深度预估模型中的特征自动组合机制演化简史
作者: 杨旭东
96 人赞同了该文章
众所周知,深度学习在计算机视觉、语音识别、自然语言处理等领域最先取得突破并成为主流方法。但是,深度学习为什么是在这些领域而不是其他领域最先成功呢?我想一个原因就是图像、语音、文本数据在空间和时间上具有一定的内在关联性。比如,图像中会有大量的像素与周围的像素比较类似;文本数据中语言会受到语法规则的限制。CNN对于空间特征有很好的学习能力,正如RNN对于时序特征有强大的表示能力一样,因此CNN和RNN在上述领域各领风骚好多年。
在Web-scale的搜索、推荐和广告系统中,特征数据具有高维、稀疏、多类别的特点,一般情况下缺少类图像、语音、文本领域的时空关联性。因此,如何构建合适的网络结构以便在信息检索、推荐系统和计算广告领域取得良好的特征表示能力,进一步提升最终的业务效果成了学术界和工业界共同关注的问题。
本文在跟踪了最近主流的互联网业务中大量使用的排序模型的基础上,总结出了深度CTR、CVR预估模型发展演化的三条主线,跟大家分享。
- 第一条主脉络是以FM家族为代表的深度模型,它们的共同特点是自动学习从原始特征交叉组合新的高阶特征。
- 第二条主脉络是一类使用attention机制处理时序特征的深度模型,以DIN、DIEN等模型为代表。
- 第三条主脉络是以迁移学习、多任务学习为基础的联合训练模型或pre-train机制,以 ESMM、DUPN等模型为代表。
其中前两条主脉络虽然出发点不同,但个人认为也有一些共通之处,比如attention机制是不是可以在某种程度上理解为一种特殊形式的组合特征。第三条主脉络属于流程或框架层面的创建。本文的主要目标是理清楚第一条主线中各个经典的深度模型的发展演化脉络,包括它们的优缺点和共通之处。
背景
构建好的特征对于机器学习任务来说至关重要,它关系到模型的学习难易程度及泛化性能。好的特征是相互独立的有区分性且易于理解的特征,具体地可以参考《 何为优秀的机器学习特征》。
交叉组合原始特征构成新的特征是一种常用且有效的特征构建方法。哪些特征需要被交叉组合以便生成新的有效特征?需要多少阶的交叉组合?这些问题在深度学习流行之前需要算法工程师依靠经验来解决。人工构建组合特征特别耗时耗力,在样本数据生成的速度和数量巨大的互联网时代,依靠人的经验和技能识别出所有潜在有效的特征组合模式几乎是不可能的。一些有效的组合特征甚至没有在样本数据中出现过。
那么,能否自动构建有效的交叉组合特征?答案是肯定的。在深度学习之前,一些有益的尝试是把特征组合的任务交给子模型来学习,最经典的方法就是Facebook在2014年的论文中介绍的通过GBDT(Gradient Boost Decision Tree)模型解决LR模型的特征组合问题。该方法思路很简单,特征工程分为两部分,一部分特征用于训练一个GBDT模型,把GBDT模型每颗树的叶子节点编号作为新的特征,加入到原始特征集中,再训练最终的LR模型。详细介绍可以查看我之前的一篇博文:《 主流CTR预估模型的演化及对比》。此类解决方案在特征工程阶段就引入了机器学习模型,虽然可以部分解决问题,但还是过于麻烦,不够灵活。
要避免上述麻烦,自然而然就是要引入端到端学习的思路,即用一个统一的模型同时完成特征组合和目标拟合的任务。因子分解机(Factorization Machines, FM)模型是第一个从原始特征出发,端到端学习的例子。然而,FM毕竟还是一个浅层模型,经典的FM模型只能做二阶的特征交叉,模型学习复杂组合特征的能力偏弱。尽管如此,FM提出了一种很好的自动学习交叉组合特征的思路,随后融入FM模型思路的深度学习模型便如雨后春笋般应运而生,典型的代表有FNN、PNN、DeepFM、DCN、xDeepFM等。关于这些模型的介绍和对比,在我之前的两篇博文中也有详细介绍,感兴趣的读者可以查阅《 主流CTR预估模型的演化及对比》、《 玩转企业级Deep&Cross Network模型你只差一步》。
本文的其余内容将会对这些模型做一个详细的复盘,同时对该主线的集大成者xDeepFM模型做一个详细的介绍,其中包括一些自己对模型的理解,实际的使用心得,以及某些模型实现时的一些trick。文章的最后还会提供某些模型的源代码链接。
特征组合的演化路线
从 FM 模型说起,FM通过特征对之间的隐变量内积来提取特征组合,其函数形式如下:

对于每个原始特征,FM都会学习一个隐向量。模型通过穷举所有的特征对(pair)并逐一检测特征对的效用值的方法来自动识别出有效的特征组合。特征对的效用值通过该特征对涉及的两个原始特征的隐向量的内积来计算。
可以看出FM最多只能识别出二阶的特征组合,模型有一定的局限性。 FNN 模型最先提出了一种增强FM模型的思路,就是用FM模型学习到的隐向量初始化深度神经网络模型(MLP),再由MLP完成最终学习。
MLP(plain-DNN)因其特殊的结构天然就具有学习高阶特征组合的能力,它可以在一定的条件下以任意精度逼近任意函数。然而,plain-DNN以一种隐式的方式建模特征之间的交互关系,我们无法确定它学习到了多少阶的交叉关系。高维稀疏的原始特征在输入给DNN之前一般都会经过embedding处理,每一个域(类别)的原始特征都会被映射到一个低维稠密的实数向量,称之为embedding向量。FM模型中的隐向量也可以理解为embedding向量。Embedding向量中的元素用术语bit表示,可以看出plain-DNN的高阶特征交互建模是元素级的(bit-wise),也就是说同一个域对应的embedding向量中的元素也会相互影响。这与FM显式构建特征交叉关系的方式是不一样的,FM类方法是以向量级(vector-wise)的方式来构建高阶交叉关系。经验上,vector-wise的方式构建的特征交叉关系比bit-wise的方式更容易学习。
虽然两种建模交叉特征的方式有一些区别,但两者并不是相互排斥的,如果能把两者集合起来,便会相得益彰。 PNN 模型最先提出了一种融合bit-wise和vector-wise交叉特征的方法,其通过在网络的embedding层与全连接层之间加了一层Product Layer来完成特征组合。PNN与FM相比,舍弃了低阶特征,也就是线性的部分,这在一定程度上使得模型不太容易记住一些数据中的规律。**WDL(Wide & Deep Learning)**模型混合了宽度模型与深度模型,其宽度部分保留了低价特征,偏重记忆;深度部分引入了bit-wise的特征交叉能力。WDL模型的一大缺点是宽度部分的输入依旧依赖于大量的人工特征工程。
能不能在融合bit-wise和vector-wise交叉特征的基础上,同时还能保留低阶特征(linear part)呢?当然是可以的。 DeepFM 模型融合了FM和WDL模型,其FM部分实现了低阶特征和vector-wise的二阶交叉特征建模,其Deep部分使模型具有了bit-wise的高阶交叉特征建模的能力。具体地,DeepFM包含两部分:神经网络部分与因子分解机部分,这两部分共享同样的输入。对于给定特征
 ,向量
,向量
 用于表征一阶特征的重要性,隐变量
用于表征一阶特征的重要性,隐变量
 用于表示该特征与其他特征的相互影响。在FM部分,
用于表示该特征与其他特征的相互影响。在FM部分,
 用于表征二阶特征,同时在神经网络部分用于构建高阶特征。所有的参数共同参与训练。DeepFM的预测结果可以写为
用于表征二阶特征,同时在神经网络部分用于构建高阶特征。所有的参数共同参与训练。DeepFM的预测结果可以写为

其中
 是预测的点击率,
是预测的点击率,
 与
与
 分是FM部分与DNN部分。
分是FM部分与DNN部分。

其中
 。加法部分反映了一阶特征的重要性,而内积部分反应了二阶特征的影响。
。加法部分反映了一阶特征的重要性,而内积部分反应了二阶特征的影响。

其中H是隐层的层数。

图1. FNN、PNN、WDL、DeepFM的网络结构对比
FM、DeepFM和Inner-PNN都是通过原始特征隐向量的内积来构建vector-wise的二阶交叉特征,这种方式有两个主要的缺点:
- 必须要穷举出所有的特征对,即任意两个field之间都会形成特征组合关系,而过多的组合关系可能会引入无效的交叉特征,给模型引入过多的噪音,从而导致性能下降。
- 二阶交叉特征有时候是不够的,好的特征可能需要更高阶的组合。虽然DNN部分可以部分弥补这个不足,但bit-wise的交叉关系是晦涩难懂、不确定并且不容易学习的。
那么, 有没有可能引入更高阶的vector-wise的交叉特征,同时又能控制模型的复杂度,避免产生过多的无效交叉特征呢?让我们先来思考一个问题。二阶交叉特征通过穷举所有的原始特征对得到,那么通过穷举的方法得到更高阶的交叉特征,必然会产生组合爆炸的维数灾难,导致网络参数过于庞大而无法学习,同时也会产生很多的无效交叉特征。让我们把这个问题称之为维数灾难挑战。
解决维数灾难挑战不可避免的就是要引入某种“压缩”机制,就是要把高阶的组合特征向量的维数降到一个合理的范围,同时在这个过程中尽量多的保留有效的交叉特征,去除无效的交叉特征。让我们谨记,所有构建高阶交叉特征的模型必然要引入特定的“压缩”机制,在学习建模高阶交叉特征的模型时我们脑中要始终绷紧一根弦,那就是这种压缩机制是如何实现的?这种压缩机制的效率和效果如何?
解决维数灾难挑战, Deep & Cross Network(DCN) 模型交出一份让人比较满意的答卷,让我们来看看它是如何做到的。
DCN 模型以一个嵌入和堆叠层(embedding and stacking layer)开始,接着并列连一个cross network和一个deep network,接着通过一个combination layer将两个network的输出进行组合。交叉网络(cross network)的核心思想是以有效的方式应用显式特征交叉。交叉网络由交叉层组成,每个层具有以下公式:

其中:
 是列向量(column vectors),分别表示来自第
是列向量(column vectors),分别表示来自第
 层和第(
层和第(
 )层cross layers的输出;
)层cross layers的输出;
 是第
是第
 层layer的weight和bias参数。
层layer的weight和bias参数。
在完成一个特征交叉f后,每个cross layer会将它的输入加回去,对应的mapping function
 ,刚好等于残差
,刚好等于残差
 ,这里借鉴了残差网络的思想。
,这里借鉴了残差网络的思想。
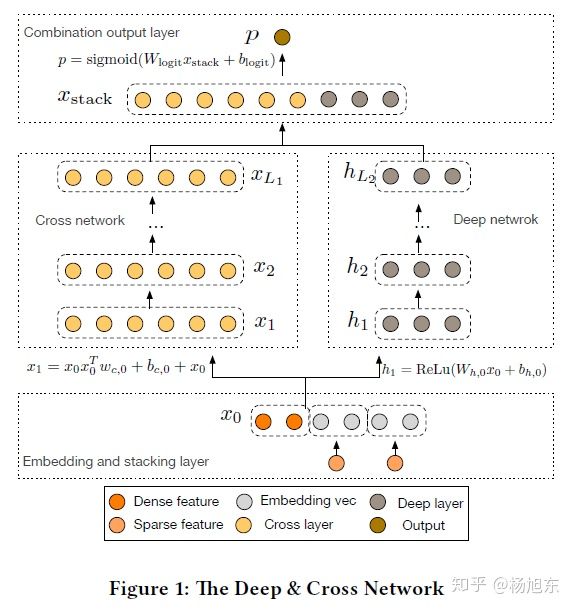
图2. DCN网络结构
特征的高阶交叉(high-degree interaction):cross network的独特结构使得交叉特征的阶(the degress of cross features)随着layer的深度而增长。对于第l层layer,它的最高多项式阶(在输入
 上)是
上)是
 。 实际上,cross network由这些交叉项
。 实际上,cross network由这些交叉项
 组成,对应的阶从1到
组成,对应的阶从1到
 。
。
组成,对应的阶从1到
 。
。
复杂度分析:假设
 表示cross layers的数目,
表示cross layers的数目,
 表示输入
表示输入
 的维度。那么,在该cross network中涉及的参数数目为:
的维度。那么,在该cross network中涉及的参数数目为:
 。
。
一个cross network的时间和空间复杂度对于输入维度是线性关系。因而,比起它的deep部分,一个cross network引入的复杂度微不足道,DCN的整体复杂度与传统的DNN在同一水平线上。如此高效(efficiency)是受益于
 的rank-one特性(两个向量的叉积),它可以使我们生成所有的交叉项,无需计算或存储整个matrix。
的rank-one特性(两个向量的叉积),它可以使我们生成所有的交叉项,无需计算或存储整个matrix。
关于DCN模型的实现,有一个重要的技巧可以节省大量的内存空间和训练时间,就是在计算cross layer的时候需要利用矩阵乘法的结合律,优先计算
 ,而不是
,而不是
 ,这是因为
,这是因为
 的计算结果是一个标量,几乎不占用存储空间,具体请参考《 玩转企业级Deep&Cross Network模型你只差一步》。
的计算结果是一个标量,几乎不占用存储空间,具体请参考《 玩转企业级Deep&Cross Network模型你只差一步》。
关于DCN模型的实现,有一个重要的技巧可以节省大量的内存空间和训练时间,就是在计算cross layer的时候需要利用矩阵乘法的结合律,优先计算
 ,而不是
,而不是
 ,这是因为
,这是因为
 的计算结果是一个标量,几乎不占用存储空间,具体请参考《 玩转企业级Deep&Cross Network模型你只差一步》。
的计算结果是一个标量,几乎不占用存储空间,具体请参考《 玩转企业级Deep&Cross Network模型你只差一步》。
亲爱的读者们,你们脑中的那根弦还在吗?DCN是如何有效压缩高维特征空间的呢?其实,对于cross layer可以换一种理解方式:假设
 是一个cross layer的输入,cross layer首先构建
是一个cross layer的输入,cross layer首先构建
 个关于
个关于
 的pairwise交叉,接着以一种内存高效的方式将它们投影到维度
的pairwise交叉,接着以一种内存高效的方式将它们投影到维度
 上。如果采用全连接Layer那样直接投影的方式会带来3次方的开销。Cross layer提供了一种有效的解决方式,将开销减小到维度
上。如果采用全连接Layer那样直接投影的方式会带来3次方的开销。Cross layer提供了一种有效的解决方式,将开销减小到维度
 的量级上:考虑到
的量级上:考虑到
 等价于:
等价于:
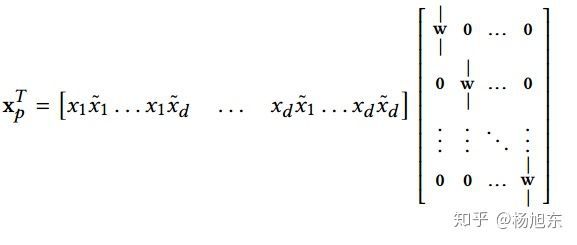
其中,行向量包含了所有
 个关于
个关于
 的pairwise交叉,投影矩阵具有一个块对角化结构,其中
的pairwise交叉,投影矩阵具有一个块对角化结构,其中
 是一个列向量。现在我们了解了DCN模型的“压缩”机制,即每个cross layer都把
是一个列向量。现在我们了解了DCN模型的“压缩”机制,即每个cross layer都把
 维度的特征空间投影到
维度的特征空间投影到
 维的空间上。
维的空间上。
DCN模型中使用的这种“压缩”机制是完美的吗,有没有什么局限性?实际上这种“压缩”方式把特征交互关系限定在一种特殊的形式上。我们再来看看cross layer的计算公式,为了简化,以便说明问题,下面去掉偏置项。

对于
 ,有如下公式:
,有如下公式:

合并可得到:

其中
 是一个关于
是一个关于
 的线性回归函数,也就是一个标量。
的线性回归函数,也就是一个标量。
根据数学归纳法,当
 时,上式成立;当
时,上式成立;当
 时,我们可以得到
时,我们可以得到

实际上,
 又是一个标量。因此Cross Network的输出就相当于
又是一个标量。因此Cross Network的输出就相当于
 不断乘以一个数,当然这个数是和
不断乘以一个数,当然这个数是和
 高度相关的。
高度相关的。
因此,我们可以总结出DCN模型的两个主要的不足:
- CrossNet的输出被限定在一种特殊的形式上
- 特征交叉还是以bit-wise的方式构建的
让我们回到最初的那个问题, 有没有可能引入更高阶的vector-wise的交叉特征,同时又能控制模型的复杂度,避免产生过多的无效交叉特征呢?
极深因子分解机模型(xDeepFM)
xDeepFM 模型是自动构建交叉特征且能够端到端学习的集大成者,它很好的回答了上一小节末提出的问题。让我们来看看它是如何做到的。
为了实现自动学习显式的高阶特征交互,同时使得交互发生在向量级上,xDeepFM首先提出了一种新的名为 压缩交互网络(Compressed Interaction Network,简称CIN)的模型。
CIN的输入是所有field的embedding向量构成的矩阵
 ,该矩阵的第
,该矩阵的第
 行对应第
行对应第
 个field的embedding向量,假设共有
个field的embedding向量,假设共有
 个field,每个field的embedding向量的维度为
个field,每个field的embedding向量的维度为
 。CIN网络也是一个多层的网络,它的第
。CIN网络也是一个多层的网络,它的第
 层的输出也是一个矩阵,记为
层的输出也是一个矩阵,记为
 ,该矩阵的行数为
,该矩阵的行数为
 ,表示第
,表示第
 层共有
层共有
 个特征(embedding)向量,其中
个特征(embedding)向量,其中
 。
。
CIN中第
 层的输出
层的输出
 由第
由第
 层的输出
层的输出
 和输入
和输入
 经过一个比较复杂的运算得到,具体地,矩阵
经过一个比较复杂的运算得到,具体地,矩阵
 中的第
中的第
 行的计算公式如下:
行的计算公式如下:

其中,
 表示哈达玛积,即两个矩阵或向量对应元素相乘得到相同大小的矩阵或向量,示例如:
表示哈达玛积,即两个矩阵或向量对应元素相乘得到相同大小的矩阵或向量,示例如:
 。
。
上述计算公式可能不是很好理解,论文作者给出了另一种更加方便理解的视角。在计算
 时,定义一个中间变量
时,定义一个中间变量
 ,
,
 是一个数据立方体,由D个数据矩阵堆叠而成,其中每个数据矩阵是由
是一个数据立方体,由D个数据矩阵堆叠而成,其中每个数据矩阵是由
 的一个列向量与
的一个列向量与
 的一个列向量的外积运算(Outer product)而得,如图3所示。
的一个列向量的外积运算(Outer product)而得,如图3所示。
 的生成过程实际上是由
的生成过程实际上是由
 与
与
 沿着各自embedding向量的方向计算外积的过程。
沿着各自embedding向量的方向计算外积的过程。
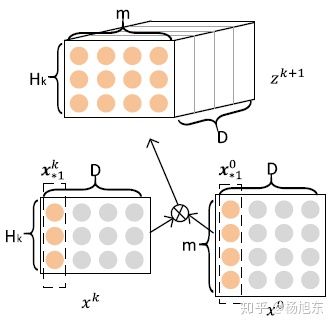
图3. CIN的隐层计算步骤一:根据前一层隐层状态和原始输入数据,计算中介结果
 可以被看作是一个宽度为
可以被看作是一个宽度为
 、高度为
、高度为
 、通道数为
、通道数为
 的图像,在这个虚拟的图像上施加一些卷积操作即得到
的图像,在这个虚拟的图像上施加一些卷积操作即得到
 。
。
 是其中一个卷积核,总共有
是其中一个卷积核,总共有
 个不同的卷积核,因而借用CNN网络中的概念,
个不同的卷积核,因而借用CNN网络中的概念,
 可以看作是由
可以看作是由
 个feature map堆叠而成,如图4所示。
个feature map堆叠而成,如图4所示。
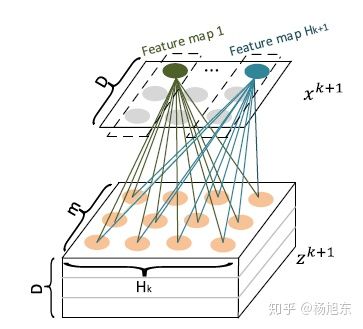
图4. CIN的隐层计算步骤二:根据中介结果,计算下一层隐层的状态
正是通过卷积操作,CIN把第
 层由
层由
 个向量压缩到了
个向量压缩到了
 个向量,起到了防止维数灾难的效果。
个向量,起到了防止维数灾难的效果。
CIN的宏观框架如下图所示,它的特点是,最终学习出的特征交互的阶数是由网络的�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%B1%E5%BA%A6%E9%A2%84%E4%BC%B0%E6%A8%A1%E5%9E%8B%E4%B8%AD%E7%9A%84%E7%89%B9%E5%BE%81%E8%87%AA%E5%8A%A8%E7%BB%84%E5%90%88%E6%9C%BA%E5%88%B6%E6%BC%94%E5%8C%96%E7%AE%80%E5%8F%B2/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


