离线学习增量学习在线机器学习的区别
以下文章来源于跳动的数据 ,作者一尘
通常算法工程师在做构建算法模型,都是以离线批量的方式在训练模型,本篇就来介绍机器学习在时间维和数据维度上的区别。
离线学习
下面一段话是引自wikipedia的定义
In machine learning, systems which employ offline learning do not change their approximation of the target function when the initial training phase has been completed.These systems are also typically examples of eager learning.
- 离线学习完成了目标函数的优化将不会在改变了
- 离线学习需要一次提供整个训练集
- 时间和空间成本效率低
- 发生数据变更或模型漂移需要从头开始训练
- 离线学习模型稳定性高,方便做模型的验证评估

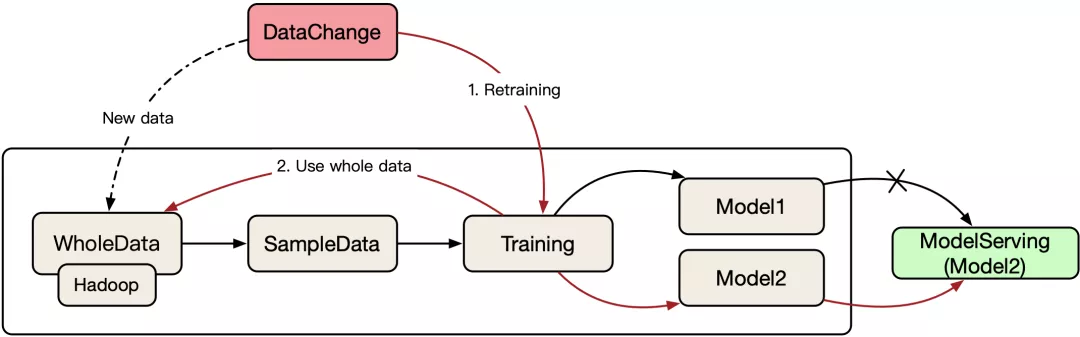
离线学习流程图
在线学习
下面一段话是引自wikipedia的定义
In computer science, online machine learning is a method of machine learning in which data becomes available in a sequential order and is used to update the best predictor for future data at each step, as opposed to batch learning techniques which generate the best predictor by learning on the entire training data set at once. Online learning is a common technique used in areas of machine learning where it is computationally infeasible to train over the entire dataset, requiring the need of out-of-core algorithms. It is also used in situations where it is necessary for the algorithm to dynamically adapt to new patterns in the data, or when the data itself is generated as a function of time, e.g., stock price prediction. Online learning algorithms may be prone to catastrophic interference, a problem that can be addressed by incremental learning approaches.
在线学习一种模型的训练方法,在这种方法中,数据按顺序可用,并用于在每一步更新未来数据的最佳预测值。
在线学习的数据效率高,适应性强。在线学习是数据高效的,因为一旦数据被消耗,就不再需要它了。
从技术上讲,这意味着您不必存储数据。在线学习是可以适应的,因为它没有假设你的数据的分布。当您的数据分布发生改变或漂移时,由于客户行为的变化,模型可以动态调整以实时跟上趋势。
Flink的流批一体,为了做一些类似的离线学习,你必须创建一个滑动窗口的数据和重训一次。
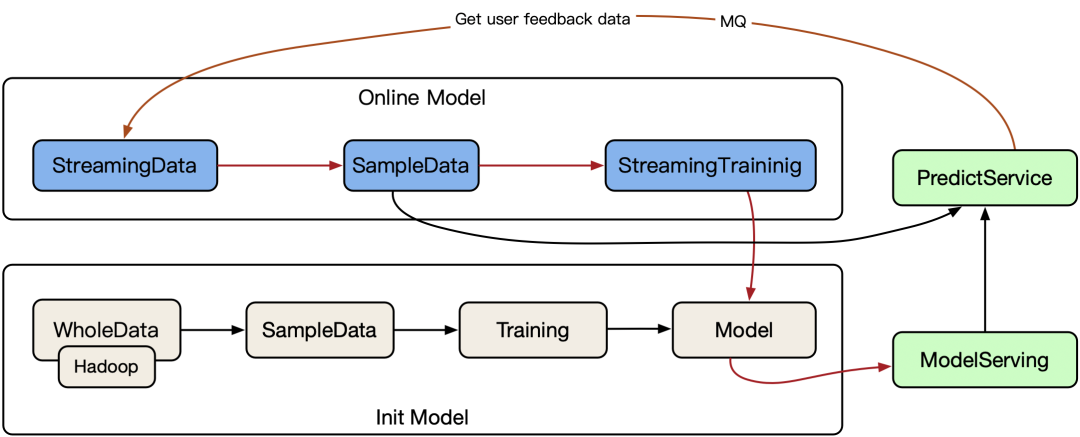 在线学习流程图
在线学习流程图
能够根据线上反馈数据,实时快速地进行模型调整,使得模型及时反映线上的变化,提高线上预测的准确率。
将模型的预测结果展现给用户,然后收集用户的反馈数据,再用来训练模型,形成闭环。
The main objective of online learning algorithms is to minimize the regret
在线学习算法的主要目标是使regret最小化
一种优化方法
增量学习
下面一段话是引自wikipedia的定义
In computer science, incremental learning is a method of machine learning in which input data is continuously used to extend the existing model’s knowledge i.e. to further train the model. It represents a dynamic technique of supervised learning and unsupervised learning that can be applied when training data becomes available gradually over time or its size is out of system memory limits. Algorithms that can facilitate incremental learning are known as incremental machine learning algorithms.
Many traditional machine learning algorithms inherently support incremental learning. Other algorithms can be adapted to facilitate incremental learning. Examples of incremental algorithms include decision trees (IDE4,[1] ID5R[2]), decision rules,[3] artificial neural networks (RBF networks,[4
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%A6%BB%E7%BA%BF%E5%AD%A6%E4%B9%A0%E5%A2%9E%E9%87%8F%E5%AD%A6%E4%B9%A0%E5%9C%A8%E7%BA%BF%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%9A%84%E5%8C%BA%E5%88%AB/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


