深入搜索引擎之必知必会一开发视角
腾讯音乐技术团队 yueqqzhang 稿
两句话了解它是什么
- 搜索引擎。提供了数据存储、数据处理、数据查询、聚合统计的能力。
- 创始人说:“不要求你必须是一个数据科学家才能把它用好”
前言
Elasticsearch 是一个很有意思的产品,不同岗位的人,对它的关注维度区别比较大
主要可以分三个层面
- 开发
- 基本功能
- 底层工作原理
- 数据建模最佳实践
- 运维
- 容量规划
- 性能优化
- 问题诊断
- 滚动升级
- 搜索结果优化
- 查全率、查准率等指标
- 搜索与如何解决搜索的相似性问题
- 具体场景下的调优
对比传统数据库的区别主要在于
传统关系型数据库
- 事务性
- Join
- 精确匹配
Elasticsearch
- Schemaless
- 相关性
- 高性能 全文搜索
本文是系列第一篇,会大体讲述 Elasticsearch 的开发视角下的必知必会内容,从存储层设计,索引机制,分词查询的基本原理、到分布式架构设计,做一个整体梳理;后续会继续运维关注的部署、灾备等,以及查询结果优化方面的两块内容梳理
起源
Elasticsearch
Elasticsearch是一个基于Lucene库的搜索引擎。它提供了一个分布式、支持多租户的全文搜索引擎,具有HTTP Web接口和无模式JSON文档。Elasticsearch是用Java开发的,并在Apache许可证下作为开源软件发布。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。[5]根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。[维基百科]
Lucene
Lucene是一套用于全文检索和搜索的开放源码程序库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程序接口,能够做全文索引和搜索。Lucene是现在最受欢迎的免费Java信息检索程序库。[维基百科]
Lucene 是一个基于 Java 语言开发的搜索引擎类库,作者是 Doug Cutting - Wikipedia 同时也是 Hadoop 之父,
Lucent 有一些局限性如
- 只能基于 Java 开发
- 学习曲线陡峭
- 不支持水平扩展
于是在 Lucene 的基础上,诞生了 Elasticsearch
- 支持分布式,可水平扩展
- 降低全文检索的学习曲线,可以被任何编程语言调用
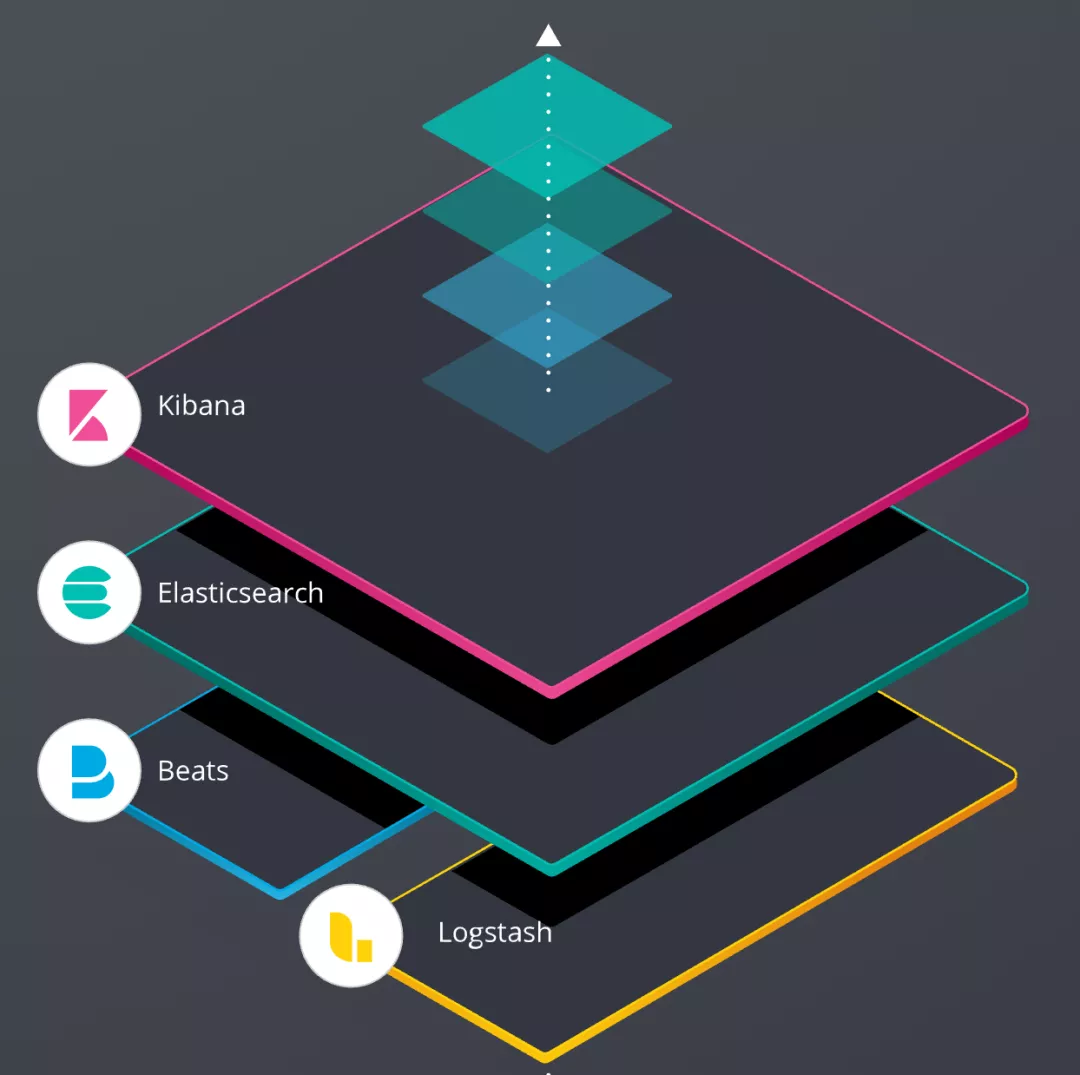
Elastic Stack 生态
基本概念
作为一个数据库,先来看看 ES 的存储设计,有以下几个概念:
- Index,是文档的容器,是一类文档的集合
- Type,现在已经已经废弃这一层,7.0 开始每个索引只有一个 Type 且名字固定为
_doc - Document 文档(类比关系数据库的记录行)
不严谨地类比关系型数据库的概念如下图
RDBMSElasticsearchTableIndex(Type)RowDocumentColumnFieldSchemaMappingSQLQuery DSL
索引(Index)
Mapping,定义文档的 Schema,有两种定义方式
- Dynamic Mapping,动态化创建,即 ES 可以根据插入的文档数据自动推断字段类型
- 显式定义 Mapping
为了减少工作量和出错的次数,可以给出显式定义的一般建议操作流程
- 创建一个临时的 Index,写入样本数据
- 通过 Mapping API 查看该 Index 动态生成的 Mapping
- 修改后,使用该 Mapping 创建真正的 Index
- 删除临时 Index
ES 支持的 字段类型 也很丰富,比较重要的,区别于一般数据库的两类如下
- keyword,精确值,整体作为一个词组(Term)来存储和被查询
- text,全文本,会做分词操作
一些常见的 Mapping 字段属性
- index:控制字段是否需要索引
- index_options:四种级别,可以控制倒排索引记录的内容粒度
- docs,记录文档 ID(非 text 类型字段默认)
- freqs,记录文档 ID、词频
- positioins,记录文档 ID、词频、位置(text 类型字段默认)
- offsets,记录文档 ID、词频、位置、偏移量
能否修改字段类型呢?分两种情况
- 新增字段
- Dynamic=true 时,有新增字段的文档写入,Mapping 会被修改
- Dynamic=false 时,有新增字段的文档写入,Mapping 不会被修改;新增字段的文档无法被索引,但是数据还是会出现在 _source 中
- Dynamic=strict 时,文档写入失败
- 已存在字段,一旦已经有该字段的数据写入,就不再允许修改 Mapping
- Lucene 实现的倒排索引,一旦生成就不能再被修改
注意:索引一旦创建,如果希望改变字段类型,就必须 ReIndex
除定义数据结构的 Mapping 外,Index 还有另一个重要的熟悉 Setting,用户定义数据的分布式属性,如:分片数、副本数
索引的不同语义 名词:一个 Elasticsearch 集群中的许多索引 动词:把一个文档保存到 Elasticsearch 的过程(indexing),主要就是创建一个倒排索引的过程
文档(Document)
Elasticsearch 是面向文档的,文档是所有可搜索数据的最小单位
- 日志中的日志项
- 一本书、歌曲的信息
文档会被序列化为 JSON 保存
- JSON 对象由字段组成
- 每个字段都有字段类型(字符串、数值、布尔、日期、二进制、范围类型)
- 数据类型可以自动推算,也可以前期指定 Mapping
每个文档都有一个 Unique ID,字段名为 _id
- 自动生成
- 自行指定
文档的一部分元数据(基本字段)列举
- _index:文档所属的索引名
- _type:文档所属的类型名
- _id:文档唯一I
- _source:文档的原始 JSON 数据
- _all:整合所有字段内容到该字段,已经废弃
- _version:文档版本
- _score:相关性打分
- _seq_no:shard 级别单调递增,保证后写入的文档的序号大于先写入的文档的序号
ES 的分布式基本组成
首先为什么需要做分布式?
相比单机的 Lucene,分布式架构的好处主要有
- 可扩展,方便水平扩容,无论是数据维度还是计算资源维度
- 高可用性,部分节点挂了,集群还能提供服务
节点(Node)
节点就是一个 ES 的实例,本质上就是一个 Java 进程。一台机器上可以运行多个 ES 进程,单数生产环境一般建议一台机器上只运行一个 ES 实例
每个节点都有一个名字,也是一样可以通过配置文件或命令行参数指定
每个节点在启动后,会分配一个 UID,保存在 data 目录下
常见节点类型
-
Master Node & Master eligible Node 每个节点启动后,默认就是一个 Master eligible 节点(Raft 的 Follower),参与选主流程,成为 Master 节点(Raft 的 Leader);当第一个节点启动的时候,它会将自己选举成为 Master 节点
每个节点上都保存了集群状态,但只有 Master 节点才能修改集群状态信息(如创建索引、决定分片分布等)
集群状态(Cluster State),维护了一个集群中必要的信息
- 所有的节点信息
- 所有的索引和其相关的 Mapping 与 Setting 信息
- 分片的路由信息
-
Data Node & Coordinating Node
Data Node:可以保存数据的节点,负责保存分片数据。在数据扩展上起到至关重要的作用
Coordinating Node:负责接受 Client 的请求,将请求分发到合适的节点,最终把结果汇集到一起;每个节点默认都是一个 Coordinating Node
-
Hot & Warm Node 不同硬件配置的 Data Node,用来实现 Hot & Warm 架构,节省部署成本
-
Machine Learning Node 负责跑机器学习的 Job
-
Tribe Node(5.3 开始使用 Cross Cluster Search) 连接不同的 ES 集群,支持将多个集群当成一个集群来使用
配置节点类型的建议:
- 开发环境一个节点可以承担多种角色
- 生产环境中,应该设置单一角色(dedicated node)
分片(Shard)
主分片(Primary Shard),解决数据水平扩展问题
- 一个运行 Lucene 的实例
- 主分片数在索引创建时指定,后续不允许修改,除非 Reindex
副本分片(Replica Shard),解决数据高可用问题
- 是主分片的备份
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
分片的设定,容量规划考虑因素
- 分片数设置过小
- 后续增加节点无法实现水平扩展
- 单个分片数据量太大,实现数据重新分配耗时
- 分配数设置过大,7.0 开始,默认主分片为 1,解决了 over-sharding 的问题
- 影响搜索结果的相关性打分,影响统计结果的准确性
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能
集群(分片)的健康情况
- Green:主分片和副本分片都正常分配
- Yellow:主分片全部正常分配,有副本分片未能正常分配
- Red:有主分片未能分配
文档(Document)
文档需要能均匀地分布在所有分片上,充分利用硬件资源,避免部分机器繁忙,部分机器空闲
比较常见的路由算法
- 随机、Round Robin,查询效率是问题
- 维护文档到分片的映射关系,当数据量大的时候映射关系维护成本也大
- 根据规则实时计算,hash
ES 实际使用的路由算法: shard = hash(_routing) % number_of_primary_shards
routing 默认是文档 ID,也可以自行指定哈希字段
这个路由规则,也正是当 Index 创建后,主分片数,不能随意修改的根本原因
分片的内部原理
思考一些问题
在进一步了解分片的内部原理前,先思考一些问题:
- 为什么 ES 的搜索是近实时的(常说 1 秒后才能搜到)?
- 如何保证数据断电不丢失?
- 为什么删除文档,不会立即释放空间?
倒排索引不可变性
首先,需要了解 Lucene 的倒排索引采用不可变设计(Immutable Design),一旦生成,不可更改
不可变带来的好处如下
- 无需处理并发写文件问题,避免了锁带来的性能损耗
- 一旦读入内核的文件系统缓存,就留在那里,只要文件系统有足够的空间,大部分请求就会直接请求内存,而不是访问磁盘,提升性能
- 缓存容易生成和维护,数据可以被压缩
但不可变性带来的问题是,如果要让一个新的文档可以被搜索,需要重建整个索引
Lucene Index
在 Lucene 中,单个的倒排索引被称为 Segment。多个 Segment 汇总在一起,就被称为 Lucene 的 Index,也就是对应 ES 中的 Shard
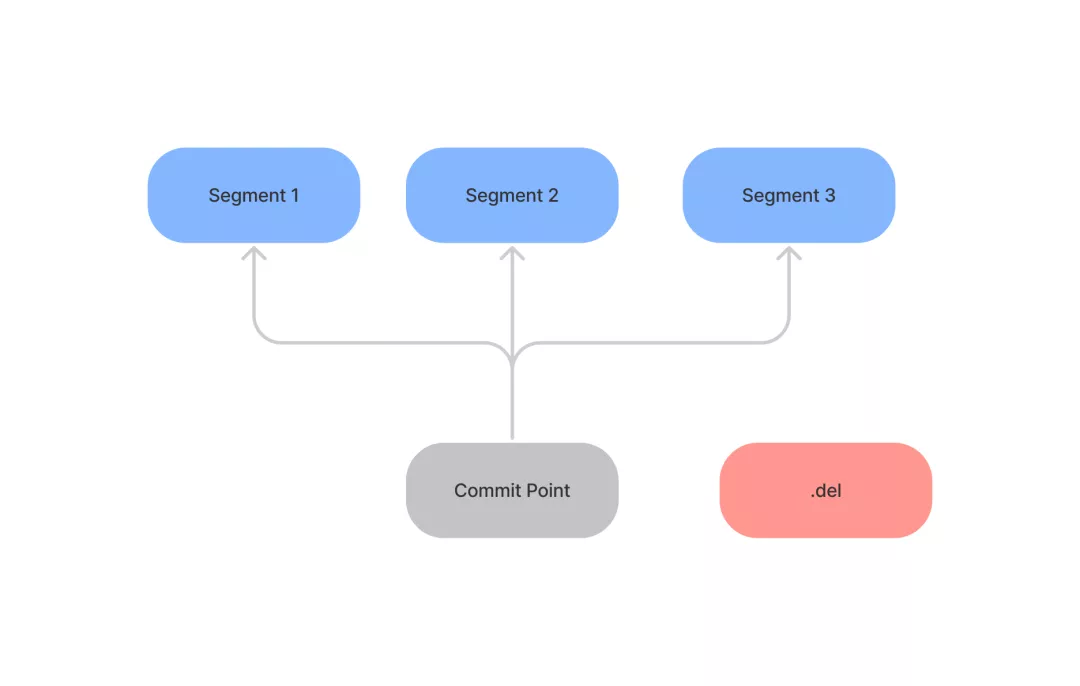
Lucene Index 中有一个 Commit Point,记录了所有 Segment 的信息,如果有新文档插入,则会生成新的 Segment;查询时会同时查询所有的 Segments,并对结果汇总
另一个文件 .del,记录了删除的文档信息;搜索的结果还会根据该文件中的内容,对结果进行过滤
数据入库过程(Indexing)
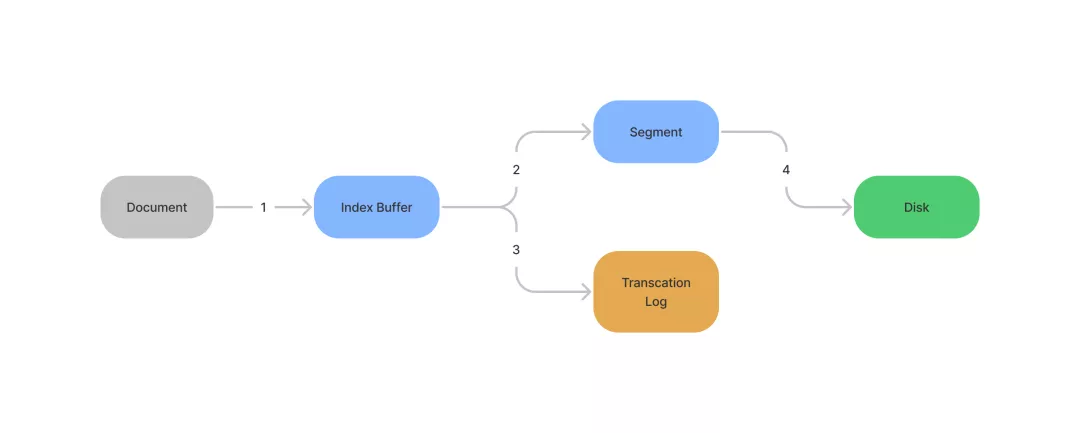
每当有新 Document 要写入时
- 文档会先写入 Index Buffer,作为缓冲区
- 将 Index Buffer 写入 Segment(内存),然后文档就可以被查询到了
- 将 Index Buffer 同时写入 Transcation Log(WAL 机制),用于断电恢复数据
- 将 Segments 落盘
其中第 2、3 两步合并成为 Refresh,默认 1 秒( index.refresh_interval)执行一次,这也就是为什么 ES 是近实时搜索引擎的原因(高版本的 ES 默认落盘);另外 Index Buffer 被写满时也会触发,默认大小是 JVM 内存的 10%
其中第 4 步,其实是归属于 Flush 操作的一个步骤。Flush 默认 30 分钟执行一次,或者 Transcation Log 满(默认 512MB)也会触发。Flush 执行包含的流程有
- 调用 Refresh
- 调用 fsync,将 Segements 落盘
- 清空 Transcation Log
但这里有个问题,按这个机制,在文档写入文档的情况下,默认每秒会产生至少一个 Segment,时间久了之后就会产生非常多的 Segment,此时需要进行 Segment 的合并操作,即 Merge 操作,该操作除了会合并多个 Segement 外,还会根据 .del 文件的内容,在合并的过程中实际删除已经标记删除的文档
ES 会自动执行 Merge 操作,如果需要人为触发,可以执行 POST index_name/_forcemerge
ES 的查询语言 Query DSL
ES 提供的查询接口是 HTTP 协议的,通用性很强,方便使用,主要有两种方式
- URI Search:URL 中直接填写查询参数,简单,适合简单场景
- Request Body Search:功能完整,ES 提供的 JSON 格式的一套 DSL
// 几种类型,可以选定不同的 index 范围
/_search
/index1/_search
/index1,index2/_search
/index*/_search
// 怎么填查询参数?查 name=John
/_search?q=name:John
// Request Body 的方式
curl -XPOST ""
-H "Content-Type: application/json" -d
{
"query": {
"match_all": {}
}
}
URL Search
URL 中直接填写查询参数
q:指定查询语句 df:默认字段,不指定时对所有字段进行查询 sort 排序,from、size 用于分页 profile 可以查看语句执行计划
Request Body
在 Request Body 里面写 JSON 格式的查询语句,语法是 ES 自己的一套 DSL,支持功能完整,项目中主要还是使用这种方式
{
"script_fields": {
"new_field": {
"script": {
"lang": "painless",
"source": "doc['order_date'].value+'_hello'" } }
},
"query": {
"match_all": {}
}
}
聚合搜索(Aggregation)
ES 除简单搜索外,还提供数据的聚合统计功能
- Bucket aggregations,一些列满足特定条件的文档的集合
- 分桶(男女)
- 嵌套(中国包含广东包含深圳)
- Metrics aggregations,一些数学运算,可以对文档字段进行统计分析;除了支持在字段上计算,也支持通过脚本(painless script)产生的结果上进行计算
- min
- max
- avg
- Pipeline aggregations,对其它的聚合结果进行二次聚合
- Matrix aggregations,支持对多个字段的操作并提供一个结果矩阵
正排索引和倒排索引
文档 ID文档内容1Mastering Elasticsearch2Elasticsearch Server3Elasticsearch EssentialsTermCountDocumentID:PositionElasticsearch31:1, 2:0, 3:0Mastering11:0Server12:1Essentials13:1
倒排索引的核心组成
- 单词词典(Term Dictionary),记录所有的单词,记录单词到倒排列表的关联关系(一般都比较大,常见实现算法见下图)
- 倒排列表(Posting List),记录了单词对应的文档集合,由倒排索引项组成
- 文档 ID
- 词频 TF - 该单词在文档中出现的次数,用于相关性打分
- 位置(Position) - 单词在文档中分词的位置,用于语句搜索(phrase query)
- 偏移(Offset) - 记录单词的开始结束位置,用于实现高亮显示
- 倒排索引项(Posting)
数据结构优缺点排序列表 Array/List二分法查找,不平衡HashMap/TreeMap高性能,内存消耗大Skip List跳表,可快速查找词语,在 Lucene、Redis、Hbase 等里都有实现Trie前缀树,适合英文词典,如果系统中存在大量字符串且基本没有公共前缀,则相应的 Trie 树将非常消耗内存Double Array Trie适合做中文词典,内存占用小,很多分词工具都采用Termary Search Tree三叉树,每个 Node 有 3 个节点,兼具查询快和节省内存的优点Finite State Transducers(FST)有限状态转移机,Lucene 4 有开源实现,并大量使用
ES 的 JSON 文档中的每个字段,都有自己的倒排索引 ,当然也可以指定对某些字段不做索引,节省存储空间,但也就自然而然不能搜索了
如 Elasticsearch 这个 Term 在前面文档列表里面,对应的倒排列表可能是
DocIDTFPositionOffset111<10, 23>310<0, 13>
分词
Analysis,文本分析,是把全文本转换成一系列单词(term/token)的过程,也叫分词
Analysis 是通过 Analyzer 分词器来实现的,ES 内置多种分词器,也可以按需定制分词器
除了数据入库的时候需要分词,查询语句也需要用相同的分词器对查询语句进行分析
分词器(Analyzer)
分词器主要由三部分组成
- Character Filters(针对原始文本处理,例如去除 HTML、正则替换等)
- Tokenizer(按照规切分为单词)
- Token Filters(将切分的单词进行加工,如大小写转换,删除 stopwords,增加同义词等)
ES 的内置分词器
// 直接指定分词器进行测试
Get /_analyze
{
"analyzer": "standard",
"text": "Mastering Elasticsearch, elasticsearch in Action"
}
// 指定索引的字段进行测试
POST books/_analyze
{
"field": "title",
"text", "Mastering Elasticsearch"
}
// 自定义分词器进行测试
POST /_analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": "Mastering Elasticsearch"
}
中文分词
中文句子要切分成一个个词(不是一个个字) 英文中,单词有自然的空格作为分隔 一句中文,在不同的上下文,有不同理解(这个苹果,不大好吃/这个苹果,不大,好吃;全民,k歌/全民k歌)
ICU Analyzer,提供了 Unicode 的支持,更好地支持亚洲语言
安装插件: Elasticsearch-plugin install analysis-icu
更多的中文分词器
- IK:支持自定义词库,支持热更新分词字典
- THULAC:THU Lexical Analyzer for Chinese,清华大学自然语言处理和社会人文计算实验室的一套中文分词器
深入搜索
基于词项(Term)
Term 是表达语义的最小单位
Term Level Query
- Term Query
- Range Query
- Exists Query
- Prefix Query
- Wildcard Query
在 ES 中,Term 查询,对输入 不做分词 ,会将输入作为一个整体,在倒排索引中查询准确的词项,并使用相关度打分公式为每个包含该词项的文档进行 相关性打分
可以用 Constant Score Query 将查询转换为一个 Filtering,避免打分,利用缓存提高性能
基于全文(Text)的搜索
查询的时候,会对输入的查询进行分词,生成一个供查询的词项列表,然后每个词项进行底层查询,最终将结果合并,并给每个文档生成一个相似度打分
- Match Query
- Match Phrase Query
- Query String Query
对应的,在数据入库 Index 阶段,如果字段类型是 text 则会分词,keyword 类型不会分词
结构化搜索
结构化搜索(Structured search)是指对结构化数据的搜索
结构化数据顾名思义也就是遵循严格定义的结构的数据
- 时间、日期、数字这类有精确格式的数据,可以对这类数据进行逻辑操作,如判断范围、比较大小等
- 结构化文本,可以做精确匹配或部分匹配
结构化结果只有“是”和“否”两个值,根据场景的需要,一样可以控制结构化结果是否需要打分
相关性(Relevance)和相关性打分
用户关心的几类问题
- 是否可以找到所有相关的内容
- 有多少不相关的内容被返回了
- 文档的打分是否合理
- 结合业务需求,调整结果排名
衡量相关性 Information Retrieval
- Precision(查准率):尽可能返回较少的无关文档
- Recall(查全率):尽量返回较多的相关文档
- Ranking:是否能按照相关度进行排序
- True Positive(正确接受)
- False Positive(错误接受)
- True Negatives(正确拒绝)
- False Negatives(错误拒绝)
Precision = TP / ALL
Recall = TP / (TP + FN)
调整 ES 查询参数,可以调优这两个参数
搜索的相关性打分,描述了一个 文档和查询语句匹配的程度 ,ES 会对每个匹配查询条件的结果进行打分 _score 打分的本质是排序,需要把最符合用户需求的文档排在最前面,ES 5 之前,默认的相关性打分算法是 TF-IDF,现在采用 BM 25
TF-IDF
词频 TF,Term Frequency,检索词在文档中出现的频率 本质上描述了两个简单的规则
- 某个词在一个文档中出现越多,越相关
- 整个文档集合中包含某个词的文档数量越少,这个词越重要

举例,输入查询“我的苹果”,我在文档 1 中出现,苹果在文档 1、2 中出现
TermDoc ID我1苹果1, 2
计算一个词的词频的简单方式可以是
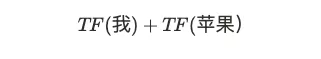
注意这里“的”是一个与语义无关的停用词,不应该考虑 TF(的) 的影响
文档频率 DF,Document Frequency,检索词在所有文档中出现的频率
- “我”在较多文档中出现
- “苹果“在较少文档中出现
逆文档频率 IDF,Inverse Document Frequency

TF-IDF 本质上就是把 TF 求和变成了加权求和
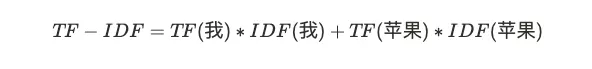
出现的文档数总文档数IDF我200 万10 亿log(500)=8.96苹果5 亿10 亿log(2)=1
TF-IDF 被公认为是信息检索领域最重要的发明 除了信息检索,在文献分类和其它相关领域有着非常广泛的应用 IDF 的概念,最早是剑桥大学的斯巴克·琼斯提出,1972 年 《关键词特殊性的统计解释和它在文献检索中的应用》,不过并没有从理论上解释为啥 IDF 是要用 log(全部文档数/检索词出现过的文档总数),也没有进行进一步研究 1970,1980 年代萨尔顿和罗宾逊,进行了进一步的证明和研究,并用香农信息论进行了证明 http://www.staff.city.ac.uk/~sbrp622/papers/foundations_bm25_review.pdf 现代搜索引擎,对 TF-IDF 进行了许多优化
Lucene 中的 TF-IDF
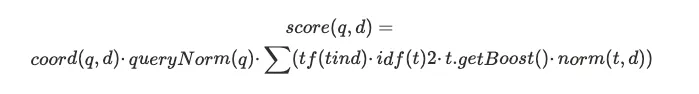
q:查询语句
d: 匹配的文档
t:分词后的词项
boost:权重提升,ES 查询时可以自行指定来改变 Boosting query
norm(t,d):文档越短,相关性越高
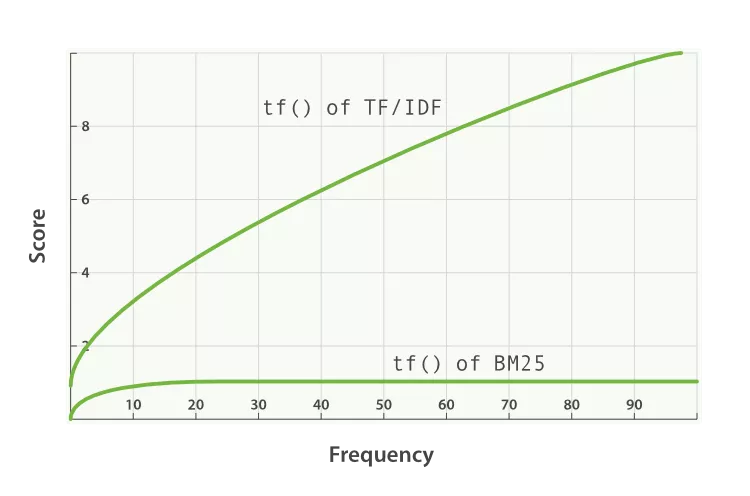
BM 25
BM 25,相比 TF-IDF,解决了一个问题:当 TF 无限增加时,BM 25 的算分会趋于一个固定值,而不是无限增长
官方文档参考链接: https://www.elastic.co/guide/cn/elasticsearch/guide/current/pluggable-similarites.html
多语言及中文分词检索
当处理自然语言时,有时候尽管搜索与原文不完全匹配,但是还是希望搜索到一些内容
一些可采取的优化
- 归一化词元:如搜索“大”的时候也会搜索“达”
- 抽取词根:清除单复数和时态的差异
- 包含同义词
- 拼写错误或同音异形词
混合多语言的挑战
- 词干提取:如以色列文档,包含了希伯来语,阿拉伯语,俄语和英语
- 不正确的文档频率:如英语为主的文档中,德语得分高(稀有)
- 需要判断用户搜索时使用的语言,语言识别
分词的挑战
英文分词:You’re 分成一个还是多个?Half-baked 要不要切分?
中文分词:
- 比英文分词更复杂,如姓和名,在哈工大标准中,姓名是分开的,但在 HanLP 标准下,姓和名是整体
- 歧义(组合型歧义,交集型歧义,真歧义)
- 中华人民共和国(中华+人民+共和国,中+华人+民+共和+国,…)
中文分词方法的演变
字典法(北京航空航天大学,梁元楠教授):一个句子从左到右扫描一遍,遇到有的词就标示出来;找到复合词,就找最长的;不认识的词就分割成单字词
最小词数的分词理论(哈尔滨工业大学,王晓龙博士)
- 一句话应该分成数量最少的词串
- 遇到二义性的分割,无能为力,多种文化规则来解决都不太成功
统计语言模型(清华大学郭进博士):解决了二义性问题,将中文分词的错误率降低了一个数量级,动态规划+维特比算法快速找到最佳分词
基于统计的机器学习算法:这类目前常用的算法是 HMM、CRF、SVM、深度学习等算法
中文分词器现状
中文分词器以统计语言模型为基础,经过几十年发展,到今天为止可以看做一个已经解决的问题
不同分词器的好坏,主要差别在于数据的使用和工程使用的精度
常见的分词器都是使用机器学习算法和词典结合,一方面能提高分词准确率,另一方面能改善领域适应性
ES 中提供的一些分词器
- HanLP:面向生产环境的自然语言处理工具包
- IK 分词器,支持词典热更新
- Pinyin 分词器,拼音
Search Template
Search Template,用于解耦程序和搜索 DSL
在开发初期就能明确查询参数,但最终的 DSL 结构无法确定,这时候可以通过 Search Template 定义一个 Contract,开发人员和搜索优化人员可以分头并行开发
Index Alias
Alias API,索引可以设置别名,实现零停机运维
Function Score Query 优化打分
ES 默认会以文档的相关度算法进行排序
Function Score Query 可以在查询结束后,对每个匹配的文档进行重新算分,根据新生成的得分进行排序
Function Score Query 提供了一些默认的打分函数
- Weight:设置权重
- Field Value Factor:使用该数值来修改得分,例如将“热度”和“点赞数”作为算分的参考因素
- Random Score:为每个用户使用一个不同的随机算分结果
- 衰减函数:以某个字段的值为标准,距离某个值越近,得分越高
- Script Score:写自定义脚本,控制逻辑
因为有了 Script Score, 可以做的事情就很多了,比如实现海明距离、余弦距离等算法,实现 对非文本类型数据的打分查询 ,比如指纹相似度、声纹相似度等
自动补全与基于上下文的提示
Complete Suggerster 提供了自动完成的功能,用户每输入一个字符,就需要即时发送一个查询请求到后端查询匹配项
对性能要求很苛刻,ES 采用了不同的数据结构,而非倒排索引来完成。ES 会将 Analyze 的数据编码成 FST 和索引一起存放,FST 会被 ES 整个加载进内存,速度很快
FST:Finite StateTransducers,有穷状态转换器
需要启用该特性的话,需要在创建 Mapping 时指定 "type": "completion"
另外还可以指定 context,来使用 suggerster 的基于上下文的提示
分布式搜索的运行机制
ES 的搜索有两个阶段
- Query
- Fetch
Query
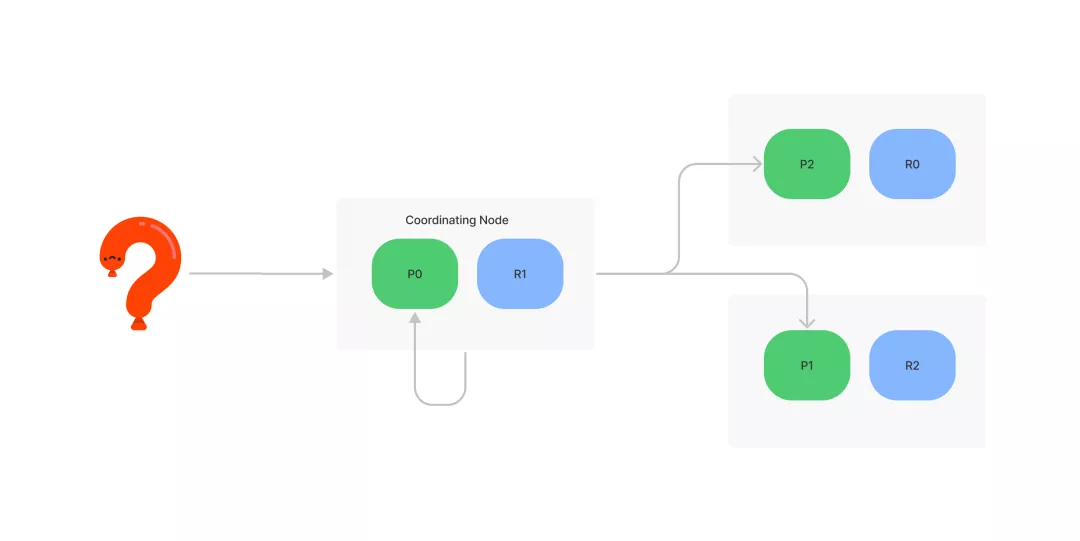
用户发出查询请求到达 Coordinating 节点(默认每个节点都是),节点会在所有主、副分片中随机出一个完整的数据分片列表组,然后将请求转发给它们,随后每个分片都会执行查询请求并 排序 ,然后每个分片都会返回 From+Size 个排序后的文档 ID 和排序值给 Coordinating 节点
Fetch
Coordinating 节点会将 Query 阶段,从每个分片获取的排序后的文档 ID 列表,进行合并排序,并选取合并后列表的 [From, From+Size) 文档的 ID 子列表;接下来再以 multi get 的请求方式,到相应的分配去获取详细的文档数据
Query Then Fetch 存在的问题
性能方面
- 每个分片上需要查的文档数 = From+Size
- 最终协调节点需要处理
分片数量 * (From+Size)这么多的文档 ID - 深度分页的时候,这里的性能问题会很严重
相关性打分方面
- 每个分片都是基于自己分片上的数据进行相关度计算,这可能会导致打分偏离的情况,特别是数据量很少的时候。相关性打分在分片之间是相互独立的。当文档总数很少的时候,主分片数越多,相关性打分会越不准
解决方案主要由两种
- 控制主分片数量
- 数据量不多的时候设置�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%B1%E5%85%A5%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E%E4%B9%8B%E5%BF%85%E7%9F%A5%E5%BF%85%E4%BC%9A%E4%B8%80%E5%BC%80%E5%8F%91%E8%A7%86%E8%A7%92/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


