统一预估引擎的设计与实现
1. 背景
随着互联网的快速发展,互联网上出现了各种海量的信息。怎么样为用户推荐感兴趣的信息是个很大的挑战?各种各样的推荐算法、系统都涌现出来。而预估引擎可以说是推荐系统中比较重要的一环,预估引擎效果的好坏严重影响了算法效果。结合oppo的业务场景,我们的预估引擎需要解决几个问题:
(1)通用性:oppo的推荐业务场景非常多,包括信息流、商店、短视频、联盟、锁屏杂志、音乐等业务,预估引擎要支持这么多的场景,框架一定要通用。
(2)多模型预估:在广告场景中,需要支持ocpx,需要一次请求同时预估ctr和cvr,可能是多个不同的转化模型(例如下载、付费等)。
(3)模型的动态更新:有些模型是小时更新、有些模型是天级更新,需要做到能够无感的动态更新。
(4)扩展性:各个业务用到的特征、字典、模型类型都可能不一样,要做到比较容易扩展。
2. 定位与技术选型
考虑到各个业务的业务特征差异比较大,统一预估引擎如果要支持各个业务的策略实验和分流实验,会让预估引擎模块非常臃肿,没法维护。所以最终决定预估引擎只做预估相关的事情。
从原始数据到得到预估ctr结果,需要经过特征提取,提取特征之后的结果再进行模型预估。考虑到特征提取结果比较大,一次预估需要用的特征结果大约有2M,这么大的数据如果通过网络来传输,耗时太长。所以预估引擎总体的流程包括了两部分:特征提取和模型预估。
3. Predictor的设计与实现
3.1 Predictor模块在整个推荐系统中的位置
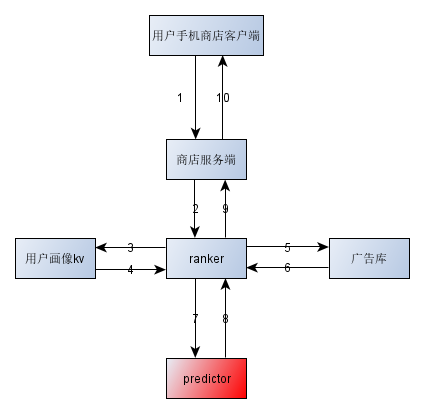
以oppo手机应用市场为类来说明predictor模块在整个系统中的位置, ranker模块负责排序,包括各种分流实验和各种运营策略等。它通过grpc框架与predictor模块进行通信。
3.2 Predictor模块的主体流程
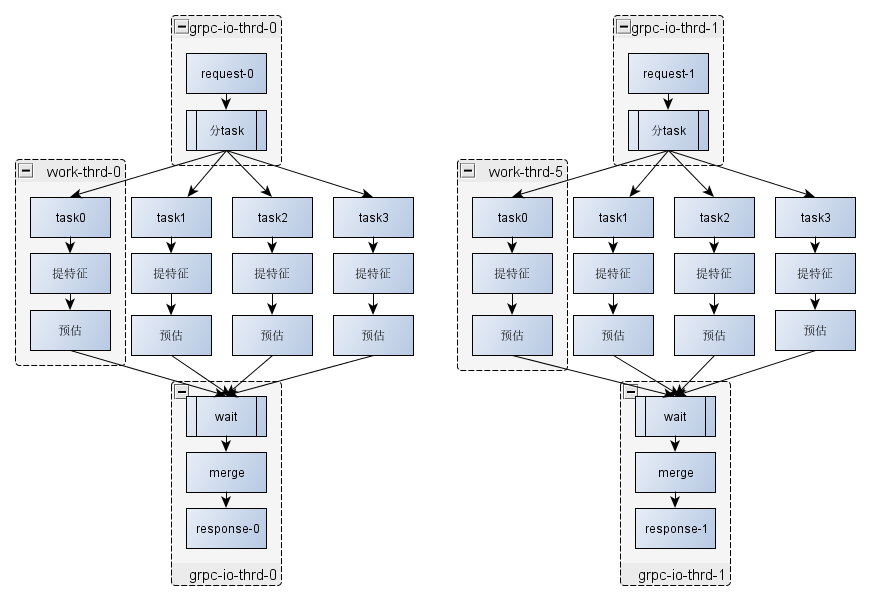
图中示意了两个请求的处理流程,图中提特征包括多个特征conf,每个样本、每个特征配置提取一次。预估也会是多个模型,每个样本、每个conf、每个模型会预估多次。特征提取依赖外部字典,预估依赖外部的模型文件,外部字典的更新、双buf切换都是通过字典管理模块来完成的。下面分别就字典管理模块、分task, 提特征,预估,merge进行详细说明。
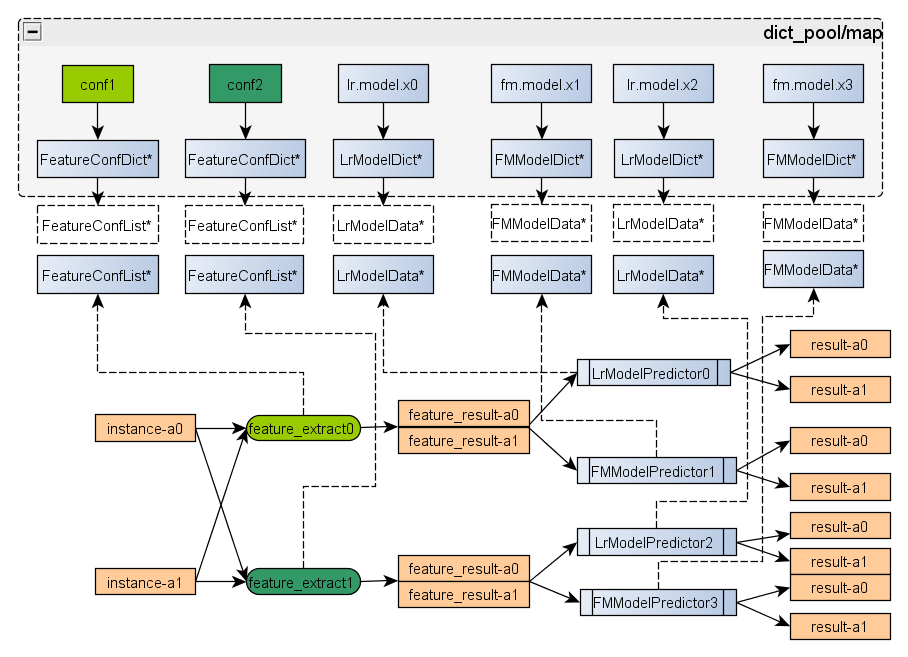
3.3 字典管理模块
如下图所示:conf1, conf2, lr_model_x0等表示磁盘上的文件,每个文件名都是通过不同的字典解析类来解析,这个字典解析类负责管理这个文件的加载,双buf切换。例如:FeatureConfDict负责解析conf1,它内部保存两个FeatureConfList类型的buf,当conf1文件发生更新时,就用备的FeatureConfList* 进行加载,加载完成后,在加载过程中,服务使用主的FeatureConfList*指针。加载完成后,进行主从切换,待没有请求使用老的buf,就释放到老的buf内存。
3.4 分task逻辑
接收到一个请求,这个请求指定了多conf多模型来预估。如下图所示:
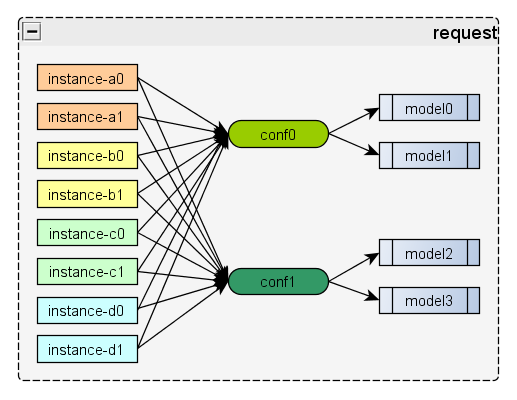
上图表示一共有8条样本,分别用两个conf:conf0, conf1来提取特征,其中conf0的结果由model0,model1来预估,conf1由model2,model3来预估。按照2个样本一个task,拆分完task之后会得到4个task,如下图所示:
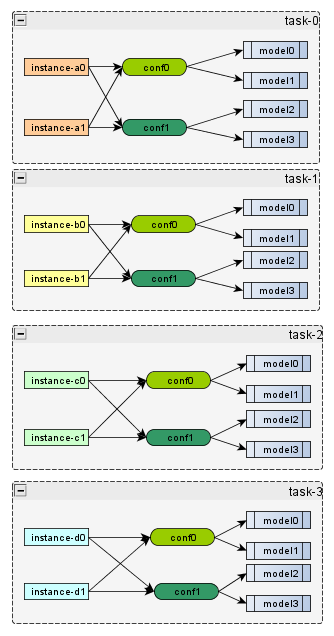
按照样本维度进行拆分成4个task,丢到线程池去执行。
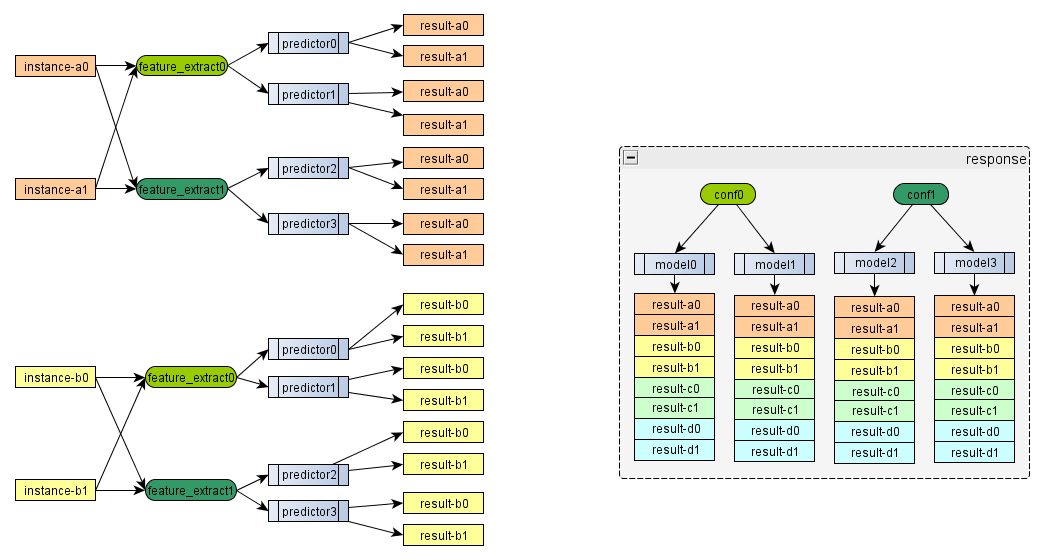
3.5 Merge流程
在预估完成之后,需要按照conf/model这个维度进行组织预估结果给ranker, 最终的response如下图右子图所示。
3.6 特征提取框架的设计
特征提取框架线上、线下都会用到,这样比较好保证线上线下的一致性。所以设计的时候要同时考虑到线上线下的业务场景。
线上是将请求带来的数据与字典数据拼成一条条样本,进行特征提取的。而线下是编译so,通过mapreduce来调用,样本是通过反序列化hdfs的一条条文本得到的。
3.6.1 特征配置文件格式
特征配置文件包括两部分: schema部分,特征算子部分。
3.6.2 schema部分
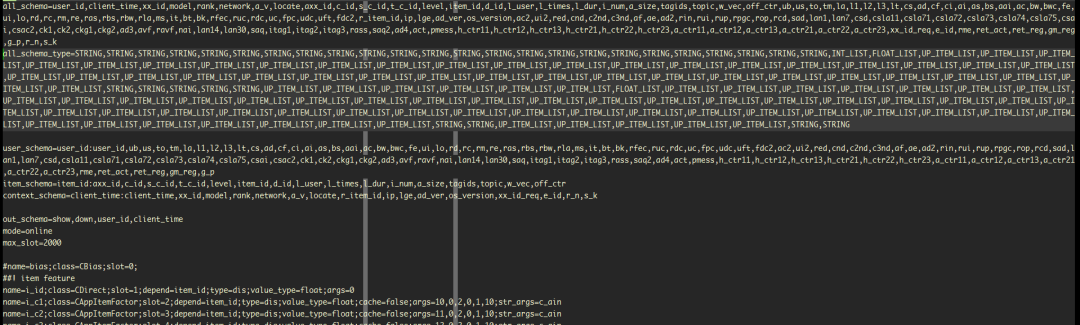
上图中有5个 schema配置
user_schema:表示当前的用户相关信息,只在在线方式使用,由上游请求带过来。
item_schema:表示推荐的item相关信息,只在在线方式使用,一部分由请求带过来,一部分由字典文件中获取。
context_schema:表示推荐的上下文相关信息,只在在线方式使用,由上游戏请求带过来。例如:当前网络状态是wifi还是4G;
all_schema: 表示最终的样本的schema信息。在线模式是将user_schema, item_schema,context_schema的各个字段放在all_schema的对应位置,离线模块是将hdfs的一行行文本,按照all_schema_type指定的类型进行反序列化生成的。不管是在线还是离线,特征框架的样本最终的字段顺序都是按照all_schema顺序存放的
all_schema_type: 离线模式才会用到,指定了各个schema的类型,这些类型名都是事先定义好的,在离线模式下,根据schema类型来反序列化各个字段。
3.6.3 特征算子配置部分
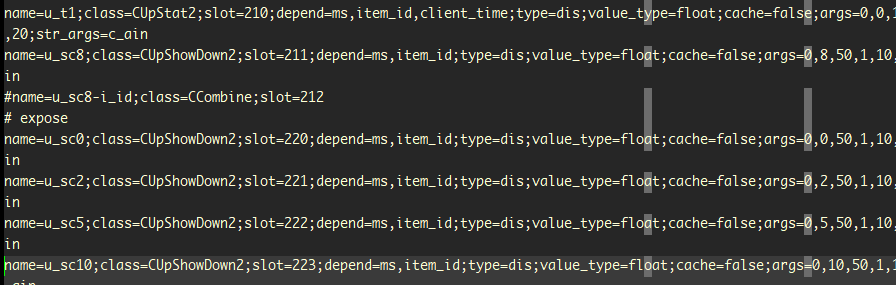
每个特征包括下面这些字段:
Name: 特征名字
Class:表示这个特征用的哪个特征算子类,对应代码里类名
Slot: 唯一标识一个特征
Depend: 表示该特征依赖哪些字段, 这个字段在上述all_schema中必须存在
Args: 表示传给特征算子的参数, 框架会转成float传给算子
Str_args: 传给特征算子的参数,以字符串的形式传递。
3.6.4 特征分group(common和uncommon)
一次预估请求里面,所有样本的用户和context信息是一样的, 考虑到有些特征只依赖用户和context信息,这部分特征只需要提取一次,所有样本共用。
特征配置里面一部分特征会依赖其他的特征(例如组合特征、 cvm特征),所以需要对特征的依赖进行分析,用来判断一个特征最终依赖的字段信息。
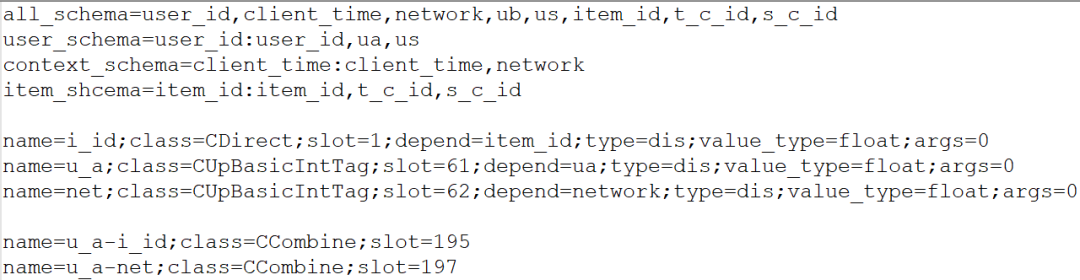
i_id特征依赖item字段的item_id,所以它是uncommon特征
u_a/net特征只依赖user_schema或者context字段, 不依赖item字段,所以它是common特征
u_a-i_id组合特征依赖i_id特征,间隔依赖item_id,所以它是uncommon特征,
u_a-net组合特征只依赖u_a和network字段,所以它是common特征,在特征提取的时候,一次请求只算一次。
注意:这里特征分group是异步字典更新线程来负责计算好的,不是请求来了现算的。
3.7 预估部分
前面提到了,一个请求里面指定了用哪个特征配置文件来提取特征,用哪个模型来预估。所有的模型都是有异步字典更新线程来负责更新。目前支持了LR, FM, DSSM, Deep&Wide等模型的预估,并且比较容易扩展。下面大概介绍下两个根据业务场景做了深度优化的模型:
3.7.1 FM模型预估(LR类似)
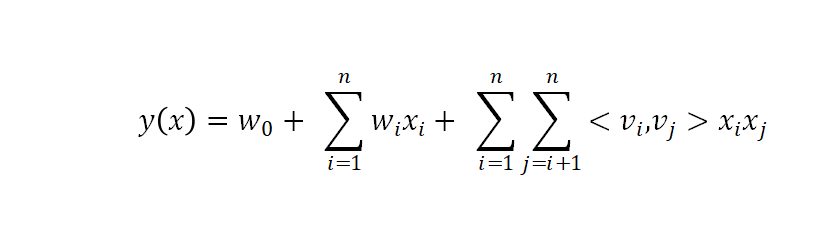
其中
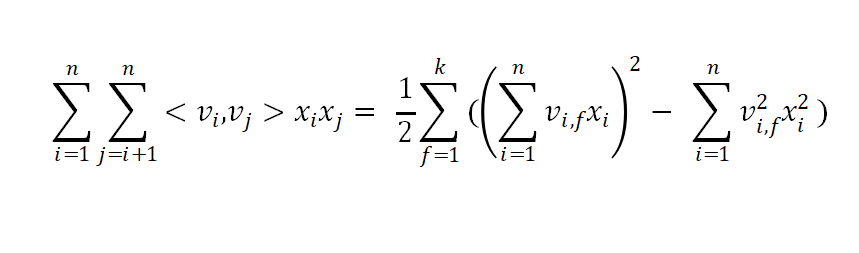
考虑到业务场景,多个样本的user/context信息是一样的,那么线上FM的 预估可�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BB%9F%E4%B8%80%E9%A2%84%E4%BC%B0%E5%BC%95%E6%93%8E%E7%9A%84%E8%AE%BE%E8%AE%A1%E4%B8%8E%E5%AE%9E%E7%8E%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


