渠江涛重排序在快手短视频推荐系统中的演进

分享嘉宾:渠江涛 快手 高级算法专家
编辑整理:吴祺尧
出品平台:DataFunTalk
导读: 快手短视频作为国内比较领先的短视频和直播社区,具有巨大的日活流量。短视频平台拥有巨大的流量入口和复杂的业务形态。例如,快手拥有短视频、直播、广告等十余种业务形态,产生了海量的交互数据。这让短视频推荐系统拥有复杂的技术场景落地,如大规模预估、强化学习、因果分析、因果推断等。本次的分享主题是快手短视频推荐系统中重排序技术环节的演进过程。
今天的介绍会围绕下面四点展开:
- 快手短视频推荐场景介绍
- 序列重排
- 多元内容混排
- 端上重排
01 快手短视频推荐场景介绍
首先给大家介绍一下快手推荐的主要技术环节。
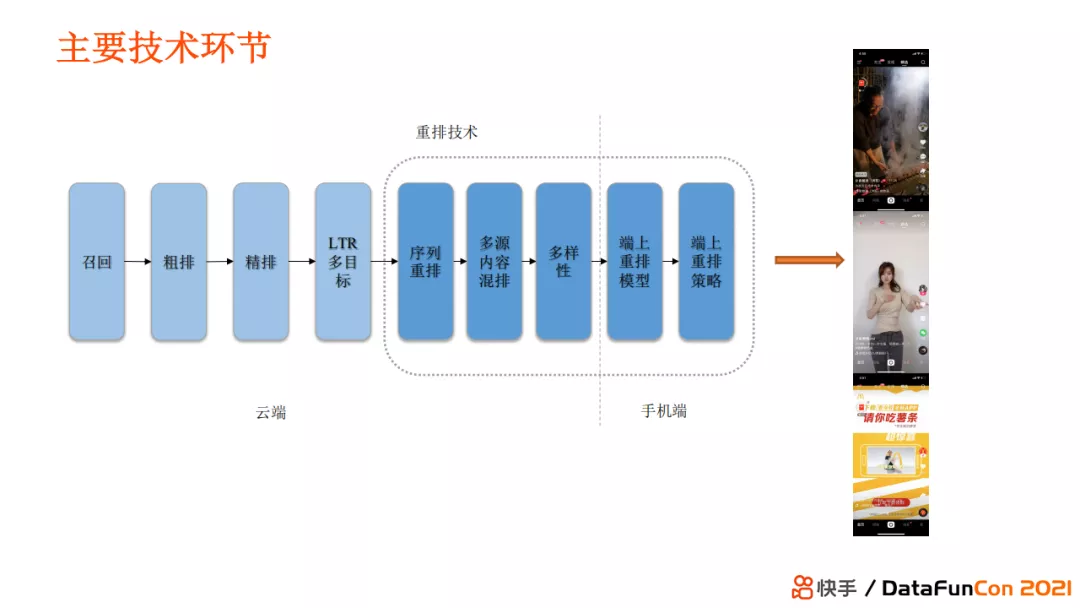
快手推荐系统包括了传统的召回、粗排、精排、Learning To Rank 的多目标排序、多目标预估等技术环节。而在这些模块之后的技术环节就属于重排序,主要包括手机端和服务端两部分。服务端通过传统服务器部署重排服务,包括序列重排、多源内容混排、多样性模块。端上部分包括端上重排模型和端上重排策略两部分。重排技术是快手十分重要的技术环节,它的发展速度远快于其他排序环节,属于较新的技术范畴。
重排阶段处理的问题包括:
- 整个序列的价值并非单 item 效果的累计,如何使得序列价值最大化;
- 沉浸式场景中,什么是好的多样性体验,业务意志如何体现;
- 同一个场景下越来越多的业务参与其中,如何恰当地分配流量和注意力,达成业务目标和整体最优;
- 如何更加及时、更加细微地感知用户状态,及时调整我们的推荐策略和内容。
02 序列重排
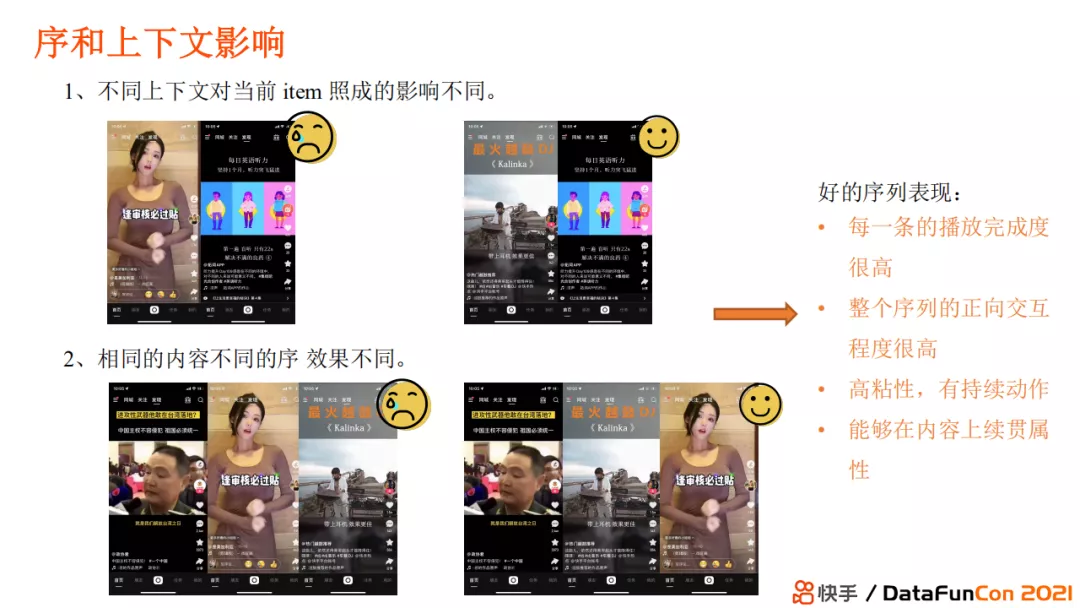
序列重排基于两个认知。
首先,上下文对当前 item 造成了重要影响 ,即视频的交互或者表现指标的好坏不仅仅由 item 自身决定,还由上文内容决定。比如当前推荐视频是有关英语学习的,但如果前一个视频是一个小姐姐跳舞的视频,那么看完上文视频再去看学英语的视频可能性较小。但如果上一条视频是一首很燃的英语歌曲,那很可能用户会因为听不懂歌曲内容,更愿意观看下一条有关学习英语的视频。
其次,相同的内容不同的序的表现也是天差地别的 。比如第一条视频是将军对于台海危机的言论,但如果下一条视频推荐了小姐姐视频那就相当不合时宜,因为这两个视频没有连贯性,推荐效果较差。那如果下一个推荐视频是比较燃的音乐,再在后面推荐小姐姐跳舞的视频,那么这时候内容的连贯性就较好,用户不会觉得突兀。
我们希望得到一个好的推荐序列使得序列价值最大,那么就会涉及到好的序列如何去定义的问题。我们认为好的序列完成度很高,整个序列的正向交互程度很高,用户具有高粘性,有看完视频后下刷的意愿,且序列在内容上具有序贯属性。
传统方案具有以下缺陷:
- 精排单点打分缺少当前 item 其他内容的信息,单点的预估存在不准确的问题;
- 贪心的打散方案只能解决内容散度的问题,缺少局部最优到整体最优路径;
- Mmr,dpp 等是在优化目标上加入散度项,并非是序列表现最佳。
所以我们序列重排的目标:
- 首先需要有 transformer 或者 LSTM 把上游内容信息融入当前内容信息中;
- 第二,我们的优化目标是序列表现情况,而不是单item的表现;
- 第三,我们需要重排模型有持续发现好的排列模式的能力。
这三个目标属于序列发现和序列评价范畴。
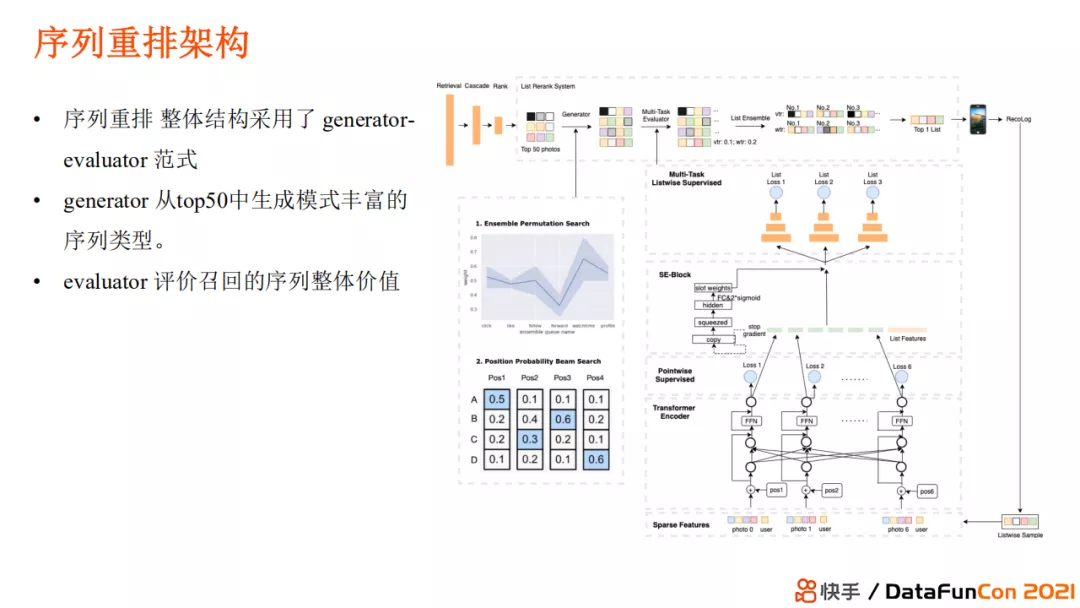
我们序列重排的整体结构采用了 generator-evaluator 范式,generator 从 top50 中生成模式丰富的序列类型,然后使用 evaluator 评价召回的序列整体价值。
序列的生成方法最容易想到的是将得分高的排在序列头部,得分低的排序序列尾部,即使用贪心的算法生成序列。其中大家常用的实现方法是 beam search,它顺序地生成每个位置的视频,选择方式是根据该位置前序的 item 选择模型或者策略预估地最优 topk 视频。
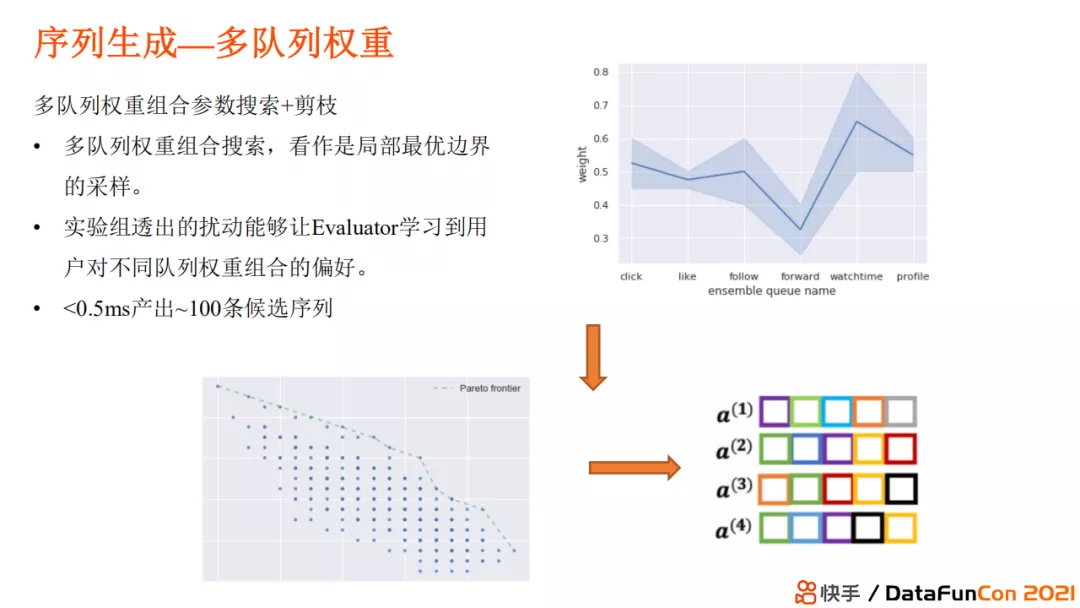
第二种方案是多队列权重。原先我们在线上的队列是使用手工调参或者使用自动调参工具的方法进行调节。但是线上参数并不是每时每刻都是固定的,我们需要在不同状态下使用不同参数,比如某段时间我需要推荐沉浸时间较长的视频,而另外一段时间需要低成本高获得感的视频内容,那么前者需要更多关注观看时长的目标,互动可以进行折算,而后者需要互动、点赞率较高。所以我们不能使用固定的参数,而是进行协同采样。采样过程从原理上来讲是不断地逼近 Pareto 最优曲面,进而得到不同的采样点,形成不同的序列。
其他的一些序列生成办法有 mmr 多样性召回、Seq2slate 召回,还有其他一些规则性的或者启发式的召回策略,在这里就不一一介绍了。
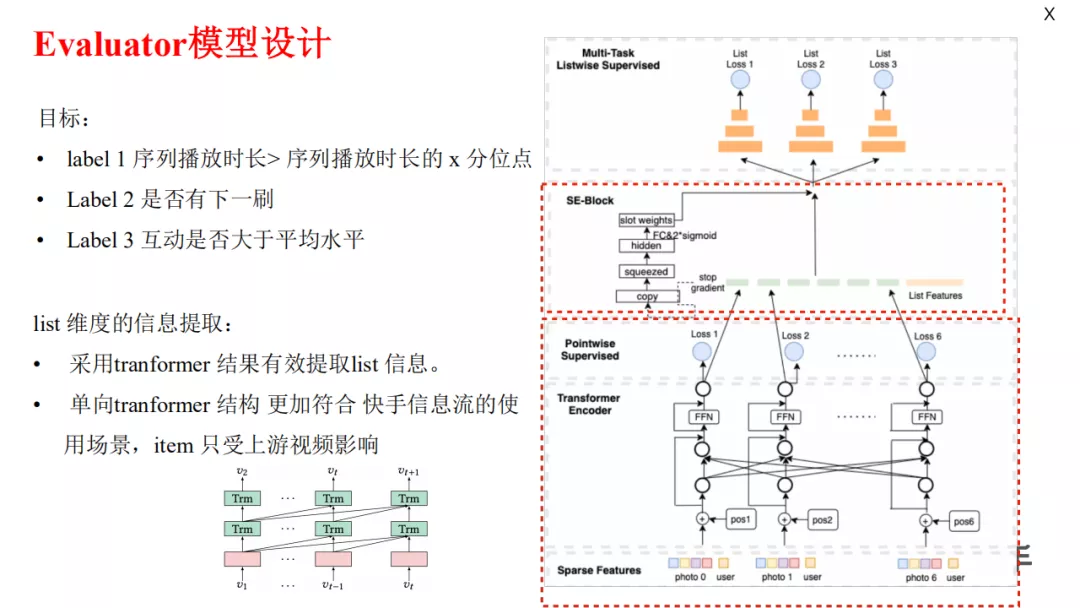
生成不同的序列后就需要对序列进行评价。我们的目标有三个:
- 首先,序列播放时长要大于某一个分位点;
- 第二,序列播放完毕后用户要有下刷动作;
- 第三,用户互动率能够大于平均互动水平。
Evaluator 使用单向 transformer 模型,这是因为用户其实是自上而下的刷视频,下游视频信息对上游视频没有增益,只有上游信息会对下游内容有影响。单向 transformer 模型可以降低计算复杂度,提升模型的稳定性。在单向 transformer 之后,我们使用一个辅助模型去做 embedding 表达,最后依次预估整个序列的得分。这一序列重排模型在线上产生了非常多的累积收益。
03 多元内容混排
下面我们介绍多元内容的混排。
在混排之前,业务是通过固定位置的形式来获取流量,平台不会考虑业务价值或者用户需求。这就会带来以下三个问题:
- 用户角度,偏好的业务和非偏好业务等频率出现;
- 业务方角度,流量中既有偏好的用户也有非偏好的用户,降低了业务服务效率;
- 平台角度,资源错配导致了浪费。
那么混排问题就可以被定义为:将各个业务返回结果恰当地组合,得到社会综合价值最大的返回序列。

最简单的办法就是对每个业务结果进行打分并据此进行排序。例如 LinkedIn 的一篇论文就是使用打分之后排序操作来实现的,他们为这一方法做了很完善的理论分析。它将优化目标设定为在用户价值体验大于C的前提下最优化营收价值。如果用户的广告价值大于用户的产品价值的时候,那我们就去投放广告内容;否则我们就去投放用户的产品内容。这一算法实现很简单,即在满足用户体验约束以及两个广告间隔约束下,那一部分价值高就推送那一部分内容。
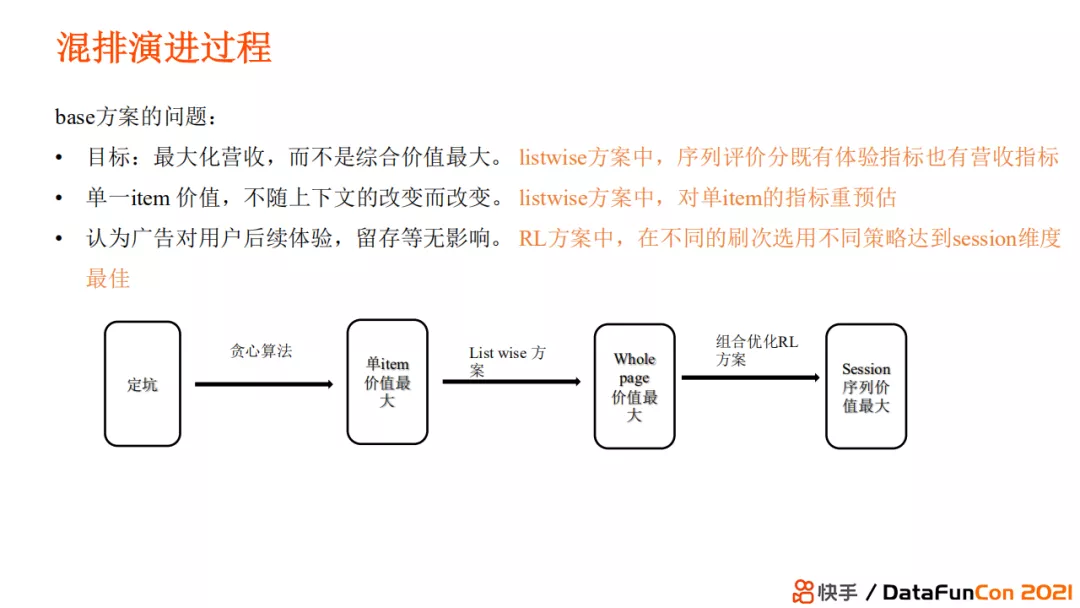
但上述方案有一个弊病,即它包含了很多强假设。首先,它的目标是最大化营收价值而不是最大化综合价值。第二,这一算法假设单一 item 的价值在不同位置和不同上下文的情况下保持不变,这和序列化建模时认知不同。第三,它认为广告对用户后续体验及留存等没有影响,但是如果从单一刷次来看放置广告的价值一定比不放广告的价值大,可是它并不是最优解,因为它会对后续的用户体验产生影响。
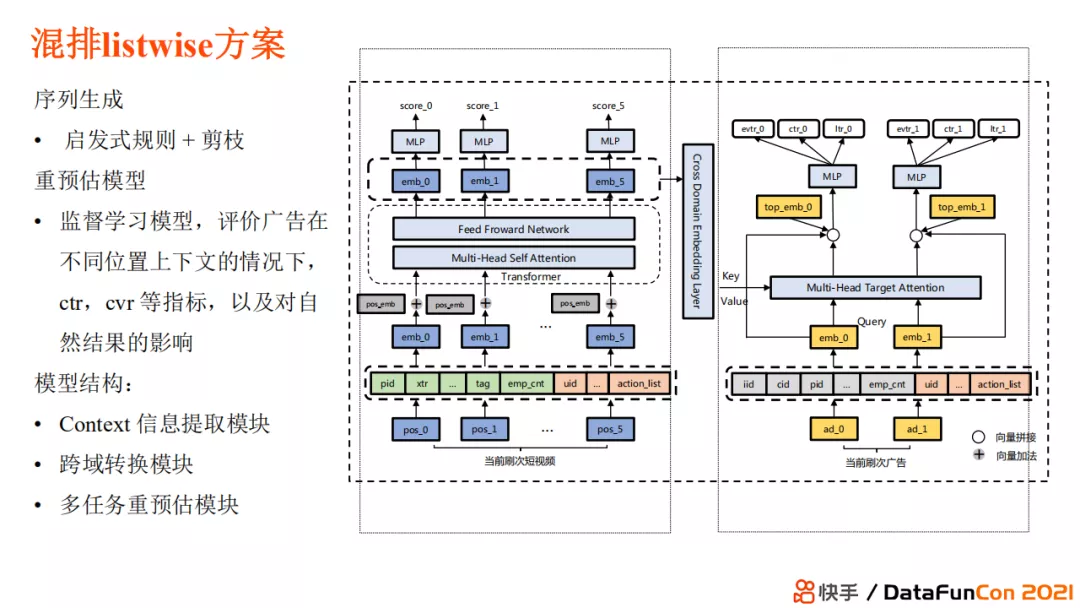
首先介绍一下 混排listwise方案 。这一方法秉承了序列生成和序列评估的过程,我们对每一种放置方案都会进行预估,衡量其对排序结果的影响,包括广告在不同位置不同上下文的情况下 ctr,cvr 等指标以及对自然结果的影响。模型的第一个模块是 context 信息提取模块。这一模块我们重新预估了视频内容的表现情况。第二个模块是跨域转换模块,因为广告和自然内容是跨域的。第三个模块会对广告的内容进行多任务重预估,比如衡量它的曝光率,cvr,ctr 等。有了这些预估指标后,我们就可以得到一个最佳价值序列。

接下来介绍 混排RL方案 。在不同状态下,RL可以在不同策略中选择一个最佳策略来达到长期体验和近期收入的平衡。原先的模型采用的是固定策略,即在不同状态下的广告放置、广告营收和结果体验的配比都是固定的。但这一做法其实是有问题的。
我们定义状态为用户在一个 session 内下刷深度、曝光内容、广告交互历史、内容交互历史、上下文信息以及本刷的内容。动作空间则包含如第一条、第二条广告放置在哪一位置等。当然动作空间中需要满足业务约束。最终的结果既要考虑营收价值,又要考虑用户体验价值以及长期留存的内容。
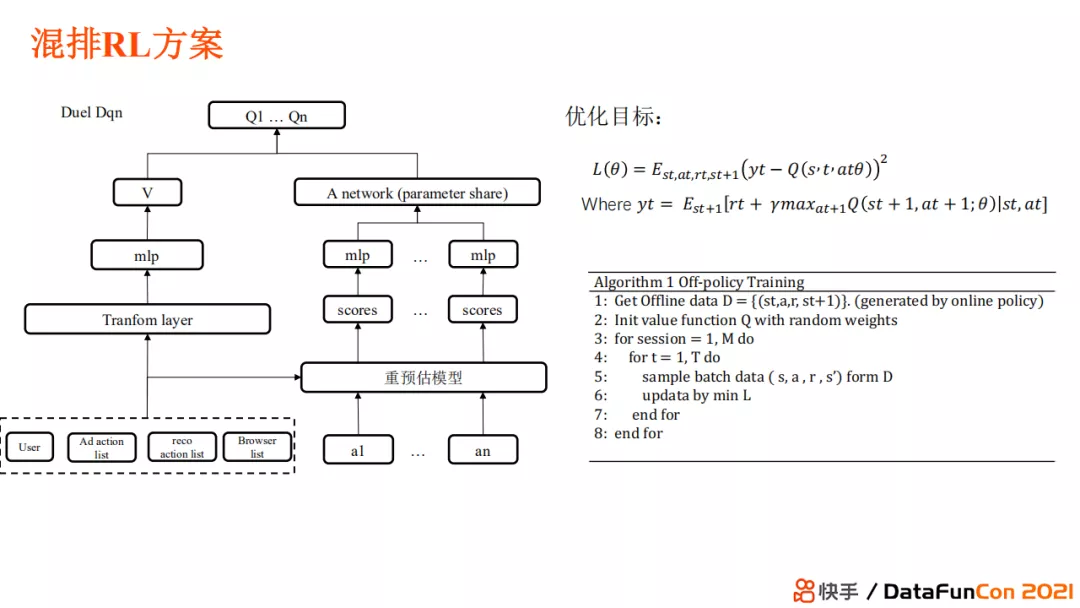
Action 空间是一个十分稀疏的空间,我们最终选择了 Duel Dqn 的方案来实现。首先,V网络评估用户当前的满意程度,这使得模型可以在不同的用户状态下选择不同的放置策略。但由于放置策略十分离散,它的解空间相当大,那么我们需要对离散空间 dense 化。我们的 dense 化不是通过模型去做的,而是通过之前使用的重预估监督模型来实现。通过监督模型,我们就可以知道这个 action 下每个位置放置的内容可以带来多少的用户体验和商业价值。之后,我们可以使用一个神经网络对不同的 action 进行打分。我们的优化目标是每一步选择能够达到最终的总和价值最大,reward 是长期价值和近期价值的组合。
我们采用了两段式训练范式,首先使用 online policy 的方式,先将模型部署上线生成 online policy 下的数据,作为 off policy 的训练数据放入回放池。之后,我们使用 off policy 来训练 Dqn 模型。经过优化后,在线上模型针对不同的用户状态得到的 Value,可以选择使得Q值最大的策略,最终得到线上的预估结果。
04 端上重排
下面为大家介绍端上重排的工作。
端上重排主要解决以下四个问题:
- 实时感知 :目前我们每次针对每次请求使用的用户信号都是历史信息,用户反馈信号感知存在延迟,导致下刷操作之间的反馈信号没有被利用到。
- 实时反馈 :分页请求场景下,下次请求前无法及时调整当前推荐内容。如果不在端上部署模型,那么针对长序列,由于序列无法根据用户下刷过程中的反馈来实时调整,导致用户由于不满意而离开,使得用户流失概率变高。
- 千人千模 :端上每一台手机都是一个小服务器,我们可以正对每一个用户训练一个模型,达到更加极致的个性化推荐。
- 算力分配 :灵活的 pagesize,可以在算力紧张的时候,动态决定服务端请求频次,提升算力经济性。
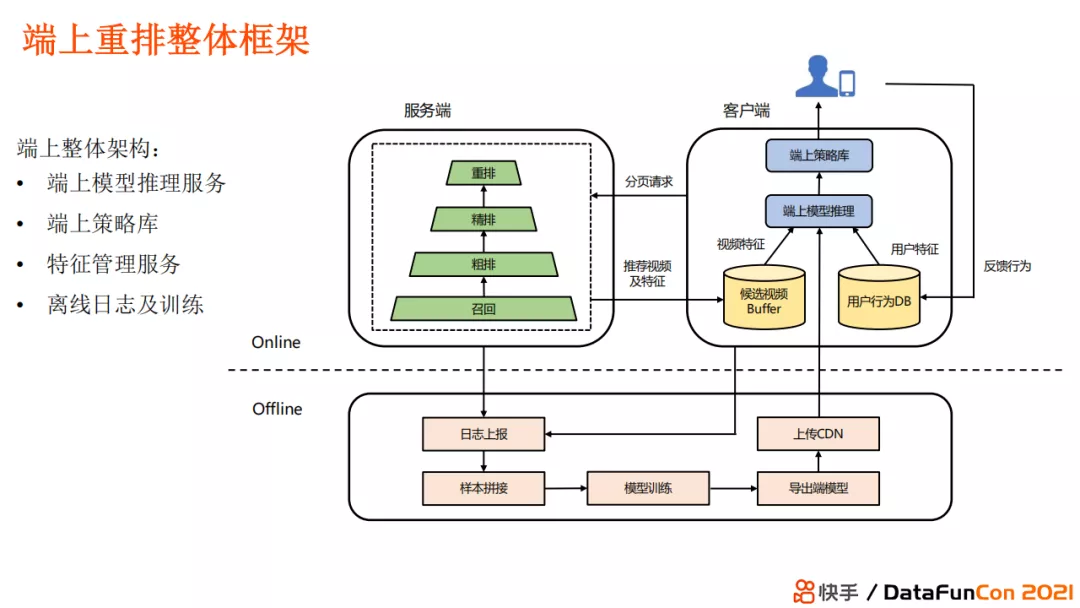
上图展示了端上重排的整体框架。服务端收到客户手机发出的一个分页请求后会进行召回、粗排、精排、重排,返回推荐的视频及特征。端上的推理模型使用候选视频以及候选视频的特征,加上用户的特征和反馈行为进行模型推理,最后使用端上策略库得到最终混排结果。Offline 比起传统的样本拼接、模型训练以外会增加一个 dqn 模型上传。
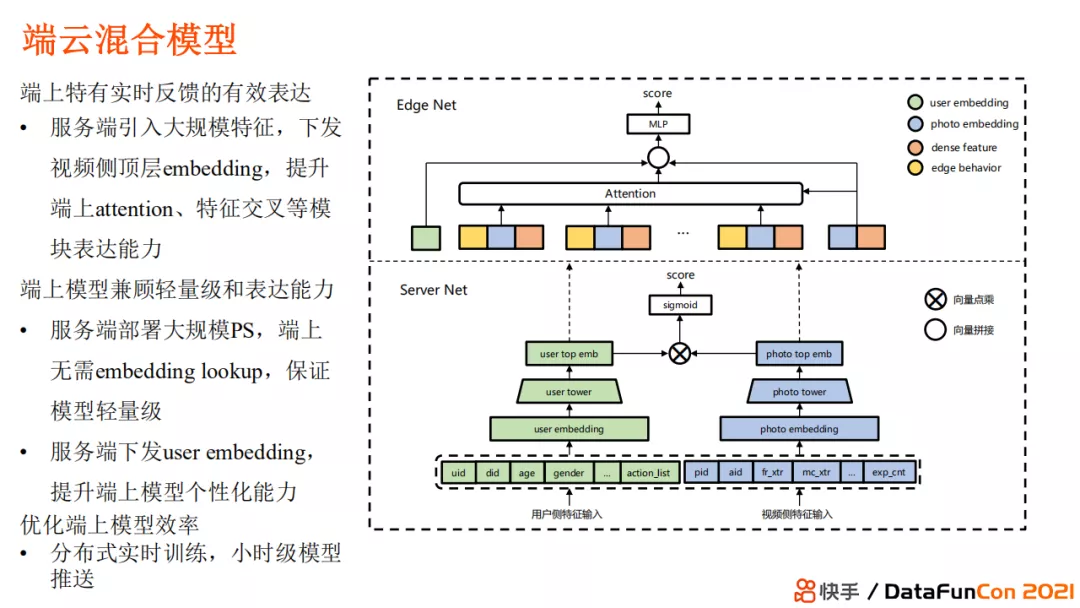
我们还在尝试千人千模的工作,目前能达到的能力是端云混合的部署模型,即我们在服务器端部署一部分模型,在客户端部署另一部分模型。在客户端,部署的这部分模型需要兼顾轻量级和表达能力,需要利用实时交互动作;在服务端则要利用其强大的算力,把所有 embedding 相关操作(如embedding lookup等)在服务器中完成。我们可以做到分布式实时训练,并达到小时级的推送能力。
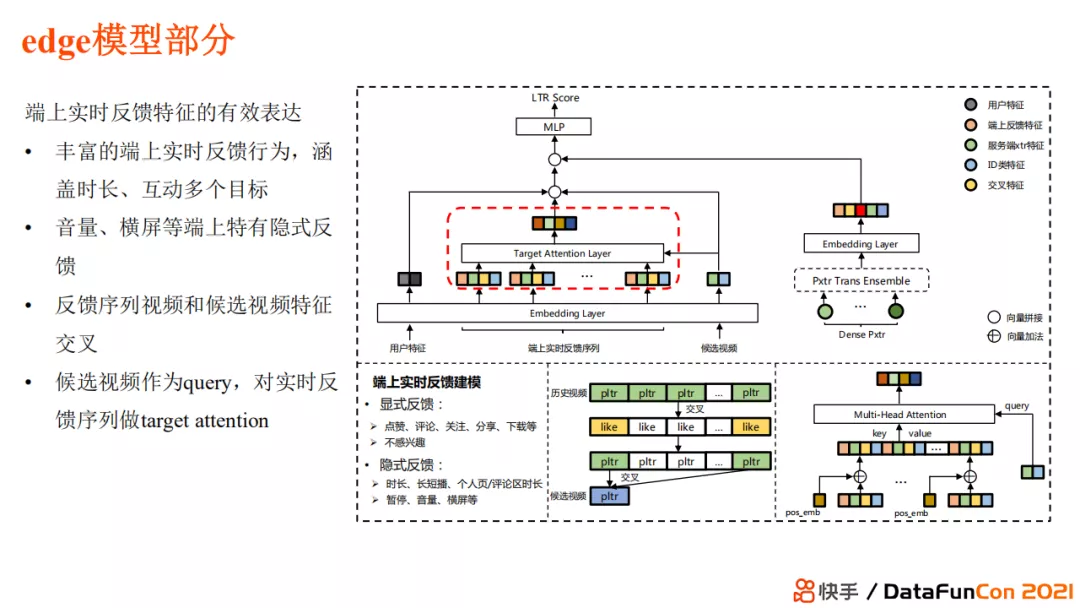
端上模型使用的特征除了显示的用户行为反馈,还有音量、横屏等端上特有的隐式反馈,这些特征在服务端是无法建模的。具体地,我们把用户最近的反馈行为加入了实时反馈列表中,使用候选动作与它们进行基于 transformer 的交互。端上模型主要体现了针对实时反馈特征的更有效地表达。
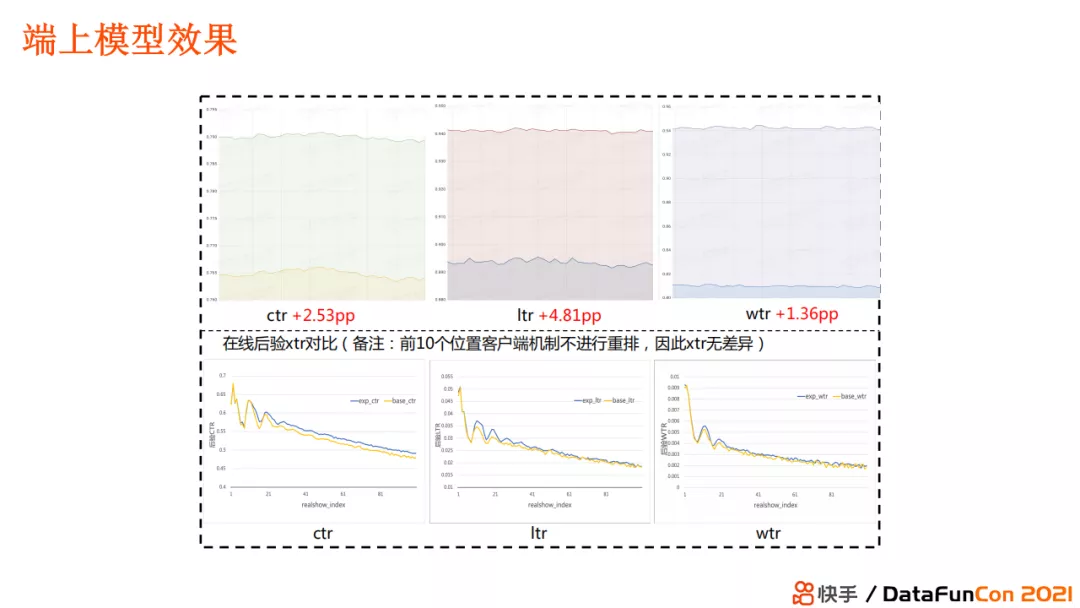
端上模型在上线后,业务指标有了明显的提升。比如模型将 ctr 提升了2.53pp,ltr 提升了4.81pp,wtr 提升了1.36pp。
05 精彩问答
Q:如何判断哪一种生成的序列效果更好?客观的模式判断会不会与主观意识上有不一致?
A:我们确实可以通过数据分析来发现较好的推荐策略与推荐模式,但是我们很难发现全部的表现情况,无法进行穷举,因为每个用户对应的最佳模式是不一样的,即它是个性化的产物。我们发现好的模式通常来说前后具有因果关系、关联关系,上游内容与下游内容具有好的承接属性。不仅如此,一个session内的推荐应该是让用户看起来是有条理性的而不是杂乱无章的。我们还发现一个的推荐策略其实是可以在一个连贯的内容中穿插一些其他效果较好的主题,进而发掘一些更好的策略。但是我们也不可能将所有的模式发掘出来,根本原因在于它是一个个性化决策过程。
Q:千人千模中每个用户的参数是一样的吗?是否需要根据每一个人来做训练?如果需要对每个用户做训练,那么如何进行模型的离线效果评测?
A:千人千模的问题就是如何把个性化特征抽取出来,做一个完全适配于每个用户的模型。我们做过离线验证,比如活跃用户和非活跃用户的区分。其实这种做法产生了很大的经济价值。我们所有的模型其实是被活跃用户主导的,而对于非活跃用户或者冷启动用户在刚进入社区的时候会有很多不适应的地方,所以对他们做单独的模型会有很好的效果。这便是千人千模方向的一个简单的试验。我们也对用户做了分群,根据他们的交互数据和人口属性做了分析,发现不同群体的用户的交互表现完全不同。这是由于快手涵盖的用户面特别多,有白领也有农民工兄弟;有中年人、青年人,也有老年人。那么这些不同群体下的表现数据一定也是具有很大的差异性的。我们利用分群做不同的模型,进行离线实验,发现这样确实会有很明显的收益,但是线上我们好没有进行部署。若想进一步将模型粒度进行切分,会存在稳定性的问题,我们目前还在尝试解决它们。
Q:会不会考虑设置一个多样性的底线,比如不同的视频类型之间的�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B8%A0%E6%B1%9F%E6%B6%9B%E9%87%8D%E6%8E%92%E5%BA%8F%E5%9C%A8%E5%BF%AB%E6%89%8B%E7%9F%AD%E8%A7%86%E9%A2%91%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E4%B8%AD%E7%9A%84%E6%BC%94%E8%BF%9B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


