深入理解推荐系统和
作为【推荐系统】系列文章的第四篇,将以推荐系统的“Fairness公平性”作为今天的主角,会从四个方面来介绍Fairness的相关问题、解决方案、相关比赛和参考文献。
有一段时间没有更新这个系列的文章,最近刚好没太多事情,Coggle也会加快更新推荐系统相关的文章,希望能给大家带来帮助。
一、Fairness相关问题
什么是推荐系统的公平性?
在一部分人正焦头烂额地为了推荐性能那百分之零点零几的准确率通宵达旦时,另一部分人决定换个方向,类比已知的存在于机器学习算法中性别偏见、种族歧视等不公平问题,可以探索推荐系统中同样存在这样的不公平问题。这仍是一个比较新的话题,还有很多的坑需要填。
如同没有绝对的正义,也没有绝对的公平。所谓的公平,只是站在不同的角度罢了。事实上,读过几篇文章后,你会觉得大部分作者都在描述自己提出的公平,可能是定义推荐结果中的各类物品比例与用户历史记录中的一致,也可能是提升不流行物品的曝光率,等等。一句话概况就是,“言之有理即可”。他们都坚持着自己认定的公平,并为达到这个目标提出自己的算法,或者只是单纯地分析现存算法有多违背自己的公平。
具体问题及解决方案
(1)Demographic parity/Population imbalance
描述: 用户不应因为自身的性别、年龄、种族等特征而接收到不同的推荐结果:追求这种公平性显然会影响推荐系统的准确度,但在诸如工作信息推荐之类的场景中有一定必要。
解决方案: 对数据进行加权或对输出进行约束,本质上不是技术问题,而是出于政治正确和平台长期利益的策略选择。
(2)Multiside fairness
描述: 推荐系统不仅仅是服务于用户,为用户推荐可能喜欢的物品,也要考虑到物品(本质上是其背后提供者)以及平台自身的利益,以求实现三方共赢。顾名思义,就是同时考虑用户方、物品方甚至平台方等多个从推荐中获利的角色。比如招聘网站上,求职者方的公平可能定义为:相同的学历、能力可以被推荐类似的工作,而不受国籍、种族等偏见;招聘方(在网站上投放招聘信息的公司等)的公平可能定义为:系统可以将他们的招聘信息推给优质的求职者,而不会因为公司的背景等因素,只将招聘信息推给不太合适的求职者;招聘网站(推荐系统)需要促成更多的交易,从中获利(广告费等),否则,求职者、招聘者就会去别的招聘网站。在电商场景下亦是如此,读者可自行分析。当然实际情况更加复杂,还要考虑很多因素,比如某些物品是收取过高昂的推广费的,在推荐的时候应该给这样的物品更多的曝光率,同时也要尽量降低给用户带来的不好体验。在之后的文章中会结合论文详细介绍。
解决方案:
- 采取多方面的评价指标,但评价指标只限于事后人为的观察与评估,可以指导对推荐系统的手动调整,但并没有直接改变推荐机制本身;
- 准确恰当地定义多方面的优化目标,并采用多目标优化方法,优化目标的设定和多目标优化两大问题难度都比较高。
(3)Position bias
描述: ranking中的每个对象受到的关注会受到展现位置的影响,位置靠前的物品比位置靠后的物品更容易被用户注意到,也更容易获得点击,从而使模型对用户偏好的感知出现偏差,预估CTR不准,并进一步通过feedback loop造成马太效应。
解决方案:
- 随机呈现推荐结果,获取数据计算position bias,作为修正项参与训练和serve;
- 选择一种Click Model建模用户行为,使用足够的数据估计出Click Model的参数,再将该Click Model应用到整个推荐模型中;
- 将position特征加入训练数据,线上serve时该特征统一置为某一定值;
- 单独用一个子网络建模position bias,线上serve时关闭该部分;
实践工作中的解决方案
item在展示列表中的位置,对item的点击概率和下单概率是有非常大影响的,排名越靠前的item,越容易被点击和下单,这就是Position Bias的含义。
在抽取特征和训练模型的时候,就需要去除这种Position Bias,具体是在两个地方做这种处理:
- 是在计算item的历史CTR(i_CTR_real)的时候,根据某种假设进行去除position bias。一个常见的假设是,把表现CTR(i_CTR)看成是真实CTR(i_CTR_real)和位置效应的乘积,而位置效应用所有item在某个位置p的CTR的平均值进行表示。
- 是在产生训练样本的时候,把展示位置作为特征放在样本里面,并且在使用模型的时候,把展示位置特征设置一个统一置的值,比如0。
(4)Exposure bias/Observation bias
描述: 用户看到的只是曝光出来的物品,这些物品才可能有用户行为,而未曝光或曝光次数少的物品由于缺乏用户行为数据,更加得不到曝光机会,造成恶性循环。
解决方案:
- 数据平滑,如贝叶斯平滑、威尔逊置信区间平滑等
- 采样Exploit与Exploration的方法
- 引入与用户行为无关的物品特征
- Calibrated Recommendation,采用贪心法求解最终推荐列表,使推荐列表中的物品类别分布与训练数据中接近,而非被曝光多的类别完全占据
- 将fairness-quality tradeoff转化为线性规划问题来求解
(5)Selection bias
描述: 用户看到的物品时推荐系统挑选出来呈现给用户的,而这个选择物品的过程并不是随机采样,因而用户看到的物品的分布和潜在的用户可能感兴趣的物品的分布不一致。(与Exposure bias的关系:Exposure Bias强调曝光物品数量少,只是一部分,Selection bias强调选择曝光物品过程有偏差;与Position bias的关系:Position bias关注的是已曝光的物品,Selection bias还考虑完全未曝光的物品)。
解决方案: 基于IPS加权,构造无偏的loss函数进行学习。推荐系统中的Propensity Score在不同paper中定义不一致,而且该方法本质上是从历史数据中统计得到IPS,再对loss函数进行修正,在数据分布变化较快的场景中,很可能无法及时对变化作出反应。
(6)Algorithmic confounding bias
描述: 推荐算法的训练数据本身是受推荐算法自身影响的,如果不考虑这一因素,推荐算法可能越来越偏,结果范围越来越窄。
解决方案: 论文中只通过实验说明了Algorithmic confounding bias会影响推荐结果的效用,并未提出具体解决方案。


(7)Popularity bias(流行度偏差)
描述: 被推荐物品的全局热度会影响其排序,导致推荐系统可能向用户推荐最热门而非最相关的物品。这样对不流行物品的不公平,不流行物品可以类比为新开的店铺,所卖物品也许质量很好,却迟迟得不到推荐系统的推荐,让店家不得不选择别的平台。其次是对于推荐平台也是不利的,提高不流行物品的曝光率,一方面可以为用户得到更多的选择,提高推荐列表的多样性,让推荐系统更好地实现个性化,另一方面可以吸引更多新的店家,扩大平台规模。反之,推荐结果如果包含大量的流行物品,结果趋同,用户得不到好的个性化体验,而且这些流行物品可能并不需要推荐系统就能被用户发现,其实也是一种资源的浪费。
解决方案: 基于热门程度对训练数据进行赋权,对过于热门的物品进行降权,对长尾物品进行提权,以保障冷门物品也有一定的曝光机会。本质上是对推荐过程的人工干预,具体的权重设定与调整机制有赖于大量的分析和实验。
总的来看,推荐系统中的bias有两大来源:输入数据与推荐机制。在有些问题上,这两者是同时存在的。这也就意味着,要进行debias,我们可以采取干预数据与改进推荐机制两种路径。干预数据的目的是为了获取无偏或者接近无偏的数据,例如对于position bias问题,最简单的干预数据方法就是在推荐时展示完全随机化的结果,使得用户点击行为排除结果相关性的影响,仅仅与position有关,以此获取需要的数据。还有在训练时对数据进行各种加权处理的,也可以归入干预数据这一方法。但是,在很多场景下,我们无法获得无偏的数据,那么就只能从改进推荐机制入手,显式建模相应的bias或者对推荐结果施加debias约束。
二、相关比赛
在很多推荐系统相关的比赛中,也会考虑到Fairness进行最终的结果评估。
1. KDD Cup 2020 Challenges for Modern E-Commerce Platform: Debiasing
本赛题的重点是如何推荐过去很少曝光的物品,以对抗推荐系统中经常遇到的马太效应。尤其是,在对点击数据进行训练时,减少偏差(bias)对于该任务的成功至关重要。就像现代推荐系统中记录的点击数据和实际在线环境之间存在差距一样,训练数据和测试数据之间也会存在差距,主要是关于趋势和项目的受欢迎程度。
2. CIKM 2019 EComm AI:超大规模推荐之用户兴趣高效检索
**
 **
**
在复赛阶段需要考虑,在推荐的用户兴趣集合中,不能出现用户历史交互过的商品。
**3. CIKM 2019 EComm AI:用户行为预测 **
在复赛中,测试集序列不包含任何用户历史行为商品,提高了对推荐策略发现性的要求。
三、参考文献
1. Multisided Fairness for Recommendation. Burke, Robin. 2017
有多个利益相关方时的fairness,一般为三方的利益,分别为Customer-fairness、Provider-fairness和CP-fairness。
Customer-fairness: 将用户映射到prototype space,其中每个prototype对受保护群体在统计上具有fairness。
Provider-fairness: 一般采用多目标优化方法来保障推荐结果的多样性,但实际上多样性与覆盖率有差异,后者更符合provider-fairness的目标。一个可以考虑的方向是借鉴RTB广告的方式,采用合理的预算分配策略来实现provider-fairness。
CP-fairness: 可以将上述两方面的方法结合使用
2. Beyond Parity: Fairness Objectives for Collaborative Filtering. Yao, Sirui,Huang, Bert. 2017
对于Demographic parity问题,现有方法主要通过去掉可能导致bias的feature或者在loss中加入约束项来取得fairness,但直接去掉部分feature会影响准确率,同时也无法完全消除bias,正则项如果设计得不好会严重影响算法表现。
本文发现,推荐系统中有两种来自underrepresentation的unfair:population imbalance和observation bias,前者源于不同类别用户在数据集中出现频率的差异,会使不同类别用户接收到的推荐结果有差异,后者源于推荐机制导致的feedback loop,会使推荐系统产生马太效应。
基于以上分析,本文提出了四个新的fairness metrics:value unfairness,absolute unfairness,underestimation unfairness,overestimation unfairness,可以作为约束项加入loss中。
3. Balanced Neighborhoods for Multi-sided Fairness in Recommendation. 2018
推荐系统的fairness和personality本质上隐含着冲突;推荐系统除了为用户推荐可能喜欢的物品,还涉及多方利益(customer/provider)。现有的推荐技术,如CF,基于相似用户群体进行推荐,更强化了不同用户群体间的差异。因此,本文提出Balancced Neighborhood,意图使受保护群体与其他群体在neighborhood中分布均衡。为了高效地实现这一目标,作者借鉴已有的SLIM算法并进行了改进。
4. Fairness of Exposure in Rankings. Singh, Ashudeep,Joachims, Thorsten. 2018
推荐系统不仅要对用户负责,也要对被推荐的物品负责。本文从曝光分配公平性的角度入手,通过一系列定义和推导将问题转化为线性规划,建立了一个在公平性限制下ranking问题的分析和求解框架。
5. Equity of Attention:Amortizing Individual Fairness in Rankings. Biega, Asia J,Gummadi, Krishna P,Weikum, Gerhard. 2018
用户对ranking结果的关注度严重受position bias的影响。与其他关于position bias的研究不同,本文意图使ranking结果受到的关注度与其相关性成正比。在具体的单次推荐中,这实际上是无法做到的,因为用户对推荐结果的关注无法不受位置的影响。因此,本文转而关注一系列ranking过程,试图实现均摊意义上的公平,这就是本文提出的amortized fairness(均摊公平性)。
本文对fairness的思考受到了individual fairness概念的启发,其强调相似的个体应受到相似的对待,而在ranking问题背景下,相关性可以作为“相似”的定义。同时,ranking影响着人们的生活,因此ranking并不是终点,而是一种分配资源的手段,而用户的注意力正是一种需要公平分配资源。
本文所提出的技术方案是将fairness-quality tradeoff转化为整数线性规划问题进行求解。
6. Calibrated Recommendations(校准化推荐)2018.
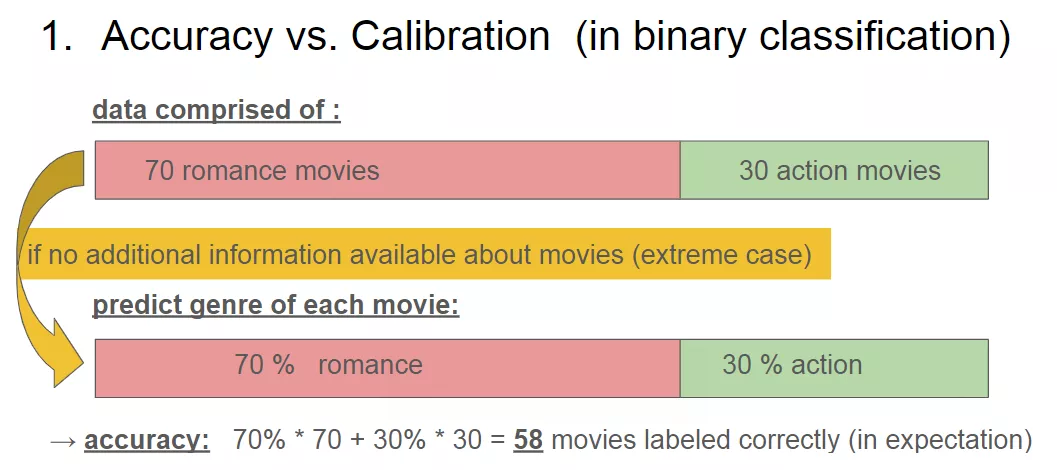
你是否有过这样的经历:某天在淘宝搜索了一样东西后,接下了一段时间的推荐都是关于这个物品的,哪怕你已经购买了这个物品或者你只是简单地搜来瞧瞧;在抖音上给某些视频点了赞,后面抖音会疯狂推荐这类视频给你,尽管你已经不想看这类视频了。
原因1: 从类别不平衡的分类问题角度来看。在类别不平衡的分类问题中,如果我们没有其他可用的信息,那么将结果全部预测为最多的那一类就可以得到最高的准确率。对于推荐来说,继续用上面的例子,如果我们没有别的可用信息,只知道佩琪购买的物品中75%都是裙子,那么我们只推荐裙子给她就可以得到最好的准确率。
原因2: 从模型训练的角度来看。以BPR训练为例,在训练过程中为每个用户采样正样本时,数量占比多的类别被采样到的概率更大,所以训练时这种偏差就刻入模型中了,但这本不是错,相反这恰恰是个性化推荐所需要的,但错在往往得到的推荐结果会过分放大这种偏差,而没有维持住原有的比例。
单纯追求accuracy(如ranking metrics)的推荐系统,产生的推荐结果容易集中在用户的主要兴趣(互动较多的物品)上,而忽略了用户的次要兴趣(互动较少的物品),这会造成恶性循环,使得用户的兴趣范围越来越窄。因此,作者提出Calibrated Recommendation,采用贪心思想生成推荐列表,意图使推荐结果中的物品类别分布与训练数据中接近,而非全部被主要类别占据。需要注意的是这一方法使listwise的,因此可能不便在ranking中使用,而是需
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E5%92%8C/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


