滴滴集群跨版本升级与平台重构之路

分享嘉宾:赵情融 滴滴专家工程师
编辑整理:王洪达
出品平台:DataFunTalk
导读: 前不久,滴滴ES团队将维护的30多个ES集群,3500多个ES节点,8PB的数据,从2.3.3跨大版本无缝升级到6.6.1。在对用户查询写入基本零影响和改动的前提下,解决了ES跨大版本协议不兼容、文件格式不兼容、mapping不兼容等难题,整个过程对绝大部分用户完全透明。同时还完成了Arius的架构升级,取得了单机查询性能提升40%,整体集群cpu下降10%,写入tps提升30%,集群资源使用率提升20%、0故障、运维成本下降60%的成绩。
本文将系统的介绍滴滴在从2.3.3跨大版本升级到6.6.1过程中的遇到的问题和解决方案,以及在搜索平台建设过程中的体系化思考。
01 背景介绍
1. 集群规模

目前滴滴使用的ES版本是2.3.3,集群个数有40多个,节点规模有3500+,集群总容量有8PB。
2. 业务规模

1200多个平台应用方在使用ES,30多个核心应用在使用ES,写入的TPS有1500W,查询的QPS有25W。
02 问题分析
针对以上规模的ES集群,从2.3.3升级到6.X版本,小版本会根据最后分析的结果确定,需要对潜在可能的问题进行分析和区分。
1. 问题分析
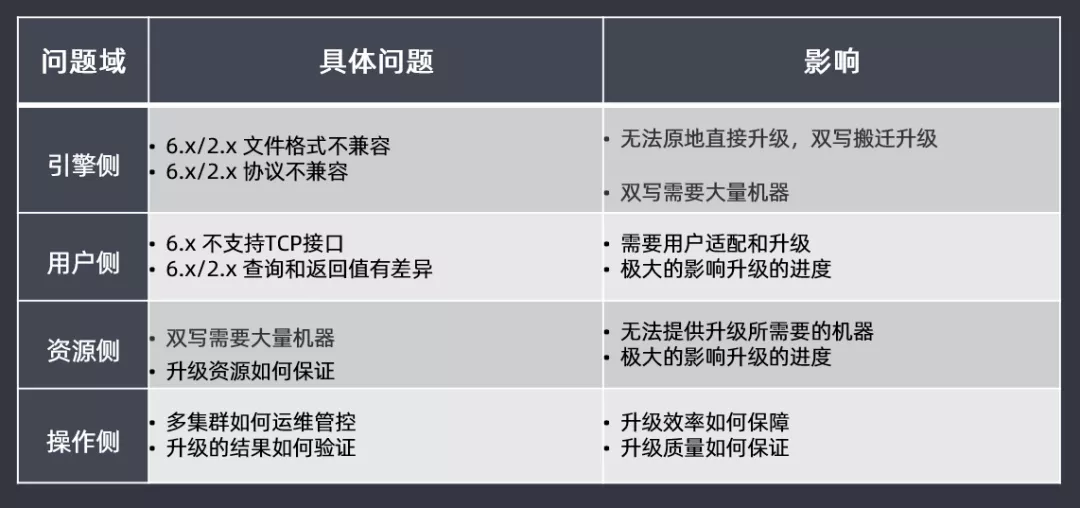
主要先从四大问题域进行区分分析:
- 引擎侧:由于从2.3.3升级到6.X版本,版本差距过大,在文件格式和协议上都不兼容,因此无法进行原地滚动直接升级,需要双写搬迁升级,这样会耗费大量的机器去参与其中
- 用户侧:6.X版本开始逐渐的不支持TCP接口,因此需要用户适配和升级;查询和返回值也有一定差异,如果用户侧做适配,会极大影响升级的进度
- 资源侧:由于无法直接原地滚动直接升级,需要双写使用大量的机器,但是无法提供升级所需要的机器,如果升级过程中资源无法得到保障,那也会极大影响升级的进度
- 操作侧:新版本的多集群如何进行运维管控?升级的结果如何验证?查询的效率和质量如何保障和保证的?这些问题都需要考虑
2. 升级思路
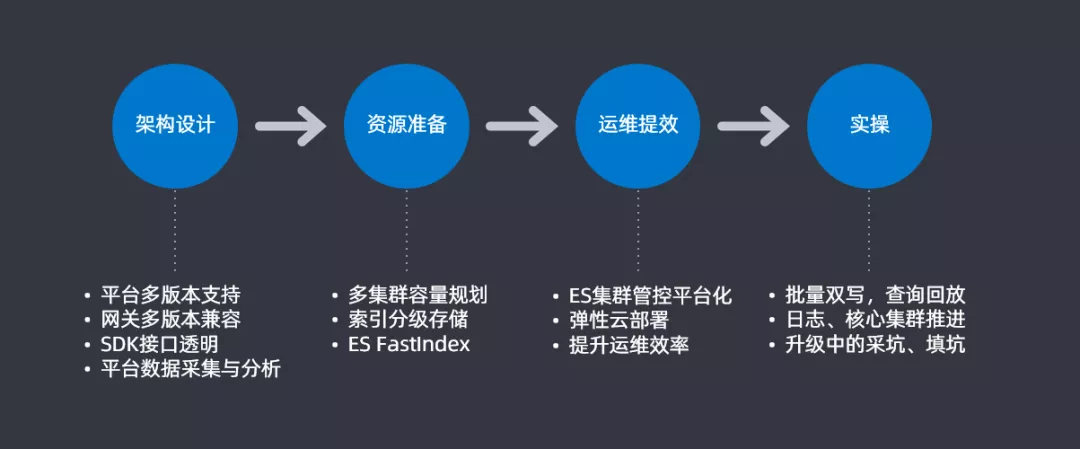
根据上一部分问题的汇总和分类,形成了一个大致的升级思路并会根据这四大步骤来解决具体的问题。
- 架构设计:平台支持多版本支持,查询网关上进行多版本兼容,在查询和插入使用SDK时候要做到SDK接口的透明,最后要做一个平台数据采集和分析用于后续做升级的分析对比
- 资源准备:进行合理的多集群容量规划来提高资源使用率,尽可能的节省机器;设计索引分级存储来提升资源的利用率;还针对大索引迁移开发了一个插件FastIndex也用来提升资源利用率
- 运维绩效:开发ES集群管控平台,将ES集群管控平台化和图表化;通过Docker的方式来提升部署和运维的效率
- 实操:在实际操作中,需要实现批量双写以及查询回放的功能;需要对业务进行区分,实现日志和核心集群的分步推进;最后就是升级过程中会遇到一些坑,需要把坑都填满,后续会详细介绍一下这些坑
3. 升级方案

上面是升级思路,接下来介绍一下升级方案:
- 架构:ES多版本支持的架构改造,同时支持2.3.3以及6.X版本;开发一套多集群管控平台,用于滴滴内部ES多个集群的管控;同时还开发了一套ES服务元数据体系建设
- 资源:设计ES分级存储体系;开发ES-FastIndex离线数据导入的插件;最后构建了一套ES集群容量规划方案来提升集群的资源使用率,节约资源成本
- 实操:通过ES多集群搭建、ES流量回放对比系统、ES版本升级采坑分享来完成升级和对比的一个过程
03 方案介绍
1. 架构
① 架构重构
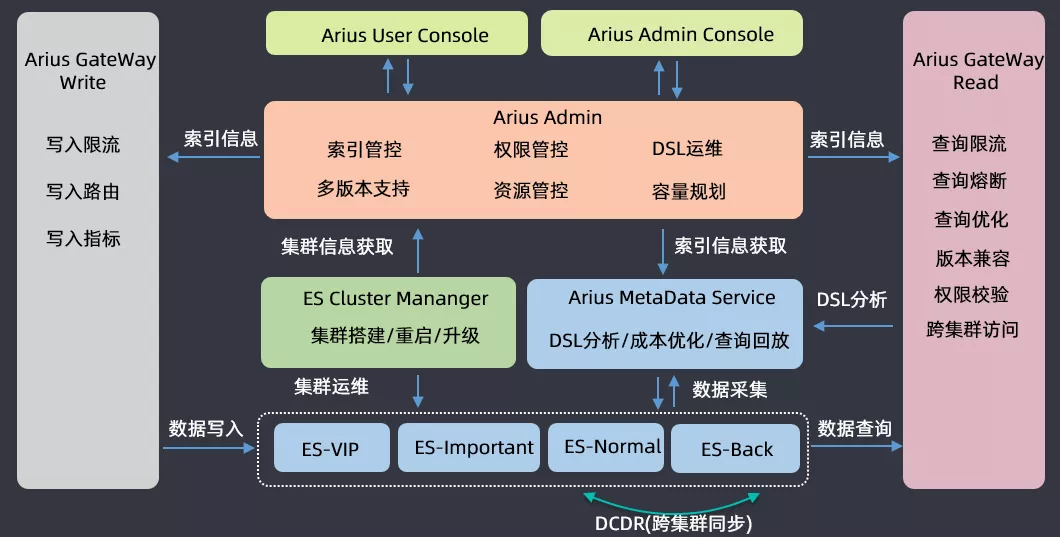
介绍一下滴滴搜索平台(Arius)的架构,业务方使用ES搜索进行读写请求时都会经过网关;运维的时候会根据集群的重要程度进行划分,会将四十多个集群划分为VIP、Important、Normal、Backup四类,开发了一个DCDR工具用于跨集群的数据同步;在ES集群运维之上开发了三大组件,一个是ES Cluster Manager,用于集群的搭建、重启和升级混合操作的平台;第二个是集群ES的数据分析构建了一个Arius Metadata Service的元数据管理服务,用于做DSL分析、成本优化和查询回放;在这两个系统之上有一套Arius Admin管控系统,包含索引管控、权限管控、DSL运维、多版本支持、资源管控以及容量规划等功能;基于Arius Admin,构建了两套面向运维和用户的管控平台前端工程。
以上就是滴滴搜索平台的整体架构,然后基于此来做ES的版本升级。
② 升级流程
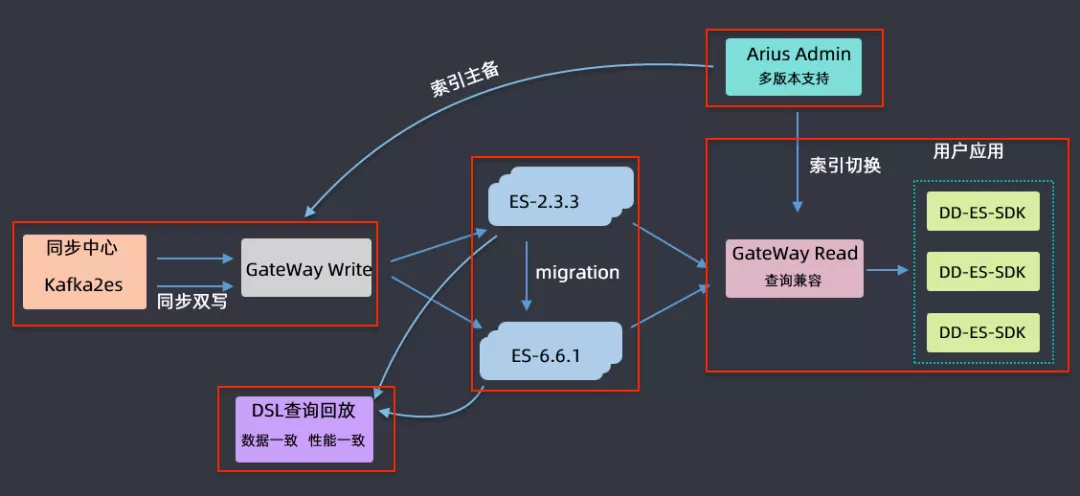
上图为升级的流程,首先是要升级对ES集群的管控,要支持2.3.3和6.6.1两个版本;对每个要升级的索引要进行主备索引的创建,创建完毕后通过双写的形式对主和备都同时写入到新的索引中,对于历史索引采取的是这样一个策略:在双写之前,主备创建之后,会暂停历史数据的写入,把历史数据通过migration的方式从低版本迁移到高版本中,迁移完后再进行双写;在迁移完成,双写链路打开之后,做一个DSL数据回放,由于用户的读写都是通过gateway进行的,所以可以拿到用户的DSL语句和返回数据来进行一个高低版本的查询、对比和分析,如果最后比对结果是数据一致、性能也一致,那就认为该索引在高低版本中迁移是成功的。如果迁移成功,会在网关层完成用户查询的向高版本的切换,如果切换完成后,业务方运行没有问题就会将低版本的索引下线掉,最终就完成了索引由低版本向高版本升级的过程。
③ GateWay兼容性
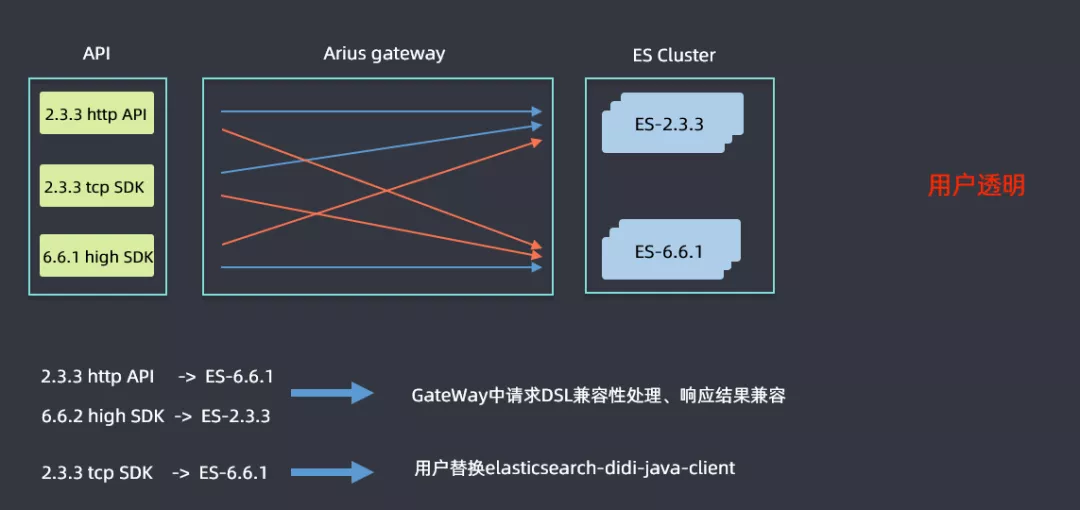
升级是一个比较漫长的过程,高低版本集群会并行运行一段时间,用户使用的SDK也会高低版本共存,这样就需要解决高低版本兼容性的问题。查询可能会分为上图六条线标识的六种情况,蓝色线表明不需要进行改造直接进行查询的,2.3.3的http和tcp sdk查询2.3.3ES集群,6.6.1 high sdk查询6.6.1的ES集群都是没有问题的;红色线表明是需要考虑兼容性问题进行改造的,例如2.3.3的sdk查询6.6.1的ES集群时候语法的差异性问题等,然后ES高版本中会逐渐取消掉tcp的查询接口,但是滴滴内部还是有很多用户是使用tcp方式查询的,如果需要用户进行代码改造的话流程会非常漫长,因此在Gateway层面做了一些兼容性处理:在2.3.3http api和6.6.1 high sdk查询6.6.1集群和2.3.3集群时候,做了请求DSL的兼容性处理和响应结果兼容,解决了用户的痛点;对于使用tcp方式查询的用户,开发了一个elasticsearch-didi-java-client的sdk,用户替换一下pom即可,表面上还是使用tcp的方式,但是在网关层面已经将其转换为了http查询的方式。这样就做到了用户透明。
④ ES集群管控平台
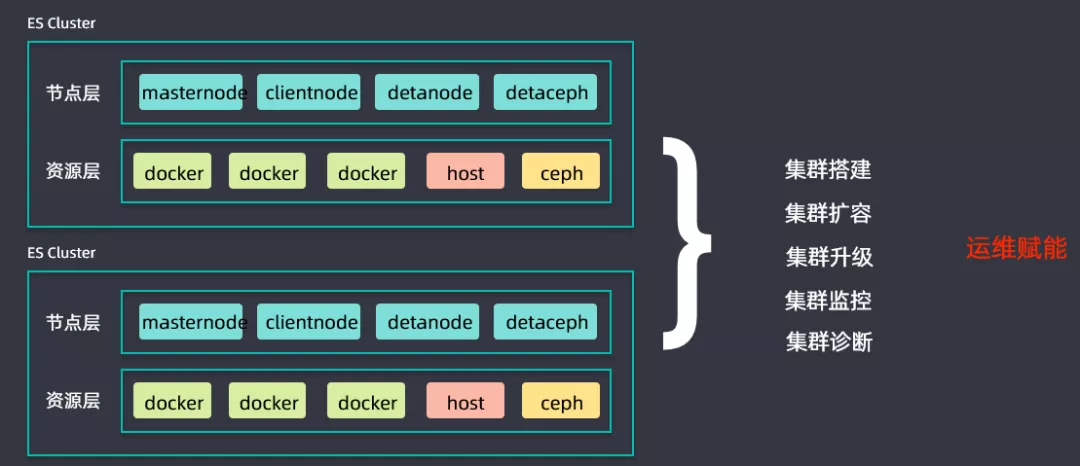
同时搭建了一套ES集群管控平台,用于进行集群搭建、集群扩容、集群升级、集群监控以及集群诊断等工作,为升级过程中的运维赋能,提升升级推进进度。
⑤ 元数据服务
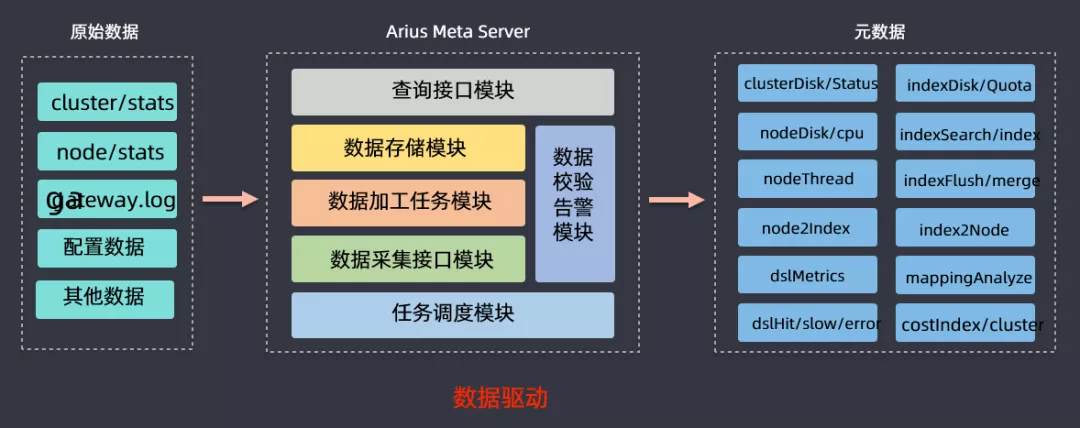
前面介绍的时候有讲到元数据服务,该模块的作用就是提供一个ES集群和业务方的数据的分析,然后获取cluster/stats、node/stats、日志、监控数据等信息进行分析,最后可以得到节点磁盘使用状况、DSL查询情况(慢查、错误查询),基于此来做容量规划、分级存储、查询回放等数据驱动型工作。
⑥ DSL服务
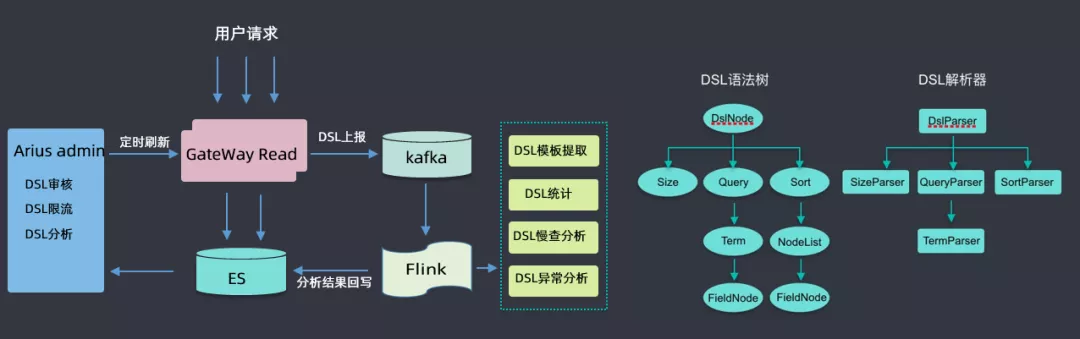
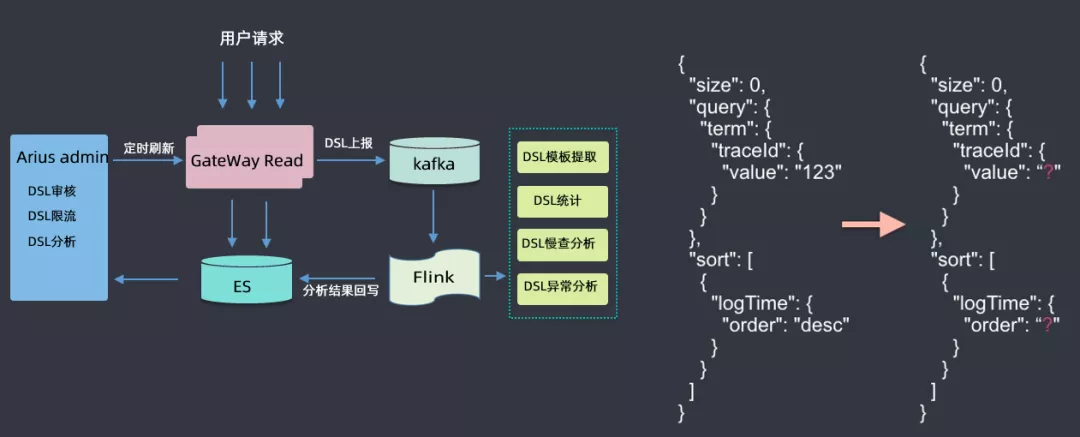
此处着重介绍一下DSL服务,用户所有请求都会通过网关,经过网关时会收集到kafka,然后用flink做一些分析,如DSL模板提取(具体查询参数去掉,抽象为模板)、DSL统计、DSL慢查分析、DSL异常分析等,然后将分析结果回写到ES集群中;然后根据这些分析的数据来做DSL审核(用户可能会查询滴滴的核心索引,此处需要审核才能查询)、DSL限流(有的DSL里面会有大量的聚合查询,此处会进行一定限流)、DSL分析(首先会对DSL语句进行语法树的解析,解析后会生成一个无参的查询模板)等。
2. 资源
① 容量规划
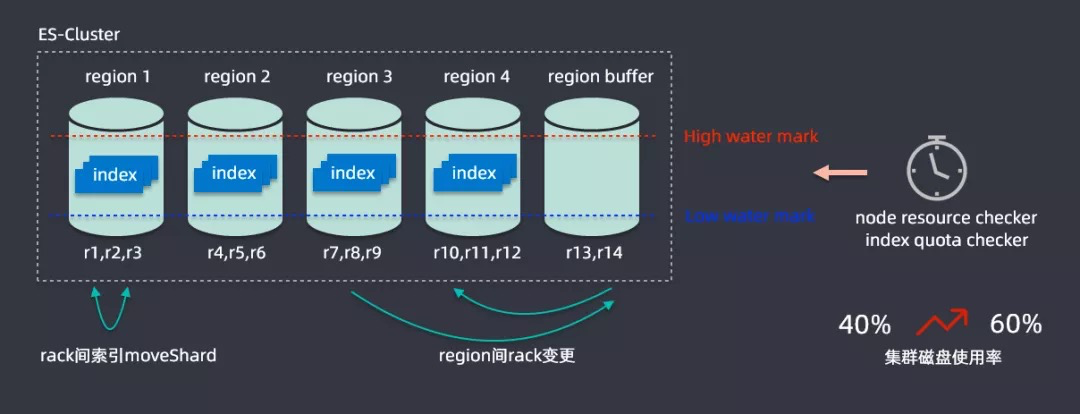
接下来将一些如何在升级过程中解决资源问题,为此开发了一个容量规划的算法,ES缺乏一个多节点之间索引均匀分布的功能;在滴滴内部最大的集群是在两百多个节点,承载容量在PB级别,索引有上千个,在写入索引时候可能流量分布式不均匀的,很有可能有索引节点的热点存在。
解决思路为将两百多个节点进行划分为五个region,一个region都会有很多节点组成,如r1、r2、r3组成,划分之后就可以计算每个region中节点磁盘的使用情况,设置一个高水位线和低水位线,通过分析每个region的数据情况,region超过高水位就会通过rack变更进行扩容,region内部会监控不同节点的使用情况,通过rack建索引mockShard进行均衡,从而整体提升资源利用率,通过该算法后集群磁盘的使用率从百分之四十提升到百分之六十,这样就节省了大量的资源。
② 分级存储
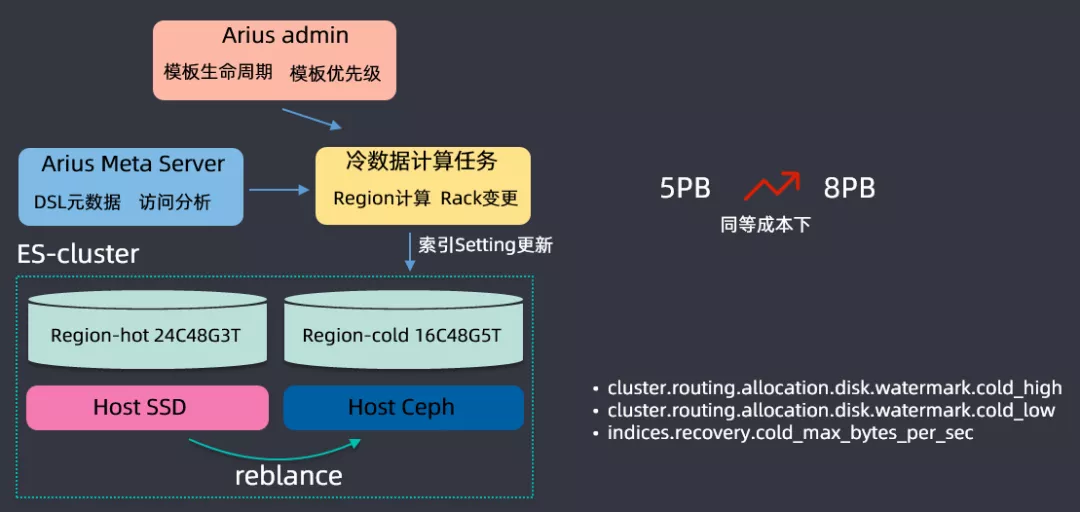
基于用户查询和保存的操作进行一个数据分析,开发了一个ES分级存储的体系,搭建ES集群时候主要基于两种磁盘进行搭建的,一种是SSD磁盘,另一种是Ceph(可以理解为HDD磁盘组成的网络磁盘);SSD磁盘非常贵,但是查询性能特别好,会存储一些查询频繁的数据,Ceph磁盘比较便宜,但是查询IO性能比较低,存储查询不是那么频繁的数据;根据用户查询的频率,将数据区分为冷数据和热数据,根绝查询的DSL来分析索引的保留期限,在滴滴内部基本上索引都是按天保存的(举个例子:日志都是按天建索引保存的),三天之内的放到SSD上保存,三天之前的数据会放到Ceph上存储,这样可以大量存储的成本,同等成本情况下,把集群存储容量从5PB提升到了8PB。
在分级存储之上,还开发了一些特性,专门开发了high level和low level的水位线,这是基于冷存和热存系统消耗是不一样的,冷存的时候high level可能会更高一点,以上就是分级存储的内容。
③ FastIndex
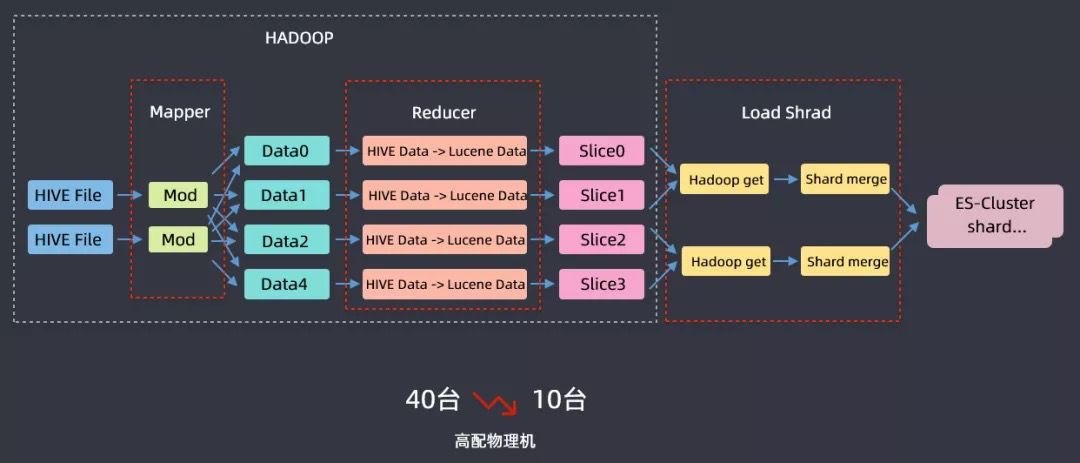
另外还为离线数据导入ES开发了一个FastIIndex的组件,该组件开发主要是基于滴滴内部用于分析乘客的标签系统,从离线系统导入ES集群而开发的;标签系统每天都会重新计算,数据总量在40TB左右,原始数据在hadoop上,计算好之后通过kafka然后实时链路写入到ES,以前把40TB数据导入到ES需要40台高配物理机,基于这样一个案例开发了FastIndex组件,利用hive进行一个mapreduce的过程,在reduce阶段使用FastIndex组件启用ES local这样的模式将数据写到lucene data中,然后再把lucene文件加载到ES集群中,这样就完成了把离线数据导入ES集群的操作,资源从40台下降到10台高配物理机,时间也从6小时下降到1.5小时,节省了大量的成本。
3. 升级
① 查询回放
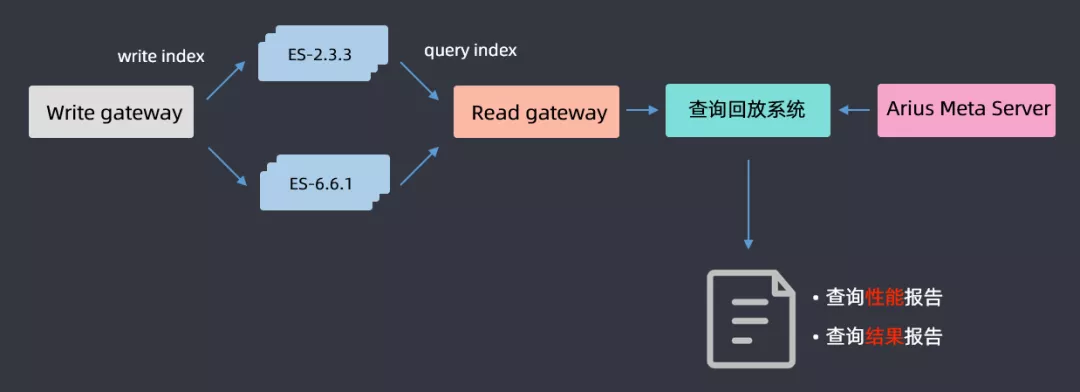
机器资源优化好了之后,开始升级,升级过程前面有讲过了,这里主要介绍一下查询回放流程,因为要保证升级后对用户的查询是没有影响的;基于gateway网关层DSL的分析,将用户查询的DSL全部在高低版本上进行一个回放,最后得出一份查询性能报告和查询结果报告,通过分析两篇报告,如果是一致的就认为升级完成;如果不一致,就分析2.3.3和6.6.1哪些查询导致的问题,然后做兼容性适配,适配完成后再进行查询回放,循环往复直至最后所有的报告都一致,这样就认为ES集群升级成功。
② 采坑
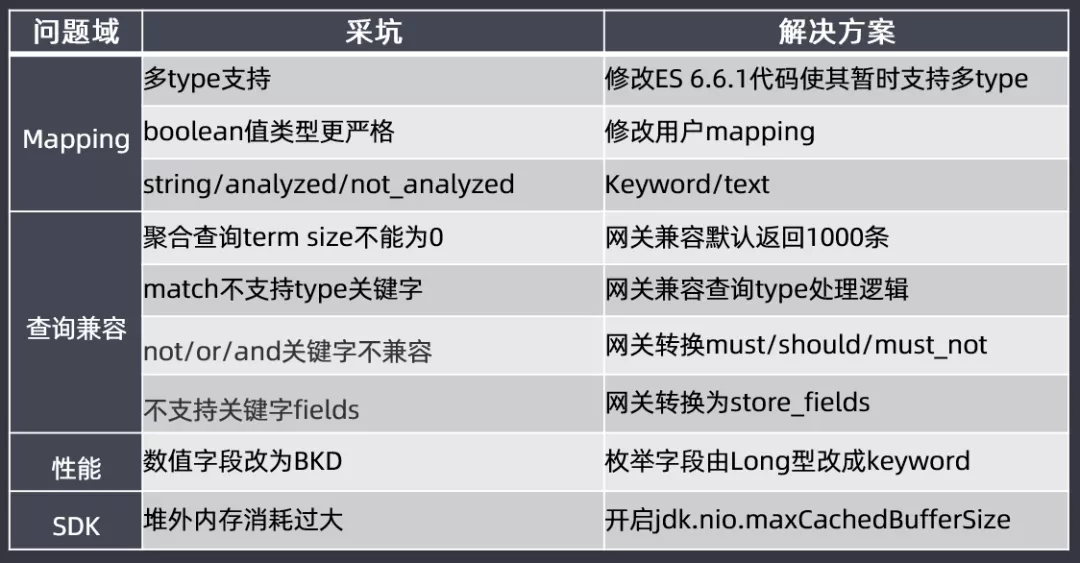
接下来介绍一下升级过程中遇到的坑:
- Mapping:选择6.6.1的理由是代码里面暂时还是支持多type的;还有就是布尔类型数据的兼容,分词不分词的mapping修改,这些内容都会提前帮助用户修改好mapping。
- 查询兼容:聚合查询term size不能为0,网关兼容默认返回1000条;match不支持type关键字,网关兼容查询type处理逻辑;not/or/and关键字不兼容,网关转换must/should/must_not;不支持关键字fields,网关转换为store_fields
- 性能:数值字段改为BKD,枚举字段会从Long类型改为keyword类型;否则long类型在BKD查询时候还有问题的
- SDK:使用高版本ES会有堆外内存消耗过大的问题,需要开启jdk,nio.maxCachedBudderSize参数来保障堆外内存不会消耗过大。
04 升级收益
1. 平台升级
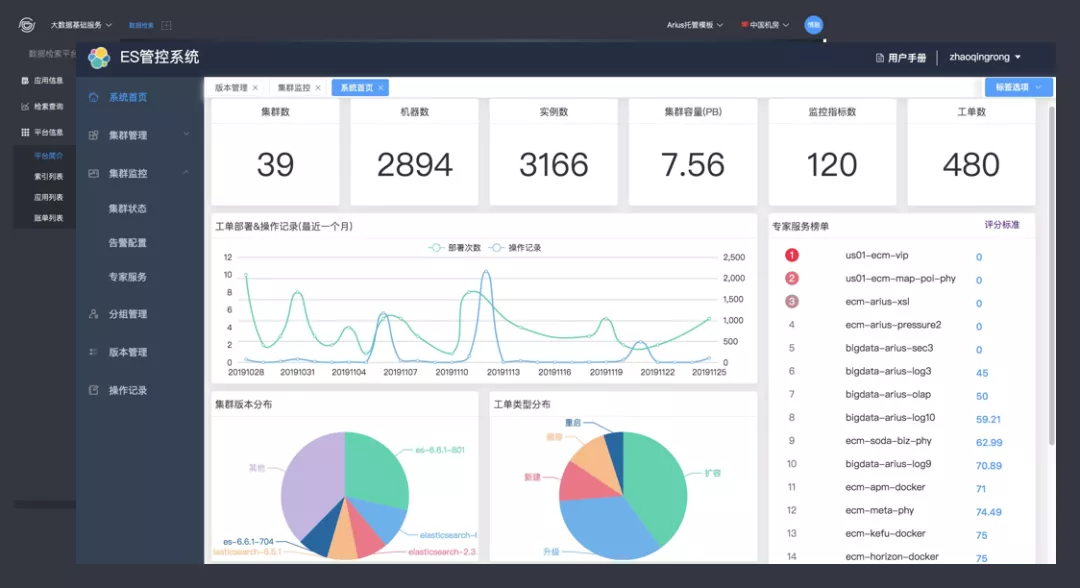
构建了一个完善的管控的平台,大大降低了使用成本。
2. 成本下降
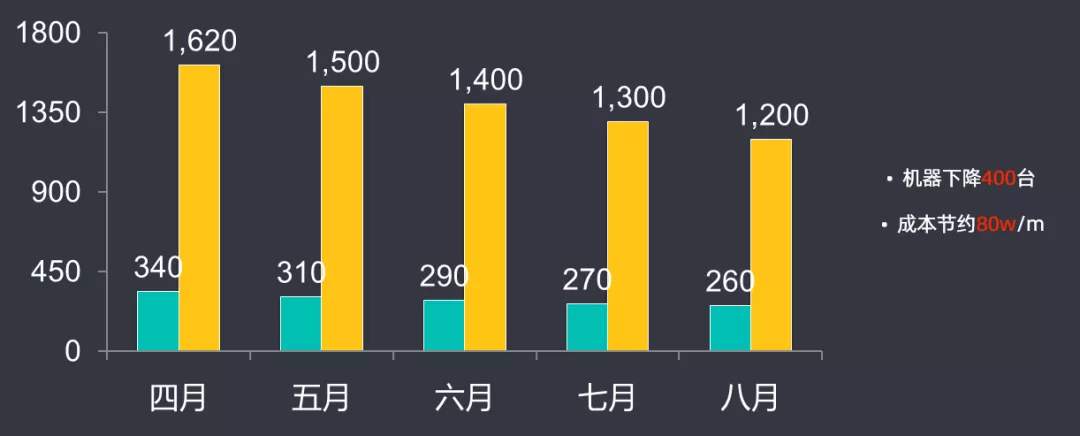
机器数量下降了400台,每月成本节约了80万左右。
3. 性能提升
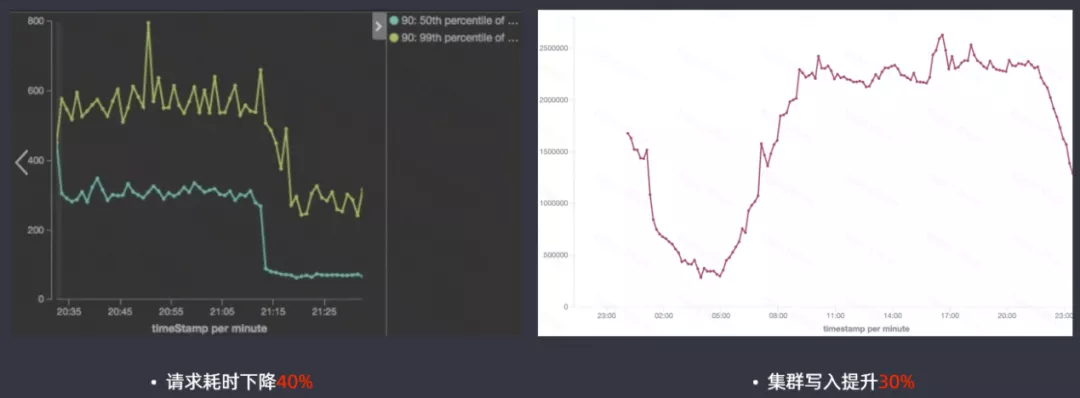
高版本的ES查询性能提升还是很明显的,请求耗时下降40%,集群写入提升30%。
4. 特性应用
使用了高版本特性带来的一些优势:
- Sequence Number提升了集群升级速度
- Ingest Node索引模板和限流从网关层下放到引擎层
- DCDR滴滴跨集群数据同步,相比CCR性能提升2倍
- Cluster reroute冷热节点shard搬迁更均匀
- Cluster allocation explain降低集群状态运维成本
05 总结与展望
1. 总结

针对搜索平台进行大版本的升级时,一定要做到:
- 架构要可控:服务化(网关服务、管控服务、元数据服务、FastIndex服务)、高内聚、一定优先保证稳定性
- 平台要易用:平台化、自动化、可视化
- 成本要低廉:数据驱动、技术改造、业务配合
- 引擎要深入:深入理解版本差异、深入理解ES原理、深入定位问题根因
2. 规划

最后对滴滴搜索平台做一个整体的规划:
- 更大的集群:在滴滴现有的目前40多个集群的规模下,做得更大,由于master元数据管理的限制导致对集群的管控是无法做到非常大的,目前滴滴希望
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BB%B4%E6%BB%B4%E9%9B%86%E7%BE%A4%E8%B7%A8%E7%89%88%E6%9C%AC%E5%8D%87%E7%BA%A7%E4%B8%8E%E5%B9%B3%E5%8F%B0%E9%87%8D%E6%9E%84%E4%B9%8B%E8%B7%AF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


