源码系列索引文件的生成七之
本文承接 索引文件的生成(六) 继续介绍剩余的内容,下面先给出生成索引文件。tim、.tip 的流程图。
生成索引文件。tim、.tip 的流程图
图 1:
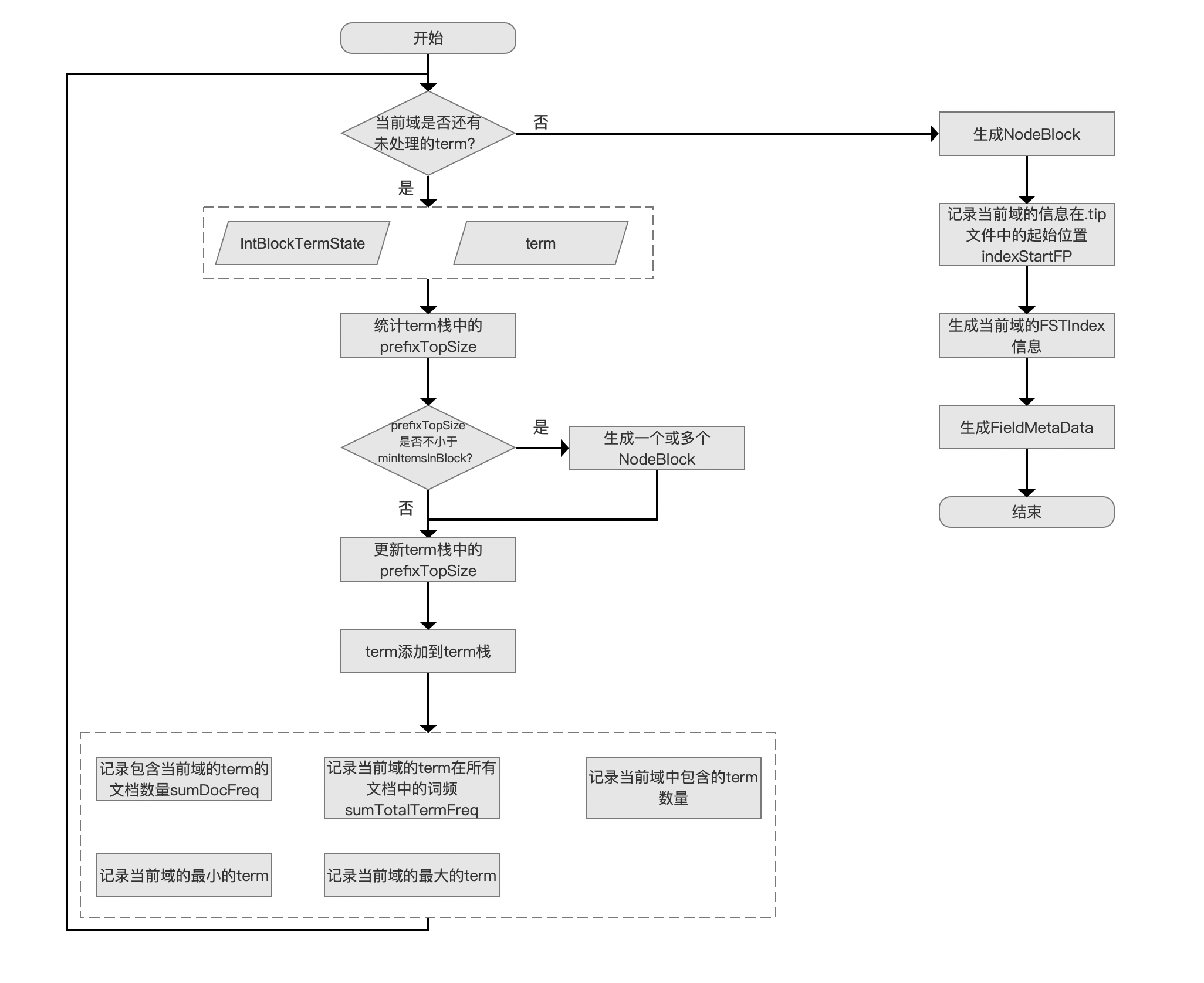
统计每一个 term 的信息
图 2:
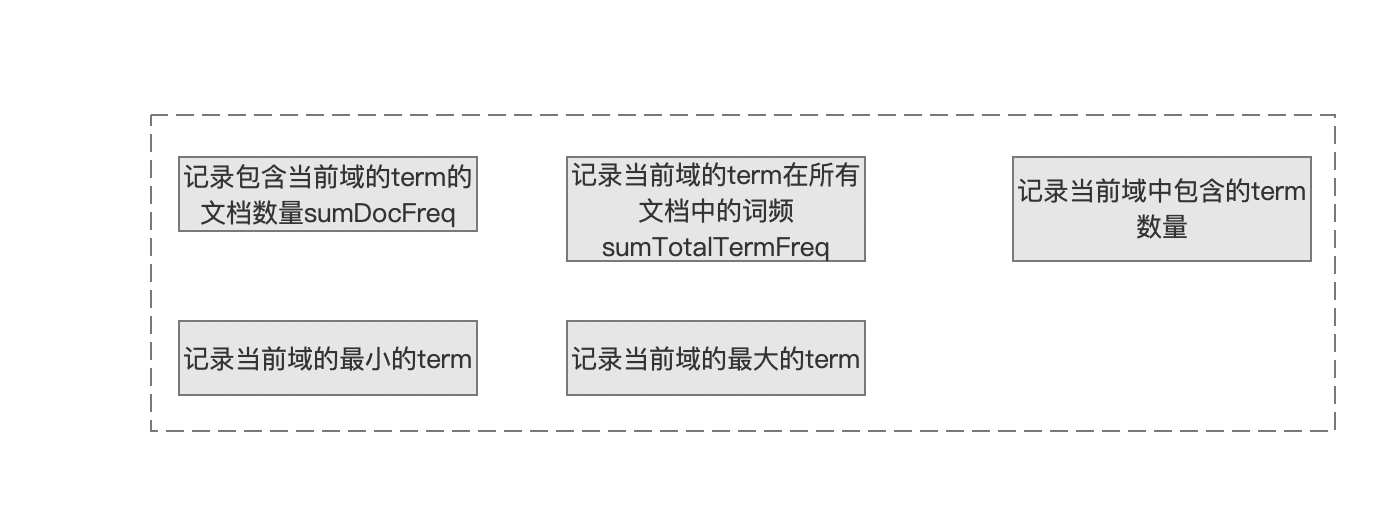
执行到该流程,我们需要将当前 term 的一些信息(图 1 中的 IntBlockTermState,见文章 索引文件的生成(五))的汇总到所属域的信息中(这里先提一下的是,这些信息在后面使用 FieldMetaData 封装),图 2 中出现的字段的含义如下:
- sumDocFreq:包含当前域的所有 term 的文档数量总和,注意的是当前域可能有多个 term 在同一文档中
- sumTotalTermFreq:当前域的所有 term 在所有文档中出现的次数总和
- numTerms:当前域中的 term 数量
- minTerm:当前域中最小(字典序)的 term
- maxTerm:当前域中最大(字典序)的 term
例如我们有如下几篇文档:
图 3:

其中用红色标注的 term 属于域名为"content"的域,那么在处理完"content"之后,图 2 中的字段的值如下所示:
- sumDocFreq:b(2)+ c(3)+ f(1)+ h(1)= 7
- sumTotalTermFreq:b(3)+ c(3)+ f(1)+ h(1)= 8
- numTerms:b、c、f、h 共 4 个 term
- minTerm:b
- maxTerm:h
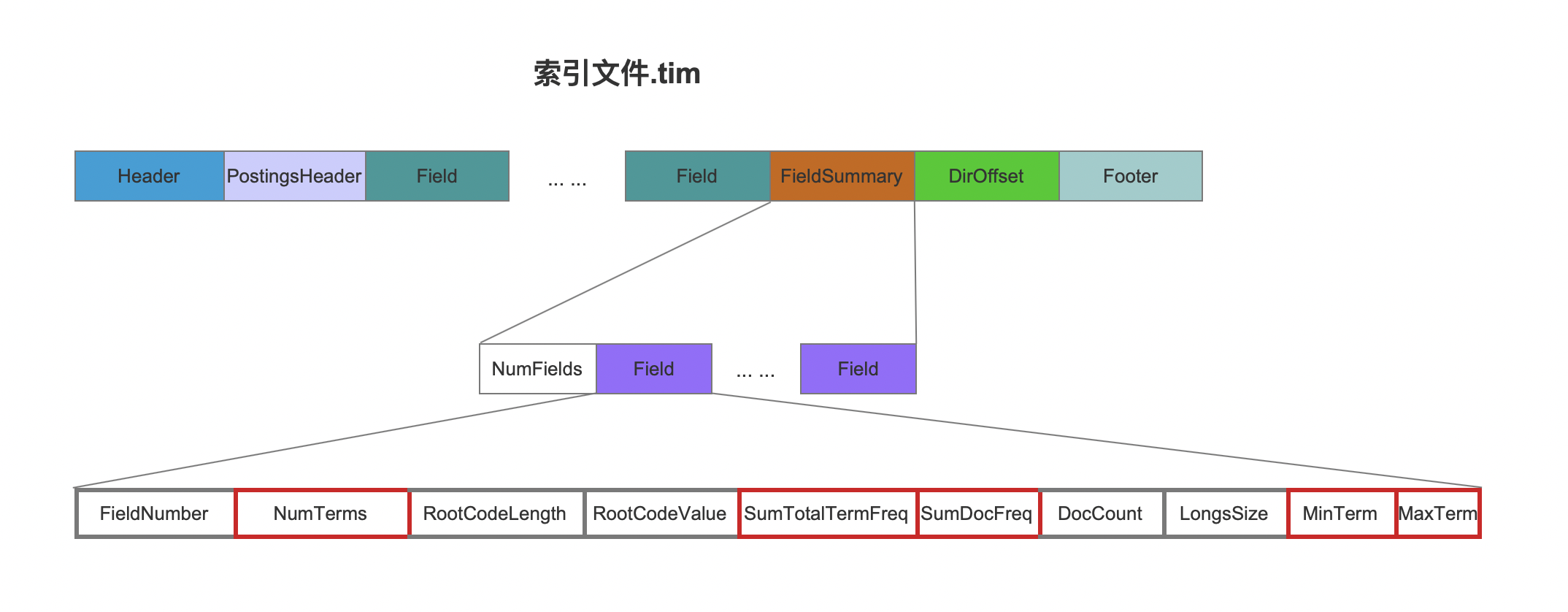
再处理完所有域之后,上述的信息在索引文件。tim 中的位置如下:
图 4:
生成 NodeBlock
图 5:

当前域的所有 term 处理结束后,那么将 term 栈中剩余未处理的 PendingEntry 生成 NodeBlock(见文章 索引文件的生成(六))。
记录当前域的信息在。tip 文件中的起始位置 indexStartFP
图 6:

到此流程,Lucene 将要在索引文件。tip 中写入当前域的 FSTIndex 信息,在读取阶段,通过读取索引文件。tip 中的 FSTIndex 信息来获取当前域在索引文件。tim 的内容,而所有域的 FSTIndex 信息连续的存储在索引文件。tip 中,那么需要 indexStartFP 来实现"索引"功能,如下图所示:
图 7:

生成当前域的 FSTIndex 信息
图 8:

在图 5 的流程中,当前域的所有 term 处理结束后,term 栈中剩余未处理的 PendingEntry 会被处理为 NodeBlock,最终只会生成一个 PendingBlock(没明白?见文章 索引文件的生成(六)),并且 PendingBlock 中的 index 信息,即 FST 信息将会被写入到 FSTIndex 中,由于本人还未对 FST 在 Lucene 中的应用有过文章的介绍,即使在本篇文章中列出 FSTIndex 中包含的字段信息,相信读者也无法理解,故只能通过几句话大概介绍下 FSTIndex 的内容以及功能:FSTIndex 包含了当前域中的 term 的一些前缀值的信息,根据该信息就可以在索引文件。tip 中找到每一种前缀值对应的 NodeBlock,该 NodeBlock 中包含了具有该相同前缀值的所有 term 的信息。
在文章 FST 算法(上) 中只是简单的介绍了 FST 的
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%E7%B4%A2%E5%BC%95%E6%96%87%E4%BB%B6%E7%9A%84%E7%94%9F%E6%88%90%E4%B8%83%E4%B9%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


