细粒度实体分类论文综述二
作者: 龚俊民(昵称: 除夕)
学校: 新南威尔士大学
单位:Vivo AI LAB 算法实习生
方向: 自然语言处理和可解释学习
前言:把分类粒度变细是亚里士多德在《形而上学》中的“给世间万物的存在基于语言来分层和分类”的进一步体现。我们只把世间万物的存在划分成人名,机构,位置,时间这些类别远远不够,就算划分为十几个、几十个、甚至上百个也是不足以映射真实的划分的,但是会更加接近我们的世界知识体系。每多一层的粒度划分,我们实质在做的是让机器能像我们人递归调用自身一样,用语言去解释语言。给定它一个“苹果”,它能找到这个“苹果”的可能歧义,读音,出处,用法和指代对象,甚至各种典故和梗。能解释该实体的一切与之相连,便有了通过将实体连在一起来描述知识的知识图谱。 这一期,我们来聊一聊细粒度实体分类。
Introduction
上一期我们提到了实体命名识别(Name Entity Regcognization)的五个难点(定义难,数量多,有歧义,边界靠词表,数据难标注),并综述了对应的解决方案。但在实际生产中,真正需要的实体类别,粒度往往会更为细致。更细致的粒度意味着同一类型下的实体在语义上呈现出更紧密的距离。这种距离的紧密带来了一个实体对应多种不同标签的问题。上游识别的实体通常要对下游的信息抽取业务(如实体链接、关系抽取)提供支撑。
实体链接本质做的是消歧,解决的是一个实体对应多种类别的情况。而关系抽取做的是找到两个识别出的实体间的谓语关系。实体的细粒度标签能很大程度暗示候选的谓语关系。显然越粗的实体粒度标签下,实体间的候选关系就越容易变复杂,相应的关系抽取任务做起来也会越难。于是实体命名识别因下游业务需要,会自然而然地过渡到另一个与之相近的任务——细粒度实体分类(Fine-Grained Entity Typing)上。
在 FGET 任务中,我们更倾向于使用 mention 去表示实体在上下文中的指代,因为它暗示着多标签实体的消歧步骤。FGET 任务要在实体被提及的情况下,根据上下文来给定 mention 一到多个标签。这些更细粒度的标签与客观世界存在的 Entity 的类别,会呈现出类似归属的关系。比如港台歌手是歌手,歌手是人类,再比如大学是教育机构,教育机构是机构。我们把这些有归属关系的实体类别整理出来,就可以得到一棵类型树。那么问题来了,我们要如何来整理出这棵类型树呢?
难点一:类别体系不统一
这个看似简单的问题,却在过往的研究中被忽略。不同数据集的类别体系还是有不少差异的。

论文标题: OntoNotes: The 90% Solution
论文来源: NAACL 2006
论文链接: https://dl.acm.org/doi/10.5555/1614049.1614064
较早拿来做细粒度实体分类的经典数据集应该是 OntoNotes 了。这个在 LDC 中的收费数据,经过一系列的申请过程后下载下来还需要推荐这个 Repro 做格式转换:
https://github.com/yhcc/OntoNotes-5.0-NER
它是一个多语种,承载了词性标注、共指解析和实体命名识别等多任务的数据集。它的命名实体部分的标注参照了《ACE 英文实体标注标准》[15] 和《ACE 中文实体标注标准》[16]。
在中文标准中,实体类型被划分成了 7 个大类别,往下再细分出了 45 个二级子类,以及往下更细的近一百来个三级子类。然而,即便存在一个这么详细的标注标准,细粒度实体类别体系这一块依然没有达成一致的统一。
许多研究者侧重都在算法优化层面而忽略了这个类别体系的构建过程。当类别划分不清楚时,会很难指导标注人员去标注数据。查阅不少文献,存在研究者们各用各的数据集的情况。不同语料下,类别分布会不一样。有些语料中,某些实体类别的样本数几乎为零,所以研究者会对其再整理。这就失去了 Benchmark 的参照意义。而且在完善的中文领域细粒度实体识别的开源数据集几乎找不到。
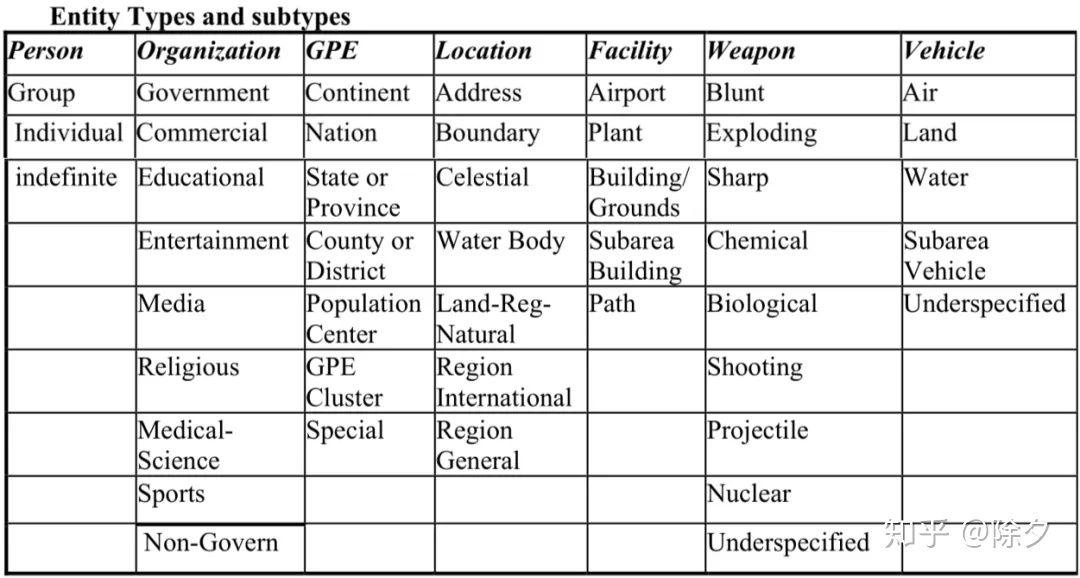 ACE 2005 中文实体标注标准一级、二级类别一览
ACE 2005 中文实体标注标准一级、二级类别一览
 **论文标题:**Fine-Grained Entity Recognition
**论文标题:**Fine-Grained Entity Recognition
论文来源: AAAI 2012
论文链接: http://xiaoling.github.io/pubs/ling-aaai12.pdf
代码链接: https://github.com/xiaoling/figer
细粒度实体识别的数据集 FIGER 将原本实体命名识别的 5-6 个类别,拓展到了 112 个标签,并将之定为多分类、多标签任务。
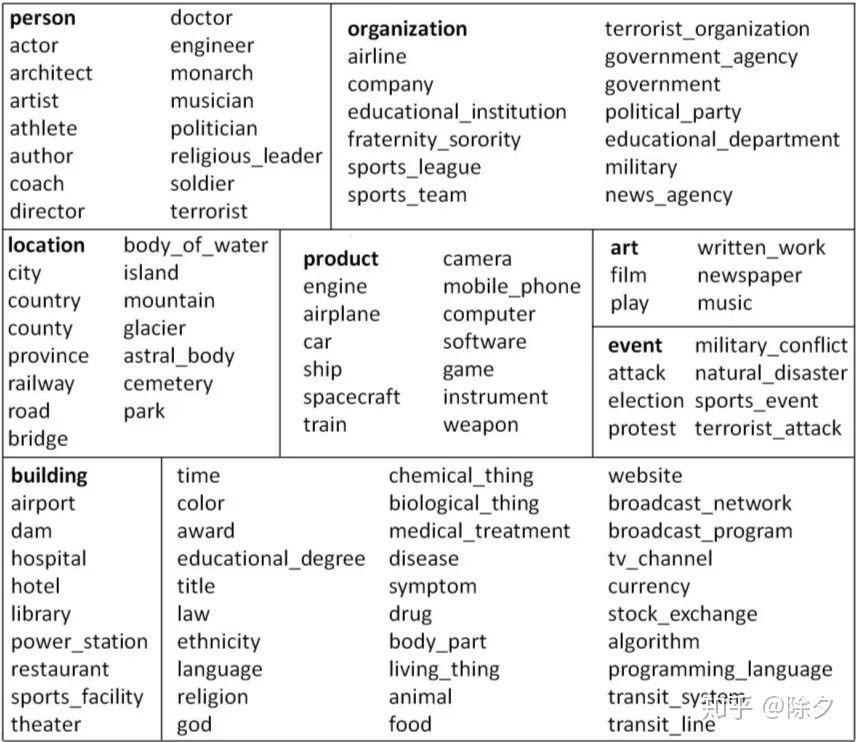 FIGER 112 个类别一览在整理标签过程中, 论文提到了三个挑战:
FIGER 112 个类别一览在整理标签过程中, 论文提到了三个挑战:
- 要如何获得这 112 个标签?
- 要如何用这些标签构建一个标注数据集?若用传统人工标注,工作量巨大。
- 要如何开发出一套准确而快速的细粒度实体识别的算法?
相应的解决方案是:
- 从已有 23425 多种类别的 Freebase types 数据集中,通过把实体较少的类别合并的方式,筛选出来。
- 利用维基百科的词条文本来获得分割好的实体类型
- 用 CRF 做实体的边界分割,用感知机算法做实体的多分类多标签任务。
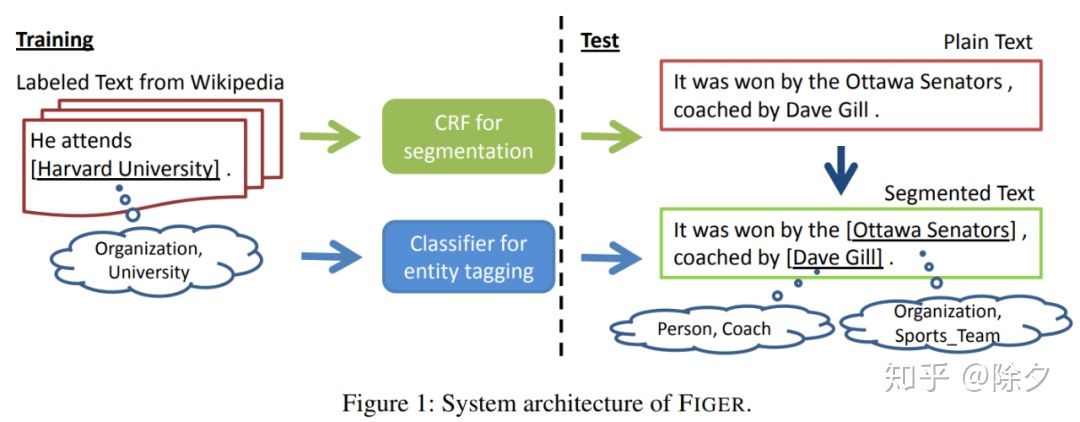 FIGER 数据集的构建流程
FIGER 数据集的构建流程
后人发现 FIGER 这个数据集存在几个版本类型树,会对结果产生巨大影响。而且 FIGER 这个数据集训练集巨大,但测试集只有 500 个样本,这会增大测试结果的随机性,因为不是所有的实体类型都在测试集中出现过。因此后人在使用它时,通常都会自己进行再整理和划分。

论文标题: Context-Dependent Fine-Grained Entity Type Tagging
发布时间: 2014
论文链接: https://arxiv.org/abs/1412.1820
这篇论文参照了 FIGER 的做法,也是从 Freebase types 数据集中筛选出类别。但不同在,这些类别被重新组织成了更明确的层级关系。
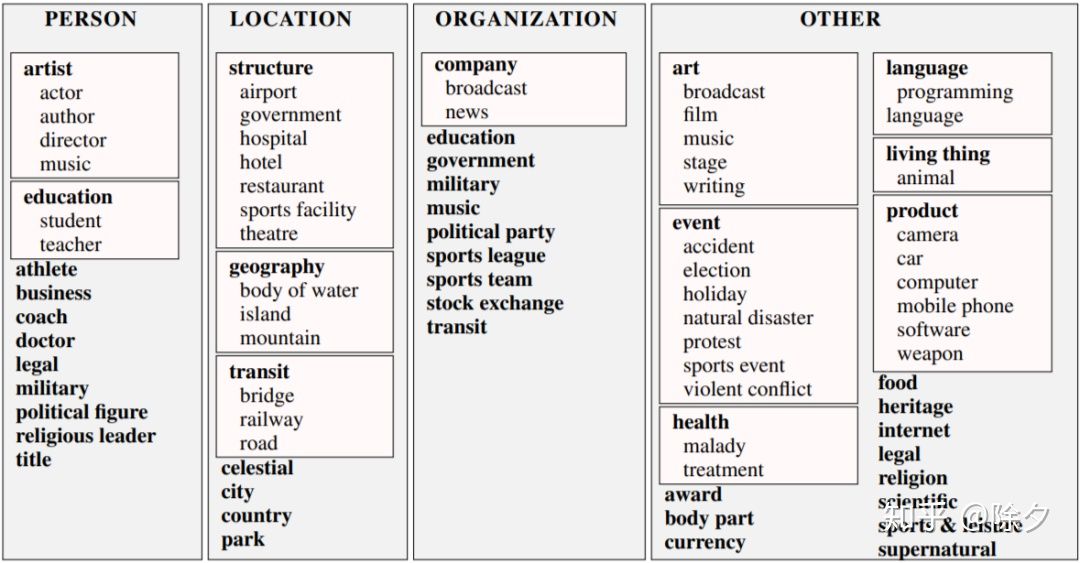 ▲ OntoNotes 数据集的类别体系
▲ OntoNotes 数据集的类别体系

论文标题: Finer Grained Entity Typing with TypeNet
发布时间: NIPS 2017
论文链接: https://arxiv.org/abs/1711.05795
代码链接: https://github.com/iesl/TypeNet
TypeNet 是一个自建的数据集。它从 freebase 中筛选出了 1081 个实体类型,和 860 个 WordNet 类型,进行重组对齐后,平均层级有 7-8 层。
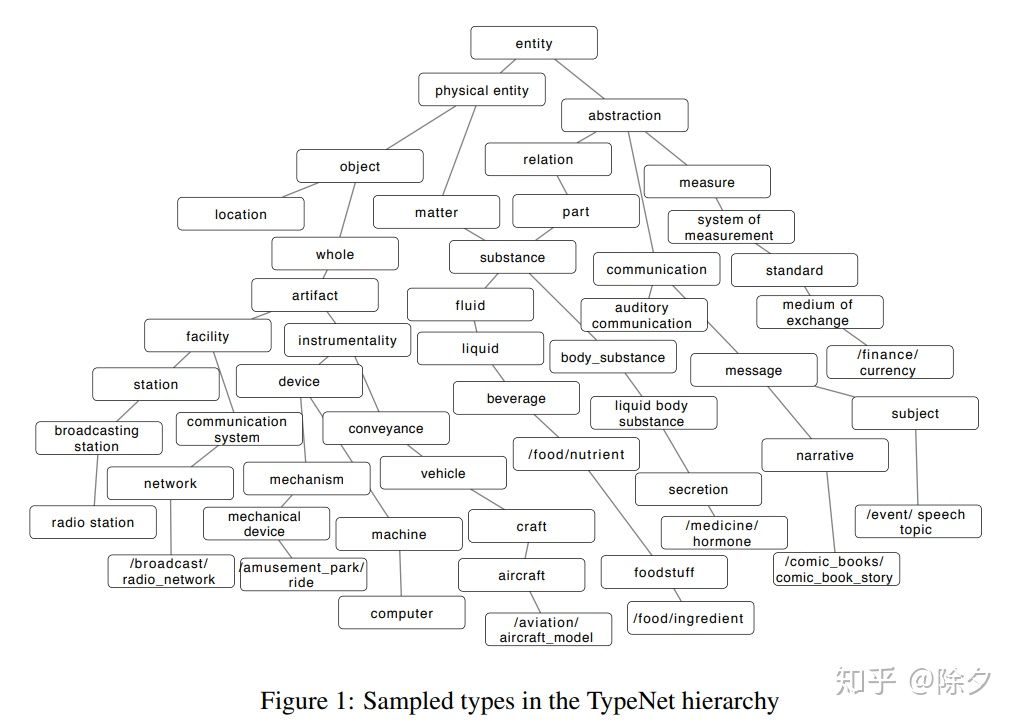 TypeNet 数据集的层级类别体系一览
TypeNet 数据集的层级类别体系一览

论文标题: Ultra-Fine Entity Typing
发布时间: ACL 2018
论文链接: https://arxiv.org/abs/1807.04905
代码链接: https://github.com/uwnlp/open_type
UFET 构建了一个类别有一万多个的新数据集。它的任务是对给定 mention 进行多标签分类。
 数据集中标注的例子,蓝字为三级超细粒度
数据集中标注的例子,蓝字为三级超细粒度
该数据集有 9 个一级类别,121 个二级细粒度类别,以及10201个多标签的超细粒度类别。其中二级类别整合了 OntoNotes 和 FIGER 数据集的划分,三级类别则通过众包的方式去标注。
对于一个 mention 到的实体,研究者会用 WordNet 去拓展它的类别,比如使用同义词或基于 Common Sence 的释义词来作为候选类别。这样细粒度类别的获取就更接近我们人用语言解释语言的递归过程。而类别的层级从上往下是从抽象到具体的,体现出我们人思维的演绎归纳过程。
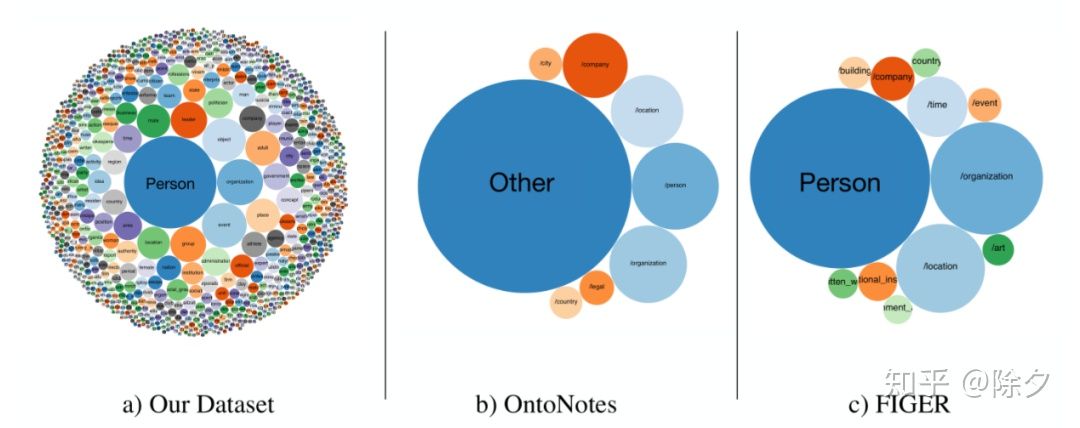 UFET 数据集与其他数据集的类别体系对比。图中球形越大代表属于这个类别的样本在语料中出现频次越高。在 OntoNotes 中,一级标签 Other 占据了很大比重。这种划分实体的类别语义并不能很好地归纳类别内的实体语义,在实际生产中也很难去用。而 UFET 的超细粒度标签更接近实体的语义属性。这些属性可以支持下游任务更灵活的搜索和匹配。比较以上 ACE,FIGER,OntoNotes,TypeNet 和 UFET 可以看出,实体类别无论是在类型数目,层级划分上都未得到一致的统一。大都是研究者一拍脑袋理所当然的去划分了。每一种划分的方式都符合我们的世界知识体系一部分。但任意一种都或多或少都存在覆盖不全的问题。
UFET 数据集与其他数据集的类别体系对比。图中球形越大代表属于这个类别的样本在语料中出现频次越高。在 OntoNotes 中,一级标签 Other 占据了很大比重。这种划分实体的类别语义并不能很好地归纳类别内的实体语义,在实际生产中也很难去用。而 UFET 的超细粒度标签更接近实体的语义属性。这些属性可以支持下游任务更灵活的搜索和匹配。比较以上 ACE,FIGER,OntoNotes,TypeNet 和 UFET 可以看出,实体类别无论是在类型数目,层级划分上都未得到一致的统一。大都是研究者一拍脑袋理所当然的去划分了。每一种划分的方式都符合我们的世界知识体系一部分。但任意一种都或多或少都存在覆盖不全的问题。
当然在业务中我们也无需用到全部的实体类型。如果下游任务是推荐,用到较多的是地址、影视名,商品名,公司名,和人名等。其中很多类别都用不到。所以经济化考虑,不覆盖全是一种在时间精力上妥协。但不统一带来的问题是,现有模型需要重新在新的数据集上训练才能拿来用。而如果我们有一个较为完备的类别体系和能在该体系上表现较好的实体识别系统,下游任务就只需要挑出需要的类别进行合并就好,可以省去不少精力。而且更全的体系在很多方面都很有用。仅仅从更好的文本表征上去看,更细粒度的实体类型划分能更好地体现出世界知识。
难点二:远程监督有噪音
当类别体系越完善,下游类别会非常多,这会给人工标注数据带来大问题。训练的语料不易构建,标注难度高不说,还有很多重叠和歧义。即便制定了标注标准,当类别从几十变成上万不等时,人工标注几乎变得不可行。而由于类别数量巨大,模型训练又需要更多的数据。
所以细粒度 NER 系统通常会用划分实体边界的算法,如 CRF 来切出候选实体 mention,再对这个 mention 进行实体链接找到该实体对应的所有类型作为标注结果。候选实体类型来自于知识图谱这类的知识库。但这种方法有两个缺陷:
- 可以通过扩充知识库来提升召回。但知识库可能不完备。比如说电视剧,近一年的新剧知识图谱可能就未收录。
- 可以通过基于 head word 的距离监督来提供上下文信息,提升精度。比如“院士袁荣平”中的“院士”,“李文亮医生”中的“医生”。但上下文信息会经常缺失。
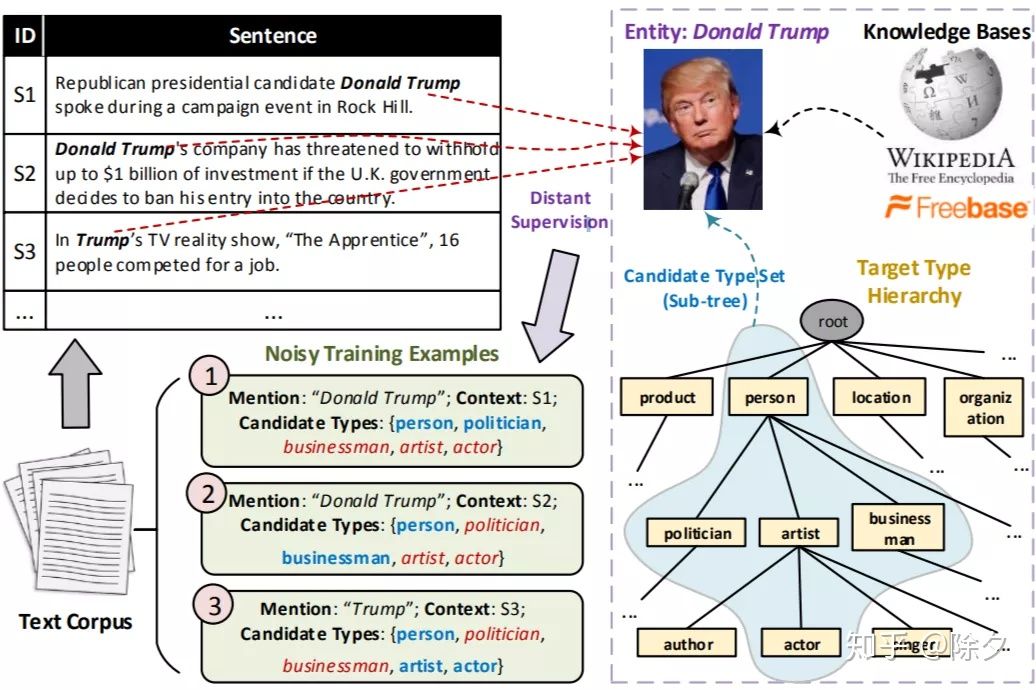 从知识库中得到的实体标签只有部分是符合上下文的
从知识库中得到的实体标签只有部分是符合上下文的

论文标题: Label Noise Reduction in Entity Typing by Heterogeneous Partial-Label Embedding
发布时间: SIGKDD 2016
论文链接: https://arxiv.org/abs/1602.05307
代码链接: https://github.com/INK-USC/PLE
远程监督算法会带来大量噪音标签。任翔等人对该问题进行了细致分析,发现噪音标签对最终细粒度实体分类模型的性能影响很大。前人通常的做法是基于启发的把有冲突的类型的 mention 给删掉。但这样会显著减少训练集样本量导致整体表现变差。当类型数量越多,这种删除 mention 的方法就会表现越糟。
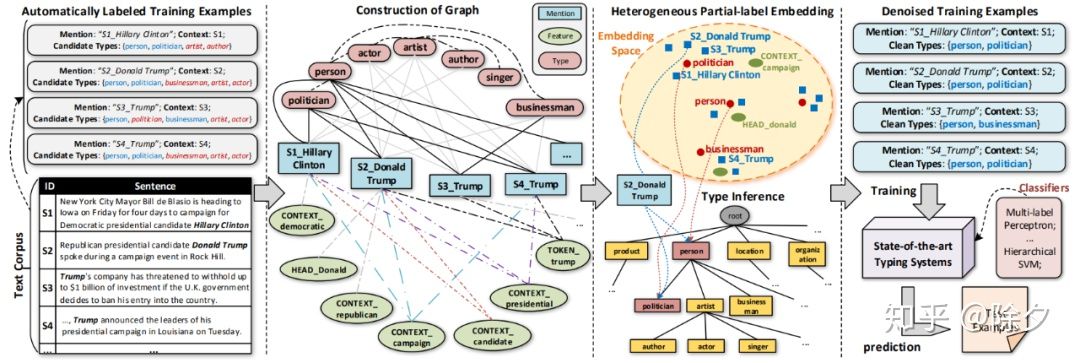 整个算法的框架作者则提出需要一种去噪算法 LNR 来减少噪音标签的影响。实体分类模型会假设所有的标签都是正确的,并用在这些带噪音数据中得到的模型去预测未标注的 mention。LNR 则侧重于从自动得到的标注的 mention 中识别出正确的标注类型,可以看作是部分标签学习。
整个算法的框架作者则提出需要一种去噪算法 LNR 来减少噪音标签的影响。实体分类模型会假设所有的标签都是正确的,并用在这些带噪音数据中得到的模型去预测未标注的 mention。LNR 则侧重于从自动得到的标注的 mention 中识别出正确的标注类型,可以看作是部分标签学习。
什么是部分标签学习呢?我们会先让模型去对每个样本的类型预测一个概率分布,再根据这个分布和候选类型去选出正确的类型。下一步模型会用和来作为监督拟合得到下一轮的模型。如此反复迭代。这种实验方法显著有效。
为实践 LNR 算法,一种基于语义嵌入的框架 PLE 来衡量实体类别和 mention 之间的语义相似度,从而筛选出语义更相近的实体类别。结果达到了当年的 SOTA 水平。
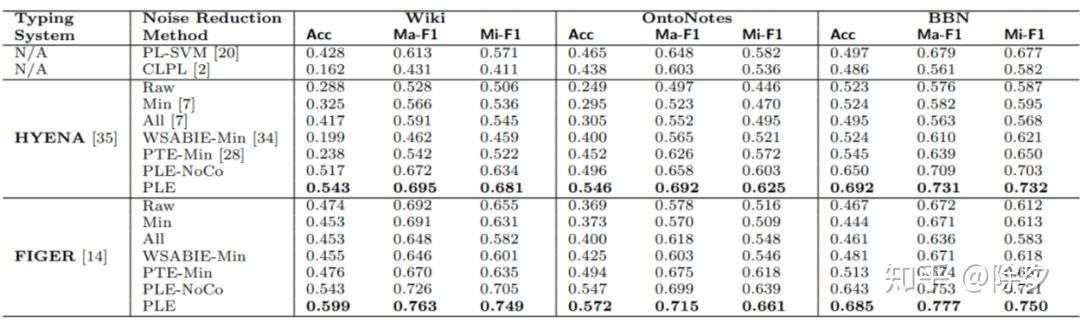 当用去噪算法筛选出正确标签去训练模型后,表现显著提升
当用去噪算法筛选出正确标签去训练模型后,表现显著提升

论文标题: Put It Back: Entity Typing with Language Model Enhancement
发布时间: ACL 2018
论文链接: https://www.aclweb.org/anthology/D18-1121
代码链接: https://github.com/thunlp/LME
考虑到实体和标签类型其实都是文本,二者之间存在语义相关性。比如人名相关的上下文,可能有“出生于”、“就职于”,“饰演”等提示词。这篇论文的思路是用语言模型去找出这种关联来降噪。
 mention 的上下文中会有限定其候选类型的关键词
mention 的上下文中会有限定其候选类型的关键词
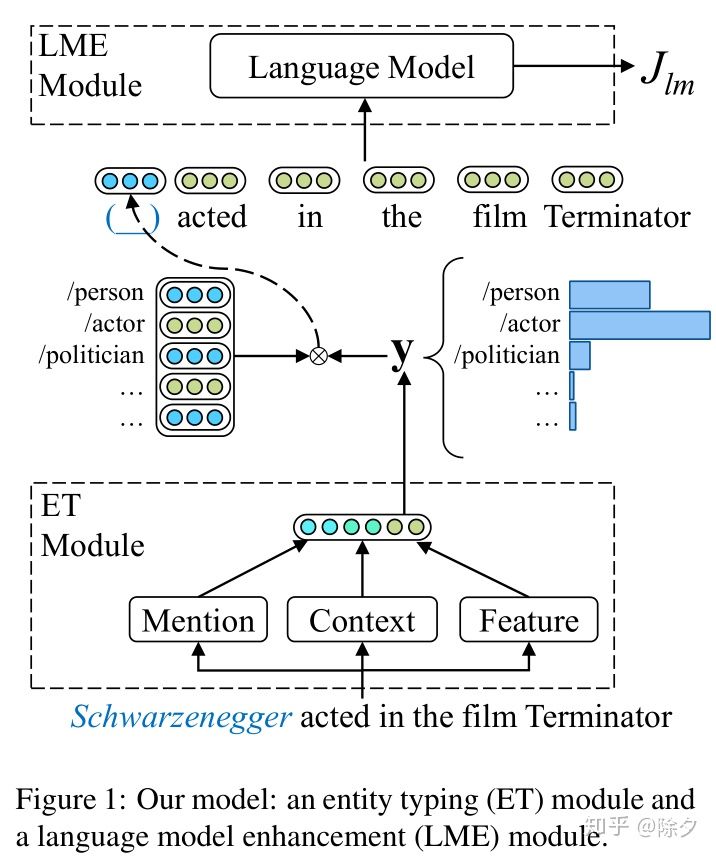 模型架构一览put it back 的模型分成了两个部分:
模型架构一览put it back 的模型分成了两个部分:
- Entity Typing (ET) 实体分类
- Language Model Enhancement (LME) 语言模型增强
模型的输入包括了三个部分:
- Mention vector (
 ) 为实体中多个词的词向量平均,比如天安门广场由两个名词“天安门”和“广场”构成,它的嵌入为这两个词的词向量平均。
) 为实体中多个词的词向量平均,比如天安门广场由两个名词“天安门”和“广场”构成,它的嵌入为这两个词的词向量平均。 - Context Vector (
 ) 为实体的上下文,由 BiLSTM + attention 建模得到。
) 为实体的上下文,由 BiLSTM + attention 建模得到。 - Hand-crafted feature vector (
 ) 为下图特征通过一个线性映射后得到的。
) 为下图特征通过一个线性映射后得到的。
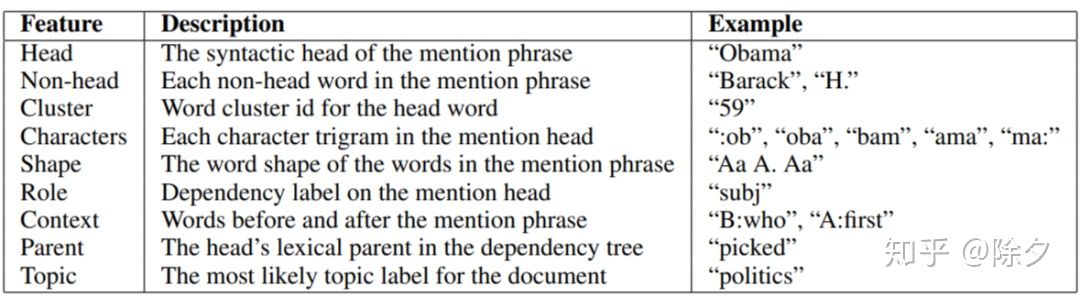 前人们做细粒度实体命名识别的通用特征这三个输入会先拼接起来变成一个向量,通过一个线性层映射到同一空间,作为 ET 模块的输入,输出得到 mention 为每个类别的分布。这个分布会与类型的嵌入做一个加权求和得到该位置的 mention 嵌入。这个嵌入会送入一个语言模型去优化。其整体损失为:
前人们做细粒度实体命名识别的通用特征这三个输入会先拼接起来变成一个向量,通过一个线性层映射到同一空间,作为 ET 模块的输入,输出得到 mention 为每个类别的分布。这个分布会与类型的嵌入做一个加权求和得到该位置的 mention 嵌入。这个嵌入会送入一个语言模型去优化。其整体损失为:
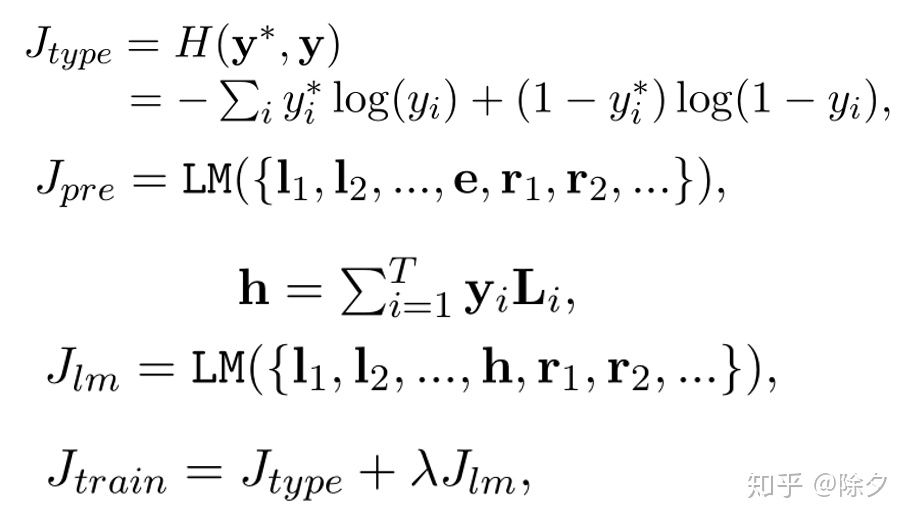
其中,语言模型的参数是预训练好的,在任务训练过程中不参与参数更新。矩阵 L 是所有标签的嵌入拼接而成的。它被初始化为类型名的词向量。如果预训练好的语言模型不认同某个候选标签,为了使得语言模型的损失下降,这个标签对应的概率也会下降。这样语言模型的损失就约束了前面部分的损失。
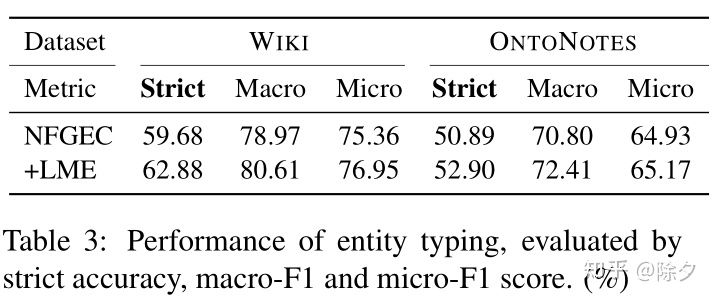 实验结果表明语言模型增强能将 F1 Score 提升1-2个点
实验结果表明语言模型增强能将 F1 Score 提升1-2个点
 **论文标题:**Improving Distantly-supervised Entity Typing with Compact Latent Space Clustering
**论文标题:**Improving Distantly-supervised Entity Typing with Compact Latent Space Clustering
发布时间: NAACL-HLT 2019
论文链接: https://arxiv.org/abs/1904.06475
代码链接: https://github.com/herbertchen1/NFETC-CLSC
论文的思路是用一种压缩隐空间簇的方法来绕开可能的标注噪音。其核心思想是利用无标签数据来约束特征抽取器的参数,使得其形成类内距离近,类间距离远的类簇,来帮助分类。
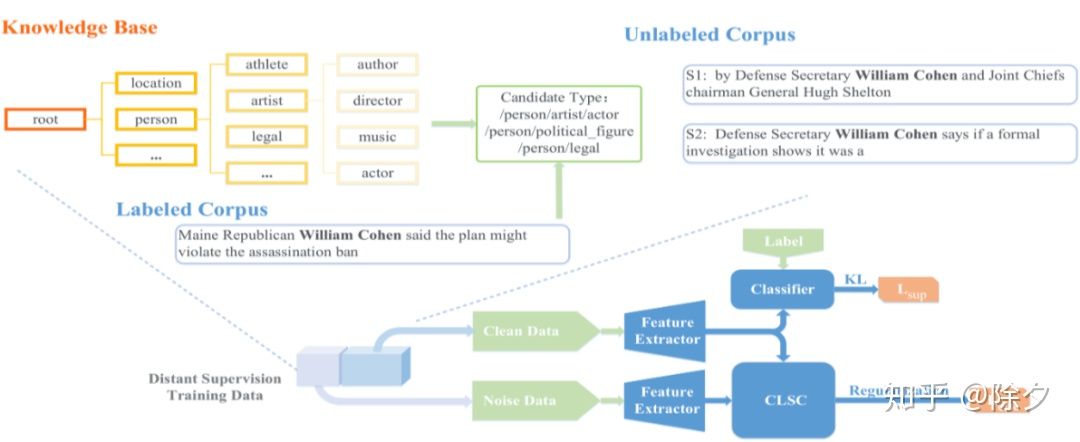 CLSC 的框架一览与部分标签学习不同,CLSC 追求模型在特征空间上的自洽。这种自洽的实现方式包括了以下几个步骤:
CLSC 的框架一览与部分标签学习不同,CLSC 追求模型在特征空间上的自洽。这种自洽的实现方式包括了以下几个步骤:
第一步,模型预测
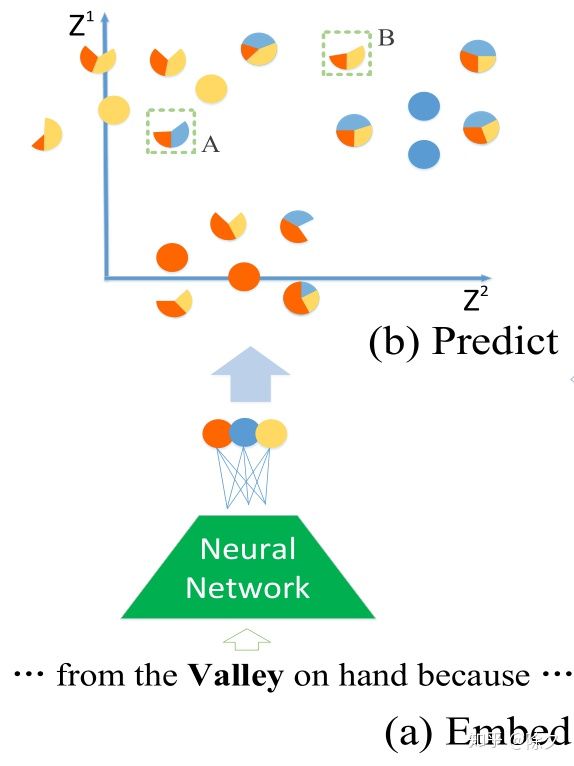
▲ 将 mention 和其上下文输入给模型后会得到每个类别的得分
第二步,构建图
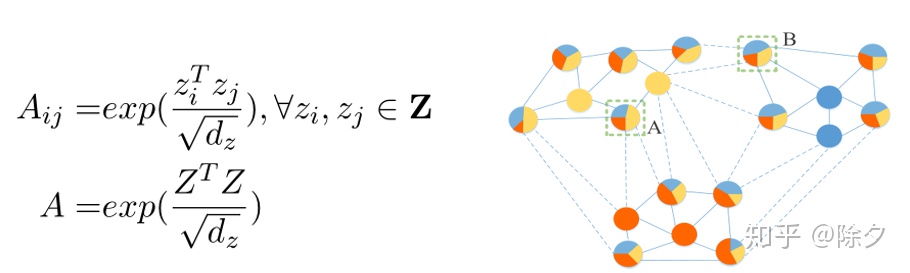 ▲ 将一个 batch 预测的得分与自身做点积,就能得到值为每个类别的两两相似性矩阵 A。这个矩阵可以看作是以类型为节点,以其相似性为权重边构建的邻接矩阵图
▲ 将一个 batch 预测的得分与自身做点积,就能得到值为每个类别的两两相似性矩阵 A。这个矩阵可以看作是以类型为节点,以其相似性为权重边构建的邻接矩阵图
第三步,标签传播
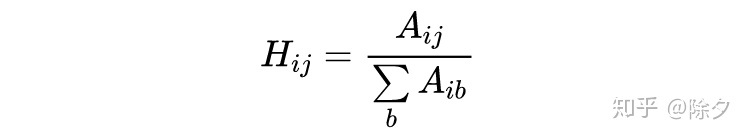
将矩阵
 做类似 softmax 的归一化就得到了标签传播矩阵
做类似 softmax 的归一化就得到了标签传播矩阵
 。
。
 越大则说明从标签
越大则说明从标签
 越可能传播到标签
越可能传播到标签
 。基于远程监督算法,每个 mention 都会得到一些候选类型标签来提供监督信息。我们假设无论是只有一条类型路径的纯净数据,还是有多条路径的噪音数据,某个 mention-type pair
。基于远程监督算法,每个 mention 都会得到一些候选类型标签来提供监督信息。我们假设无论是只有一条类型路径的纯净数据,还是有多条路径的噪音数据,某个 mention-type pair
 只在模型预测的类型
只在模型预测的类型
 上转移。我们随机初始化一个形状为
上转移。我们随机初始化一个形状为
 的矩阵
的矩阵
 ,表示每一行样本的标签分布。然后用这个
,表示每一行样本的标签分布。然后用这个
 与
与
 相乘,就得到一次标签传播的过程。利用远程监督得到的候选标签集 M,我们让非候选标签的概率都为 0。
相乘,就得到一次标签传播的过程。利用远程监督得到的候选标签集 M,我们让非候选标签的概率都为 0。
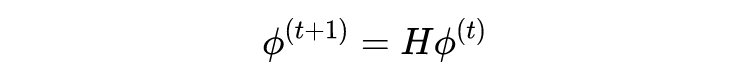
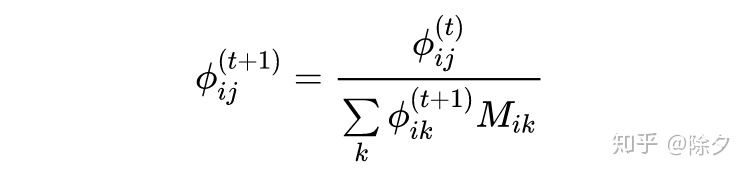
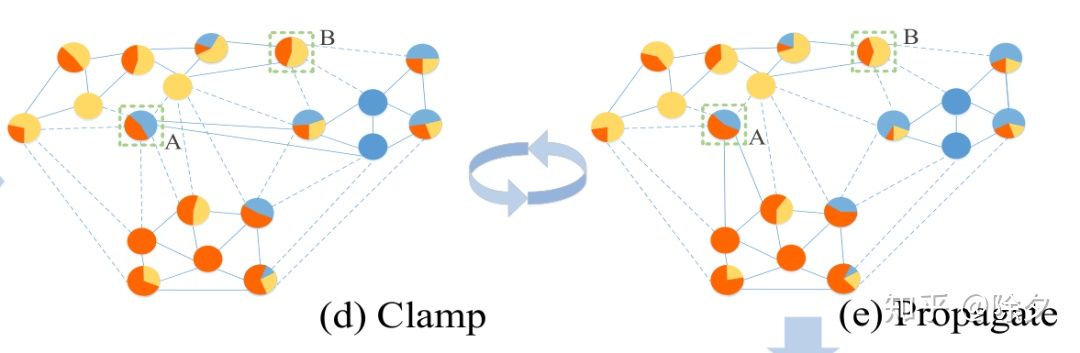
▲ 再根据如上两个公式,用图示的方式进行迭代更新直至收敛
第四步,压缩隐空间簇
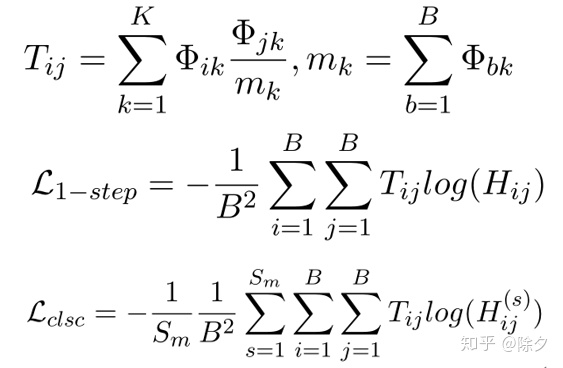 模型拟合的不是标签传播后的分布,而是一个正则项损失。我们希望标签近似的样本距离越接近。标签相似度
模型拟合的不是标签传播后的分布,而是一个正则项损失。我们希望标签近似的样本距离越接近。标签相似度
 是计算得来的,用来约束矩阵
是计算得来的,用来约束矩阵
 的距离。便得到了正则化部分的损失。
的距离。便得到了正则化部分的损失。
这个
 可以看作是样本间可以多重转移的马尔科夫链的特例。把每个样本的
可以看作是样本间可以多重转移的马尔科夫链的特例。把每个样本的
 相加取平均便是这个 batch examples 的 CLSC 正则损失。
相加取平均便是这个 batch examples 的 CLSC 正则损失。
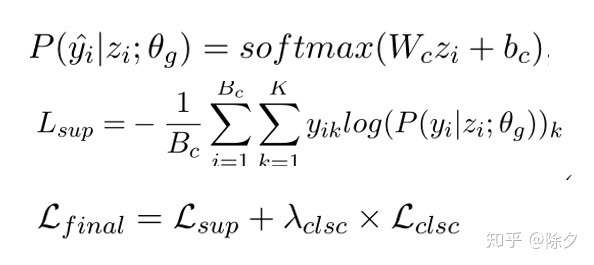
对于单类型路径的标签,我们无需考虑噪音问题,则直接用 KL 散度算损失。
 为调节 CLSC 影响程度的正则项超参数。
为调节 CLSC 影响程度的正则项超参数。
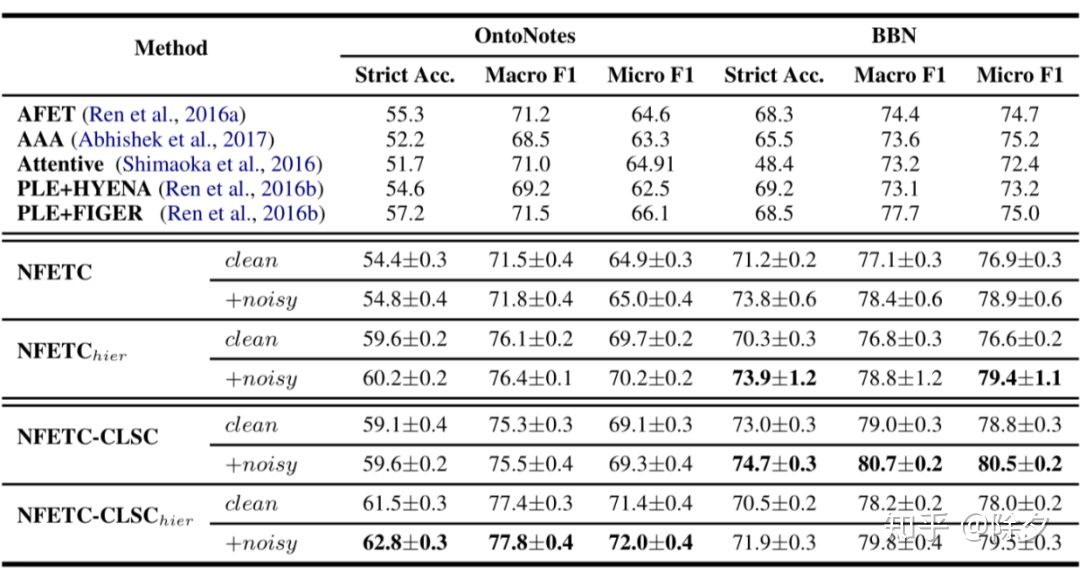 ▲ 结果表明,CLSC 在 OntoNotes 数据集和 BBN 数据集上都显著好于过去的 SOTA 模型。而且该方法在只有很少的单类型路径的干净数据上也有很好的鲁棒性
▲ 结果表明,CLSC 在 OntoNotes 数据集和 BBN 数据集上都显著好于过去的 SOTA 模型。而且该方法在只有很少的单类型路径的干净数据上也有很好的鲁棒性
难点三:实体标签不独立
大部分实体分类器都是把实体的类别默认为互相独立的去分类,而忽略了实体类别间存在层级、语义相关的关系,且每个实体类别的重要性是不对等的。比如演员与歌手的语义距离会比演员与政客的语义更近。这种相关性的忽略会导致分类器在样本量较多的实体类型上表现好,而在样本量较少的实体类型上表现差。直觉上看,训练时某个实体被分类的标签与正确标签的语义较近,计算的损失应该比与正确标签语义较远的小。比如一个演员被误分类为歌手的损失要显著小于它被误分类为政客的损失。这种区分能够帮助模型更好地去减少更离谱的错误。

论文标题: AFET: Automatic Fine-Grained Entity Typing by Hierarchical Partial-Label Embedding
发布时间: EMNLP 2016
论文链接: https://www.aclweb.org/anthology/D16-1144
代码链接: https://github.com/INK-USC/AFET
对于实体类别相关问题,论文的做法是把样本表示和类型表示映射到同一个空间,这样就能通过计算样本和类型语义的相似度来进行分类。对于某个预定义好的实体类型,我们不能直接用其类型词的词向量去计算语义距离,因为比如 other 标签就很难反映与其他类型的差异。相对可靠的是寻找类型类别对应的典型实体。
用这些典型实体的词向量取平均作为类型嵌入,效果会不错。另一种是可以通过类型共现去算 SVD,来建模类型之间的相对距离。这个降维得到的距离矩阵去约束样本的表示,希望样本表示能够重构出这个类型表示,用一个回归损失来构建约束。
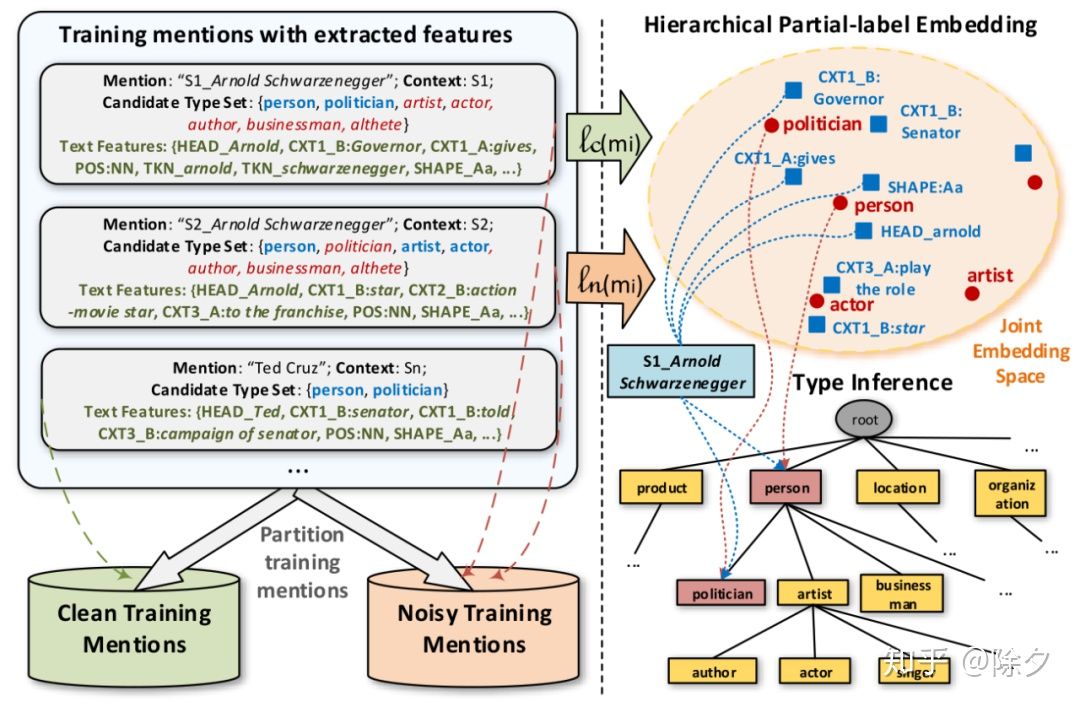 AFET 的流程架构AFET 会先去学习文本和类型的低层表征,然后用这些学到的嵌入去推断 mention 的类型路径。它大体包含了四个步骤: 第一步,提取文本特征
AFET 的流程架构AFET 会先去学习文本和类型的低层表征,然后用这些学到的嵌入去推断 mention 的类型路径。它大体包含了四个步骤: 第一步,提取文本特征
 AFET 用到的文本特征,其中 head word 可通过句法解析获取
AFET 用到的文本特征,其中 head word 可通过句法解析获取
第二步,把训练数据集中的 mention 分成
- clean set 指 mention 的标签只有一条类型路径
- noise set 指 mention 的标签存在多条类型路径
第三步,将文本表征和类型表征映射到同一个空间
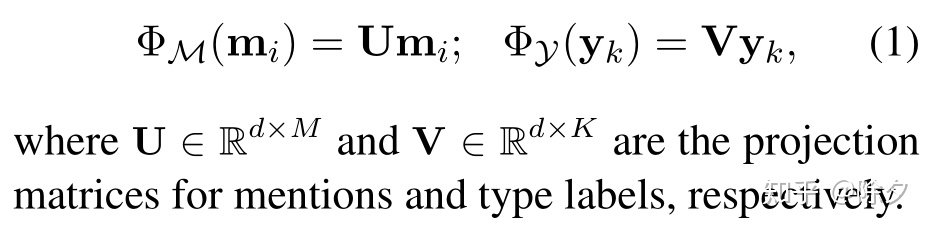 其中,
其中,
 为第一步中 mention 的文本表征,
为第一步中 mention 的文本表征,
 为候选类型的表征,可以用之前的类型共现算 SVD 的方法去计算。对两个表征做线性映射,确保维度一致,就可以到同一空间了。
为候选类型的表征,可以用之前的类型共现算 SVD 的方法去计算。对两个表征做线性映射,确保维度一致,就可以到同一空间了。
第四步,为类型相关性建模
类别相关的信号可以从两个方面获得:
- 类型的层级结构
- 看知识库中有哪些同一个实体有多种标注的重叠类型
两个类别
 和
和
 的相关性记为
的相关性记为
 ,其计算方式为:
,其计算方式为:
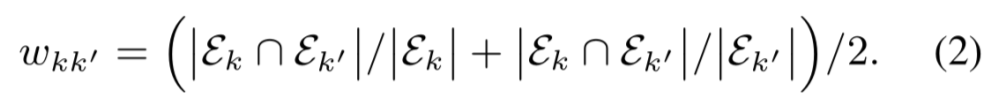 ▲ 类别相关性的计算公式
▲ 类别相关性的计算公式
其中,
 为 类别 k 占的所有实体集合。这个公式描述出两个实体类别共有的实体越多就越相似。
为 类别 k 占的所有实体集合。这个公式描述出两个实体类别共有的实体越多就越相似。
 时,相关性最大为 1 。对于 clean set 中的样本
时,相关性最大为 1 。对于 clean set 中的样本
 ,我们假设其表示应该和候选标签
,我们假设其表示应该和候选标签
 之间的距离非常近,与非候选标签之间非常远。我们拿这两个之间的距离作为损失便是 max margin loss。这个边际是任意类别两两之间的,是一个 KxK 的矩阵,损失的计算公式如下:
之间的距离非常近,与非候选标签之间非常远。我们拿这两个之间的距离作为损失便是 max margin loss。这个边际是任意类别两两之间的,是一个 KxK 的矩阵,损失的计算公式如下:
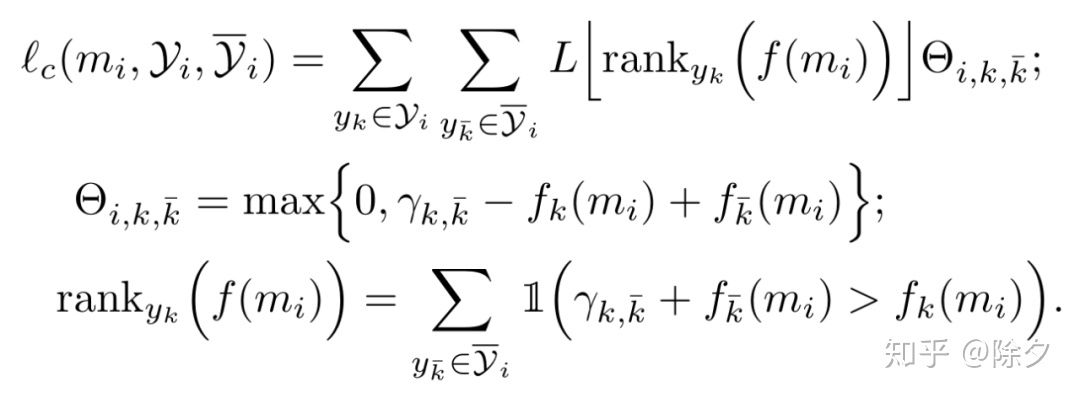 其中,
其中,
 用将嵌入点积的方式来计算样本与标签类型在语义上的相似度。
用将嵌入点积的方式来计算样本与标签类型在语义上的相似度。
 是一个正类和负类之间的适应性间距,
是一个正类和负类之间的适应性间距,
 是用来调节平滑度的参数。当类型在类型树上越接近,适应性间距就相对小,我们对这种错误就越包容。函数
是用来调节平滑度的参数。当类型在类型树上越接近,适应性间距就相对小,我们对这种错误就越包容。函数
 会把排序转换为一个权重。
会把排序转换为一个权重。
对于候选标签
 ,有越多非候选标签与样本表示相似度排在它的前面,这个损失惩罚就会越大。它类似于 softmax 的效果。梯度正向取决于,目标类型表示与样本表示接近,负向部分取决于样本表示和非目标类型表示的距离。这个权重再乘上这个 Max-margin loss
,有越多非候选标签与样本表示相似度排在它的前面,这个损失惩罚就会越大。它类似于 softmax 的效果。梯度正向取决于,目标类型表示与样本表示接近,负向部分取决于样本表示和非目标类型表示的距离。这个权重再乘上这个 Max-margin loss
 作为最终的损失。
作为最终的损失。
对于noise set 中的样本,我们假设其候选的类别得分应该大于非候选类别的得分。
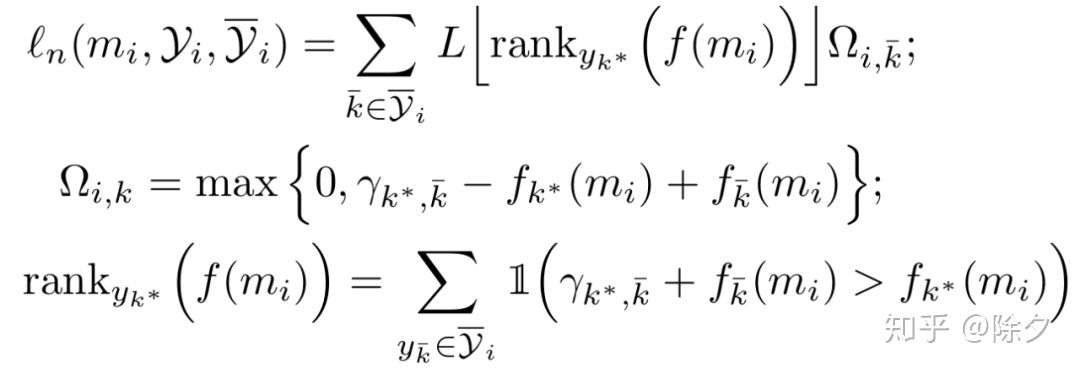
▲ 模型最终要最小化这两个损失的加权和
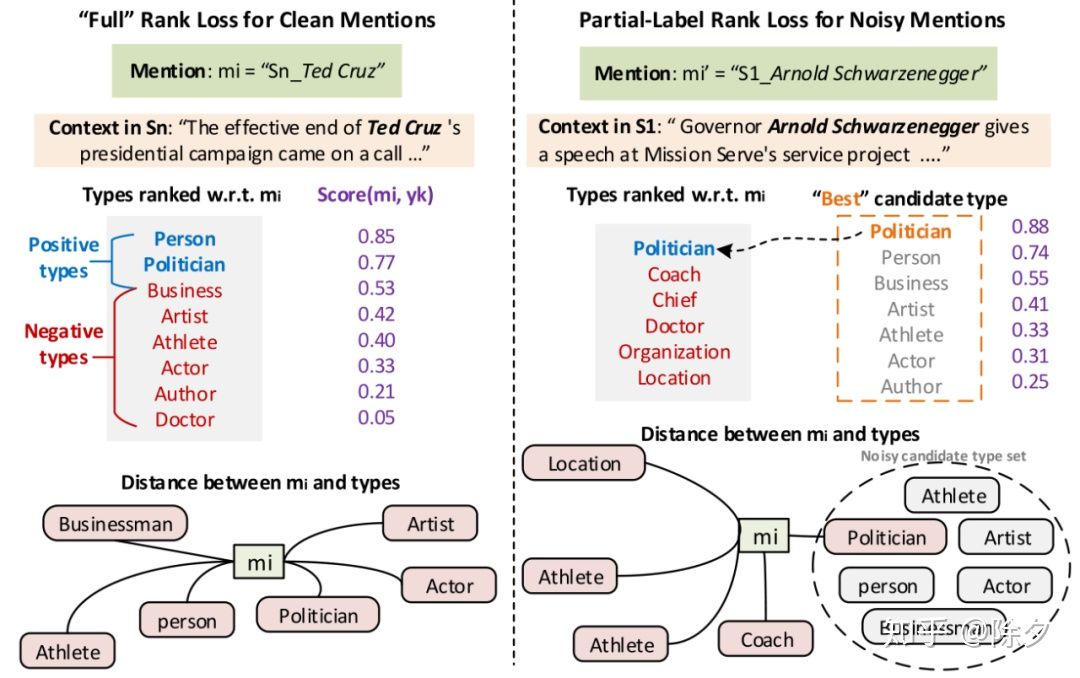
▲ rank loss 计算流程可视化
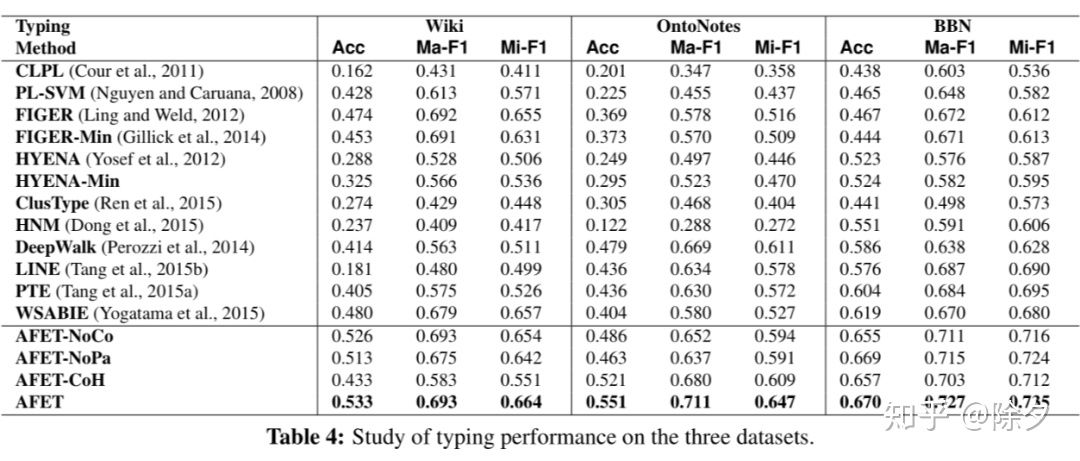
▲ AFET 结果一览,2016 年 SOTA 水平
难点四:实体标签有层级
对于多标签问题,不同标签之间存在包含与被包含的层级关系。父级标签的确定会约束下级的候选标签有哪些。而且在语义上父级标签会比更细粒度的标签更通用、宽泛。实体标签层级问题我们可以完全可以用 AFET 的思路去解。但也有不少有趣的论文针对标签层级问题提出了自己的解法。
 **论文标题:**Neural Architectures for Fine-grained Entity Type Classification
**论文标题:**Neural Architectures for Fine-grained Entity Type Classification
发布时间: EACL 2017
论文链接: https://arxiv.org/abs/1606.01341
代码链接: https://github.com/shimaokasonse/NFGEC
这篇文章为细粒度实体分类模型构建了一个统一的框架。这也是后来著名的 Attentive 模型。它把 mention 实体中的词向量取平均后的表征,与经过 BiLSTM + Attention 之后的上下文表征一起拼接起来,经过 MLP 进行类别。
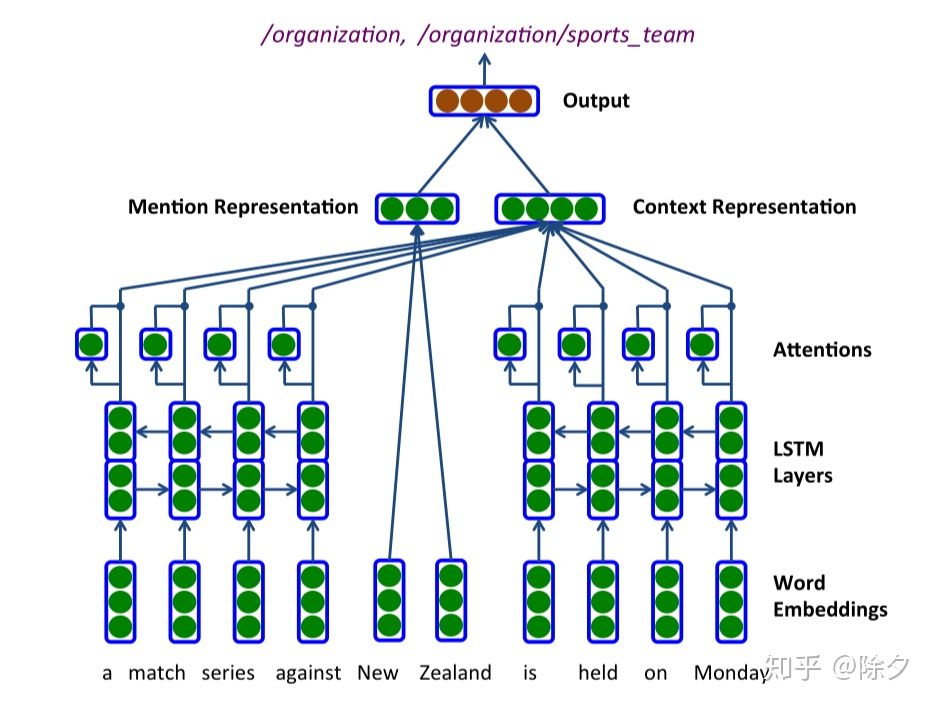
论文把每种层级关系都考虑为一个预测类别。比如 Person/artist/actor 存在三种粒度。它会把这个类别编码成三个向量。
第一级 Person 为一个 one-hot 向量,第二级粒度 Person/artist 为有两个索引位置为 1 的多标签向量,第三极粒度 Person/artist/actor 为有三个索引位置为 1 的多标签向量。
如图所示。这个向量会乘上一个学到的权重矩阵编码成包含层级关系的嵌入。这种方式的好处是,允许相同层级的标签共享相同的参数,使得在学习在相同层级下的标签更容易。
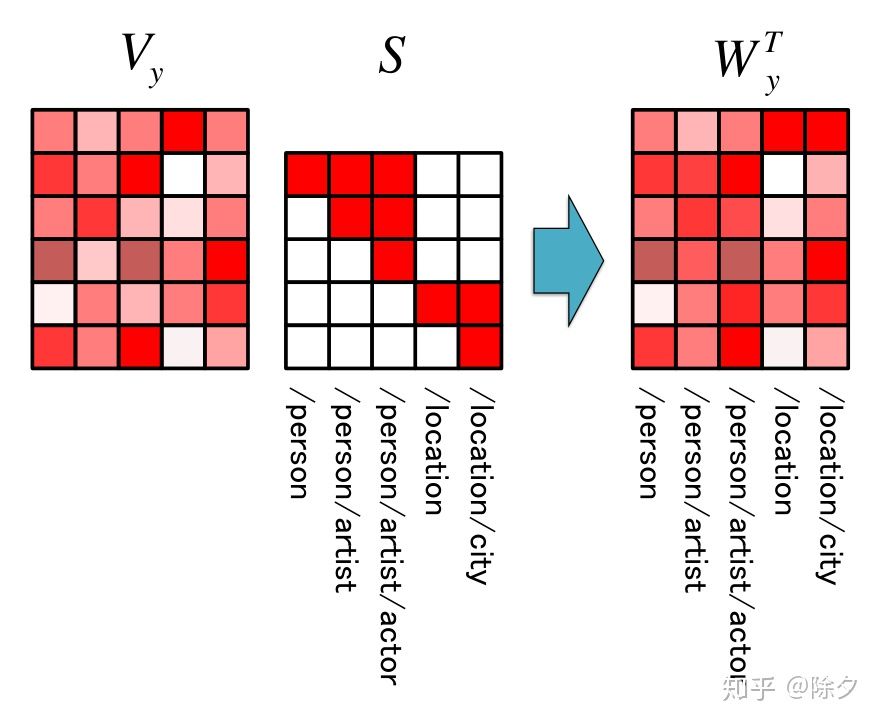

论文标题: Neural Fine-Grained Entity Type Classification with Hierarchy-Aware Loss
发布时间: NAACL 2018
论文链接: https://arxiv.org/abs/1803.03378
代码链接: https://github.com/billy-inn/NFETC
在远程监督的噪音中,有一类噪音需要特别留意,那便是 over-specific noise。远程监督的方法经常会给数据标出过于细致的标签。其中的部分过细标签并不能从上下文情景中推断处理。
比如周杰伦出生于台北中,候选标签可能会有歌手,创作人,演员,导演等各种标签。但这里的上下文只能将“周杰伦”这个实体推断为人类。之前的去噪算法其实都不能很好地去区分这种噪音,这是因为它们忽略了实体标签之间的层级依赖关系。
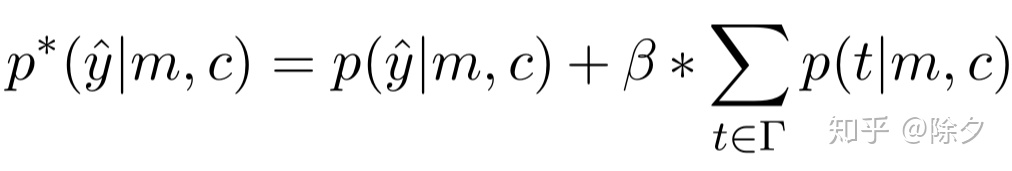 论文使用了一种层次感知的损失来为标签的层级关系建模。其中,是标签的所有上级的集合。这样上级的类型也被当作是部分正确的标签加入优化。但对于没有 over-specific noise 的数据可能也会因此而加上一个错误的标签。这种方法和数据集有很大关系。如果测试集倾向于标注叶节点的标签,则会带来额外的损失。
论文使用了一种层次感知的损失来为标签的层级关系建模。其中,是标签的所有上级的集合。这样上级的类型也被当作是部分正确的标签加入优化。但对于没有 over-specific noise 的数据可能也会因此而加上一个错误的标签。这种方法和数据集有很大关系。如果测试集倾向于标注叶节点的标签,则会带来额外的损失。
难点五:实体边界有嵌套
嵌套实体命名识别推荐看 Paperweekly 的这篇综述 浅谈嵌套命名实体识别。写的深入浅出,非常全面,这里不冗述。另外值得一看的是去年的 SOTA 模型 基于机器阅读理解的命名实体识别方法,这个 PaperWeekly 也有人详解。
结语
- 完备的细粒度实体类别体系非常有价值,但依赖于现有的垂类知识库。这条件只有大厂才能做。
- 远程监督噪音问题推荐用压缩隐空间簇去解决,提升效果显著且鲁棒性高。
- 基于阅读理解的命名实体识别方法适用于稍长的资讯类文本,但对于短文本,高层语义信息的加入提升效果不明显。
- 标签层级问题再推荐近两年来的三篇论文 [12],[13],[14]。直观地说,模型和人一样,更容易区分粗粒度实体,而相对容易混淆细粒度实体。[14] 的解决思路值得一探,通过在不同层级为排序模型设定不同的边际,再让解码器在类型层次结构上去搜索可以保障预测标签不违反层次结构。
- 在细粒度实体标注中,思考如何利用远程标注信息来让模型要区分的类别变少,从而减缓模型的学习曲线也是一个很值得研究的方向。直觉上看,二分类要比多分类要容易。在相同条件下,类别越少,模型要预测信息的困惑程度越低。
过往文章链接:
除夕:命名实体识别 NER 论文综述:那些年,我们一起追过的却仍未知道的花名 (一)
Reference
[1] Hovy, E., Marcus, M., Palmer, M., Ramshaw, L., & Weischedel, R. (2006, June). OntoNotes: the 90% solution. In Proceedings of the human language technology conference of the NAACL, Companion Volume: Short Papers (pp. 57-60).
[2] Ling, X., & Weld, D. S. (2012, July). Fine-grained entity recognition. In Twenty-Sixth AAAI Conference on Artificial Intelligence.
[3] Gillick, D., Lazic, N., Ganchev, K., Kirchner, J., & Huynh, D. (2014). Context-dependent fine-grained entity type tagging. arXiv preprint arXiv:1412.1820.
[4] Murty, S., Verga, P., Vilnis, L., & McCallum, A. (2017). Finer grained entity typing with typenet. arXiv preprint arXiv:1711.05795.
[5] Choi, E., Levy, O., Choi, Y., & Zettlemoyer, L. (2018). Ultra-fine entity typing. arXiv preprint arXiv:1807.04905.
[6] Ren, X., He, W., Qu, M., Voss, C. R., Ji, H., & Han, J. (2016, August). Label noise reduction in entity typing by heterogeneous partial-label embedding. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 1825-1834).
[7] Xin, J., Zhu, H., Han, X., Liu, Z., & Sun, M. (2018). Put it back: Entity typing with language model enhancement. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (pp. 993-998).
[8] Chen, B., Gu, X., Hu, Y., Tang, S., Hu, G., Zhuang, Y., & Ren, X. (2019). Improving distantly-supervised entity typing with compact latent space clustering. arXiv preprint arXiv:1904.06475.
[9] Ren, X., He, W., Qu, M., Huang, L., Ji, H., & Han, J. (2016, November). AFET: Automatic Fine-Grained Entity Typing by Hierarchical Partial-Label Embedding. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (pp. 1369-1378).
[10] Shimaoka, S., Stenetorp, P., Inui, K., & Riedel, S. (2016). Neural architectures for fine-grained entity type classification. arXiv preprint arXiv:1606.01341.
[11] Xu, P., & Barbosa, D. (2018). Neural fine-grained entity type classification with hierarchy-aware loss. arXiv preprint arXiv:1803.03378.
[12] Murty, S., Verga, P., Vilnis, L., Radovanovic, I., & McCallum, A. (2018, July). Hierarchical losses and new resources for fine-grained entity typing and linking. In P
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BB%86%E7%B2%92%E5%BA%A6%E5%AE%9E%E4%BD%93%E5%88%86%E7%B1%BB%E8%AE%BA%E6%96%87%E7%BB%BC%E8%BF%B0%E4%BA%8C/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


