短视频如何做到千人千面排序模型深度解析
背景
信息流短视频以算法分发为主,人工分发为辅,依赖算法实现视频的智能分发,达到千人千面的效果。整个分发流程分为:触发召回、排序与重排三个阶段。排序层在其中起着承上启下的作用,是非常重要的一个环节。在排序层优化的过程中,除了借鉴业界前沿的经验和做法,我们也做了模型上的一些创新。
信息流短视频排序目前使用是以CTR预估为目标的Wide&Deep模型。通过引入时长特征、点击+时长多目标优化等工作,我们取得了不错的收益:
● 增加视频平均播放时长特征,作为用户真实体感信号,带来用户消费时长提升;
● 通过消费时长样本加权,实现点击+时长多目标优化,实现点击率与消费时长的提升;
● 引入多个视频下发场景的样本数据,实现多场景样本融合;
在优化排序模型的过程中,我们也调研了DeepFM/DeepCN等深度模型,这些模型无论从离线还是线上指标上,都没有明显优势。在优化Wide&Deep模型的同时,更迫切的需求,是跳出原有的框架,寻找新的收益点。
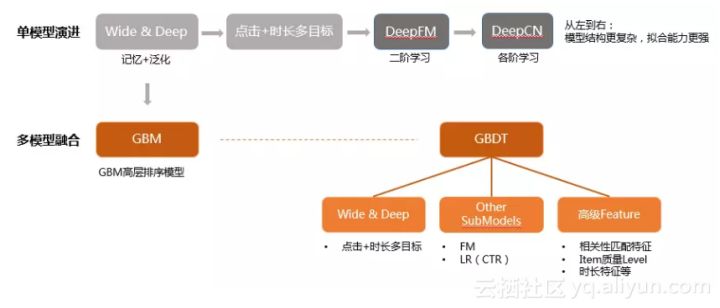
引入GBM对submodel和高级特征等信号做集成学习,效果要优于单模型。从计算学习理论上看,Wide&Deep是high-variance模型,容易过拟合(wd模型的训练比评估指标高7%)。GBM通过boosting的方式组合集成多个submodel和高级特征,更好地发挥各自不同的作用和优势互补,同时从整体上有更好的可解释性。
上面是对信息流短视频排序模型演进的简要介绍;而其中的FM+GBM模型是我们团队比较有开创性的一项工作,下面稍微展开介绍。
模型
向量分解机(Factorization Machines, FM)是一种应用较为广泛的推荐模型,其发明者Steffen Rendle目前供职于Google。FM是对传统LR模型在处理高阶交互特征问题上的优化和改进:LR通过特征交叉的方式,将组合后的特征作为新特征加入到模型中,模型复杂度为O(N^2)(N为交互特征的数量,下同),记忆性较强而泛化性偏弱;FM通过将特征表征为隐向量,通过隐向量的相似度(內积)来表示特征关联这种方式来巧妙地提升模型的泛化能力;FM模型的复杂度为O(N*k)(k为隐向量维度超参)。

以二阶交互的FM模型为例,其模型定义如下:

FM本质上是一个线性模型,不同项之间以线性组合的方式影响模型的输出。如果要考虑更加复杂的模型组合,计算复杂度将会非常高。尽管学术界也有像张量分解(Tensor Decomposition)这类处理高阶交互特征的模型;但在工业级,考虑到效果与性能的折衷,往往只考虑二阶的交互。但在此基础上,我们可以考虑引入非线性的模型来优化FM模型。
在非线性模型中,树模型(CART/GBM/Random Forest)的应用非常广泛。我们引入GBM作为组合FM的非线性模型:

FM+GBM一期(纯GBM)
一期主要打通整个实验框架和数据流,并没有引入额外的信号。GBM使用的信号包括:wd/lr模型等sub-model打分、点击率/时长和体感特征,以及一些简单的匹配度特征。整个实验框架比较简单:精排流程新增GBMScorer,实现以下2个功能:
● 分发服务器通过流量分桶决定精排是否使用GBM打分,由GBMScorer具体执行;
● 特征归一化和回流。提取的特征经归一化后返回给分发服务器,由分发服务器回流至日志服务器落盘。点击日志也同时经由日志服务器落盘。点击-展现日志通过reco_id+iid对齐,经清洗、过滤和反作弊处理后,提取回流特征用于模型训练;
在调研和实验的过程中,以下是一些经验和教训:
**● 样本与超参的选择:**为了让模型尽可能地平滑,我们从7天滑动窗口的数据中随机抽取样本,并按比例分割训练/验证/测试集。通过交叉验证的方式选择超参;在所有的超参中,树深度对结果的影响比较大,深度为6时效果明显优于其他选择。在调参过程中,auc和loss这两项评估指标在训练/评估/测试数据集上并没有明显的差异,由此可见GBM模型的泛化性。
**● 离线评估指标:**auc是排序模型常用的离线评估指标之一,但全局auc粒度太粗,可以结合业务计算一些细粒度的auc。行业有采用以Query为粒度,计算QAUC,即单个Query的auc,再按均值或者加权的方式融合得到的auc,比起全局auc指标更加合理。我们采用类似做法,以单次下发为粒度计算auc,再计算均值或者按点击加权。需要注意的是,auc计算的粒度决定了划分数据集的粒度。如果按照单次下发为粒度计算,那么一次下发的所有样本都必须同时落在训练/评估/测试数据集上。除此之外,单次下发中如果零点击或者全点击,这部分数据也是需要废弃的。
**● 特征的归一化:**尤其是对与用户相关的特征进行归一化尤为重要。通过分析精排打分(wd),我们发现不同用户间的精排打分分布的差异较为显著:同一用户的打分方差小,分布比较集中;不同用户用户打分均值的方差比较大。如果不对精排打分做归一化处理,GBM训练过程很难收敛。
GBM和精排打分也会随特征回流。日志对齐后,可以对这两个模型在离线评估指标上做比较fair的对比。从全局auc/单次下发粒度auc与小流量实验的结果来看,细粒度auc与在线实验的效果更加趋于一致。
FM+GBM二期
一期搭建了实验框架和数据流,二期开始考虑引入新的信号。
纵观眼下GBM用到的信号,主要分为两类:一是item侧信号,这类特征从各个维度刻画了item的特性:热度、时长、质量等。**这类特征有助于我们筛选精品内容,提升推荐质量baseline。**二是相关性特征,用于刻画用户和视频的关联度(关联度可以通过点击刻画,也可以通过时长刻画;目前主要通过点击),提升推荐的个性化,做到千人千面。 个性化水平才是信息流的核心竞争力。
目前相关性特征通过长短期用户画像计算和视频在一级/二级类目和TAG上的匹配程度,至少存在2个问题:
● BoW稀疏的特征表达无法计算语义层面的匹配度;例如,带足球标签的用户和梅西的视频通过这种方式计算得到的匹配度为0。
● 目前视频结构化信息的准确率/覆盖率较低,会直接影响这类特征的效果。
wd/lr模型能够一定程度解决上述问题。尤其wd模型,通过embedding技术,将用户和视频本身及各个维度的结构化信息嵌入到一个低维隐向量,能够一定程度缓解这个问题。但是这类隐向量缺乏灵活性,无法脱离wd模型单独使用:计算用户和视频的匹配度,除了需要用户和视频的隐向量,还要结合其他特征,并经过一系列隐层的计算才能得到。
业界主流公司的做法,是通过FM模型,将所有id特征都分成在同一个空间内的隐向量,因而所有的向量都是可比的:不仅用户与视频本身和各个维度的匹配度,甚至用户之间、视频之间,都可以通过简单的向量运算得到匹配度。从模型结构看,FM模型可以认为是能够更加紧密刻画这种匹配度的神经网络结构。为此,我们引入FM模型分解点击-展现数据,得到用户和视频本身及各个维度的隐向量。通过这些隐向量计算�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%9F%AD%E8%A7%86%E9%A2%91%E5%A6%82%E4%BD%95%E5%81%9A%E5%88%B0%E5%8D%83%E4%BA%BA%E5%8D%83%E9%9D%A2%E6%8E%92%E5%BA%8F%E6%A8%A1%E5%9E%8B%E6%B7%B1%E5%BA%A6%E8%A7%A3%E6%9E%90/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


