精准推送实践
转载自 58架构师 公众号
时间: 2019-12-15
引言
在大数据和算法的时代到来后,内容分发已经不仅仅是简单的渠道随意推送,而是精准地识别用户爱好、精准地为用户推荐他所喜爱看的内容,然后将“精准”变得越来越专业,进而牢牢地抓住用户。
在产品运营的概念中,常见的精准推送给划分为以下两种:
1、站内精准推送:包括站内广告、信息流的推荐、商品推荐等
2、站外精准推送:包括广告投放、短信、 push 等
本文只针对站外(主要是 push)进行谈论。
精准用户集推送服务衍生自58用户画像体系,根据用户画像数据生成精准目标用户集,并依托于公司内部的推送平台,完成消息、广告推送的全生命周期管理。精准用户集推送功能面向于集团内部运营人员,已于2016年年底上线。
本文将通过 用户集服务架构演进 和 精准推送算法优化 两个方面,介绍精准推送在58的实践。
用户集服务架构演进
基本功能
用户集服务提供以下功能:
1、支持根据用户画像维度进行与、或、非等逻辑筛选用户集,用于在15分钟内的推送任务;
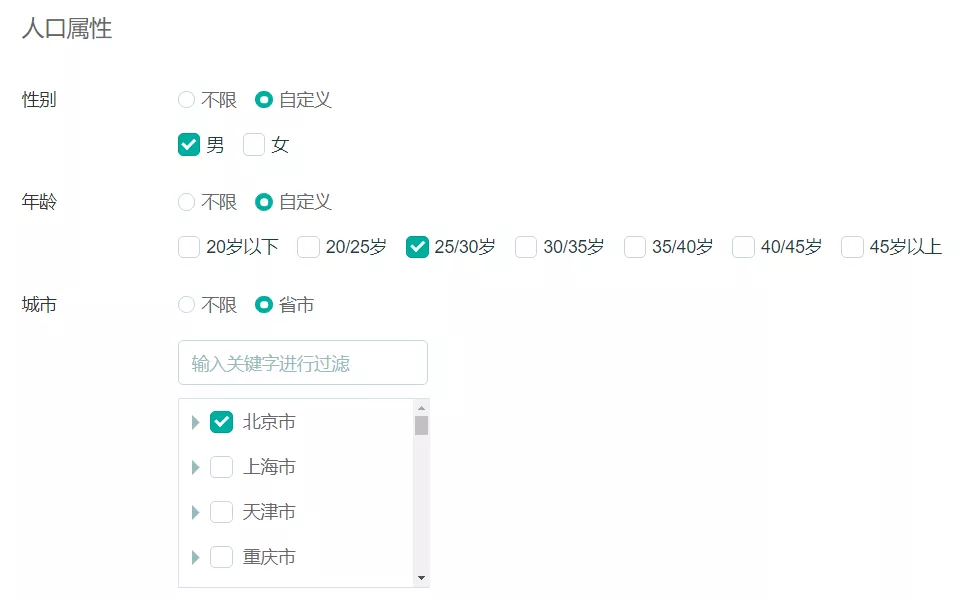
2、支持筛选过程中实时提示当前人群的预估人数;
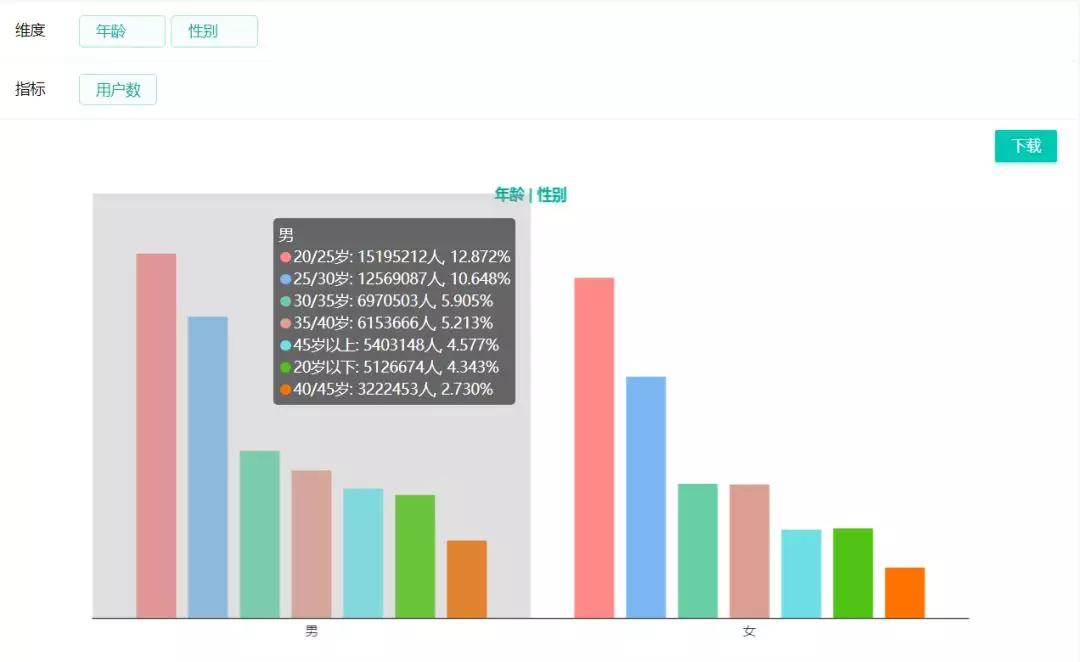
3、支持对全量人群或筛选人群的进行画像维度统计和可视化数据展示。
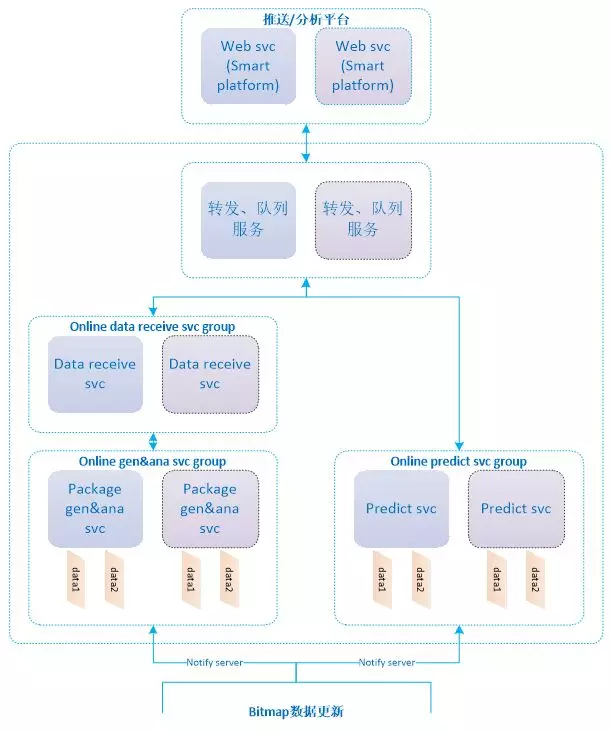
架构原型
用户集服务基于用户画像数据作为数据源,其中用户画像的设计本文不再赘述,可参考 《58用户画像实践》,目前已支持 亿级 用户的 2000 多个画像标签维度的用户集筛选。
整个架构根据功能拆分为三个服务:
1、优先处理推送用户集的人群筛选服务,提供同步调用服务;
2、人群分析服务优先级较低,耗时较大,提供异步调用服务;
3、人数预估服务提供人群筛选过程中实时显示预估人数的服务,区别于人群筛选服务和人群分析服务,为保证实时响应,采用了样本用户集预估计算而非全量用户集。
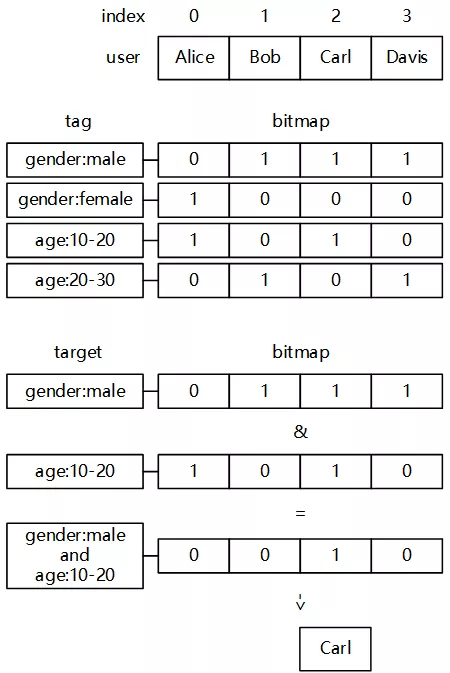
用户集服务底层存储前身基于MongoDB,后因计算效率等原因采用新的存储结构Bitmap取代了MongoDB。Bitmap采用全内存存储,存储和运算逻辑由C/C++代码实现。原理是将所有标签展开为具体项,每个用户所拥有的每个构成一个比特位,所有用户的构成一个超长数组,所有标签构成了数组list,包含了每一个用户该标签的拥有情况(有就是1,没有则是0),这样所有用户及其标签构成了一张巨大的二维稀疏矩阵;用户筛选过程就是对矩阵的扫描、‘与或非’操作,最终得到满足条件的结果用户。
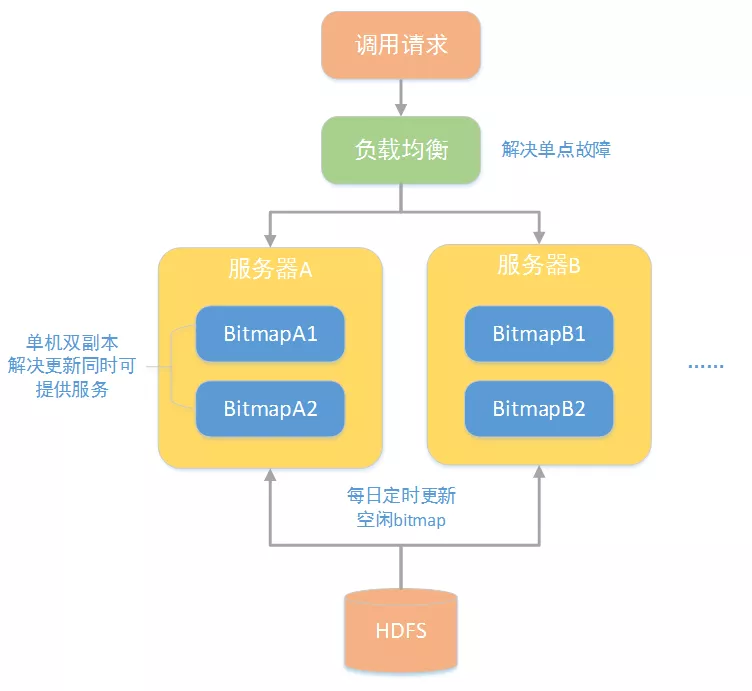
为保证系统的可用性,将底层存储横向扩展为多实例部署和前置负载均衡,解决单点故障问题。同时由数据的更新是离线过程,耗时较长,使用单实例双副本(active-stanby)的方式提供更新时业务的一致性。
架构演进
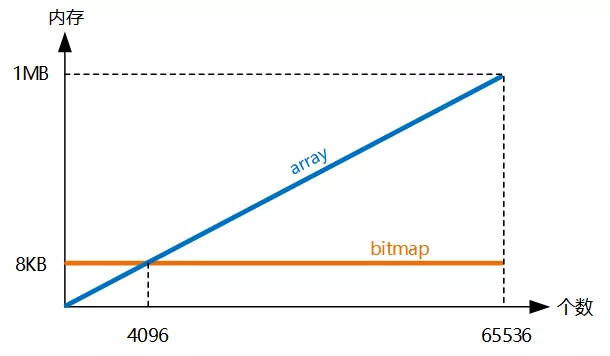
随着用户数量和画像标签增长,原生的Bitmap存储容量也呈线性增长,在保证响应速度的前提下,我们考虑针对Bitmap存储的数据结构进行优化,经过几种方案的对比,我们最终采用了开源的RoaringBitmap实现Bitmap的存储和运算。其原理可简单描述为:使用Array和Bitmap两种容器来存储Bitmap的数据。

可证明:4K以内的数据量采用Array容器的存储空间优于Bitmap。对比我们较为稀疏的业务场景,可将内存大量压缩,同时也可保证逻辑运算的高效。
**
**
**
**
精准推送算法优化
应用背景
结合各个业务线的用户需求,结合用户的特征行为,融合多种机器学习算法,对每位目标用户进行实时精准推送。
机制设计
58用户画像推送系统针对来自不同业务线、不同目标用户群及不同目的的需求,为每一次推送实现“定制化”的服务。
例如从业务角度来看,是否推送一位用户,可以由于以下原因:
-
对于全职招聘中的用户关注那些发布者对我感兴趣
-
浏览二手车的用户可能会在天冷的时候更加有买车的欲望
-
浏览新车的活跃用户对汽车的前沿资讯更加在意
它们在用户画像中分别表现为如下数据中:
-
哪些企业或者雇主浏览过用户的信息
-
二手车浏览用户增加、买卖双方通话量增加、IM微聊的信息增加、App使用频率变高
-
浏览新车页面的用户行为与汽车新闻的浏览行为高度相关
对于一个精准推送的需求,往往除了需要把完整的业务逻辑清晰地转化在数据的表征上,同时还需要可能通过机器去挖掘专家经验系统之外的数据表征,看其与目标用户是否存在某在潜在关系,通常会从很多方面入手,例如:
-
个人基础属性:年龄、性别、收入水平、兴趣爱好
-
行为特征:浏览偏好、活跃程度、通话频率、微聊使用频率、活跃帖子类目
-
网络属性:好友圈、常驻位置等
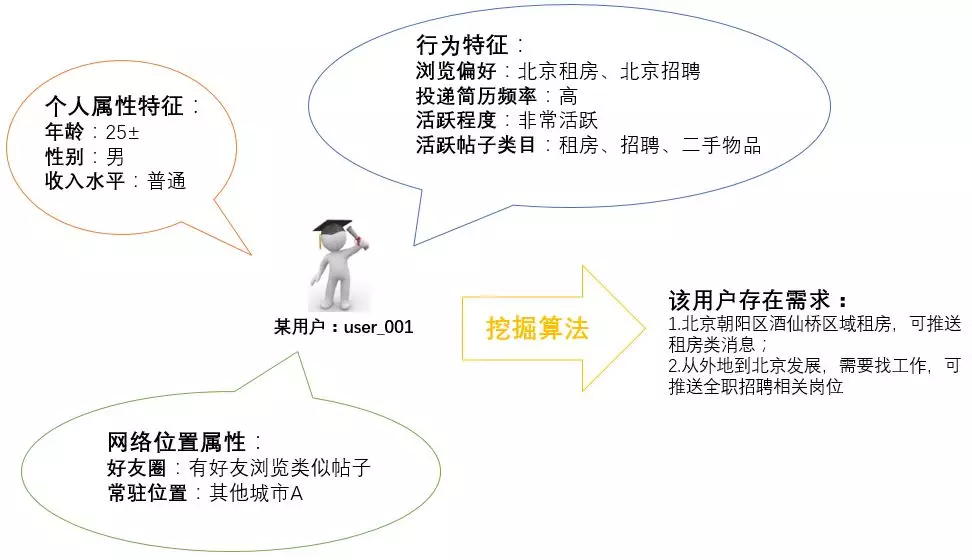
根据众多维度的数据表征的情况,对目标数据进行深度数据挖掘,获取精准推送用户明细。
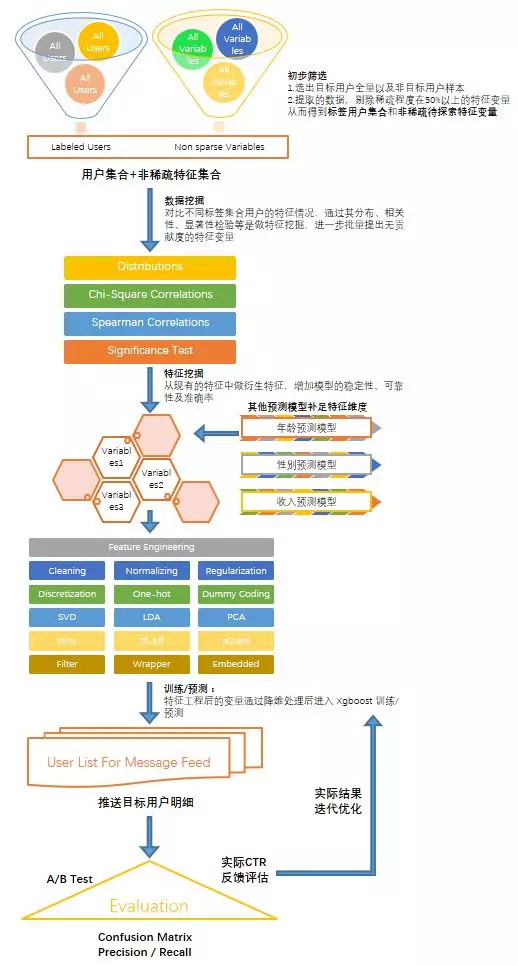
由于需要考虑专家经验系统以外相关的数据表征,因此实际上用到的数据可能多至数千维,数据源融合自多个业务线及多个子公司,用户表征各不相同、数据稀疏、倾斜度高。
为了确保模型的可靠和稳定,在进行特征工程之前,需要初步筛选出较高信息量的数据维度,同时获取带有标注的用户集合。然后分别使用数理统计方法对特征变量进行进一步的增减,例如各种相关性计算,显著性检验等。随后,在剩余的特征中利用画像的基础模型对特征进行补足,例如图中的年龄、性别、收入等信息都与用户的租房偏好、应聘偏好直接相关。随后通过数据的预处理,使用可用特征,根据业务逻辑及多维周期维度构造衍生变脸,然后利用特征工程对数据进行进入模型前的最后处理,例如行为特征与文本特征融合后的处理,连续变量在某一个特定区间段内的离散化等,最后模型进入分类器判别目标用户。
当模型的预测效果在现在使用后,模型会根据每一次线上转化的评估结果进行迭代自优化,逐步提升模型效果。
多维融合
精准推送的三个特性主要表现在三个方面场景化、本地化和实时化。
场景化:
用户、终端以及时间空间同时构成了推送的精准场景,在如今移动互联时代,用户已经不是生活在曾经一人一机的年代里,而是同时使用pc机的web端,浏览器m端,app端等,数据可能分别来自是同城、赶集、转转、到家等,这时我们需要同时把用户在同一场景下来自不同数据源通过IDMapping汇总,把每�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%B2%BE%E5%87%86%E6%8E%A8%E9%80%81%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


