精选知识点什么是非极大值抑制
文末免费送电子书:七月在线干货组最新 升级的《名企AI面试100题》免费送!
解析1:
- NMS是一种Post-Procession(后处理)方式,跟算法无关的方式。
- NMS应用在所有物体检测的方法里。
- NMS物体检测的指标里,不允许出现多个重复的检测。
- NMS把所有检测结果按照分值(conf. score)从高到底排序,保留最高分数的 box,删除其余值。
节前给推荐一门硬核数据分析课,由七月& 深度 联合出品的【数据分析业务实战年度VIP】课程
课程老师均由在一线实战5年的数据分析是和科学技术担任,本课将通过 4大数分思维 + 12种数据分析工具 + 30+企业级项目实战 + 名师1V!答疑 + 全套课件代码 ,助你从 0到1 构建分析能力、深度理解业务逻辑!
课程链接: https://www.julyedu.com/course/getDetail/380

解析2:
概述
非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,可以理解为局部最大搜索。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。这里不讨论通用的NMS算法(参考论文《Efficient Non-Maximum Suppression》对1维和2维数据的NMS实现),而是用于目标检测中提取分数最高的窗口的。例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。
NMS在计算机视觉领域有着非常重要的应用,如视频目标跟踪、数据挖掘、3D重建、目标识别以及纹理分析等。
NMS 在目标检测中的应用-人脸检测框重叠例子:

我们的目的就是要去除冗余的检测框,保留最好的一个。
目标检测 pipline
产生proposal后使用分类网络给出每个框的每类置信度,使用回归网络修正位置,最终应用NMS.
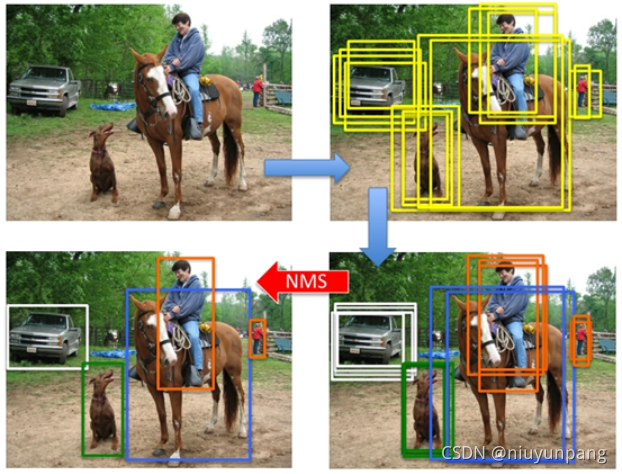
NMS 原理
对于Bounding Box的列表B及其对应的置信度S,采用下面的计算方式.选择具有最大score的检测框M,将其从B集合中移除并加入到最终的检测结果D中.通常将B中剩余检测框中与M的IoU大于阈值Nt的框从B中移除.重复这个过程,直到B为空.
重叠率(重叠区域面积比例IOU)阈值:常用的阈值是 0.3 ~ 0.5.
其中用到排序,可以按照右下角的坐标排序或者面积排序,也可以是通过SVM等分类器得到的得分或概率,R-CNN中就是按得分进行的排序.

就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。非极大值抑制的方法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率 分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%B2%BE%E9%80%89%E7%9F%A5%E8%AF%86%E7%82%B9%E4%BB%80%E4%B9%88%E6%98%AF%E9%9D%9E%E6%9E%81%E5%A4%A7%E5%80%BC%E6%8A%91%E5%88%B6/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


