浅谈搜索系统中理解和分析
作者: OPPO 算法工程师,搜索方向;北京科技大学本硕,统计学毕业,在学期间曾经发表 6 篇论文,其中 4 篇 SCI。CS 的陋室号主
搜索是一个系统,大小不好说,但肯定是五脏俱全,我做的比较多的就是 query 理解和分析,这次给大家重点讨论一下这块内容。
久违的懒人目录:
- query 理解的目的。
- 例子。
- query 理解的内容。
- query 理解的操作。
- 背后的知识。
- 软实力支撑。
- 总结。
query 理解的目的
query 理解是整个搜索系统中最上游的一环,负责的是从 query 中提取信息,从而了解用户希望通过这个 query 搜索出什么,泛泛的说完了,剩下来看详情。
query 理解,决定了下游的搜索召回策略。底层数据从技术上,有各种类型的数据库需要检索;从算法策略上,也有多种召回的方案,例如高准确的、高召回的等等,要用什么策略,这要取决于 query 理解的结论。
例子
要把一个事情说清楚,举例是一个很好的方法。来一个 query:唐人街探案(此条广告 5 毛,记得删掉括号)
直观的看,这里有一个核心词——唐人街探案,其核心意图就是想看看唐人街探案的相关内容吧,来看看系统内干了些啥:
纠错:初步看来,没有错误,过。
意图识别和实体识别:有唐人街探案这个实体,常见的首先是一部电影,最近还上了网剧,从热度上看,由于网剧比较新,所以用户在近期更可能看的是网剧,当然信息不足,不代表用户真的就只想看网剧,所以电影的东西也要给一些,最大限度保证满足需求。
好了,以百度为例看看结果:
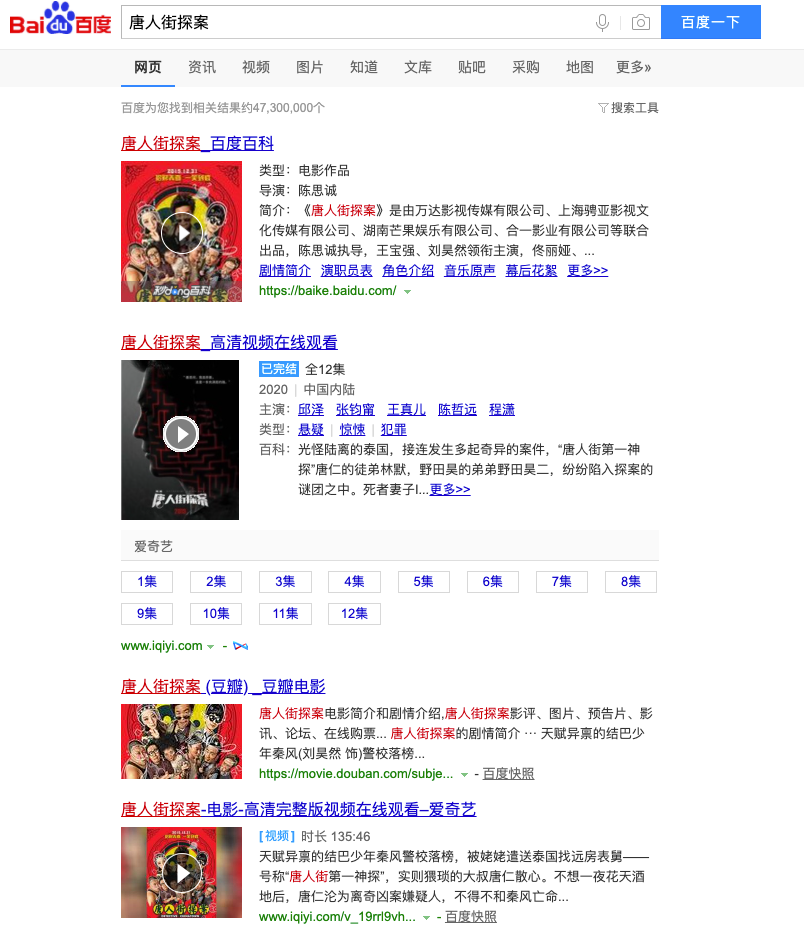
前 4 条,分别给的是百科、爱奇艺网剧、豆瓣电影评论、爱奇艺电影。基本上就覆盖了我上面的分析内容,用户只输入了一个简单的实体,就会给出精准的对应信息,百科了解概况,爱奇艺网剧满足近况,豆瓣电影有影评,最终补充了电影,满足更为全面的请求。
我们来复杂一些,升级为唐人街探案网剧怎么样。
唐人街探案还是一个实体,网剧和电影双意图,但是由于用户输入了网剧,有关电影的内容基本上就可以不出了,最后来了个怎么样,说明用户是更在乎影评,而非要看电视剧了,当然给电视剧了用户不会反感,属于弱意图了。好了,来看百度结果:
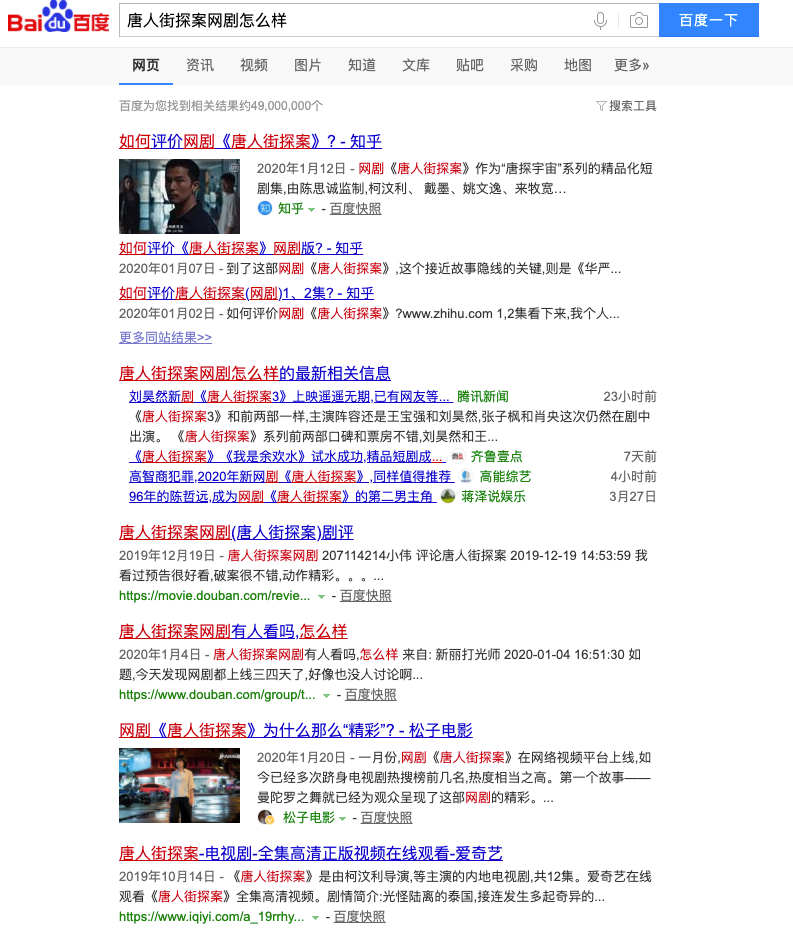
前 5 条都围绕着影评进行,可以说是分析的非常精准了,且前面几条也是比较出名的媒体给出的答案,知乎、新闻、豆瓣、松子电影,第六条很机智的给了爱奇艺的链接了,而且不是展开的,而是一个摘要形式的,大家可以对比一下上一条搜索的结果区别,从这里,大家就能理解,query 理解具体做了些什么事情。
query 理解的内容
那么,要做 query,要做什么工作呢。仔细想想,其实主要就是下面几个:
- 纠错改写。针对用户输错的,没输入完全的,内容,进行修正。底层数据库只支持精准搜索,因此需要将 query 改写到正确的内容下。
- 意图识别。通过分析语义等方式,在一定的类目结构下,识别出具体意图。这个意图识别的目标,大家可以理解为告诉下游,需要在哪个库数据进行搜索。
- 实体识别。其实和意图识别一样,只不过,粒度更细,但是是词级别的分析,从 query 中抽取关键的实体,如果说意图识别是为了告诉下游该检索那个数据库,那实体识别就是为了告诉下游,在该数据库下,该检索哪些字段。
- 词权重问题。query 里面有两个词,两个文档分别匹配到了其中一个词,那谁能靠前?这就要看匹配到什么内容更为重要。如家宾馆,匹配到一个如家酒店和五洲宾馆,如家酒店应该在前,这里就是为了解决这个问题。
query 理解的具体操作
query 理解下的所有内容,除了意图识别本身外,其实我都或多或少介绍过,这里先
纠错改写
之前写过文章了,在这里: R&S[23] | 搜索系统中的纠错问题
简单地说,就这两个思路:
- 基于统计挖掘,分析最高频的正确答案,在用户错误的时候,分析他的真实意图,改写过去。
- 基于机器学习和深度学习,识别错误,改正错误。
意图识别
意图识别简单的理解,其实是一次文本分类,那么文本分类,我们把思路拓展开,其实也是两条路——传统方法和 NLP。
- 传统方法想必很多人其实了解的并不多,但其实是搜索领域内非常常见,通过规则、词典、正则等方式进行识别,准确率高、速度快。
- NLP,通过语义分析的手段,文本分类,达到语义分析的目的。
实体识别
其实问题抽象出来,就是个难度高于文本分类的序列标注问题,搜索中的命名实体识别,我聊过的,在这里: NLP.TM[18] | 搜索中的命名实体识别。具体思路仍然分为两派,传统方法和 NLP。
词权重问题
我还是聊过哈哈: NLP.TM[20] | 词权重问题。这个问题,在我多年(咳咳恩,别装)的经验下,感觉这是一个非常考验基本功的任务,对数据的理解、操纵,对程序的把握,都有很重的考验。
- 统计的方法,其中 tfidf 最为常见,而由于 query 的长度都不长,所以其实就是 idf 的计算了。
- NLP 方法,其实就是序列标注问题的升级版了。
背后的知识
最近是在知乎上回答了一个问题:
一个合格的搜索算法工程师应该具备哪些能力? https://www.zhihu.com/question/381003357/answer/1173551448
里面的内容不复述了,这里主要谈谈可能涉及的技术,无论是算法模型,还是工程技术。
算法上:
- nlp 是跑不掉的,尤其是文本分类和序列标注,另外建议大家懂一些文本相似度的计算,会有很大机会用到。
- 紧跟着第一点来强调,对短文本的处理,非常重要。
- 简单复杂的统计和实验方法,在设置阈值、调优等等,非常重要。
- 低复杂度的,低消耗的算法,建议大家要会用,要懂原理,例如 fasttext、word2vector。
技术上:
- python 必会,Java 和 c++ 至少会一个,尽可能会两个,这是门槛问题。
- 搜索领域常用的数据结构要懂,trie 树之类的,当然基本的数据结构,链表、堆栈、树之类的,是基操。
- 会自己动手写一个可通信的服务,语言不定,要求对这个通信服务有概念,常见的是 http 请求,另外还有底层通信的 grpc,这个其实对算法而言是更常用的。
- 大数据的操作,hadoop、hdfs、spark,当然还包括 MySQL。
软实力支撑
和选电脑一样,不能只看面板指标,和选男女朋友一样,不能只看外表,那么在搜索领域,最好有哪些软实力呢?
- 需求和问题�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B5%85%E8%B0%88%E6%90%9C%E7%B4%A2%E7%B3%BB%E7%BB%9F%E4%B8%AD%E7%90%86%E8%A7%A3%E5%92%8C%E5%88%86%E6%9E%90/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


