精华搜索推荐系统实战篇上半篇
欢迎关注我的公众号: 炼丹笔记
1. 前言
背景
在电商搜索中,例如淘宝,拼多多,京东等的搜索的场景往往是: 用户A通过搜索框Query找到他/她想要购买的东西,然后搜索引擎通过某些算法策略返回一系列商品,用户再决定是否进行点击购买。
要做好这样一个问题,我们需要抓住问题的核心。那么搜索引擎的核心是什么呢?至少有两点。
- 返回的商品一定要是强相关的,也就是说Query和Item必须是强相关的,如果返回的商品是不相关的,举个例子,用户过去只在Aliexpress上买篮球鞋,突然有一天想买个足球,结果搜索引擎返回的全部是篮球鞋相关或者是其它无关的商品,此时用户的体验肯定会非常差,用户大概率会骂搜索引擎垃圾……所以搜索引擎最为重要的一步就是返回强相关的商品;
- 返回用户大概率会购买的商品:如果搜索引擎返回的商品都是强相关的,那么下一步,我们便可以把该问题转化为一个推荐相关的问题,我们需要找出该情况下转化率最高的商品推荐给用户。因为即使是相关的商品,也会有千千万万个,但用户并不是所有的商品都会进行购买,比如,某用户月收入是几千元,但搜索引擎返回给用户的商品都是几十万的,很明显超出了用户的能力范围,所以用户购买的概率几乎为0,但如果我们推荐的商品是用户能力范围内的符合用户兴趣爱好的,那么用户购买的概率就会大大提升。
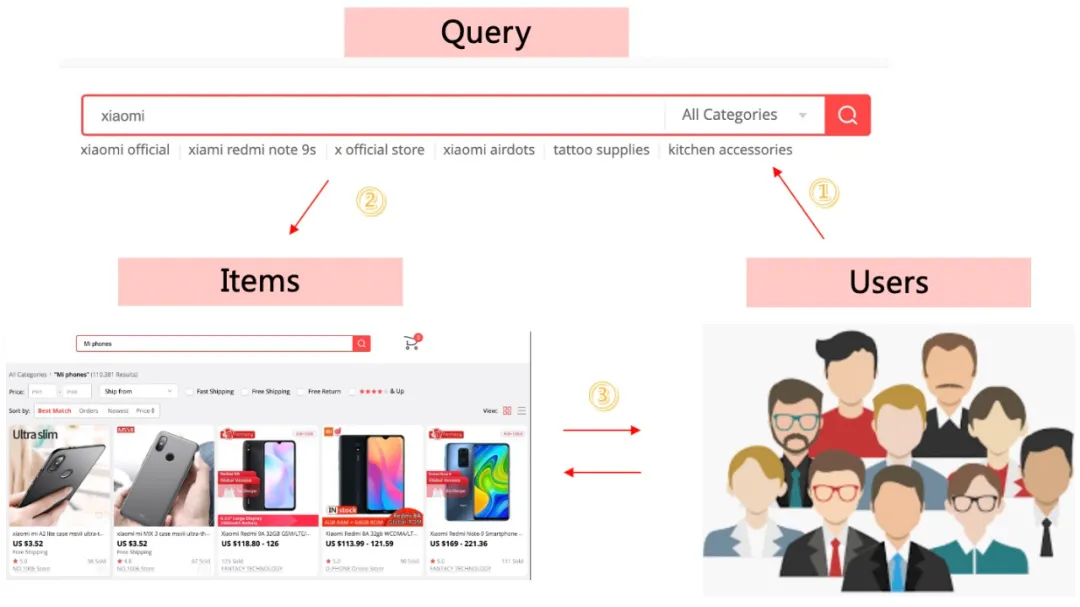
从上面看,我们的核心至少有两个,一个是构建Query与Item的关系(保证Query下返回的商品至少是强相关的),第二个就是构建User和Item的关系(在强相关的商品中,找到用户大概率会点击购买的商品)。
上面两点是很多电商搜索引擎需要做到的,依据平台的不同,可能还会有些许不一致。


问题定义
在电商搜索背景下,我们的目标依据大佬们对于平台当前的发展定位以及未来规划达到的目标往往会有些许不同,优化的指标也会有较大的不同,常见的一些热门指标如下:
-
UV价值:店铺转化率越高同时客单价也较高的话,店铺的UV价值就会很不错;如果平台上店铺的uv价值不错,那么商家就只需要通过相关策略提升店铺的uv,往往就可以带来不错的收益。该指标可以从一定程度反映平台的性质,如果转化率很高,但是UV价值很低,那么大家的定位可能就是卖便宜商品的;如果转化高,UV价值也高,这个一般就是非常完美的了。
- UV价值=销售额/访客数=转化率*客单价;
-
曝光到购买的转化率:这个指标较容易理解,就是商品从曝光到被购买的概率,如果平台的转化率很高,一般可以反映该平台诸多产品都还是很受欢迎的;用在推荐搜索推荐的场景较多, 可以从侧面反映搜索引擎的好坏;
- 转化率=购买量/曝光量;
- GMV(Gross Merchandise Volume):是成交总额(一定时间段内)的意思,一般包含拍下未支付订单金额,所以一般会高于实际成交额。该指标越大,往往能说明平台的影响力也非常大,因而该指标也常常被用于各大电商平台的比较,该指标一般也是 长期需要被关注的指标
- 复购率:重复购买率有两种计算方法:一种是所有购买过产品的顾客,以每个人人为独立单位重复购买产品的次数,比如有10个客户购买了产品,5个产生了重复购买,则重复购买率为50%;第二种,按交易计算,即重复购买交易次数与总交易次数的比值,如某月内,一共产生了100笔交易,其中有20个人有了二次购买,这20人中的10个人又有了三次购买,则重复购买次数为30次,重复购买率为30%。企业一般采用的是第一种。该 指标一般到了平台到一定规模之后会关注的,考量用户的对于平台的忠诚度,用来衡量平台的良性;
- 90天内重复购买率达到1%15%;说明你处于用户获取模式;把更多的精力和资源投入到新用户获取和转化;90天内重复购买率达到1530%;说明你处于混合模式;平衡用在新用户转化和老用户留存、复购上的精力和资源;90天内重复购买率达到30%以上;说明你处于忠诚度模式;把更多的精力和资源投入到用户复购上;(摘自:《精益数据分析》)
上面几个指标是电商平时较为关注的,当然还有非常多其它重要的评估指标,例如:总体运营指标,网站流量指标,销售转化指标,客户价值指标,商品及供应链指标,营销活动指标,风险控制指标,市场竞争指标等等,想要深入理解的话可以阅读参考文献[7]。


本文重点
本文我们重点关注精排侧提升 曝光到转化 的优化问题,即从曝光到被购买的概率优化问题。
2. 建模
和许多数据建模问题类似,在我们的问题初步确定之后,接下来需要考虑的问题就是设计评估指标并针对问题进行指标的优化。


评估指标设计
- 线上指标:计算的就是从曝光到购买的转化率,无需再进一步设计;
- 线下指标:线下指标我们需要能尽可能的对应到线上,即,线下涨的同时尽可能保证线上也能涨;


线下评估指标对比
1. AUC(采样/不采样)
在很多情况下,我们一开始会选用AUC(Area Under Curve)指标来对线下模型进行评估。ROCAUC被定义为ROC曲线下与坐标轴围成的面积,一般我们以TPR为y轴,以FPR为x轴,就可以得到ROC曲线。
AUC =\frac{ROC曲线下的面积~~~~~~~~}{ 在x与y下面的面积} = \frac{\sum_{ins_i} rank_{ins_i} - M*(M+1)/2 }{M*N}
其中,M、N分别为正、负样本数。
AUC的数值都不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,一般就无太多应用价值了。其中关于:FPR(False Positive Rate)以及 TPR(True Positive Rate)的数学计算公式为:
FPR= \frac{FP}{(TN+FP)}\\ TPR= \frac{TP}{(TP+FN)}
在数据量非常大的情况下计算AUC是比较耗时的,有时为了快速迭代,我们会对验证样本进行随机采样然后计算AUC的值进行比较,这在KDD2020 Best Paper中也有讨论,采样之后的AUC一般是没有问题的,所以还是相对稳定的。
AUC指标在诸多问题中是一个非常不错的指标,但是在电商搜索的问题上可能会有些许不一致。举个简单的例子,假设我们每次曝光3个商品,
场景1:
- 用户A搜索之后得到商品i_1, i_2, i_3,模型预测概率为0.8,0.7,0.6,用户购买了第一个商品;
- 用户B搜索之后得到商品i_1, i_2, i_3,模型预测概率为0.5,0.4,0.3,用户购买了第一个商品;
场景2:
- 用户A搜索之后得到商品i_1, i_2, i_3,模型预测概率为0.8,0.7,0.6,用户购买了第一个商品;
- 用户B搜索之后得到商品i_1, i_2, i_3,模型预测概率为0.8,0.7,0.6,用户购买了第一个商品;
这个时候,场景1得到的AUC是0.75,而场景2得到的AUC则是1;这么看这个指标好像并不是非常合理,同样的购买情况,但是得到的结果却是不一样的,因而AUC指标把所有的预测结果都放在了一起考虑,所以对于电商搜索等场景该指标有些粗犷了,我们需要一些更加精细的评估指标。
from sklearn.metrics import roc_auc_score
## 场景1
pred_A = [0.8,0.7,0.6]
pred_B = [0.5,0.4,0.3]
label_A = [1,0,0]
label_B = [1,0,0]
roc_auc_score(y_score=pred_A + pred_B, y_true=label_A + label_B)
0.75
## 场景2
pred_A = [0.8,0.7,0.6]
pred_B = [0.8,0.7,0.6]
label_A = [1,0,0]
label_B = [1,0,0]
roc_auc_score(y_score=pred_A + pred_B, y_true=label_A + label_B)
1.0
2. GAUC
GAUC的数学形式如下:
GAUC = \frac{\sum_{i=1}^n w_i * AUC_i}{\sum_{i=1}^n w_i}
此处的w_i可以表示很多东西,例如带有点击的页面的权重,那么GAUC就是每个展示页面中,用户的对于排序的商品的满意度。
在电商搜索中,我们也可以令w_i表示 单个用户单条query 的权重,那么此时GAUC就是用户在query下对于得到的排序商品的满意度,在有些场景下w_i也可以表示是某个用户,在计算GAUC的时候,我们一般会删除全部为0的情况。如果我们采用GAUC为评估指标,在上面的两个场景中,我们的GAUC都是1,这其实就比较符合我们的预期了。
但正如大家所看到的,GAUC也存在一些问题,
- 我们在计算GAUC的时候, 把全部为0的情况删去了,而如果这种情况占比较大,GAUC的不确定性就会增大。
- 用户在当前页面购买了曝光位置为3个商品,而没有购买曝光位置为1的商品和用户在当前页面购买了曝光位置为1的商品,而没有购买曝光位置为3的商品AUC不一致,这时我们计算得到的AUC_i是不一样的;这也较为合理,因为我们希望越好的商品越靠前;再比如用户在当前页面购买了曝光位置为最后的商品,这个时候我们计算得到的AUC_i为0,但在这两种情况,我们线上的UV/PV转化率是差不大的,所以有时会带来线下线上不一致的情况;这从指标的设计来看,也是可以理解的。
从众多的文章博客和论文中的实验记录,以及我们自己的评测指标来看,目前大家都还是主要看GAUC指标, 本文剩下的内容也会以PV的GAUC为主要观测指标。
3. 关于AUC与GAUC
从我们平时的实践情况来看,在90%的情况下AUC和GAUC是一致的,也就是说AUC上涨的话,那么GAUC基本都是涨的,但这并不是绝对的。但平时线下90%的情况下对比AUC的实验也是合理的。
3. Loss&整体框架设计
- 把Loss的设计排在特征工程等操作之前,结合业务指标并设计对应的Loss一般都是模型优化的第一步,如果Loss设计不佳,可能后续的诸多结论在新的情况下都会有问题, 所以在第一个模块我们先重点Loss的设计与探索。


问题背景
目前绝大部分传统机器学习框架都是基于下面的形式进行的,我们将训练数据输入到某个深度的模型框架,最后通过设计的某种Loss进行模型的训练,

因为我们的目标是提升模型从曝光到被购买的转化率,这看起来和非常多的二分类问题类似,我们只需要 将曝光且被用户购买的记录标记为1,而将曝光但是用户却没有购买的商品标记为0,然后使用Logloss/Binary cross entropy作为损失函数进行模型训练和设计即可。
Loss = -\frac{1}{N} \sum_{i=1}^N (y_i logp_i + (1-y_i) log(1-p_i))
其中N是样本的个数,y_i是标签(曝光且被点击就是1,反之为0),p_i是关于第i个样本的预测概率。
初看,好像没有太大的问题,在之前的IJCAI2018年的”阿里妈妈搜索广告转化预测“的诸多Top方案基本是类似的,只需要直接使用上面的Loss进行优化即可,但是实际情况 和我们理想情况下还是相差较大的。
在几乎现在90%的电商搜索领域,大家使用的模型都是基于多个模型的Cotrain,也就是大家经常听到的DeepMTL(DeepMTL:Deep Multi-Task Learning,深度多任务学习)。如下图就是一种常见CTR+CVR Cotrain的框架:
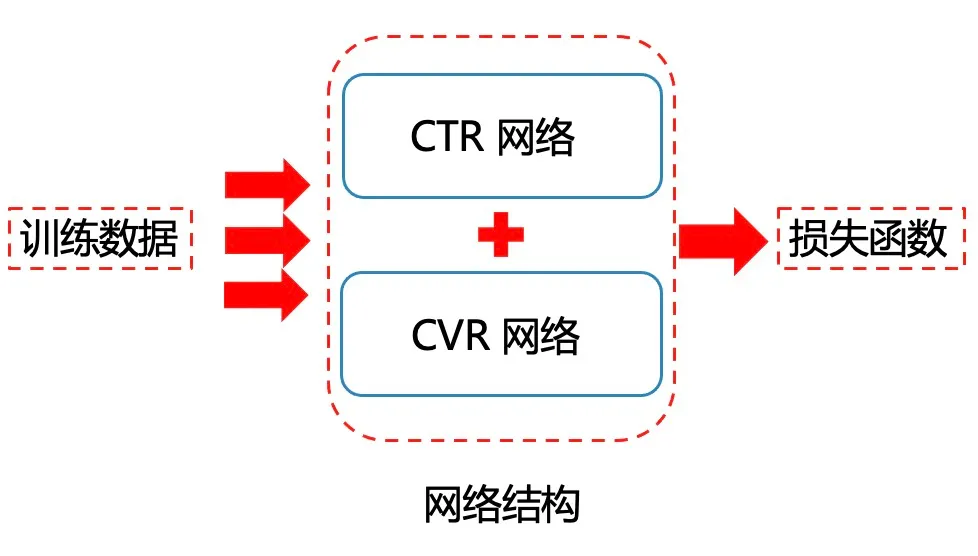
CTR+CVR Cotrain的框架,就是两个网络分支,一个对应CTR, 一个对应CVR。最后我们采用pctr * pcvr的形式表示我们从曝光到购买的概率。而此时我们优化的Loss如下:
Loss = \alpha \cdot CTRLoss + \beta \cdot CVRLoss
其中:
- \alpha, \beta, 为平衡两个loss的系数,一般通过线下实验进行调整。
刚开始对于这类设定我们还是非常怀疑的,明明可以直接优化的Loss,为什么还要加个CTR的Loss进行辅助?于是我们做了个线下的对比实验,直接训练曝光到转化以及早期的CTR和CVR Cotrain的模型,结果发现:
- 单独训练曝光到购买的转化模型相较于Cotrain的模型效果变差了很多,有将近 1-2个绝对百分点的GAUC下降;
这和平时实践中直接优化Loss的直觉是相反的,甚至有些怀疑人生,但是我们实践经验却时刻提醒我们要做好问题的优化,一个好的Loss至关重要。所以我们便去调研如下问题:
- Why DeepMTL优化单纯的单模型优化?
在和一些搞精排模型的朋友交流之后, 大家关于CTR和CVR进行Cotrain方式的解释大致可以归纳为:
- 直接优化曝光到购买的loss,因为正样本太少, Embedding学习不充分,而Cotrain的方式可以缓解这样的问题;
- CTR+CVR的方式是之前较为 成功的尝试,直接在此基础上进行进一步改进可以拿到更好的效果。
为了更好地了解采用DeepMTL方案的原因,我们进行了较为深入的调研。
DeepMTL有效性理解的调研
从网上的诸多资料的调研之后,我们发现一般采用DeepMTL的场景有下面6个大类。
- 隐式数据/特征扩充(Implicit data augmentation)
- 正则,去噪,扩大泛化性
- 作为Hints信息
- 常见于决策过程(例如:exposure -> click -> pay)问题中,修正中间结果(例如pcvr)or利用前一层信息
- 赋能添加其它功能
- 单模型集成
1. 隐式数据/特征扩充(Implicit data augmentation)
进行多任务建模,意味着我们需要有多个任务,而 多个任务,这也意味着每个任务都可能拥有不同的数据,所以每个任务都可以从其他任务的数据集里面吸收额外的有用的信息,获得额外的增益。我们在模型训练的时候其实是加入了额外(其他任务的信息)的信息,这个时候原先的任务效果得到提升也是大概率的事情。其实如果从第二个任务中抽取特征等加入到主任务中,可能也会有提升。DeppMTL则是通过梯度回传的方式将其它任务的信息加入了进来。
经典的工作有:
- Why I like it_Multi-task Learning for Recommendation and Explanation,RecSys2018
- Improving Entity Recommendation with Search Log and MultiTask Learning,IJCAI2018
- Jointly Learning Explainable Rules for Recommendation with Knowledge Graph,WWW2019
- SEMAX: Multi-Task Learning for Improving Recommendations,IEEE2019
- Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation,WWW2019
这些论文的工作都是通过寻找相关的任务,例如第一篇论文的工作就是通过加入评论信息来辅助用户商品的协同过滤效果, 第二个工作则通过使用context-aware ranking信息来辅助提升实体推荐的效果。
2. 正则,去噪,提升泛化性
多任务学习, 任务之间共享的特征表示因为需要同时满足多个任务, 这就意味着这些特征表示需要拥有不错的泛化性,所以多任务学习可以降低因为单个任务数据脏而带有较多噪音的问题。因为DeepMTL最终优化的Loss是由多个任务的Loss结合起来的, 对于每个单独的任务,其他的任务对应的Loss可以当做是正则项。
3. 作为Hints信息
有些信息较为难学,但又是主任务(核心任务)的重要特征,可以另外起一个任务对其进行学习,再将学习到的信息传递给主任务。
一些特征对于某些特定任务是非常易于学习的,但是对于另外一个任务A可能却很难学,而这种难学可能是由于特征和任务A的关系较为复杂等原因造成的,通过多任务学习,我们可以令任务B去学习,而最简单的方式就是通过hints去做这件事。还常见于一些图像问题中,单独分出一个任务识别小的物体信息;
经典的工作有:
- Learning Sentence Embeddings with Auxiliary Tasks for Cross-Domain Sentiment Classification.EMNLP2016
- Neural Multi-Task Recommendation from Multi-Behavior Data.ICDE2019
第一篇文章通过预测输入句中是否含有积极或消极的情绪词,作为情绪分析的辅助任务; 第二篇则通过模型输出前面任务的预测结果作为Hints信息传递给后续的模型当中。
4. 用于决策过程,缓解SSB/DS,调优中间结果or利用前一决策信息
此处说的决策过程最典型的例子就是在电商的购物流程中, 消费者购物需要经历:exposure -> click -> pay的过程。
1. 缓解SSB/DS,调优中间结果
这在电商搜索和广告问题里面最为经典的就是CVR预估问题,CVR预估在整个决策的中间阶段,直接使用中间阶段的数据则会出现较多的问题,例如SSB(Sample Selection Bias),DS(Data Sparsity)等,那么怎么办呢?用多任务学习将整个决策过程串联起来。最为典型的工作就是:
- Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate, SIGIR2018
- Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction,SIGIR2020
这样我们建模的时候就可以利用到丰富的点击数据,从而使得我们神经网络中的Embedding得到更为充分的训练,缓解Data Sparsity的问题,此外,我们的建模目前是直接基于曝光建模的,也可以缓解SSB问题。
那为什么我们说还可以修正中间结果呢?我们以第一篇ESMM为例,我们看用户的购物过程是下面这样一个过程:用户先进行了搜索,然后得到了搜索引擎的反馈X1, 用户对自己相对感兴趣的商品进行点击, 进入了详情页X2, 然后通过在X1看到的信息并结合X2的信息以及自身的需求确定是不是购买。如下图所示, 此处我们先不考虑加购收藏等情况,
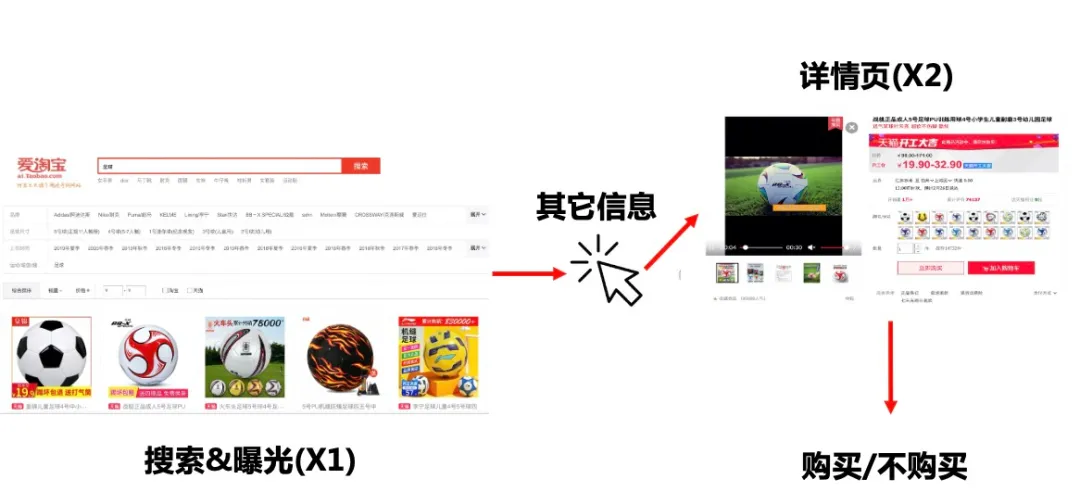
CVR就是在求,
P(pay=1|click=1,X2')
这边X2’表示详情页的信息X2以及一些上下文信息,例如从曝光页X1带过来的信息,用户在曝光页面看到了很多感兴趣的商品,这些也会影响他进入详情页之后是否最终购买的决定。
我们看ESMM论文中给出的公式是:
P(pay=1,click=1|X) = P(pay=1|click=1,X) * P(click=1|X)
这在数学上成立的,但是却忽略了一个比较大的问题,点击页面给出的X和详情页的X是不一样的,此处我们的P(pay=1,click=1|X)以及P(click=1|X)可以认为是无偏的,我们强行用相乘的形式来表示二者的关系,所以修正了在相乘关系下的情况。
2. 利用前一决策的信息
在用户决策的过程中,存在先后顺序,在后续的决策过程中,我们可以通过利用前一阶段的信息来辅助后续的建模。典型的案例有:
- Neural Multi-Task Recommendation from Multi-Behavior Data.ICDE2019
- Deep Bayesian Multi-Target Learning for Recommender Systems,ArXiv2019
这几个工作都会将前一阶段的信息作为特征输入输入到后续的模块当中,而且都取得了不错的效果。我们在实践中也验证了这一点。
5. 模型集成
一个模型,中间多次相同任务的优化,中间表示层拼接然后做CF,可以做到类似集成效果;典型的工作有:
- Improving One-class Recommendation with Multi-tasking on Various Preference Intensities,RecSys2020
6. 赋能添加其他功能,例如可解释性等
多任务学习用于多个不同任务的建模也就意味着模型会拥有这些不同任务的功能。除了能辅助提升模型效果之外, 还可以扩展模型的功能性。达到一个模型多个功能的效果。典型的作品有:
- Why I like it_Multi-task Learning for Recommendation and Explanation,RecSys2018
- Jointly Learning Explainable Rules for Recommendation with Knowledge Graph,WWW2019
这两个工作将原任务和知识图谱等信息结合并利用知识图谱部分的任务对原模型赋能,使得模型还具有了一定的可解释性。


小结
从我们关于DeepMTL有效性的调研情况来看,电商搜索中采用DeepMTL模型建模能带来收益的原因主要有下面几点:
- 对于决策过程的建模是一种很不错的选择:曝光到支付是一个决策过程,我们需要先点击曝光的商品进入到详情页,进入详情页之后再决定是否进行购买;即,我们其实是在对整个过程进行建模;
- 利用更多的数据缓解DS的问题:使用点击的数据建模,可以缓解神经网络中Embedding训练不充分的问题,这是目前大家普遍比较认可的一种;
- Hints可以带来较大的帮助:CTR模型的预估结果可以带来不错的Hints信息,而CTR的预估概率对于最终转化是有非常强的正相关关系的,只有被点击的商品才可能带来转化,所以CTR模型的预估结果当作Hints信息可以为我们带来非常大的帮助。
在明确了DeepMTL的建模有效性之后,下一步要做的就是去细化它。
3.1 DeepMTL常见的两种建模方式探讨
虽然确立了DeepMTL的建模框架,但其实还存在非常多需要细化的地方,和一些做该方向的朋友交流之后,我们发现目前大家采用的DeepMTL框架大致可以按照对于数据流的使用方式不同而划分为两类。当然不管是哪种方式,都是有很多可以提升的地方的,下面我们将两种建模策略的诸多问题以及可能潜在的提升策略进行汇总。
1. CTR数据流+CVR数据流
CTR数据流+CVR数据流的大致流程如下图所示:
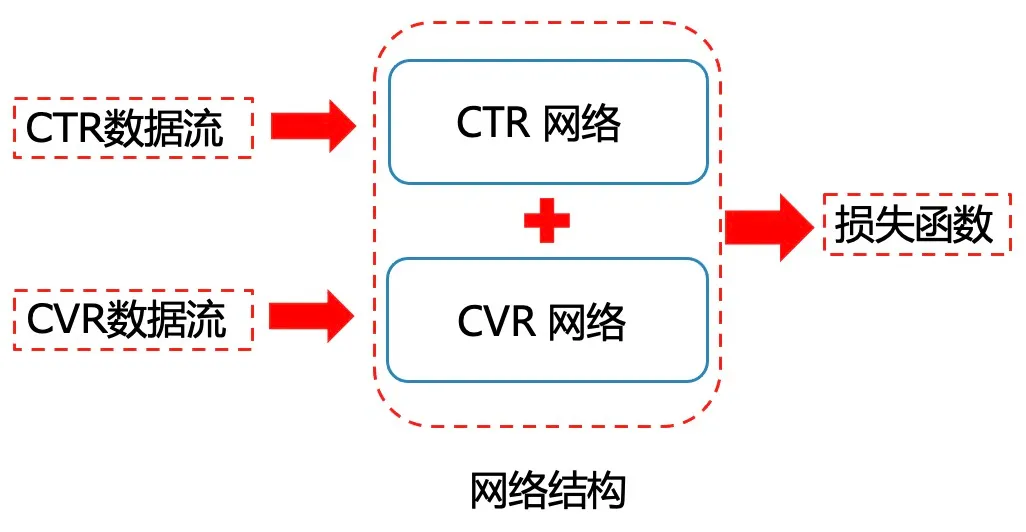
- 在CTR网络中,我们输入CTR数据流;
- 在CVR网络中,我们输入CVR数据流(click=1的数据);
- 这种情况下,我们一般会共享embedding层;
- 最终 曝光到购买的概率就是Pctr * Pcvr;
下面我们介绍这种策略的几个问题,以及对应的处理策略;
1.CTR/CVR数据流浪费问题:
-
问题:在使用两套数据流的时候,我们一般需要对CTR和CVR数据流分别进行batch采样进行模型的训练,例如CTR网络的batch_size为4096,CVR网络的batch_size为1024等,但这么做最大的问题就是可能CVR数据走完了,但是CTR数据却还没全部用完,造成CTR数据流的浪费;也有可能是CVR数据还没走完,但是CTR数据已经走完了,造成CTR数据的浪费;
-
解决策略:针对该问题,我们的解决策略自然就是基于样本采样层面的,
- 手工调整两个网络的batch_size比例,使得我们能尽可能少的浪费数据;例如固定CTR网络侧的batch_size,调整CVR网络侧的batch_size,选择较适合自己业务的数据集的理想比例;
- 采用某些动态采样的策略,使得两侧的数据尽可能同时跑完,这个tensorflow应该有对应的策略;
-
实验小结:对于网络侧的batch_size以及数据集的使用对于此类建模策略影响还是非常大的,是非常建议尝试的,算是一种没太多技术含量,但是实践价值却很大的操作,我们经常可以在调整之后得到稳定的增长(多天验证);
2.CTR&CVR网络数据层面的关联性丢失:
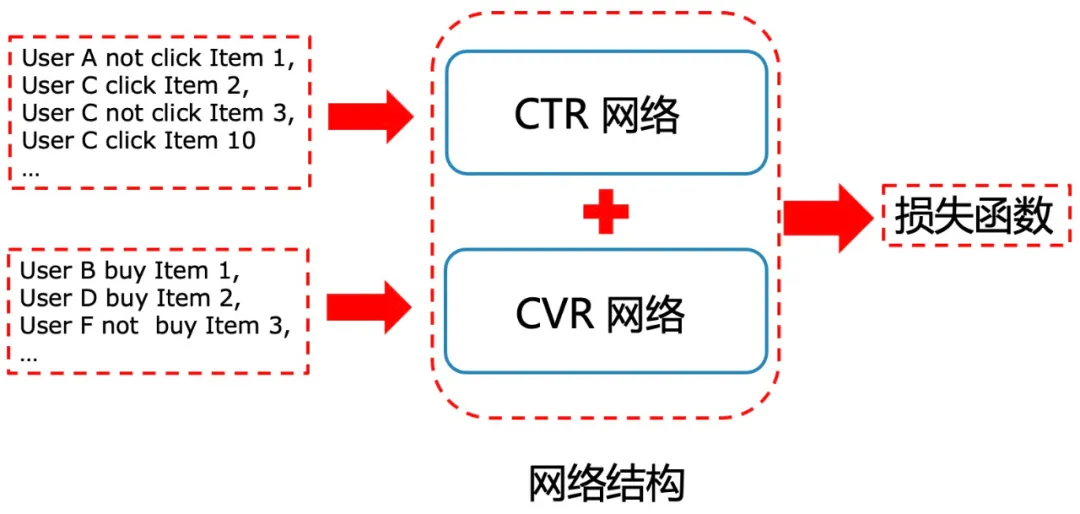
-
问题:CTR数据和CVR数据是分开采样训练的,每次都是分别随机采样的不同batch_size的数据,丢失了CTR数据和CVR数据之间的关联信息;经常出现同一个用户的连续行为被分割开,CTR数据是A用户点击了某个商品,但是CVR数据是B用户购买了某个商品,都不包含A的信息;关系如上图所示。
-
解决策略:尝试对数据之间进行某种方式的关联,尽可能去捕获这种关系。
- 从数据层进行关联:尽可能使得每次CVR的数据集和CTR数据集能进行关联;
- 从Loss设计层进行关联:加入辅助Loss,加强数据之间的关联,例如我们可以将CVR的数据再过一遍CTR网络,得到pctr的预估值,再和我们的CVR网络的输出进行相乘得到曝光到购买的预估概率,然后再使用该购买的标签数据设计新的Loss等;同样地,也可以将CTR的数据过一遍CVR网络,同样的策略;
Loss = \alpha \cdot CTRLoss + \beta \cdot CVRLoss + \kappa \cdot OtherLoss
其中\alpha, \beta, \kappa 是超参数,可以自己调整,OtherLoss是辅助Loss,用来加强数据之间的联系。
- 实验小结:设计辅助Loss,在使用CTR数据流+CVR数据流建模的情况下,可以稳定提升曝光到转化的预估准确率;
3.CTR&CVR网络数据Cotrain的问题:
- 发现:在模型的过程中,我们发现先对CTR网络先进行单独训练,固定住CTR网络再对CVR网络进行训练,相较于CTR网络和CVR网络共同训练带来的效果要好很多,但是训练的成本也会大一些,这个发现应该是通用的,也较容易理解,我们先对CTR网络进行训练完成之后,我们的embedding会获得一个不错的中间结果,这个时候我们再在此基础上训练CVR网络,肯定会比一起训练来的要好一些。
2. 纯CTR数据流
基于对CTR数据流和CVR数据流Cotrain的讨论,我们发现既然CVR的数据是全部被包含在CTR数据中的,分开训练又浪费数据又没法直接关联关系,既然所有的CVR数据流都来源于CTR数据流,那为什么不只使用CTR数据流呢?于是便有了基于CTR数据流的建模。
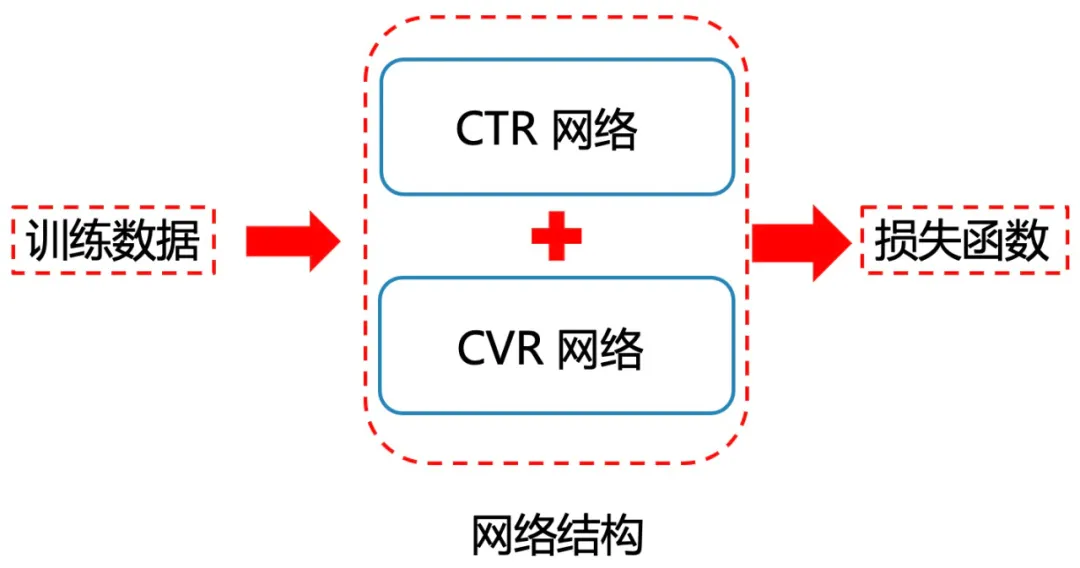
- 我们将同一份数据输入到整个网络中即可,无需单独产出两份数据;
- CTR和CVR网络公用一份数据,当然此处是CVR网络可以是其它网络,如果还是CVR网络的话,注意对click=0的数据对应的loss进行mask即可;
- Embedding层也是多个网络共享的。
1.CTR&CVR网络数据层面的优点:
- 节省了内存:因为所有的CVR数据都是直接从CTR数据流中得到的,我们并不需要再单独存储CVR数据,可以节省一定的存储空间;
- 数据关联加强:我们的数据得到了充分的关联,每个batch的数据关联性得到了加强。
2. 可待继续改进的地方:
-
问题:我们的数据的关联虽然得到了加强,但是我们的目标是提升从曝光到购买的概率;能不能从模型的层面进行改进?
-
解决策略:这个在CTR和CVR数据流建模的流程中其实也有提到:
- 加入辅助Loss,这边也较为简单,直接使用曝光到购买的信息构建Binary Cross Entropy Loss即可;
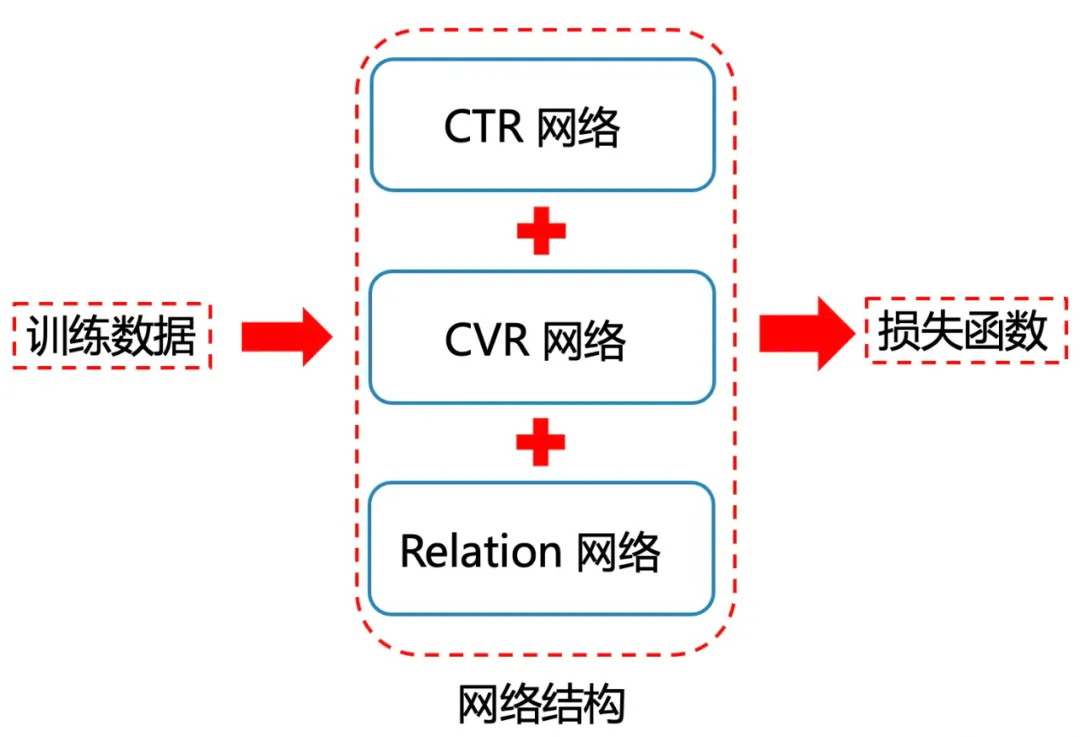
- 利用exposure -> click -> pay的序列关系进行建模。
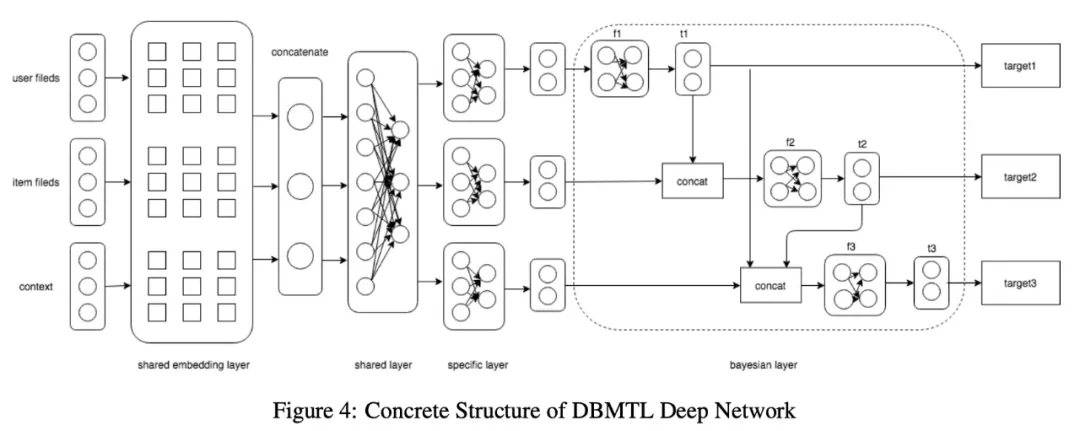
- 实验小结:基于DeepBayesian MTL的框架在曝光到转化率的预估过程中能带来较大的收益,和论文中阐述的相差不大,这种对过程建模的方式可以从这套框架中获得非常大的帮助。
3.2 DeepMTL挑战&提升角度&应用场景
在上面小节的讨论中,我们确定了我们模型大致框架,即使用单CTR数据流的DBMTL形式的建模策略,其实本质还是DeepMTL,所以关于DeepMTL中的挑战的处理往往可以为我们的模型带来不错的提升。
1. 相关任务的寻找&辅助Loss的设计
如何寻找能信息共用的问题, 即相关任务, 然后再对相关任务的建模辅助提升主任务的效果;目前比较成功的一些案例就是使用知识图谱提升协同过滤的效果;使用搜索log中context-aware ranking提升实体推荐的效果等。
- 使用推荐的广告的数据作为辅助任务来提升搜索转化的效果?
- 使用PC端的数据来提升mobile端的搜索转化效果?
2. 不同任务之间特征层信息的共享问题(如何避免负迁移);
这块最具代表性的工作就是MMOE,RecSys2020的Best Paper提出的PLE等算法了。不同任务的共享不可避免要讨论的就是共享层特征的公用问题,目前看PLE算法已经较好地解决了多任务特征层信息共享出现的跷跷板现象。但是有没有其他更好的策略仍然值得研究。
- Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts,KDD2018
- Progressive Layered Extraction(PLE)_A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations,RecSys2020
MMOE之前在CTR+CVR Cotrain的框架下得到了不错的提升,这块是非常值得参考的。
3. 不同任务之间的loss权重设计;
该挑战最为常见的使用场景就是视频推荐任务, 在视频推荐任务中,我们经常会使用视频观看时长百分比,是否观看完,是否点击等信息来共同建模,而这个时候就不可避免的发现下面这样的问题:视频观看的百分比是回归问题;是否点击是二分类问题;量纲不一致,直接loss相加调整权重的话,会出现比较多的问题,这一块的经典工作是:
- Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
4. 模型优化,不同任务共同优化;
在实践中,我们发现,对于不同的任务使用不同的优化方式进行优化可以给模型带来一定的帮助。在Taboola工程师的实践经验分享中也发现了这样的问题,如何对不同的任务进行优化也是一个值得探索的问题。
It’s a common convention that learning rate is one of the most important hyperparameters for tuning neural networks. So we tried tuning, and found a learning rate that looked really good for task A, and another one that was really good for task B. – By Zohar Komarovsky
5. 什么样的任务使用MTL任务是最好的, 能带来较大的帮助?
这个目前大家还是基于经验来做的,暂时没有完美的理论支撑。
小结
通过这一章的调研与实验,我们初步决定使用下面的框架:
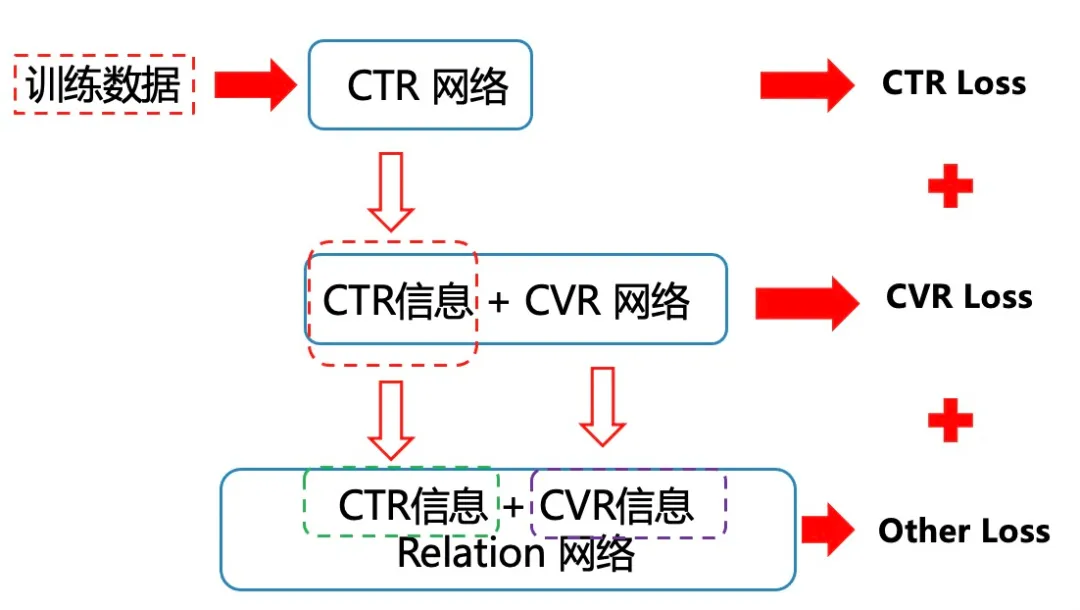
该框架的诸多优点:
- 只使用CTR数据流,可以节省一定的存储空间。
- 使用CTR数据,方案是从曝光到最终pay的流程进行建模,可以缓解SSB的问题;
- 使用了Click的数据,所以相对数据量还是可以的,可以缓解因为转化的正样本过少而引入的DS问题(方案使用了CTR数据,大大缓解了embedding的训练问题);
- 采用了类似DBMTL的框架,对整个流程进行建模,充分利用数据流之间的信息;
- 通过relation来构建CTR与CVR之间的联系,不再使用Pctr * Pcvr来建模购买关系,更为合理,符合直觉。
4. 数据收集&理解&数据预处理
1. 数据收集&理解
1.1 数据收集机制理解
关于我们的数据收集形式对我们进行后续数据的使用和预处理起到非常关键的作用,我承认这块我做得不是很好,导致在实验的过程中无脑的把数据直接丢入模型,看上去模型的效果变差了,带来了非常多错误的结论。从而使得后期又不得不重复进行实验。
注:公司的数据一般非常大,做大模型的话,在机器资源不够的情况下,跑一轮得到的结果是极其浪费时间的,关于这块,个人最大的建议就是在直接将数据丢到模型之前,至少检查以下几点东西。
- 重复数据观测:查看相同的id是否存在较为严重的重复,即出现了较多的重复数据,这些重复的数据会使得模型训练变差,从而带来幻觉,这些数据是没有意义的,但其实把重复的数据删去之后可能结论就完全相反了;
- 收集的数据丢失率检测:好的meta数据是建模有效的前提之一,如果数据收集的策略有问题,最差的情况是数据收集出错了,那就没必要建模了;不过最常见的讨论的问题还是丢失率的问题,就是理想情况下可以收集到100条数据,实际只能收集到60条,这种情况的话也没什么好说的,最简单的就是询问工程端能否提升数据的收集率,这是最简单的,数据多了准了,模型自然也会有提升的;
- 标签是如何来的:在电商中,用户点击完商品并不会立即就购买,所以购买的信息要和前面用户的用户点击记录相关联,这种关联机制也很重要,了解这些对数据预处理能带来非常大的参考。
- 其它的很多很多坑。
1.2 数据字段理解
这边不想吐槽太多,目测很多公司很多业务都是类似的,尤其是当业务发展多年的情况下,会遗留下一大堆数据表,这些表有非常多的字段,但是表的负责人已经离职了,很多数据字段也都没有写备注,但是这张表又和后面的很多关键表相关联,这是非常头疼的事情。
为什么说字段的理解非常重要呢?举个例子来说,商品ID(ItemID),比如iphone12的ID,
- 情况1:在不同的国家,iphone12都是使用同一个ItemID来表示的;
- 情况2:在不同的国家,iphone12都是使用不同的ItemID来表示的;
这样两种不同的数据字段携带的信息量是完全不一样的,
- 对于情况1,iphone12是只能反映在全局情况下的情况;
- 但是对于情况2,iphone12却反映的是在国家细粒度下的情况;
我们知道,不同国家的iphone12的销量可能是完全不一样的,在贫穷的国家可能销量就低;在富有的国家则销量很高,所以说数据字段的理解是至关重要的,相同的字段在不同设计情况下统计的特征可能完全是两码事。
2. 数据清洗
数据清洗:我们的数据中,存在非常多的脏数据,这些数据的处理可以帮助我们更好地提效,使得模型训练得到的结果更为良性;这一块没有做太多的工作,可能反欺诈等团队做的工作会多一些,典型的就是:
- 刷单的数据;
- 刷好评的数据等等;
- 爬虫的信息过滤等;
- 其它;

对这些数据的清洗可以更为真实的反映用户的习惯。
3. 训练数据采样
数据采样:因为大模型这块数据量非常大,很多时候数据经过各种merge操作之后,都可以达到上PB级别,所以模型的训练经常需要有合理的采样策略;而目前最为常见的采样策略是基于随机的,基于启发式的(也就是大家经常会使用的基于规则的),也有一些基于最新的一些论文的方式:
3.1 负样本随机采样
这个基本所有的公司和数据竞赛中在样本规模达到一定比例的时候都会有碰到, 将全部的负样本全部丢入到模型中进行训练,会浪费非常多的资源,而且常常因为类别不平衡等原因经常获得的效果往往还不如经过随机采样来的效果好。在我们的实验中,我们发现:
- 负样本的采样比例影响还是较大的,随机采样10%的负样本和随机采样20%的
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%B2%BE%E5%8D%8E%E6%90%9C%E7%B4%A2%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E5%AE%9E%E6%88%98%E7%AF%87%E4%B8%8A%E5%8D%8A%E7%AF%87/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


