算法在哈啰顺风车中的实践应用

分享嘉宾:盛小双 哈啰出行 算法专家
编辑整理:Hoh
出品平台:DataFunTalk
导读: 如果科技让出行更美好,可以推动出行的进化,那么AI算法模型的应用,就是其中一个最大的推动力。本次分享的主题为算法在哈啰顺风车中的实践应用,将首先介绍算法同学依托于什么样的算法平台来解决哪些具体的业务场景;其次,介绍匹配推荐引擎,包括引擎的架构,召回和精排模块的演进;再次,介绍交易生态治理算法,包括治理算法的架构和模型的演进;最后,介绍智能营销算法的架构和模型的演进。
01 业务介绍
首先介绍下哈啰的算法平台基础建设,给算法同学在业务中落地算法提供了有力的保障。
1. 平台基建
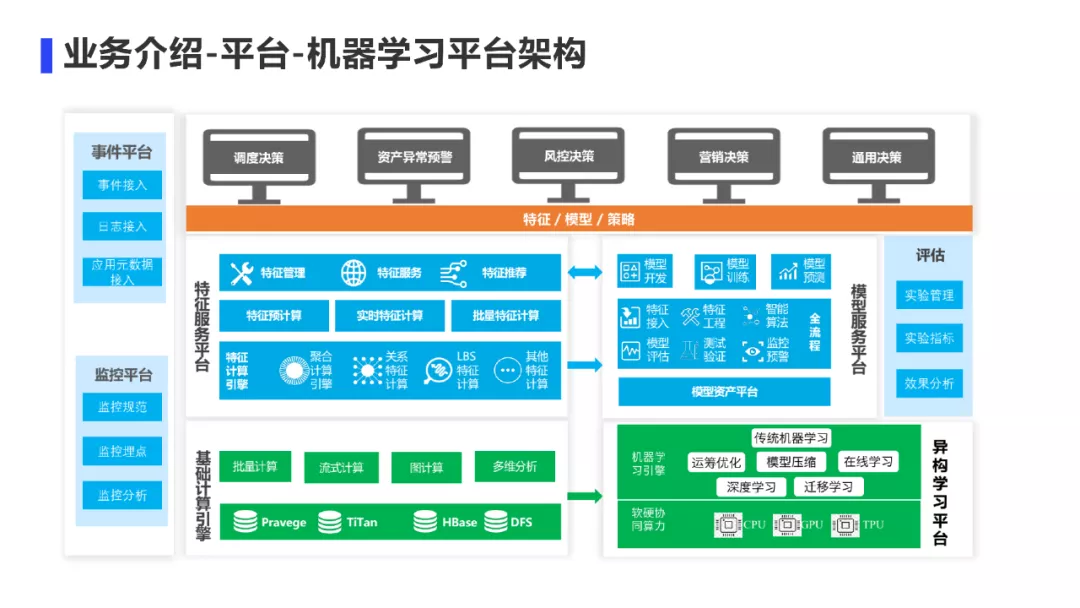
公司的机器学习平台是基于机器学习和深度学习计算框架进行二次开发,提供一站式的服务,为算法同学提供从数据预处理、模型训练、模型评估、模型在线预测的全流程开发和部署支持。为算法同学提供端到端的一站式服务,帮助我们脱离繁琐的工程化开发,把有限的精力聚焦于算法策略的迭代上面。
- 该平台底层依托于Hadoop/Yarn进行资源调度管理,集成了Spark ML、XGBoost、TensorFlow三种机器学习框架,同时支持CPU,GPU异构资源的使用
- 我们的特征服务平台:提供了离线特征能力和实时特征能力,将线下的特征应用到线上,也可以将实时计算的特征推送到线上
- 我们的模型服务平台:管理算法的版本以及算法版本所用的模型、特征和参数,并为机器学习和深度学习模型实时计算提供高可用在线预测服务
- 我们的AB实验平台:通过科学的分流和评估方法,能更快更好地验证算法的效果
其实最开始的时候,我们的特征和模型是跟业务强耦合的,导致每次模型迭代,服务端都要搞发布,迭代效率很低。所以后面我们就把特征和模型全部剥离出来,放到机器学习平台去。
有了机器学习平台的一站式解决方案,算法同学可以方便快速的进行顺风车业务算法的落地。下面介绍一下,顺风车业务算法的构成。
2. 顺风车业务
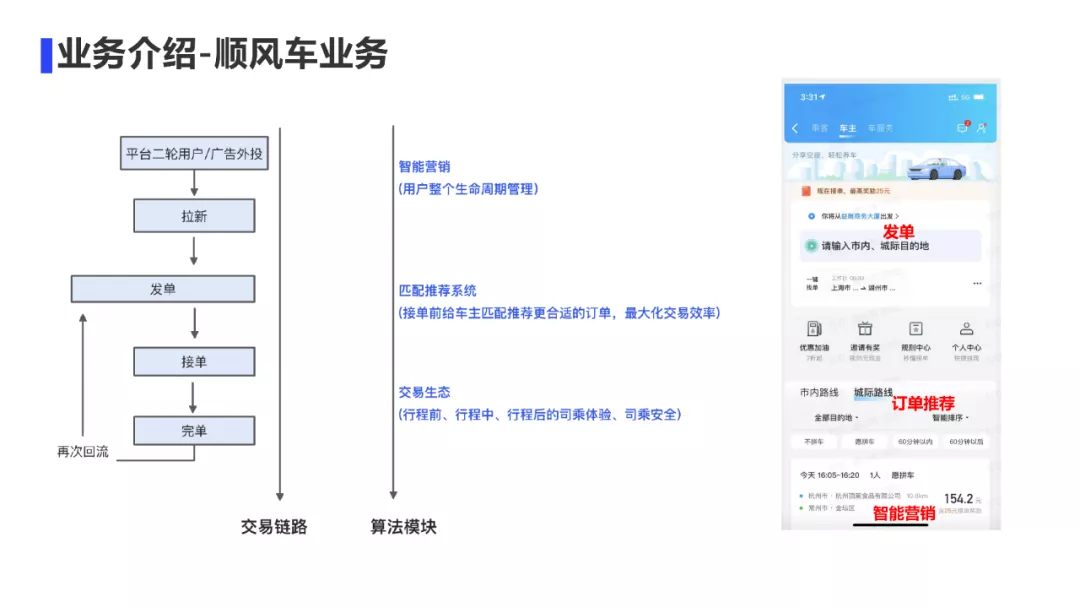
从我们平台的二轮用户转化或者广告外投的渠道通过智能营销算法拉新过来的车主在平台发布订单后,通过我们的匹配推荐系统进行乘客订单的推荐,然后车主接单后进入行程中,我们会有交易生态治理算法来为司乘的体验与安全保驾护航。
所以整个交易链路,涉及3块算法,第一块是匹配推荐引擎,第二块是交易生态治理算法,第三块是智能营销算法。
首先介绍一下我们的匹配推荐引擎。
**02 匹配推荐引擎
此模块主要分3个部分来讲,从架构到召回模块演进到精排模块演进。
1. 架构
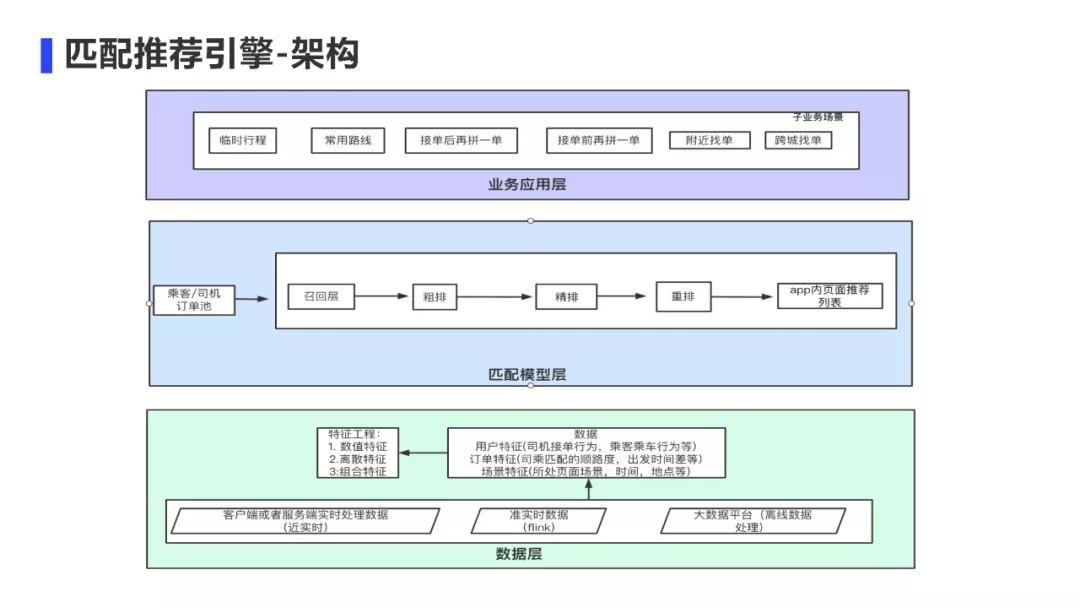
匹配推荐引擎的目标是最大化交易效率的同时能够兼顾长期留存。
我们首先介绍一下推荐引擎的架构。从数据层来讲,数据来自于3个方面,一个是客户端传下来的实时上下文数据,比如乘客订单的价格、起点距离等上下文特征。一个是flink任务计算的准实时数据,比如同一笔乘客订单被多少司机看到,所有这些看到的司机中跟这个乘客订单的平均顺路度,起点距离等。一个是离线计算的宽表特征,比如对于车主接单行为的画像特征。
从数据层到模型匹配层,模型层主要分为召回层、粗排、精排、重排4个阶段。
从模型层到业务层,针对每个子场景都定制一套自己的模型,我们的顺风车从2个大场景来说,分为车主侧和乘客侧;而车主侧又分为临时行程、常用路线、附近找单、跨城找单等接单渠道。
接下来主要讲一下召回模块和精排模块的演进。
2. 召回模块
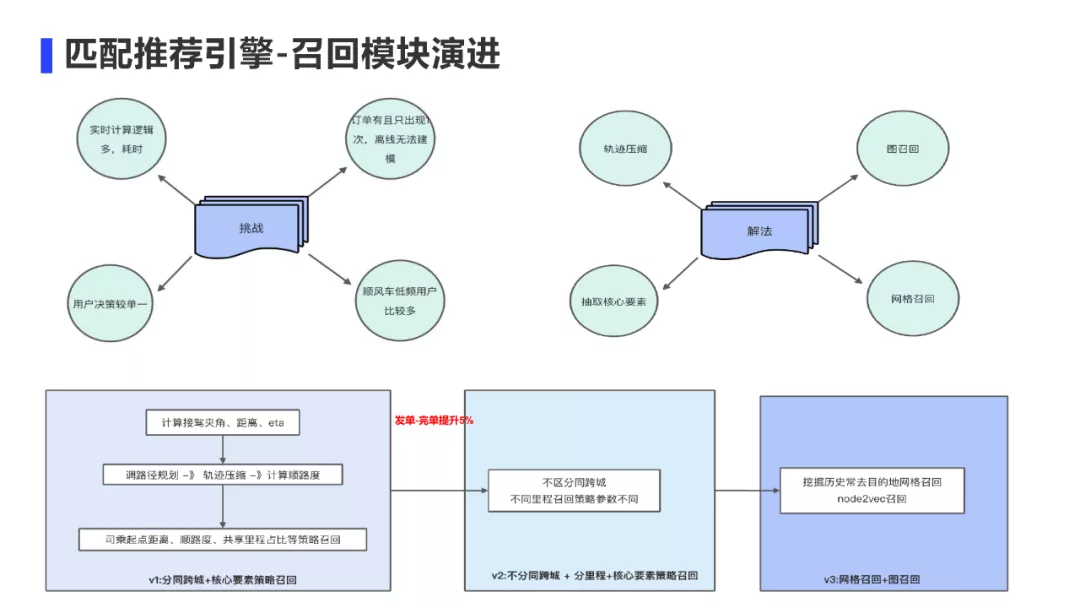
召回模块面临4个挑战:
第1个挑战是需要实时计算的逻辑太多,非常耗时。我们是基于位置的服务,当车主发单后,需要外扩经纬度形成矩形框后,在矩形框内进行路径规划、顺路度等计算逻辑,这些都是需要实时计算的。特别是当跨城订单里程很长的时候,轨迹点特别多,耗时更加严重。
针对这个问题,我们的一个解法是添加了轨迹压缩算法,轨迹压缩率达到80%,一定程度上降低了计算的压力。
第2个挑战是订单有且只出现一次,离线无法直接建模,生产embeding。
电商的召回模型统统失效了,因为订单是昙花一现的,没法在车主完单序列中反复出现。所以必须想一种办法,来对问题进行转化。
我们的解法是通过一定编码转化后通过图召回来解决,具体细节后面会讲。
第3个挑战是用户决策单一,车主总是希望离它近,价格高,更顺路,出发时间匹配的订单进行决策。我们的解法是在召回侧就将这些核心要素抽取出来作为召回链路的补充
第4个挑战是顺风车低频用户比较多。对于个人来说,低频,但是对于一个网格里面的车主来说,就会变得不低频。所以我们解法是挖掘历史目的地进行网格召回。
我们召回模块的V1版本从大方向是区分同跨城订单+核心策略召回;V2版本是不分同跨城+分里程+核心要素召回,召回到了更多订单,改变了供需关系,发单到完单提升5%;V3版本补充了网格召回 + 图召回。
下面着重讲一下,我们是怎么转化数据来做图召回的。
图召回:
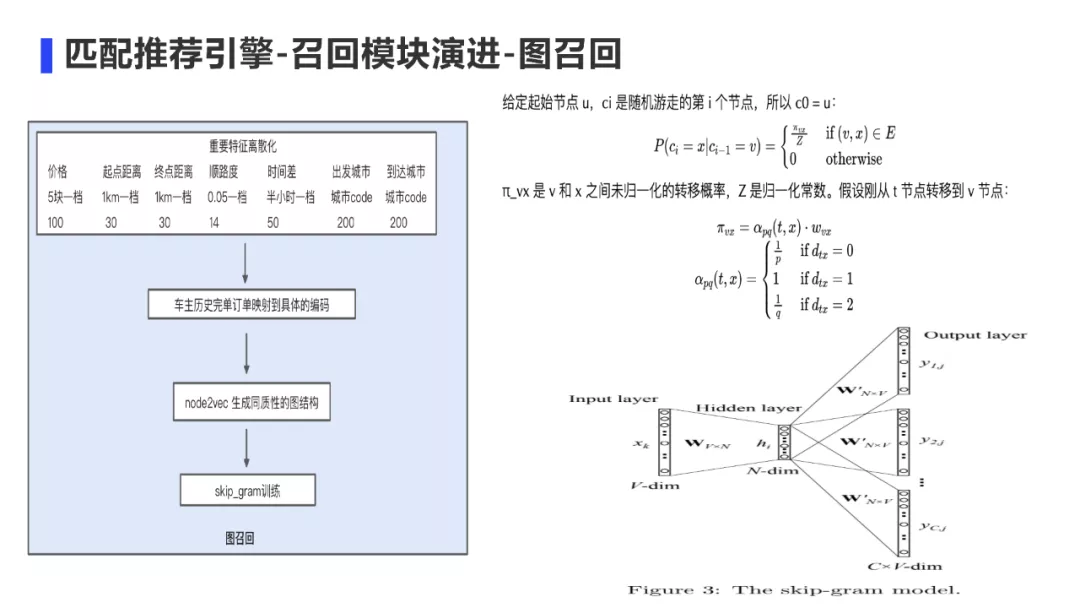
首先是对重要特征离散化之后,对每一笔订单进行编码。比如核心要素价格按照5块钱分桶,顺路度按照0.01分桶,起点距离和终点距离按照1km分桶等。最终分桶后每笔订单编码为14位的映射码。这样在车主完单序列中相似的订单就可以反复出现了。这种编码的好处是近似订单基本等价于一个编码,就类似于电商中的一个商品了。那此时就可以使用电商里面的embeding算法了。
编码完成后对车主历史完单序列映射到具体编码。
然后通过node2vec来生成同质性的图结构,转移概率的公式直接用的论文的,只不过这里有个比较巧的方式是,为了生成同质性的图结构,此时远离参数q要设置一个比较小的值来使得游走的网络结构具有同质性。
生成好的编码序列,可以使用skip-gram的方式来训练,同时通过负采样来加速模型的训练速度。
3. 精排模块
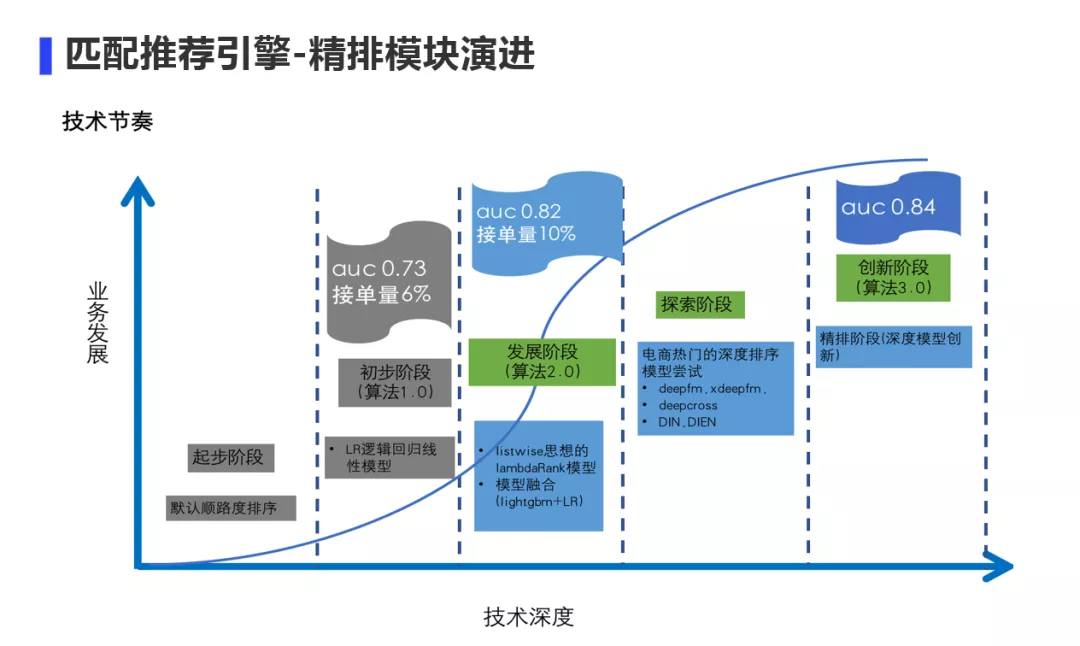
下面讲一下精排模型的迭代思路:
最开始业务冷启动上线时,直接按照顺路度排序。算法1.0是采用逻辑回归上线,AB实验接单量提升6%,效果不错。算法2.0部分场景使用pointwise 框架用lightgbm + LR算法,接单量相比1.0进一步提升5%;部分场景使用listwise框架通过将文档排序的思想迁移过来,比如点击得1分,接单得2分,完单得3分,采用lambdaRank模型排序,接单量相比1.0提升10%。此后我们开始探索深度模型,尝试了电商的精排模型,比如deepfm,xdeepfm,DIN,DIEN等,离线验证auc并没有2.0版本效果好。
我们开始分析为何电商模型在出行行业并没有好的表现:电商场景亿级别的离散稀疏特征,顺风车场景则连续特征居多。所以,关键点在于电商的离散特征很多,embedding技术能发现更多特征的隐式交叉。而在顺风车场景,连续特征非常多,如果我们能找到一种方式把连续特征转化为离散特征,那特征交叉会更有效。
所以我们的算法3.0是这样一个模型:
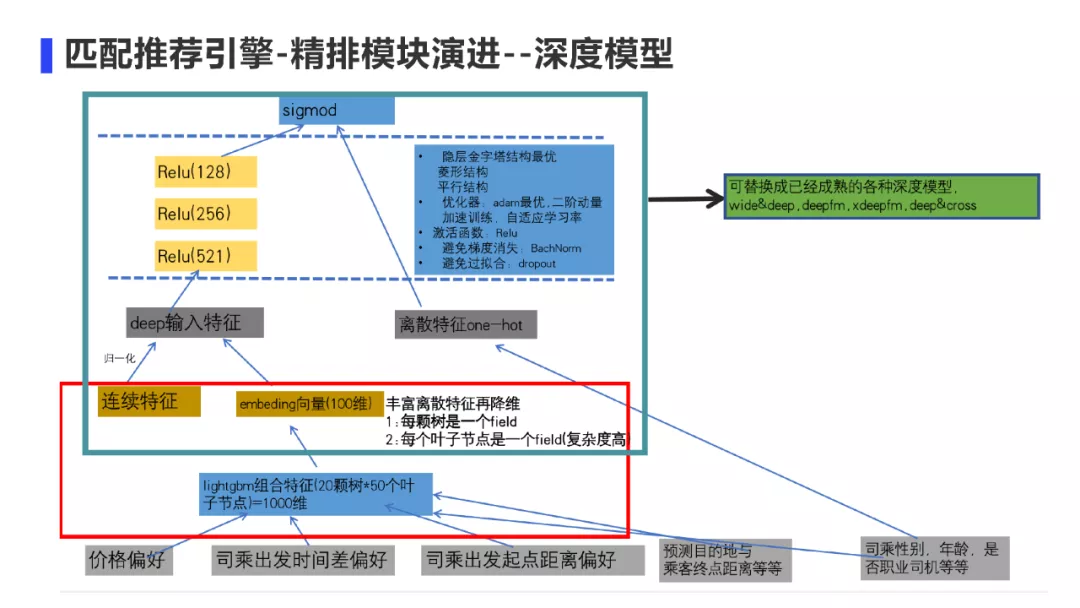
- 将连续特征灌入lightgbm后生成20颗树*50个叶子节点的1000维叶子编码的离散特征,达到升维的目的;然后再通过embedding达到降维的目的。
- 然后将原始的连续特征归一化之后、原生的离散特征、emdeding向量一起喂入金子塔结构的神经网络中。可以通过dropout,batchnorm来避免过拟合、梯度消失的问题
- 将神经网络的最后隐层的输出与最原生的离散特征一同进入sigmod函数中,来增加模型记忆能力。
其实这里面的深度模型结构可以替换成已经成熟的各种深度模型,核心逻辑是如何处理连续特征,有利于深度模型进行更有效的特征交叉。因为如果一个连续特征只占一个bit位,在神经网络的特征交叉中不能充分被表达。
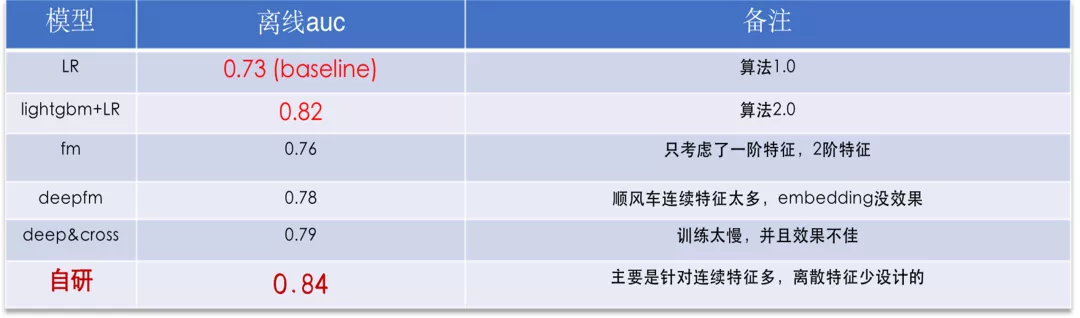
这幅图是当时离线测试的结果,可以看到自研模型的离线auc有2个点的百分位提升。
03 交易生态治理算法
交易生态模块,目标是保证车主在行程前、行程中、行程后的履约体验和行程安全。此模块包含4个部分,交易链路、架构,模型演进和场景举例。
1. 链路
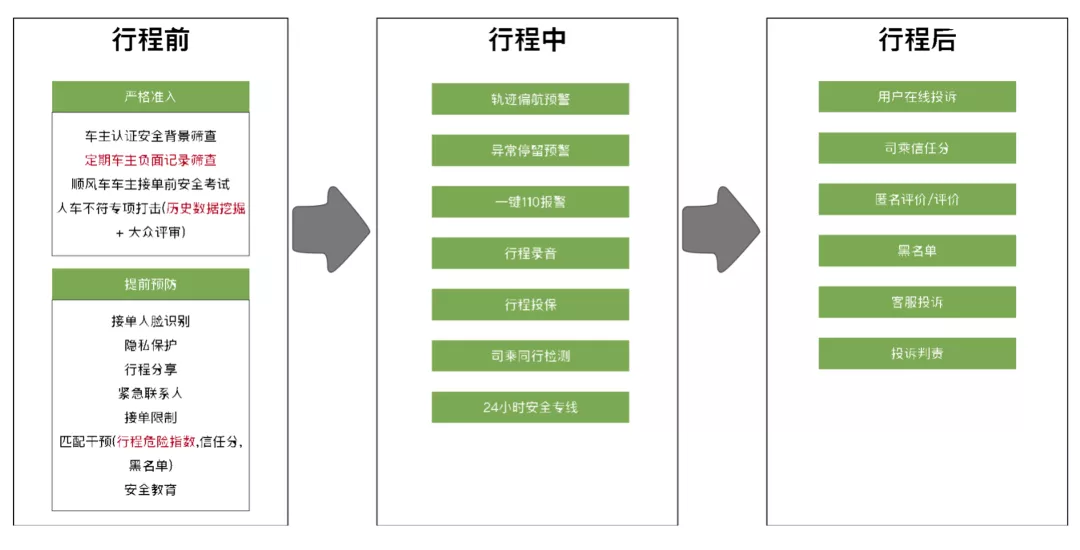
在行程前我们会预测一笔交易发生取消、投诉、或者恶性事件的概率来做匹配干预,差司机和挑剔乘客避免碰到一起引起不舒服的体验。同时在行程前我们会根据历史数据预测车主或者乘客可能会有哪种不好的行为比如线下交易,绕路接人等,在接单前对疑似用户进行教育与引导。
在行程中,我们会通过算法进行轨迹偏航实时检测、异常停留的实时检测等不同手段的监测算法,保护司乘的安全。
在行程后,我们通过判责算法来保证司乘的合法权益。
2. 架构
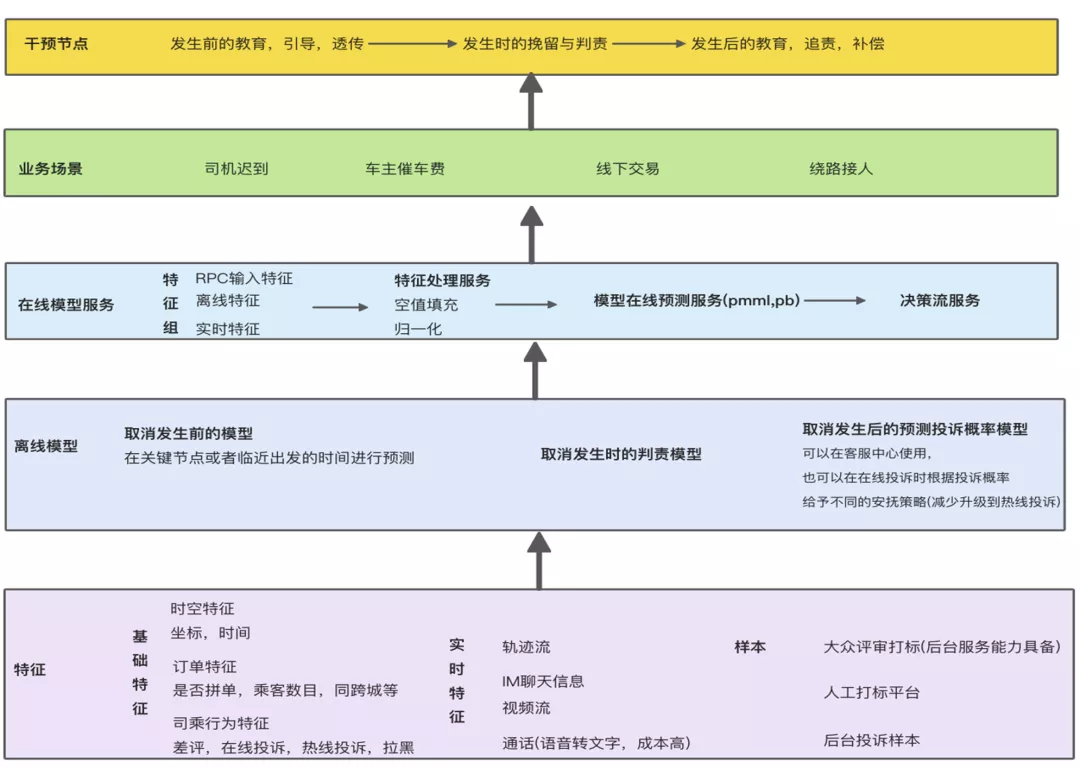
在交易生态治理算法的特征一部分来自于基础特征,包括时空特征(比如订单坐标,时间等)、订单特征(是否拼单,乘客数目,是否同跨城等)、以及离线的司乘行为特征。另外一部分来自于实时特征,比如实时的轨迹流、IM聊天信息、通话等。
而样本是我们比较头痛的一部分,样本需要人工打标,耗费人力。我们这边是通过大众评审和后台投诉样本来获取一些用户标记给我们的正样本。
有了特征和样本后,我们可以离线训练模型。这个模型也是在行程前、行程中、行程后根据不同的场景进行定制化开发。然后将模型通过机器学习平台部署和发布到线上去,来让算法服务于每个环节的履约体验。
交易生态的治理算法中,因为正样本非常珍贵,所以我们这边的模型演进也面临着一些挑战:
3. 模型演进
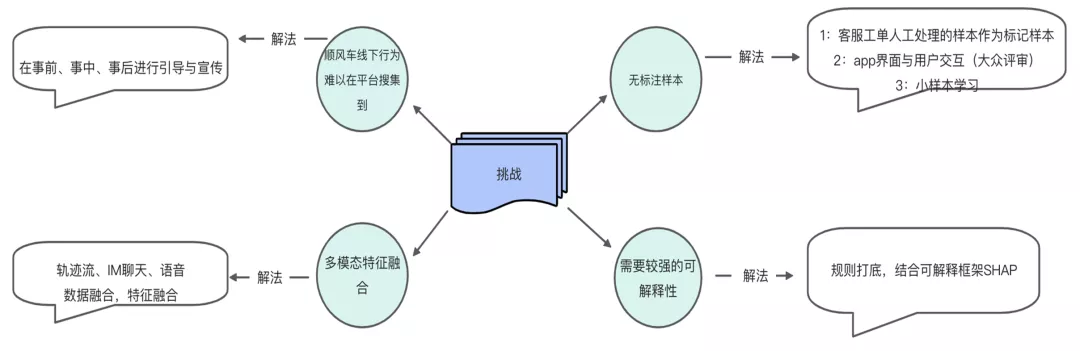
首先第一个挑战是,顺风车线下行为难以在平台搜集到,比如轨迹流的获取,乘客一般上车后就不再打开app,导致轨迹不能上报。那就需要针对不同的场景进行在合适的节点触发引导与宣传。
第二个挑战是,没有标记样本。这边通过3种方式来解决,第一是客服工单人工处理的样本作为标记样本;第二是大众评审,就是app界面发送问题,让用户来打标回答,目前应答率在30%左右。第三个是通过小样本学习的方式来扩充前两个手段的样本量。比如对于使用模型预测概率比较高的样本可直接填充为正样本,来增加正样本数量。
第三个挑战是:特征的来源比较多,有轨迹流,有IM聊天信息,语音等。这里我们通过多模态特征融合来解决这个问题。
对于同一任务,能够应用多种模态的数据,可以做出更鲁棒的预测并且模态之间可能会存在互补的信息。我们当前的融合还处于比较早期的方法,是在提取了各模态的特征后,进行融合,利用了每个模态低水平特征之间的相关性和相互作用,使用单一模型进行训练,上线复杂性和性能都可控。
第四个挑战是:算法需要较强的可解释性,增加说服力。因为我们这边很多后台的计算逻辑需要透传给用户,引导用户朝着好的方向去走。所以算法的输出需要很强的可解释性,不然没法引导用户的具体行为。我们通过模型来提炼出一些规则,我们这边是规则打底,同时结合可解释框架SHAP来分析每个特征对结果的贡献。
下面我们看一个轨迹偏航算法的迭代过程,来了解交易生态的模型迭代:
4. 具体场景轨迹偏航
顺风车行程过程中对可能出现异常的行程进行提前预警,这里面面临的挑战:
- 司机不按照导航走,增加了偏航的难度:由于动态事件,比如封闭,施工,事故等造成车主不按导航走
- 传统的轨迹偏航算法不适合我们目前的业务场景:我们业务是容许一定范围的偏航
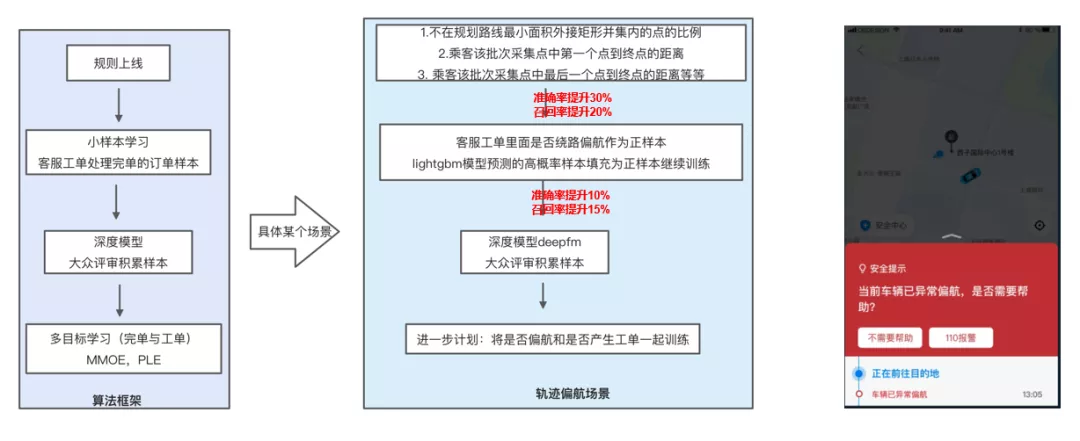
v1版本我们通过计算路线规划内,乘客与车主上报的轨迹批次中,当前批次与上一个批次,方向夹角,距离等的变化,计算一个偏航得分,通过这种方式上线后,在app端内开一定的小流量当处于偏航预警时,push用户给一个反馈。这样我们就有了一定的样本积累,方便后续的模型迭代。
v2版本我们通过将v1版本的用户打标样本和客服工单处理的偏航样本作为正样本,通过lightgbm进行小样本学习。
v3版本在前两个版本的积累下,可以开更多的流量通过大众评审用户打标有更多的样本后,进入深度模型的训练。
在模型迭代上,我们下一步的思路是将多目标训练融合进来,比如将是否偏航和是否产生工单一起训练,提升模型的准确率与召回率。
下面讲最后一个模块,智能营销:
04 智能营销
这一部分主要包含4个部分,营销的架构,用户运营的生命周期,模型的演进,uplift模型。
1. 架构
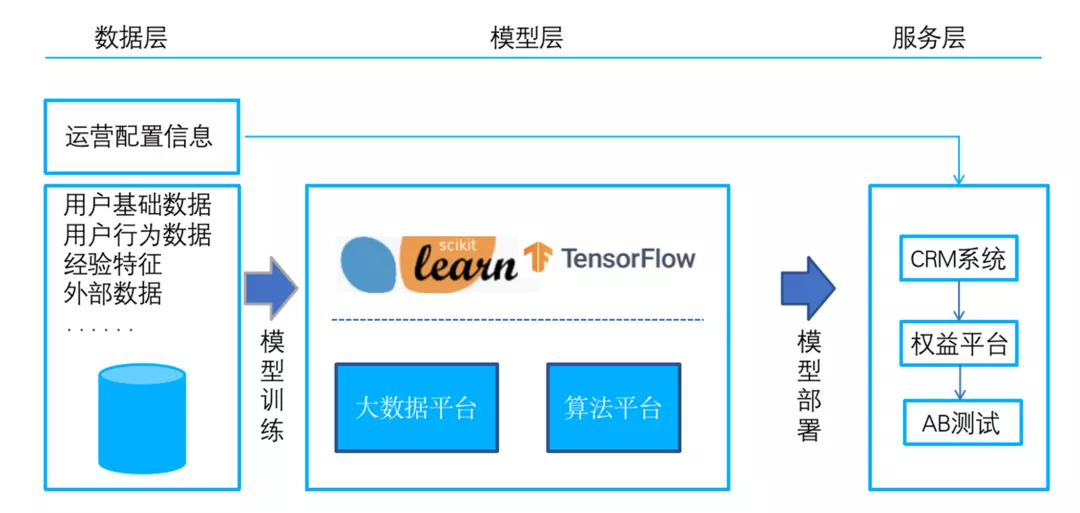
从数据层来说,营销用到的数据主要是用户的基础画像数据,用户的行为特征,以及最近在我们平台的浏览点击行为特征。通过这些特征,我们离线训练机器学习或者深度模型后进而在线部署模型。然后通过CRM平台给不同的用户发放不同的权益。
2. 用户运营周期
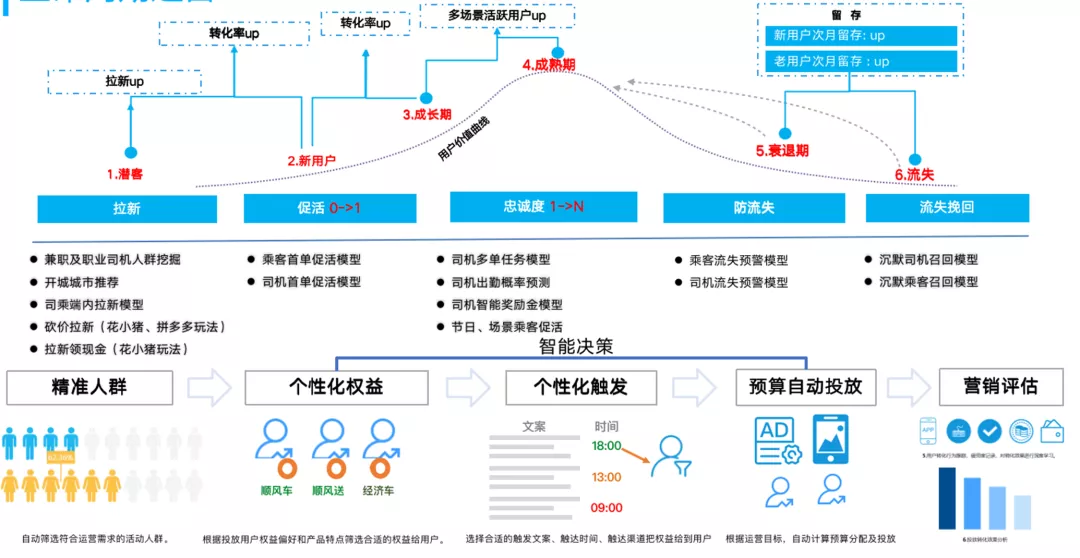
对于平台的用户来说,一般都会经历拉新,促活,防流失,召回挽留等阶段。对于每个阶段来说,我们希望有对应的营销算法和触达手段来激发用户在平台的活跃度与忠诚度,同时也能提升公司的钱效,用好每一笔钱。
这里面涉及3个问题,第1个问题是:给什么样的人发券,即圈人阶段;第2个问题是:圈的人给什么样的权益,比如是5块钱还是10块钱;第3个问题是:通过什么样的文案来触达用户,这里面就涉及智能文案的问题。
接下来主要讲一下前两个问题的解法。因为智能文案是专门有一个团队做成平台化来提供给整个公司的业务线来使用。
3. uplift模型
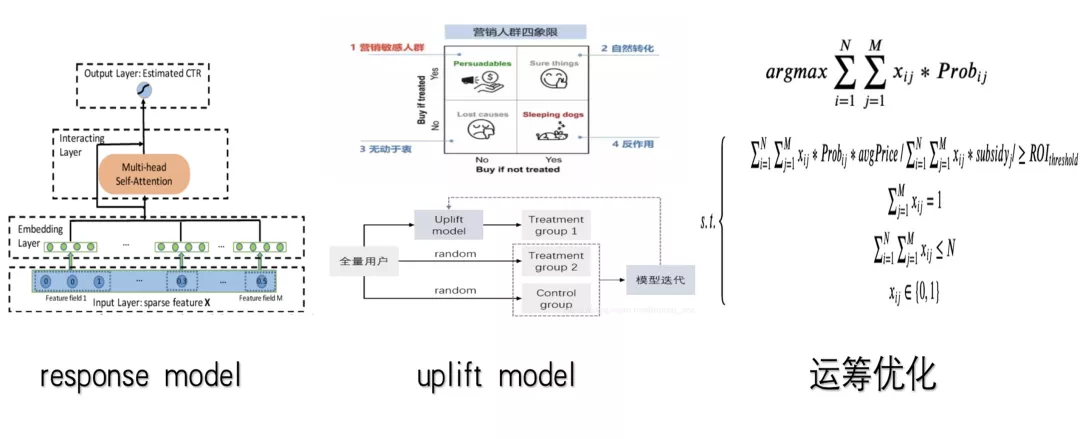
我们最开始的v1版本是从response model开始。去预测用户的出行概率,然后根据出行概率来制定不同的发券策略。这里面会出现自然转化的用户也发放了优惠券,导致钱效不高。
其实对于用户来说,主要分为4大类,第一类是营销敏感的人群,这类人是下单犹豫不决,需要券来刺激一把。第二类是自然转化的用户,不管发没发券,这个人第二天都是有出行需要的。第三类是无动于衷,发不发券都没反应,第4类是发券可能会起反作用,比如券可能是站内push的方式来发送,用户可能觉得太烦了,直接app关闭推送功能。这4类人中我们要抓住的就是第一类人,营销活动的重点人群。
所以v2版本,我们通过v1版本发券积累的数据,来尝试了uplift增益模型,对发券和不发券对用户带来的增量进行建模,然后根据这个增量来实施发券策略。
这里面有个缺点是,发券的金额仍然没有做到用模型cover住,钱效仍然不是很高。
所以v3版本,我们通过预测不同券的核销概率,与使用不同券的增益值,来通过运筹优化的问题解决券金额发放千人千面的问题。
比如x_{ij} 代表第i个用户是否发放第j种券,那约束条件是:每个用户至多发一种劵,以及所有用户的发券总和不能超过实际预算,优化目标可以是所有用户的增益值最大,也可以是gmv最大或者roi最大等
运筹优化的求解主要是整数规划,整数规划目前采用谷歌的ortools来求解。但是优化器当求解参数上千万时,性能就出问题了,要算十个小时左右,这是不能接受的。目前的解决方案是分而治之,通过分城市来求解优化器,因为每个城市间的用户相对来说是相互独立的,互不干扰。
接下来我们主要讲一下uplift模型的3种范式。

首先S-Learner就是single-learner,把对照组和实验组放在一起建模,只是把干预相关的特征作为特征加到模型中去训练,本质还是对response进行拟合,所以对于因果效应并没有很好地学到。

而T-Learner就是two-learner,是用对照组和实验组分别建模得到两个模型,对每个样本计算两个模型的预测值之差作为HTE(异质因果效应)。两个模型误差累计比较大,因为对照组的模型无法学到实验组的pattern,实验组的模型也无法用到对照组的数据。两个模型完全隔离,也就导致两个模型可能各自有各自的偏差,从而导致预测产生较大的误差。

而x-learner就是交叉的意思,是融合了S-Learner,T-Learner。
首先分别对对照组和实验组进行建模得到两个模型,然后把对照组放进实验组模型预测,实验组放进对照组模型预测,预测值和实际值的差作为异质因果效应的近似。这一块跟T-Learner是一样的。
然后把获取到的异质因果效应D1,D0作为训练目标,再训练两个模型,
最后把这两个模型加权求和就是uplift值。
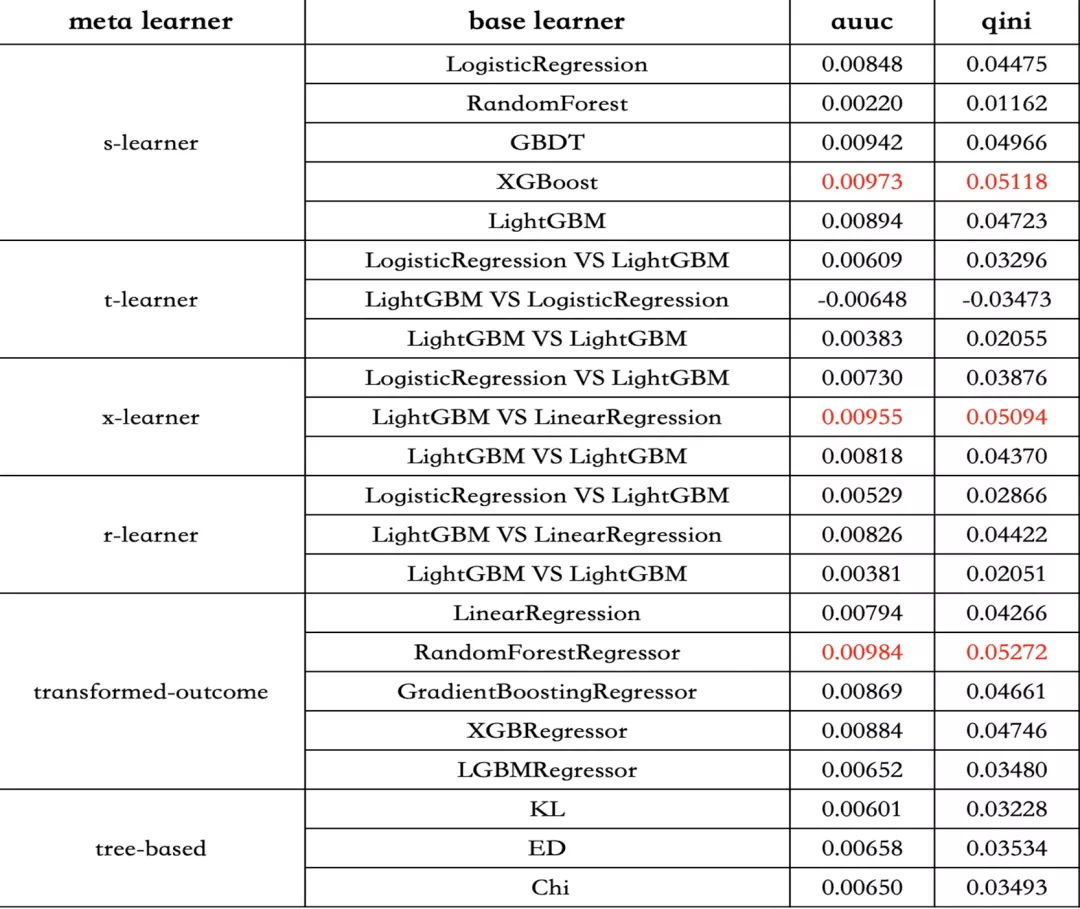
其实uplift模型除了meta-learning的模式外,还有tree-based,nn-based。
与 meta-learner 不同的是,uplift model 下的树模型通过对增量直接建模,对特征点进行分裂, 将 X 划分到一个又一个 subspace 中,那划分准则与传统的决策树信息熵或者基尼系数不一样,这边主要是采用分布散度或者CTS分裂准则。
nn-based我们还没有尝试,他是将propensity score估计即倾向性得分和uplift score估计合并到一个网络实现。
从图中我们可以看到x-leaner的离线效果更好,auuc和gini 值都表现更好。同时从车主促活场景来看,确实比较更优异。所以在我们的营销场景,uplift增益模型使用的是x-leaner。
我们当前这一套uplift + 运筹优化的框架,相比之前的的res
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%AE%97%E6%B3%95%E5%9C%A8%E5%93%88%E5%95%B0%E9%A1%BA%E9%A3%8E%E8%BD%A6%E4%B8%AD%E7%9A%84%E5%AE%9E%E8%B7%B5%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


