用户画像番外篇之随笔三则
超人赵,人工智能爱好者社区专栏作者
知乎:
一则:开发上的一点记录
文章说是生活随笔,到不如说是对本周开发工作中的一些体会与思考的记录。
这个专栏我想除了对知识上的一些记录,以后也可以加入生活上的收获。好记性不如烂笔头,或许多年后再回看这些文章,回看进步的历程,也是一件很有成就感的事情。
4月份换了工作去做数据开发,重点项目还是做用户画像。开发时间排的很紧,平均每天要开发1~2个标签。从和需求方确认标签口径,找标签对应数据所在的表、字段定义、数据存储结构,到写标签逻辑,上线验证标签正确性…. 时间简直不够,更不要说某些复杂口径的一个标签都要写上百行的逻辑。
这周到现在又开发了6个标签,写了一个调度脚本,正在进行着一次数据逻辑调优。下面挑两个重要点的记录一下:
1、任务调度脚本开发
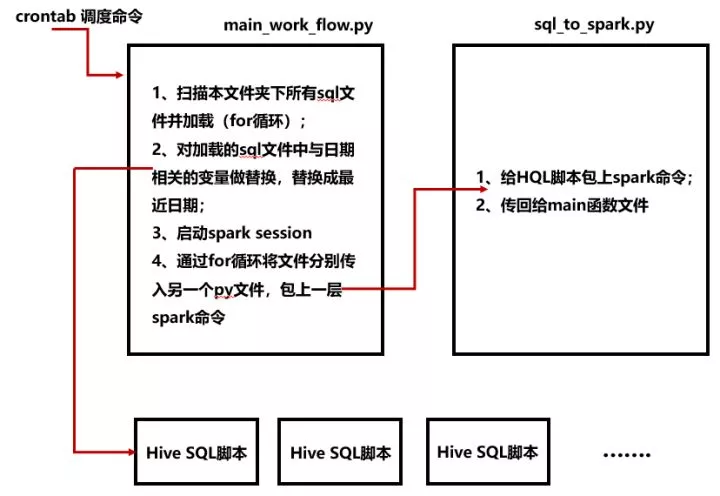
画像数据目前是写在Spark SQL里面,通过每天定时任务调python脚本,来执行Spark SQL。
但这样的话开发效率比较低,一方面开发人员写完Hive SQL脚本后,还需要在外面包一层spark才打包成可执行脚本,另一个方面对于每一个打包后的python脚本都要写一个crontab调度命令。
所以必须要优化一下流程。优化方式就是:
①开发人员对画像标签只需写Hive SQL脚本,传到服务器对应目录下;
②通过一个python脚本,自动扫描目录下的sql文件,加载并替换掉sql中的日期变量,并将替换日期后的脚本文件包上spark去执行;
③每天crontab命令只需定时调度该python脚本即可,不需要在每新上一个标签的Hive SQL逻辑,就上一条调度命令。
2、数据逻辑调优
开发出的标签很多了,但有的标签逻辑复杂,需要做进一步调优,提高每日跑批作业的执行效率,这里就与日志数据相关的标签为例。
用户近30日活跃时间段_:_这个口径需要计算用户近30天是在中午、下午、晚上哪个时间段访问次数最多,这显然是一个与日志数据相关的口径。
而记录用户访问行为的日志数据的情况是:
1、做了_日期分区_,每日全量更新历史数据。而且日志数据量很大,每天都有亿级pv;
2、这就导致了在每天跑批时都需要从近30天的访问日志中抽取数据计算,一次几十亿pv的计算,相当耗费计算资源了。
后来做的调优方式是:
①首次刷数据时刷近30日用户在每个时间段的活跃次数,做倒排序找出用户活跃时间段;
②后续每天跑批任务时,只需计算前一天用户访问各时间段对应的次数(不通过日期分区字段找,对用户访问时间做日期格式处理后通过访问日期来找),并与历史数据做加总,找出其活跃时间段;
③这样计算就免去了计算近30日的日志数据,仅需计算前一天的数据即可。
近期在不断补充学习新知识,spark要搞起来了、shell命令要用熟起来了。都要投入精力搞。
写到这会已经周五早上53分了,过几个小时还要继续投入。这周的一些想法先总结到这里。
我觉得生活也好、工作也好,或许就是在这么一天天的貌似不起眼的积累中,不断进步的。
作为一个多年的米粉,记得那次看红米note3发布会的末尾,被他文案中朴实、真诚的语句吸引了。在这里想用那句台词做结“我所有的向往”。向往着在每一个看似普通的日子中精彩生活、不断进步、奔腾向前。
二则:自动发送邮件脚本
这段时间在对流量部门提供数据方面的支持,把每天自动发送邮件的脚本讲一讲吧,虽然很基础,好像没什么可以说的 …
在日常运营工作中,数据提取人员面对众多业务方的数据需求,往往应接不暇。他们需要一套自动化的程序去帮助他们完成一些周期性和重复性较强的工作。
为了减少重复性工作,数据提取人员可以使用Python自动化脚本跑定时任务。将写好的HQL语句放入Python脚本中,并在linux服务器上设置crontab定时调度任务,保证每天定时自动从数据仓库提取数据完毕后,将结果集写到excel中并发送邮件到数据需求方的邮箱。Python脚本代码执行如下
#coding: utf-8
search_data = """ 创建临时表查询昨日运营数据"""
report_data = ''' select * from 上一步创建的临时表 '''
import psycopg2
import smtplib
import os
import openpyxl
import datetime
from impala.dbapi import connect
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.mime.image import MIMEImage
import pyhs2 # HIVE环境
wb = openpyxl.load_workbook('/home/path/username/daily_report_v1.xlsx') # 打开服务器存储路径下的excel文件
# 连接HIVE环境
impala_conn = pyhs2.connect(host='10.xx.xx.xx', port=xxx, authMechanism="PLAIN", user='username', password='password', database='dwd')
seo_h5_1 = impala_conn.cursor()
h5_result = impala_conn.cursor()
seo_h5_1.execute('''SET mapreduce.job.queuename=root.yydata''')
seo_h5_1.execute(search_data) # 执行HQL语句
# 取出来数据
h5_result.execute(report_data) # 取出来数据
h5_result = h5_result.fetchall()
#放到sheet里面去
sheet = wb.get_sheet_by_name('daily_report') #daily_report表
#清除历史数据
for i in range(2,sheet.max_row + 1 ):
for j in range(1,sheet.max_column + 1 ):
sheet.cell(row=i,column=j).value = ''
#填充结果数据
for i in range(2,len(h5_result) + 2 ):
for j in range(1,len(h5_result[i-2]) + 1 ):
sheet.cell(row=i,column=j).value = h5_result[i-2][j-1]
#关闭HIVE链接
impala_conn.close()
wb.save('/home/path/usernamet/daily_report_v1.xlsx') # 保存excel文件
receiver = 'receiver_email@xxx.com' # 收件人邮箱地址
date_str = datetime.datetime.strftime(datetime.date.today()-datetime.timedelta(days=1),'%m%d')
mail_txt = """
Dear All,
附件是运营日报,请查收。
"""
msgRoot = MIMEMultipart('mixed')
msgRoot['Subject'] = unicode(u'日报-%s' % date_str) #添加日期
msgRoot['From'] = 'sender_email@xxx.com'
msgRoot['To'] = receiver
msgRoot["Accept-Language"]="zh-CN"
msgRoot["Accept-Charset"]="ISO-8859-1,utf-8"
msg = MIMEText(mail_txt,'plain','utf-8')
msgRoot.attach(msg)
att = MIMEText(open('/home/path/usernamet/daily_report_v1.xlsx', 'rb').read(), 'base64', 'utf-8')
att["Content-Type"] = 'application/octet-stream'
att["Content-Disposition"] = 'attachment; filename="日报2017%s.xlsx"' % date_str
msgRoot.attach(att)
smtp = smtplib.SMTP()
smtp.connect('mail.address.com')
smtp.login('sender_email@xxx.com', 'sender_password')
for k in receiver.split(','):
smtp.sendmail('receiver_email@xxx.com', k, msgRoot.as_string())
smtp.quit()
将上面的python脚本后放入连接到数据仓库的服务器上,在linux下设置crontab调度语句,如“10 16 * * * python /home/path/username/auto_email.py”表示每天下午16点10分执行/home/ path/username/路径下的auto_email.py文件。
执行代码后,程序将自动执行SQL语句连接到数据库提取数据,提数完毕后将数据写入excel文件中,并自动发送邮件到数据需求方邮箱。
这样通过定时调度的脚本即可解决业务方每天对日报数据的需求,将数据提取人员从繁重的机械性劳动中解放出来。
三则:一次对渠道流量异常情况的分析
流量部门目前对APP线上推广需要支付较多的渠道推广费用,但不同渠道带来的用户质量、活跃度、消费能�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%94%A8%E6%88%B7%E7%94%BB%E5%83%8F%E7%95%AA%E5%A4%96%E7%AF%87%E4%B9%8B%E9%9A%8F%E7%AC%94%E4%B8%89%E5%88%99/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


