程序员必知必会的零拷贝技术
写在前面
本篇文章我们学习Linux IO中的零拷贝技术,最后的参考链接中介绍的非常好,大家都可以看一下
传统IO过程
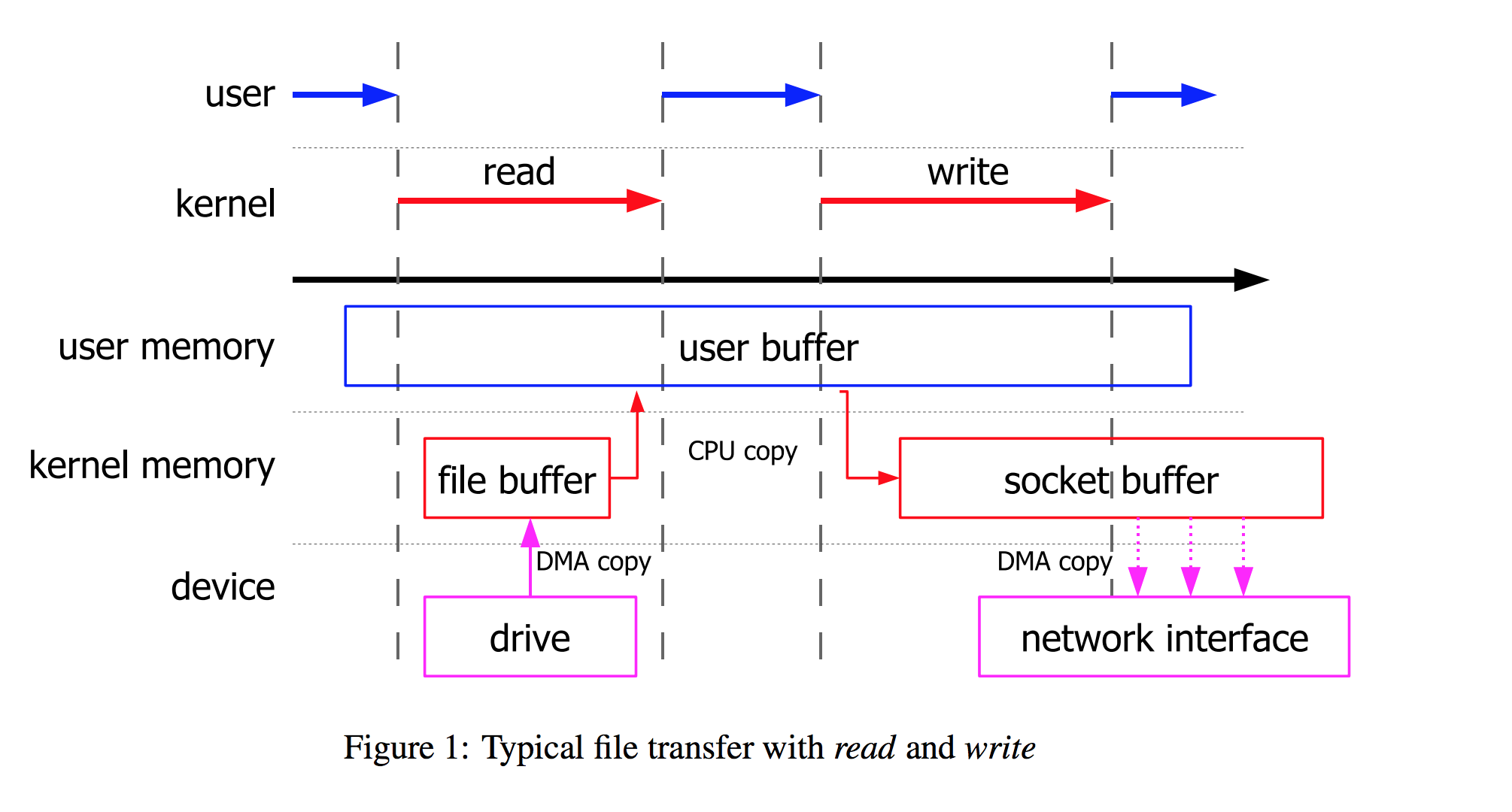
考虑这样一个过程:我们从磁盘中读取一个文件数据,然后将数据通过网络传输到另一个机器。对用户来说可能就是简单的理解为两步操作。
File.read(fileDesc, buf, len);
Socket.send(socket, buf, len);
但是,如果我们看传输中涉及的内核部分的内部工作原理,我们将看到
即使是使用DMA传输的硬件支持,这种方法也效率很低。首先,内核将使用DMA将磁盘中的数据加载到其自己的内核缓冲区中,除非在先前访问同一文件之后,该数据仍被缓存在内核缓冲区中。这样传输不需要太多的CPU工作,CPU只需要进行缓冲区管理和DMA创建和处理。Linux 操作系统会根据 read() 系统调用指定的应用程序地址空间的地址,把这块数据存放到请求这块数据的应用程序的地址空间中去,在接下来的处理过程中,操作系统需要将数据再一次从用户应用程序地址空间的缓冲区拷贝到与网络堆栈相关的内核缓冲区中去,这个过程也是需要占用 CPU 的。数据拷贝操作结束以后,数据会被打包,然后发送到网络接口卡上去。在数据传输的过程中,应用程序可以先返回进而执行其他的操作。之后,在调用 write() 系统调用的时候,用户应用程序缓冲区中的数据内容可以被安全的丢弃或者更改,因为操作系统已经在内核缓冲区中保留了一份数据拷贝,当数据被成功传送到硬件上之后,这份数据拷贝就可以被丢弃。
所以我们会发现这个过程涉及到了3次上下文切换,和4次数据拷贝的过程:
利用mmap()
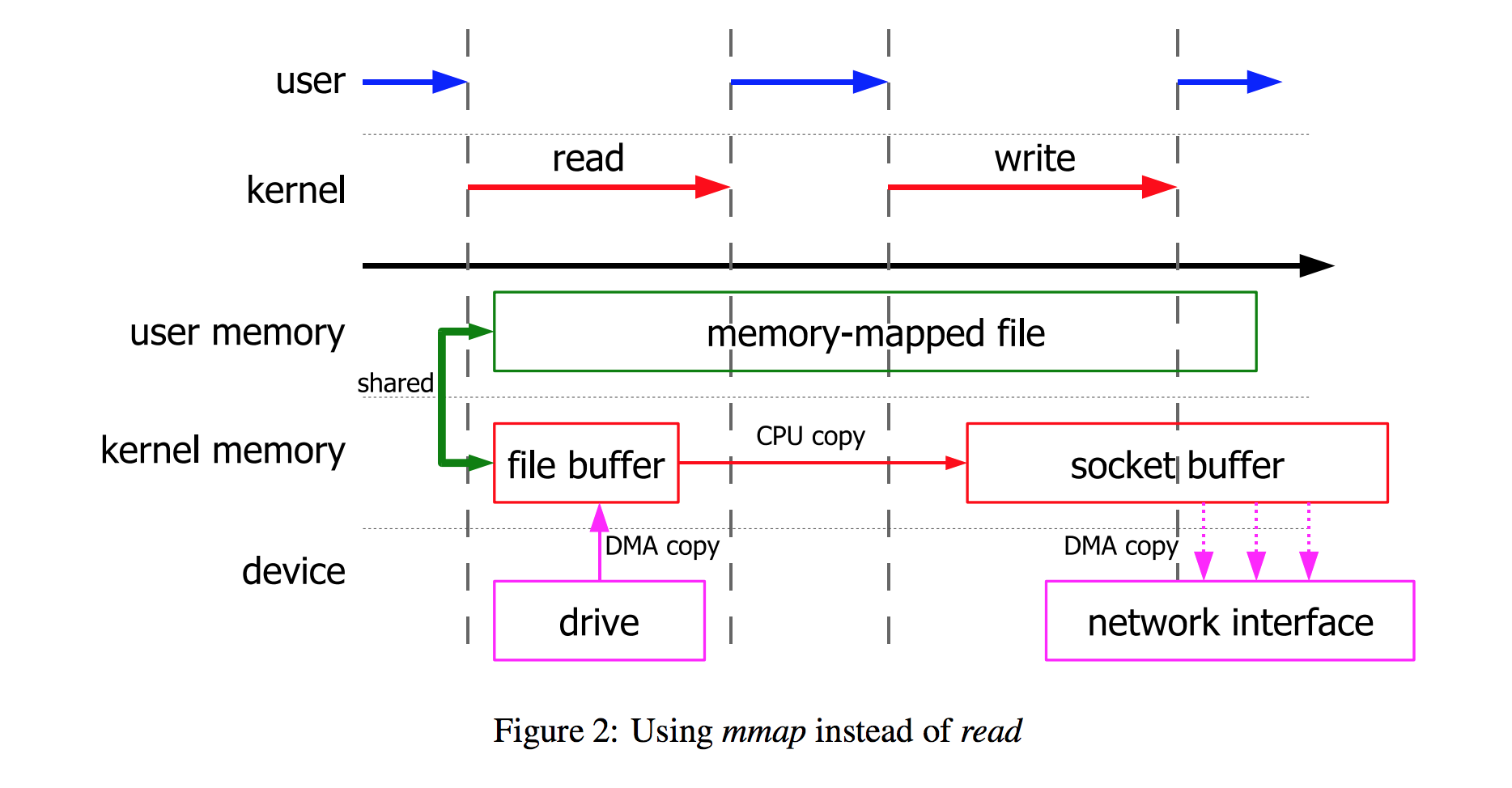
在 Linux 中,减少拷贝次数的一种方法是调用 mmap() 来代替调用 read,比如:
tmp_buf = mmap(file, len);
write(socket, tmp_buf, len);
首先,应用程序调用了 mmap() 之后,数据会先通过 DMA 拷贝到操作系统内核的缓冲区中去。接着,应用程序跟操作系统共享这个缓冲区,这样,操作系统内核和应用程序存储空间就不需要再进行任何的数据拷贝操作。应用程序调用了 write() 之后,操作系统内核将数据从原来的内核缓冲区中拷贝到与 socket 相关的内核缓冲区中。接下来,数据从内核 socket 缓冲区拷贝到协议引擎中去,这是第三次数据拷贝操作
尽管 mmap() 可以减少一次 I/O 拷贝,但由于 mmap() 的实现很复杂,调用 mmap() 将会带来额外的开销,因此在一些情况下,没有使用 mmap() 的必要:
- 访问小文件时,直接使用
read()或write()将更加高效。 - 单个进程对文件执行顺序访问时(sequential access),使用
mmap()几乎不会带来性能上的提升。譬如说,使用read()顺序读取文件时,文件系统会使用 read-ahead 的方式提前将文件内容缓存到文件系统的缓冲区,因此使用read()将很大程度上可以命中缓存。
那么,在什么情况下使用 mmap() 去访问文件会更高效呢?
- 对文件执行随机访问时,如果使用
read()或write(),则意味着较低的 cache 命中率。这种情况下使用mmap()通常将更高效。 - 多个进程同时访问同一个文件时(无论是顺序访问还是随机访问),如果使用
mmap(),那么 OS 缓冲区的文件内容可以在多个进程之间共享,从操作系统角度来看,使用mmap()可以大大节省内存。
sendfile()
为了
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%A8%8B%E5%BA%8F%E5%91%98%E5%BF%85%E7%9F%A5%E5%BF%85%E4%BC%9A%E7%9A%84%E9%9B%B6%E6%8B%B7%E8%B4%9D%E6%8A%80%E6%9C%AF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


