淘宝搜索中语义向量检索技术
转载自 蘑菇先生学习记
今天带来一篇论文的分享,KDD'21的Applied Data Science Track中,淘宝搜索发表的一篇EBR文章[9]: Embedding-based Product Retrieval in Taobao Search 。论文要讨论的几大问题提前预览下:
- 搜索场景中,query如何 充分地进行语义表征 ?电商平台的query通常是短query,如何对有限长度的query进行充分的语义表征?
- 搜索场景中, 用户历史行为序列如何建模 ?如何防止 引入和当前query无关的历史行为 导致相关性问题?
- 搜索场景中,基于向量的检索系统(EBR)如何 保证相关性 ? EBR是基于向量的检索,不是完全匹配的检索,很容易检索到和当前query不相关的商品,那么该如何保证相关性?
下面按照 Motivation,Solution,Evaluation和Summarization 来介绍。
1. Motivation
研究对象 :电商平台的商品搜索引擎(product search engines)。
整体淘宝搜索系统包括四阶段 :match-prerank-rank-rerank,召回,粗排,精排,重排。本文重点在match。
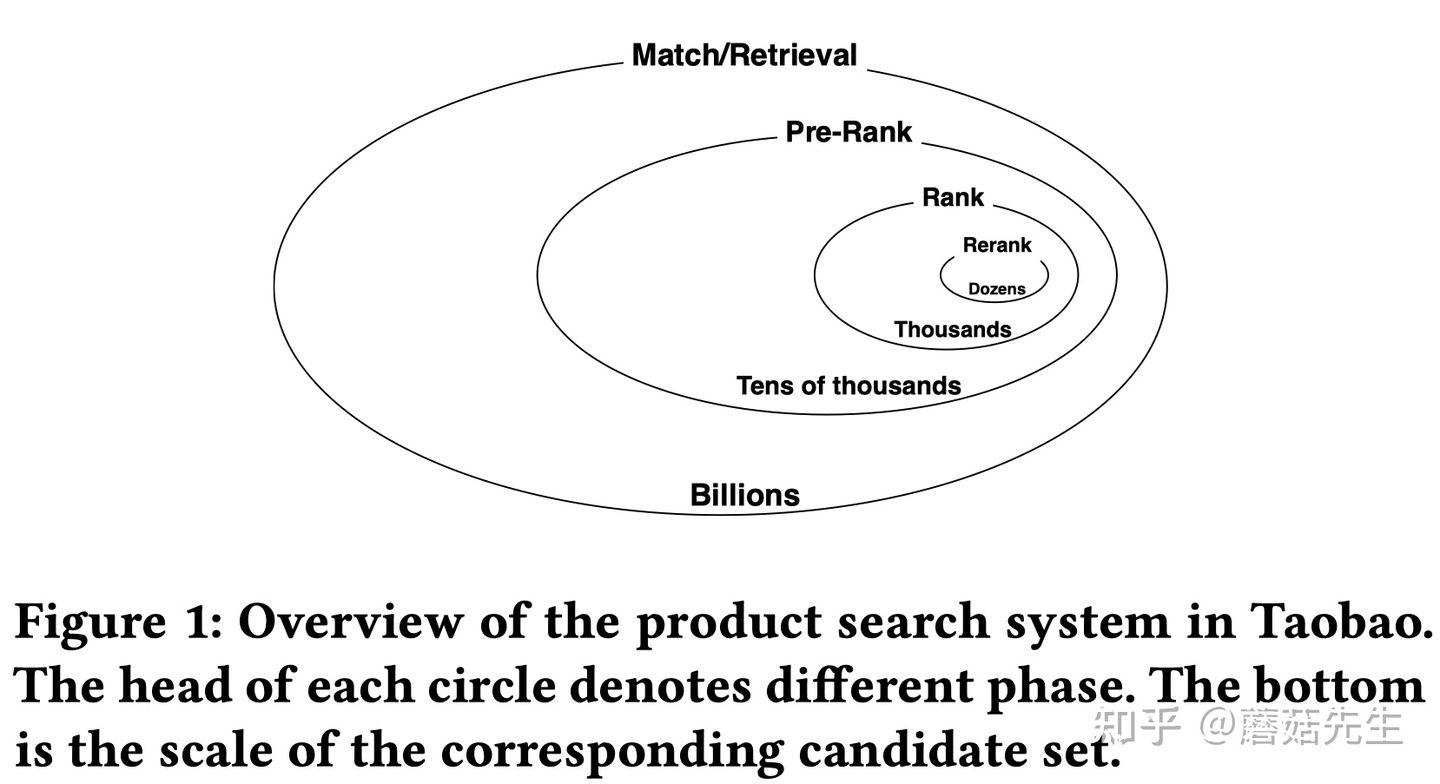 挑战 :电商平台的文本通常较短,没有语法结构,因此要考虑引入海量的用户历史行为。基于词匹配(lexical matching)的搜索引擎(倒排索引),性能好、可控性强,尽管存在一些语义鸿沟问题,但仍被广泛的应用在现有的搜索引擎架构中。但是,这种搜索引擎无法有效区分 相同query下 , 不同用户的 兴趣差异 ,无法捕捉用户 个性化 的特征。因此,如何 高效 地检索出【最相关】、【最能够满足用户需求】的 商品,权衡 【query语义】和【用户个性化历史行为】之间的关系,是电商平台主要的挑战。
挑战 :电商平台的文本通常较短,没有语法结构,因此要考虑引入海量的用户历史行为。基于词匹配(lexical matching)的搜索引擎(倒排索引),性能好、可控性强,尽管存在一些语义鸿沟问题,但仍被广泛的应用在现有的搜索引擎架构中。但是,这种搜索引擎无法有效区分 相同query下 , 不同用户的 兴趣差异 ,无法捕捉用户 个性化 的特征。因此,如何 高效 地检索出【最相关】、【最能够满足用户需求】的 商品,权衡 【query语义】和【用户个性化历史行为】之间的关系,是电商平台主要的挑战。
工业界经典的EBR系统文章有,
电商平台:
- [1]亚马逊:Priyanka Nigam, Yiwei Song, Vijai Mohan, Vihan Lakshman, Weitian Ding, Ankit Shingavi, Choon Hui Teo, Hao Gu, and Bing Yin. 2019. Semantic product search . In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2876–2885.
- [2]京东:Han Zhang, Songlin Wang, Kang Zhang, Zhiling Tang, Yunjiang Jiang, Yun Xiao, Weipeng Yan, and Wen-Yun Yang. 2020. Towards Personalized and Semantic Retrieval: An End-to-End Solution for E-commerce Search via Embedding Learning . arXiv preprint arXiv:2006.02282 (2020).
其它:
- [3] Facebook:Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano, and Linjun Yang. 2020. Embedding-based retrieval in facebook search . In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2553–2561.
- [4] 百度:Miao Fan, Jiacheng Guo, Shuai Zhu, Shuo Miao, Mingming Sun, and Ping Li. 2019. MOBIUS: towards the next generation of query-ad matching in baidu’s sponsored search . In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2509–2517.
- [5] Google:Tao Wu, Ellie Ka-In Chio, Heng-Tze Cheng, Yu Du, Steffen Rendle, Dima Kuzmin, Ritesh Agarwal, Li Zhang, John Anderson, Sarvjeet Singh, et al. 2020. Zero-Shot Heterogeneous Transfer Learning from Recommender Systems to Cold-Start Search Retrieval. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2821–2828.
作者指出上述大多数文章 避重就轻 ,只强调在指标上提升很多,却没有说明 向量召回会降低相关性 ,引入很多相关性的CASE。
作者也部署了向量检索系统在淘宝搜索中,观察了很长一段时间,有几个发现:
- 长短期效果差异 :短期效果很好;长期来看,基于embedding的方法由于不是词匹配,即:缺乏【 完整匹配 (exact match)】query所有terms的能力,很容易造成相关性BAD CASE。
- 相关性控制 :为了能够保证相关性,作者采用了一个相关性控制模块,来对检索到的商品做过滤。控制模块对EBR检索后的结果,做进一步的完整匹配过滤,只保留那些能够 完整匹配 结构化字段的商品,给到后续的排序阶段。作者统计了下,这几乎会过滤掉30%的商品,即:30%的商品相关性较低,被过滤的商品既耗费计算资源,又不能够参与到后续精排,导致本来可以进入后续排序的相关性商品无法进入排序,整体指标下降。
- 因此,本文的主要目标是期望基于向量的模型能够检索到 更多相关的商品 , 有更多相关的商品 能够参与到后续排序阶段中,从而在保证相关性的前提下,提高整个系统的线上指标。
这篇文章的核心贡献总结如下:
- 模型 :提出了一种 多粒度深度语义商品检索模型 (Multi-Grained Deep Semantic Product Retrieval (MGDSPR) Model),能够动态地捕捉用户搜索语义和个性化交互历史行为的关系,兼顾 语义 和 个性化 。
- 训练和推理的一致性 :为了保证训练和推理的一致性,使得模型具备全局比较能力,除了采用随机负采样策略外,作者还采用了softmax交叉熵损失函数,而不是hinge pairwise损失函数,因为后者只具备局部比较能力。
- 相关性保证 :提出了两种不需要额外训练过程,就能够保证检索出更多相关商品的方法。1.即: 在softmax基础上引入温度参数 ,对用户隐式反馈(点击数据)进行相关性噪声的平滑。2. 混合正样本和随机负样本 来产生" 相关性增强 “的困难负样本。进一步,作者采用了 相关性控制模块 来保证EBR系统的相关性。
- 实验和分析 :在真实的工业级数据上,阐明了MGDSPR的有效性。进一步分析了MGDSPR对 搜索系统每个阶段 的影响,介绍了应用向量检索在商品搜索过程中的宝贵经验。
2. Solution
问题形式化 :
 表示
表示
 个用户集合;
个用户集合;
 表示相应的queries,
表示相应的queries,
 表示
表示
 个物品的集合。同时,作者将用户
个物品的集合。同时,作者将用户
 的历史行为根据离当前的时间间隔划分为3个子集合,
的历史行为根据离当前的时间间隔划分为3个子集合,
- 实时行为序列 (当前时间戳前的若干行为):
 ;
; - 短期行为序列 (不包括在
 中的10天内的行为):
中的10天内的行为):

- 长期行为序列 (不包括在
 和
和
 中的1个月内的行为序列):
中的1个月内的行为序列):
 。
。
任务 :给定用户
 的历史行为序列
的历史行为序列
 ,在时间
,在时间
 发起了一次搜索请求
发起了一次搜索请求
 ,我们期望返回物品的集合
,我们期望返回物品的集合
 来满足该用户的搜索需求。具体而言,目标是基于用户
来满足该用户的搜索需求。具体而言,目标是基于用户
 和物品 items 之间的得分
和物品 items 之间的得分
 ,从
,从
 中预测出Top-
中预测出Top-
 候选物品。即:
候选物品。即:

其中,
 是打分函数,
是打分函数,
 是query/behaviors的编码器,
是query/behaviors的编码器,
 是item编码器。作者也是采用了双塔的召回模型,
是item编码器。作者也是采用了双塔的召回模型,
 用内积函数来表示。
用内积函数来表示。
先介绍下 整体的网络框架结构 :
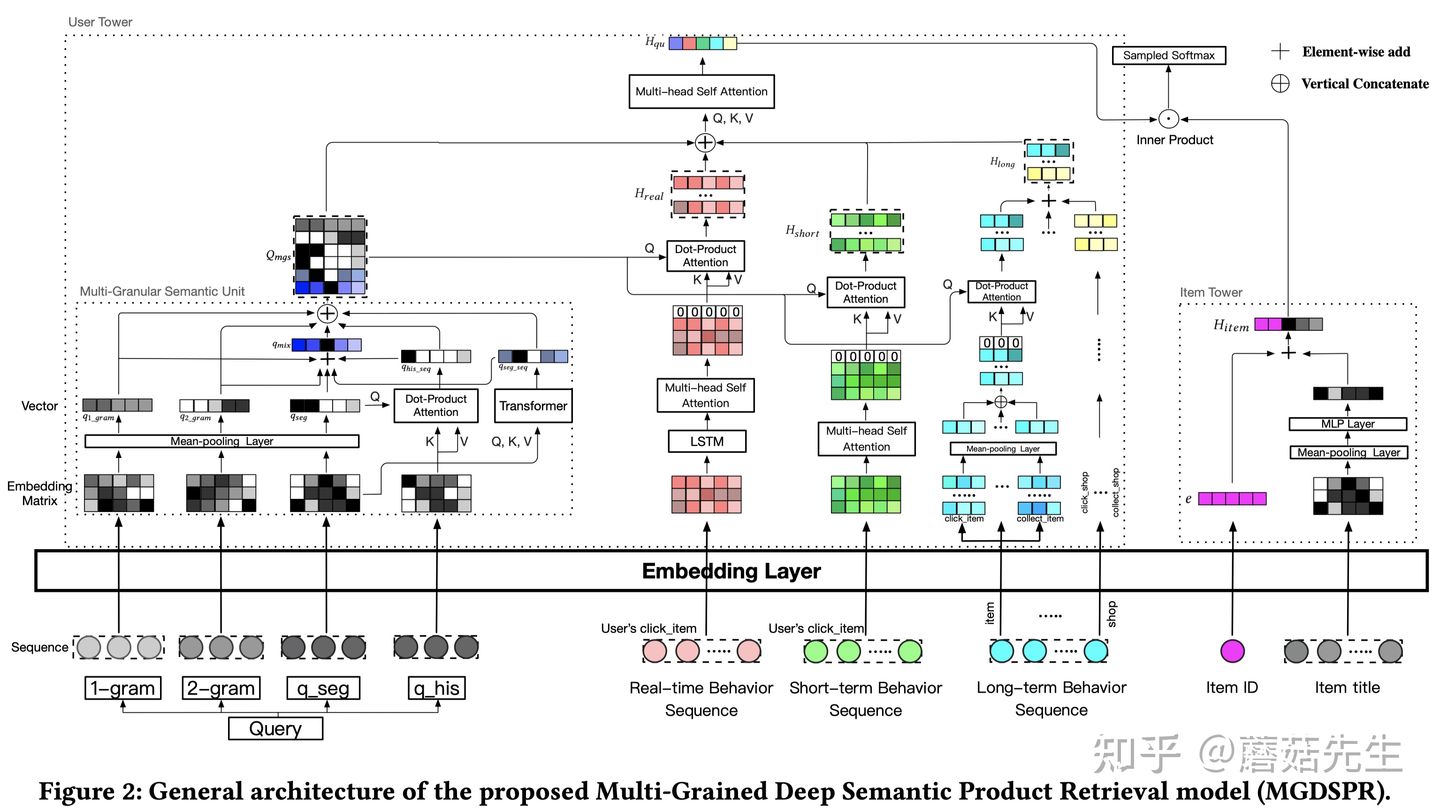 典型的 双塔结构 ,在user tower部分做的比较重,item tower部分做的比较轻量。user tower输出的用户表征向量和item tower输出的物品表征向量做点积得到预测值,再使用sampled softmax损失函数在全局item pool中进行优化。其中,
典型的 双塔结构 ,在user tower部分做的比较重,item tower部分做的比较轻量。user tower输出的用户表征向量和item tower输出的物品表征向量做点积得到预测值,再使用sampled softmax损失函数在全局item pool中进行优化。其中,
-
1. user tower 包含三个重量的部分,
- query语义表征;
- 用户实时、短期、长期历史行为序列个性化表征;
- 以及二者如何融合起来的组件。
分别对应图中user tower的左侧、中间和上半部分。
-
2. item tower 包含三个轻量的部分,
- item ID;
- item的辅助信息;
- 以及二者如何融合起来的组件。
-
3. 优化 :
- sampled softmax损失函数。
- 优化策略:温度参数对训练集进行噪声平滑、在embedding空间生成困难负样本。
下面将分别围绕上述三个部分user tower, item tower和优化方法展开,最后介绍系统架构。
2.1 User Tower
2.1.1 多粒度语义单元(Multi-Granular Semantic Unit)
淘宝搜索的query通常是中文。经过query分词后,每个分词结果的长度通常小于3。因此,作者提出了一种【 多粒度语义单元 】来多粒度地挖掘query语义。具体而言,输入:
- 当前query的 分词结果
 ,比如:{红色,连衣裙}
,比如:{红色,连衣裙} - 每个词
 又由 字构成 ,
又由 字构成 ,
 ,比如:{红,色}
,比如:{红,色} - 该用户的 历史搜索行为
 ,比如:{绿色,半身裙,黄色,长裙}
,比如:{绿色,半身裙,黄色,长裙}
其中,词:
 ,字:
,字:
 ,
,
 ,即:每个词、字、query整体的embedding维度数都设置为
,即:每个词、字、query整体的embedding维度数都设置为
 。可以获得如下6种粒度的表征,
。可以获得如下6种粒度的表征,
 ,
,
 unigram 单字粒度的表征做mean-pooling,
unigram 单字粒度的表征做mean-pooling,

 2-gram 的表征做mean-pooling,
2-gram 的表征做mean-pooling,

 分词粒度 的词的表征做mean-pooling,
分词粒度 的词的表征做mean-pooling,

 分词粒度的序列 ,用Transformer作为序列Encoder后,再对最后1层隐层向量做mean pooling,
分词粒度的序列 ,用Transformer作为序列Encoder后,再对最后1层隐层向量做mean pooling,

- 历史搜索词
 和当前搜索词的表征
和当前搜索词的表征
 做attention后,加权融合,
做attention后,加权融合,

- 混合表征 :上述5种表征向量相加得到,

最终,
 由上述6种拼接而成。具体计算公式如下:
由上述6种拼接而成。具体计算公式如下:
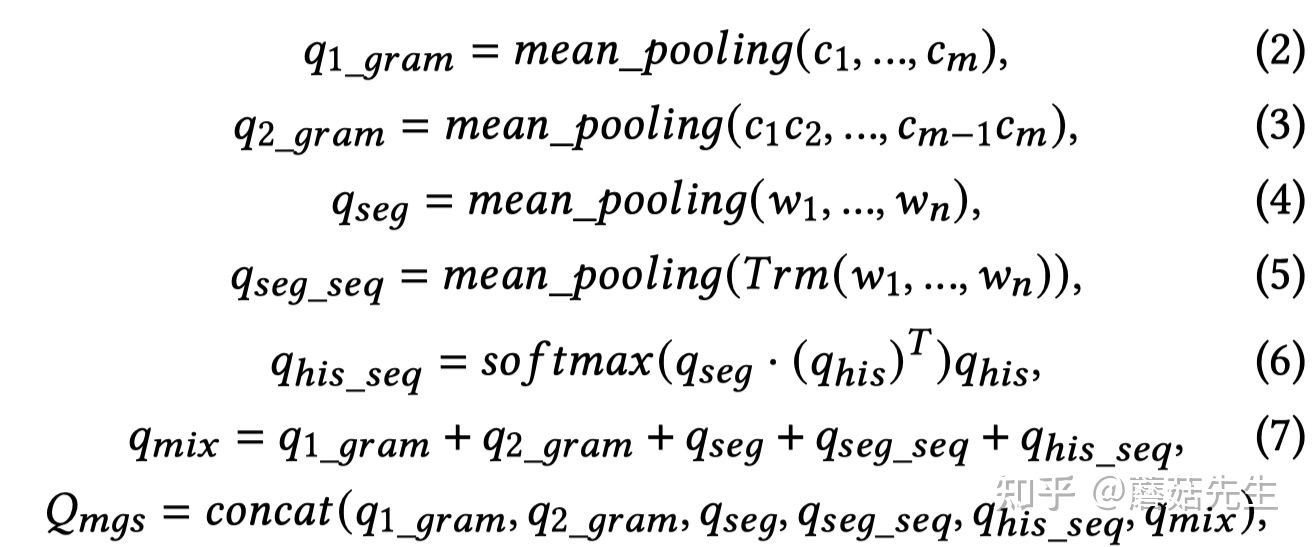 其中,
其中,
 即为Transformer,
即为Transformer,
 的计算同
的计算同
 。
。
可以看到,作者从两个方面来充分地对query进行语义表征, 由此可以回答开篇的第一个问题 ,query如何 充分地进行语义表征 ?
- query 字面上的组织方式多样 :字粒度,2-gram粒度,词粒度。
- query的 表征方法多样 :pooling,transformer,concat,addition等。
当然,只讲结果,没有讲为什么这么做。有点过于经验性/实验性驱动,而不是问题/动机驱动。
2.1.2 用户行为注意力机制(User Behaviors Attention)
用户行为包括:用户的 实时、短期或长期 的点击或者购买行为。用户
 在
在
 时刻点击item
时刻点击item
 ,用
,用
 来表示。对于物品
来表示。对于物品
 的表征向量,首先使用ID和side information(叶子类目、一级类目、品牌和所属店铺)做嵌入,然后对得到的嵌入向量 做pooling或者拼接在一起。
的表征向量,首先使用ID和side information(叶子类目、一级类目、品牌和所属店铺)做嵌入,然后对得到的嵌入向量 做pooling或者拼接在一起。
不同于广告和推荐场景中常用的 target-item注意力机制 (如DIN,DIEN等),此处使用query注意力机制来捕捉 用户历史行为 和 当前query 的 语义相关性 。目的是发现哪些 历史行为 和本次query 相关 ,来 丰富用户在当前query下的语义/意图表征 。比如:历史购买行为,篮球鞋、裙子,此次搜索query是红裙,显然篮球鞋历史行为(可能送人的)对此次query毫无帮助,直接引入还会带来噪声,而裙子历史行为对此次query是有帮助的。
具体而言,在搜索场景中,用户的 历史行为 和 当前query 可能 都无关 ,参考[6]的做法,作者加了一个 全零的向量 到用户的 行为数据 中,来消除 潜在噪声 和解决 用户历史行为和当前query可能完全无关 的情况。
个人认为这个优化点非常巧妙 ,如果不加全零向量,模型无论如何都会 强制关注到至少一个行为 ,这在历史行为 和当前query都无关 的时候,显然是噪声。加了零向量后, 在完全无关 的时候,模型 attend到这个零向量 即可, 不会引入额外的噪声 。个人认为这个优化点在搜索场景中至关重要,也是和推荐场景差别较大的地方,鲜有论文会提到这点。
接下来介绍如何融合用户的 实时行为、短期行为和长期行为。
-
实时点击行为序列 :
 ,其中,
,其中,
 是ID和辅助特征嵌入拼接在一起实现。
是ID和辅助特征嵌入拼接在一起实现。- 首先使用 LSTM 来捕捉用户行为的演变,得到LSTM的隐层输出,
 。
。 - 接着,参考 SDM [7]的做法,使用多头自注意力机制来从
 中汇聚多个潜在的兴趣点,得到
中汇聚多个潜在的兴趣点,得到
 。
。 - 接着,加一个全零的向量进去,得到:
 。
。 - 最后,使用注意力机制,来获取和
 最相关的实时历史行为表征,
最相关的实时历史行为表征,
 。
。
 ,注意这个向量的维度数,实际上等价于拿组成
,注意这个向量的维度数,实际上等价于拿组成
 的6个向量分别和实时行为做attention后,再拼接起来。
的6个向量分别和实时行为做attention后,再拼接起来。
- 首先使用 LSTM 来捕捉用户行为的演变,得到LSTM的隐层输出,
-
短期点击行为序列 :
 ,其中,
,其中,
 是ID和辅助特征嵌入拼接在一起实现。
是ID和辅助特征嵌入拼接在一起实现。和实时行为序列表征相比,少了第一步LSTM,其它都一样。
- 使用多头自注意力机制从
 中汇聚得到
中汇聚得到

- 同样,加一个全零的向量进去,得到:
 。
。 - 最后,使用注意力机制,来获取和
 最相关的短期历史行为表征,
最相关的短期历史行为表征,


- 使用多头自注意力机制从
-
长期点击/购买/收藏行为序列 :
 ,考虑到线上用户行为变化很快,
,考虑到线上用户行为变化很快,
 是ID和辅助特征嵌入做mean pooling得到,和实时行为、短期行为中用的” 拼接 “方式不同。
是ID和辅助特征嵌入做mean pooling得到,和实时行为、短期行为中用的” 拼接 “方式不同。除此之外,使用4种属性序列来描述1个月内用户的长期行为序列,包括:
- item ID序列(
 )
) - shop ID序列(
 )
) - 叶子节点类目ID(
 )
) - 品牌ID(
 )
)
- item ID序列(
每种属性行为使用用户的点击、购买、收藏行为来表示。例如:物品序列
 包含了用户的物品点击序列
包含了用户的物品点击序列
 ,购买序列
,购买序列
 和收藏序列
和收藏序列
 ,全部拼接在一起,形成长期行为序列,
,全部拼接在一起,形成长期行为序列,
 ,可以看到同样添加了零向量。则,使用query对长期行为应用注意力机制捕捉这种长期行为表征。
,可以看到同样添加了零向量。则,使用query对长期行为应用注意力机制捕捉这种长期行为表征。

同理,对shop ID序列、叶子节点类目ID序列、品牌ID序列执行上述过程得到长期行为表征,最终融合起来的长期行为表征向量为:

由此可以回答开篇的第二个问题 ,query注意力机制而非target-item注意力机制以及引入零向量,能够保证捕捉和query相关的历史行为信息。
2.1.3 语义表征和个性化行为表征融合 (Fusion of Semantics and Personalization)
输入:
- 多粒度query语义表征:

- 个性化序列表征:

使用自注意力机制来捕捉二者的关系。特别的,作者添加了
 token在首位,形成输入:
token在首位,形成输入:
 。
。
输出:
然后将self自注意力机制的输出作为user tower的表征,


 我理解是指用单头自注意力机制即可。
我理解是指用单头自注意力机制即可。
 模仿BERT中的结构,可学习的向量,浓缩信息。
模仿BERT中的结构,可学习的向量,浓缩信息。
2.2 Item Tower
根据作者的实验经验,使用Item ID和Item的Title来获得Item的表征
 。具体而言,给定item
。具体而言,给定item
 的ID,其嵌入为:
的ID,其嵌入为:
 。给定title的分词结果
。给定title的分词结果
 ,得到物品的表征,
,得到物品的表征,
 ,即:
,即:

其中,
 是可学习的变换矩阵。作者表示,通过实验发现,使用LSTM、Transformer等来捕捉title上下文感知的表征,其效果还不如上述简单的mean-pooling。给出的理由是:大部分的title由关键词堆叠而成,且缺乏语法结构。个人理解,可能想说字面上的语义信息足够凸显,上下文信号较弱,不需要复杂的模型来捕捉语义。
是可学习的变换矩阵。作者表示,通过实验发现,使用LSTM、Transformer等来捕捉title上下文感知的表征,其效果还不如上述简单的mean-pooling。给出的理由是:大部分的title由关键词堆叠而成,且缺乏语法结构。个人理解,可能想说字面上的语义信息足够凸显,上下文信号较弱,不需要复杂的模型来捕捉语义。
2.3 Loss Function
为了保证训练时的样本空间和在线推理时的样本空间一致,大部分工作会使用随机负采样的方法。但是这些工作都采用了pairwise hinge loss作为损失函数,只能进行局部的比较,和在线推理时需要的全局比较不一致。为此,作者使用了softmax交叉熵损失函数,具体而言,给定正样本
 ,
,


 是全部的item集合。实际上就是softmax交叉熵损失,然后因为
是全部的item集合。实际上就是softmax交叉熵损失,然后因为
 的数量很大,使用sampled softmax来优化即可。此处没有太大的创新点。在sampled softmax中,仍然需要负样本,参考[2]京东的做法,作者使用同一个batch内的其它样本作为当前正样本
的数量很大,使用sampled softmax来优化即可。此处没有太大的创新点。在sampled softmax中,仍然需要负样本,参考[2]京东的做法,作者使用同一个batch内的其它样本作为当前正样本
 的负样本对,这个效果和使用随机任意的样本作为负样本差不多,而前者还能省不少计算资源。
的负样本对,这个效果和使用随机任意的样本作为负样本差不多,而前者还能省不少计算资源。
接着,为了提高EBR系统的相关性,增加更多相关性的样本进入后续的排序阶段。作者提出了两种优化策略,
- 对训练集中的样本进行噪声平滑 :作者引入了温度参数
 。此处也没有什么太大的创新点。
。此处也没有什么太大的创新点。
 无穷小时,相当于拟合one-hot分布,无限拉大正样本和负样本之间的差距;
无穷小时,相当于拟合one-hot分布,无限拉大正样本和负样本之间的差距;
 无穷大时,相当于拟合均匀分布,无视正样本还是负样本。作者认为,训练集中用户的点击和购买行为包含有不少噪声数据,不仅受到query-product相关性的影响,也受到图片、价格、用户偏好等诸多因素的影响,即用户点击/购买的item不一定和query相关,如果一味地拟合点击/购买行为,可能会带来很多相关性问题,因此引入温度参数来平滑,温度参数参数越大,则平滑的作用越明显,让模型不去过分关注点击样本,也花点"心思"去关注没有点击但是可能是相关的样本。形如:
无穷大时,相当于拟合均匀分布,无视正样本还是负样本。作者认为,训练集中用户的点击和购买行为包含有不少噪声数据,不仅受到query-product相关性的影响,也受到图片、价格、用户偏好等诸多因素的影响,即用户点击/购买的item不一定和query相关,如果一味地拟合点击/购买行为,可能会带来很多相关性问题,因此引入温度参数来平滑,温度参数参数越大,则平滑的作用越明显,让模型不去过分关注点击样本,也花点"心思"去关注没有点击但是可能是相关的样本。形如:

-
生成相关性增强的困难负样本 :先前有些工作[8]会引入额外的人工标注数据来提升EBR模型的相关性。和这些工作不同,作者提出了一种在embedding空间自动生成困难负样本的方法。特别的,给定一个训练样本
 ,其中
,其中
 是随机负采样的item表征,
是随机负采样的item表征,
 是用户表征,
是用户表征,
 是正样本item的表征,为了得到困难负样本:
是正样本item的表征,为了得到困难负样本:使用
 去Item Pool中找到和其 点积最大 的top-N个负样本集合:
去Item Pool中找到和其 点积最大 的top-N个负样本集合:
 ,然后通过插值的方式,来混合正样本
,然后通过插值的方式,来混合正样本
 和困难负样本
和困难负样本
 ,即:
,即:

 ,形成N个困难负样本。其中,
,形成N个困难负样本。其中,
 是从均匀分布
是从均匀分布
 中采样到的,
中采样到的,
 ,显然,
,显然,
 越接近1,生成的样本越接近正样本,即:生成的样本越困难。把生成的样本也纳入损失函数的计算:
越接近1,生成的样本越接近正样本,即:生成的样本越困难。把生成的样本也纳入损失函数的计算:
 可以通过调参
可以通过调参
 和
和
 来控制负样本的"困难程度”。
来控制负样本的"困难程度”。
好奇的是,实现上如何高效地对
 和Item Pool中所有负样本计算top-N点积?难道也是拿当前batch中的样本来计算的?另外,万一top-N里头存在相关的会有影响吗?
和Item Pool中所有负样本计算top-N点积?难道也是拿当前batch中的样本来计算的?另外,万一top-N里头存在相关的会有影响吗?
由此可以回答开篇的第三个问题 ,通过引入温度参数进行噪声平滑以及生成困难负样本来保证EBR系统的相关性。
2.4 系统架构
最后,我们来欣赏下淘宝搜索引擎的系统架构。
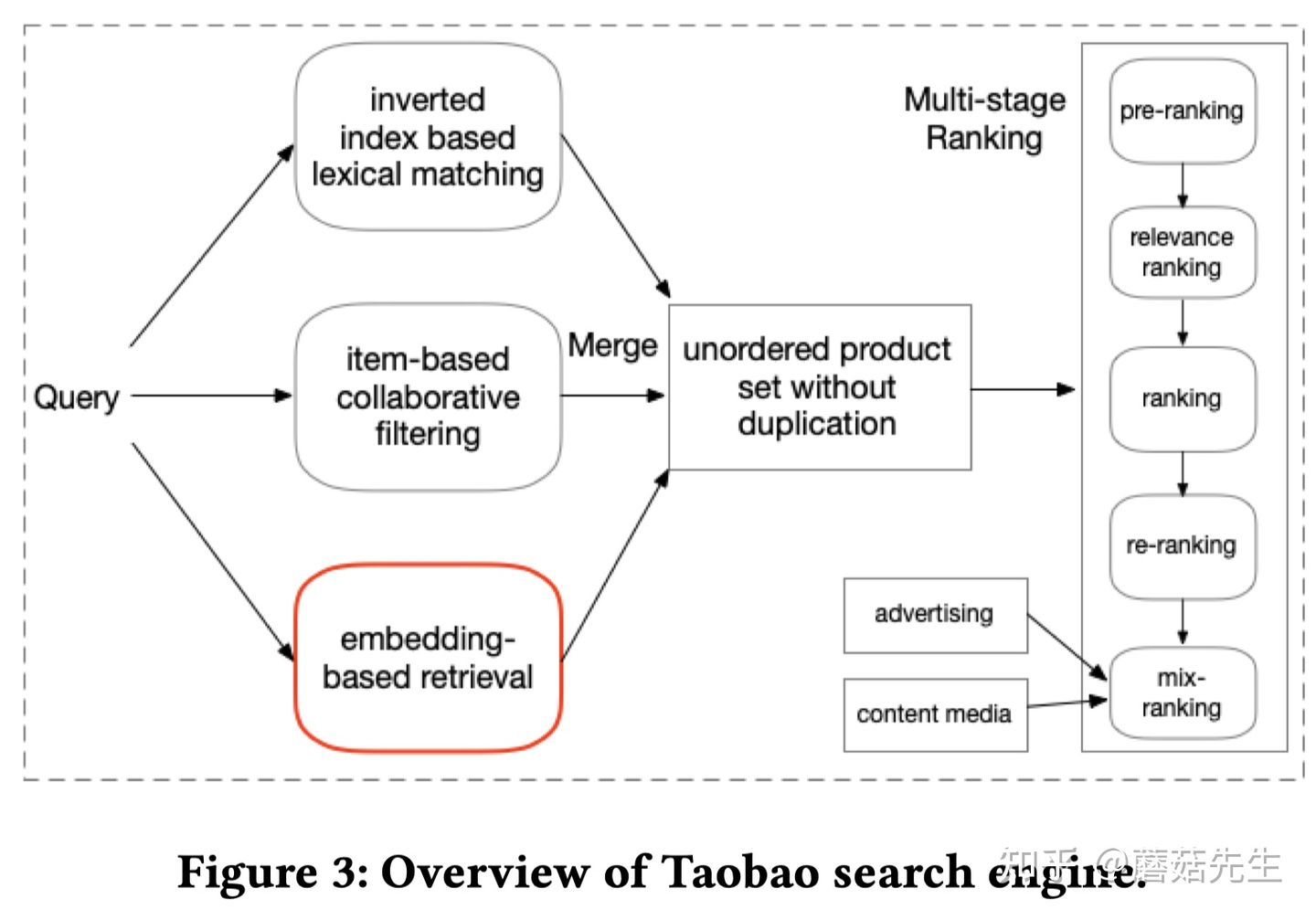 搜索的整个过程如下:
搜索的整个过程如下:
- 用户发起一次请求
- 触发多通道检索系统,形成未排序的商品集合
- 基于倒排索引的文本匹配
- 基于Item的协同过滤
- 基于向量的检索
- 多阶段排序
- 粗排
- 相关性排序
- 精排
- 重排
- 混排:商品、广告、多模态内容
本文重点在基于向量的检索 :
- 离线 :使用分布式Tensorflow对过去 1周内 的搜索日志数据进行训练, 天级更新 模型参数。
- 部署 :item tower离线算好所有product的向量,并存在ANN索引系统里,product量级巨大,分片存,共6列,借助层次聚类算法做量化降低存储开销(实际上猜测就是Faiss);query/user network做实时serving。实际检索的时候,能够实现类似布尔检索系统的高效检索。笔者当时针对Facebook[3]的文章,花了很长的时间做调研和理解,详细地写过一篇ANN检索的底层工程实现细节,感兴趣的可以参考下,语义向量召回之ANN检索:
语义向量召回之ANN检索 mp.weixin.qq.com/s/GDkY09tKmhEo1WZWmFK9Ug

- 性能 :实时检索9600个item。98%的item在10ms内能检索完,即:98线为10ms。很强的性能了。
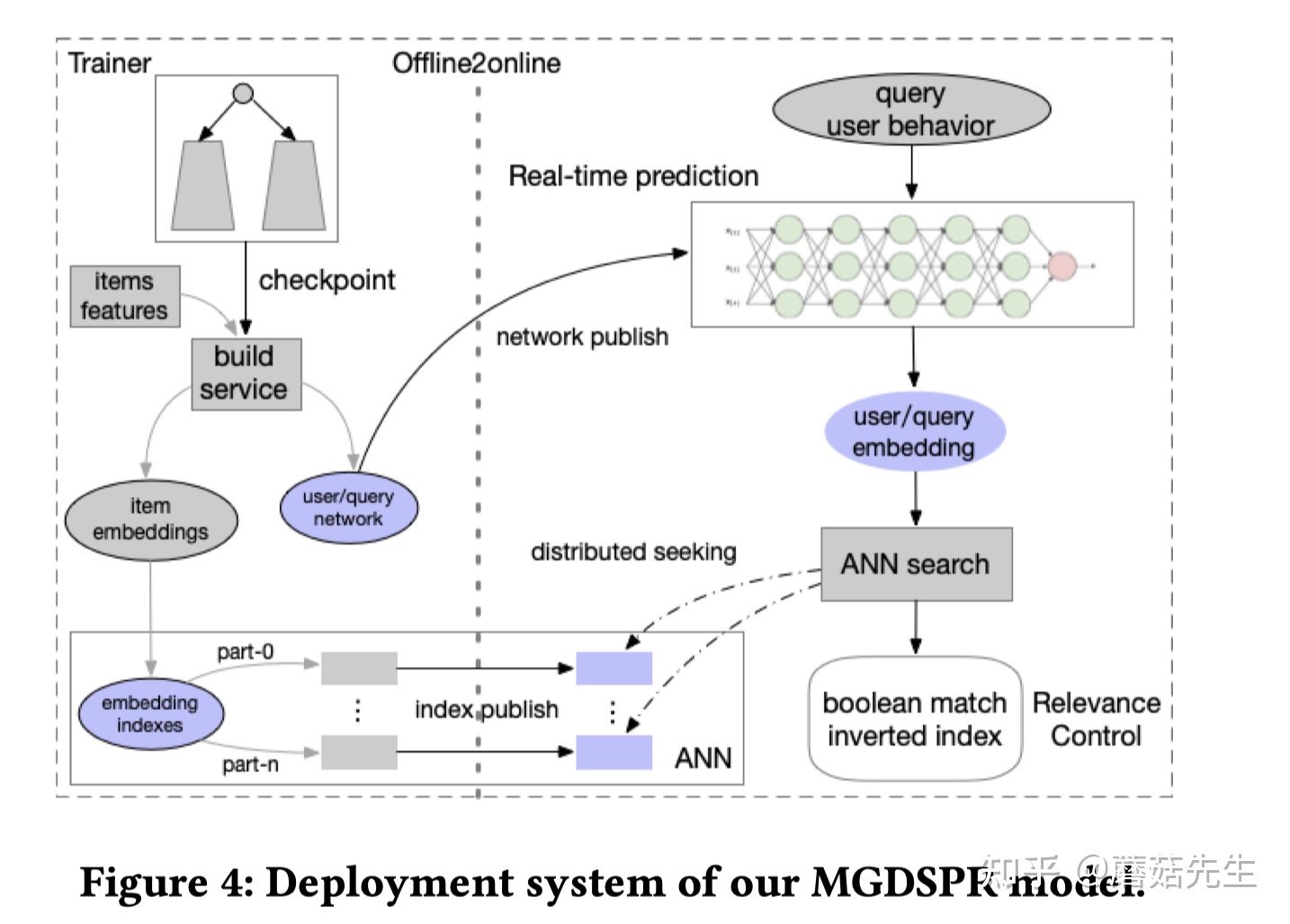 还有个很重要的相关性模块还没有介绍。开篇提到过,EBR检索系统在 个性化和模糊匹配方面做的很好 ,但是相关性上缺点也很大。归根结底在于,EBR不是完全匹配的方式,在搜索里,其实就是指不是Term Query。也即,结构化检索,比如品牌,颜色,类型等结构化字段,这些结构化字段能够很大程度上保证相关性。但是EBR却做不到这点。
还有个很重要的相关性模块还没有介绍。开篇提到过,EBR检索系统在 个性化和模糊匹配方面做的很好 ,但是相关性上缺点也很大。归根结底在于,EBR不是完全匹配的方式,在搜索里,其实就是指不是Term Query。也即,结构化检索,比如品牌,颜色,类型等结构化字段,这些结构化字段能够很大程度上保证相关性。但是EBR却做不到这点。
比如:用户检索阿迪达斯运动鞋,那么完全匹配查询能够去检索品牌:阿迪达斯,类目:运动鞋;但是EBR可能在embedding空间检索到耐克运动鞋,这显然是不相关的,会影响用户的体验。
因此,作者在ANN结果的后面,又加了层相关性控制模块,对query进行了查询理解,识别出品牌、类目等意图,然后对item的title中也挖掘出品牌、类目等结构化字段,然后用这些查询理解的意图对item做term query,过滤掉未命中这些结构化字段取值的item。
作者还提到,Facebook[3]的文章是通过EBR系统来弥补基于完全匹配的检索系统在个性化、模糊匹配上的不足;而淘宝搜索相关性控制模块的出发点相反,是通过基于完全匹配的检索系统来提升EBR系统的 相关性 。总之,二者相辅相成。
3. Evaluation
离线实验以及实现细节也是工业界文章的核心亮点,值得大家好好品。
3.1 Settings
-
离线指标 :
 。用户点击或者购买的item作为ground truth,去预测Top-K Item。作者提到,在检索阶段,用AUC做离线指标时,和线上的GMV指标无法保持一致,而召回指标则可以。
。用户点击或者购买的item作为ground truth,去预测Top-K Item。作者提到,在检索阶段,用AUC做离线指标时,和线上的GMV指标无法保持一致,而召回指标则可以。
 。相关性指标,Top-K结果中有多少个结果和query强相关,即:相关item的数量比例。是否相关的label不是人工标注的,而是采用了一个很强的相关性模型(在单独的人工标注数据集上的AUC能够达到 0.915 )来打标。
。相关性指标,Top-K结果中有多少个结果和query强相关,即:相关item的数量比例。是否相关的label不是人工标注的,而是采用了一个很强的相关性模型(在单独的人工标注数据集上的AUC能够达到 0.915 )来打标。
 。衡量EBR检索系统对各个阶段的影响指标。即:预测的Top-K Item中,有多少个 和query相关的item 会进入后续的各个排序环节,进入越多,说明相关性保证的越好。
。衡量EBR检索系统对各个阶段的影响指标。即:预测的Top-K Item中,有多少个 和query相关的item 会进入后续的各个排序环节,进入越多,说明相关性保证的越好。
-
在线指标 :
 = #pay amount.
= #pay amount.
-
线上相关性标注指标,
 展示给用户的item中,和query相关的占比,
展示给用户的item中,和query相关的占比,
 和
和
 ,前者用模型打标,后者外包标注。
,前者用模型打标,后者外包标注。 -
实现细节 :
- 网络结构:
- 实时行为序列最大长度50,长短期行为序列最大长度都是100,超过的mask掉,使用带mask机制的attention实现即可。
- user tower, item tower, LSTM等结构的隐层维度数为128。
- 实时行为中,LSTM结构2层,dropout=0.2,LSTM之间加残差连接,自注意力机制头的数量是8。
- 训练:
- batch大小为256。
- 困难负样本中,均匀分布a和b的值为0.4,0.6;生成的困难负样本数量为684。
- 温度参数
 。
。 - 随机初始化所有参数。
- AdaGrad,初始学习率0.1。
- 梯度裁剪,当梯度的L2范数超过3时做裁剪。
- 配置:
- 分布式机器学习平台,20个参数服务器,100个GPU作为worker,配置是Tesla P100。
- 训练时间:3500万步,耗时54小时。
- 网络结构:
-
数据集,
淘宝真实的搜索行为数据集,2020年12月连续8天的点击和购买日志,过滤掉了作弊用户行为。
- 训练集 :前7天作为训练集,约47亿条(item维度的)
- 测试集 ;从第8天中,随机从搜索系统数据中抽100W条数据;从推荐系统数据中抽50W条购买数据。
全量的候选item的数量级是1亿,和线上真实推断时的候选集保持一致。
3.2 离线对比实验
- Baseline:
 -DNN,MLP结构,很强的baseline。静态特征,统计特征,序列特征做pooling作为输入。(怎么训练的没说清楚,二分类任务还是本文的训练方法?)
-DNN,MLP结构,很强的baseline。静态特征,统计特征,序列特征做pooling作为输入。(怎么训练的没说清楚,二分类任务还是本文的训练方法?) - MGDSPR:本文的方法,如上文所述。作者提到一点,加入统计特征到MGDSPR中,recall指标并没有提升。挺神奇的。可能行为序列信息捕捉地足够好,不需要过多统计特征。
 提升还是挺大的,尤其是相关性样本的占比,以及进入粗排的相关性item的数量。说明EBR提前考虑了相关性后,在相关性控制模块中不会被过滤太多不相关的ITEM,有更多的相关ITEM进入后续的排序环节。
提升还是挺大的,尤其是相关性样本的占比,以及进入粗排的相关性item的数量。说明EBR提前考虑了相关性后,在相关性控制模块中不会被过滤太多不相关的ITEM,有更多的相关ITEM进入后续的排序环节。
3.3 消融实验
几大组件,唯一没说清楚的是,不使用mgs, trm等时,用的什么做baseline?拼接?
- mgs:2.1.1中提出的多粒度语义单元,对recall和相关性指标都有用。
- trm:2.1.3中的语义表征和个性化行为表征做融合,对recall和相关性指标都有用。
 : 2.3中的温度参数。对召回指标负向,但是对相关性指标提升非常显著。
: 2.3中的温度参数。对召回指标负向,但是对相关性指标提升非常显著。
 ,对召回指标负向,对相关性指标帮助大。
,对召回指标负向,对相关性指标帮助大。
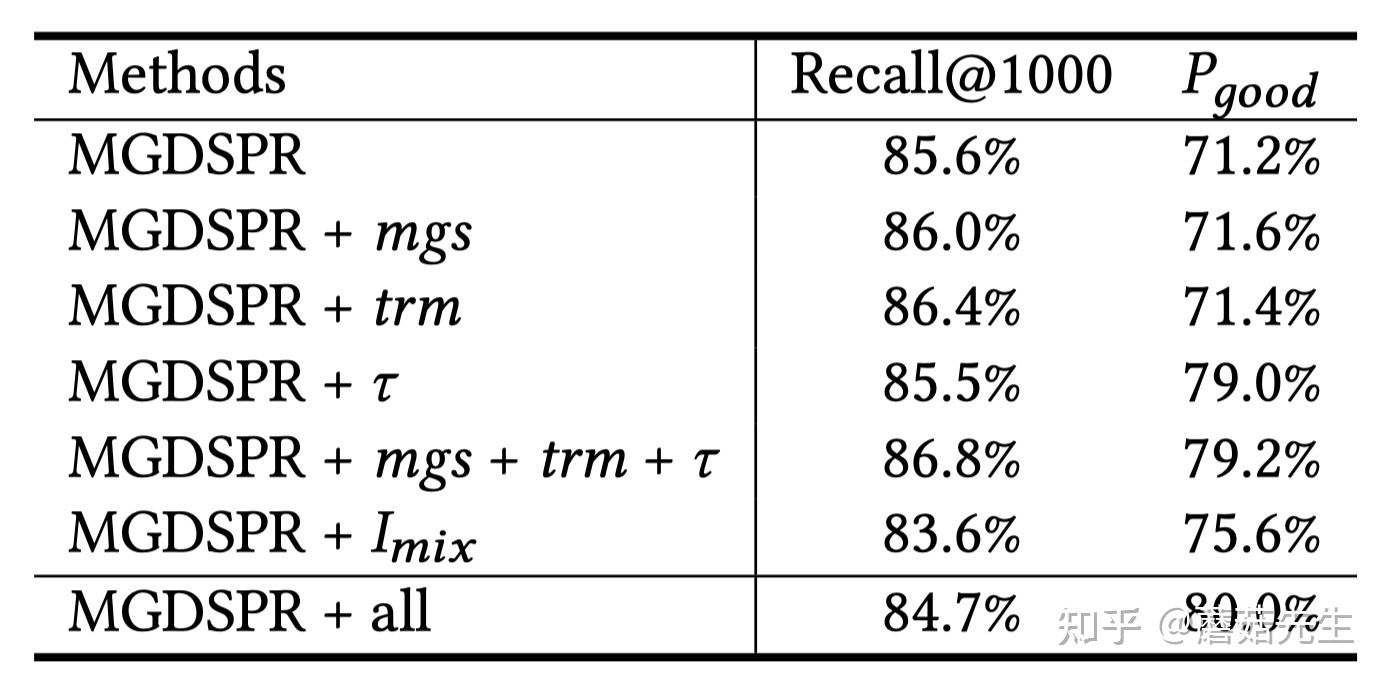 看了消融实验,对召回指标帮助大的是mgs和trm;对相关性指标帮助大的是温度参数和困难负样本。
看了消融实验,对召回指标帮助大的是mgs和trm;对相关性指标帮助大的是温度参数和困难负样本。
3.4 Online A/B Test
 有挺大的线上指标提升。
有挺大的线上指标提升。
其它的分析实验比较常规,总结下来就是:
- softmax收敛速度比pairwise loss快,recall指标也高不少。
- 温度参数和困难负样本对相关性的提升很大。
4.Summarization
总体而言,这篇文章干货很多,细读会发现很多细节。有几大亮点,
- 多粒度语义单元 ,对query语义的多粒度挖掘和表征,值得在搜索场景中尝试。
- 用户行为序列在搜索场景中的建模方法 ,query attentive而不是target-item attentive以及零向量的引入是最大亮点,长短期融合等也值得实践。
- EBR系统对相关性的保证 ,softmax损失函数+温度参数;在embedding空间生成困难负样本。
个人认为还有几个疑问没解释清楚:
- 多粒度语义单元结构如此复杂 ,里头每个组件都是有效的吗?过于empirically/experimentally实验驱动,而不是问题驱动。
- 困难负样本生成的时候 ,如何高效地对所有Item求点积最大的top-N?这里头Top-N是否有可能存在和当前query相关的item,是否会产生负面影响?
- 相关性模块 :EBR和完全匹配的Term Query结果取交集保证相关性,那和直接用完全匹配做召回相比,增益在哪里?我理解这种只可能在 完全匹配召回的候选集合item 数量远大于排序候选集合item数量的时候才有效,EBR提前考虑了个性化因素,能够防止满足个性化需求的item无法进入排序阶段。
- 实验的一些细节 ,baseline的训练方式没说清楚。消融实验中,不使用那4个组件时,模型用什么方式替代没说清楚。
不过总的来说,同以往的EBR文章一样,值得细读和实践!
这是KDD 21工业界文章的第一篇分享,更多KDD 21 工业界文章参见下文。下期分享见!
蘑菇先生:KDD 21 工业界搜推广nlp论文整理58 赞同 · 2 评论文章

References
[1] Priyanka Nigam, Yiwei Song, Vijai Mohan, Vihan Lakshman, Weitian Ding, Ankit Shingavi, Choon Hui Teo, Hao Gu, and Bing Yin. 2019. Semantic product search . In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2876–2885.
[2] Han Zhang, Songlin Wang, Kang Zhang, Zhiling Tang, Yunjiang Jiang, Yun Xiao, Weipeng Yan, and Wen-Yun Yang. 2020. Towards Personalized and Semantic Retrieval: An End-to-End Solution for E-commerce Search via Embedding Learning . arXiv preprint arXiv:2006.02282 (2020).
[3] Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano, and Linjun Yang. 2020. Embedding-based retrieval in facebook search . In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2553–2561.
[4] Miao Fan, Jiacheng Guo, Shuai Zhu, Shuo Miao, Mingming Sun, and Ping
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%98%E5%AE%9D%E6%90%9C%E7%B4%A2%E4%B8%AD%E8%AF%AD%E4%B9%89%E5%90%91%E9%87%8F%E6%A3%80%E7%B4%A2%E6%8A%80%E6%9C%AF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


