由于幸存者偏差导致强变量在后续迭代中逐渐削弱甚至相反怎么办文末有福利
解析:
幸存者偏差(SurvivorshipBias)与样本不均衡(Imbalance Learning)问题都是由于风控模型的拒绝属性导致的。但表现形式略有不同。幸存者偏差是指,每次模型迭代时,使用的样本都是被前一个模型筛选过的,从而导致的样本空间不完备。
其实主要是添加负样本的问题。简单一些可以直接用增量学习,效果更好的是迁移学习和半监督学习。比如用GAN网络产生新样本,对齐现有样本和旧的历史样本的分布,然后进行建模。
文末免费送电子书:七月在线干货组最新 升级的《名企AI面试100题》免费送!
解析2
- 1、什么是幸存者偏差效应?
幸存者偏差(Survivorship bias),另译为“生存者偏差”或“存活者偏差”,是一种常见的逻辑谬误,意思是只能看到经过某种筛选而产生的结果,而没有意识到筛选的过程,因此忽略了被筛选掉的关键信息。
通俗地说,当我们取得资讯的渠道仅来自于幸存者时(因为死人不会说话),资讯可能与实际情况存在一定的偏差。
这一规律也适用于金融和商业领域。存活下来的企业往往被视为“传奇”,它们的做法被争相效仿,而其实有些企业也许只是因为偶然原因而幸存了下来。
幸存者偏差在日常生活也中十分常见,比如:
很多人得出“读书无用”的结论,是因为看到有些人“没有好好上学却仍然当老板、赚大钱”,却忽略了非常多的因为没有好好上学而默默无闻,甚至失魂落魄的人;
又比如你可能听到朋友推荐某个“偏方”说他的亲戚用这个偏方治好了重疾,但实际上这个偏方到底治好了多少比例的人,有多少人用了这个偏方没有痊愈却没有人知道……
- 2、金融风控中的幸存者偏差效应
广义的幸存者偏差用统计学的专业术语来解释是——“选择偏倚”,即我们在进行统计的时候忽略了样本的随机性和全面性,用局部样本代替了总体随机样本,从而对总体的描述出现偏倚。
在金融信贷场景中,放款机构会通过模型评分筛选用户,评分较好的用户可以获得放款,评分较差的用户直接被拒绝,机构只能获得放款用户样本的好坏标签,对于大量拒绝用户的还款情况无法获得。
随着时间的推移,机构手中的训练样本都是“评分较好”的通过用户,而没有“评分较差”的拒绝用户,由此训练的模型在“评分较好”用户中表现越来越好,在“评分较差”用户中却无法得到任何验证。
但是,金融风控模型真实面对的客群却包括了“评分较差”的用户,模型在“评分较差”用户中无法得到验证,导致训练的模型越来越偏离实际情况,甚至通过了大量应该被拒绝的坏用户,致使大量坏账出现,直接带来巨大经济损失。
用下图示意的话,在客户全集为A的情况下,放款机构仅能通过分析子集幸存者A1的还款与行为数据寻找区分客户好坏的标签,但却不得不把这种标签推广应用在包括子集沉默者A2在内的全集上,而从A1取得的好坏标签在A2中可能并不成立。
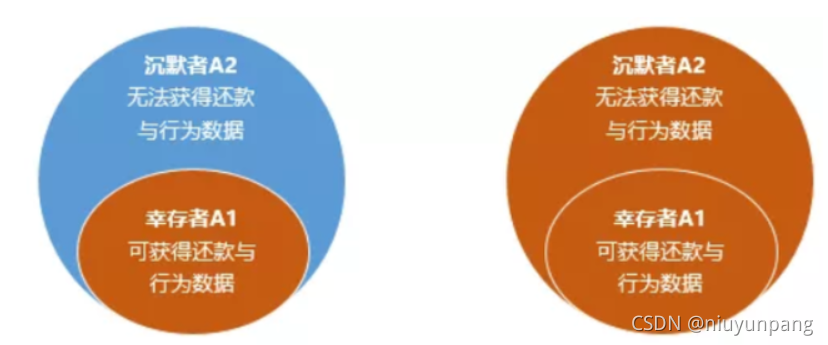
因此,当只能获得优质放款用户的好坏标签的情况下,如何保证建模对所有放款用户和拒绝用户都有良好的排序能力,是金融风控模型需要解决的重要问题。
- 3、使用“拒绝推断”解决幸存者偏差
拒绝推断(Reject Inference),即推断建模总体中被拒绝的客户样本可能出现的结果。拒绝推断是建立申请评分模型时的特有问题。如果我们能够顺利运用某些方法成功地推断出被拒绝的客户的信用表现(即是好客户还是坏客户),那么我们就得到一个较完整的建模总体和建模样本。
拒绝推断的方法
- 接受部分坏客户
解决样本选择偏差的最直接有效的方法就是随机抽取未被授信的客户,对其进行授信,观察未来表现。对于这部分客户加以一定的权重与那些原本被授信的客户合起来作为模型开发的样本。
但是这种方法在现实中很难被风险管理部门所接受,因为未被授信的客户一般被认为存在拖欠行为的可能性较大,对这部分客户进行授信,风险也往往较高,易带来损失。
- 两阶段加权的方法
(核心基于诺贝尔奖获得者Heckman的两阶段模型)
这里先解释下Heckman的两阶段模型。
Heckman 在1974年发表的《Shadow Price, Market Wages and Labor Supply》(影子价格、市场工资与劳动供给)中研究了工资与教育程度的关系。很显然,研究者只可能从有工作的人们那儿获得有关工资的数据。根据这些数据,研究者可以绘制成下图这样的分布图。图1中W表示工资,X表示受教育程度,可获得工资数据是图中的实心点。这样,我们研究所得到的两者的关系就如虚线所示。
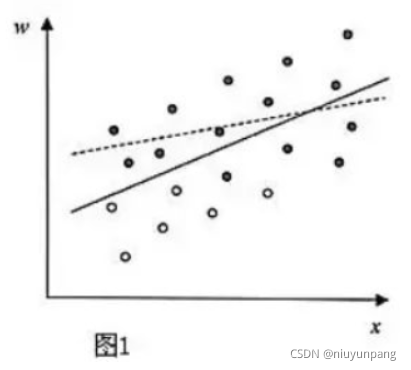
但是,这个关系是有偏差的。因为有不小比例的人没有参加工作,对这些人,我们可以了解他的教育程度,却不知道他一小时可以挣多少钱。一般地,人们是否参加工作取决于实际可得的工资与意愿工资,当工资低于意愿工资时,人们就会选择不工作。把不工作这部分人也搬到我们的图上,其分布就是图中的空心点。这时,工资与教育程度的关系就是图中的实线。可以发现,如果只拿实心点研究,得出的结论实际上低估了受教育程度对工资的影响。
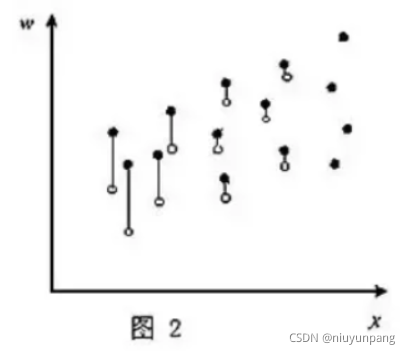
在Heckman 1979年发表的另一篇论文《Sample selection bias as a specification error》(样本选择偏差导致的设定误差)中给出了这一问题的具体解决方法。首先,算出不同教育水平的人,参加工作的概率各有多大,这可以通过经验数据模型得到。然后,删去不工作之人的样本,将余留的样本点依其工作概率的不同,垂直往下位移。工作概率愈小,向下位移愈大;工作概率愈大,向下位移愈小。工作概率百分之百的,不作位移。(下图,实心点下移到由空心点标示的新位置。)
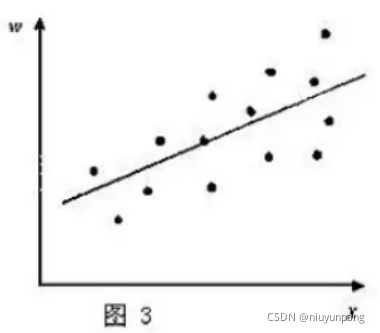
然后,对位移后的样本点,求出其回归线。理论上可以证明,这条回归线,与第一个图中标出的真实关系线,应当是一致的(参见图3)。
回到我们的问题当中,假设被拒绝的申请者行为模式与被授信的申请者行为模式相似,其基本思想是加权被授信的申请者,使得被授信的申请者能够代表被拒绝的申请者的行为。该方法分为两个阶段。
- 第一阶段,建立一个拒绝/批准模型,用来预测一个申请者被拒绝/批准的概率。然后假设拒绝/批准概率相近的客户具有近似的风险特征,因此考虑将拒绝/批准概率分成若干段,每段的好坏账户能代表该段内的被拒客户的特征,因此利用这些好坏账户可以推测被拒帐户中的好坏。
- 第二阶段,为每一个样本计算出用于修正样本选择偏差的权重修正因子,从而建立有权重修正因子的违约预测模型。
具体操作如下:
- 对所有样本账户先构建一个粗略的拒绝/批准模型,其中批准账户包括“好账户”、“坏账户”,据此得到对所有账户的预测的拒绝概率。该拒绝/批准模型仅用于加权调整,采用的�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%94%B1%E4%BA%8E%E5%B9%B8%E5%AD%98%E8%80%85%E5%81%8F%E5%B7%AE%E5%AF%BC%E8%87%B4%E5%BC%BA%E5%8F%98%E9%87%8F%E5%9C%A8%E5%90%8E%E7%BB%AD%E8%BF%AD%E4%BB%A3%E4%B8%AD%E9%80%90%E6%B8%90%E5%89%8A%E5%BC%B1%E7%94%9A%E8%87%B3%E7%9B%B8%E5%8F%8D%E6%80%8E%E4%B9%88%E5%8A%9E%E6%96%87%E6%9C%AB%E6%9C%89%E7%A6%8F%E5%88%A9/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


