源码系列查询原理下
本文承接 Lucene 源码系列——查询原理(上) 。
第三小节
是否使用多线程
图 2:
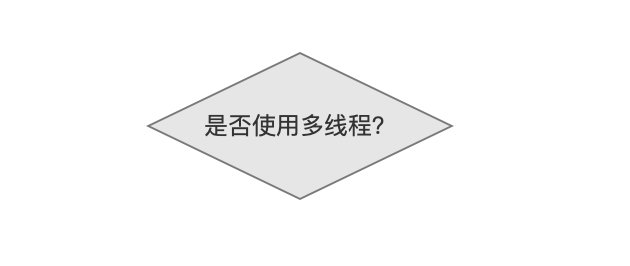
在生成 IndexSearcher 对象时,用户可以提供参数 ExecutorService,调用下面的 构造函数,来实现多线程搜索:
|
|
当索引目录中有多个段时,把对一个段的搜索(search by segment)作为一个任务(task)交给线程池,最后在合并(reduce)所有线程的查询结果后退出;如果不使用多线程,那么单线程顺序的对每一个段进行搜索,在遍历完所有的段后退出。
无论是否使用多线程,其核心流程是对一个段进行处理,故下文中我们只介绍单线程的流程,并且在最后介绍图 1 中的流程点 合并查询结果。
是否还有未查询的段
图 3:
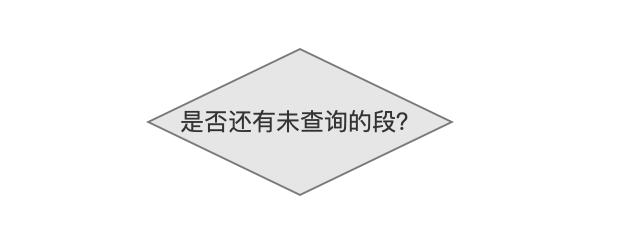
当索引目录中有多个段,那么每次从一个段中查询数据,直到所有的段都处理结束。
生成 BulkScorer
图 4:

该流程点将会获得查询对应的文档和词频,这些信息被封装在 BulkScorer 中。
如图 5 所示,不同的查询方式(见第一小节)有不一样 BulkScorer 对象(通过装饰者模式层层包装 BulkScorer 来实现多样的 BulkScorer),在本篇文章中只根据图 6、图 7 的中的 BooleanQuery 对应的 BulkScorer 展开介绍,其生成的 BulkScorer 对象为 ReqExclBulkScorer。
图 5 中是 BulkScorer 的类图:
图 5

图 6,索引阶段的内容:
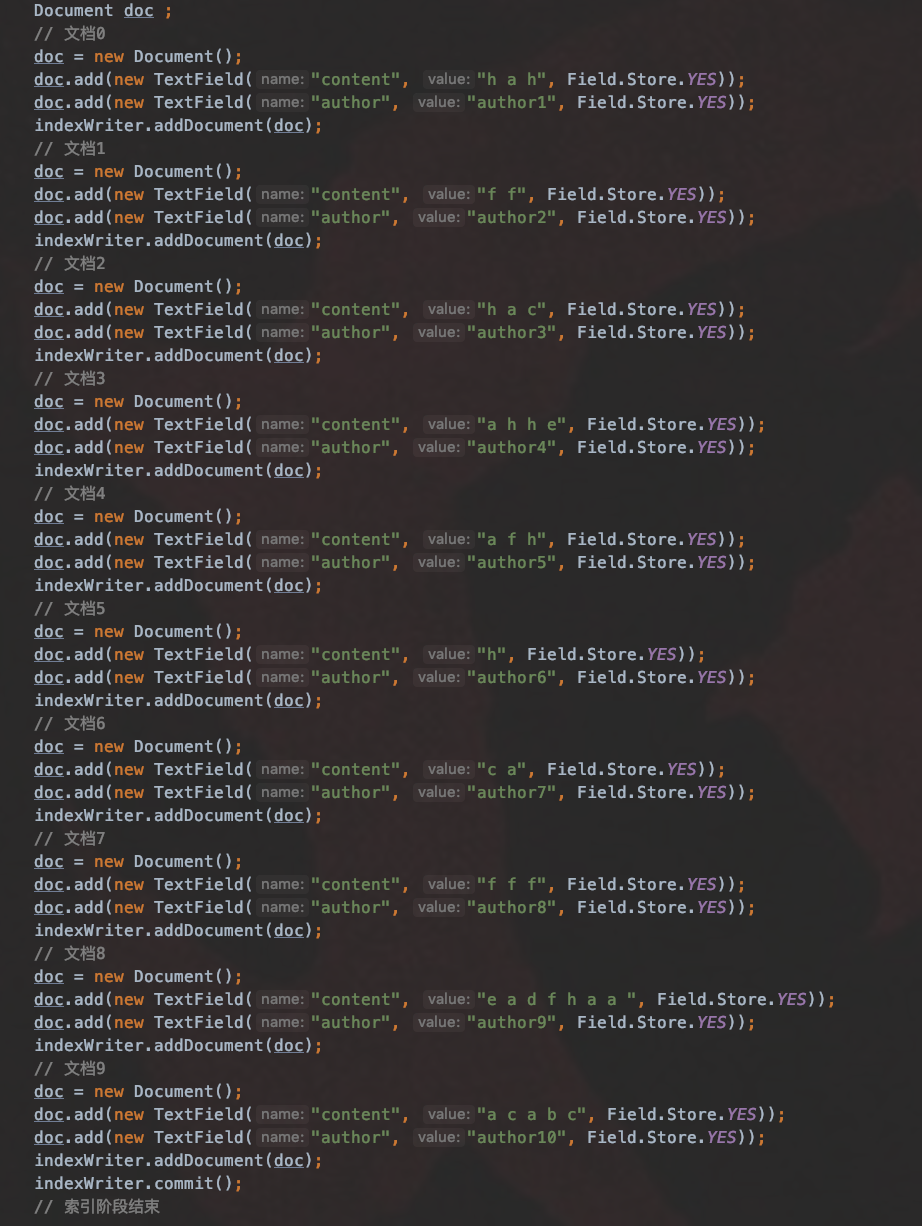
图 7,查询阶段的内容:
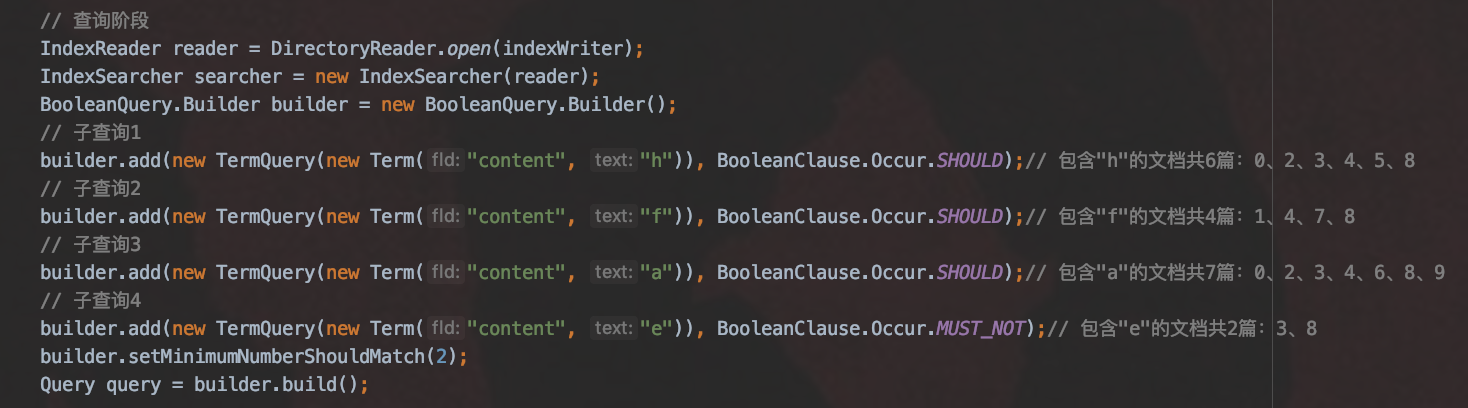
注意的是本文中的例子跟 查询原理(上) 中的 BooleanQuery 例子是不同的。
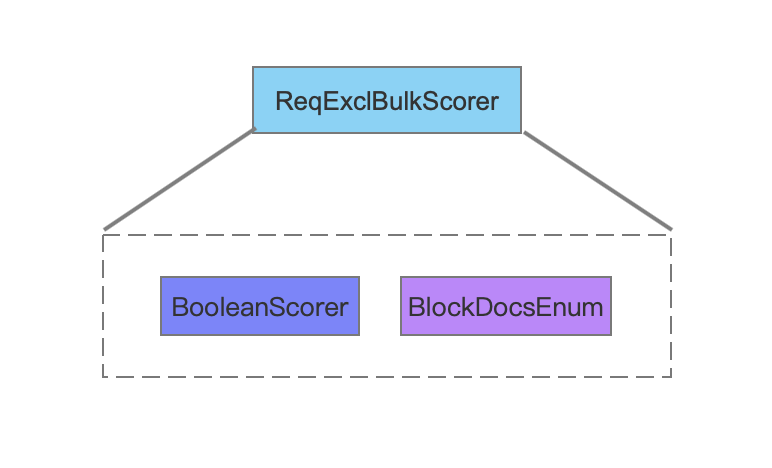
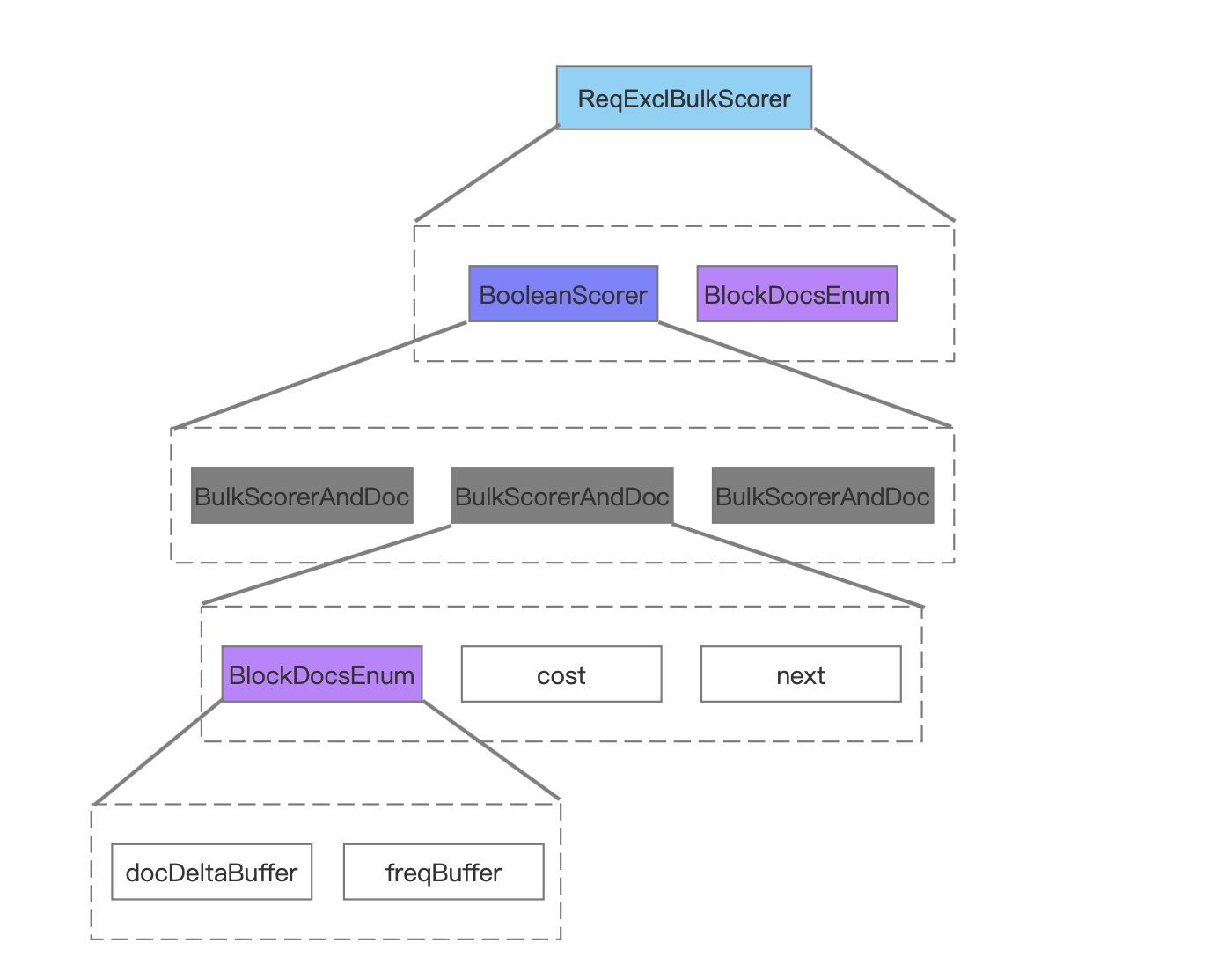
ReqExclBulkScorer
图 8 中描述的是 ReqExclBulkScorer 中包含的两个对象,其中 BooleanScorer 描述了 BooleanClause.Occure.SHOULD 的 TermQuery 的信息,BlockDocsEnum 描述了 BooleanClause.Occure.MUST_NOT 的 TermQuery 的信息。
图 8
BooleanScorer
图 9
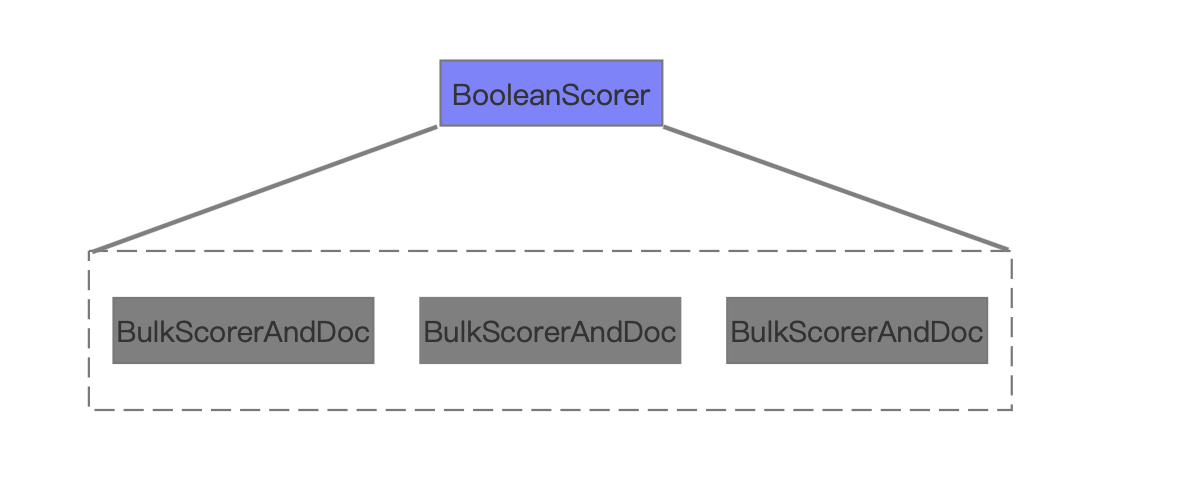
图 9 中描述的是 BooleanScorer 中的主要信息, 其包含的 BulkScorerAndDoc 的个数跟图 7 中 BooleanClause.Occure.SHOULD 的 TermQuery 的个数一致。
图 10
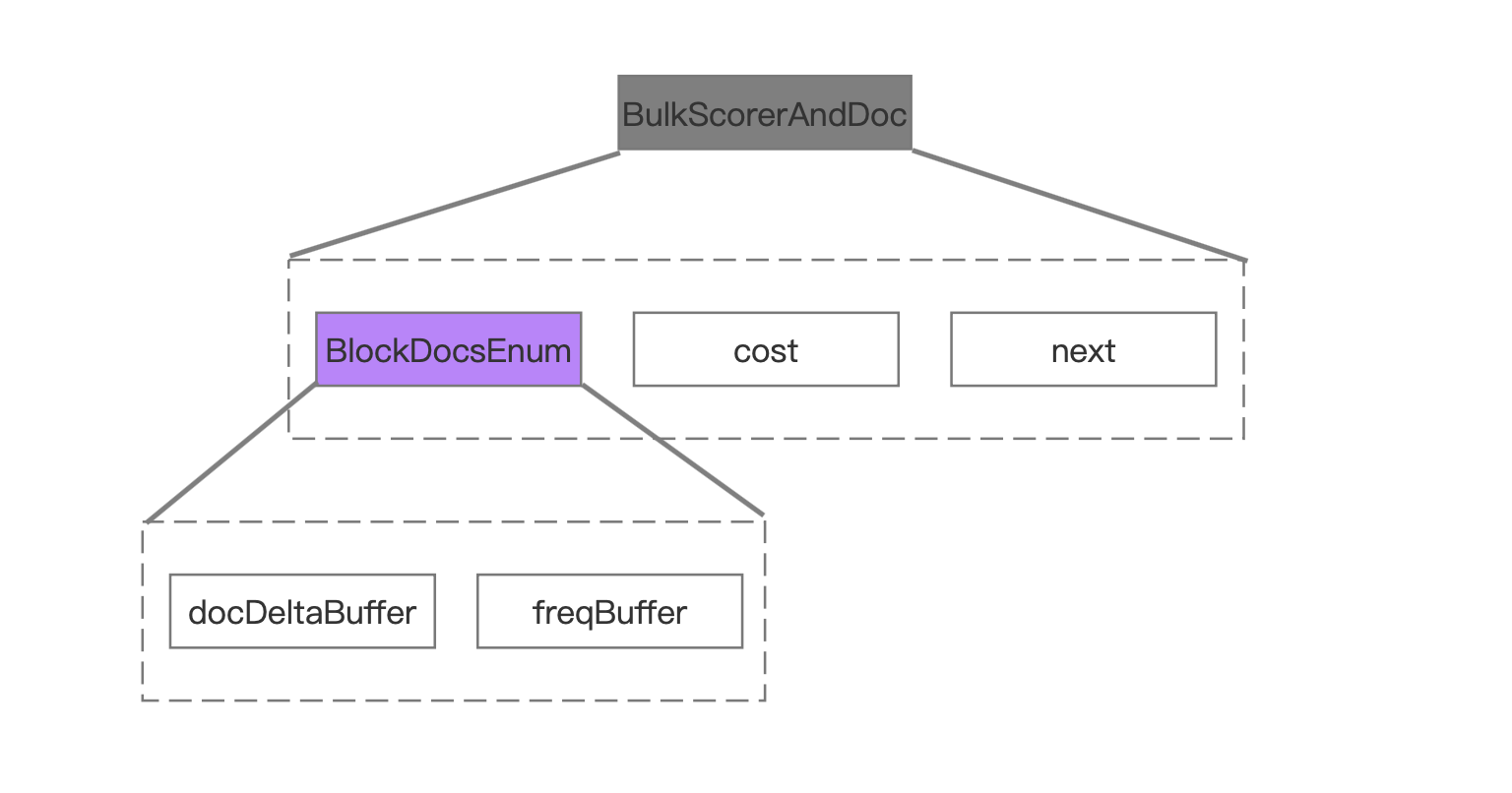
图 10 中描述的是 BulkScorerAndDoc 中包含的主要信息。
cost、next
这两个值在这里我先暂时不给出解释,因为在下一篇文章中才会使用到这两个值。
docDeltaBuffer、freqBuffer
docDeltaBuffer、freqBuffer 都是 int 数组类型,其中 docDeltaBuffer 中存放的是文档号,freqBuffer 中存放的是词频
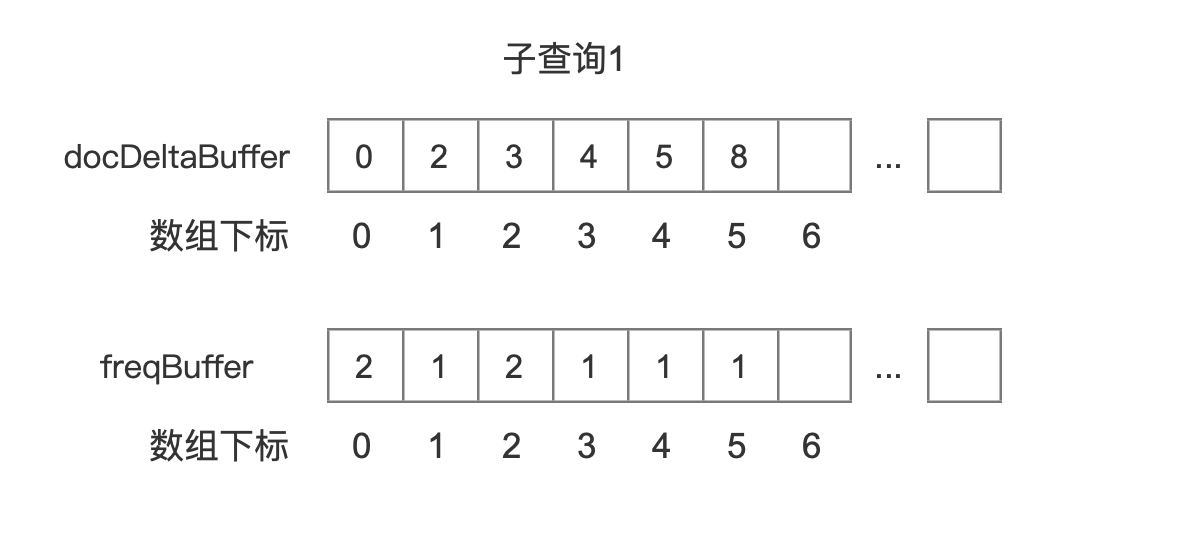
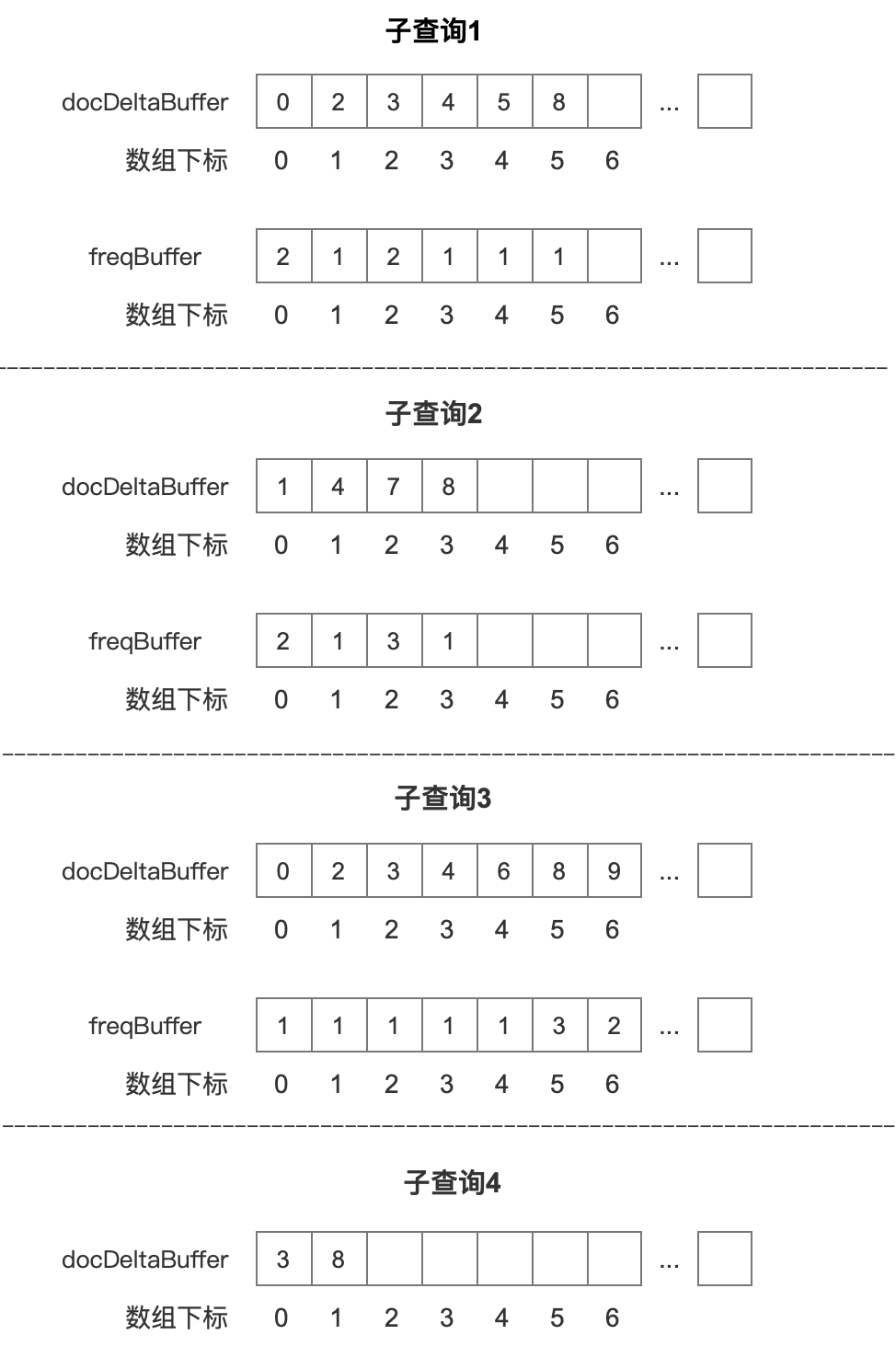
按照图 7 中的例子,4 个子查询对应的 BlockDocsEnum 中包含的两个数组 docDeltaBuffer、freqBuffer 如下所示:
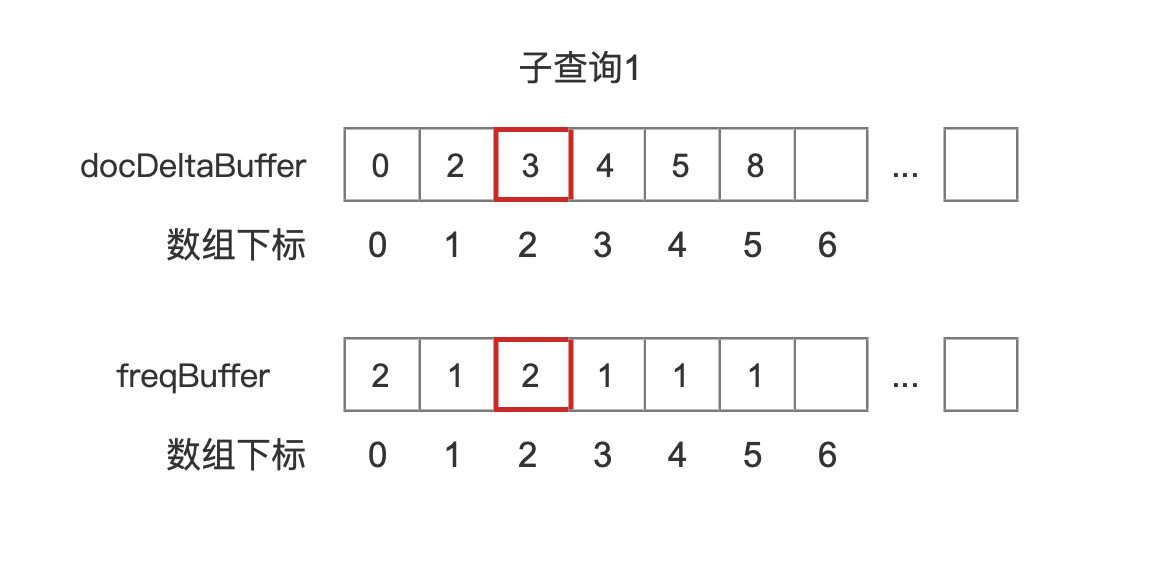
子查询 1
图 11
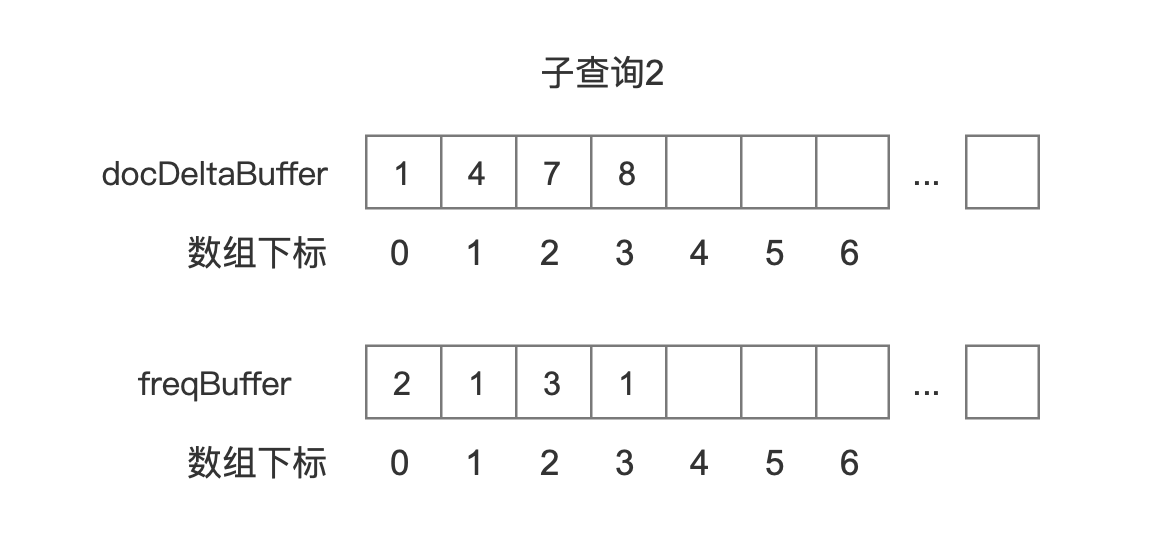
子查询 2
图 12
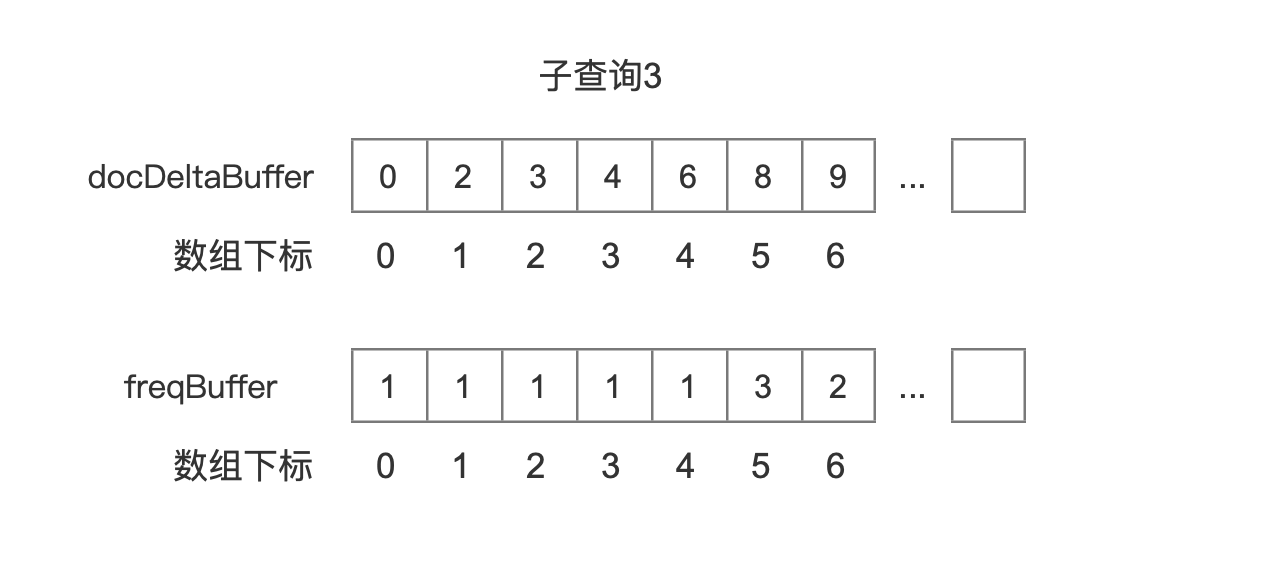
子查询 3
图 13
子查询 4
图 14
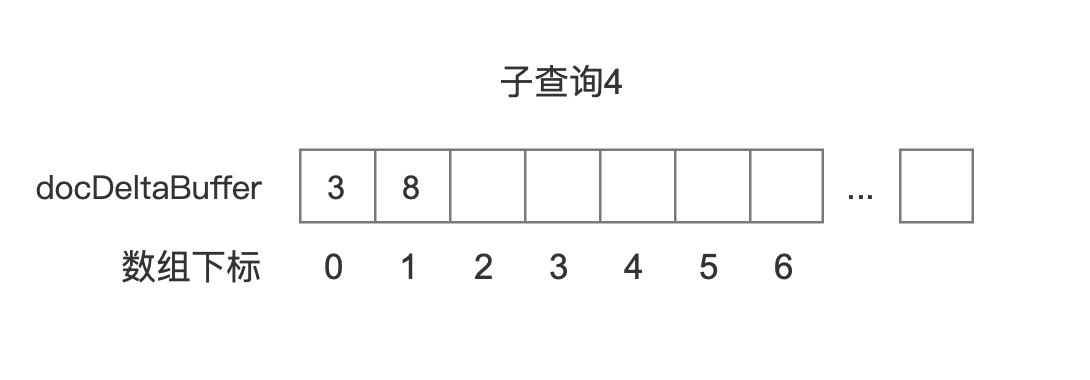
图 14 中我们没有列出该查询对应的 freqBuffer,原因是图 7 中子查询 4 属于 BooleanClause.Occure.MUST_NOT,我们只关心这个查询对应的文档号。
docDeltaBuffer、freqBuffer 的关系
两个数组的同一个数组下标值对应的数组元素描述的是域值在文档号中的词频,如图 15 所示:
图 15
在图 15 中,结合图 6,描述的是域值"h"在文档 3 中的词频是 2。
docDeltaBuffer、freqBuffer 数组的信息是通过读取索引文件 .doc 获得的。
图 16
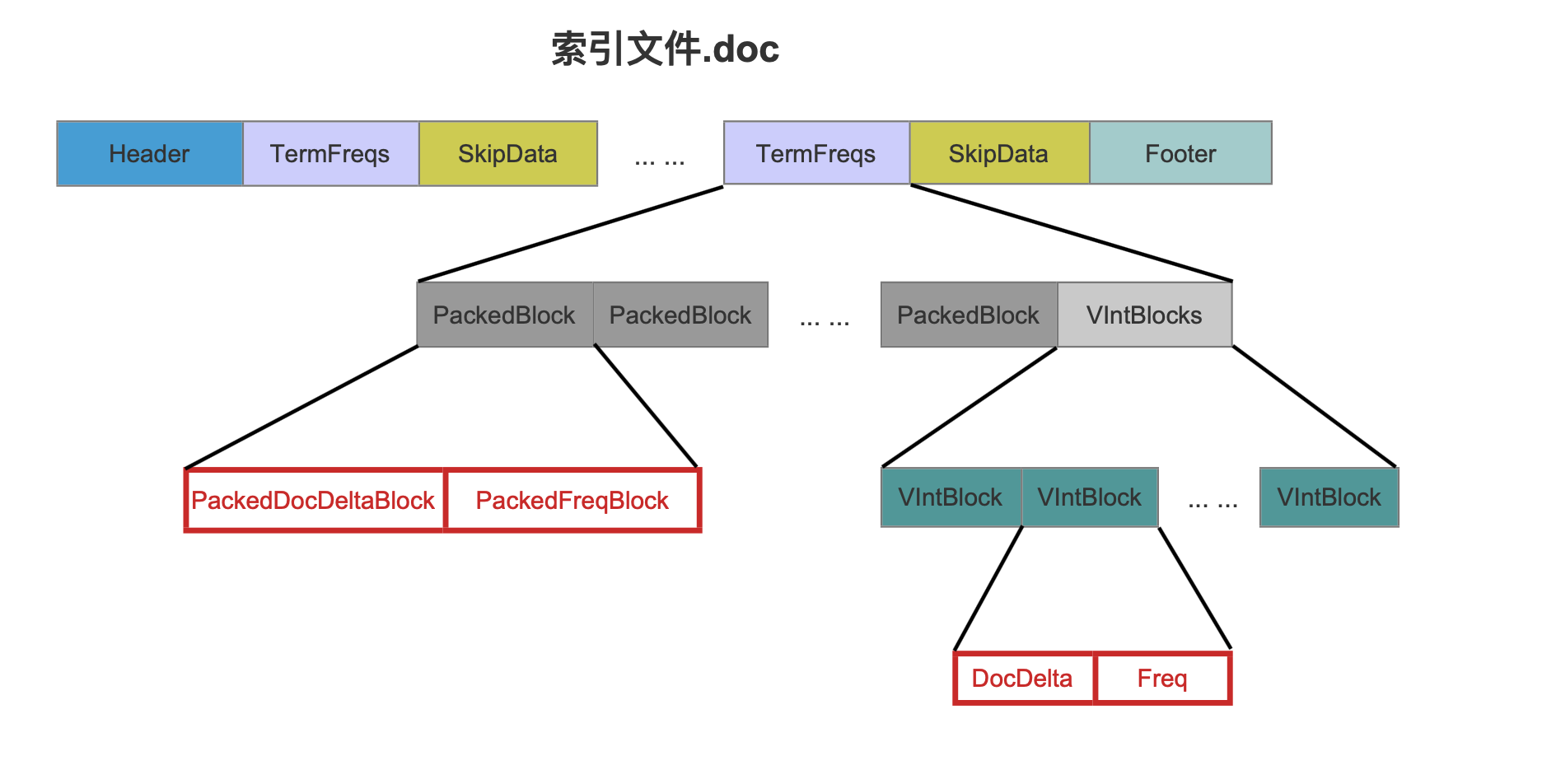
docDeltaBuffer、freqBuffer 数组的信息要么分别从图 16 中红框标注的 PackedDocDeltaBlock 跟 PackedFreqBlock 中获取,要么分别从 DocDelta 跟 Freq 获得,其选择方式和读取索引文件 .doc 的过程不在本篇文章中介绍,本人不想介绍的原因是,只要了解索引文件的数据结构是如何生成的,自然就明白如何读取索引文件~~
在 索引文件之 doc 文章中我们提到,文档号使用差值存储,所以实际在搜索阶段,我们获得的 docDeltaBuffer 数组中的数组元素都是差值,还是以图 7 中的子查询 1 为例,它获得真正的 docDeltaBuffer 数组如下所示:
图 17
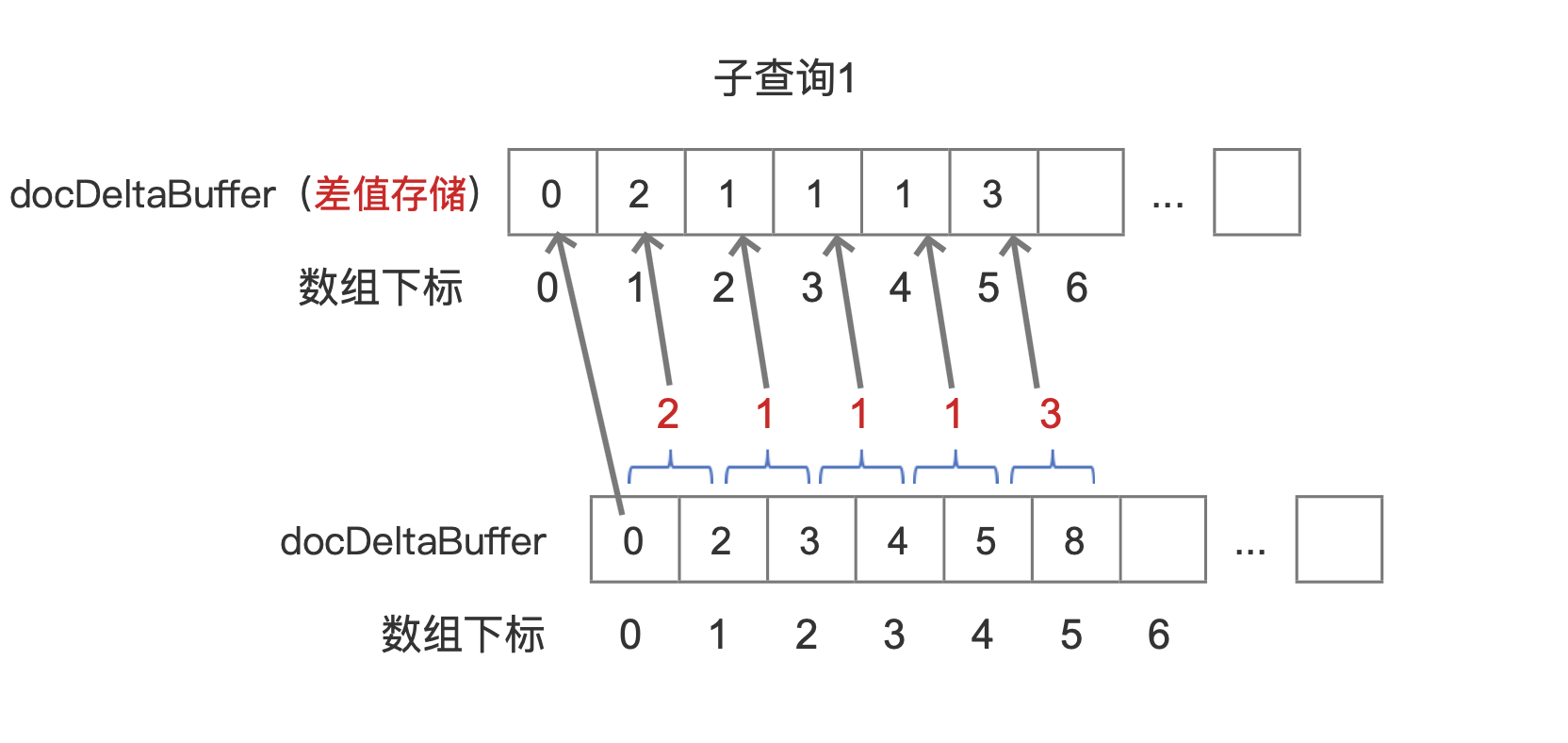
注意的是图 17 中使用差值存储的 docDeltaBuffer 数组, 它的第一个数组元素是原始值。
为什么要使用差值存储:
- 压缩数据,减少内存/磁盘占用
去重编码(dedupAndEncode) 的文章中详细介绍了差值存储,感兴趣的可以了解下。
关于 BulkScorer
在 查询原理(上) 的文章中我们提到,在生成 Weight 的阶段,除了文档号跟 term 在文档中的词频这两个参数,我们已经获得了计算文档打分的其他条件,而在生成 BulkScorer 的过程中,我们获得了每一个子查询对应的文档号跟词频,所以在图 1 的 生成Weight 跟 生成BulkScorer 两个流程后,我们获得了一个段中文档打分需要的所有条件。
最后给出完整 ReqExclBulkScorer 包含的主要信息:
图 18
结语
本篇文章中我们只介绍了在生成 BulkScorer 的过程中,我们获得了每一个子查询对应的文档号跟词频,实际上还有几个重要的内容没有讲述,这些内容用来描述在 Collector处理查询结果 的流程中如何对每一个子查询的文档号进行遍历筛选(即上文中为介绍的 next、cost 的信息),基于篇幅,这些内容在下一篇文章中展开介绍。
第四小节
本文承接第三小节,继续介绍查询原理。
图 2、图 3 是 BooleanQuery 的查询实例,在第三小节中我们根据这个例子介绍了 生成BulkScorer 的流程点,本篇文章根据这个例子,继续介绍图 1 中剩余的流程点。
图 2:
图 3:
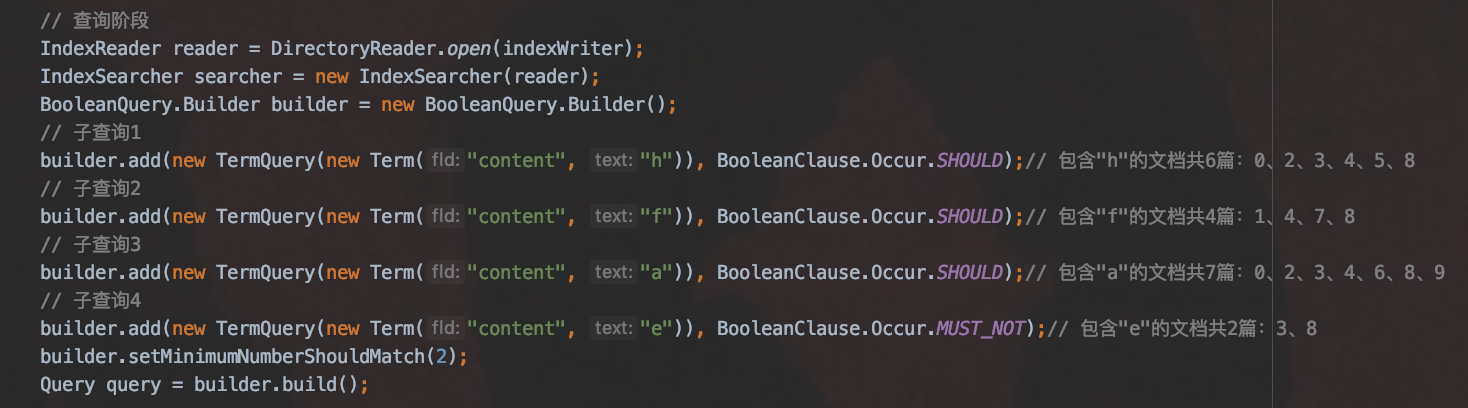
Collector 处理查询结果
在查询原理(三)中的 生成BulkScorer 流程点,我们获得了每一个子查询对应的文档号跟词频,见图 4,结合 查询原理(上) 文章中的 生成Weight 流程点,我们就可以在当前流程点获得满足查询条件(图 3)的文档集合及对应的文档打分值。
图 4:
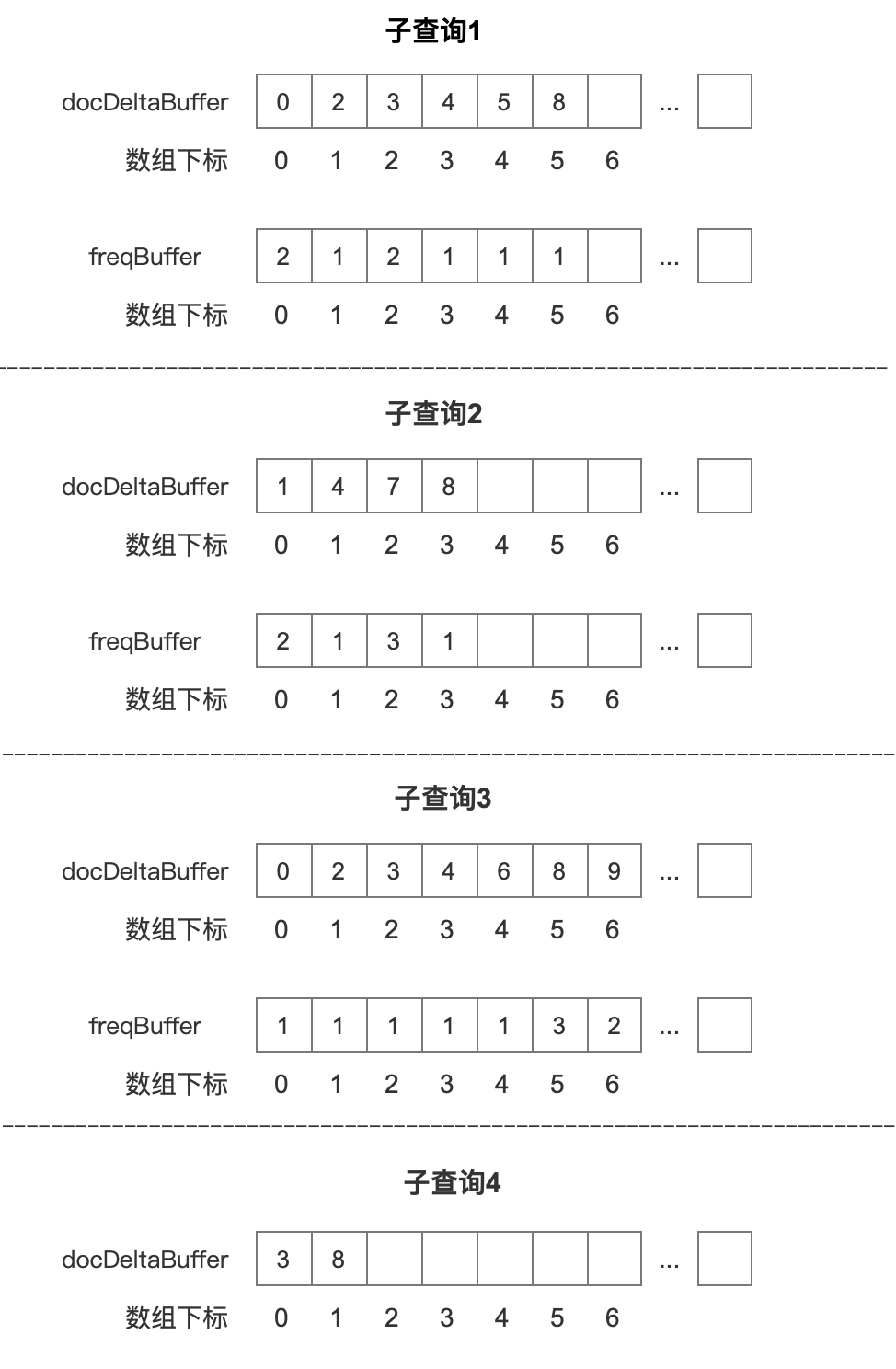
Collector处理查询结果 的流程图
图 5:
是否还有遍历区间?
图 6:
图 4 中的子查询 4,该查询对应的文档号集合不是用户期望返回的,那么可以根据这些文档号划分出多个左闭右开的遍历区间。
满足子查询 4 条件的文档号集合为 3、8,故可以划分出 3 个遍历区间:
- [0,3)
- [4,8)
- [9,2147483647):2147483647 即 Integer.MAX_VALUE
随后从每个遍历区间中找到满足子查询 1、子查询 2、子查询 3 且 minShouldMatch 为 2 的文档号,minShouldMatch 通过图 3 中的 builder.setMinimumNumberShouldMatch 方法设置,描述的是用户期望的文档必须至少满足子查询 1、子查询 2、子查询 3 中的任意两个(minShouldMatch)的查询条件。
为什么要使用遍历区间:
- 降低时间复杂度:通过左闭右开实现过滤子查询 4 中的文档号(时间复杂度 O(n)),否则当我们找出根据子查询 1、子查询 2、子查询 3 且 minShouldMatch 为 2 文档号集合后,每一个文档号都要判断是否满足子查询 4 的条件(时间复杂度 O(n*m)),其中 n 跟 m 都为满足每一个子查询条件的文档数量,在图 4 中的例子中,n 值为 17(6 + 4 + 7,3 个 docDeltaBuffer 数组的元素个数的和值),m 值为 2
处理子查询的所有文档号
图 7:
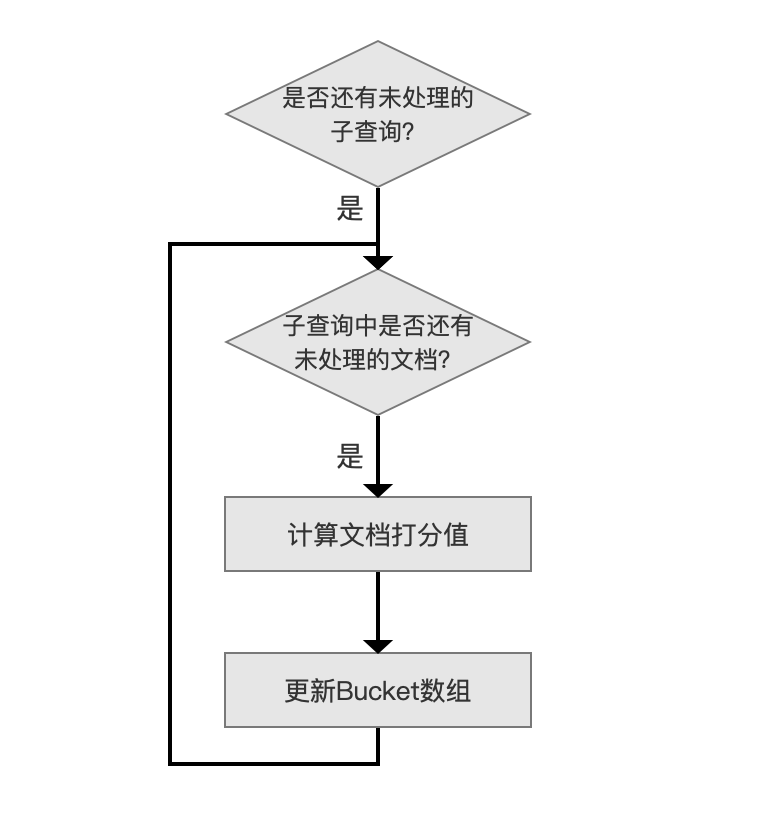
该流程处理子查询的所有文档号,先看下 Bucket 数组,该数组的数组下标用来描述文档号,数组元素是 Bucket 对象,它用来记录该文档的打分值跟满足子查询条件的查询个数,Bucket 类如下所示:
|
|
- score:文档打分值
- freq:满足子查询条件的查询个数
freq
我们先说下 freq,freq 描述的是满足子查询条件的查询个数,例如图 2 中的文档 8(文档号为 8),因为文档号 8 中包含了"h"、“f”、“a”,所以它满足子查询 1、子查询 2、子查询 3 的三个查询条件,故文档号 8 对应的 Bucket 对象的 freq 值为 3。
score
图 8 为 BM25 模型的理论打分公式:
图 8:
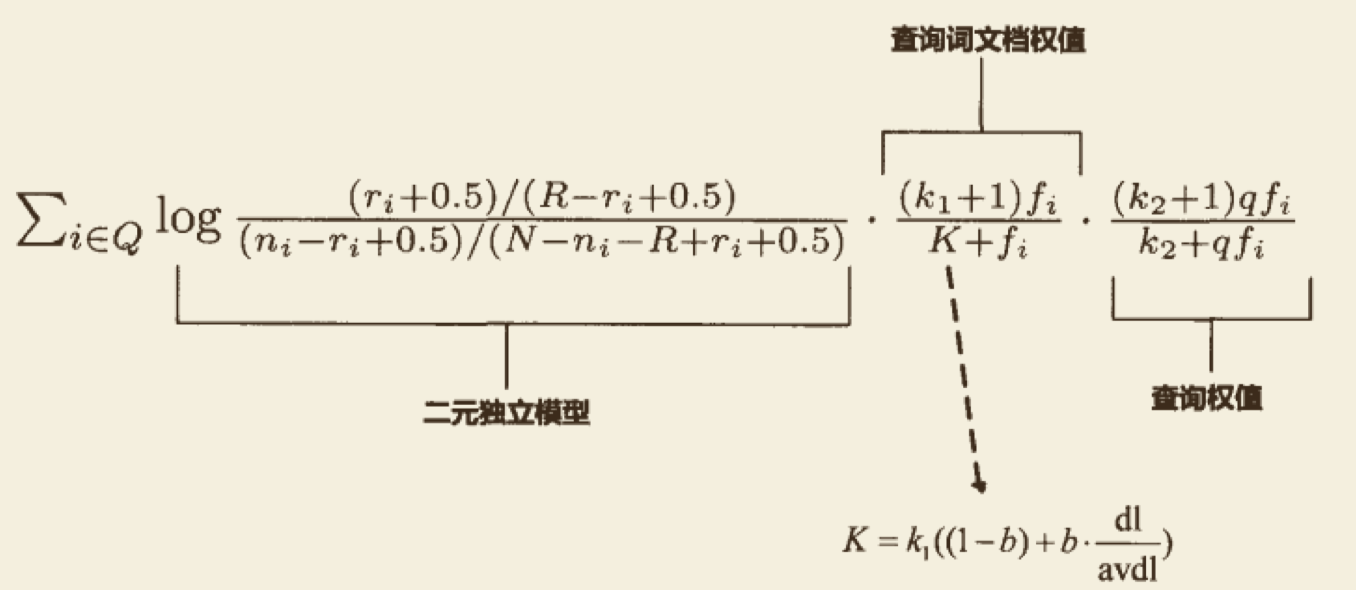
图 17 源自于 « 这就是搜索引擎 »,作者:张俊林。
图 9 为在 Lucene7.5.0 版本中 BM25 模型的具体实现 BM25Similarity 的公式:
图 9:

从图 9 的公式可以看出,一篇文档的打分值是一个 累加值,累加的过程即 更新Bucket数组 的流程,如果一篇文档满足多个子查询的条件,那么该文档的打分值是每个子查询对这篇文档打分的和值。
例如图 2 中的文档 0,该文档包含了两种 term,分别是 “a”,“h”,故文档 0 满足图 3 中的两个子查询的条件,分别是子查询 1、子查询 3,所以文档 0 的打分值是两个查询对这篇文档打分的和值,最后将这个和值添加到 Bucket 数组的数组下标为 0(因为文档 0 的文档号是 0)的数组元素 Bucket 对象中,该对象的 freq 的值同理会被赋值为 2。
BM25Similarity 打分公式
图 10:

- Idf、boost、avgdl、docCount、docFreq:这些值在第二小节中计算 SimWeight 时获得,不赘述
- freq:子查询条件中的域值在文档(正在计算打分的文档)中的词频,即图 4 中的 freqBuffer 数组的数组元素
- k_1、b:BM25 模型的两个调节因子,这两个值都是经验参数,默认值为k_1 = 1.2、b = 0.75。k_1值用来控制非线性的词频标准化(non-linear term frequency normalization)对打分的影响,b 值用来控制文档长度对打分的影响
- norm:该值描述的是文档长度对打分的影响,满足同一种查询的多篇文档, 会因为 norm 值的不同而影响打分值
-
cache 数组:在 查询原理(上) 文章中,我们简单的提了一下 cache 生成的时机是在
生成Weight的流程中,下面详细介绍该数组。- cache 数组的数组下标 normValue 描述的是文档长度值,这是一个标准化后的值(下文会介绍),在 Lucene 中,用域值的个数来描述文档长度,例如图 3 中的子查询 1,它查询的条件是域名为"content",域值为"h"的文档,那么对于文档 0,文档长度值为域名为"content",term 为"h"在文档 0 中的个数,即 2;cache 数组的数组元素即 norm 值
- 上文说到域值的个数来描述文档长度,但是他们两个的值不总是相等,域值的个数通过标准化(normalization)后来描述文档长度,标准化的过程是将文档的长度控制在[0,255]的区间中,跟归一化的目的是类似的,为了平衡小文档相跟大文档的对打分公式的影响,标准化的计算方式不在本文中介绍,感兴趣的可以看 https://github.com/LuXugang/Lucene-7.5.0/blob/master/solr-7.5.0/lucene/core/src/java/org/apache/lucene/util/SmallFloat.java 中的 intToByte4(int)方法,该方法的返回值与 0XFF 执行与操作后就得到标准化后的文档长度值
- 根据标准化后的文档长度值(取值范围为[0,255])就可以计算出 norm 中 dl 的值,dl 为文档长度值对应的打分值,同样两者之间的计算方法不在本文中介绍,感兴趣可以看 https://github.com/LuXugang/Lucene-7.5.0/blob/master/solr-7.5.0/lucene/core/src/java/org/apache/lucene/util/SmallFloat.java 中的 byte4ToInt(byte)方法,图 11 给出了文档长度值跟 dl 之间的映射关系
-
图 11:
图 11 中, 横坐标为文档长度值,纵坐标为 dl,由于数据跨度太大,无法看出文档长度值较小的区间的趋势图,故图 12 给出的是文档长度值在[0,100]区间的映射图
图 12:
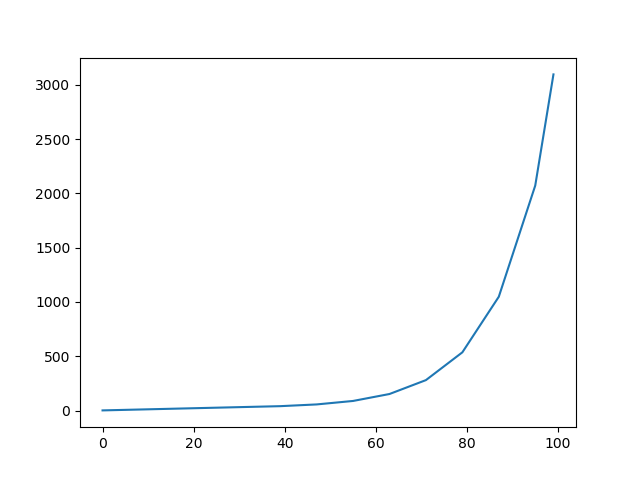
图 13 中,文档长度值在[0,50]区间的映射图,能进一步看出文档长度值小于等于 40 时,dl 正比于文档长度值
图 13:
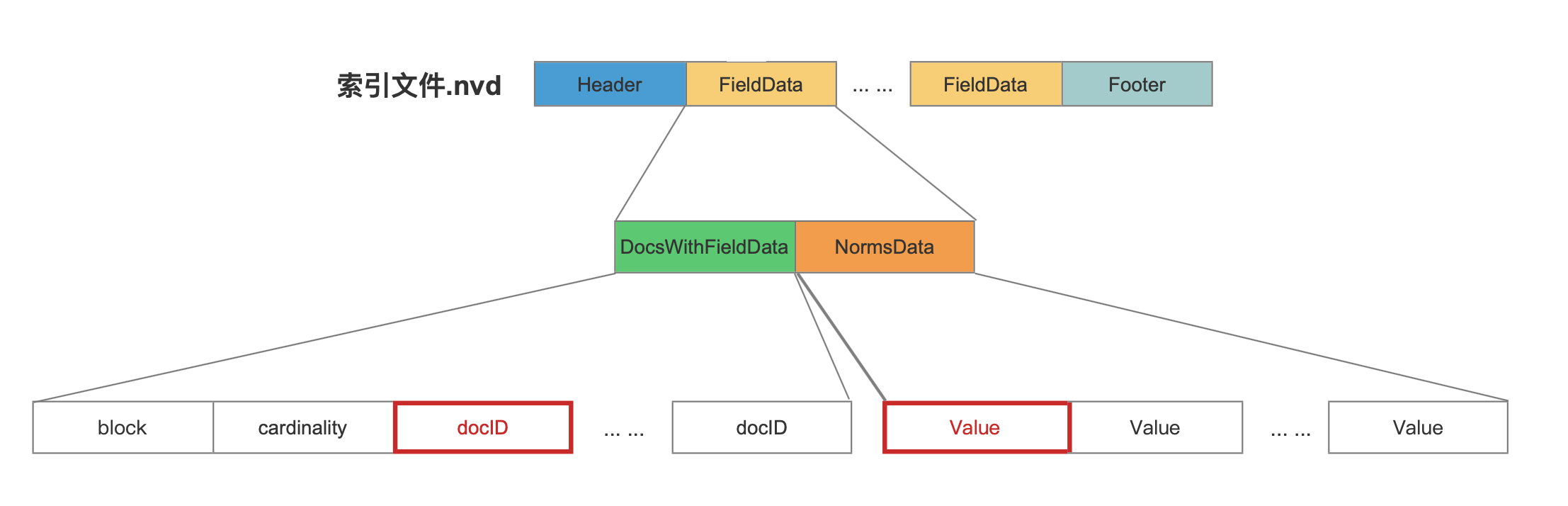
图 10 中的 normValue 根据文档号从 索引文件.nvd 中获得,图 14 中用红框标识了一篇文档的文档号及其对应的 normValue。
读取索引文件的过程不展开介绍,本人不想介绍的原因是,只要了解索引文件的数据结构(见 索引文件数据结构 )是如何生成的,自然就明白如何读取索引文件~~
图 14:
处理 Bucket 数组
图 15:

处理 Buck 数组的过程就是找出所有满足图 3 中 minShouldMatch 的文档,然后分别将文档号交给 Collector 收集器 处理
某个遍历区间 内的生成 Bucket 数组的过程在 文档号合并(SHOULD) 的文章中已经介绍,不过注意的是,在那篇文档中,没有考虑文档的打分值,故 Bucket 数组只介绍了 freq。由于那篇中没有类似图 3 中的子查询 4,所以遍历区间为[0,2147483647]。
对于本篇文章中图 2、图 3 的例子,在遍历区间为[0,3)对应生成的 Bucket 数组如下所示,相比较 文档号合并(SHOULD) 中的内容,我们增加每篇文档的打分值,列出遍历区间为[0,3)的 Bucket 数组:
遍历区间[0,3)
图 16:

在图 16 中,文档 0 跟文档 2 的 freq 大于等于 minShouldMatch(2),故这两篇文档满足图 3 中的查询要求。
结语
至此,我们介绍了单线程下的查询原理的所有流程点,但还有一个很重要的逻辑没有介绍,那就是在图 5 的 是否还有未处理的子查询 流程点,我们并没有介绍在还有未处理的子查询的情况下,如何选择哪个子查询进行处理,这个逻辑实际是个优化的过程,可能可以减少遍历区间的处理,以图 2、图 3 为例,尽管根据子查询 4,我们得出 3 个遍历区间,实际上我们只要处理[0,3)、[4,8)这两个逻辑区间,至于原因会在下一小节展开。
图 2.、图 3 的 demo 点击这里: https://github.com/LuXugang/Lucene-7.5.0/blob/master/LuceneDemo/src/main/java/lucene/query/BooleanQuerySHOULDNOTTEST.java。
另外对于多线程的情况,图 1 中的 合并查询结果 流程也留到下一小节中介绍。
第五小节 终
合并查询结果
该流程点遍历所有子收集器的结果,对这些进行结果进行合并,合并过程比较简单,即利用优先级队列,由于太过简单,故不详细展开了。
遗留问题
在介绍这个遗留问题前,我们先说下在第三小节的文章中,我们在介绍 ReqExclBulkScorer 时,有两个信息没有介绍,即 cost、next,这两个信息用来选择哪些子查询进行处理。
图 2:
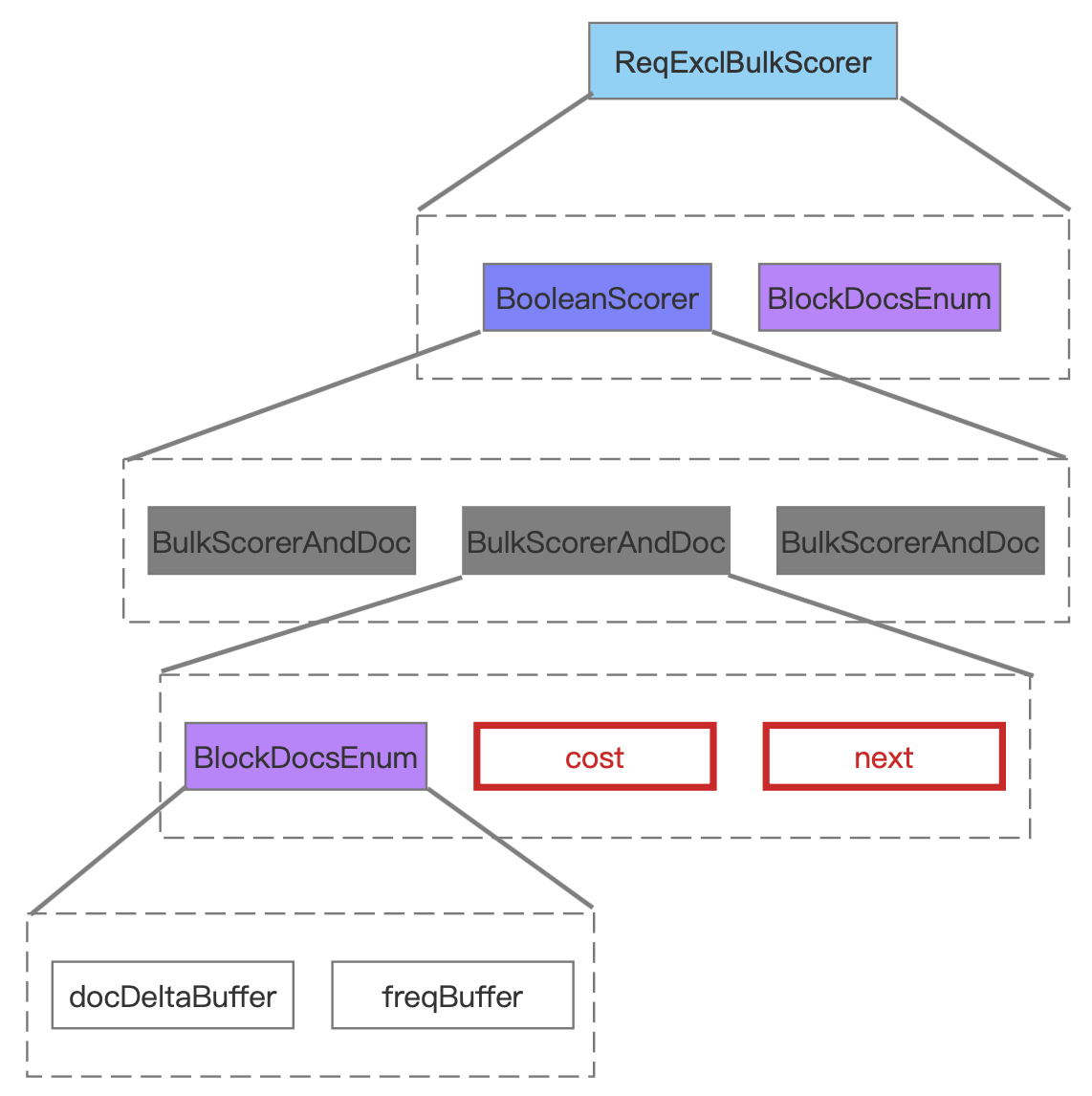
图 3:
- cost:该值描述的是满足子查询的文档个数,例如图 3 中的子查询 3,因为 docDeltaBuffer 数组有 7 个数组元素(数组元素为满足子查询的文档号),故它的 cost 值为 7
- next:该值描述的是下一次处理的文档号,每当处理一篇文档,即更新到 Bucket 数组(见第四小节),那么 next 被更新为下一个要处理的文档号,next 的值是 一个递增值
在第四小节的文章中,我们介绍了单线程下的查询原理的所有流程点,但还有一个很重要的逻辑没有介绍,那就是我们并没有介绍在还有未处理的子查询的情况下,如何选择哪个子查询进行处理,这个逻辑实际是个优化的过程,可能可以减少 遍历区间(见第四小节的处理,下面将填补这个坑。
上文的描述可以拆分两个问题,以图 3 为例:
- 问题一:我们从子查询 1、子查询 2、子查询 3 中的哪个 docDeltaBuffer 开始遍历(选择子查询)
- 问题二:是不是所有的 docDeltaBuffer 的每一篇文档号都要遍历(减少遍历区间)?
这两个问题可以转化为一道面试算法题,来了解面试者对 Lucene 的熟悉程度:有 N 个 int 类型数组,其中所有数组的数组元素都是有序(升序)的,同一个数组内的数组元素都是不重复的,设计一种方法,从这 N 个数组中找出所有重复(minShouldMatch 大于等于 2)的数组元素。
对于上述的算法题,以图 3 为例,对于子查询 1、子查询 2、子查询 3,总的时间复杂度至少为 3 个子查询的开销的和(子查询的开销即上文中的 cost),即我们需要遍历每一个子查询对应的文档号。
Lucene 是如何处理的:
- 下图给出 Lucene 中处理方式的注释,原注释可以看这里: https://github.com/LuXugang/Lucene-7.5.0/blob/master/solr-7.5.0/lucene/core/src/java/org/apache/lucene/search/MinShouldMatchSumScorer.java 中 cost( )方法的注释
图 4:
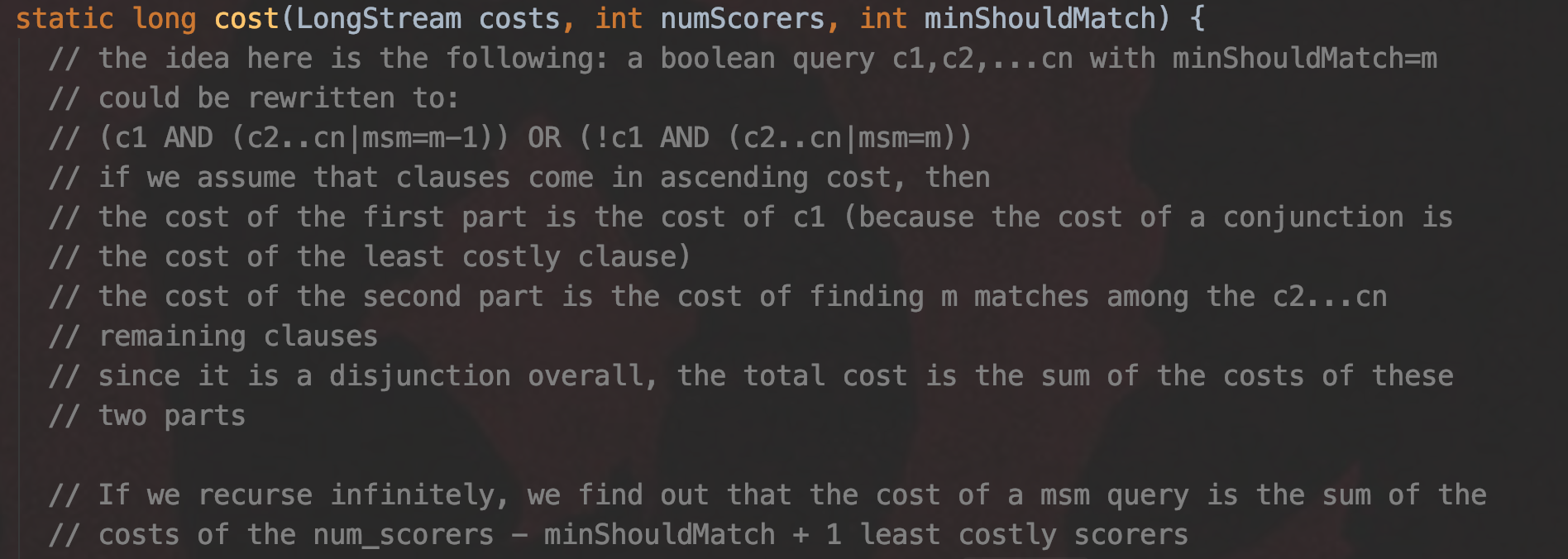
-
图 4 中描述了这么一个结论:如果 BooleanQuery 有 n 个子查询,它们之间为 BooleanClause.Occur.SHOULD 的关系,并且 minShouldMatch 为 m,那么 BooleanQuery 的开销最少可以是( numScores - minShouldMatch + 1)个子查询的开销和,也就说在某些情况下我们不用遍历所有子查询对应的文档集合
- numScores:子查询的个数 n
- minShouldMatch:文档必须同时满足 BooleanQuery 中的至少 m 个子查询的查询条件
BooleanQuery 的开销最少可以是( numScores - minShouldMatch + 1)个子查询的开销和是怎么推算出来的:
- 包含 n 个子查询 c1,c2,… cn 且 minShouldMatch 为 m 的 BooleanQuery,它可以转化为
|
|
-
(c1 AND (c2..cn|msm=m-1)) :第一块部分描述了满足 BooleanQuery 查询要求的文档,如果 满足 子查询 c1,那么必须至少满足 c2..cn 中任意 m-1 个子查询
-
(!c1 AND (c2..cn|msm=m)):第二块部分描述了满足 BooleanQuery 查询要求的文档,如果 不满足 子查询 c1,那么必须至少满足 c2..cn 中任意 m 个子查询
- 根据两块部分的组合关系, BooleanQuery 的开销是这两部分的开销和
-
假设子查询 c1,c2,… cn 是按照 cost(上文中已经介绍) 升序排序 的,那么对于第一块部分(c1 AND (c2..cn|msm=m-1)) ,由于 c1 的 cost 最小,并且必须满足 c1 的查询条件, 所以第一块部分的开销就是 c1 的开销
-
对于第二块部分(!c1 AND (c2..cn|msm=m)),它相当于一个包含 n -1 个子查询 c2,… cn 且 minShouldMatch 为 m 的 子 BooleanQuery,所以它又可以转化为(c2 AND (c3..cn|msm=m-1)) OR (!c2 AND (c3..cn|msm=m))
-
以此类推如下所示
图 5:

在图 5 中,最后推导出 BooleanQuery 的总开销为 n-m+1 个查询的开销,所以在 Lucene 中,它使用优先级队列 head(大小为 n-m+1)、tail(大小为 m - 1)来存放子查询的信息(即第三小节中的 BulkScorerAndDoc),优先级队列的排序规则如下:
- head:按照 cost 升序
- tail:按照 next 升序
当 head 中优先级最低的 BulkScorerAndDoc 的文档号不在遍历区间内,那么就可以跳过这个遍历区间,即使此时 tail 中还有其他的 BulkScorerAndDoc。
这里提供一个 demo: https://github.com/LuXugang/Lucene-7.5.0/blob/master/LuceneDemo/src/main/java/lucene/query/BooleanQuerySHOULDNOTTEST.java,这个 demo 对应图 3 的内容,根据子查询 4,我们会获得 3 个遍历区间第四小节, 即[0,3)、[4,8)、[9,2147483647),但是实际只需要遍历[0,3)、[4,8),因为子查询 1、子查询 2 会被放到 head 中,而这满足这两个查询的最大文档号为 8,故不用处理[9,2147483647)的遍历区�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%E6%9F%A5%E8%AF%A2%E5%8E%9F%E7%90%86%E4%B8%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


