源码系列索引文件的生成十一之
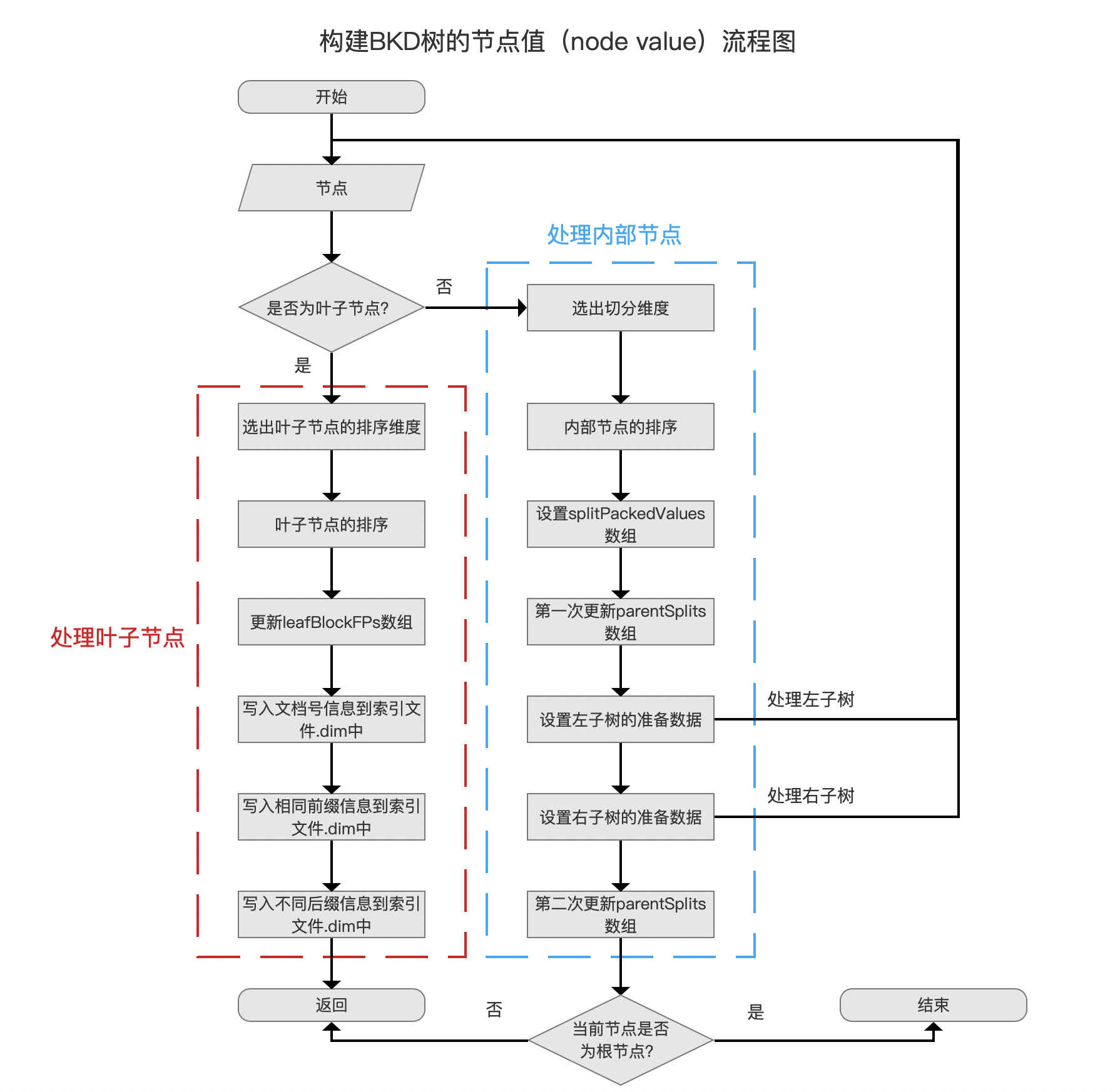
本文承接 索引文件的生成(十),继续介绍剩余的内容,为了便于下文的介绍,先给出 生成索引文件.dim&&.dii 的流程图以及流程点 构建BKD树的节点值(node value) 的流程图:
图 1:
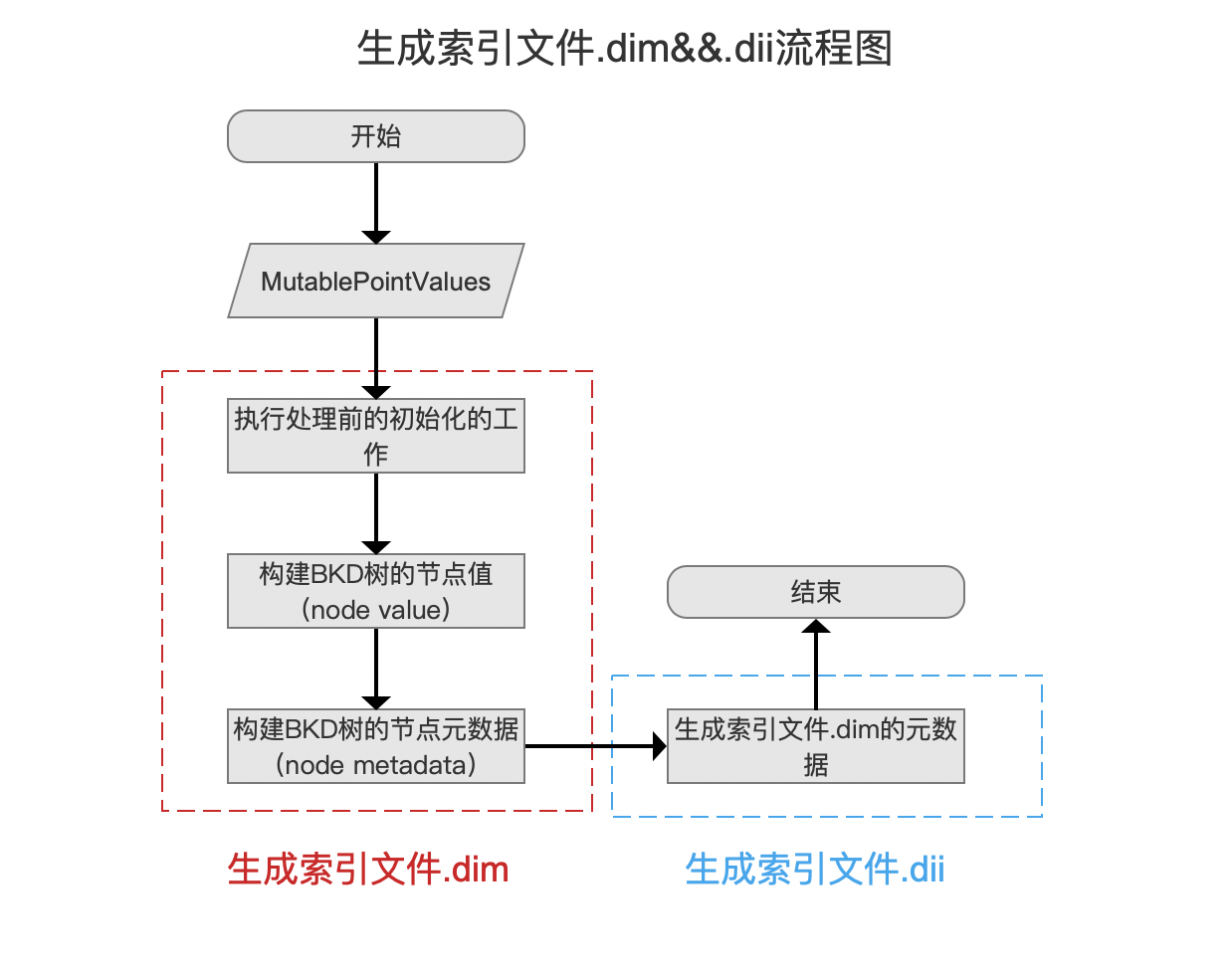
图 2:
第一次更新 parentSplits 数组
图 3:

parentSplits 数组的数组元素数量跟点数据的维度数量相同,下标值为 0 的数组元素描述的是维度编号(见文章 索引文件的生成(十)之 dim&&dii)为 0 的维度值在祖先节点中作为 切分维度(见文章 索引文件的生成(十)之 dim&&dii)的次数(累加值):
图 4:
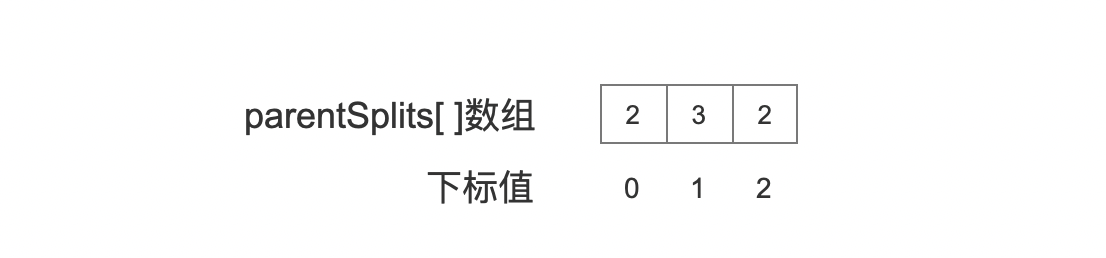
如果某一时刻,parentSplits 数组如上述所示,说明当前处理的点数据的维度为 3(数组大小),并且维度编号为 1(数组下标为 1)的维度在祖先节点中已经 3 次作为切分维度,如果执行完图 2 的流程点 选出切分维度 后,维度编号 1 再次作为了切分维度,那么在当前流程点,我们就需要 第一次更新parentSplits数组,更新后的 parentSplits 数组如下所示:
图 5:

为什么要更新 parentSplits 数组
如果当前节点划分后的左右子树还是内部节点,那么左右子树需要根据 parentSplits 数组提供执行流程点 选出切分维度 的条件判断依据。
设置左子树的准备数据、设置右子树的准备数据
图 6:
执行到当前流程点,内部节点的处理工作差不多已经全部完成(除了流程点 第二次更新parentSplits数组),当前流程点开始为后续的左右子树的处理做一些准备数据,根据当前的节点编号(见文章 索引文件的生成(十)之 dim&&dii),即将生成的左右子树可能仍然是内部节点,或者是叶子节点。这两种情况对应的准备数据是有差异的,我们会一一介绍。另外根据满二叉树的性质,如果当前节点编号为 n,那么左右子树的节点编号必然为 2*n、2*n + 1,在文章 索引文件的生成(十)之 dim&&dii 中我们说到,根据节点编号就能判断属于内部节点(非叶节点)还是叶子节点,不赘述。
处理节点(叶子节点或者内部节点)需要的准备数据有好几个,这些准备数据在源码中其实就是 https://github.com/LuXugang/Lucene-7.5.0/blob/master/solr-8.4.0/lucene/core/src/java/org/apache/lucene/util/bkd/BKDWriter.java 类中的 build(…)方法的参数:
图 7:
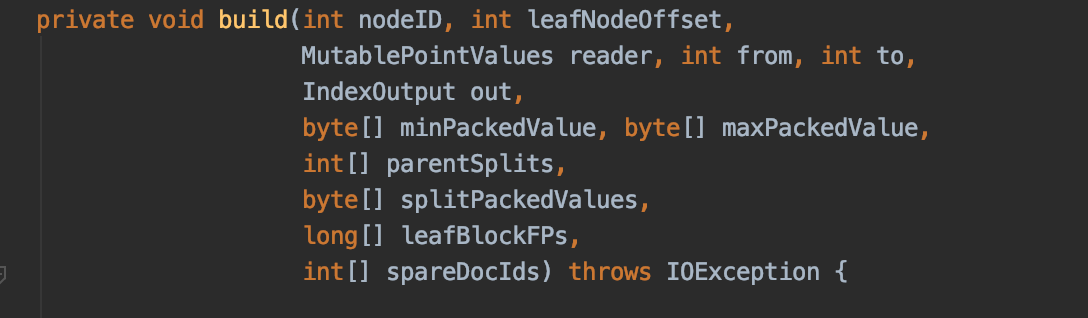
图 6 中的 nodeID 参数即节点编号,leafNodeOffset 参数即最左叶子节点的节点编号值,其他的参数在下文中会部分介绍。
左右子树为内部节点
如果节点编号 nodeId 小于最左叶子节点的节点编号 leafNodeOffset,那么当前节点是内部节点,对于内部节点的处理,主要关心的参数是 minPackedValue、maxPackedValue。
minPackedValue、maxPackedValue
在图 2 的流程点 选出切分维度 中,我们会使用到 minPackedValue、maxPackedValue 参与条件判断(见文章 索引文件的生成(九)之 dim&&dii),我们在处理根节点(内部节点)时,在图 1 的流程点 MutablePointValues, ,设置了 minPackedValue、maxPackedValue 的值,为处理根节点做了准备,其初始化的内容见文章 索引文件的生成(九)之 dim&&dii,而当处理其他内部节点时,minPackedValue、maxPackedValue 的值的设置时机点则是在当前流程点。
非根节点的内部节点的 minPackedValue、maxPackedValue 是如何设置的
我们先回顾下 minPackedValue 数组的作用是存放每个维度的最小值,maxPackedValue 数组的作用是存放每个维度的最大值,比如当前节点中包含的点数据集合如图 8 所示,那么 minPackedValue、maxPackedValue 中的内容如下所示:
|
|
在图 2 的执行完流程点 选出切分维度、 内部节点的排序 之后,我们就获得了当前内部节点划分维度编号 n,并且当前节点中点数据集合的每一个点数据按照维度编号 n 对应的维度值进行了排序(见文章 索引文件的生成(十)之 dim&&dii),如果我们另排序后的点数据都有一个从 0 开始递增的序号,假设有 N 个点数据,那么序号为 0~ (N/2 - 1)的点数据将作为当前节点的左子树的点数据集合,序号为 N/2 ~ N 的点数据将作为当前节点的右子树的点数据集合。
例如当前内部节点有如下的点数据集合,数量为 7,并且假设按照维度编号 2 进行了排序:
图 8:
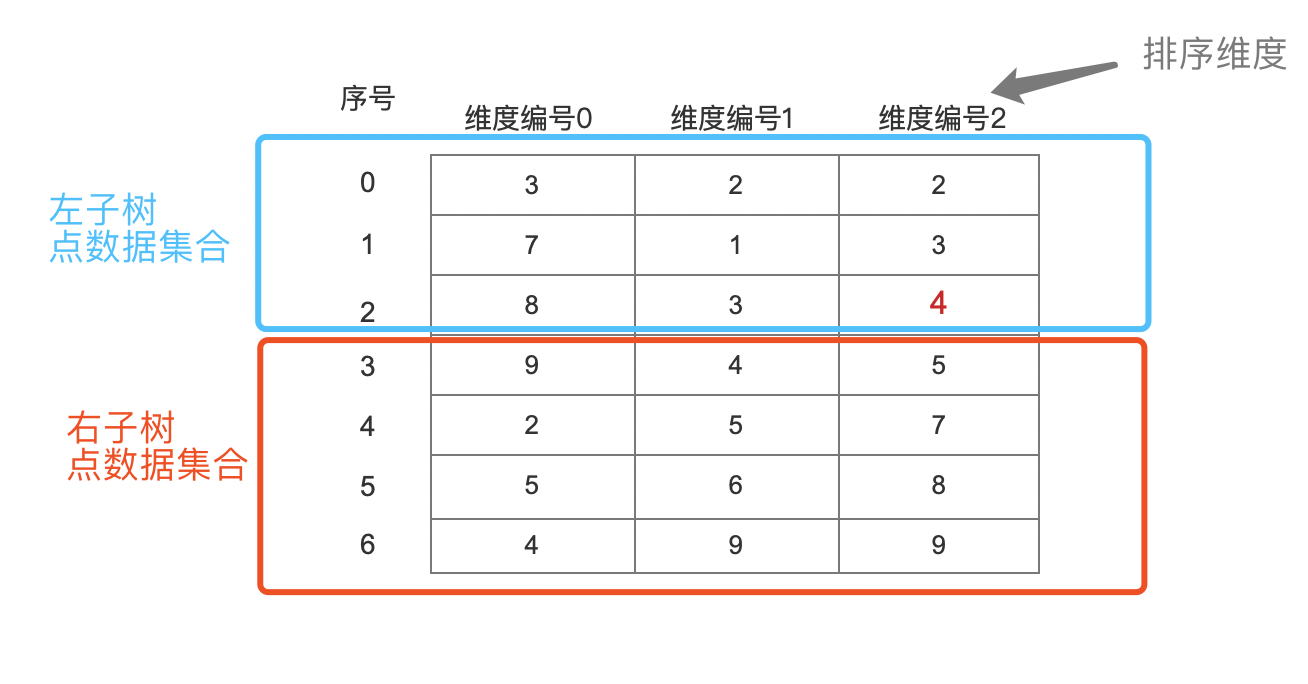
根据图 8,当前的 minPackedValue、maxPackedValue 以及左右子树的 minPackedValue、maxPackedValue 如下所示:
图 9:
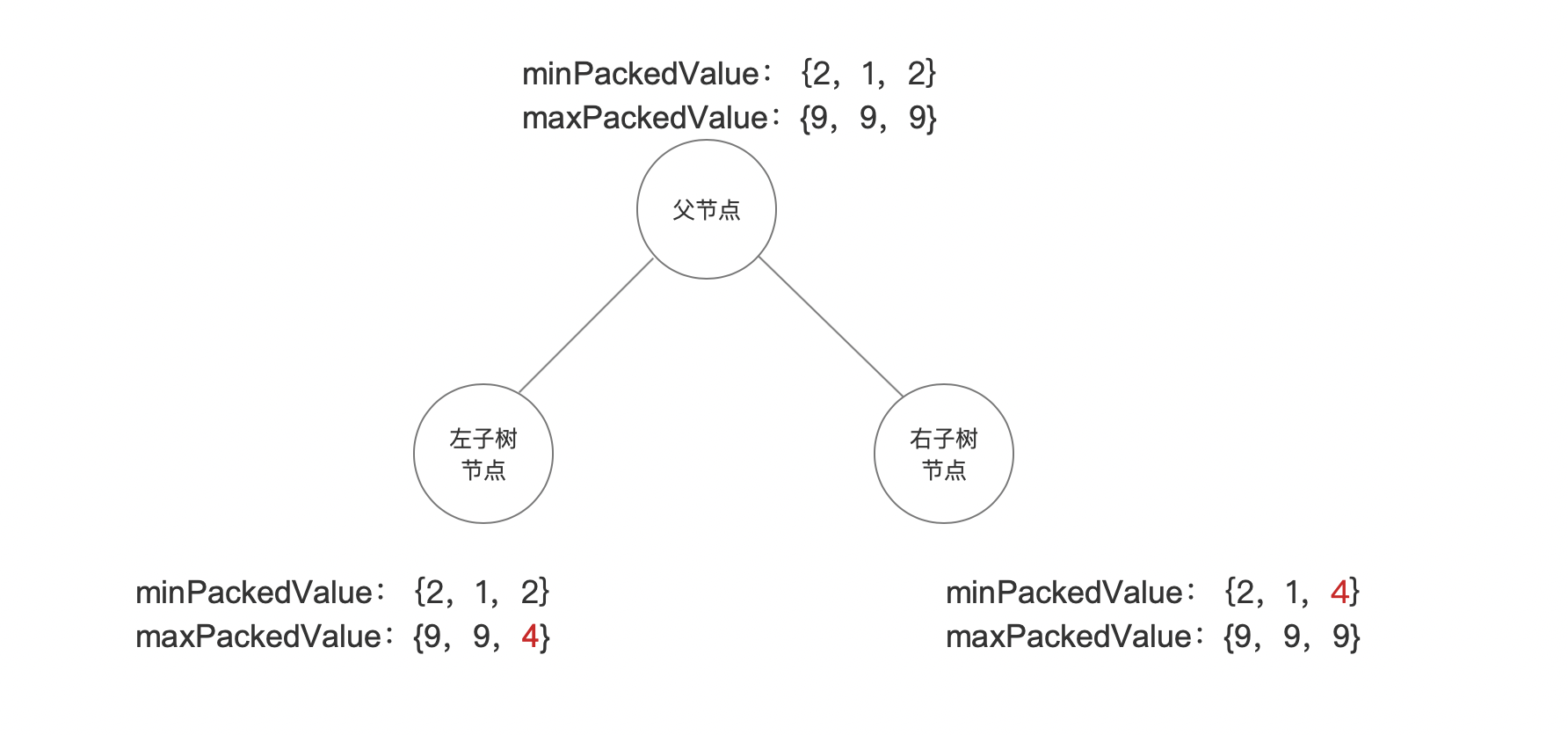
从图 9 可以看出左子树的 maxPackedValue 跟右子树的 minPackedValue 的维度编号为 2 的值被更新为同一个新值,而该值就是序号为(N/2 -1) 的点数据的维度编号为 2(父节点的排序维度)对应的维度值,即图 8 中红色标注的维度值。
对于左右子树来说,如果他们还是内部节点,那么执行图 1 的 选出切分维度 的流程时就会使用到父节点提供给它们的参数 minPackedValue、maxPackedValue。
回看上文中内部节点给左右子树的准备参数 minPackedValue、maxPackedValue 是有点问题的,比如左子树的点数据集合以及 minPackedValue、maxPackedValue 如下所示:
图 10:
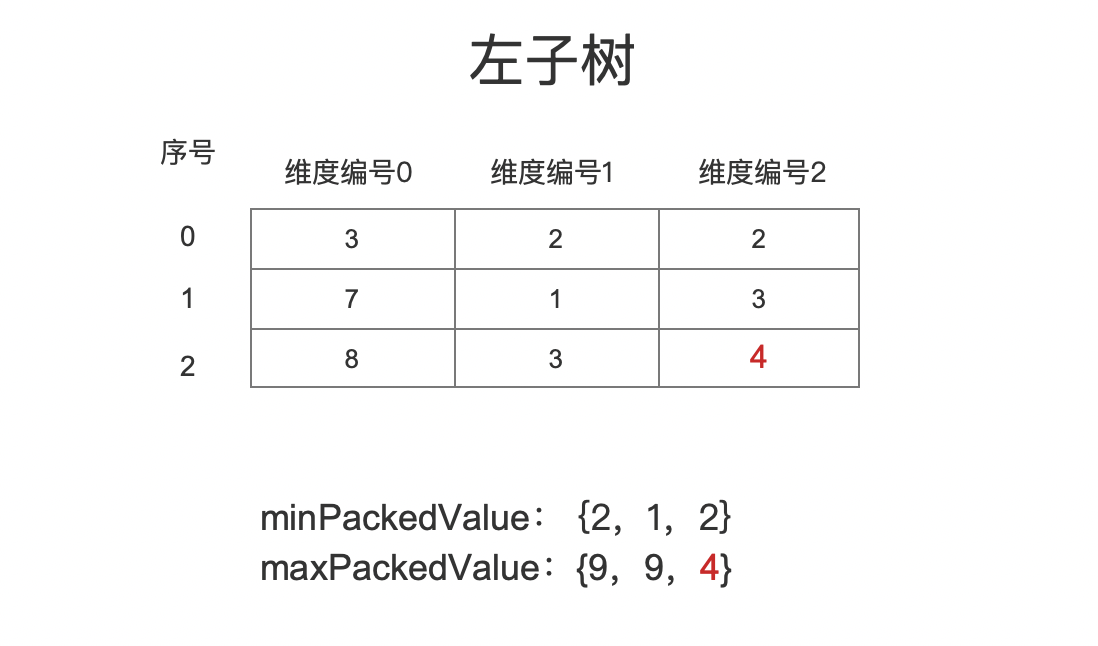
图 10 中,左子树节点 实际 的 minPackedValue、maxPackedValue 应该是:
|
|
而即将在流程点 选出切分维度 使用的 minPackedValue、maxPackedValue 是父节点提供的信息,即图 10 中的值,所以在执行 选出切分维度 的算法时,可能无法能得到最好的一个切分维度。
所以从 Lucene 8.4.0 版本后,在执行流程点 选出切分维度 会根据一个条件判断是否需要重新计算 minPackedValue、maxPackedValue,而不是使用父节点提供的 minPackedValue、maxPackedValu
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%E7%B4%A2%E5%BC%95%E6%96%87%E4%BB%B6%E7%9A%84%E7%94%9F%E6%88%90%E5%8D%81%E4%B8%80%E4%B9%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


