源码系列默认策略
这篇文章介绍 TieredMergePolicy,它是 Lucene4 以后的默认段的合并策略,之前采用的合并策略为 LogMergePolicy,建议先熟悉 LogMergePolicy 后再了解 TieredMergePolicy,这样对于两种合并策略的优缺点能一目了然,使得在不同业务使用对应的策略,其中两种合并策略最大的不同是:
- LogMergePolicy 总是合并相邻的段文件,合并相邻的段文件(Adjacent Segment)描述的是对于 IndexWriter 提供的段集,LogMergePolicy 会选取连续的部分(或全部)段集区间来生成一个待合并段集
- TieredMergePolicy 中会先对 IndexWriter 提供的段集进行排序,然后在排序后的段集中选取部分(可能不连续)段来生成一个待合并段集,即非相邻的段文件(Non-adjacent Segment)。
如果用一句话来描述合并策略 TieredMergePolicy 的特点的话,那就是:找出大小接近且最优的段集。在下文中,通过介绍一些参数以及找出合并段集的逻辑自然就理解这句话的含义。
TieredMergePolicy 的一些参数
MERGE_TYPE
MERGE_TYPE 中描述了 IndexWriter 在不同状态下调用合并策略的三种类型:
- NATURAL:IndexWriter 对索引执行变更操作后调用合并策略
- FORCE_MERGE:IndexWriter 需要将索引中包含所有的段集数量(total set of segments in the index)合并为指定数量
- FORCE_MERGE_DELETES:IndexWriter 需要将索引中包含所有的段中的被删除文件进行抹去(expunge)操作
由于逻辑大同小异,下文中只介绍 NATURAL。
maxMergeAtOnce(可配置)
maxMergeAtOnce 的默认值为 10,描述了在 NATURA 类型下执行一次合并操作最多包含的段的个数(Maximum number of segments to be merged at a time during “normal” mergin)。
segsPerTier(可配置)
segsPerTier 的默认值为 10,描述了每一层(层级的概念类似 LogMergePolicy,这里不赘述)中需要包含 segsPerTier 个段才允许合并,例外情况就是当段集中包含的被删除的文档数量达到某个值(下文会介绍),就不用考虑 segsPerTier 中的段的个数。
mergeFactor
mergeFactor 描述了执行一次合并操作 最多 包含的段的个数,它的计算方式为:
|
|
段大小(SegmentSize)
SegmentSize 描述了一个段的大小,它是该段中除去被删除文档的索引信息的所有索引文件的大小的总和,
maxMergedSegmentBytes(可配置)
maxMergedSegmentBytes 默认值为 5G,它有两个用途:
- 限制合并段集大小总量:待合并的段集大小总和不能超过该值
- 限制大段(Segment with huge size)合并:该值的一半,即(maxMergedSegmentBytes / 2)用来描述某个段如果大小超过就不参与合并(限制大段还要同时满足被删除文档的条件,在下文中会介绍)
hitTooLarge
hitTooLarge 是一个布尔值,当 OneMerge 中所有段的大小总和接近 maxMergedSegmentBytes,hitTooLarge 会被置为 true,该值影响 OneMerge 的打分,下文件中会详细介绍打分。
deletesPctAllowed(可配置)
deletesPctAllowed 的默认值为 33(百分比),自定义配置该值时允许的值域为[20,50],该值有两个用途:
- 限制大段合并:限制大段参与合并需要满足该段的 SegmentSize ≥ (maxMergedSegmentBytes / 2) 并且满足 段集中的被删除文档的索引信息大小占总索引文件大小的比例 totalDelPct ≤ deletesPctAllowed 或 该段中被删除文档的索引信息大小占段中索引文件大小的比例 segDelPct ≤ deletesPctAllowed,如下:
|
|
- 计算 allowedDelCount:计算公式如下,其中 totalMaxDoc 描述了段集中除去被删除文档的文档数量总和,allowedDelCount 的介绍见下文:
|
|
allowedSegCount、allowedDelCount
- allowedSegCount:该值描述了段集内每个段的大小 SegmentSize 是否比较接近(segments of approximately equal size),根据当前索引大小来估算当前索引中"应该"有多少个段,如果实际的段个数小于估算值,那么说明索引中的段不满足差不多都相同(approximately equal size),那么就不会选出 OneMerge (这里不赘述该名词含义,见 LogMergePolicy) 。allowedSegCount 的最小值为 segsPerTier,allowedSegCount 的值越大,索引中会堆积更多的段,说明 IndexWriter 提交的段集(不包含大段)中最大的段的 MaxSegmentSize 跟最小的段 MinSegmentSize 相差越大,或者最小的段 MinSegmentSize 占段集总大小 totalSegmentSize 的占比特别低,一个原因在于有些 flush()或者 commit()的文档数相差太大,另一个原因是可配置参数 floorSegmentBytes 值设置的太小。
- allowedDelCount:描述了 IndexWriter 提交的段集(不包含大段)中包含的被删除文档数量,在 NATURAL 类型下,当某个段集中的成员个数不满足 allowedSegCount 时,但是如果该段集(不包含大段)中包含的被删除的文档数量大于 allowedDelCount,那么该段集还可以继续参与剩余的合并策略的处理(因为执行段的合并的一个非常重要的目的就是"干掉"被删除的文档号),否则就该段集 此次 不生成一个 oneMerge。
floorSegmentBytes(可配置,重要!!!)
floorSegmentBytes 默认值为 2M(2 * 1024 * 1024),该值描述了段的大小 segmentSize 小于 floorSegmentBytes 的段,他们的 segmentSize 都当做 floorSegmentBytes(源码原文:Segments smaller than this are “rounded up” to this size, IE treated as equal (floor) size for merge selection),使计算出来的 allowedSegCount 较小,这样能尽快的将小段(tiny Segment)合并,另外该值还会影响 OneMerge 的打分(下文会介绍)。
设置了不合适的 floorSegmentBytes 后会发生以下的问题:
- floorSegmentBytes 的值太小:导致 allowedSegCount 很大
(allowedSegCount = n * segsPerTier + m \qquad 0 ≤ m≤ segsPerTier,n ≥ 1)
特别是段集中最小的段 MinSegmentSize 占段集总大小 totalSegmentSize 的占比特别低,最终使得索引中一段时间存在大量的小段,因为段集的总数小于等于 allowedSegCount 是不会参与段合并的(如果不满足 allowedDelCount 的条件)。源码中解释 floorSegmentBytes 的用途的原文为: This is to prevent frequent flushing of tiny segments from allowing a long tail in the index
- floorSegmentBytes 的值太大:导致 allowedSegCount 很小(最小值为)(最小值为segsPerTier),即较大的段合并可能更频繁,段越大,合并开销(合并时间,线程频繁占用)越大(在后面的文章中会介绍索引文件的合并)
Lucene7.5.0 版本的 Tiered1MergePolicy.java 中 380 行~392 解释了上面的结论,这里不通过源码解释的原因是,换成我也不喜欢在文章中看源码。。。
SegmentSize 多小为小段(tiny Segment),这个定义取决于不同的业务,如果某个业务中认为小于 TinySegmentSize 的段都为小段,那么 floorSegmentBytes 的值大于 TinySegmentSize 即可。
流程图
图 1:
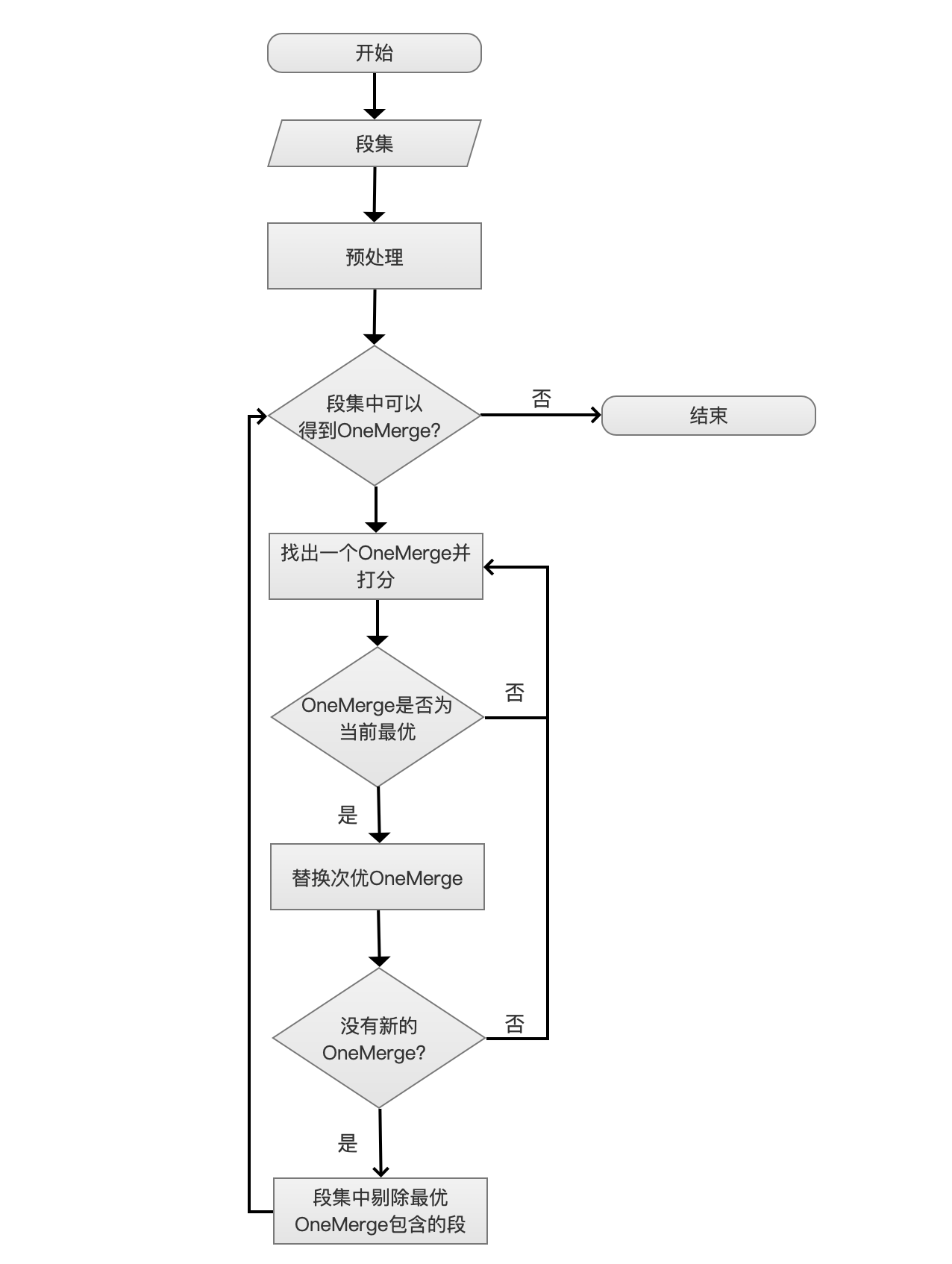
开始
图 2:

当 IndexWriter 对索引有任意的更改都会调用合并策略。
段集
图 3:

IndexWriter 会提供一个段集(段的集合)提供给合并策略。
预处理
图 4:

预处理的过程分为 4 个步骤,分别是排序、过滤正在合并的段、过滤大段、计算索引最大允许段的个数。
排序
排序算法为 TimSort,排序规则为比较每个段中索引文件的大小,不包括被删除的文档的索引信息。
过滤正在合并的段
当 IndexWriter 获得一个 oneMerge 后,会使用后台线程对 oneMerge 中的段进行合并,那么这时候索引再次发生更改时,IndexWriter 会再次调用 TieredMergePolicy,可能会导致某些已经正在合并的段被处理为一个新的 oneMerge,为了防止重复合并,需要过滤那些正在合并中的段。后台合并的线程会将正在合并的段添加到 Set 对象中,在 IndexWriter 调用合并策略时传入。
过滤大段(Large Segment)
在 LogMergeolicy 中,如果某个段的大小大于一个阈值则视为大段,而在 TieredMergePolicy 中,判断是否为大段需要同时满足两个条件,在上文介绍 deletesPctAllowed 参数时候已经说明,不赘述。
计算索引最大允许段的个数(Compute max allowed segments in the index)
即计算上文中已经介绍的 allowedSegCount,不赘述。
段集中可以得到 OneMerge?
图 5:

如果同时满足下面三个条件,那么说明无法段集中可以得到 OneMerge:
- MergeType:合并类型,即上文中的 MERGE_TYPE,必须是 NATURAL 类型
- SegmentNumber:段集中段的个数,如果 SegmentNumber ≤ allowedSegCount
- remainingDelCount:剩余段集中被删除文档的总数,如果 remainingDelCount ≤ allowedDelCount
为什么叫做剩余段集,从流程图中可以看出,当前已经进入了迭代流程,当前流程点有可能不是第一次迭代(iterations),即段集中的段的个数可能已经小于从预处理过来的段集中的段的个数了,并且从此流程开始称为层内处理,当再次进入此流程,则为下一层处理。
找出一个 OneMerge 并打分
图 6:

在这个流程中,需要做两个处理:找出一个 OneMerge、OneMerge 打分。
找出一个 OneMerge
找出一个 OneMerge 会遇到下面几种情况,OneMerge 中段的个数记为 NumInOneMerge:
- NumInOneMerge = 1:段集中的第一个段大小 ≥maxMergedSegmentBytes,但是这并不意味着就不会去合并这个段,因为如果该段中被删除的文档,那么还是有必要作为一个 OneMerge,毕竟段的合并的目的不仅仅是为了减少索引中段的个数,剔除被删除的文档号是很重要的
- 1 <NumInOneMerge ≤ mergeFactor: OneMerge 中段的总量 非常接近 maxMergedSegmentBytes,hitTooLarge 的值为被置为 true。这里的逻辑得说明下,因为它是** 装箱问题(bin packing)**的一个具体实现
|
|
假设我们有以下的数据,其中 maxMergedSegmentBytes = 80,mergeFactor = 5:
图 7:
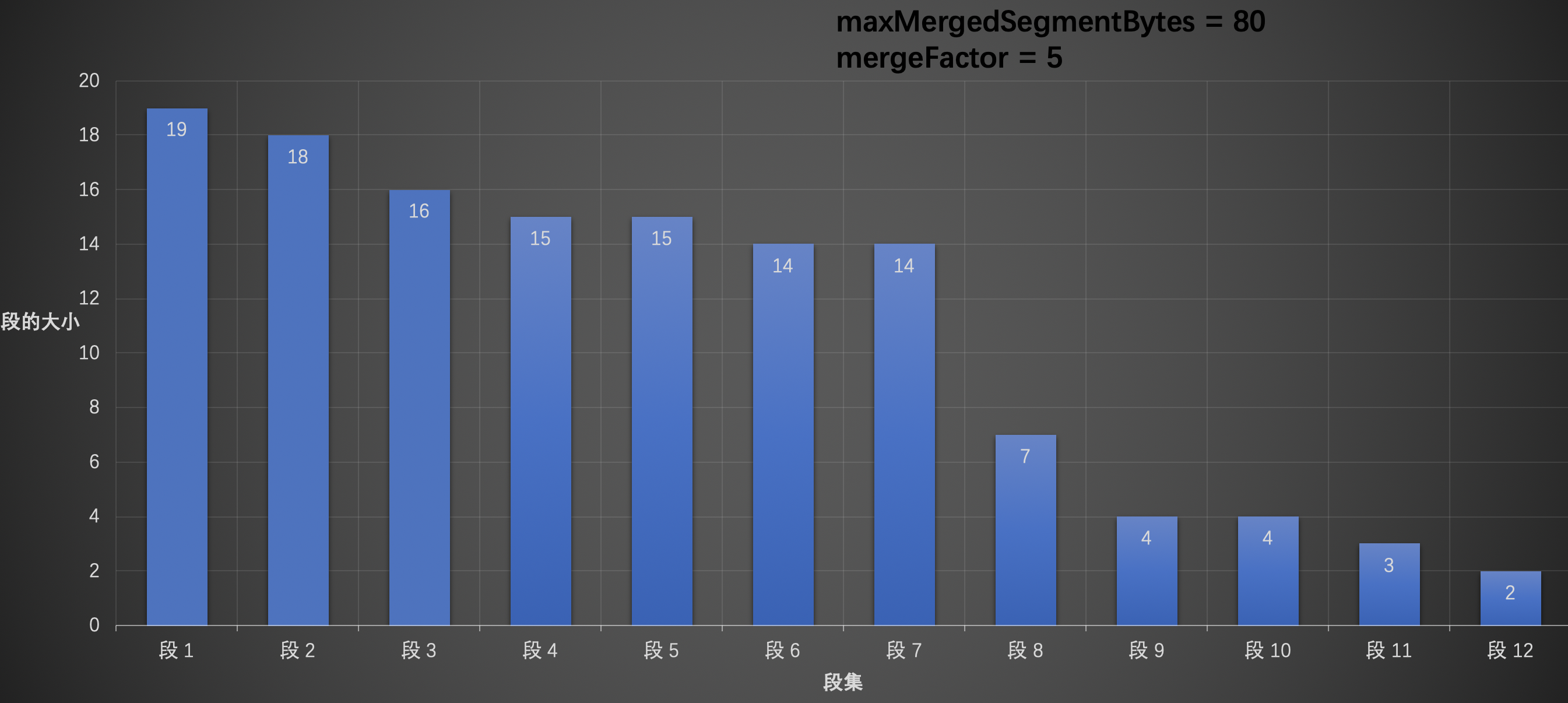
从段 1 开始,逐个添加到 OneMerge 中,当遍历到段 5 时发现,如果添加段 5,那么 OneMerge 的大小,即 19 (段 1) + 18 (段 2)+ 16 (段 3) + 15 (段 4) + 15 (段 5) = 83,该值大于 maxMergedSegmentBytes (80),那么这时候需要跳过段 5,往后继续找,同理段 6、段 7 都不行,直到遍历到段 8,OneMerge 的大小为 19 (段 1) + 18 (段 2)+ 16 (段 3) + 15 (段 4) + 7 (段 8) = 75,那么可以将段 8 添加到 OneMerge 中,尽管段 9 添加到 OneMerge 以后,OneMerge 的大小为 19 (段 1) + 18 (段 2)+ 16 (段 3) + 15 (段 4) + 7 (段 8) + 4 (段 9) = 79,还是小于 maxMergedSegmentBytes (80),但是由于 OneMerge 中段的个数会超过 mergeFactor (5),所以不能添加到 OneMerge 中,并且停止遍历,如下图:
图 8:
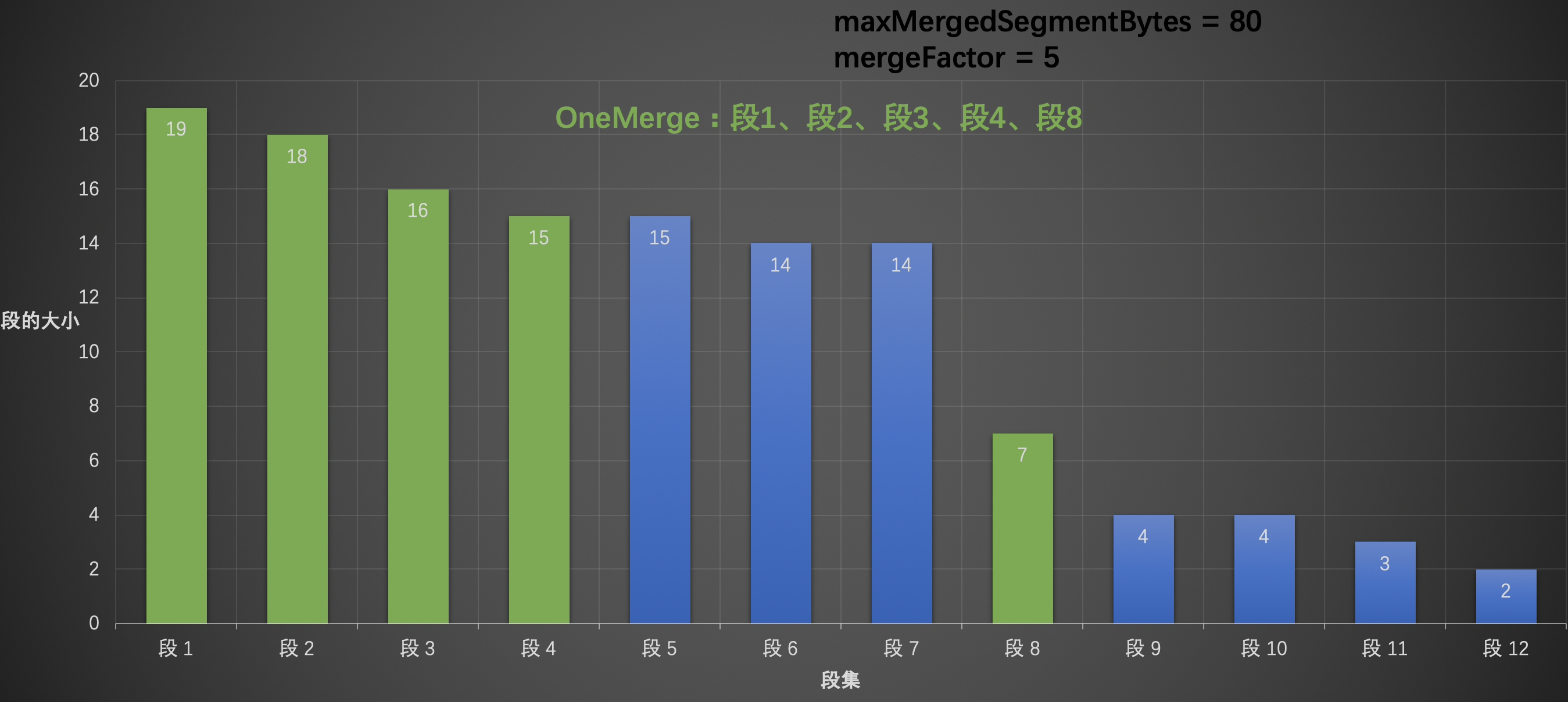
在这里我们可以看到了 TieredMergePolicy 跟 LogMergePolicy 另一个差异,那就是 LogMergePolicy 每次合并的段的个数都是固定的。而 TieredMergePolicy 中则不是,所以为什么在上文中介绍 mergeFactor 的概念时,对"最多"两个字进行加黑操作。
OneMerge 打分
对刚刚找出的 OneMerge 进行打分,打分公式为: mergeScore = skew * totAfterMergeBytes^{0.05} * nonDelRatio^2 ,mergeScore 越小越好(smaller mergeScore is better)。
- skew:粗略的计算 OneMerge 的偏斜值(Roughly measure “skew” of the merge),衡量 OneMerge 中段之间大小的是否都差不多相同,如果 OneMerge 中段的大小接近 maxMergedSegmentBytes,即 hitTooLarge 为 true,那么 skew = \frac {1.0}{mergeFactor},否则 ,skew = \frac {MaxSegmentSize} {\sum_{i=0}^{NumInOneMerge} Max(maxMergedSegmentBytes,SegmentSize)}, 其中 MaxSegment 为 OneMerge 中最大的段的大小,SegmentSize 为每一个段的大小,maxMergedSegmentBytes 在上文中已经介绍。
- totAfterMergeBytes:该值是 OneMerge 中所有段的大小,这个参数描述了段合并比较倾向于(Gently favor )较小的 OneMerge
- nonDelRatio:该值描述了 OneMerge 中所有段包含被删除文档比例,这里就不详细给出计算公式了,nonDelRatio 越小说明 OneMerge 中包含更多的被删除的文档,该值相比较 totAfterMergeBytes,对总体打分影响度更大,因为段合并的一个重要目的就是去除被删除的文档(Strongly favor merges that reclaim deletes)
故最终的打分公式:
, mergeScore = \begin{cases} \frac {1.0}{mergeFactor} * totAfterMergeBytes^{0.05} * nonDelRatio^2,\qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad hitTooLarger = true\\ \frac {MaxSegmentSize} {\sum_{i=0}^{NumInOneMerge} Max(maxMergedSegmentBytes,SegmentSize)}* totAfterMergeBytes^{0.05} * nonDelRatio^2,\qquad hitTooLarge = false\end{cases}
再贴个图,怕上面的公式显示不出来,不过在我家 27 寸 4K 显示器上看的蛮清楚的~😄
图 9:
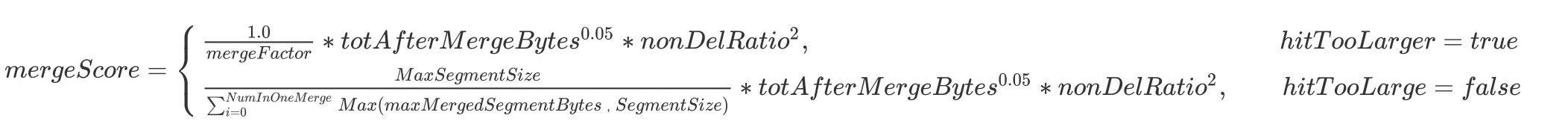
替换次优 OneMerge
图 10:

当前层中只允许选出一个 OneMerge,即 mergeScore 最低的 OneMerge。
没有新的 OneMerge?
图 11:

在图 9 中,我们遍历的对象是 段 1 段 12,并且选出了一个 OneMerge,接着我们需要再次从 段 2 段 12 中选出一个 OneMerge 后,再从段 3~段 12 中再找出一个 OneMerge,如此往复直到找不到新的 OneMerge,没有新的 OneMerge 的判定需要同时满足三个条件:
|
|
- bestScore != null:bestScore 如果为空,说明当前还没有产生任何的 OneMerge,那么肯定会生成一个 OneMerge
- hitTooLarge == false:如果 bestScore 不为空,hitTooLarge 为 true,也要生成一个 OneMerge。
- 剩余段集个数:bestScore 不为空,hitTooLarge 为 false,如果剩余段集个数 SegmentNum 小于 mergeFactor 就不允许生成一个 OneMerge
下图表示从段 3~段
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%E9%BB%98%E8%AE%A4%E7%AD%96%E7%95%A5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


