百分点大数据技术团队基于多任务的数据同步方案实践
编者按
在数据大爆发的时代里,数据分析和应用领域对数据即查即得的需求越来越迫切,ClickHouse凭借无与伦比的查询速度脱颖而出,被广泛应用于众多领域和方案中,是优秀的OLAP代表者。但是实践应用中,尤其是需要代码操作时会遇到一定的性能问题,尤其在数据量大的情况下表现更为突出。
本文针对实践场景中遇到的问题,结合Spark技术与集群资源对ClickHouse进行解剖和分析,并借助百分点科技在某数据中台项目中的案例,逐层分析并给出解决方案,文章偏向技术实践和应用,通用性较强。
概览
百分点科技是国内最早探索数据价值落地的公司之一,早在2017年,百分点大数据技术团队就开始深入探索和研究ClickHouse,并在国家级项目中得到最佳实践,获得客户一致好评。凭借雄厚的技术实力和成熟的解决方案,百分点科技已经完成上万家客户服务,依靠强大的团队力量、多年的项目实战经验和技术积累,在众多领域和行业沉淀出优秀的解决方案,并积累了夯实的实战经验。
在此引用早在2019年百分点大数据技术团队对CK的实践总结:
- 百分点科技使用规约:禁止采用CK分布式写入,通过本地表写入。
- 充分利用SparkStreaming的流量控制和反压机制。
- 在写入ClickHouse时合理控制时间频率。
文章 | 百分点大数据技术团队:ClickHouse国家级项目最佳实践
作为服务全球企业和政府的数据智能公司,百分点科技拥有成熟、完善的数据仓库理论和数据治理方案。本次某集团数据中台项目也同样运用本套解决方案,从不同系统中进行数据接入,历经ODS、DWD、DWS等各个层次的数据处理,最终产出完美型数据结果,并集中分布在DM集市层。其实数据集市层已经具备对外提供访问和数据呈现的能力,例如对接BI系统、对接WEB页面、对接上下系统交互、对接多个第三方系统检索、对接数据置换等。
但Hive受限于Hadoop生态圈,无法做到快速既查即得的效果,尤其这种结果型数据的使用,频繁的查询和调取,几乎不可能满足业界对Hive的期待,在数据仓库和数据应用方之间亟待需要一种既查即得、满足各种严格的高性能数据库系统。在众多OLAP领域,ClickHouse凭借其无与伦比的查询速度和诸多特性脱颖而出,成为了OLAP使用场景中优秀的代表者。
ClickHouse特性:
- 列式存储数据库,数据压缩;
- 关系型、支持SQL;
- 分布式并行计算,把单机性能压榨到极限;
- 高可用;数据量级在PB级别。
选择ClickHouse,就不能逾越各种数据的接入和各种介质的数据输出。从Hive到ClickHouse,从ClickHouse到其他存储介质的需求也常常存在。那么,如何做到彼此之间更好地衔接和更高效地传输,本文将作为专题进行详细讲解,希望能够跟大家一起讨论、学习和进步。
二 案例分析
可能有的同学会有疑问,使用CK查数据已经很快了,为啥还要需要这么折腾呢?
用过ClickHouse的同学们都清楚,CK分两种表,一种是分布式和一种是本地表,分布式表是做查询用的,本地表是做存储用的。一张本地表等同于一份数据的分片,通常一张表会分成多个本地表分布存储,从而达到海量存储和负责均衡的集群效应。写入ClickHouse的时候会按照一定的均衡方式,均匀地落在不同本地表中,假如100万数据需要写入CK,假如CK集群有三个主节点,则每个主节点的本地表会存33w左右,假如CK集群有四个节点,则每个节点存25w左右,以此类推。
为方便大家更好的思考和理解,后边会以三主三备的ClickHouse集群为案例进行讲解,首先先了解一下ck分布式表查询的过程图解:
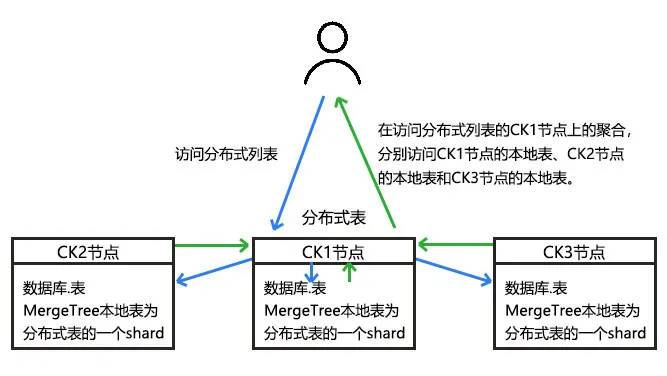
图一:ClickHouse分布式表查询过程
如上图所示,在每个节点执行的语句都一样,操作也一样,只是查询的数据不同。同理存储过程也非常类似,其实写入数据时也可以写入分布式表,让其均匀落到不同节点上,但是这样的写入方式会存在诸多问题,如:数据的一致性问题、合并速度与写入速度不匹配问题,zk压力问题等,因此一般是禁止写入分布式表的,所以选择写入本地表是一种不错的方案。
CK的3个主节点保存的数据是不重复,所以在准备Hive数据的时候可以将Hive数据分成3份数据,与CK的3个本地表形成对应关系。这里引入Hive分桶的概念,每个桶对应CK的一个本地表,从Hive导入ClickHouse的时候分别对应导入(3个桶对应3个本地表),执行3次就能完成全部数据的导入。
通过JDBC操作ClickHouse一般都是单线程的,从Hive的一个桶读完数据后再写入CK,有的同学会问,可不可以搞成多线程的?答案是可以的(实践证明这种思路是正确的)。
但无论是单线程还是多线程都存在两个问题,一个是性能问题,一个是资源问题,仅限于执行服务器上资源,即使这台服务器有128G内存、32cores,我也只能用这么多。
所以可不可以发挥集群的作用呢?答案也是可以的,利用大数据集群的资源管理系统Yarn,就可以解决资源的问题;利用分布式计算框架Spark技术可以解决并发的问题。
综合上述产出我们的最终方案(也是本篇文章的亮点,概览已提到): 合理集成Spark技术框架,充分发挥Yarn资源管理机制,实现多线程并发操作ClickHouse的架构设计和案例分析 。
三 项目实践
以三主三备的ClickHouse集群为例,以用的最多的MergeTree+Distributed的分布式架构方案为例,逐步进行方案的分解和分析。
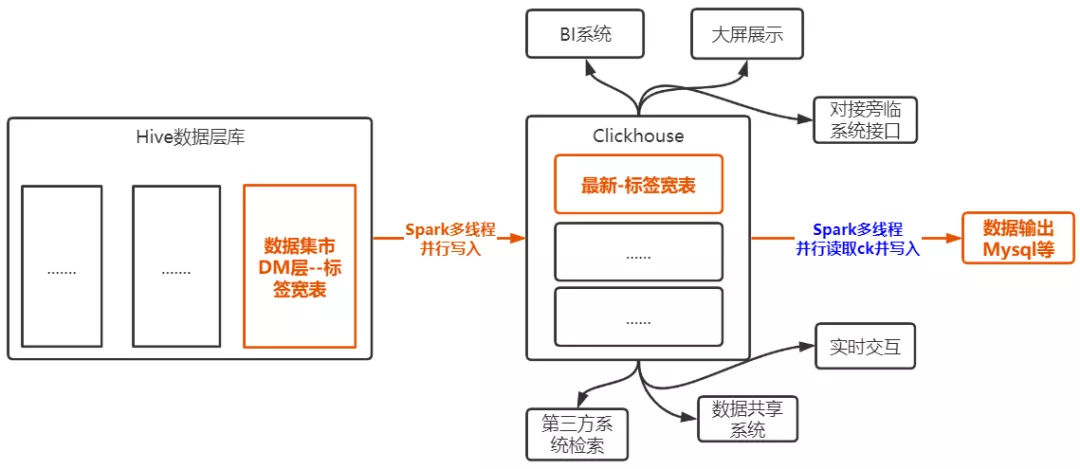
业务需求:经过数据仓库建设和数据加工最终产出数据集市DM层中的一张1亿条*400字段体量的客户信息标签大宽表(全中国14亿人中就有1个人在里面),该表数据需要同步到ClickHouse中,以满足BI展示、WEB页面数据查询、第三方系统数据检索和数据输出(数据输出多为MySQL等)的需求,同时也满足旁临系统的使用。如下图所示:
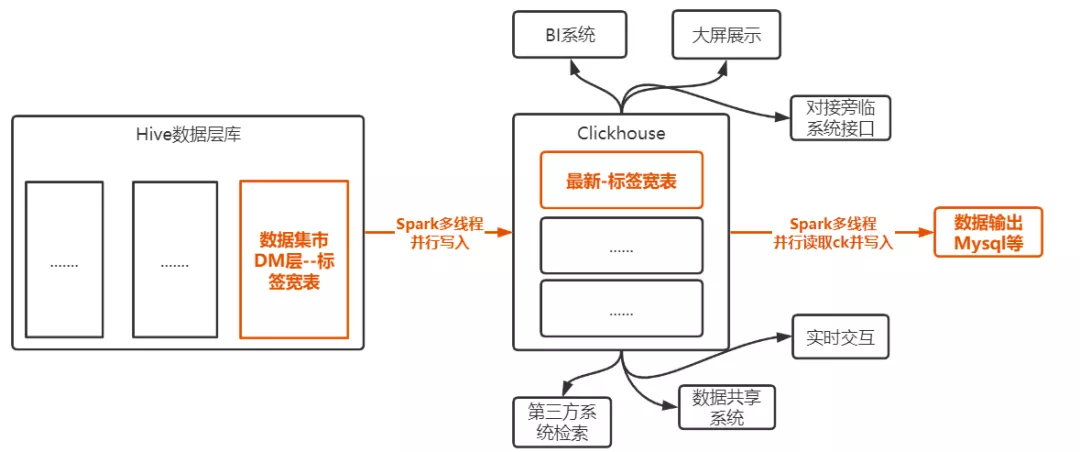
本次主要分析图中橙色字体部分,总结为如下3个步骤:
- Hive集市数据准备
- Hive数据同步到ClickHouse
- ClickHouse数据同步到MySQL
接下来会按框内步骤逐一进行详细分解。
1. Hive集市数据准备
Hive产出一张表很简单,但如果对接ClickHouse,如何更合理地去组装数据,可以达到更好的效果呢? 其实在第三节,案例分析阶段已经给出了答案 ,根据ClickHouse三主三备的特性,将Hive表生成3个同样逻辑上的桶与CK中的本地表–对应,如果很抽象的话,你可以理解为做成了3条一样的流水线管道,我们负责建成管道,只待水来、只待数据来。
在HiveSQL中distribute by就是分桶的概念,sort by指定每个bucket的文件内部数据排序字段,如果distribute by和sort by 字段相同可以cluster by 统一代替,分桶的字段一定是原表中存在的真实字段。
在我们需要确保reduce的数量与表中的bucket数量一致,需要设置几个参数:
(1)让Hive强制分桶,自动按照分桶表的bucket进行分桶。 (推荐 )

(2)手动指定reduce数量。
我们的桶数量为3,所以这里的值也为3。

(3)采用insert overwrite重新组装新表数据,完成Hive数据的准备任务。
2. Hive数据写入ClickHouse
数据已经按照3桶分的形式准备好了,那么,如何更快速高效的完成数据导入呢?Spark技术又如何使用的呢?
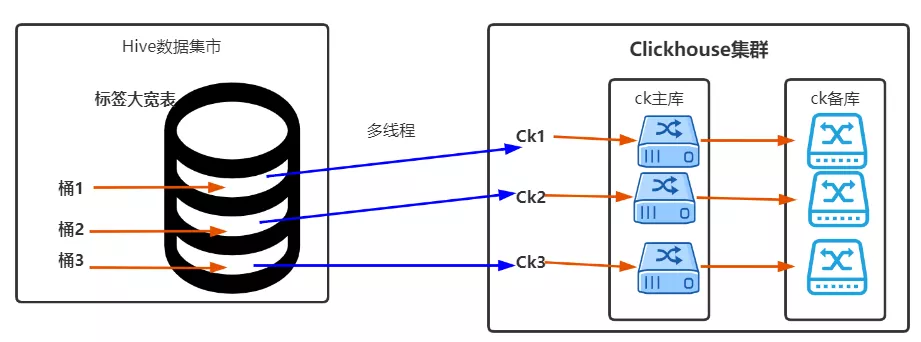
如果说第一节准备的数据是水的话,那该章节就是要建立从Hive到CK的第一个管道– 引水管道 。
建立引水管道大概分为3个步骤,如下:
- 建立ClickHouse所有主节JDBC点连接
- Spark分别读取Hive,按3取模,分3次读取
- 按3取模,分3次单独写入CK主节点数据
注:2和3在同一个线程中前后顺序执行。
请看如下示意图(3条线–3个管道):
第一步: 建立CK多节点连接
首先需要知道ClickHouse的所有连接,可以通过CK的元数据得到,即使CK集群发生了变化我们在使用前获取最新的集群信息,以保障数据一致。
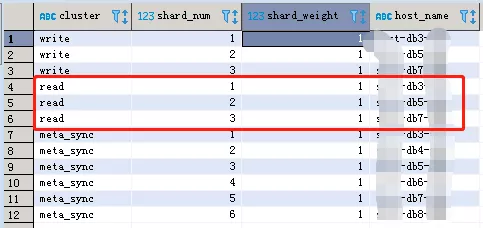
如上图所示,我们可以看到所有集群对应的hostname列表,通过图内容我们可以看到该ClickHouse拥有3个数据集群,集群名字为write、read、meta_sync,分别部署在6个节点,其中read和write为3主3备模式,meta_sync为6主模式没有备份,一般元数据信息的建表语句或者更新语句都采用meta_sync,表创建肯定都会在每个节点上都创建,一般数据表采用write或者read,三个备节点会定时同步主节点数据,即使一台节点挂掉了也不影响整个集群使用,所以本次数据写入我们使用read集群,三主三备,所以我们写入的主机名为db3、db5、db7,db4、db6、db8会自动同步主节点数据完成数据备份。
第二步:Hive数据读取
参考代码:
select*from xxxxx where l_date='2021-10-16'and tablesample(bucket %s out of 3 on uid)
说明:%s是标示从第几个桶读取数据,是动态参数,根据代码循环动态拼接Hive SQL,利用Spark特性分布式并行执行,加快数据读取速度(因为数据表数据量很大,数据量超过hdfs block块默认值大小,就会分成N多个block块存储在不同的节点上,Spark就会发出N个并行线程同时进行数据读取),数据量大的这种场景使用Spark读取Hive数据是最合适的方式。
总结:每个block块都会有一个线程进行数据读取,N个block块就会相当于N个管道同时引水,这就是Spark的优势。
第三步:多线程并发读取和写入
如果第二步是把一条管道建立好了,那第三步就是建立多条这样的管道同时引水。具体多少条管道,与ClickHouse的节点个数和Hive的桶数量有着直接的关系。
本案例我们建立3个并发3条管道(因为CK节点和Hive桶都是3个),每个管道都独立抽水并引入ck中。3个管道,互不影响,相互独立,收发统一。
每条管道就是个线程任务,负责吸水和引水。先通过Spark执行HiveSQL读取数据生产DataFrame,然后DataFrame写入CK,读Hive的连接和CK的连接都是动态拼接的,然后一起启动线程,并通过join()函数监测线程任务,最终完成整体任务。
3. ClickHouse数据到MySQL
通过上一章节的管道建立,数据已经写入到CK之中,CK的数据可以对外提供访问和检索。上一章节的建立的是数据引入管道,那本章节建立就是第二道管道–数据流出管道,即从CK到MySQL。
那从ClickHouse数据同步到MySQL这条管道如何实现呢?如何更高效的实现呢?Spark技术又如何利用?带着问题且听下面讲解,正如图中蓝色部分所示:
从ClickHouse到MySQL的步骤与之前从Hive到ClickHouse的过程恰恰相反,Hive到ClickHouse是流入管道,这次是流出管道(相当于从CK抽水的动作),这种场景也很常见,例如数据交换、数据同步、第三方需求等,不要求太高的更新频率,只需要数据输出即可。众多数据库中,MySQL用的是最多的,所以本次以MySQL作为案例场景进行分解;虽然与Hive到CK数据流程相反,但建立管道的方案和技术都触类旁通,此次架构设计也是基于ClickHouse的存储特性而出发的,整合Spark框架技术,充分利用大数据集群资源而作出的数据输出架构设计和案例分析。
从ClickHouse输出到MySQL,前后共尝试四种方案进行逐阶段尝试,分析利弊。
第一种:JDBC读取分布式表
采用JDBC读取分布式表的形式,在某一个节点上建立连接和读取数据,其实在底层做的也是任务分发查询,然后汇总在执行节点上统一返回。CK是多主节点共同存在的,可以在不同的主节点提交任务,但无论在哪个节点,都会受资源的限制,因为执行仅限于本台服务器上。查询数据量小还可以,但如果数据量大就会造成服务器CPU爆满、内存吃紧,如果该节点部署其他组件或应用,会严重影响他们的使用,如果影响到Zookeeper、Kafka、Redis等集群节点,可能整个集群都会受到影响,所有这种方法酌情使用。
总结:抽水的只有一条管、一个水泵(一个服务器可以形象化为一个水泵)。
第二种:多线程并发读取本地表
多线程JDBC同时读取本地表的形式,呈现出多线程同步执行的盛景(较第一种有了很大的进步,起码有3个线程3条管道在并行操作),但如果表很大,数据量很多,同样会受到资源的限制。因为这3个线程都集中在一台服务器上,同样也面临更严峻的CPU、内存爆满,其槽点依然是未能更好地使用集群资源去解决问题,我们需要亟待挖掘出更好的方法。
总结:虽然有三条管一起抽水,但是都挤在一个水泵里,总体还是受这一个水泵的限制。
第三种:Spark读取分布式表
充分利用集群的资源,那尝试Spark读取ClickHouse,虽然Spark和ClickHouse都给对方做了集成,但并不是非常的好用的那种,Spark读取分布式表时只有一个线程在执行(也只建立了一个管道),虽然写MySQL呈现出多线程并行执行的现象,但是读数据却让人大跌眼镜,整体效果跟JDBC的形式也相差不了太多,效率和速度并未达到预期的效果,所以Spark读分布式表的形式也不是最佳的选择。
总结:本方案虽然写MySQL是多条管道,但是抽水的依然是一个水管(槽点)、一个水泵,无奈抽水慢,总体也不会快到哪里。
第四种:多线程Spark读取本地表
基于第三种方案的槽点,改造优化和改造。Spark读分布式表只有一个线程很慢,可不可以改成读本地表和多线程的形式?答案是可以的,结合第二种和第三种方案的优点,从ClickHouse存储特点出发,将Spark读分布式表改造成多线程读本地表形式进行尝试,形成第四种方案的基本方针。
既然ClickHouse的数据都均匀分布在各个主节点上,建立每个线程用Spark并行读取本地表形成DataFrame数据集,利用DataFrame数据可分区的特性,将数据重新分成多个数据分区,每个数据分区都会写入MySQL,这也充分发挥Spark分布式计算引擎的特性,形成多线程并行读取,多线程并行写入的壮景。
总结:本方案建立起来有三个水泵三条管道一起抽水,写MySQL的有了3 N个线程(3 N条管道),相比之前的方案,本方案抽水是最快的。
现将这种方案进行拆分讲解,执行步骤如下:
**第一步:获取各本地表连�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%99%BE%E5%88%86%E7%82%B9%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%8A%80%E6%9C%AF%E5%9B%A2%E9%98%9F%E5%9F%BA%E4%BA%8E%E5%A4%9A%E4%BB%BB%E5%8A%A1%E7%9A%84%E6%95%B0%E6%8D%AE%E5%90%8C%E6%AD%A5%E6%96%B9%E6%A1%88%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


