源码系列索引文件的生成九之
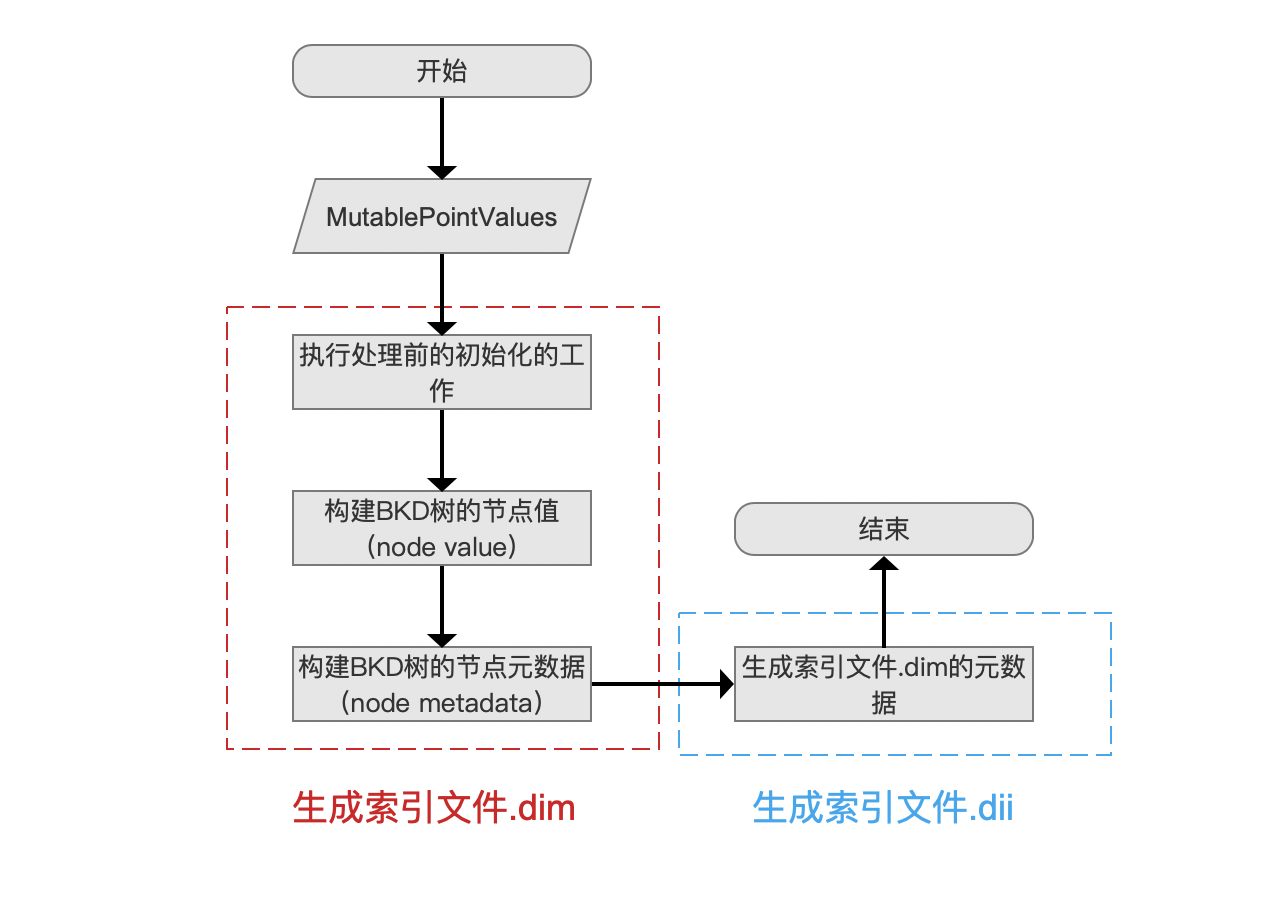
上一篇文章中,我们介绍了在索引(index)阶段,Lucene 收集了跟点数据相关的信息,这些信息在 flush 阶段会被读取,用于生成索引文件。dim&&.dii,从本文开始介绍索引文件。dim&&.dii 生成的详细过程,如图 1 所示,另外阅读本文中需要前置知识: 索引文件之 dim&&dii:
图 1:
MutablePointValues
MutablePointValues 为图 1 流程图的准备数据,该对象中包含了在索引阶段收集的点数据的信息,我们在文章 索引文件的生成(八)之 dim&&dii 中已经详细的展开介绍了,故这里只简单的列出这些信息:
- numPoints
- docIDs
- numDocs
- bytes
MutablePointValues 对象中至少包含了上述的几个信息,但如果 IndexWriter 对象使用了 IndexSort 配置,那么 MutablePointValues 中还要额外包含一个信息:DocMap 对象。
我们简单的回顾下 IndexSort 这个概念,文章 构造 IndexWriter 对象(一) 中我们说到,在构造一个 IndexWriter 对象的的过程中,其中一个流程是 设置IndexWriter的配置信息IndexWriterConfig,当设置了 IndexSort(IndexSort 的一些介绍见文章 文档提交之 flush(三))配置后,段中的文档会按照 IndexSort 的排序规则进行段内的文档排序,由于每添加(例如 IndexWriter.addDocument(…)方法)一篇文档,就排一次序,在实现(implementation)上不可能执行真正的数据排序(数据之间的交换),故通过一个映射关系,即 DocMap 对象来描述文档之间的排序关系,所以在一个段内,当设置了 IndexSort 配置后,每一篇文档有一个原始的段内文档号,该文档号按照文档被添加的先后顺序,是一个从 0 开始的递增值,而 DocMap 对象中提供了方法来描述文档之间基于 IndexSort 的排序关系,该方法在源码中的注释见 https://github.com/LuXugang/Lucene-7.5.0/blob/master/solr-8.4.0/lucene/core/src/java/org/apache/lucene/index/Sorter.java 中内部类 DocMap 提供的两个方法,这里简单的给出:
|
|
执行处理前的初始化的工作
在当前流程点,我们就可以基于 MutablePointValues 中的信息来 执行处理前的初始化的工作,工作内容为初始化以下几个信息:
- numLeaves
- splitPackedValues
- leafBlockFPs
- docsSeen
- parentSplits
- maxPackedValue
- minPackedValue
numLeaves
该值为 long 类型的变量,它用来描述我们随后即将构建的 BKD 树中的叶子节点的数量。
为什么能预先计算出 BKD 树中的叶子节点数量:
在图 1 的流程点 构建BKD树的节点值(node value) 中我们将会介绍 Lucene 将一个节点生成左右子树的划分规则(可以先看下文章 Bkd-Tree 简单的了解划分规则),该规则会使得总是生成一颗 满二叉树,那么根据满二叉树的性质,我们只需要知道点数据的数量就可以计算出 BKD 树中的叶子节点的数量,而点数据的数量在收集阶段实现了统计,并且用 numDocs(见上文中的 MutablePointValues)来描述。
为什么要先计算出 BKD 树中的叶子节点数量:
在后面的流程中,我们可以根据当前处理的节点编号来判断当前节点是内部节点(inner node)还是叶子节点(leaf node),在介绍 构建BKD树的节点值(node value) 时会详细展开介绍 numLeaves 的作用,这里先介绍下节点编号是什么:
图 2:
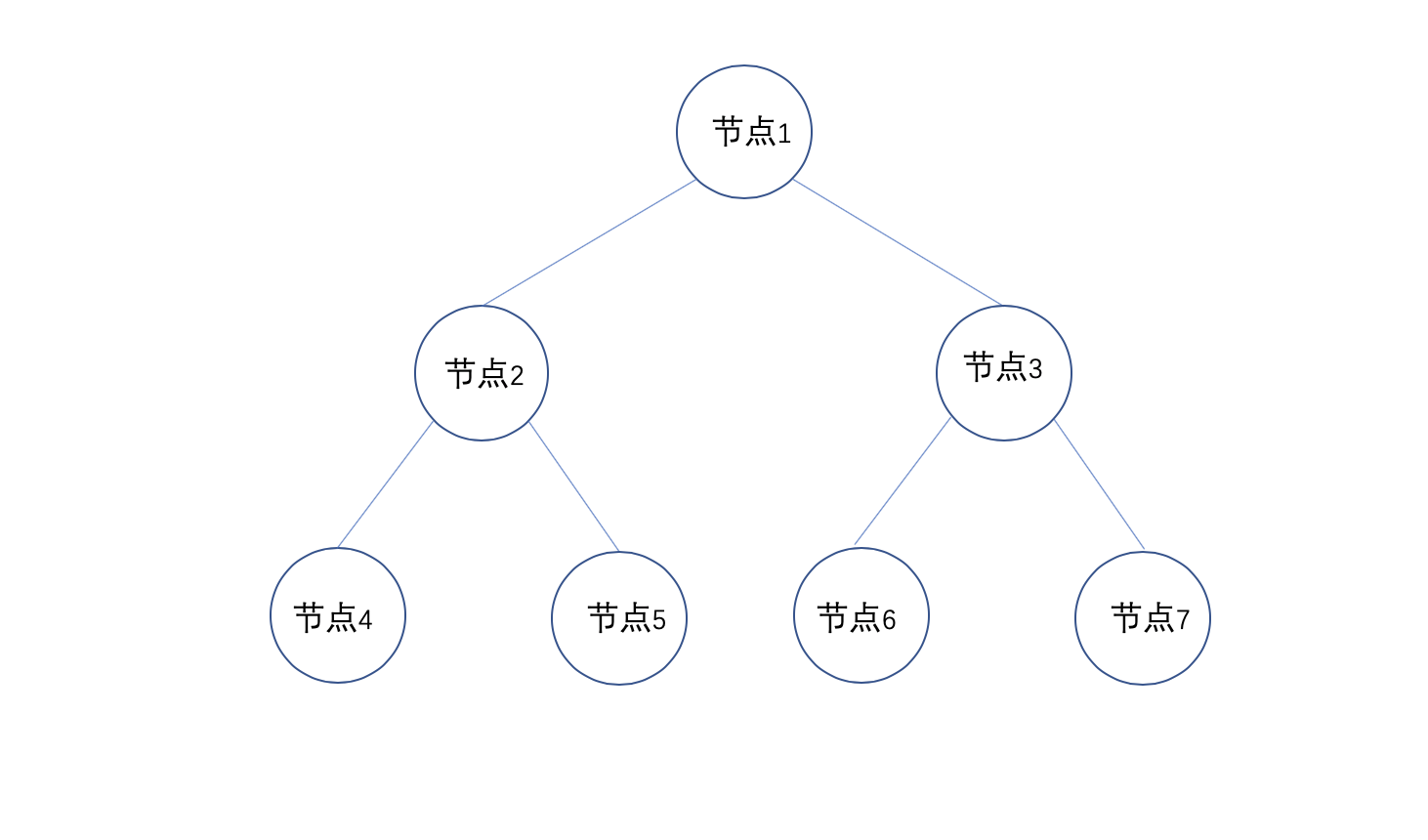
图 2 中,按照广度遍历的顺序,依次为每一个节点赋予一个节点编号,节点编号的作用在后面的流程中会使用到。
另外 numLeaves 也用来初始化例如 splitPackedValues、leafBlockFPs,见下文。
splitPackedValues
splitPackedValues 是一个字节数组,该值用来描述每一个节点使用哪个维度(维度编号)进行划分以及维度的值(在本篇文章中暂时不用理解这段话,在后面的文章中展开介绍),在当前流程点,我们只需要知道该数组的初始化的时机点,初始化的代码很简单,故直接给出:
|
|
上述代码中,numLeavs 为即将构建的 BKD 树中的叶子节点的数量,bytesPerDim 的值为每个维度的值占用的字节数量,例如 int 类型的维度值占用 4 个字节(见文章 索引文件的生成(八)之 dim&&dii 中关于数值类型转为为字节类型的介绍)。
leafBlockFPs
leafBlockFPs 是一个 long 类型的数组,在当前流程点被初始化,如下所示:
|
|
leafBlockFPs 在随后的流程中会记录每一个叶子节点的信息在索引文件。dim 中的起始位置,如下所示:
图 3:
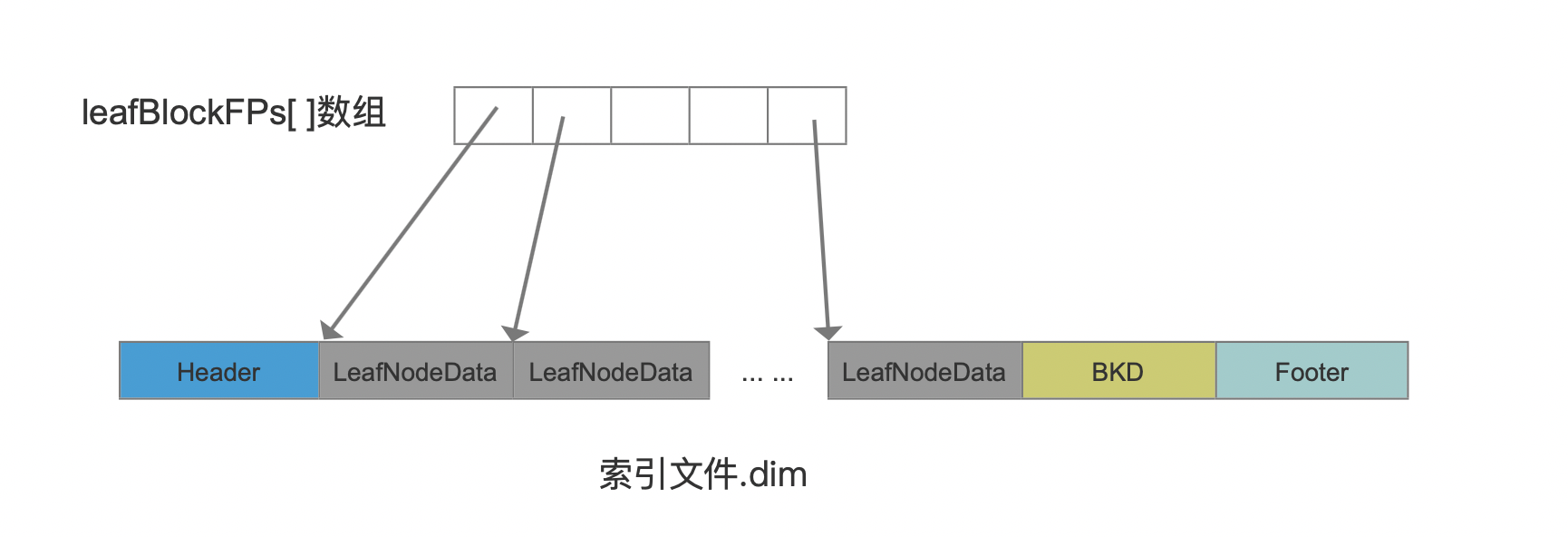
图 2 中的 LeafNodeData 描述的是每个叶子节点的信息,可见 leafBlockFPs 数组中的数组元素数量为叶子节点的数量,即上文中的 numLeaves。
docsSeen
docsSeen 是一个 FixedBitSet 对象,用来 去重记录 包含当前点数据域的文档的数量,例如我们添加下面两篇文档:
图 4:
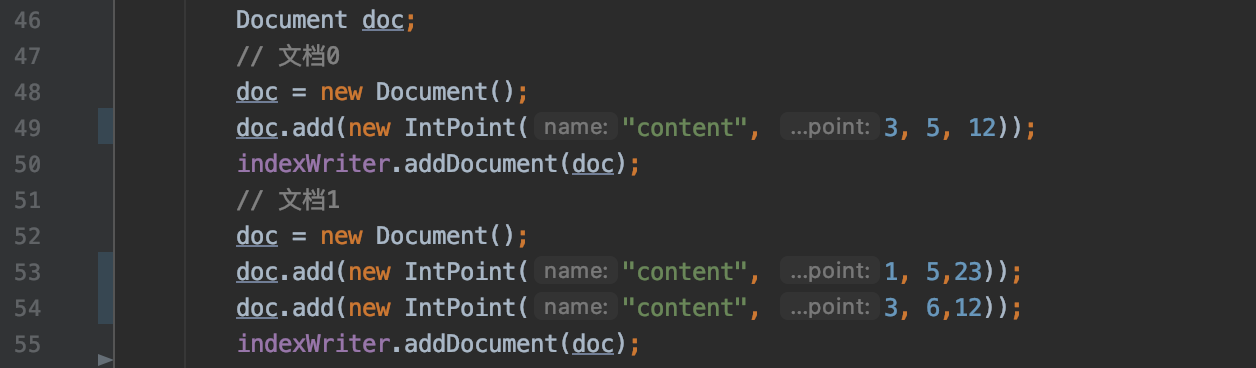
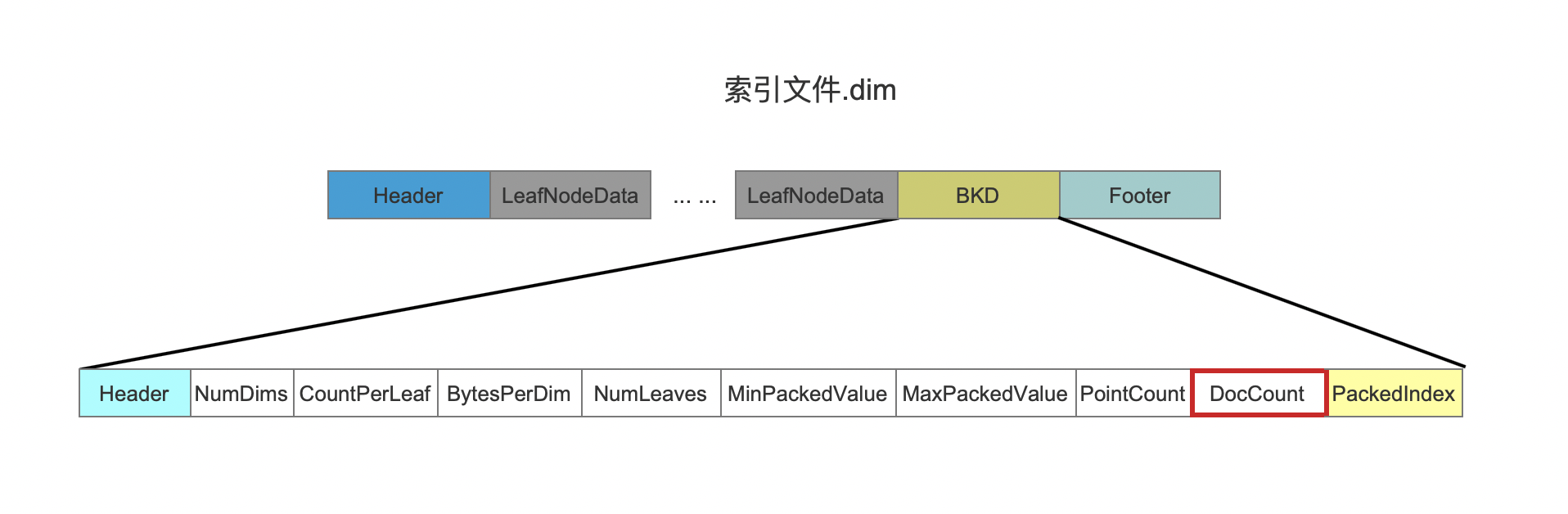
图 3 中,尽管有 3 条点数据内容,但是文档 1 中包含了 2 条,那么包含域名为"content"的点数据的文档的数量为 2,docsSeen 中统计的文档数量在后面的流程会被写入到索引文件。dim 中,如下红框所示:
图 5:
parentSplits
parentSplits 是一个 int 类型的数组,首先看下初始化这个数组的源码:
|
|
上述源码中,numDims 指的是当前处理的点数据的维度数,例如图 3 中处理的是三维的点数据,那么 numDims 的值为 3。
在文章 Bkd-Tree 中介绍关于 选出切分维度 的内容时候说到,选择的判断依据如下:
|
|
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%E7%B4%A2%E5%BC%95%E6%96%87%E4%BB%B6%E7%9A%84%E7%94%9F%E6%88%90%E4%B9%9D%E4%B9%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


