熊飞猜你去哪飞猪用户旅行意图预测

分享嘉宾:熊飞 阿里巴巴 算法工程师
编辑整理:小赵
出品平台:DataFunTalk
导读: 旅行商品推荐和实物商品推荐不管从用户维度还是宝贝维度上都具有较大的差异,不管是度假商品、门票、酒店、交通都具有较强的目的地心智。针对旅行场景的特殊性,此次分享介绍飞猪在用户旅行意图预测上的技术沉淀,包括如何克服用户行为稀疏的问题以及如何通过融合用户多源的旅行行为获得更准确的意图刻画表达。主要包括以下几部分:
- 旅⾏场景下的算法策略现状
- ⻜猪⽤户旅⾏意图预测
- 总结
01 旅⾏场景下的算法策略现状
首先介绍下具体的预测场景。
1. 场景介绍
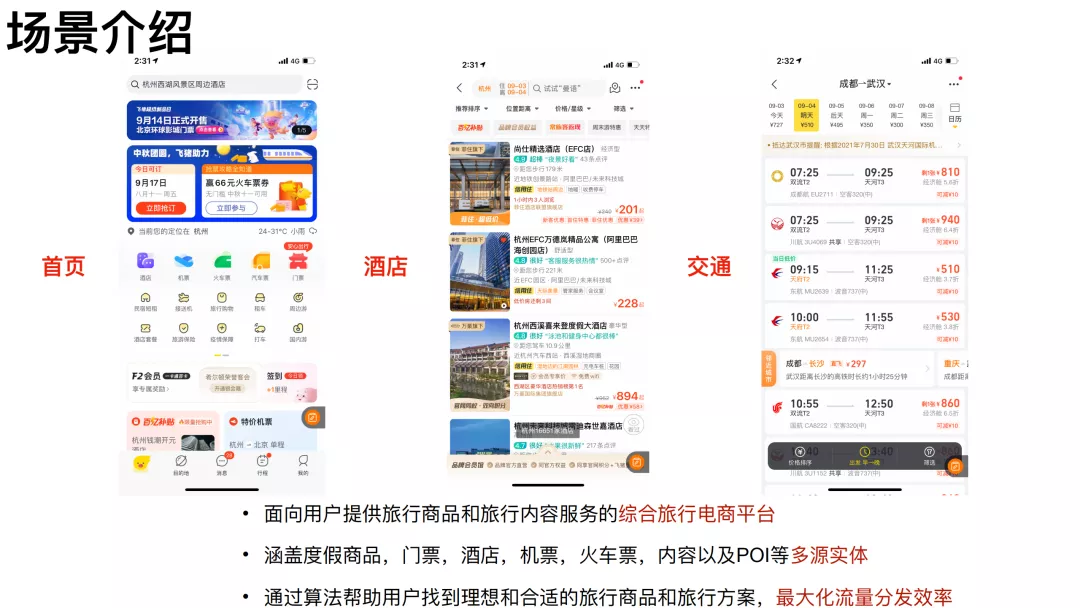
飞猪是面向用户提供旅行商品和旅行内容服务的一个综合电商平台,涵盖了非常多类目的旅行商品,包括度假商品、⻔票、酒店、机票、⽕⻋票、内容以及POI等多源实体,我们的目标是通过算法帮助用户找到理想和合适的旅行商品以及旅行方案,最大化流量分发效率。
2. 旅行场景的特质
旅行场景的特质可以总结为以下几点:
- ⽤户旅⾏是超低频需求,⽤户⾏为数据以及商品⾏为数据异常稀疏;
- ⽤户访问频次低、间隔⻓,上⼀次的访问信息可能失效,需要实时快速的捕捉当前⽤户的真实兴趣;
- 旅⾏具有明显的⾏前→⾏中→⾏后的状态转移过程,并且不同状态下存在明显的差异;
- ⽤户对旅⾏的决策期较⻓,会有明显的前瞻规划需求;
- 旅⾏具有丰富的混合LBS特质,包括跨城的⻓途旅⾏、跨区的周边游旅⾏以及跨⻢路的短途旅⾏;
- 旅⾏⾏为多源化,涵盖多个⾏为域,包括⽕⻋票,酒店,机票,度假宝⻉等;
- 旅⾏不是单点需求,是⼀个package需求,⼀次完整的旅⾏涵盖多个⾏为域的交叉。
02 飞猪用户旅行意图预测
1. 预测目标
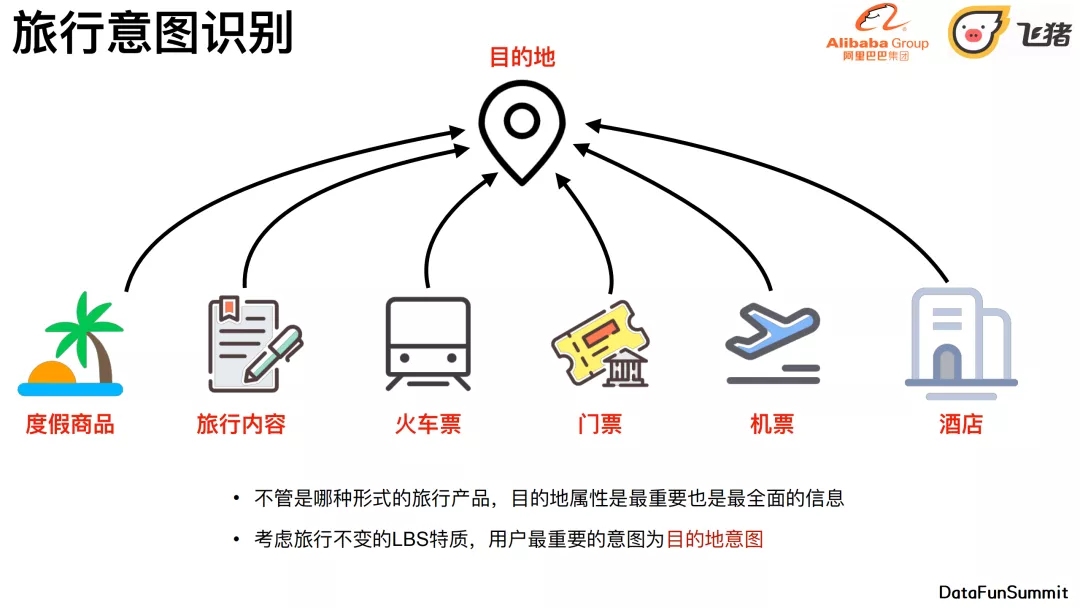
不管是哪种形式的旅⾏产品,⽬的地属性是最重要也是最全⾯的信息。考虑旅⾏不变的LBS特质,⽤户最重要的意图为⽬的地意图。所以我们的目标就是准确预测用户旅行意图(目的地偏好)。
针对前面提到的问题:
- 第一个问题,用户旅行是一个超低频的需求,那么我们在预估用户旅行意图的时候,在用户历史行为的一些信息去刻画的时候,时间必须要足够长,行为域要足够多。
- 第二个问题,用户访问频次低,间隔长。那么在考虑用户长期行为的时候,也必须把用户近期实时的行为考虑进来,并且在刻画意图的时候必须要考虑时间维度。
- 第三个问题,旅行行为多源化,不是单点需求。在考虑用户历史行为时,要充分融合用户多域的行为。
2. 多源行为的聚集性
不管是哪种形式的商品,在目的地上都是可以做到统一的。
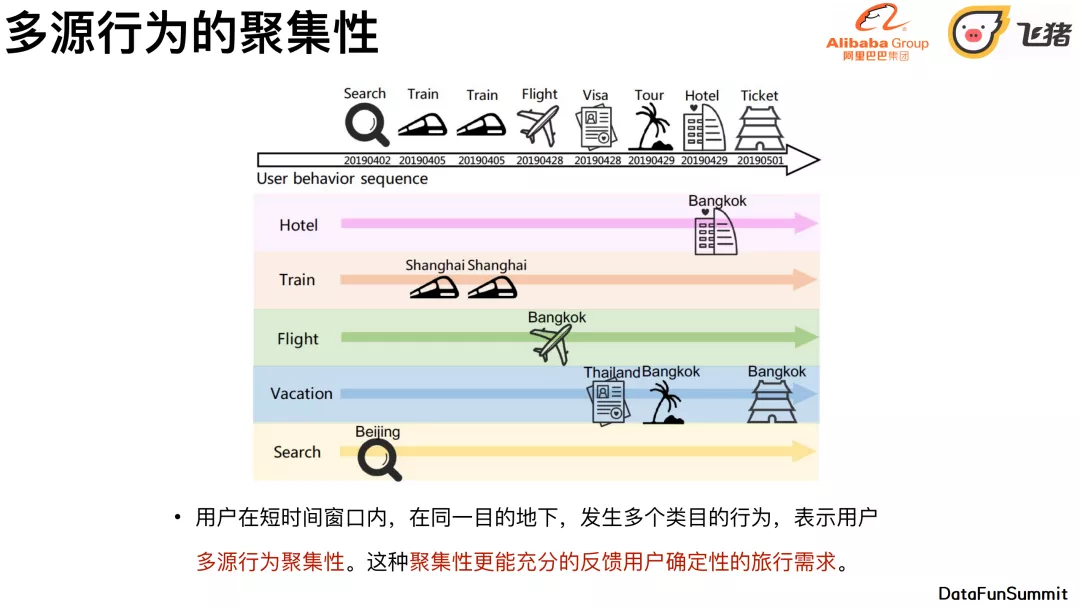
如上图,上部分是一个按照时间线的某用户的行为条,下部分不同颜色的纵轴表示不同的业务线,将不同的行为去映射到不同的行为线上不同的行为类目上面。比如说用户在上海,行为是购买了两次火车票,但是该用户没有产生预订相应自由行门票的行为,其实我们可以认为上海的旅行意图不是很稳定,有可能是出差,或者不是一个旅行的需求,可能是很随意的点击或者购买,所以就需要考虑到多源行为的聚合性。
多源行为的聚集性 :⽤户在短时间窗⼝内,在同⼀⽬的地下,发⽣多个类⽬的⾏为,表示⽤户多源⾏为聚集性。这种聚集性更能充分的反馈⽤户确定性的旅⾏需求。
3. 多源行为序列处理
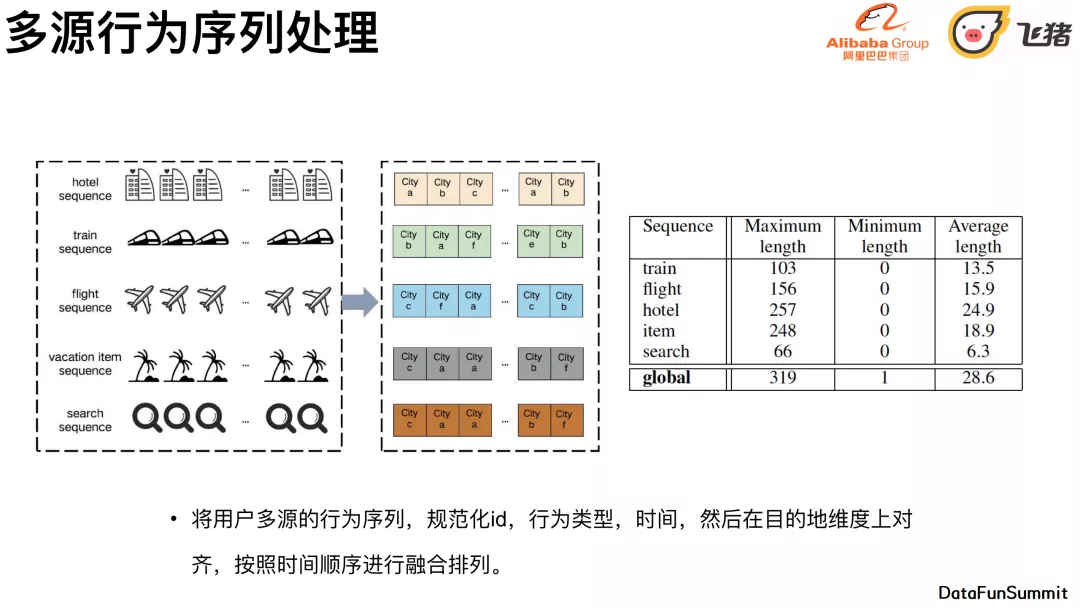
我们首先要将多源行为序列的埋点规范,采集规范,时序关系必须要统一。在这个基础上,我们要规范化id,统一⾏为类型、时间,⽬的地维度上对⻬,按照时间顺序进⾏融合排列。上图(右)可以看到五种行为序列的最大、最小长度,以及均值长度。最后的global就是融合上面所有的,可以看到经过融合后,长度扩大了很多。
4. 模型设计
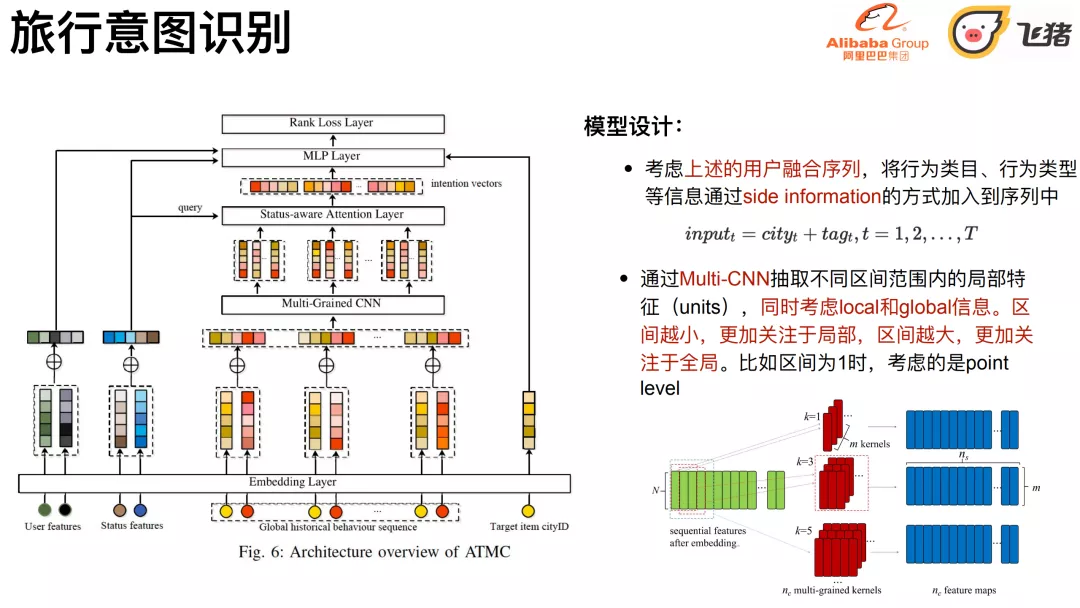
第一步: 考虑上述的⽤户融合序列,将⾏为类⽬、⾏为类型等信息通过side information的⽅式加⼊到序列中,主ID还是规范化ID。
第二步: 针对聚集性特点,通过Multi-CNN抽取不同区间范围内的局部特征(units),用一维卷积替代长序列上去做卷积,去产出进行局部units之后的结果。涉及到多粒度卷积,同时考虑local和global信息。区间越⼩,更加关注于局部,区间越⼤,更加关注于全局。⽐如区间为1时,考虑的是point level。
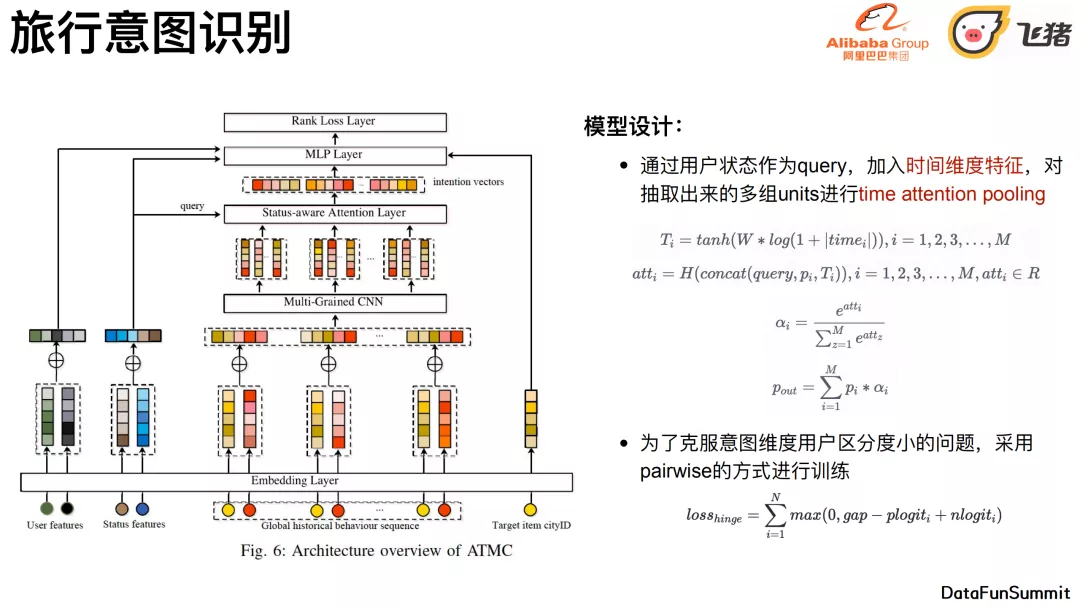
第三步 :通过⽤户状态作为query,加⼊时间维度特征,对抽取出来的多组units进⾏time attention pooling。(公式参见上图)
第四步 :为了克服意图维度⽤户区分度⼩的问题,采⽤pairwise的hinge loss的⽅式进⾏训练。(公式参见上图)
5. 模型实验
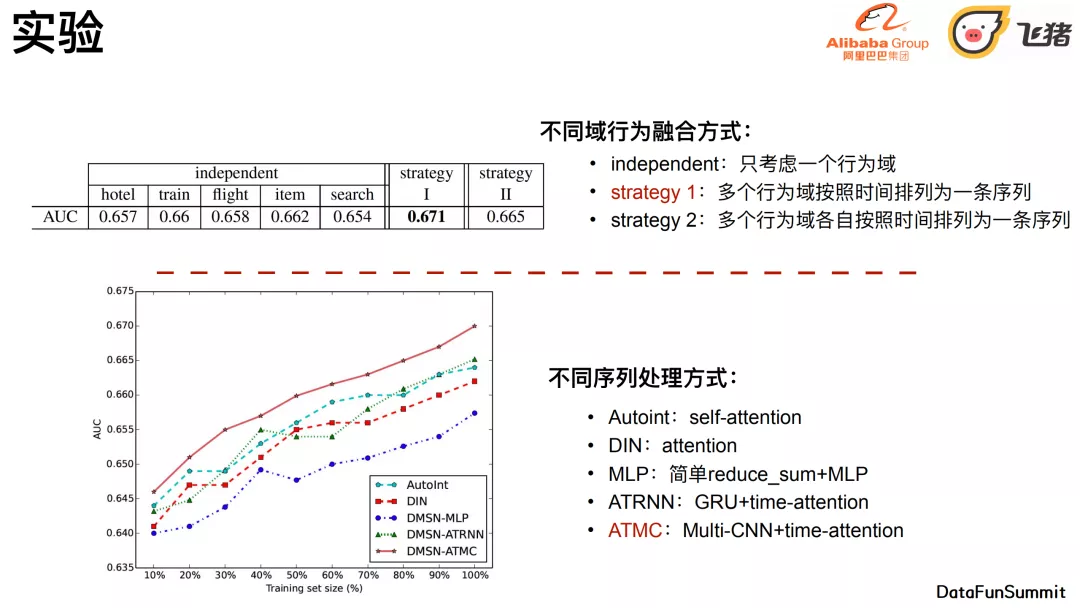
首先验证不同域⾏为融合⽅式是否有效果。
- independent:只考虑⼀个⾏为域
- strategy 1:多个⾏为域按照时间排列为⼀条序列
- strategy 2:多个⾏为域各⾃按照时间排列为⼀条序列
不同序列处理⽅式:
- Autoint:self-attention
- DIN:attention
- MLP:简单reduce_sum+MLP
- ATRNN:GRU+time-attention
- ATMC:Multi-CNN+time-attention
对比以上baseline,我们的多粒度卷积抽取加time-attention达到了一个比较稳定的效果。
6. 融合用户兴趣建模
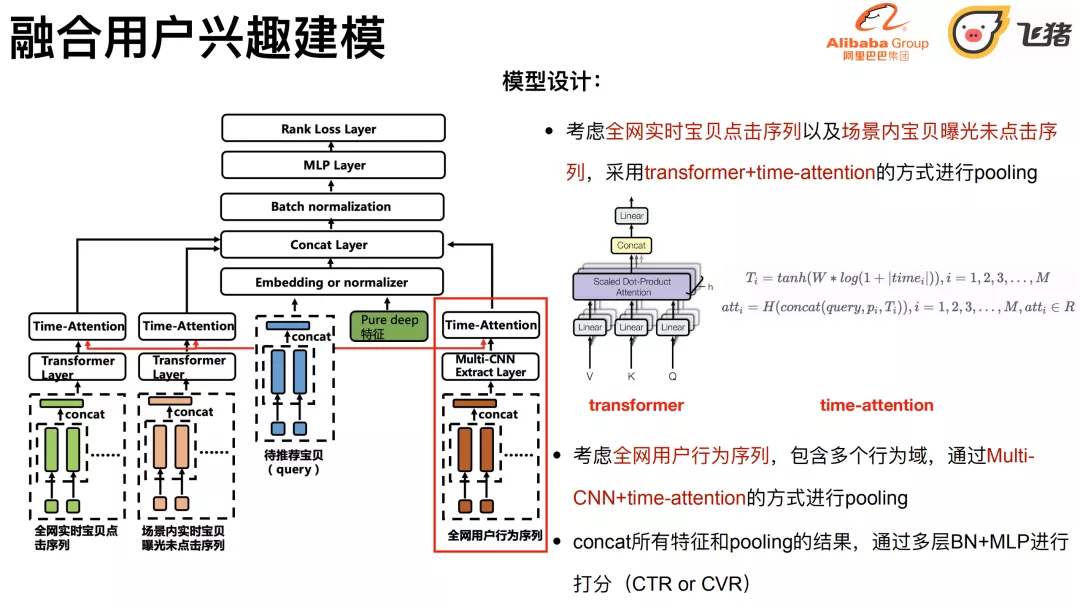
- 考虑全⽹实时宝⻉点击序列以及场景内宝⻉曝光未点击序列,采⽤transformer + time-attention的⽅式进⾏pooling。
- 考虑全⽹⽤户⾏为序列,包含多个⾏为域,通过MultiCNN + time-attention的⽅式进⾏pooling。
- concat所有特征和pooling的结果,通过多层BN + MLP进⾏打分(CTR or CVR)
7. 融合实验结果
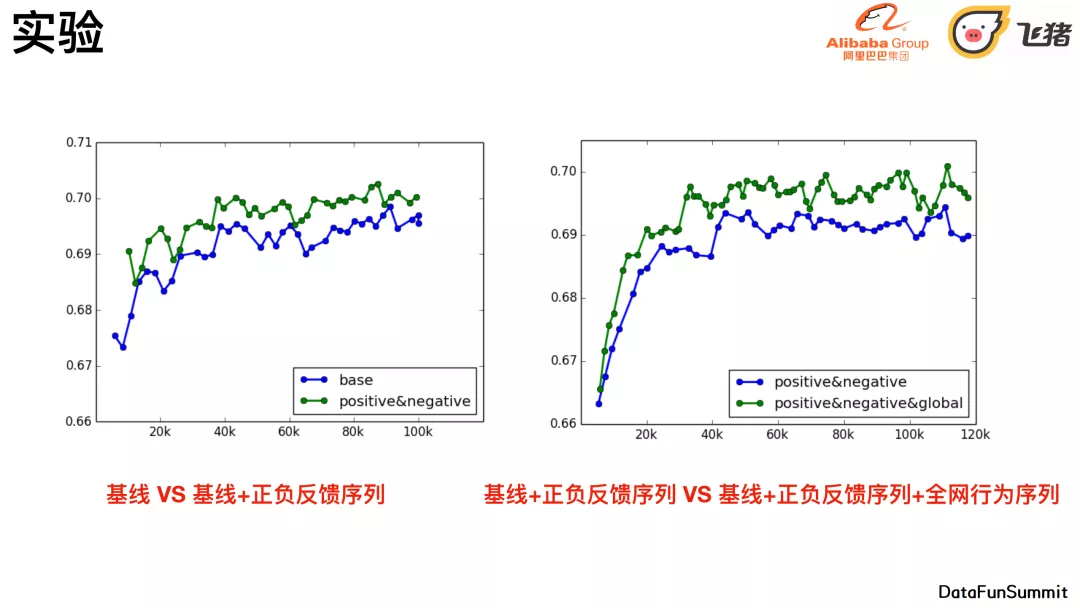
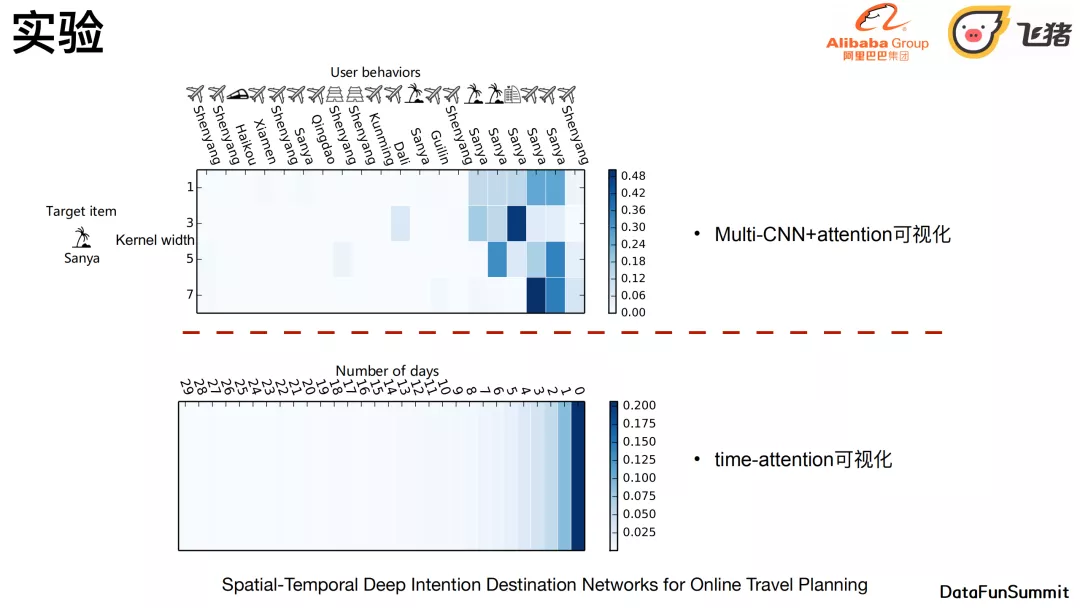
左图包括正负反馈,但在这个的基础上,我们把刚刚说的多力度卷积提取用户全网行为去或多源融合序列的结果,做一个可提高的结构加进来之后,在这个基础上会有比较稳定的提升。
03 总结
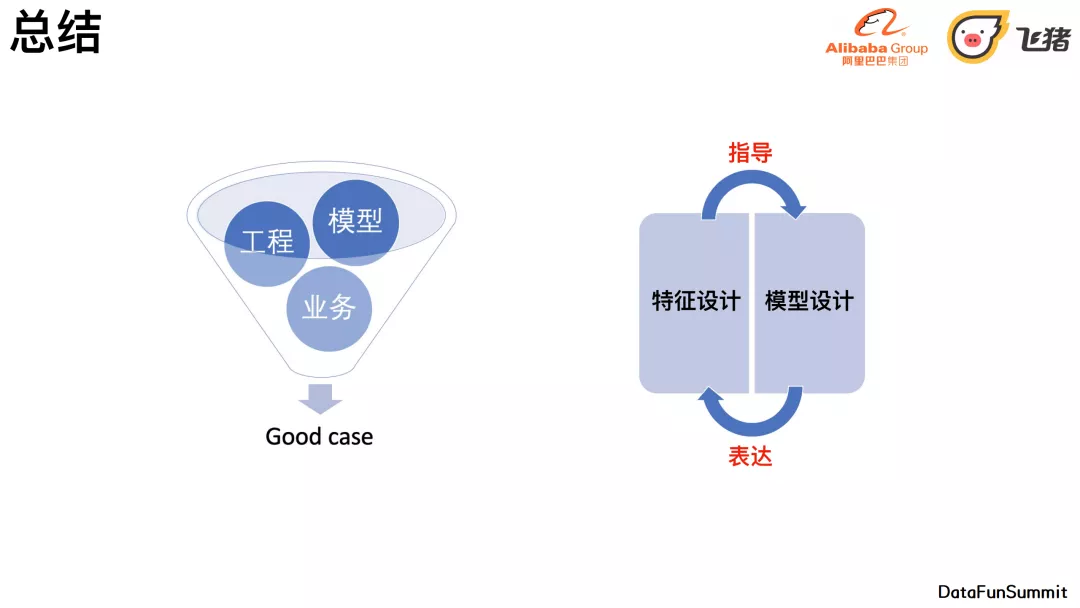
我们做模型时,首先考虑的是需要哪些特征,然后在这些特征的基础上,去考核这部分特征和信息的特点,去完成相应的模型设计,从而让我们设计的模型更加充分地去表达我们想要拟合的特征。用特征去指导模型设计,再想模型怎么更好的去表达特征,形成一个回环。
模型只是整个项目中的一部分,若想要更好的推荐结果和good case,其实是业务、工程和模型等多方面来共同保证的。
04 精彩问答
Q:请问旅行意图的预测主要输出是什么?旅行意图是否有其他方向的应用?
A:输出其实有很多种形式,我们开始做这个事情的时候,当时的输�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%86%8A%E9%A3%9E%E7%8C%9C%E4%BD%A0%E5%8E%BB%E5%93%AA%E9%A3%9E%E7%8C%AA%E7%94%A8%E6%88%B7%E6%97%85%E8%A1%8C%E6%84%8F%E5%9B%BE%E9%A2%84%E6%B5%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


