算法工程师必知必会的经典模型系列一模型串讲
章立 美团点评算法工程师
未经许可 禁止转载
这是本系列的第一篇文章,期待大家关注我,跟进后续哦 ~
注意力机制与 Transformer 模型分享
注意力机制
什么是注意力
注意力 的原型很容易理解,例如图片 👇
这张图里的要素很多,对于抱有不同目的或者习惯的人。会有注意到不同的内容。
- 如果我是对色彩比较敏感的人,那么可能 CSDN 的广告是我最先关注的。
- 如果我是想知道注意力模型感兴趣的人,我可能关注在左边这个 Markdown 文本。
等等
用相对抽象的语言来描述的话, 注意力 是对实体的一种被动(长期)或者主动(短期)的重要性评价。
颜色,这个重要性评价就是被动(长期)的,是人类进化过程中对颜色的敏感。
是否是和注意力模型相关,这个重要性评价就是主动(短期)的,是因为今天我们的主题之一就是注意力模型。
如果再进一步用更抽象一些的语言来描述:
如果一个实体i可以由一个d维向量x_i表示,n个实体构成一个矩阵X_{n,d}.
那么注意力可以简单的表示为一个n维的向量\omega_n,\omega _i 表示对实体i的注意力。
那么\omega \cdot X表示什么呢?可知\omega_{1,n} \cdot X_{n,d} = Y_{1,d}。如果这个实体x_i表示的是图像的一层。整个注意力机制相当于卷积神经网络(CNN)中常见的池化方法。如果\omega_i = \frac{1}{n},那么就是平均池化。如果只有最大的x_i对应的\omega _i = 1,其他\omega_j=0。那么就是最大池化。
如果x_i是考试的每门科目,平均池化相当于不偏科型学生,最大池化相当于严重偏科型学生。
这个小节,我们将注意力理解为对某类实体的重要程度,并且与 CNN 中池化建立了关系。
注意力模型的数学描述
一种普遍接受的注意力模型的描述是基于 神经图灵机(Neural Tunning Machine)的语言风格进行说明。
简单的说神经图灵机中有一种类似于搜索的描述语句,来描述一次对存储状态的值进行查询。
硬寻址:基于关键词k进行查询q,从存储状态v中取出对应的状态v_{i_1},v_{i_2},v_{i_3}…
软寻址:基于关键词k进行查询q,对存储状态v中状态进行加权得到w_{i_1}v_{i_1},w_{i_2}v_{i_2},w_{i_3}v_{i_3}…
如果软寻址的权值皆为 0/1,那么软寻址 = 硬寻址。
这里查询q并不是第q次查询,而是形式为q的查询。
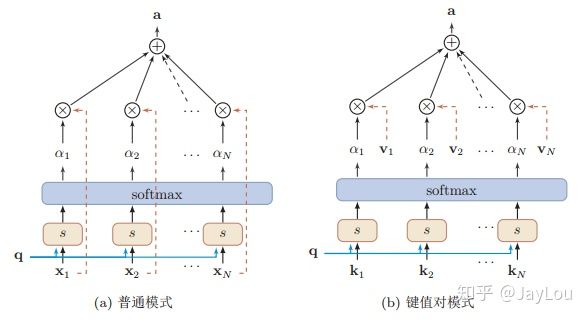
使用硬寻址方法的注意力方法称为 hard attention,使用软寻址方法的注意力方法称为 soft attention.
图上为软寻址的两种描述,其中普通模式可视为键值对的一种特例。
Transfomer 模型
Transformer 模型来源于 Google 2017 年的论文《Attention Is All You Need》
RNN 的问题与 CNN 对 NLP 问题的短板
在自然语言处理领域,循环神经网络(RNN)是常用的一种网络架构。而在计算机视觉领域,卷积神经网络(CNN)是一种更常用的网络架构。由于时间问题不对 RNN 和 CNN 进行详细的描述,而是直接给出结论:
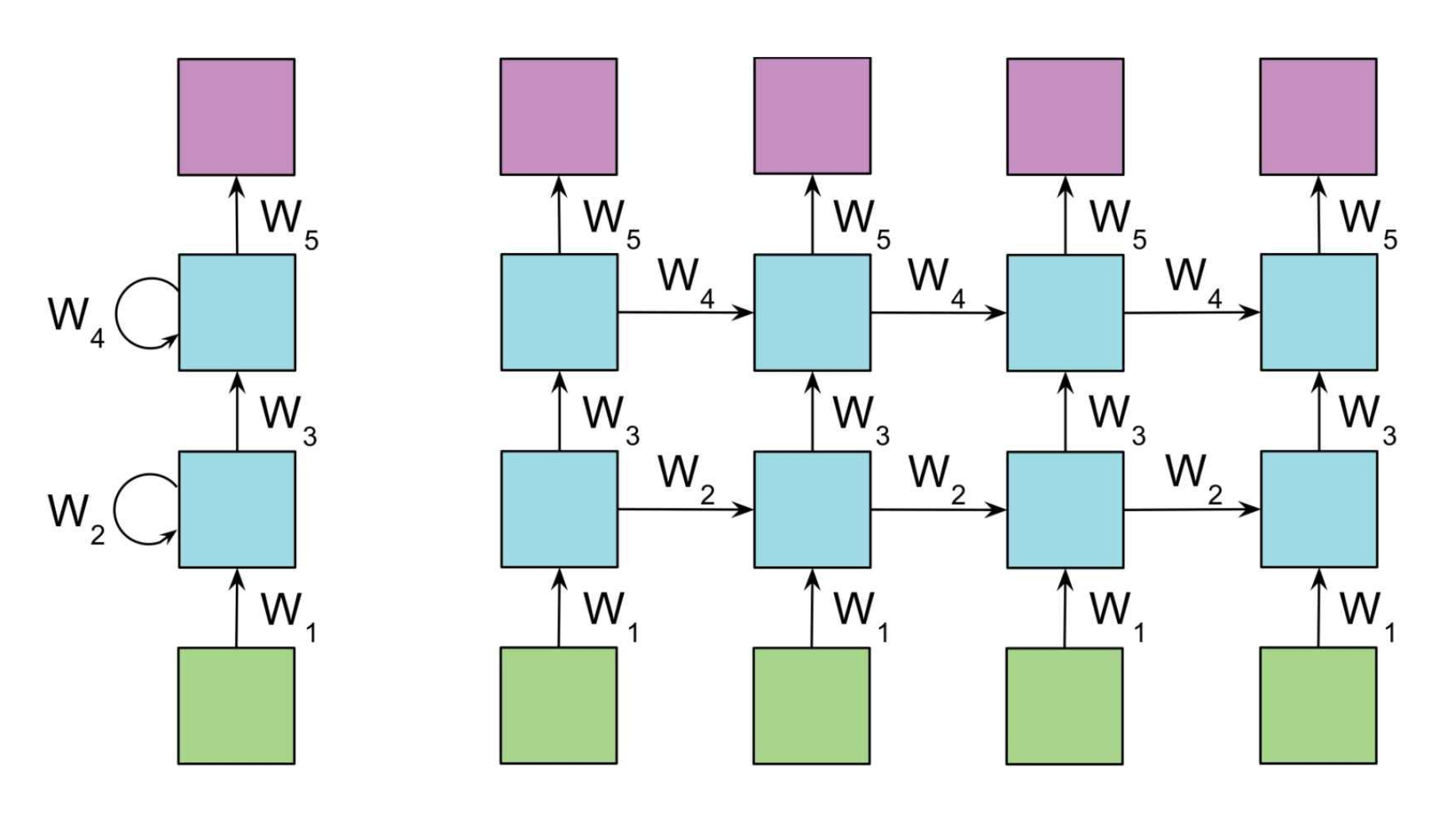
- 传统 RNN 在训练过程中存在梯度消失和梯度爆炸问题,虽然有 LSTM、GNU 等神经单元和 batch normalization、梯度截断等方法能缓解和解决。
- 传统 RNN 由于训练过程中一个神经单元的输入依赖上一个神经单元的输出,无法进行并行化计算
- 由于在类似于 seq2seq 等实际场景中,句法/行文风格等差异,导致不同位置对结果贡献会有差异。但是 RNN 由于是固定权重,需要较大的成本去适应复杂多变的句法和行文风格。
RNN:
那么 RNN 这么多问题,那么我索性不用了。放眼 NN 家族,除了 RNN,就数 CNN 生的靓丽,那么就用 CNN 吧。
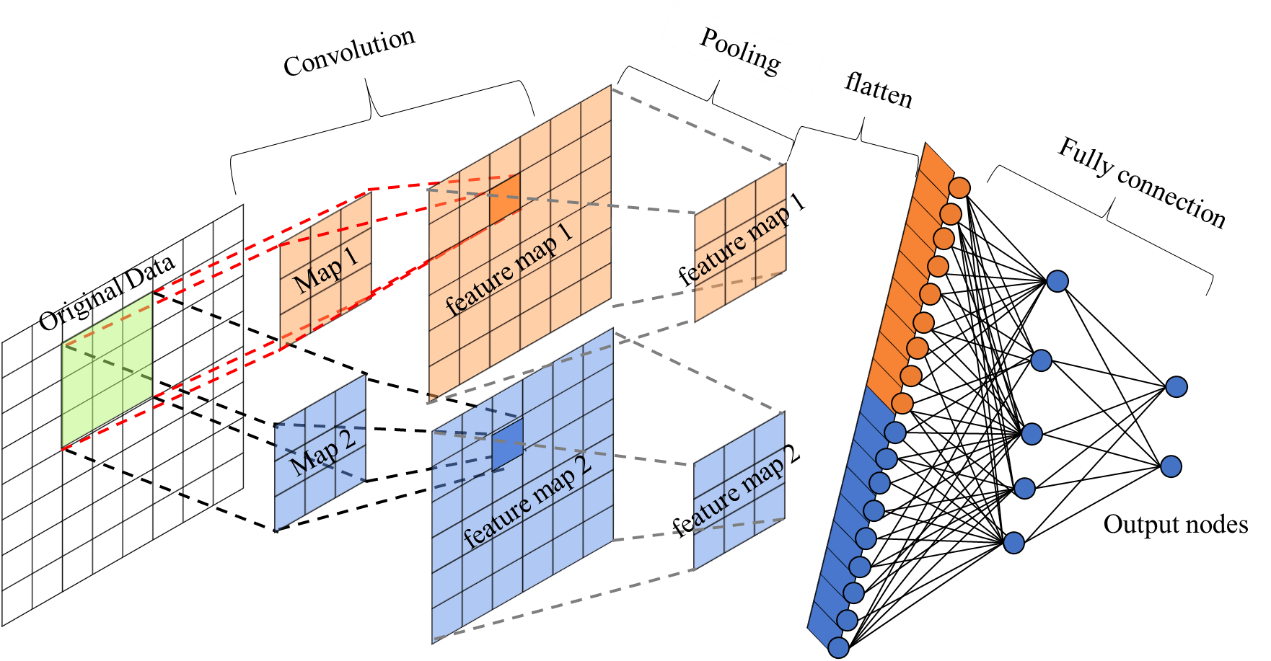
但是 CNN 直接用在 NLP 上最大的问题在于,计算机视觉中主要处理的对象是图像,它有先天的三个特点:
- 图像中不同层(RGB)间相对独立,层间信息往往不会互相影响
- 图像的相邻像素点间自然而然地存在强关联,较远的像素点的信息损失是可以被接受的。
- 颜色编码自然地存在连续性,使得分类边界相对比较平滑,而且空间更加连续,因此线性 kernel 在计算机视觉领域效果很好。
而 NLP 处理的对象是文字,不具备这样的特点:
- 一句话的文字间往往有较为强的相互影响
- 文字之间的影响并不是一定随着距离远而衰减
- 文字的信息本身相对精炼,文字之间轻微的轻重程度也可能会导致两个文字实体差异很大,
基于以上原因,CNN 的 kernel 和池化那样对文本信息造成较大损失,而且即使要用线性 kernel 效果也不一定好。CNN 并不适合直接挪到一般 NLP 场景。
那么是不是如果我们对 CNN 进行一些改造就适合使用在 NLP 问题上呢?Transformer 就是一种改造结果。
Transfomer 原理
如果有一些 CNN 相关的知识,理解 Transformer 应该会更加容易一些。
我们总结一下上一节说过 CNN 与 RNN 在 NLP 上有几个问题:
- CNN 的 kernel 对较远距离的文字造成太多的信息损失
- 线性 kernel 不适用于文字
- 简单池化对信息的损失过大
- CNN 无法把握顺序的概念
- RNN 无法进行并行训练
- RNN 存在潜在的梯度消失和梯度爆炸问题(这个问题其实 Transformer 也没有完全解决,实质上还是依赖一些 tricks 来解决的)
我们来看 Transformer 是怎么解决这些问题的。我们先介绍 Transformer 的架构:
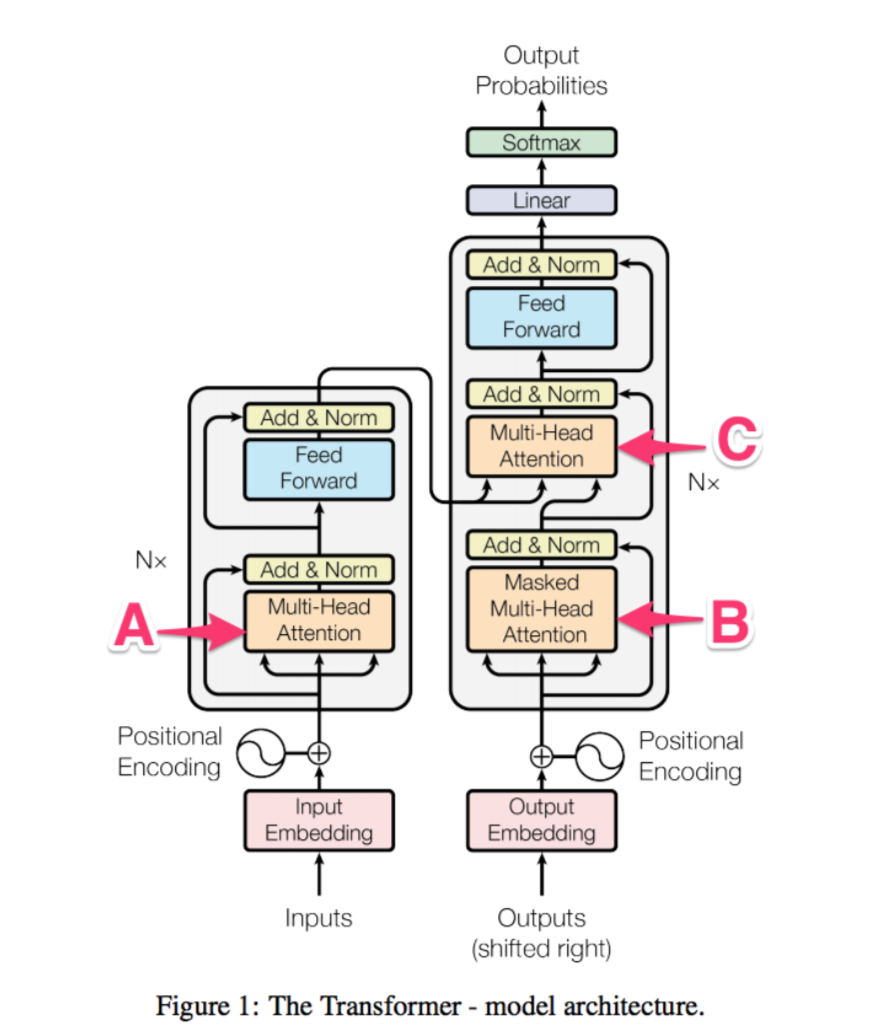
上图是 Transformer 在 Seq2Seq 框架下的一个实现,从结构图上看一般我们把左侧部分称为 Encoder,右侧部分称为 Decoder。对于翻译任务来说这个 Seq2Seq 模型相当于对于长度为N的输入序列(Encoder 输入),与长度为M的已输出结果(Decoder 输入),来预测第M+1位置的输出结果。我们先从下至上介绍 Transformer 网络结构图的各个模块。
Positional Encoding
由于没有了 RNN 那样顺序,所以讲位置作为 embeding 的一部分加入
论文中的方法异常玄学:
PE_{(pos,2i)} = sin(pos/10000^{2i/d_{model}}) \\ PE_{(pos,2i+1)} = cos(pos/10000^{2i/d_{model}})
论文上说和学习出来的 Positional Encoding 差不多,而且更加节约学习成本并且如果出现长度超过训练集的向量,通过学习生成的 Positional Encoding 难以支持。在 BERT 以及一些后续的模型中 Positional Encoding 选择了学习的方式。序列中每个 token 的 embedding 与 position 的 Embedding 相加的向量作为模型的输入。
Multi-Head Attention
模型结构图中存在三个 Multi-Head Attention 单元,这三个单元结构上类似,但是又有些许差异。
Multi-Head Attention 相较于一般的 Attention,差异在于:
- 使用了 Stacked 的多个 Attention 结果,然后 concat。
- 使用 Scaled Dot-Product Attention,我们在下面会详细来说明论文中用到的 Sacled Dot-Product Attention 的结构
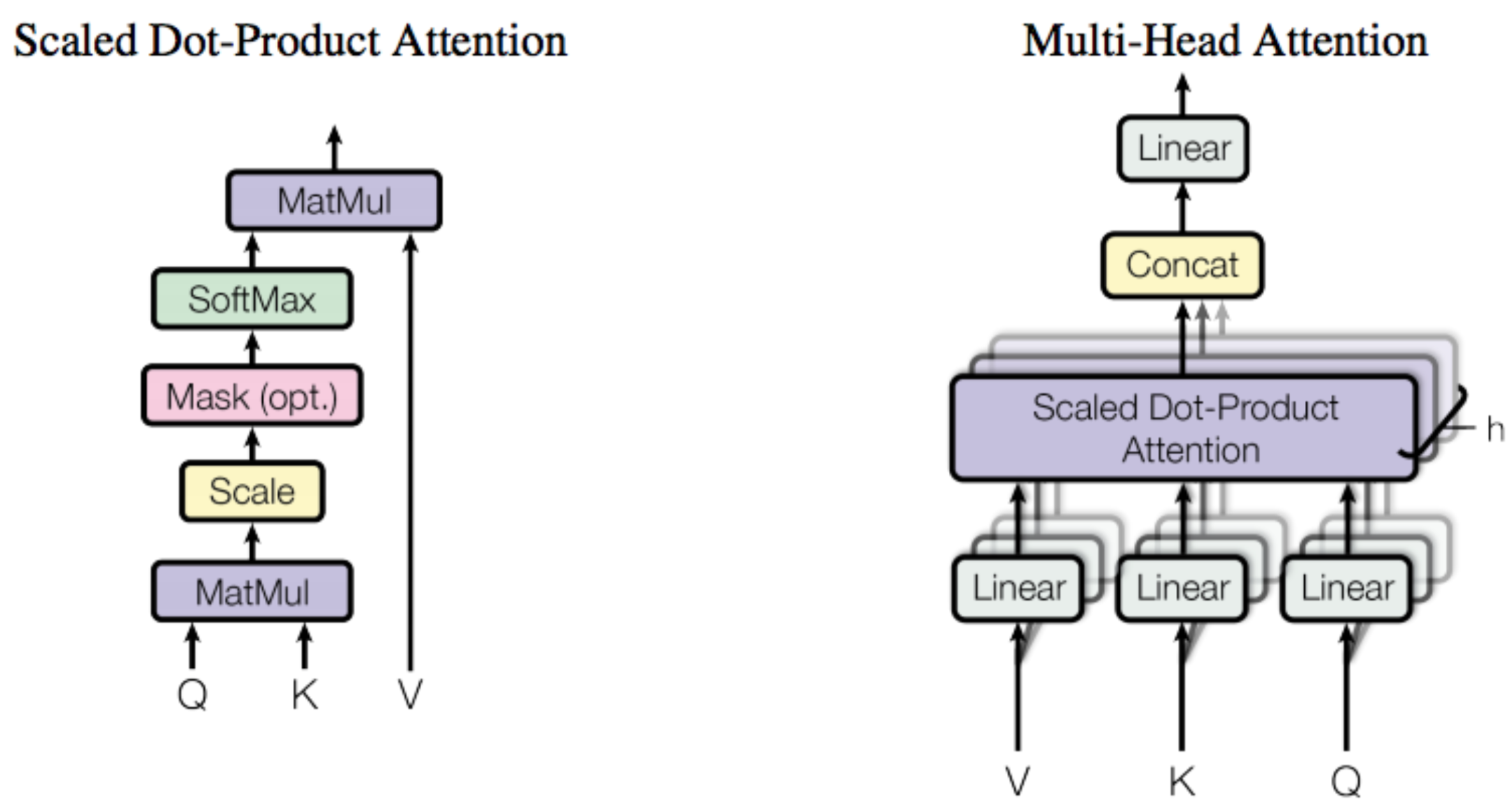
Scaled Dot-Product Attention 三个变量输入(Q、K、V),这里说一下他的含义:
- Q 表示查询上下文,可以理解为一句话中的语境。
- K 表示注意力的查询关键词,token 序列的每一个向量都是一个查询关键词,而 attention 会作用在每一个 token 上。因此为了方便表示一般把K表示为一个max\_seq\_length \times dim的矩阵。dim 是 token 的向量长度,max_seq_length 是 token 序列的最大长度。
- V 存储值,Attention 所提供的就是对不同存储值的权重,最后 Attention 机制的目标是在上下文Q的情况下,对于一个关键词K,对于V的不同分量计算各自的权重,最后以加权和的 embedding 表示关键词K。
相对于一般的 self-attention 可以看到,Scaled Dot-Product Attention 主要是多了 Scale 和 Mask 两个环节,并且输出会将 softmax 的输出与V进行点乘(MatMul)
Scale 单元会对输入矩阵的每个元素除以\sqrt{d_k},d_k是 K 的维度。
Mask 单元会将一部分输入矩阵的元素置为 0,在论文中只有 Decoder 的 Multi-Head Attention 中使用了这个单元,将进入这个单元的矩阵的下半反对角矩阵的值清空,主要是为了防止 Decoder 部分对预测结果发生泄漏。
对于论文中三个 Multi-Head Attention 单元的差异
A:Encoder 的 Multi-Head Attention 中K=V=Q,都是输入序列的 embedding 矩阵。
B:Decoder 中提取 Outputs 序列 Multi-Head Attention。他的Q、K、V都是相同的。但是相比于 A 的 Attention,他多了 Mask 单元来防止 Outputs 序列发生泄漏。
C. Decoder 中将输入序列与 Outputs 序列交叉的部分,所以他的上下文矩阵Q来自上一个 Decoder 的 Multi-Head Attention 单元的输出,K,V来自 encoder 的输出矩阵
Add & Norm
从名称上可以看出来,这个部分由 Add 和 Norm 两个部分构成
Add 部分是 residual connection,输出为x + Sublayer(x)
Norm 部分使用 layer normalization,对同一层的输出进行标准化,【原理基于流形 https://arxiv.org/abs/1607.06450】
Feed Forward——position-wise fully feed-forward network
类似于 CNN 的卷积层
position-wise 我个人的理解是作用在一个 pos 的 embeding 上
Pos1Pos2Pos3dim1x11x21x31dim2x21x22x32dim3x31x23x33Dim4x41X24X33
如果一条长为 3 的序列在进入模型经过 Multi-Head Attention 后,被表达为上述的一个 4*3的矩阵 ,同理对于一个长度为 4 的序列,在进入模型经过 Multi-Head Attention 后,会被表达为一个 $4*4$ 的矩阵
对于每个位置上的向量X_i = \{x\}_{dim},例如对于上表的句子X_1 = (x_{1,1},x_{2,1},x_{3,1},x_{4,1}) 。将下面函数作用于对于每个位置上的向量上 :
FFN(x) = max(0,xW_1+b_1)W_2+b_2
W_1、W_2、b_1、b_2对于每个位置向量是相同,相等于在每个位置上权重共享。其中第一层是 ReLU,第二层是 Linear。最后进入这一个单元的输入为(N,M)的矩阵,输出都是(N,M)的矩阵
Transformer 总结
我们之前说过 CNN 与 RNN 在 NLP 上有几个问题,我们分别看一下 Transformer 如何解决这个问题的:
- CNN 的 kernel 对较远距离的文字造成太多的信息损失:Transformer 采用了 Attention 机制,保留了不同距离的文字信息
- 线性 kernel 不适用于文字:所以在 Feed Forward 中引入了类似于核函数的权重共享,并且使用了 Relu 激活函数而不是线性核
- 简单池化对信息的损失过大:Transformer 不进行池化,采用 Seq2Seq 的结构可以得到每个 token 的表达
- CNN 无法把握顺序的概念:Transformer 通过引入 position encoding 机制来对位置进行编码,从而让模型可以感知到顺序
- RNN 无法进行并行训练:通过 Mask 将后向的输出进行隐藏,可以对每个位置进行并行的计算。
- RNN 存在潜在的梯度消失和梯度爆炸问题:通过 Transformer 中大量使用 Relu 以及 residual connection,保证了梯度消失问题的影响相对较小。对于梯度爆炸通过梯度裁剪可以较好地控制。
官方实现的 Transformer 代码:
[https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/evolved_transformer.py](https://www.
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%AE%97%E6%B3%95%E5%B7%A5%E7%A8%8B%E5%B8%88%E5%BF%85%E7%9F%A5%E5%BF%85%E4%BC%9A%E7%9A%84%E7%BB%8F%E5%85%B8%E6%A8%A1%E5%9E%8B%E7%B3%BB%E5%88%97%E4%B8%80%E6%A8%A1%E5%9E%8B%E4%B8%B2%E8%AE%B2/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


