火灾检测烟雾检测古文预训练语言模型等开源项目分享
项目一:FinBERT基于 BERT 架构的金融领域预训练语言模型
项目地址:
https://github.com/valuesimplex/FinBERT
为了促进自然语言处理技术在金融科技领域的应用和发展,熵简科技 AI Lab 近期开源了基于 BERT 架构的金融领域预训练语言模型 FinBERT 1.0。据我们所知,这是国内首个在金融领域大规模语料上训练的开源中文BERT预训练模型。相对于Google发布的原生中文BERT、哈工大讯飞实验室开源的BERT-wwm 以及 RoBERTa-wwm-ext 等模型,本次开源的 FinBERT 1.0 预训练模型在多个金融领域的下游任务中获得了显著的性能提升,在不加任何额外调整的情况下,F1-score 直接提升至少 2~5.7 个百分点。
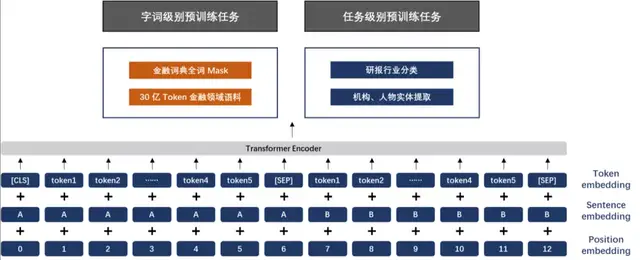
FinBERT 采用了两大类预训练任务,分别是字词级别的预训练和任务级别的预训练。两类预训练任务的细节详述如下:
(1)字词级别的预训练
字词级别的预训练首先包含两类子任务,分别是 Finnacial Whole Word MASK(FWWM)、Next Sentence Prediction(NSP)。同时,在训练中,为了节省资源,我们采用了与 Google 类似的两阶段预训练方式,第一阶段预训练最大句子长度为128,第二阶段预训练最大句子长度为 512。两类任务具体形式如下:
Finnacial Whole Word MASK(FWWM)
Whole Word Masking (wwm),一般翻译为全词 Mask 或整词 Mask,出是 Google 在2019年5月发布的一项升级版的BERT中,主要更改了原预训练阶段的训练样本生成策略。简单来说,原有基于WordPiece的分词方式会把一个完整的词切分成若干个子词,在生成训练样本时,这些被分开的子词会随机被mask。在全词Mask中,如果一个完整的词的部分WordPiece子词被 Mask,则同属该词的其他部分也会被 Mask,即全词Mask。
在谷歌原生的中文 BERT 中,输入是以字为粒度进行切分,没有考虑到领域内共现单词或词组之间的关系,从而无法学习到领域内隐含的先验知识,降低了模型的学习效果。我们将全词Mask的方法应用在金融领域语料预训练中,即对组成的同一个词的汉字全部进行Mask。首先我们从金融词典、金融类学术文章中,通过自动挖掘结合人工核验的方式,构建出金融领域内的词典,约有10万词。然后抽取预语料和金融词典中共现的单词或词组进行全词 Mask预训练,从而使模型学习到领域内的先验知识,如金融学概念、金融概念之间的相关性等,从而增强模型的学习效果。
Next Sentence Prediction(NSP)
为了训练一个理解句子间关系的模型,引入一个下一句预测任务。具体方式可参考BERT原始文献,Google的论文结果表明,这个简单的任务对问答和自然语言推理任务十分有益,我们在预训练过程中也发现去掉NSP任务之后对模型效果略有降低,因此我们保留了NSP的预训练任务,学习率采用Google 官方推荐的2e-5,warmup-steps为 10000 steps。
(2)任务级别的预训练
为了让模型更好地学习到语义层的金融领域知识,更全面地学习到金融领域词句的特征分布,我们同时引入了两类有监督学习任务,分别是研报行业分类和财经新闻的金融实体识别任务,具体如下:
研报行业分类
对于公司点评、行业点评类的研报,天然具有很好的行业属性,因此我们利用这类研报自动生成了大量带有行业标签的语料。并据此构建了行业分类的文档级有监督任务,各行业类别语料在 5k~20k 之间,共计约40万条文档级语料。
财经新闻的金融实体识别
与研报行业分类任务类似,我们利用已有的企业工商信息库以及公开可查的上市公司董监高信息,基于金融财经新闻构建了命名实体识别类的任务语料,共包含有 50 万条的有监督语料。
整体而言,为使 FinBERT 1.0 模型可以更充分学习到金融领域内的语义知识,我们在原生 BERT 模型预训练基础上做了如下改进:
- 训练时间更长,训练过程更充分。为了取得更好的模型学习效果,我们延长模型第二阶段预训练时间至与第一阶段的tokens总量一致;
- 融合金融领域内知识。引入词组和语义级别任务,并提取领域内的专有名词或词组,采用全词 Mask的掩盖方式以及两类有监督任务进行预训练;
- 为了更充分的利用预训练语料,采用类似Roberta模型的动态掩盖mask机制,将dupe-factor参数设置为10。
项目二:guwenbert 古文预训练语言模型(古文BERT)
项目地址:
https://github.com/Ethan-yt/guwenbert
GuwenBERT是一个基于大量古文语料的RoBERTa模型。
在自然语言处理领域中,预训练语言模型(Pre-trained Language Models)已成为非常重要的基础技术。目前互联网上存在大量的现代汉语BERT模型可供下载,但是缺少古文的语言模型。为了进一步促进古文研究和自然语言处理的结合,我们发布了古文预训练模型GuwenBERT。
对于古文的常见任务:断句,标点,专名标注,目前通常采用序列标注模型。这类模型非常依赖预训练的词向量或者BERT,所以一个好的语言模型可以大幅提高标注效果。经过实验,在古文NER任务中我们的BERT比目前最流行的中文RoBERTa效果提升6.3%,仅仅300步就可以达到中文RoBERTa的最终水平,特别适合标注语料不足的小数据集。使用我们的模型也可以减少数据清洗,数据增强,引入字典等繁琐工序,在评测中我们仅仅用了一个BERT+CRF的模型就可以达到第二名。
- GuwenBERT基于殆知阁古代文献语料训练,其中包含15,694本古文书籍,字符数1.7B。所有繁体字均经过简体转换处理。
- GuwenBERT的词表是基于古文语料构建的,取其中高频字符,大小为23,292。
- 基于继续训练技术(Continue Training),GuwenBERT结合现代汉语RoBERTa权重和大量古文语料,将现代汉语的部分语言特征向古代汉语迁移以提升表现。
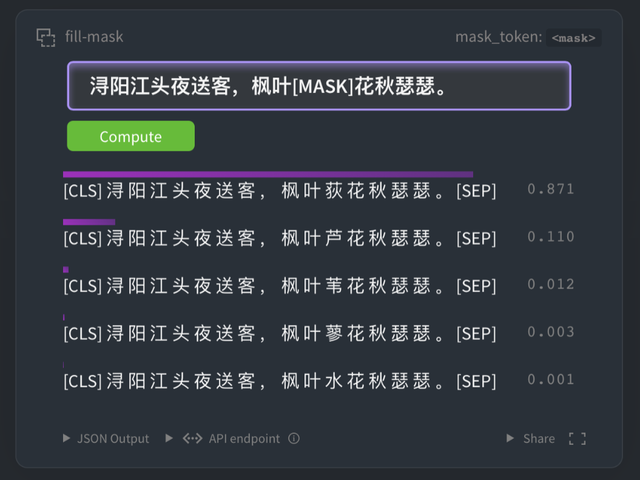
通过huggingface官网直接下载:
https://huggingface.co/ethanyt/guwenbert-base
https://huggingface.co/ethanyt/guwenbert-large
评测结果:
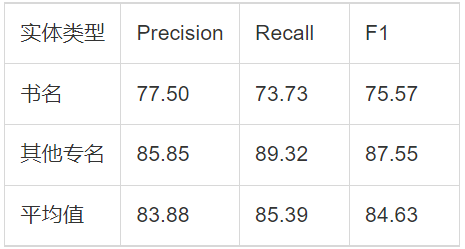
具体任务为:根据给定的古籍篇章,将候选篇章中的命名实体提取出来,并且按照既定类别进行归并。提取出来的实体名称大致分为两类:书名和其他专名(含人名、地名、朝代名、民族名等)。
数据集方面:分为训练数据和评测数据,涉及经、史、子、集等1900多篇古籍文本。训练数据为带有标签的文本文件,共计1063291字符(计空格),含11068组书名,10040组专名。
项目三:fire-detect-yolov4 火灾检测,烟雾检测
项目地址:
https://github.com/gengyanlei/fire-detect-yolov4

安装环境:
- python: 3.6+
- ubuntu16.04 or 18.04
- darknet (cuda10.0 docker)
- pytorch 1.6+ (cuda10.2 docker)
烟火检测数据集包含的场景类型:
大火-小火,建筑起火、草原起火、森林起火、车辆(汽车、卡车、摩托车、电动车)起火、白天-黑夜起火、室内-室外起火。
烟火检测数据集(按照Pascal VOC格式排列):
- –VOC2020
- –Annotations (xml_num: 2059)
- –ImageSets(Main)
- –JPEGImages (image_num: 2059)
- –label_name: fire
项目四:yolodet-pytorch端到端基于pytorch框架复现yolo最新算法的目标检测开发套件
项目地址:
https://github.com/wuzhihao7788/yolodet-pytorch
YOLODet-PyTorch是端到端基于pytorch框架复现yolo最新算法的目标检测开发套件,旨在帮助开发者更快更好地完成检测模型的训练、精度速度优化到部署全流程。YOLODet-PyTorch以模块化的设计实现了多种主流YOLO目标检测算法,并且提供了丰富的数据增强、网络组件、损失函数等模块。
目前检测库下模型均要求使用PyTorch 1.5及以上版本或适当的develop版本。
特性:
- 模型丰富:
- YOLODet提供了丰富的模型,涵盖最新YOLO检测算法的复现,包含YOLOv5、YOLOv4、PP-YOLO、YOLOv3等YOLO系列目标检测算法。
- 高灵活度:
- YOLODet通过模块化设计来解耦各个组件,基于配置文件可以轻松地搭建各种检测模型。
支持的模型:
- YOLOv5(s,m,l,x)
- YOLOv4(标准版,sam版)
- PP-YOLO
- YOLOv3
更多的Backone:
- DarkNet
- CSPDarkNet
- ResNet
- YOLOv5Darknet
损失函数支持:
- bbox loss (IOU,GIOU,DIOU,CIOU)
- confidence loss(YOLOv4,YOLOv5,PP-YOLO)
- IOU_Aware_Loss(PP-YOLO)
- FocalLoss
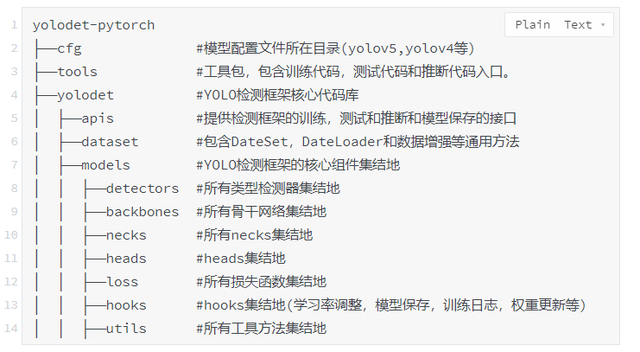
代码结构说明:
项目五:TDC 治疗数据共享
项目地址:
https://github.com/mims-harvard/TDC
Therapeutics Data Commons(TDC)是第一个统一的框架,可以系统地访问和评估整个治疗领域的机器学习。
TDC中收集的数据集、学习任务和基准,是领域和机器学习科学家的交汇点。我们设想,TDC可以大大加快机器学习模型的开发、验证以及向生物医学和临床实施的过渡。
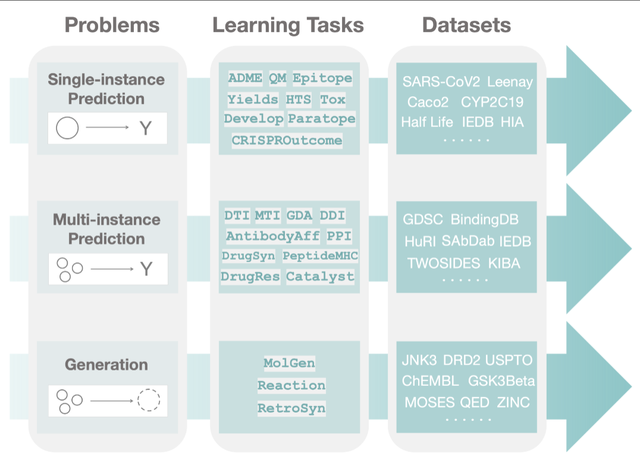
特点:
- 疗法开发的多样化领域。TDC涵盖了广泛的学习任务,包括小分子、抗体和疫苗等生物医药产品的目标发现、活性筛选、疗效、安全性和生产。
- 随时可用的数据集。TDC对外部软件包的依赖性最小。任何TDC的数据集只需用3行代码就可以检索到。
- 数据功能。TDC提供广泛的数据功能,包括数据评估器、有意义的数据拆分、数据处理器和分子生成器。
- 排行榜。TDC为公平的模型比较提供基准,并提供系统的模型开发和评估。
- 开源倡议。TDC是一个开放源码的倡议。如果你想参与,请告诉我们。
设计:
- TDC有一个独特的三层层次结构,据我们所知,这是第一次尝试系统地组织机器学习的治疗方法。我们将TDC组织成三个不同的问题。对于每个问题,我们都给出了一个学习任务集合。最后,对于每个任务,我们提供一系列的数据集。
- 在第一层中,在观察了大量的治疗学任务后,我们将机器学习可以促进科学进步的三个主要领域(即问题)分类并抽象出来,即单实例预测、多实例预测和生成。
- 单实例预测 single_pred: 对给定的单个生物医学实体的属性进行预测。
- 多实例预测 multi_pred: 对多个生物医学实体的属性进行预测。
- 生成生成。生成新的理想的生物医学实体。
- TDC结构中的第二层被组织为学习任务。这些任务的改进可以带来许多应用,包括识别个性化的组合疗法,设计新型的抗体类别,改善疾病诊断,以及为新出现的疾病寻找新的治疗方法。
- 最后,在TDC的第三层,每个任务通过多个数据集进行实例化。对于每�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%81%AB%E7%81%BE%E6%A3%80%E6%B5%8B%E7%83%9F%E9%9B%BE%E6%A3%80%E6%B5%8B%E5%8F%A4%E6%96%87%E9%A2%84%E8%AE%AD%E7%BB%83%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E7%AD%89%E5%BC%80%E6%BA%90%E9%A1%B9%E7%9B%AE%E5%88%86%E4%BA%AB/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


