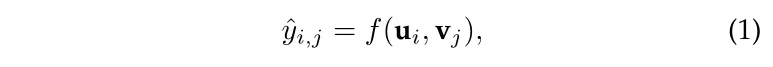
在这类方法中,有一些 典型的模型 代表,如 CKE、DKN、KSR。
我们拿 CKE 模型来简单说一下:CKE 模型在 CF 框架中整合了各种辅助信息,它们将 item 的结构化知识(item graph)以及内容知识(文本、图像等)采用 KGE 方法编码整合到一起。
具体来说,采用 TransR 算法对 item 的结构化知识 进行编码,对文本特征 和图片特征 采用自编码结构进行提取,这些表示与从 user-item 交互矩阵中抽取到的偏移向量 一起整合,具体公式如下(2)。再获取到 user 的向量表示后,采用两者内积的方式计算 user 选择 item 的可能性大小,然后排序。
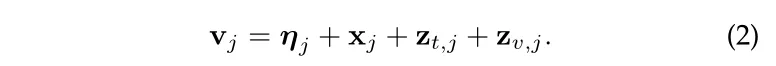
2.1.2 使用 user-item graph
该方法直接构建 user-item graph,其中 user、item 及其相关属性作为节点(实体)。在 user-item graph 中,属性级关系(品牌、类别等)和 user 相关关系(co-buy、co-view等)作为边(关系)。 在利用 KGE 编码得到相关的实体表示后,既可以利用 item graph 中的公式(1)计算 user 的偏好,也可以将关系向量考虑进去,采用新的计算方法,如下:
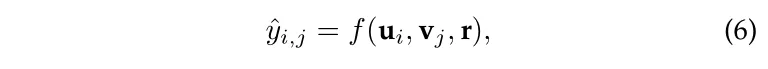
在这类方法中,有一些 代表性模型 如 CFKG、SHINE、DKFM。
我们简单的说下 CFKG:CFKG 是构建了一个 user-item 知识图谱,即 user-item graph,在这个 KG 中,user、item 及其相关属性作为实体,用户的一些历史行为(如购买、提及)被视为实体之间的一种关系类型,并且包含了多种关系类型的 item 辅助信息(如评论、品牌、品类、购买组合等)。为了更好的学习实体以及关系的 Embedding,重新定义了一个距离计算函数,如下:
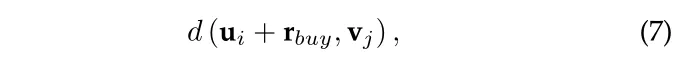
2.1.3 其他的方法
以往的一些研究工作一般直接利用 KGE 技术学习到的 user 或者 item 表示进行推荐。最近,有些研究工作尝试通过 改进 KGE 方法学习到的实体/关系表示来提高推荐性能,例如结合 GAN 的 KTGAN 方法,以及结合 TransE、GNN 和贝叶斯框架的 BEM 方法。
除此之外,另一种趋势是采用 多任务学习(Multi-task Learning)的方法,在一些基本 KG 相关任务的共同学习下做推荐任务。大概来说,有一个推荐系统的任务 f 用于从 user-item 交互矩阵中学习,推荐 user 感兴趣的 item,对应的在 KG 的三元组分类任务 g 中,判断这个三元组是否有效,这两个任务在损失函数部分结合,共同学习。这样学习的一个大概动机在于推荐系统中的 item embedding 共享来自 KG 中的实体 embedding。这类方法的一些典型代表如: KTUP、MKR、RCF 等。
2.2 基于 Path 的方法
基于 Path 的方法构建 user-item graph,并利用 KG 中实体的连通性模式进行推荐, 基本思想是考虑到 user 和/或 item 之间连通相似性(实体语义相似性),进而提升推荐效果。
根据 path 的不同使用方式又做了细分,主要是基于 path 的连通相似度和把 path 嵌入到低维空间,获取 path embedding,我们下面分别看一下。
2.2.1 path 的连通相似性
这种方式是利用计算不同路径下实体之间的语义相似性,并作为一种正则方法优化 user 和 item 的表示,进一步就可以采用公式(1)中內积的方式计算 user 选择 item 的偏好可能性。
有三种类型的实体相似性方法如下:
User-User Similarity: 如果 user 之间具有较高的元路径相似度,那么将迫使 user 在向量空间中接近。
Item-Item Similarity: 与上面的类似,如果 item 基于元路径的相似度高,则 item 的向量表示应该接近。
User-Item Similarity: 如果 user 和 item 的元路径相似度很高,那么 user 和 item 的向量就会非常接近。
这个方法的典型模型有: FMG、Hete-MF、HeteRec、HeteRec_p、Hete-CF、SemRec、HERec、RuleRec。
2.2.2 Path embedding
这种方法直接学习连接 user 和 item 之间的显式 path(部分/所有) embedding,以便直接对 user-item 的关系建模。
具体来说一下,假设存在 user 和 item 之间存在 K 个路径,针对其中的路径 p ,学习到其向量表示为 ,最终的路径信息如下,其中 g 可能是 max-pooling 或者是加权的 sum-pooling。
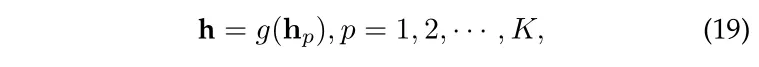
接下来可以采用下面的方式计算 user 对 item 的偏好。
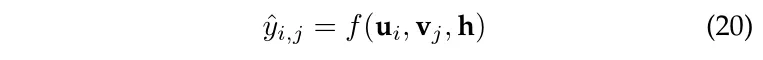
这一方法的代表模型如:MCRec、RKGE、KPRN、PGPR、EIUM、Ekar.
2.3 联合的方法
基于 embedding 的方法利用 KG 中 user/item 的语义表示进行推荐,而基于路径的方法使用语义连通信息,而且这两种方法只利用 KG 中一个方面的信息。
为了更好地利用KG中的信息,提出了将实体和关系的语义表示与路径连通信息相结合的统一方法, 统一的方法是基于 Embedding 传播的思想。 这些方法以 KG 中的路径连通性为指导精炼了实体表示(user/item)。
这里面也是分为了两类方法,具体的下面简单看一下。
2.3.1 基于 user 的历史行为
这个基本思想是利用 user 在历史交互行为中交互过的 item 以及 item 的多跳邻居这些行为丰富 user 的表示信息。
丰富的 user 表示可以表示如下,其中 代表 multi-hop ripple sets, g 代表 concatenate embeddings 的操作。
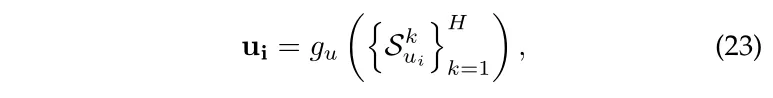 因为传播是从 user 参与的 item 开始的,所以这个过程可以看作是在 KG 中传播 user 的偏好。
因为传播是从 user 参与的 item 开始的,所以这个过程可以看作是在 KG 中传播 user 的偏好。
代表的模型如:RippleNet、AKUPM、RCoLM
2.3.2 基于 item 的多跳邻居
这种方式是利用 item 的多跳邻居(multi-hop neighbors) 来丰富 item 表示。一个通常的表示如下:
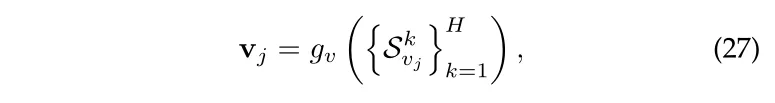 是候选 item 的 ripple set, g 代表 concatenate embeddings 的操作,concatenate 要做两步的操作。
是候选 item 的 ripple set, g 代表 concatenate embeddings 的操作,concatenate 要做两步的操作。
首先要学习候选 item 的 k 阶邻居的表示:
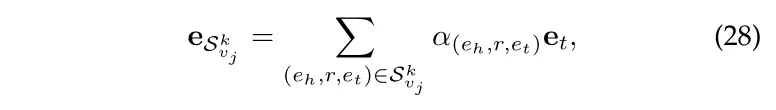
然后更新:
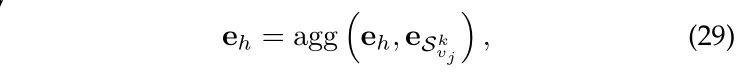
其中 agg 可以是 Sum Aggregator、Concat Aggregator、Neighbor Aggregator、Bi-Interaction Aggregator等。
典型的代表模型如:KGCN、KGCN-LS、KGAT、KNI、IntentGC、AKGE.
2.4 Methods 小结
基于 Embedding 的方法使用 KGE 方法对 item graph 或 user-item graph 的 KG 进行处理,获取实体和关系的 embedding,并进一步整合到推荐框架中。但是, 该方法忽略了 KG 的信息连通性,缺少可解释性。
基于路径(Path)的方法通过预先定义元路径或自动挖掘连接模式,利用 user-item graph 来发现 user 或 item 的路径相似度。 基于路径的方法还可以为推荐的结果的提供可解释性。
联合方法是将基于 Embedding 的方法与基于路径的方法相结合,充分挖掘两方面的信息,是当前的研究趋势。此外,联合方法还具有解释推荐过程的能力,具备可解释性。
根据上述的方法分类,我将其用下面的一张图来表示:
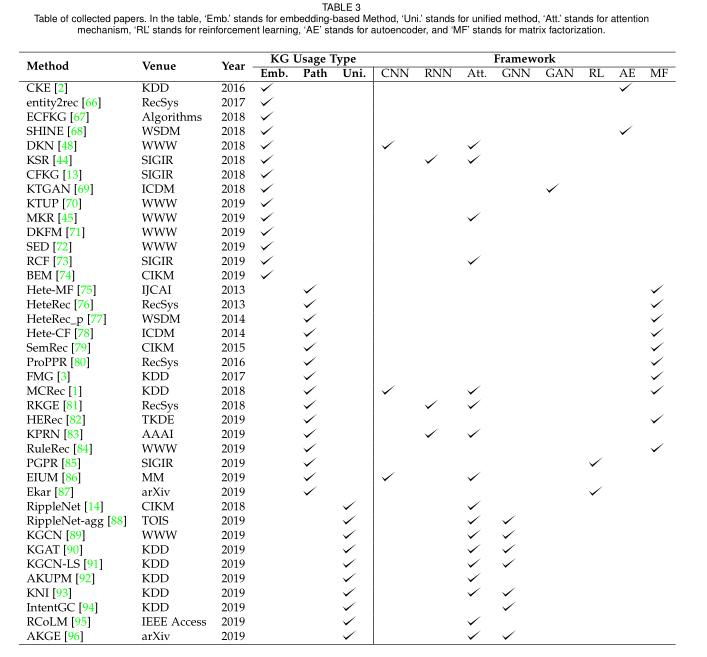
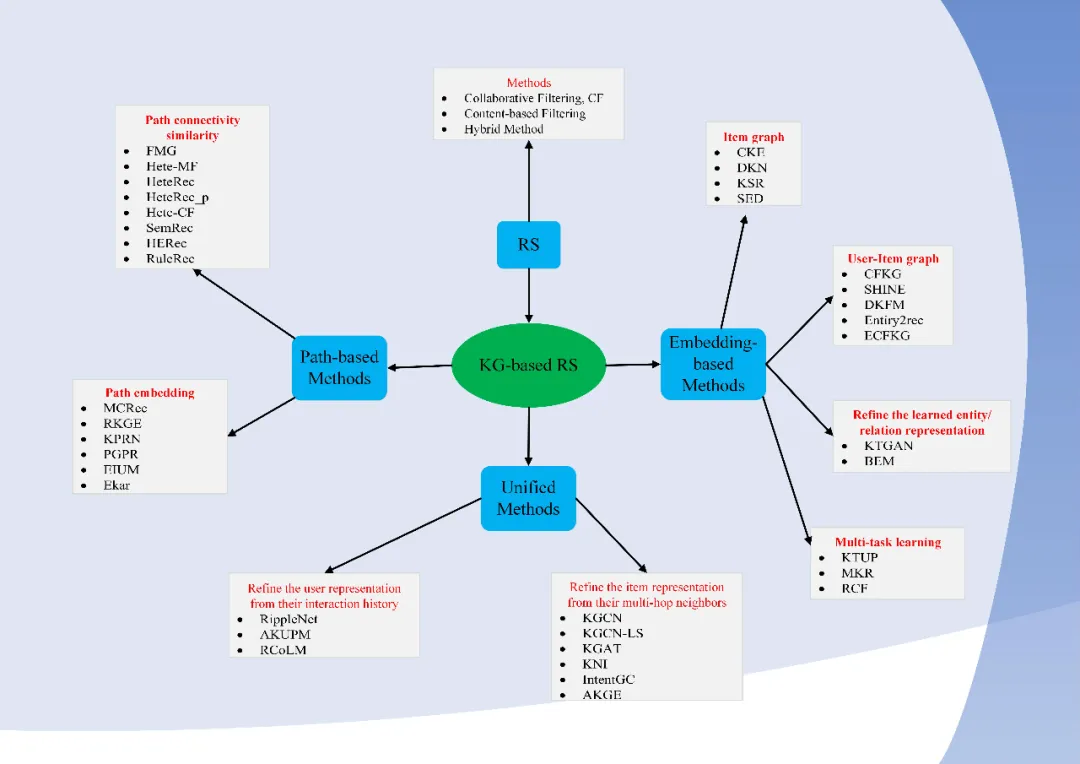 基于知识图谱的推荐方法上述代表性的模型在下图中全部列出:
基于知识图谱的推荐方法上述代表性的模型在下图中全部列出:
三、DataSets
基于 KG 的推荐系统除了具有准确性和可解释性之外,另一个优点是这种类型的辅助信息可以很自然地结合到不同应用的推荐系统中。为了证明 KG 作为辅助信息的有效性,基于 KG 的推荐系统在不同场景下的数据集上进行了评估。在本节中,我们将根据数据集对这些工作进行分类,如下:

四、未来研究方向
虽然已经提出了许多新的模型来利用 KG 作为推荐的辅助信息,但仍存在一些机会。在此概述和讨论一些未来的研究方向:
1 动态推荐(Dynamic Recommendation):现有的大多数方法都是采用用户的静态偏好推荐。然而,在某些情况下,如在线购物、新闻推荐、Twitter 和论坛,用户的兴趣可能会很快受到社会事件或朋友的影响。在这种情况下,使用静态偏好建模的推荐可能不足以理解实时兴趣爱好。为了捕获动态偏好,利用动态图网络可以作为一种解决方案。
2 多任务学习(Multi-task Learning):知识图谱中可能存在丢失的事实,从而导致丢失关系或实体,用户的偏好也可能因此而被忽略,从而导致推荐结果的恶化。将知识图谱补全和推荐系统联合训
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BB%BC%E8%BF%B0%E5%9F%BA%E4%BA%8E%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1%E7%9A%84%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E7%BB%BC%E8%BF%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


