特征工程时序特征挖掘的奇技淫巧
最近在做时间序列的项目,所以总结一下构造的特征的方法和一些经验。
先放上大纲:
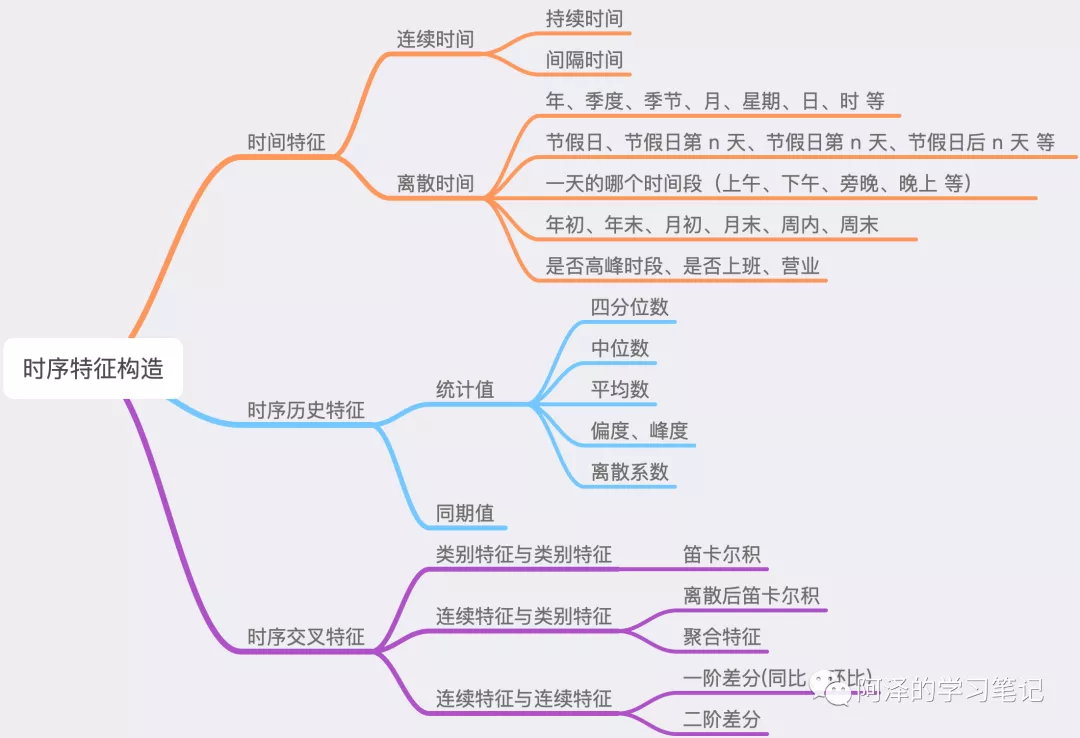
1.时间特征
1.1 连续时间
-
持续时间:
- 浏览时长;
-
间隔时间:
-
购买/点击距今时长;
-
距离假期的前后时长(节假日前和节假日后可能会出现明显的数据波动);
1.2 离散时间
-
年、季度、季节、月、星期、日、时 等;
- 基本特征,如果用 Xgboost 模型可以进行 one-hot 编码;
- 如果类别比较多,可以尝试平均数编码(Mean Encoding)。
- 或者取 cos/sin 将数值的首位衔接起来,比如说 23 点与 0 点很近,星期一和星期天很近。
-
节假日、节假日第 n 天、节假日前 n 天、节假日后 n 天;
-
数据可能会随着节假日的持续而发生变化,比如说递减;
-
节假日前/后可能会出现数据波动;
-
不放假的人造节日如 5.20、6.18、11.11 等也需要考虑一下;
-
一天的某个时间段;
-
上午、中午、下午、傍晚、晚上、深夜、凌晨等;
-
年初、年末、月初、月末、周内、周末;
-
基本特征;
-
高峰时段、是否上班、是否营业、是否双休日;
-
主要根据业务场景进行挖掘。
# 年、季度、季节、月、星期、日、时
data_df['date'] = pd.to_datetime(data_df['date'], format="%m/%d/%y")
data_df['quarter']=data_df['date'].dt.quarter
data_df['month'] = data_df['date'].dt.month
data_df['day'] = data_df['date'].dt.day
data_df['dayofweek'] = data_df['date'].dt.dayofweek
data_df['weekofyear'] = data_df['date'].dt.week # 一年中的第几周
# Series.dt 下有很多属性,可以去看一下是否有需要的。
data_df['is_year_start'] = data_df['date'].dt.is_year_start
data_df['is_year_end'] = data_df['date'].dt.is_year_end
data_df['is_quarter_start'] = data_df['date'].dt.is_quarter_start
data_df['is_quarter_end'] = data_df['date'].dt.is_quarter_end
data_df['is_month_start'] = data_df['date'].dt.is_month_start
data_df['is_month_end'] = data_df['date'].dt.is_month_end
# 是否时一天的高峰时段 8~10
data_df['day_high'] = data_df['hour'].apply(lambda x: 0 if 0 < x < 8 else 1)
# 构造时间特征
def get_time_fe(data, col, n, one_hot=False, drop=True):
'''
data: DataFrame
col: column name
n: 时间周期
'''
data[col + '_sin'] = round(np.sin(2*np.pi / n * data[col]), 6)
data[col + '_cos'] = round(np.cos(2*np.pi / n * data[col]), 6)
if one_hot:
ohe = OneHotEncoder()
X = OneHotEncoder().fit_transform(data[col].values.reshape(-1, 1)).toarray()
df = pd.DataFrame(X, columns=[col + '_' + str(int(i)) for i in range(X.shape[1])])
data = pd.concat([data, df], axis=1)
if drop:
data = data.drop(col, axis=1)
return data
data_df = get_time_fe(data_df, 'hour', n=24, one_hot=False, drop=False)
data_df = get_time_fe(data_df, 'day', n=31, one_hot=False, drop=True)
data_df = get_time_fe(data_df, 'dayofweek', n=7, one_hot=True, drop=True)
data_df = get_time_fe(data_df, 'season', n=4, one_hot=True, drop=True)
data_df = get_time_fe(data_df, 'month', n=12, one_hot=True, drop=True)
data_df = get_time_fe(data_df, 'weekofyear', n=53, one_hot=False, drop=True)
2.聚合特征
2.1 统计值
基于历史数据构造长中短期的统计值,包括前 n 天/周期内的:
-
四分位数;
-
中位数、平均数、偏差;
-
偏度、峰度;
- 挖掘数据的偏离程度和集中程度;
-
离散系数;
-
挖掘离散程度
这里可以用自相关系数(autocorrelation)挖掘出周期性。
除了对数据进行统计外,也可以对节假日等进行统计,以刻画历史数据中所含节假日的情况。(还可以统计未来的节假日的情况。)
# 画出自相关性系数图
from panda
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%89%B9%E5%BE%81%E5%B7%A5%E7%A8%8B%E6%97%B6%E5%BA%8F%E7%89%B9%E5%BE%81%E6%8C%96%E6%8E%98%E7%9A%84%E5%A5%87%E6%8A%80%E6%B7%AB%E5%B7%A7/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


