源码系列收集各个命中的
在搜索阶段,每当 Lucene 找到一个满足查询条件的文档(Document),便会将该文档的文档号(docId)交给 Collector,并在 Collector 中对收集的文档号集合进行排序(sorting)、过滤(filtering)或者用户自定义的操作。
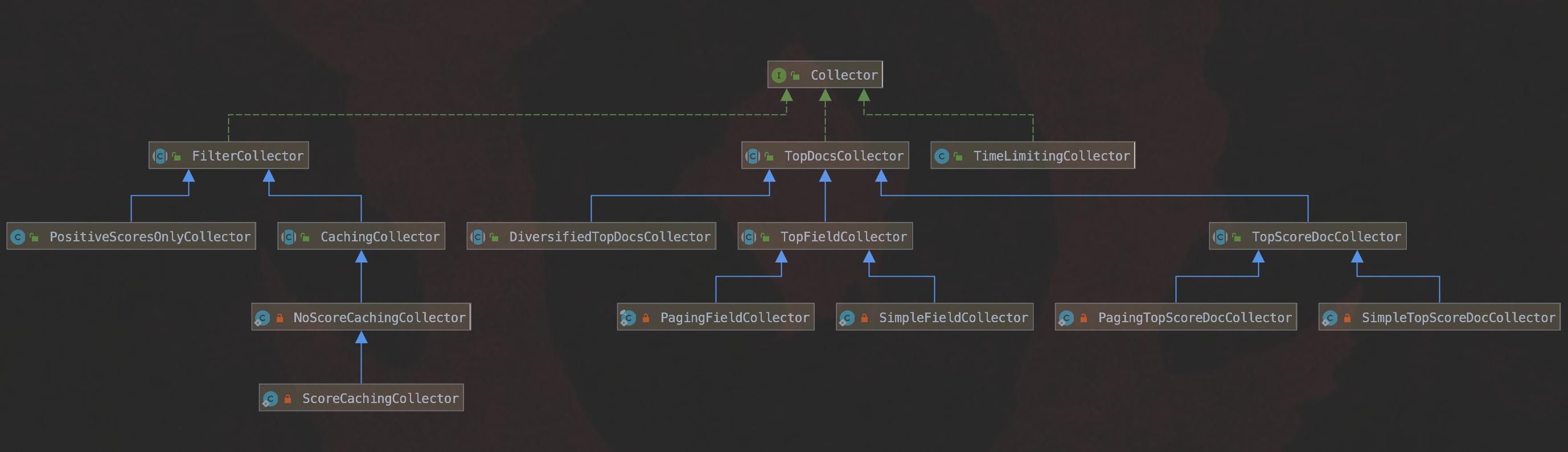
本篇文章将根据图 1 中的类图(Class diagram),介绍 Lucene 常用的几个收集器(Collector):
图 1:
第 1 小节 Collector 处理文档
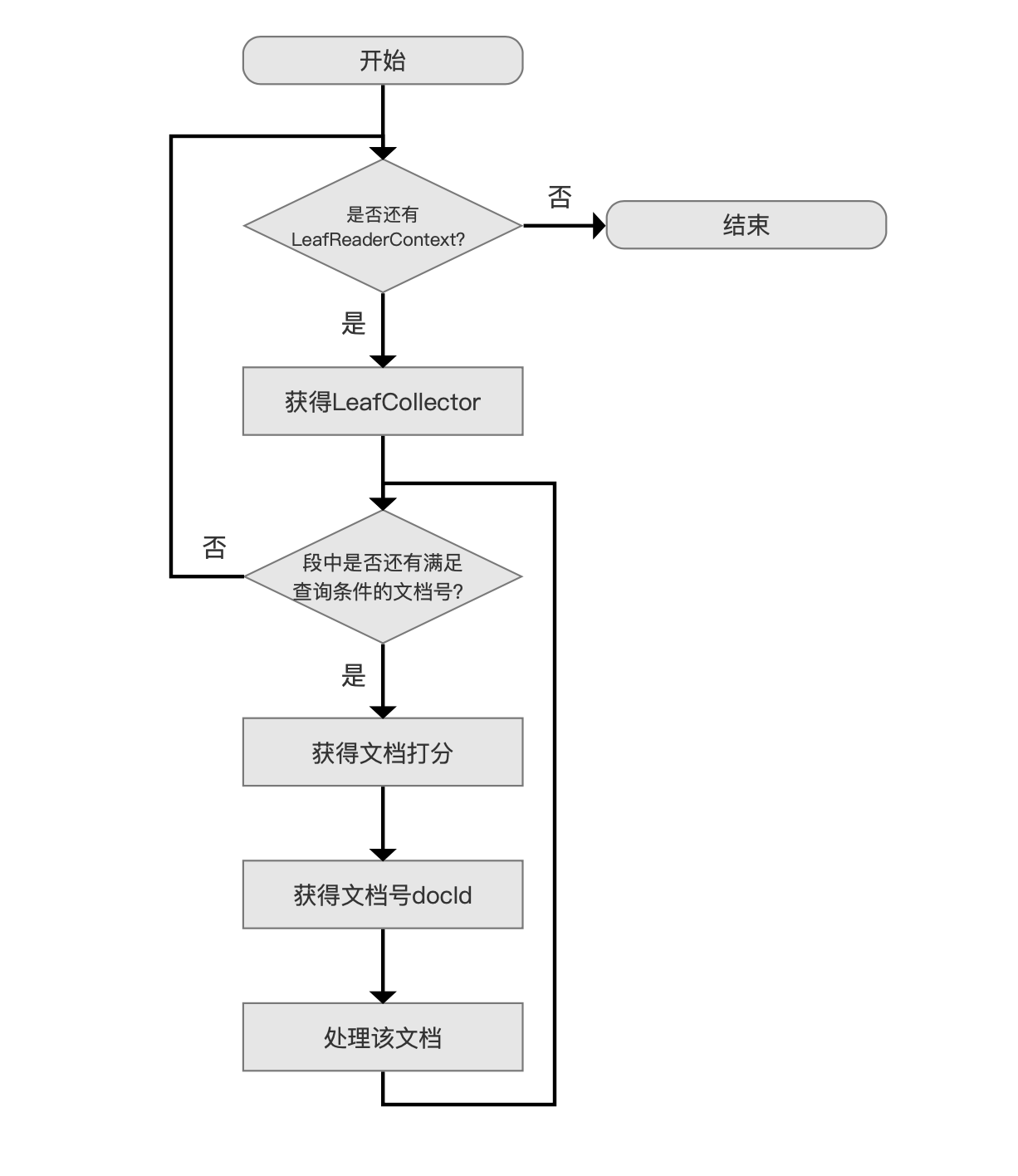
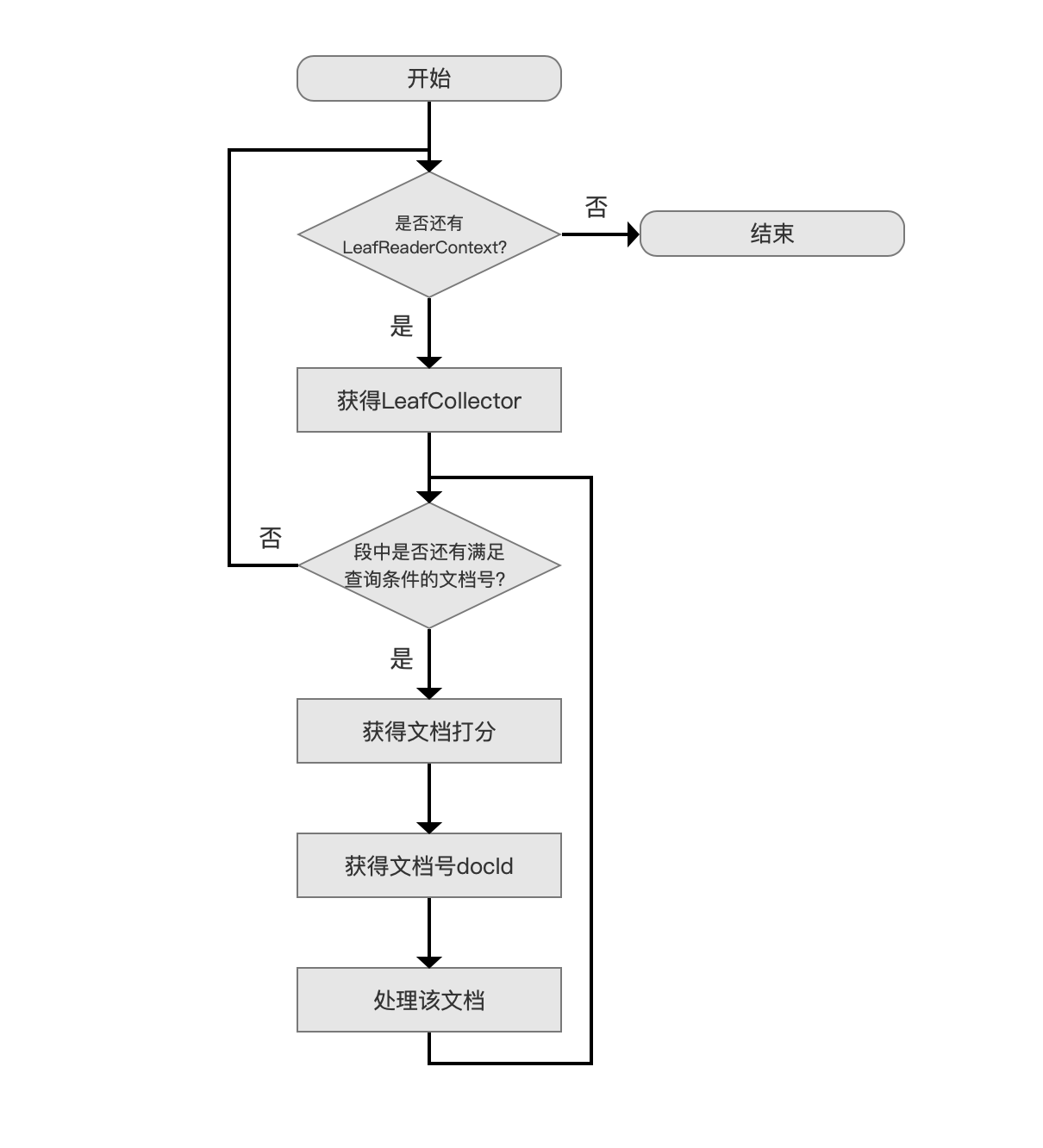
下图中描述的是 Collector 处理文档的流程:
图 2:
获得 LeafCollector
图 3:
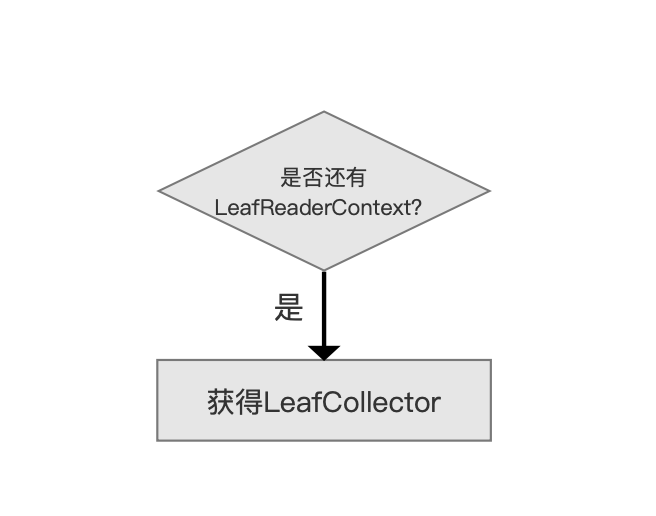
当索引目录中存在多个段时,我们需要从每个段中分别找出满足查询条件的文档,LeafReaderContext 即用来描述某一个段的信息,并且通过它能获得一个 LeafCollector 对象,在本篇文章中我们只要知道 LeafReaderContext 有这个功能(functionality)即可,在后面介绍 IndexReader 的文章中会展开。
在搜索阶段,通过 Collector 类的方法来获得 LeafCollector 对象,下面是 Collector 类的代码,由于 Collector 类是一个接口类,并且只有两个接口方法,故列出并介绍:
|
|
接口方法 getLeafCollector
通过该方法获得一个 LeafCollector 对象,Lucene 每处理完一个段,就会调用该方法获得下一个段对应的 LeafCollector 对象。
LeafCollector 对象有什么作用:
- 首先看下 LeafCollector 类的结构:
|
|
- setScorer 方法:调用此方法通过 Scorer 对象获得一篇文档的打分,对文档集合进行排序时,可以作为排序条件之一,当然 Scorer 对象包含不仅仅是文档的打分值,在后面介绍查询的文章中会展开
- collect 方法:在这个方法中实现了对所有满足查询条件的文档进行排序(sorting)、过滤(filtering)或者用户自定义的操作的具体逻辑。在下文中,根据图 1 中不同的收集器(Collector)会详细介绍 collect 方法的不同实现
接口方法 needsScores
设置该方法用来告知 Lucene 在搜索阶段,当找到一篇文档时,是否对其进行打分。如果用户期望的查询结果不依赖打分,那么可以设置为 false 来提高查询性能。
处理一篇文档
图 4:
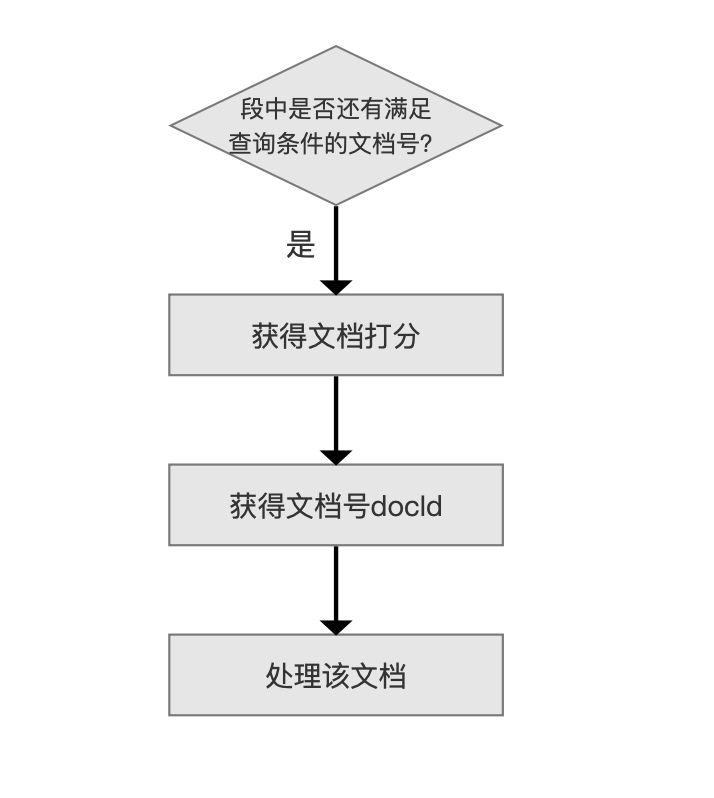
当 Lucene 找到一篇满足查询条件的文档,会调用 LeafCollector 的 setScorer(Scorer score)方法来执行 获得文档打分 的流程,随后在 获得文档号docId 流程后获得一个 docId,最后调用 LeafCollector 的 collect(int doc)方法(参数 doc 即文档号 docId)来实执行 处理该文档 的流程,在该流程中,实现对文档进行排序(sorting)、过滤(filtering)或者用户自定义的操作。
TimeLimitingCollector
在介绍完 Collector 处理文档的流程后,我们依次介绍图 1 中的收集器。
TimeLimitingCollector 封装了其他的 Collector,用来限制 Collector 处理文档的时间,即设定了一次查询允许的最长时间 timeLimit。如果查询的时间超过 timeLimit,那么会抛出超时异常 TimeExceededException。
在哪些流程点会判断查询超时:
- 调用 Collector.getLeafCollector(LeafReaderContext context)方法时会执行超时判断,即图 3 中的
是否还有 LeafReaderContext的流程点 - 调用 LeafCollector.collect(int doc)方法时会执行超时判断,即图 4 中的
处理该文档的流程点
如何实现超时机制:
- 通过后台线程、解析值 resolution、计数器 counter 实现、timeLimit
- 计数器 counter:AtomicLong 类型,用来描述查询已花费的时间
- 解析值 resolution:long 类型的数值,触发查询超时的精度值
- 后台线程:Thread.setDaemon(true)的线程
- timeLimit:上文已经介绍
- 后台线程先执行 counter 的累加操作,即调用 counter.addAndGet(resolution)的方法,随后调用 Thread.sleep(resolution)的方法,如此反复。收集文档号的线程在 判断查询超时的流程点处通过 counter.get()的值判断是否大于 timeLimit
使用这种超时机制有什么注意点:
- 由于后台线程先执行 counter 的累加操作,随后睡眠,故收集文档号的线程超时的时间范围为 timeLimit - resolution 至 timeLimit + resolution 的区间,单位是 milliseconds,故查询超时的触发时间不是精确的
- 由上一条可以知道,resolution 的值设置的越小,查询超时的触发时间精度越高,但是性能越差(例如线程更频繁的睡眠唤醒等切换上下文行为)
- 由于使用了睡眠机制,在运行过程中实时将 resolution 的值被调整为比当前 resolution 较小的值时(比如由 20milliseconds 调整为 5milliseconds),可能会存在调整延迟的问题(线程正好开始睡眠 20milliseconds)
- resolution 的值至少为 5milliseconds,因为要保证能正确的调用执行 Object.wait(long)方法
贪婪(greedy)模式:
在开启贪婪模式的情况下(默认不开启),如果在 LeafCollector.collect( )中判断出查询超时,那么还是会收集当前的文档号并随后抛出超时异常,注意的是如果在 Collector.getLeafCollector( )中判断出查询超时,那么直接抛出超时异常。
FilterCollector
FilterCollector 类是一个抽象类,它用来封装其他的 Collector 来提供额外的功能。
PositiveScoresOnlyCollector
PositiveScoresOnlyCollector 首先过滤出文档的打分值大于 0 的文档号,然后将文档号交给封装的 Collector,由于 collect 方法比较简单,故列出:
|
|
其中 in 是 PositiveScoresOnlyCollector 封装的 Collector,scorer 即一个 Scorer 对象。
CachingCollector
CachingCollector 可以缓存 Collector 收集的一次搜索的结果,使得其他的 Collector 可以复用该 Collector 的数据。
CachingCollector 缓存了哪些数据:
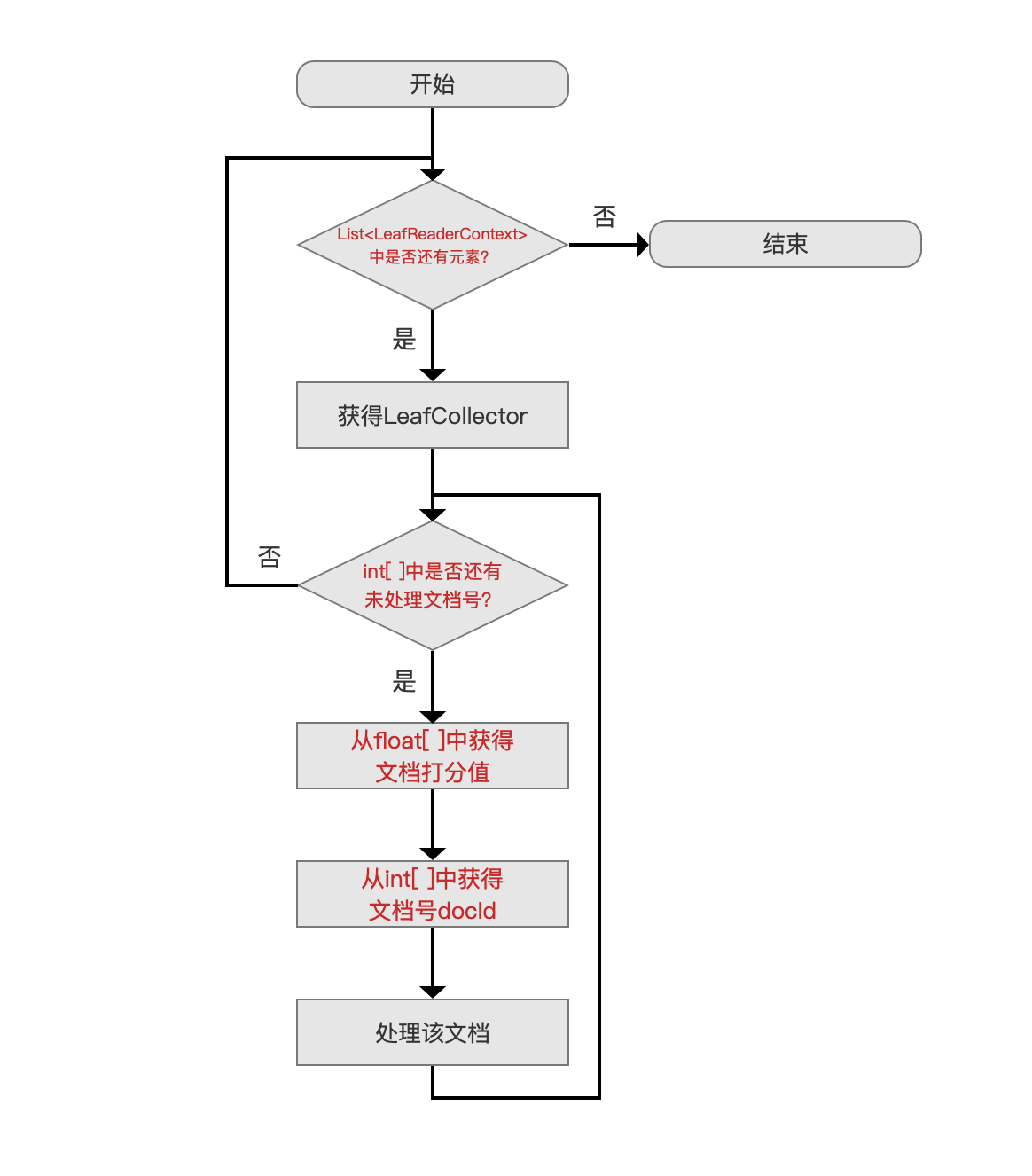
- List:在前面我们提到,LeafReaderContext 描述的是一个段内的信息,当索引目录中存在多个段,那么我们需要用 List 来缓存所有的 LeafReaderContext
- List<int[ ]> docs:一个段中可能有多个满足查询条件的文档,所以使用 int[ ]来缓存那些文档的文档号,当索引目录中存在多个段时,需要用 List 来缓存每一个段中的所有文档号集合
- List<float[ ]> scores:一个段中所有满足查询条件的文档的打分值使用 float[ ]缓存,当索引目录中存在多个段时,需要用 List 来缓存每一个段中的所有文档的打分值集合
图 1 中 NoScoreCachingCollector、ScoreCachingCollector 两者的区别在于是否缓存文档的打分值。
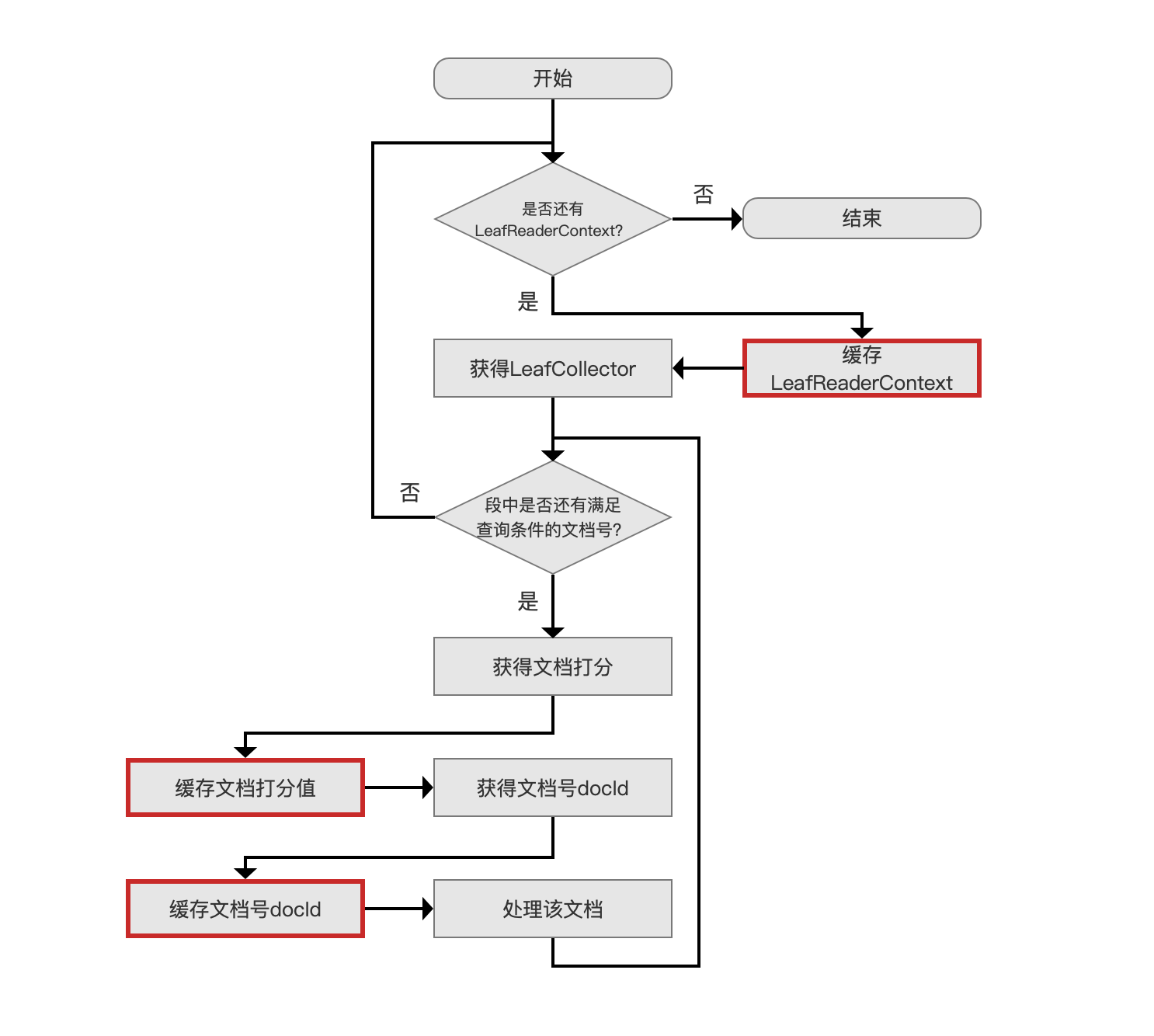
CachingCollector 缓存流程图
图 2 是 Collector 处理文档的过程,每个流程点在前面已作介绍,不赘述:
图 2:
CachingCollector 缓存流程图跟图 2 类似,故用红框标记出不同处:
图 3:
CachingCollector 复用流程图
图 4:
另外,CachingCollector 可以设置允许缓存文档个数最大值。
在缓存阶段,当缓存的个数超过阈值,那么清空此前缓存的所有数据,另变量 cache 的值为 false,即这次的缓存操作置为失败,故在复用 CachingCollector 时需先检查 cache 的值是否为 true。
第 2 小节 TopDocsCollector
TopDocsCollector 类在收集完文档后,会返回一个的 TopDocs 对象,TopDoc 对象是什么不重要,在这篇文章中我们只需要知道收集后的文档信息按照某种排序规则有序的存放在 TopDoc 对象中,该对象为搜索结果的返回值。根据不同的**排序(sorting)**规则,TopDocsCollector 派生出图 1 中的三种子类:
- DiversifiedTopDocsCollector
- TopScoreDocCollector
- TopFieldCollector
其中,根据一定的**过滤(filtering)**规则,TopScoreDocCollector、TopFieldCollector 还分别派生出两个子类:
- TopScoreDocCollector
- SimpleTopScoreDocCollector
- PagingTopScoreDocCollector
- TopFieldCollector
- SimpleFieldCollector
- PagingFieldCollector
上文中我们给出了 TopDocsCollector 的 7 个子类,结合图 2 中的流程,他们之间的流程差异仅在于 处理该文档 这个流程点,即 collect(int doc)方法的不同的实现
故在下文中,只介绍每个 Collector 的 collect(int doc)方法的具体实现。
TopScoreDocCollector
TopScoreDocCollector 类的排序规则为 “先打分,后文档号”:
- 先打分:即先通过文档的打分进行排序,打分值越高,排名越靠前
- 后文档号:由于文档号是唯一的,所以当打分值相等时,可以再通过文档的文档号进行排序,文档号越小,排名越靠前。
根据过滤规则,我们接着介绍 TopScoreDocCollector 的两个子类:
- SimpleTopScoreDocCollector:无过滤规则
- PagingTopScoreDocCollector:有过滤规则,具体内容在下文展开
SimpleTopScoreDocCollector
SimpleTopScoreDocCollector 的 collect(int doc)流程图:
图 5:
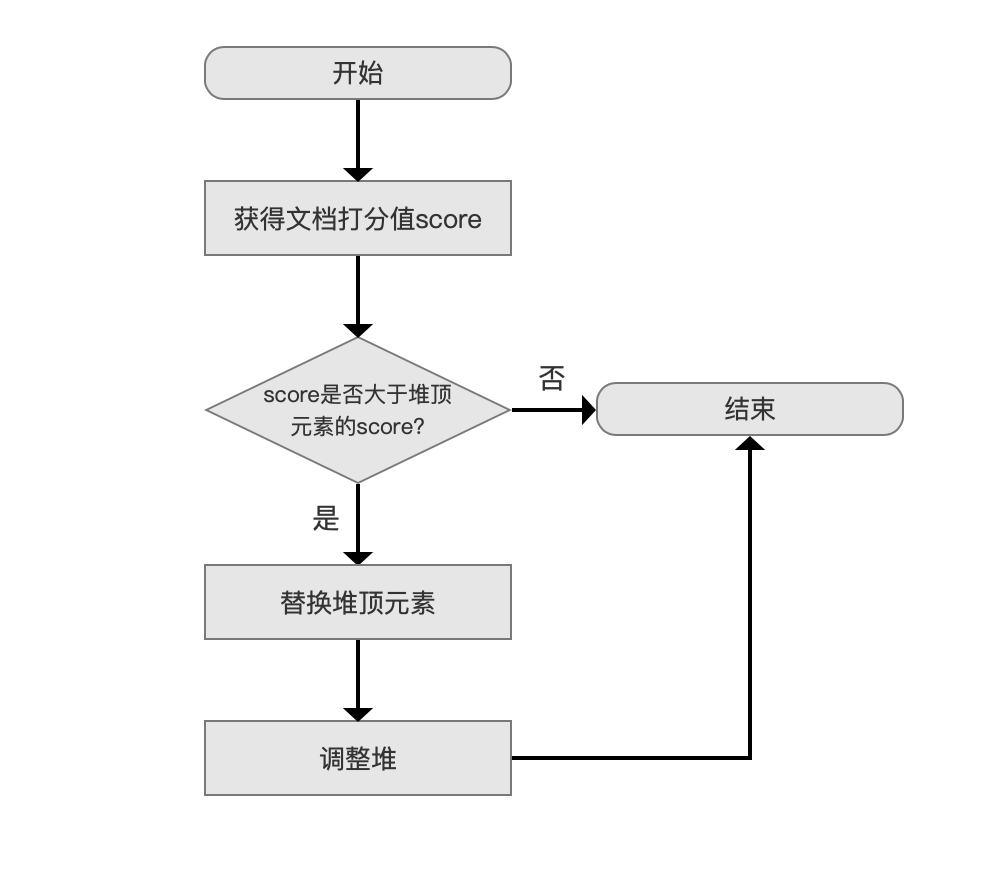
score 是否大于堆顶元素的 score?
图 6:
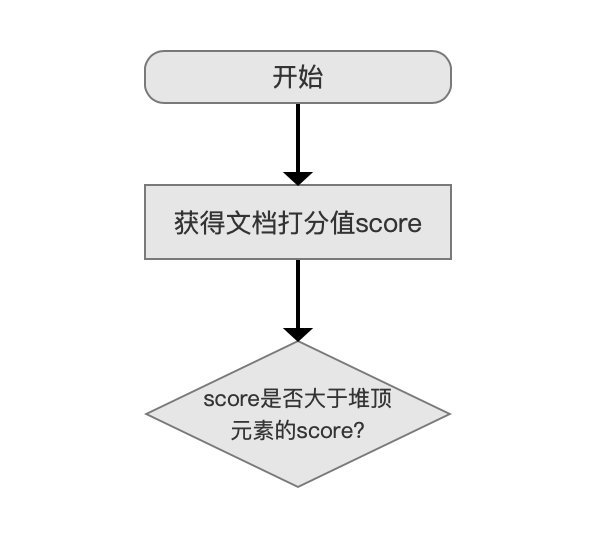
使用优先级队列 PriorityQueue 来存放满足搜索条件的文档信息( 文档信息至少包含了文档打分 score 以及文档号 docId),分数最低的文档信息位于堆顶,堆的大小默认为段中的文档总数(用户也可以指定堆的大小,即用户期望的返回结果 TopN 的 N 值)。
为什么判断条件是 score 等于堆顶元素的 score 的情况下也不满足:
- 因为 collect(int doc)方法接受到的文档号总是按照从小到大的顺序,当 score 等于堆顶元素的 score 时,当前文档号肯定大于堆顶元素的文档号,根据上文中 TopScoreDocCollector 的排序规则,故不满足
调整堆
图 7:
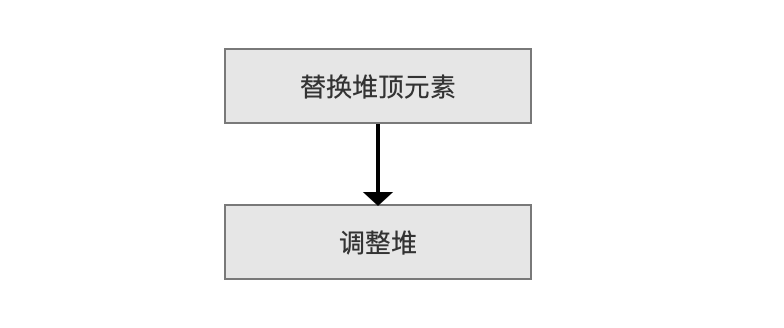
替换堆顶元素 后,我们需要调整堆重新找到分数最低的文档信息,调整的规则同样按照“先分数,后文档号”。
PagingTopScoreDocCollector
PagingTopScoreDocCollector 是带有过滤规则的 Collector,用来实现分页功能。
在 SimpleTopScoreDocCollector 中如果满足搜索条件的文档个数有 M 个,其中 N 为用户期望返回的个数(即 TopN),为了便于理解,我们这里假设 M > 2N,那么第一次搜索后,返回的搜索结果,即 N 篇文档,任意一篇的打分值 score 都是 大于等于 剩余的(M - N)篇文档中的任意一篇,如果使用了 PagingTopScoreDocCollector,我们可以就从 (M - N)篇文档中继续找出 N 篇文档,即执行第二次搜索。该 PagingTopScoreDocCollector 可以使得通过多次调用 IndexSearcher.searchAfter(ScoreDoc after, Query query, int TopN) 的方法来实现分页功能,其中 ScoreDoc 对象 after 即过滤规则。下面给出 ScoreDoc 类的部分变量:
|
|
score 为上文 N 篇文档中分数最低的打分值,doc 为对应的文档号,在下文中会介绍如何使用 ScoreDoc 作为过滤规则来实现分页功能。
PagingTopScoreDocCollector 的 collect(int doc)流程图:
图 8:
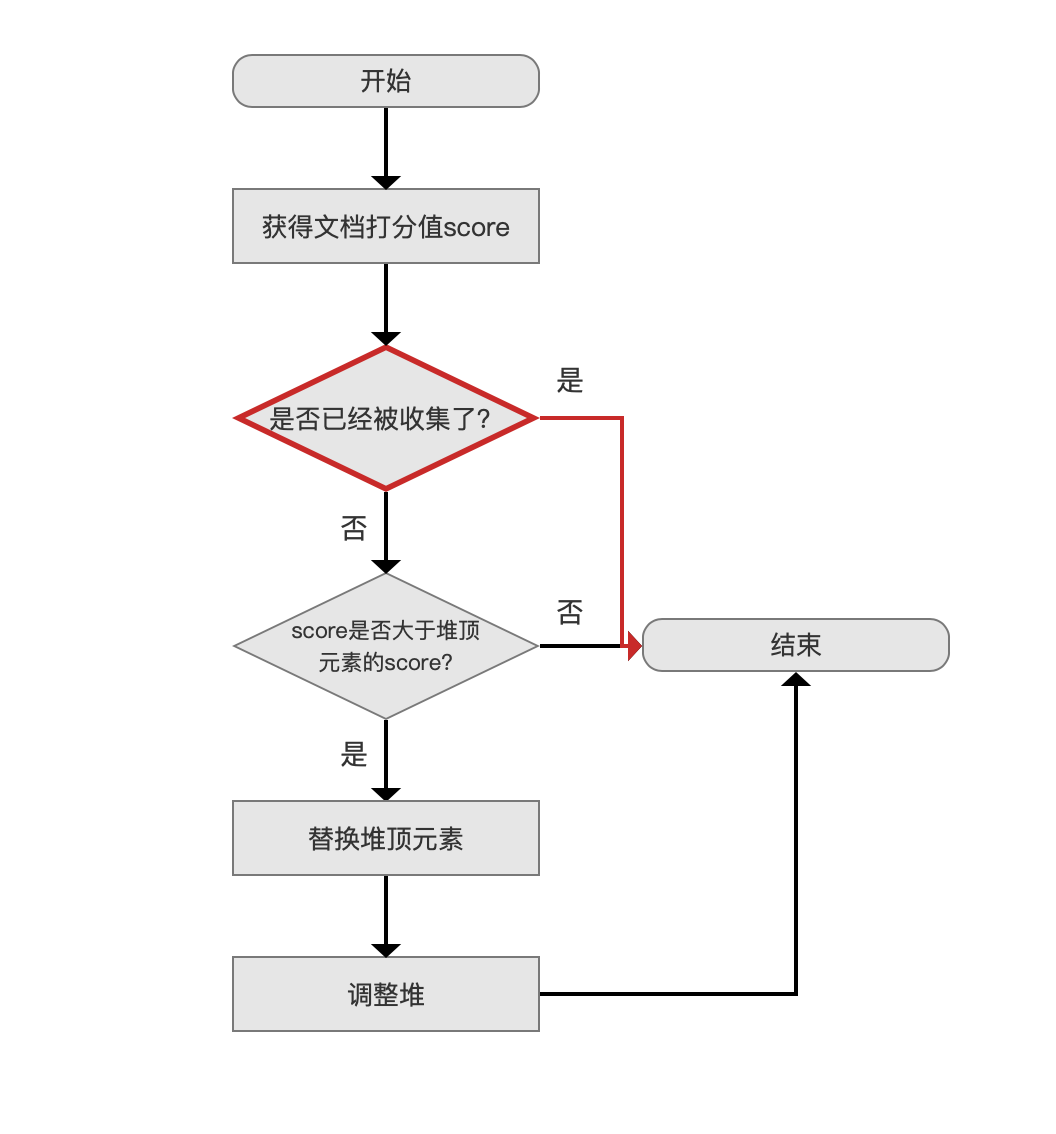
除了红色的流程点,其他流程点跟 SimpleTopScoreDocCollector 是一样的,不赘述。
是否已经被收集了?
图 9:

是否已经被收集了 描述的是该文档号是否已经在前面的搜索中被收集了,判断的条件如下,如果为 true,说明该文档已经被收集了:
|
|
- score:该值描述的当前文档的打分值
- after:该值即上文中的 ScoreDoc 对象
由于 after.score 是前面所有分页搜索的结果中分数最低的文档,所以如果当前文档的打分值大于 after.score,必定该篇文档已经在前面某次分页搜索中被收集过了。
如果 score > after.score 不为 true,还要考虑 score == after.score 的情况,在图 6 中我们知道如果两篇文档的打分值一样,那么文档号较大的不会被收集,所以在如果当前的文档号小于等于 after.doc,必定该篇文档已经在前面某次分页搜索中被收集过了。
从上面的介绍可以看出,如果一个段中有 M 篇文档满足搜索条件,在使用分页搜索的情况,每一次 Collector 都需要处理这 M 篇文档,只是在每一次的分页搜索时选出 N 篇文档。
第 3 小结 TopDocsCollector
TopFieldCollector
在前面我们介绍了 TopScoreDocCollector 收集器以及它的两个子类 SimpleTopScoreDocCollector、PagingTopScoreDocCollector,它们的排序规则是"先打分,后文档号",TopFieldCollector 的排序规则是“先域比较( FieldComparator),后文档号”。
- 先域比较(FieldComparator):根据文档(Document)中的排序域(SortField)的域值进行排序。
- 后文档号:由于文档号是唯一的,所以当无法通过域比较获得顺序关系时,可以再通过文档的文档号进行排序,文档号越小,排名越靠前(competitive)
我们先通过例子来介绍如何使用 TopFieldCollector 排序的例子,随后介绍排序的原理。
本人业务中常用的排序域有 SortedNumericSortField、SortedSetSortField,其他的排序域可以看 SortField 类 以及子类,在搜索阶段如果使用了域排序,那么 Lucene 默认使用 TopFieldCollector 来实现排序。
例子
SortedNumericSortField
图 2:
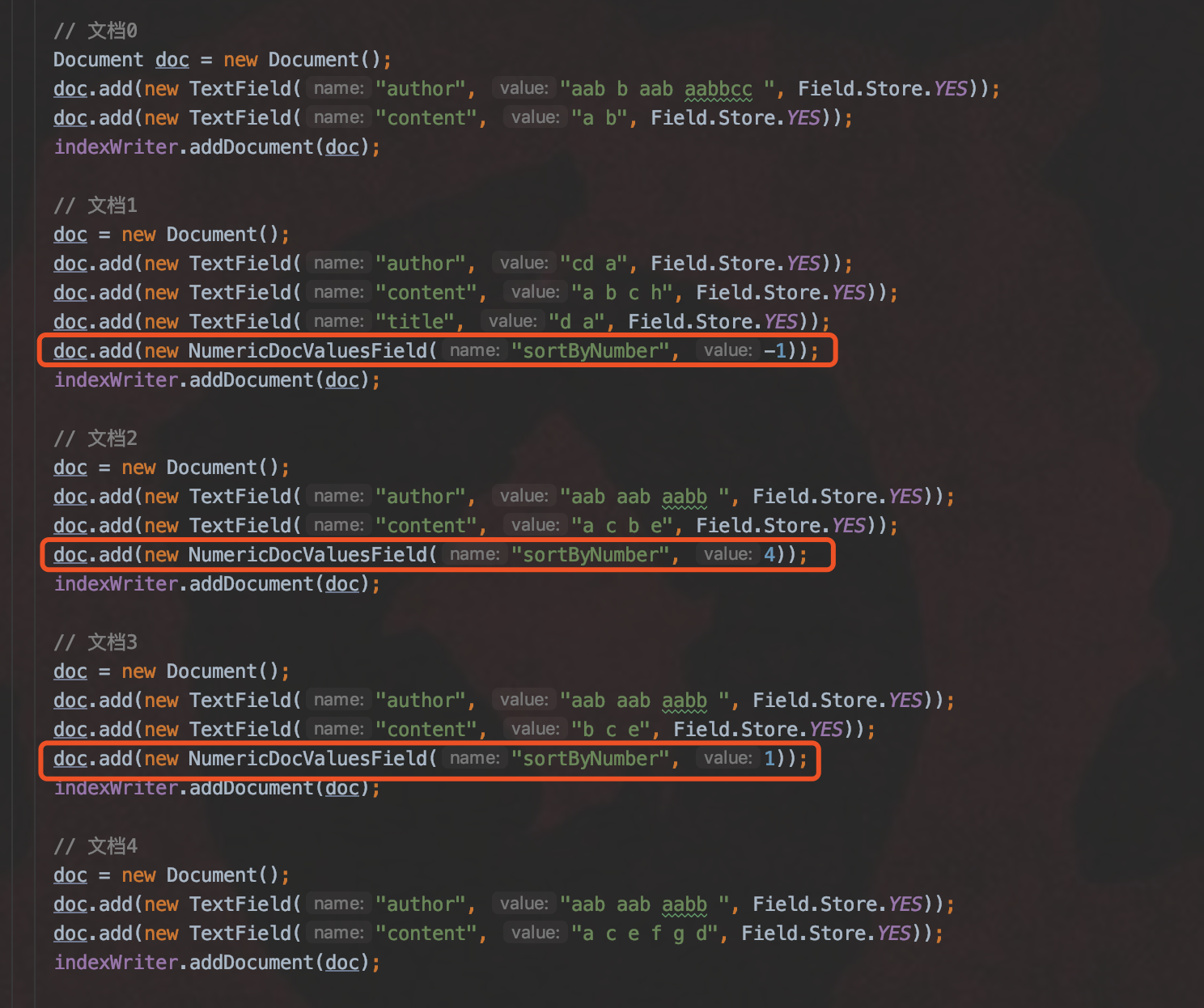
图 3:

- SortedNumericSortField:根据文档(document)中 NumericDocValuesField 域的域值进行排序, 如果文档中没有这个域,那么域值视为 0
- 图 2 为 索引阶段 的内容,我们根据域名为“sortByNumber”的 NumericDocValuesField 域的域值进行排序, 其中文档 0、文档 4 没有该域,故它的域值被默认为 0,它们按照文档号排序
- 图 3 为 搜索阶段 的内容,使用 SortedNumericSortField 对结果进行排序,所以按照从小到大排序(图 3 中参数 reverse 为 true 的话,那么结果按照从大到小排序),那么排序结果为:
|
|
SortedSetSortField
图 4:
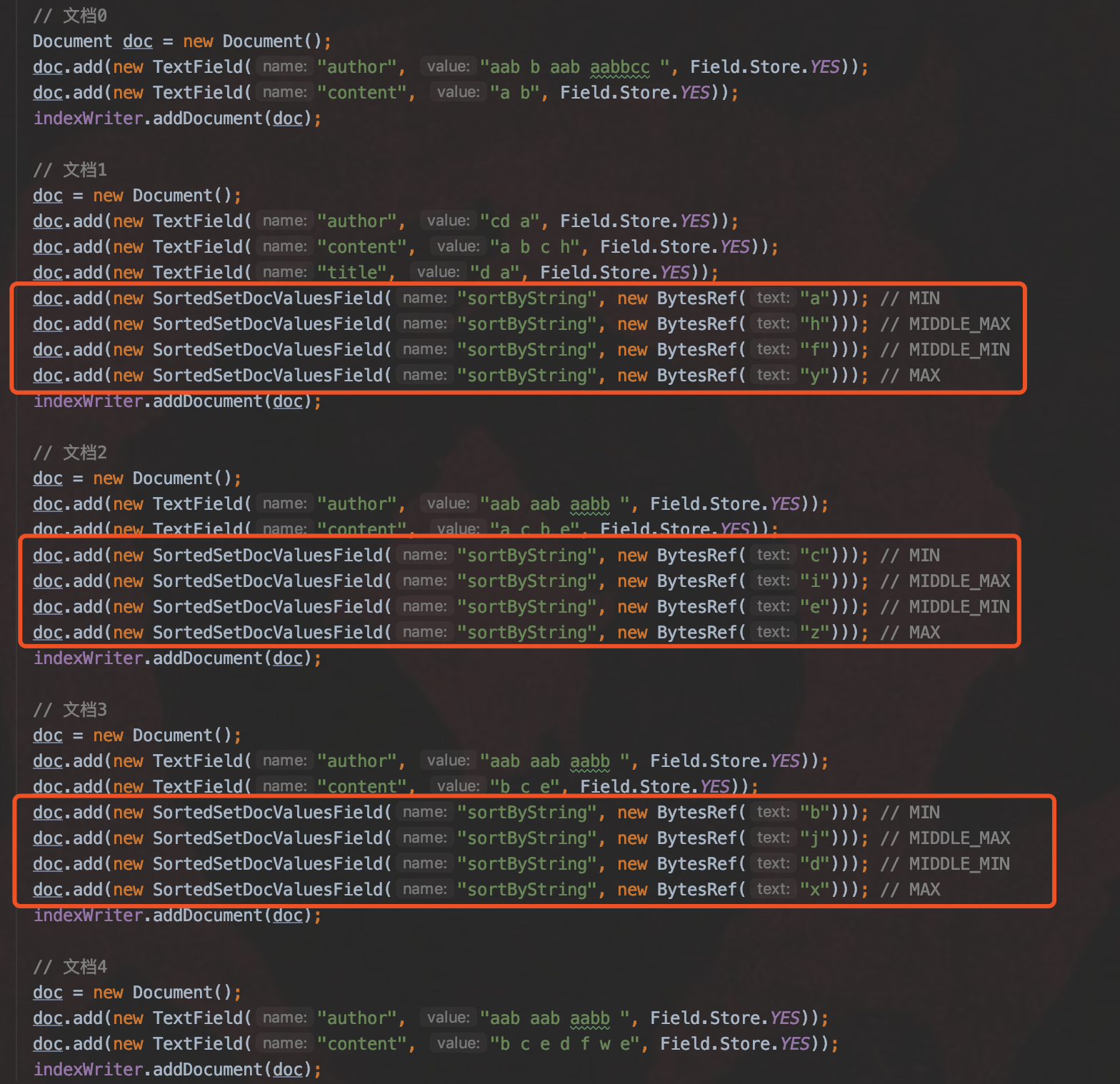
图 5:

- SortedSetSortField:根据文档(document)中 NumericDocValuesField 域的域值进行排序,如果文档中没有这个域,那么域值视为 null,被视为"最小"
- 图 3 为 索引阶段 的内容,允许设置相同域名的 SortedSetSortField 有多个域值, 这么做的好处在于,在搜索阶段,我们可以选择其中一个域值来进行排序,提高了排序的灵活性
- 图 4 为 搜索阶段 的内容,使用域名为"sortByString"的 SortedSetSortField 域的域值进行排序, 其中文档 0、文档 4 没有该域,故它的域值被视为 null,它们之间按照文档号排序
如何在搜索阶段选择排序域值:
-
通过 SortedSetSelector.Tyte 来选择哪一个域值,SortedSetSelector 提供了下面的参数
- MIN:选择域值最小的进行排序,例如上图中文档 1、文档 2、文档 3 会分别使用域值"a"、“c”、“b”作为排序条件,图 5 中即按照这个规则排序,由于参数 reverse 为 false,所以排序结果从小到大排序,其中文档 0、文档 4 的排序域值为 null:
|
|
- MAX:选择域值最大的进行排序,例如上图中文档 1、文档 2、文档 3 会分别使用域值"y"、“z”、“x”作为排序条件,由于参数 reverse 为 false,所以排序结果从小到大排序,其中文档 0、文档 4 的排序域值为 null:
|
|
- MIDDLE_MIN:选择中间域值,如果域值个数为偶数个,那么中间的域值就有两个,则取 较小值,例如上图中文档 1、文档 2、文档 3 会分别使用域值"f"、“e”、“d”作为排序条件,,由于参数 reverse 为 false,所以排序结果从小到大排序,其中文档 0、文档 4 的排序域值为 null:
|
|
- MIDDLE_MAX:选择中间域值,如果域值个数为偶数个,那么中间的域值就有两个,则取 较大值,例如上图中文档 1、文档 2、文档 3 会分别使用域值"h"、“i”、“j”作为排序条件,,由于参数 reverse 为 false,所以排序结果从小到大排序,其中文档 0、文档 4 的排序域值为 null:
|
|
SortedNumericSortField 也可以在索引阶段设置多个具有相同域名的不同域值,其用法跟 SortedSetSortField 一致,不赘述。
接下来我们根据过滤(filtering)规则,我们接着介绍 TopFieldCollector 的两个子类:
- SimpleFieldCollector:无过滤规则
- PagingFieldCollector:有过滤规则,具体内容在下文展开
SimpleFieldCollector
SimpleFieldCollector 的 collect(int doc)方法的流程图:
图 6:
预备知识
IndexWriterConfig.IndexSort(Sort sort)方法
在初始化 IndexWriter 对象时,我们需要提供一个 IndexWriterConfig 对象作为构造 IndexWriter 对象的参数,IndexWriterConfig 提供了一个 setIndexSort(Sort sort) 的方法,该方法用来在索引期间按照参数 Sort 对象提供的排序规则对一个段内的文档进行排序,如果该排序规则跟搜索期间提供的排序规则(例如图 3 的排序规则)是一样的,那么很明显 Collector 收到的那些满足搜索条件的文档集合已经是有序的(因为 Collecter 依次收到的文档号是从小到大有序的,而这个顺序描述了文档之间的顺序关系,下文会详细介绍)。
以下是一段进阶知识,需要看过 文档的增删改 以及 文档提交之 flush 系列文章才能理解,看不懂可以跳过:
- 我们以图 2 作为例子,在单线程下(为了便于理解),如果不设置索引期间的排序 或者 该排序跟搜索期间的排序规则不一致,文档 0~文档 4 对应的文档号分别是:0、1、2、3, Lucene 会按照处理文档的顺序,分配一个从 0 开始递增的段内文档号,即 文档的增删改(下)(part 2) 中的 numDocsInRAM ,这是文档在一个段内的真实文档号,如果在索引期间设置了排序规则如下所示:
索引期间,图 7

搜索期间,替换下图 3 的内容,使得图 2 中的例子中 搜索期间跟查询期间的有一样的排序规则,图 8

- ( 重要)在图 7、图 8 的代码条件下,传给 Collector 的文档号依旧分别是 0、1、2、3,但是这些文档号并不分别对应文档 0~文档 4 了,根据排序规则,传给 Collector 的文档号 docId 跟文档编号的映射关系:
图 9:
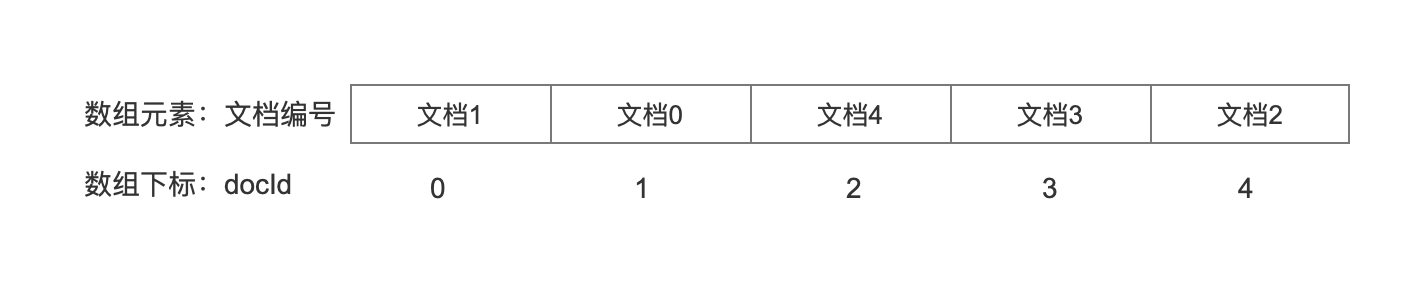
由图 9 可以知道,Collector 还是依次收到 0 ~ 4 的文档号,但是对应的文档号已经发生了变化,因为这些文档在索引期间已经根据域名为"sortByNumber"的 SortedNumerricSortField 域的域值排好序了。
( 极其重要)尽管在索引期间已经对段内的文档进行了排序,实际上文档 0~文档 4 在段内的 真实文档号 依旧是:0、1、2、3,只是通过图 9 中的数组实现了 映射关系,故给出下图:
图 10:

图 10 中通过数组实现的映射关系即 Sorter.DocMap 对象 sortMap,在 flush 阶段,生成 sortMap(见 文档提交之 flush(三))。
小节
TopFieldCollector 相比较 TopScoreDocCollector,尽管他们都是 TopDocsCollector 的子类,由于存在 索引期间 的排序机制,使得 TopFieldCollector 的 collect(int doc)的流程更加复杂,当然带来了更好的查询性能,至于如何能提高查询性能,由于篇幅原因,会在下面介绍图 6 的 collect(int doc)的流程中展开介绍。
第 4 小结 TopDocsCollector
TopFieldCollector
根据过滤(filtering)规则,TopFieldCollector 派生出的两个子类:
- SimpleFieldCollector:无过滤规则
- PagingFieldCollector:有过滤规则,具体内容在下文展开
SimpleFieldCollector
SimpleFieldCollector 的 collect(int doc)方法的流程图:
图 2:
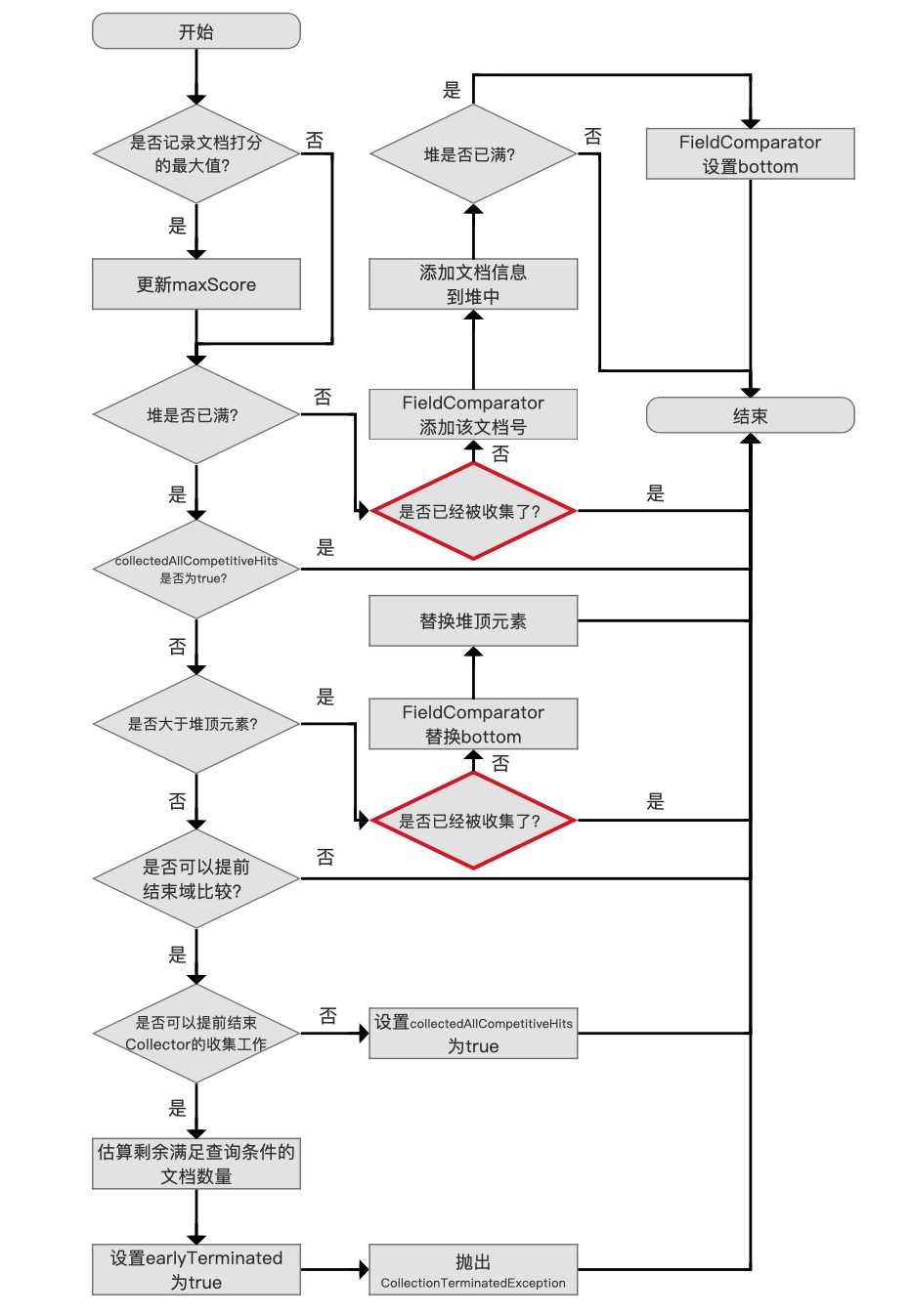
在介绍每个流程之前,先介绍下 TopFieldCollector 中的几个变量:
- trackMaxScore:该值是 TopFieldCollector 类的构造参数,用来描述是否需要记录所有满足查询条件的文档集合中最高的文档打分值,用 maxScore 用来记录该最大值
- trackDocScores:该值是 TopFieldCollector 类的构造参数,用来描述是否需要记录所有满足查询条件的文档的文档打分值
- totalHits:该值描述了 Collector 处理的满足搜索条件的文档数量,每当进入图 2 的流程,该值就递增一次。
如果业务中不需要用到文档的打分值或者 maxScore,强烈建议另这两个参数为 false,因为找出 maxScore 或者文档的打分值需要遍历所有满足查询条件的文档,无法提前结束 Collector 工作(canEarlyTerminate),在满足查询提交的文档数量较大的情况下,提前结束 Collector 的收集工作能显著提高查询性能。canEarlyTerminate 会在下文中介绍
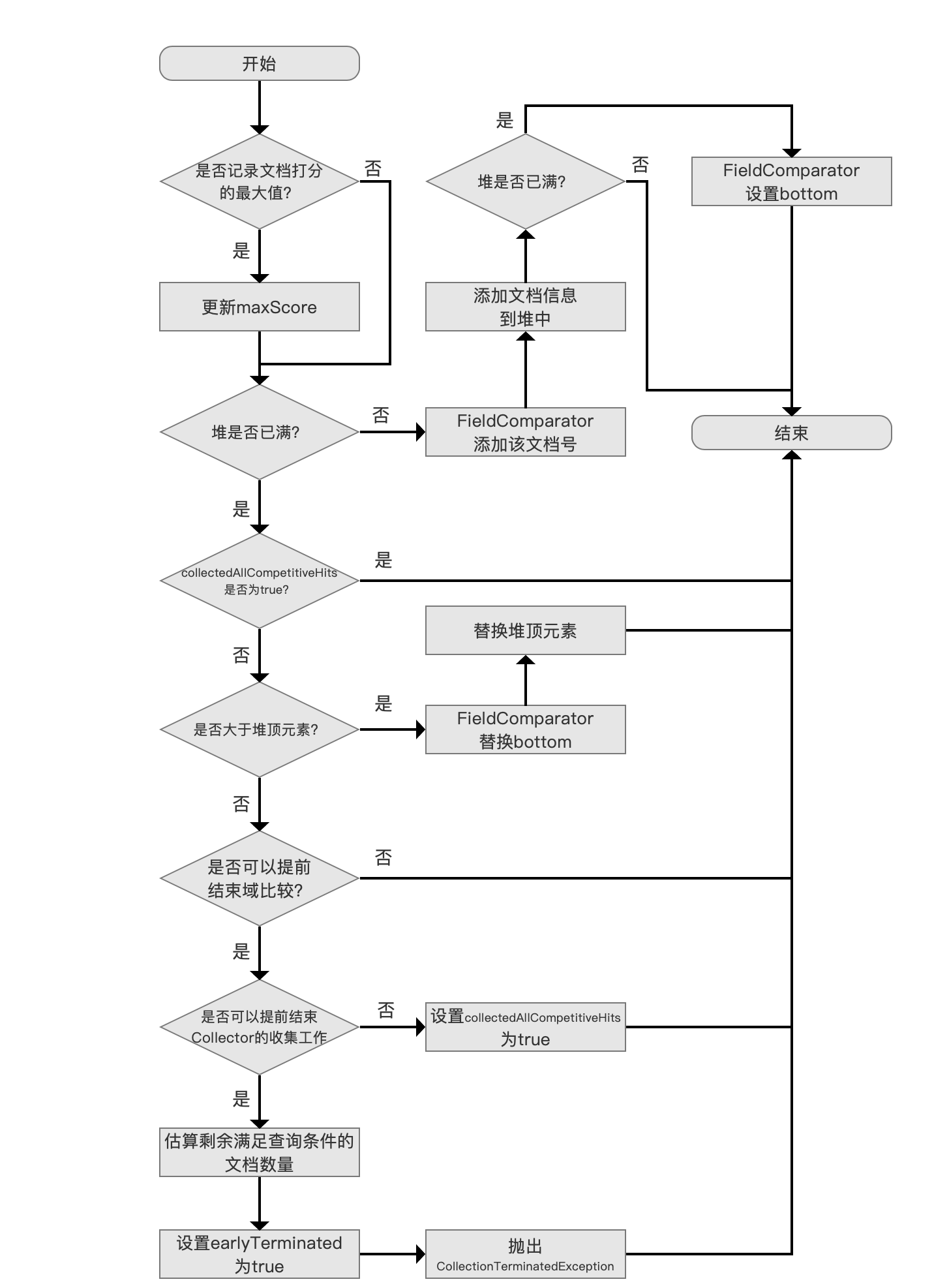
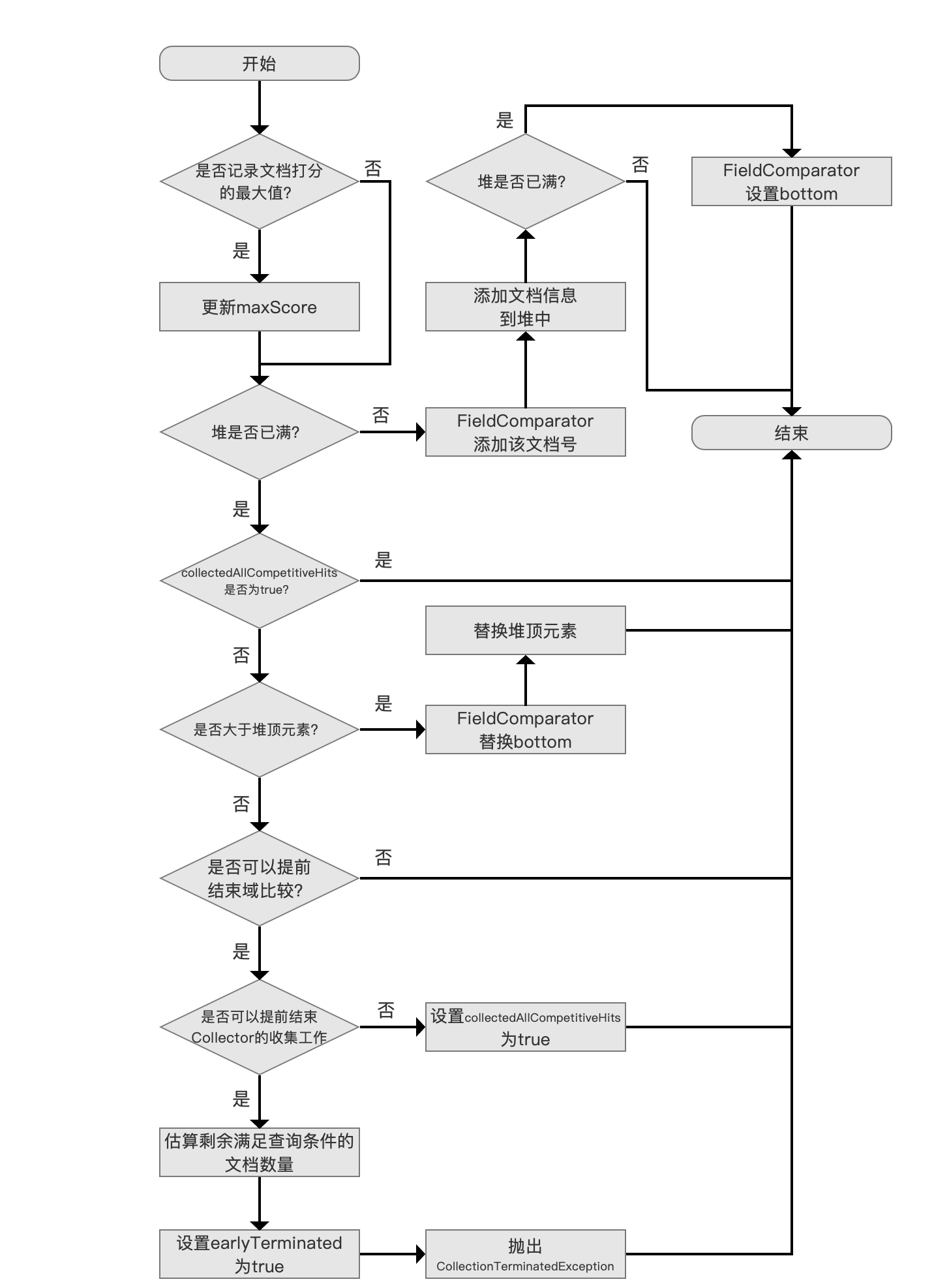
记录文档打分值最高的文档
图 3:
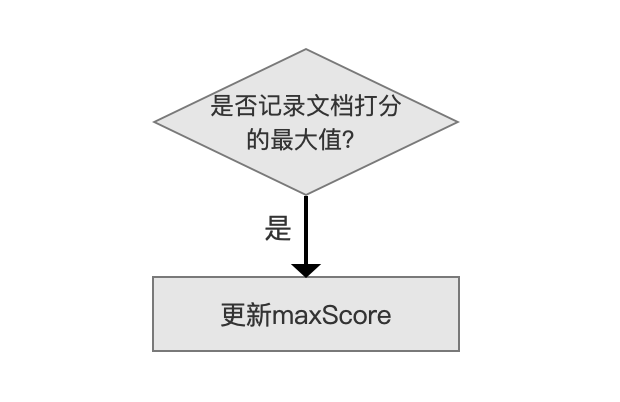
如果参数 trackMaxScore 为 true,那么 Collector 每处理一篇文档,就要记录该文档的打分值 score,如果 score 大于当前 maxScore 的值,则更新 maxScore 的值。
添加文档信息
图 4:
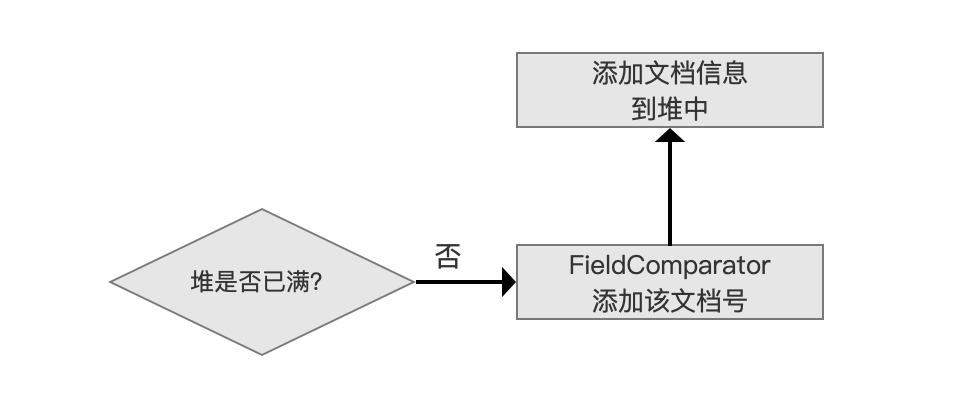
使用优先级队列 PriorityQueue 来存放满足搜索条件的文档信息( 文档信息至少包含了文档打分 score 以及文档号 docId),分数最低的文档信息位于堆顶,堆的大小默认为段中的文档总数(用户也可以指定堆的大小,即用户期望的返回结果 TopN 的 N 值)。
如果堆没有满,那么将文档号交给 FieldComparator,FieldComparator 的概念在 FieldComparator 的文章中介绍了,不赘述,它用来描述文档间的排序关系( 从代码层面讲,通过 FieldComparator 实现了优先级队列 PriorityQueue 的 lessThan() 方法),接着添加文档信息到堆中。
设置 bottom 值
图 5:
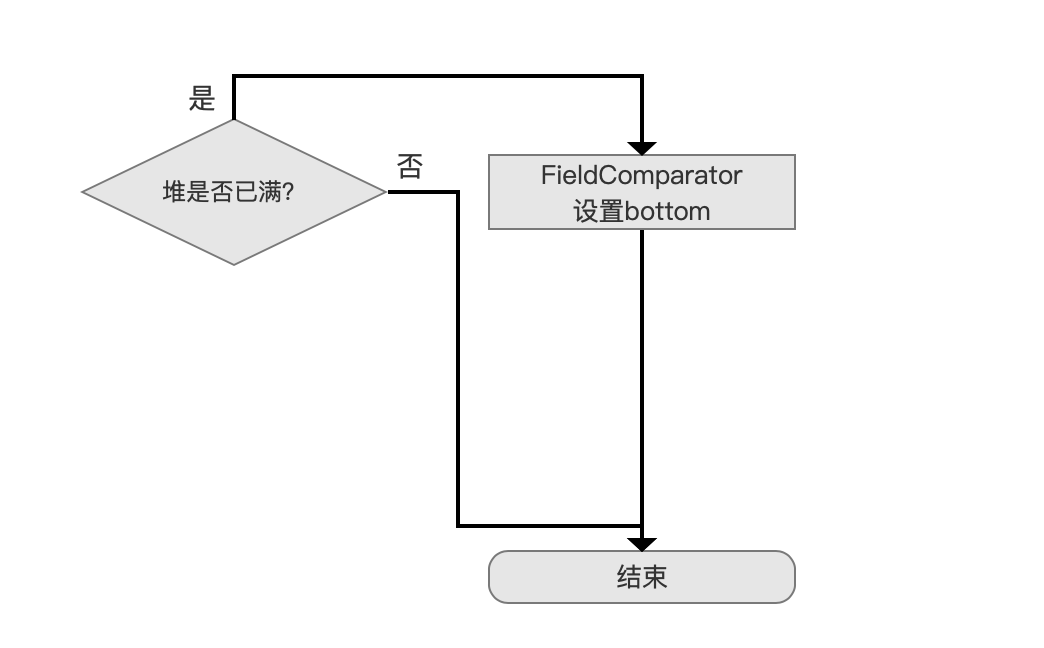
在 添加文档信息到堆中 流程后,如果此时堆正好满了,那么我们需要设置 bottom 的值,即从我们已经处理的文档中找出最差的(the weakest,sorted last),使得当处理下一篇文档时,只需要跟这个最差的文档进行比较即可。
仅统计满足查询条件的文档个数
图 6:

在堆满的情况的下,并且 collectedAllCompetitiveHits 为 true,直接可以退出,尽管直接退出了,还是统计了 totalHits 的值,所以从 collectedAllCompetitiveHits 的命名方式也可以看出来只是统计了 totalHits。
满足下面条件的情况下,collectedAllCompetitiveHits 会为 true:
|
|
- canEarlyStopComparing:该值描述了是否可以提前结束域比较,在 Collector(三) 我们提到,当索引期间通过 IndexWriterConfig.setIndexSort(Sort sort) 设置的排序规则与搜索期间提供的排序规则一致时,Collector 收到的文档集合已经是有序的,在堆已满的情况下,后面处理的文档号就没有比较的必要性了,那么 canEarlyStopComparing 的值会被 true,每次获取一个段的信息时设置 canEarlyStopComparing,即调用 getLeafCollector(LeafReaderContext context) 时候设置(见 Collector(一))。
- canEarlyTerminate:该值描述了是否可以提前结束 Collector 的收集工作,canEarlyTerminate 设置为 true 需要满足下面的条件:
|
|
如果满足上面的条件,Lucene 会通过抛出异常的方式结束 Collector,该异常会被 IndexSearcher 捕获。这样的好处在于能提高查询性能。比如说某一次查询,我们需要返回 Top5,但是满足搜索条件的文档数量有 10000W 条,那么在 Collector 中当处理了 5 篇文档后(文档在段中是有序的),就可以直接返回结果了。
如果条件不满足,即 canEarlyTerminate 的值为 false,那么尽管我们已经收集了 Top5 的数据(查询结果不会再变化),但是要继续遍历处理剩余的 9995 篇文档,因为我们需要记录 totalHits(如果 trackTotalHits 为 true)或者需要获得打分值最大的文档(如果 trackMaxScore 为 true),所以此时 collectedAllCompetitiveHits 为 true,继续处理下一篇文档
更新最差的(the weakest,sorted last)文档
图 7:
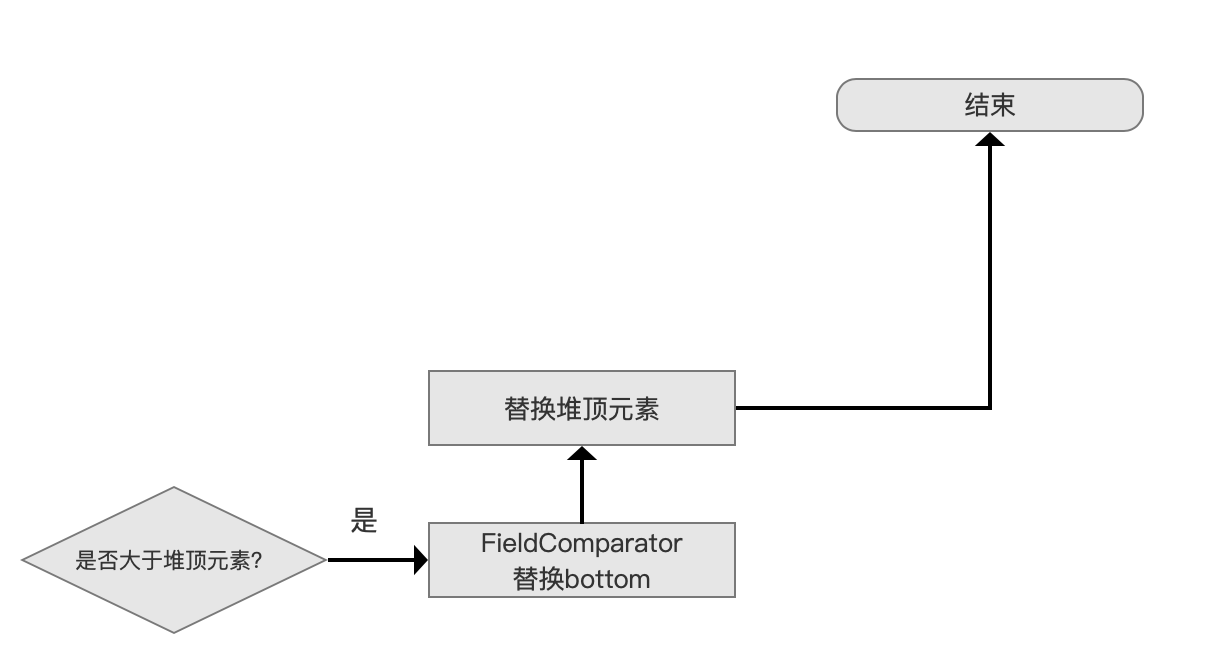
通过与域比较器(FieldComparator)的 bottom 值比较,如果比该值更好(competitive),那么先替换 bottom,然后重新算出新的 bottom,随后还要替换堆顶元素,然后调整堆,算出新的堆顶元素,最后退出继续处理下一篇文档。
无法提前结束域比较
图 8:
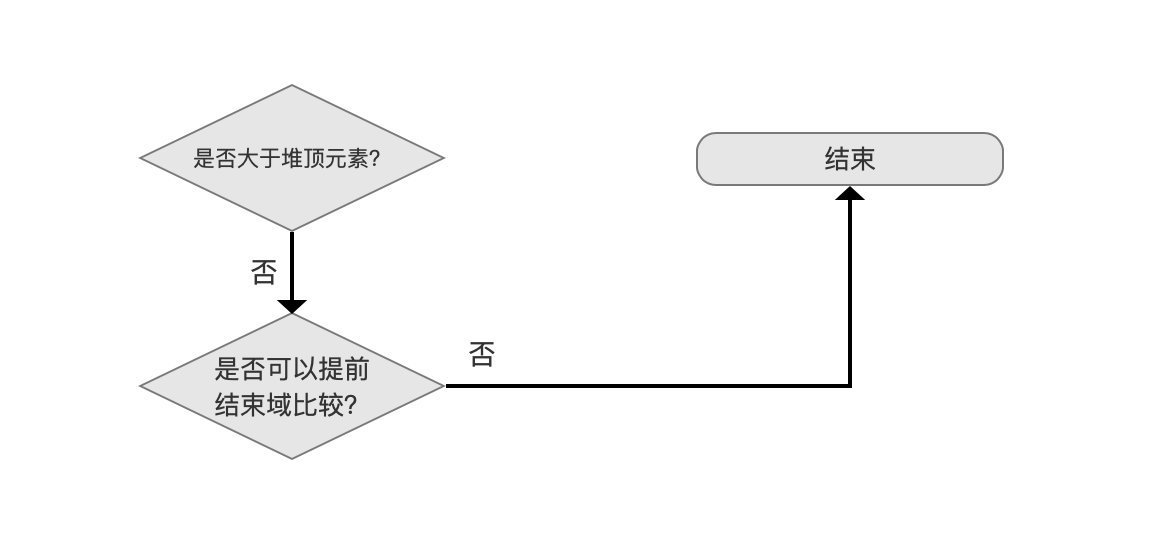
由于通过域比较后,当前文档比 bottom 还要差,那么先通过 canEarlyStopComparing 判断出能不能提前结束比较,如果 canEarlyStopComparing 为 false,则退出并处理下一篇文档。
canEarlyStopComparing 为 false 说明段中的文档没有按照搜索期间的排序规则进行排序,所以当前已经收集的 TopN 未必是最终的搜索结果,所以退出处理下一篇文档。
设置 collectedAllCompetitiveHits 为 true
图 9:
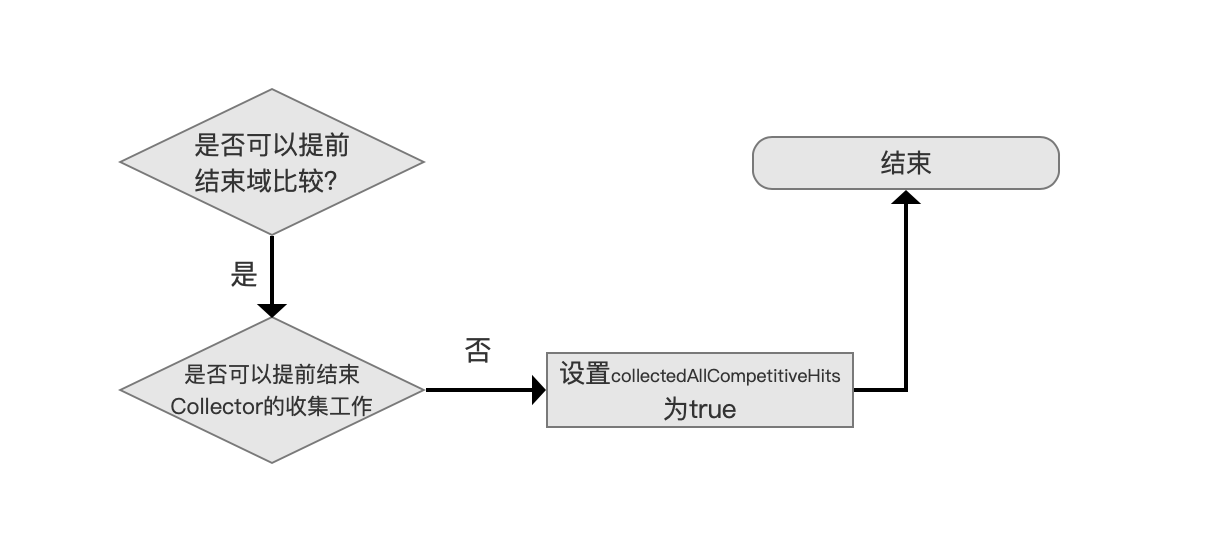
可以提前结束域比较,即 canEarlyStopComparing 为 true,并且不可以提前结束 Collector 的收集工作,即 canEarlyTerminate 为 false,那么同时满足这两个条件就可以设置 collectedAllCompetitiveHits 为 true 了。使得处理下一篇文档时就可以走图 6 中的流程了。
提前结束 Collector 的收集工作
图 10:
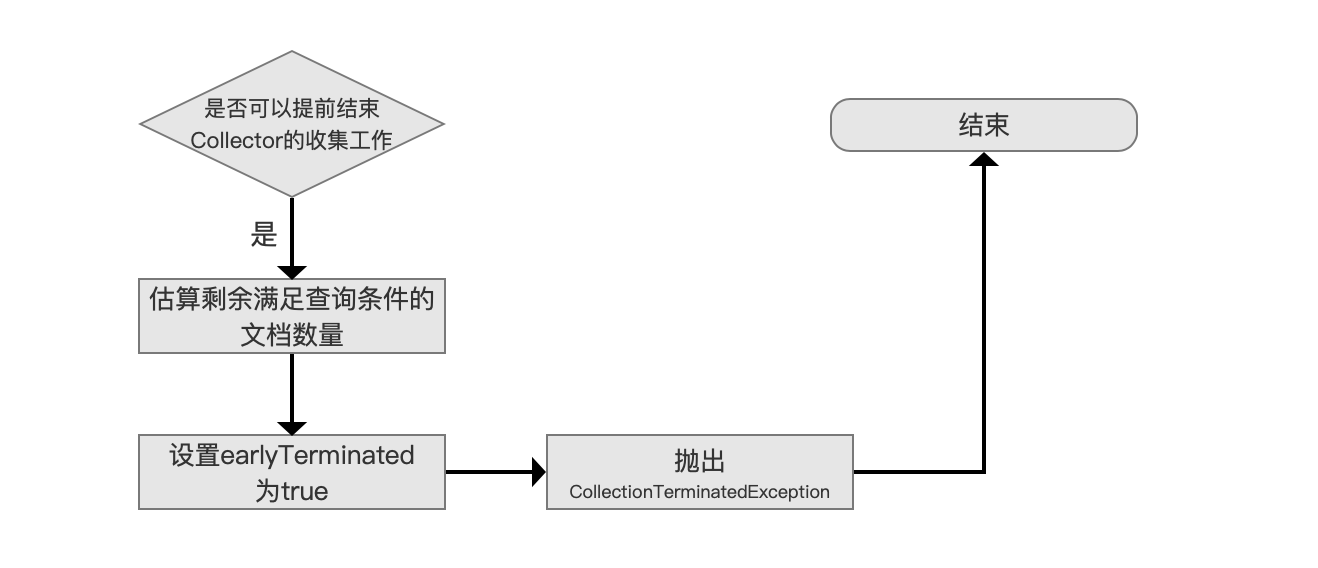
可以提前结束 Collector 的收集工作,那么我们先估算剩余满足查询条件的文档数量,通过线性估算出实现,估算方法不展开介绍,没有实际意义。
接着设置一个 earlyTerminated 的值为 true,用户在得到查询结果后可以通过该值来了解 Collector 提前结束收集工作这个事件。
通过抛出 CollectionTerminatedException 异常的方式来实现,大家可以点击链接看下源码中对这个异常的解释。
PagingFieldCollector
PagingFieldCollector 同 Collector(二) 中的 PagingTopScoreDocCollector 一样,相对于 SimpleFieldCollector 实现了分页功能,分页功能的介绍见 Collector(二),不赘述,collect(int doc)的流程图是相似的,并且用红圈标记出不同处。
PagingFieldCollector 的 collect(int doc)方法的流程图:
图 11:
是
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%E6%94%B6%E9%9B%86%E5%90%84%E4%B8%AA%E5%91%BD%E4%B8%AD%E7%9A%84/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


