源码系列索引文件的生成一之
在执行 flush()的过程中,Lucene 会将内存中的索引信息生成索引文件,其生成的时机点如下图红色框标注:
图 1:
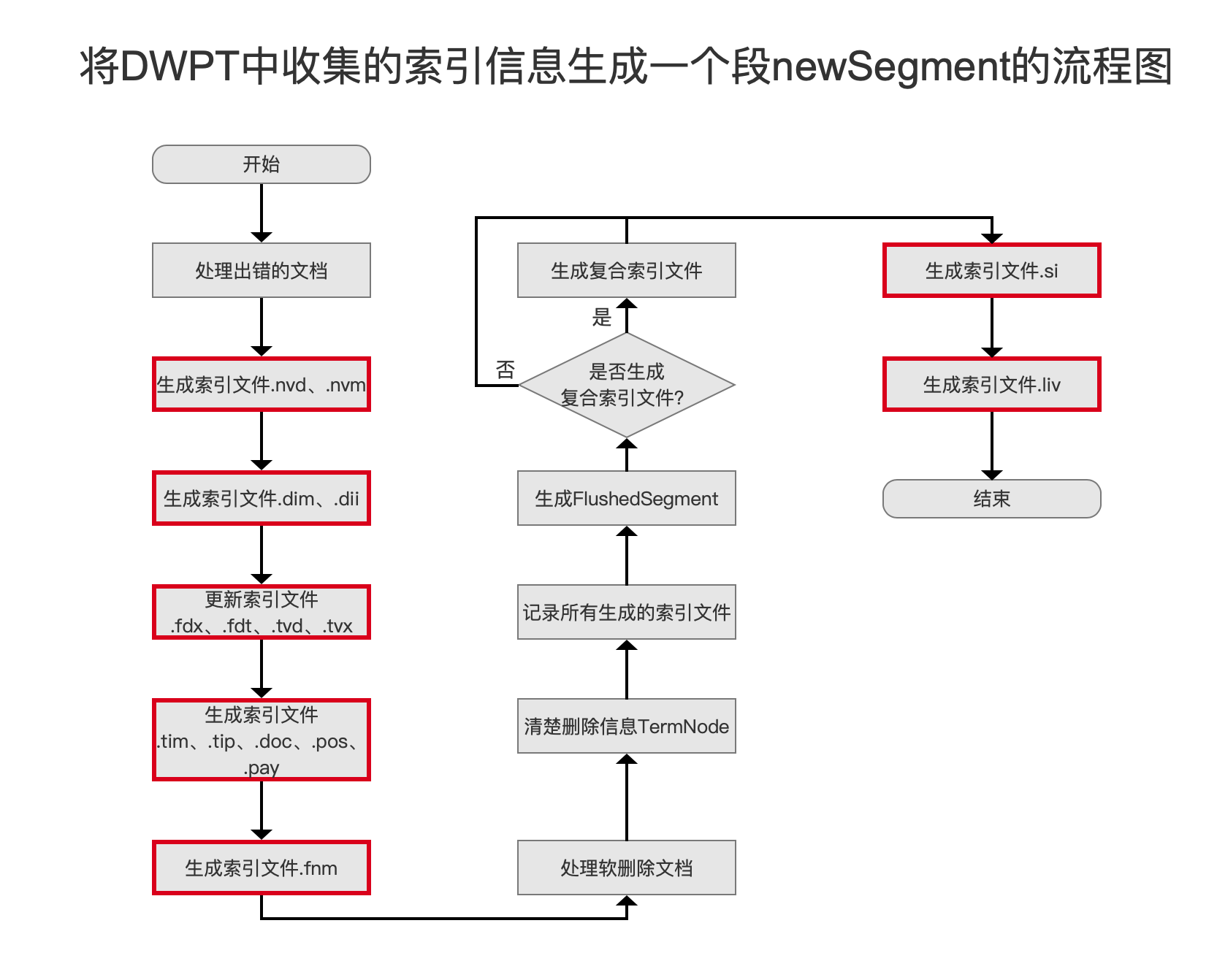
图一中的流程是 flush()阶段的其中一个流程点,完整的 flush()过程可以看系列文章 文档提交之 flush, 索引文件的生成 系列文章将会介绍图一中红框标注的每一个流程点,本篇文章先介绍 生成索引文件 .tim、.tip、.doc、.pos、.pay 流程点。
生成索引文件。tim、.tip、.doc、.pos、.pay
在添加文档阶段,一篇文档中的 term 所属文档号 docId,在文档内的出现次数 frequency,位置信息 position、payload 信息、偏移信息 offset,会先被存放到 倒排表 中,随后在 flush()阶段,读取倒排表的信息,将这些信息写入到索引文件 .tim、.tip、 .doc、 .pos、.pay 中。
生成索引文件。tim、.tip、.doc、.pos、.pay 的流程图
图 2:
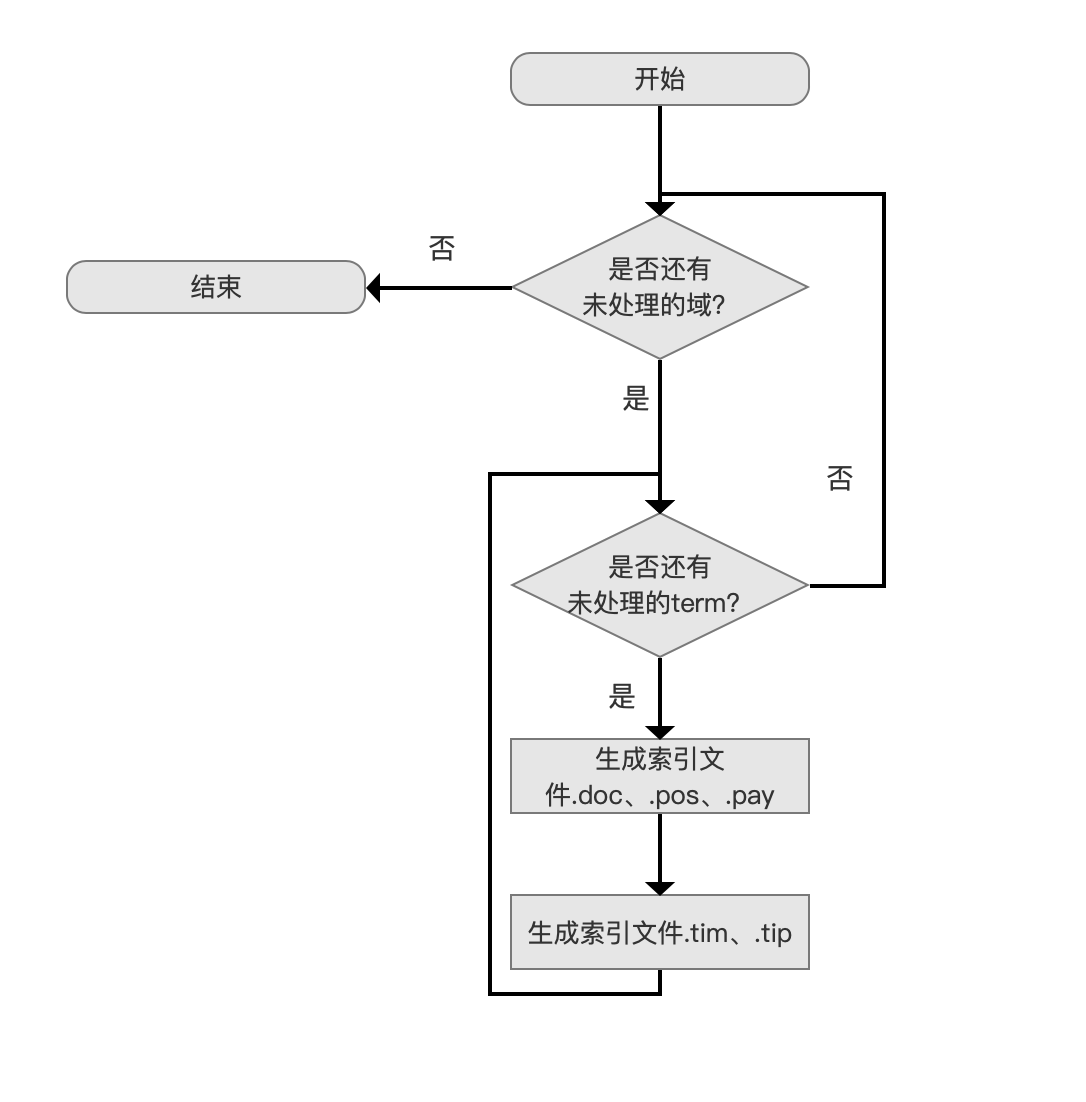
写入索引文件的顺序
图 3:
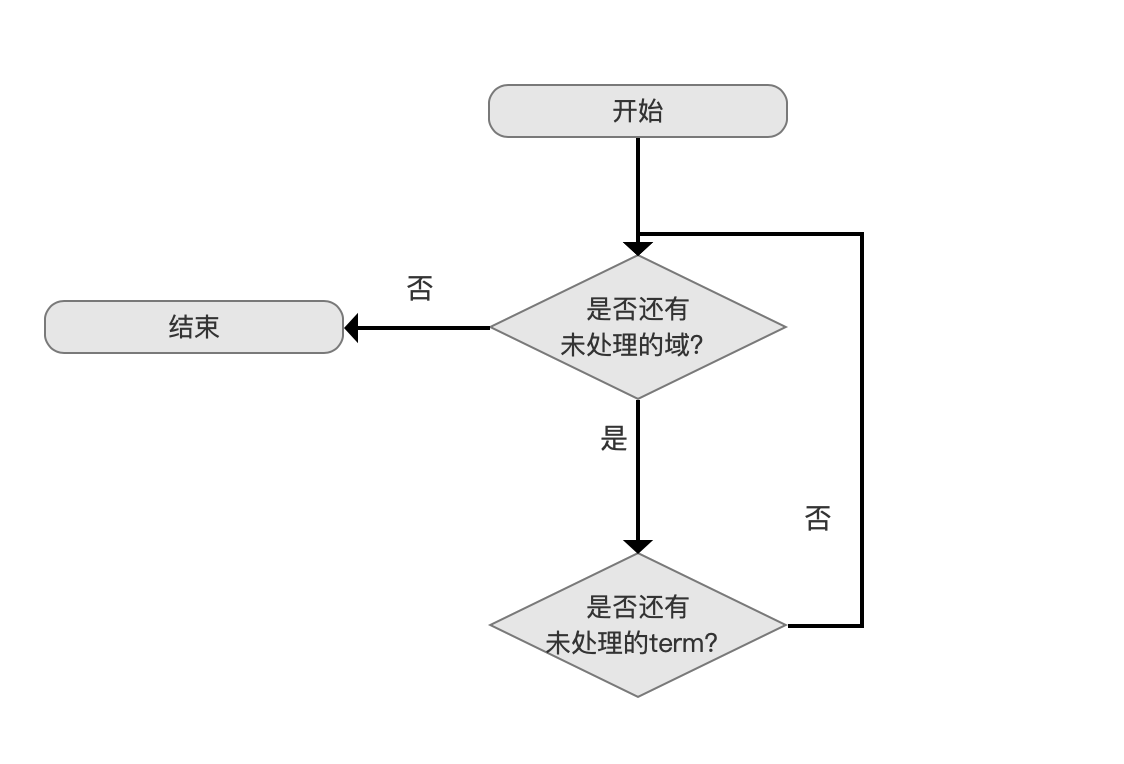
在文章 倒排表 中我们知道,倒排表中的内容按照域进行划分,域之间可能存在相同的 term,但是一个域内 term 是唯一的,故其写入索引文件的顺序如图 3 所示, 域间(between filed)根据域名(field name)的字典序处理,域内(inner field)按照 term 的字典序进行处理。
生成索引文件.doc、.pos、.pay
图 4:

我们先介绍在 一个域内,生成索引文件.doc、.pos、.pay 的逻辑。
生成索引文件.doc、.pos、.pay 的流程图
图 5:
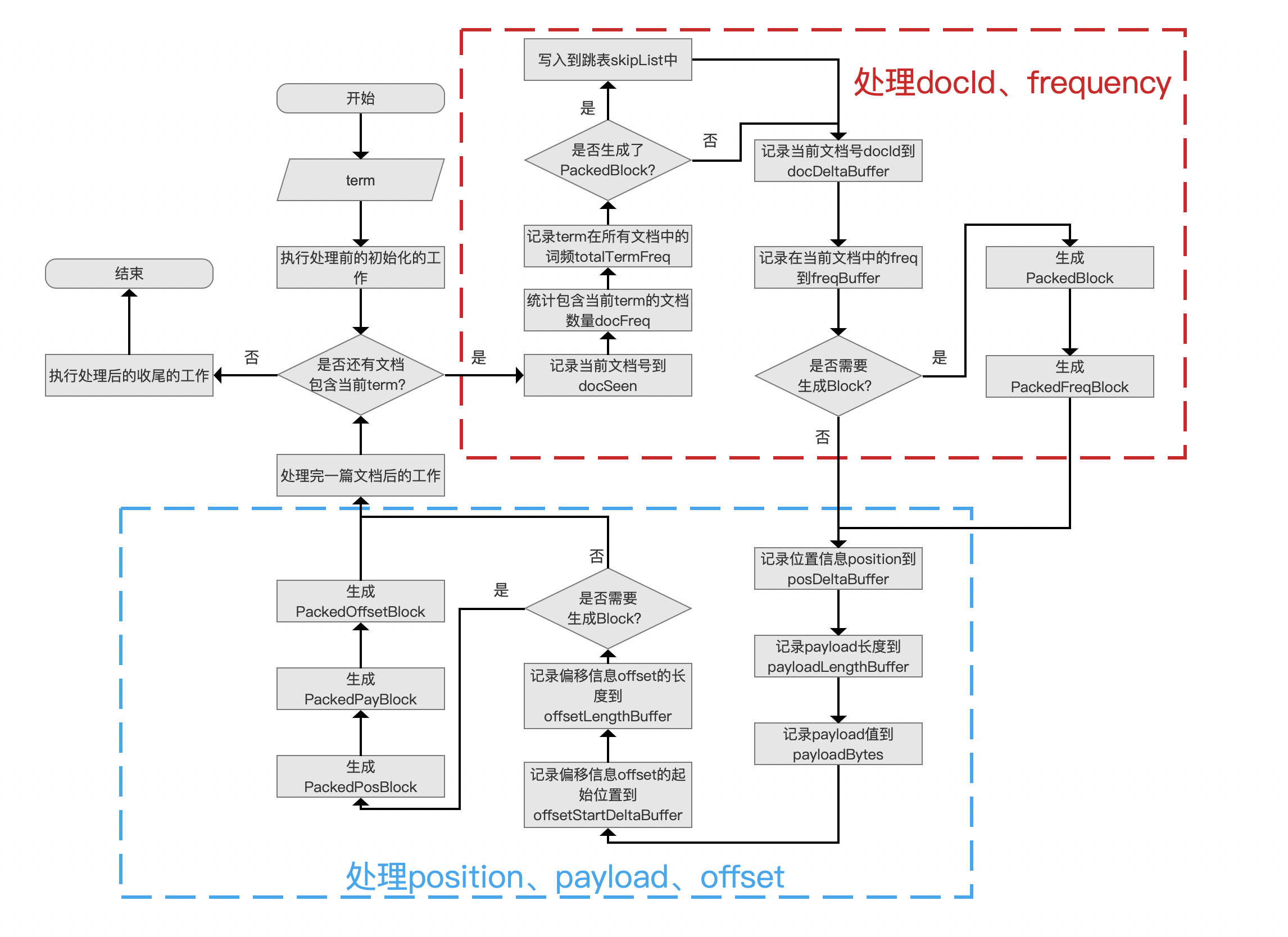
图 5 描述的是同一个域内处理一个 term,生成索引文件.doc、.pos、.pay 的过程。
执行处理前的初始化的工作
图 6:
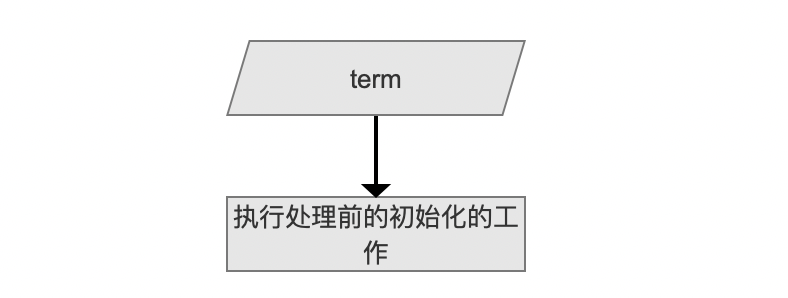
依次处理当前域中所有的 term,并且是按照 term 的字典序处理。
为什么要按照 term 的字典序处理:
- 在后面介绍生成 索引文件.tim、tip 时,需要存储 term 的值,而相邻有序的 term 更有可能具有相同的前缀值,那么通过前缀存储(见 索引文件之 tim&&tip)就可以节省存储空间。
在处理一个 term 前,我们先要 执行处理前的初始化的工作,工作内容为获取上一个 term 后处理结束后的信息,包括以下信息:
- docStartFP:当前 term 在 索引文件.doc 中的起始位置,在后面的流程中,当前 term 的文档号 docId、词频 frequency 信息将从这个位置写入,因为索引文件是以数据流的方式存储,所以 docStartFP 也是上一个 term 对应的信息在索引文件.doc 中的最后位置 +1
- posStartFP:当前 term 在 索引文件.pos 中的起始位置,在后面的流程中,当前 term 的位置 position 信息从这个位置写入,因为索引文件是以数据流的方式存储,所以 posStartFP 也是上一个 term 对应的信息在索引文件。pos 中的最后位置 +1
- payStartFP:当前 term 在 索引文件.pay 中的起始位置,在后面的流程中,当前 term 的偏移 offset、payload 信息从这个位置写入,因为索引文件是以数据流的方式存储,所以 payStartFP 也是上一个 term 对应的信息在索引文件。pay 中的最后位置 +1
- 重置跳表信息:该信息在后面介绍跳表时再展开介绍
图 7:
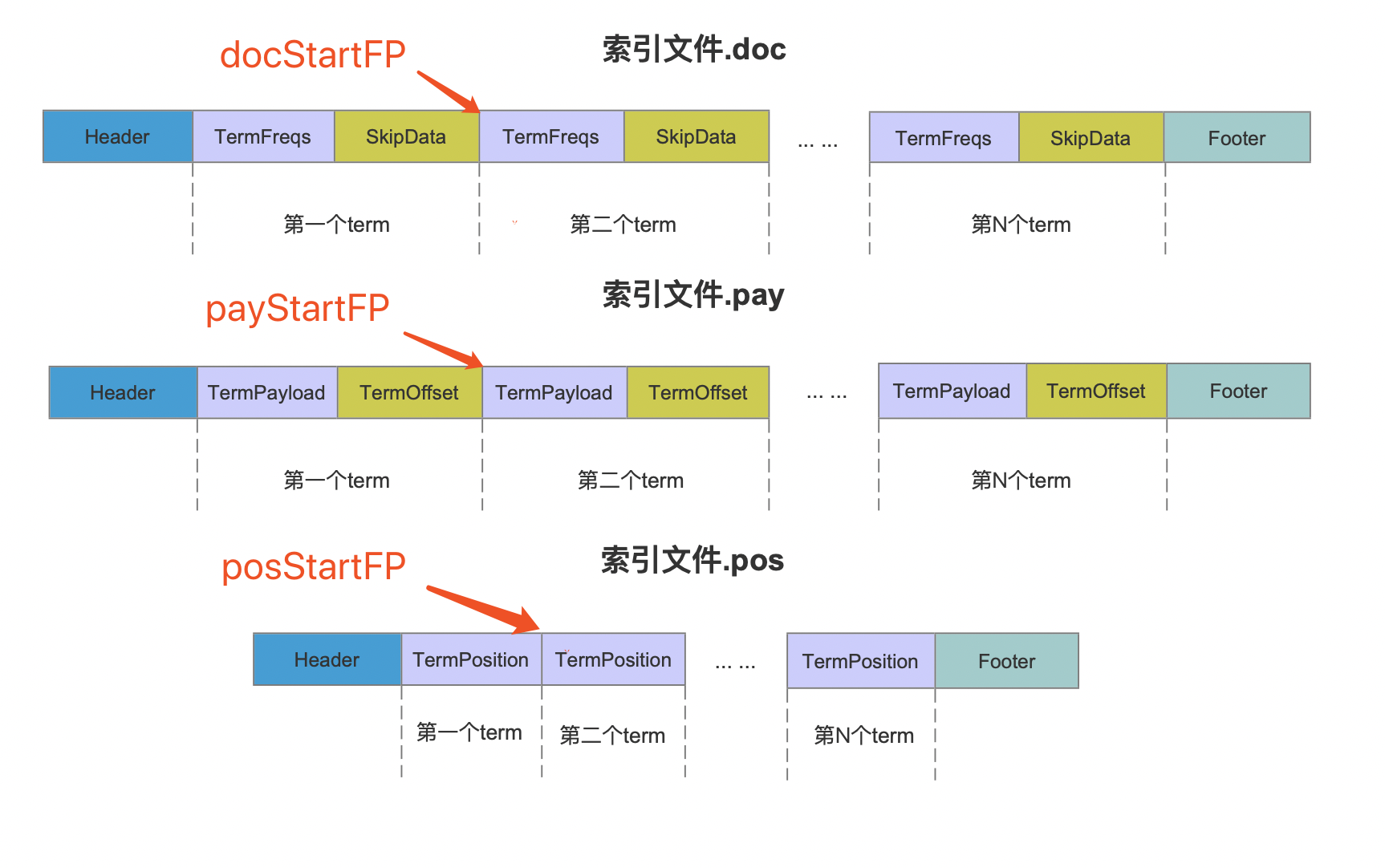
图 7 中,如果 当前开始处理第二个 term,那么此时 docStartFP(docStart File Pointer 缩写)、posStartFP、payStartFP 如上所示,这几个信息将会被写入到索引文件。tim、.tip 中,本文中我们只需要知道生成的时机点,这些信息的作用将在后面的文章中介绍。
是否还有文档包含当前 term?
图 8:
按照文档号从小到大,依次处理当前 term 在一篇文档中的信息,这些文档中都包含当前 term。
记录当前文档号到 docSeen
图 9:

使用 FixedBitSet 对象 docSeen 来记录当前的文档号,docSeen 在生成 索引文件.tim、tip) 时会用到,这里我们只要知道它生成的时间点就行。
记录 term 所有文档中的词频 totalTermFreq
图 10:

这里说的所有文档指的是包含当前 term 的文档,一篇文档中可能包含多个当前 term,那么每处理一篇包含当前 term 的文档,term 在这篇文档中出现的次数增量到 totalTermFreq,totalTermFreq 中存储了 term 在所有文档中出现的次数,同样增量统计 docFreq,它描述了包含当前 term 的文档数量。
totalTermFreq、docFreq 将会被存储到 索引文件.tim、tip) 中,在搜索阶段,totalTermFreq、docFreq 该值用来参与打分计算(见系列文章 查询原理)。
是否生成了 PackedBlock?
图 11:
每当处理 128 篇包含当前 term 的文档,就需要将 term 在这些文档中的信息,即文档号 docId 跟词频 frequency,使用 PackeInts 进行压缩存储,生成一个 PackedBlock。
图 12:
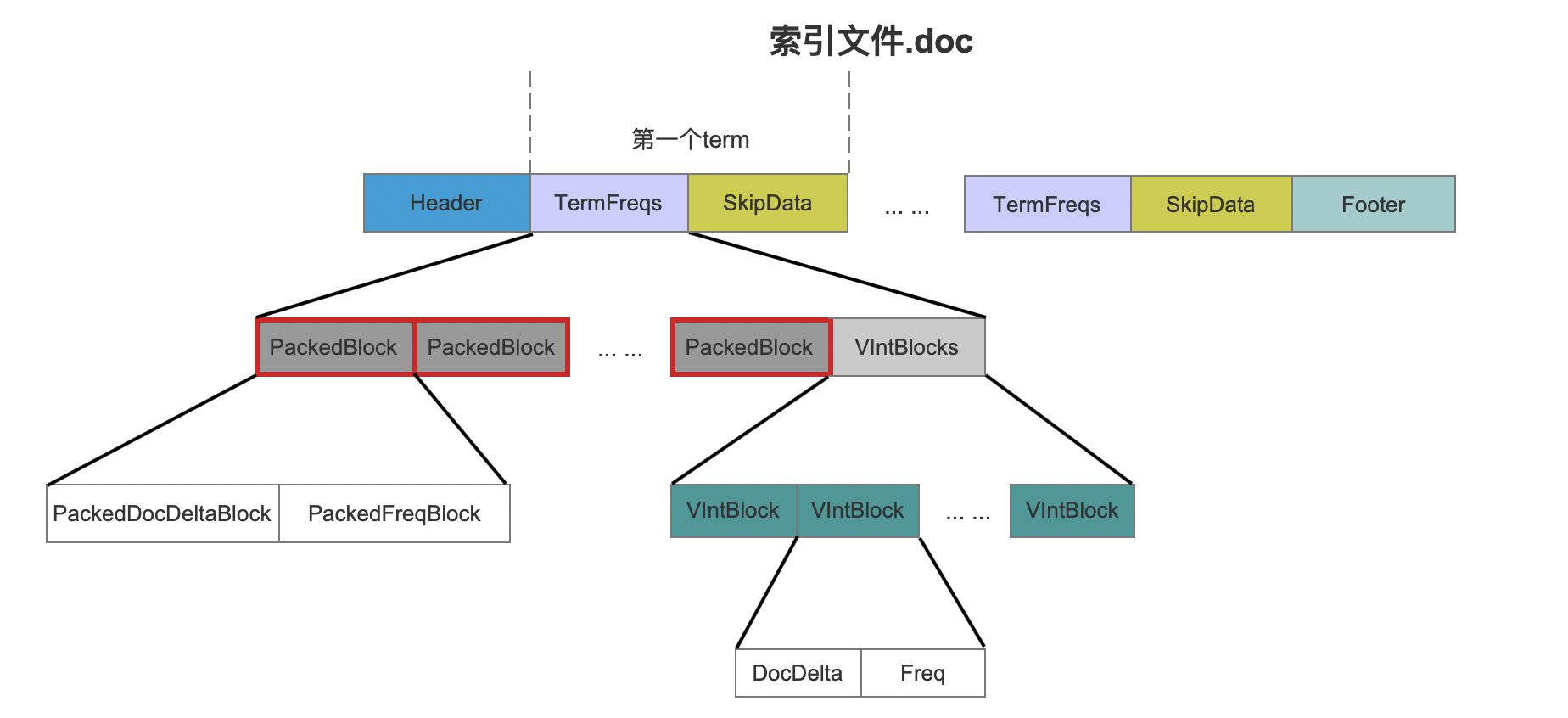
图 12 中,红框标注的即 PackedBlock,关于 PackedBlock 的介绍以及几个问题在后面的流程中会介绍,这里先抛出这几个问题:
- 为什么要生成 PackedBlock
- 为什么选择 128 作为生成 PackedBlock 的阈值
写入到跳表 skipList 中
图 13:

如果生成了一个 PackedBlock,那么需要生成跳表,使得能在读取阶段能快速跳转到指�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%E7%B4%A2%E5%BC%95%E6%96%87%E4%BB%B6%E7%9A%84%E7%94%9F%E6%88%90%E4%B8%80%E4%B9%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


