洋码头搜索应用架构
作者介绍
皮勇泽,洋码头搜索工程师
多年搜索业务开发经验,负责洋码头搜索系统开发
传送门: http://www.6aiq.com/article/1537369562943
http://www.6aiq.com/article/1537369469861
搜索是洋码头APP流量分发的主要入口。随着洋码头商品数的激增,搜索的重要性愈加凸显。本文以整体搜索框架为切入点,围绕搜索业务展开,介绍下索引创建、搜索服务、热词推荐和排序因素等。
本文约4000字,可参阅下面的大纲阅读。
1. 业务特点及总体架构
2. 索引构建
3. 分词策略
4. 搜索策略
5. 结果集排序
6. 热搜词服务
7. 结语
1. 业务特点及总体架构
区别于Baidu和Google等搜索引擎,作为电商平台,洋码头的搜索应用有以下特点:
-
数据源分布广,涵盖商品、活动、买手、物流、评论等多个系统。
-
召回要求高,在保证有效召回的基础上,需确保流量分配的公平性。
-
实时性要求,良好的用户体验,决定了近实时的需求,更新量与商品量成正比。
-
排序要求高,在保证流量分配的基础上,保证流量的质量,需综合各个维度的因素。
-
个性化需求,在保证流量分配的公平性和价值性的基础上,满足用户的个性化需求,也是优化用户体验的重要环节。
基于这些特点,我们部署了多套ES业务系统,并分别针对不同的场景来构建索引;在实时性需求上,架构有主从表、DB增量和消息增量等模式来分别应对不同的增量数据规模;在排序上,分为用排序插件粗排和模型精排两轮,保证结果集的准确度;在个性化方面,根据离线计算好的用户画像来获取用户兴趣来召回结果集。
系统的总体架构参见下图。
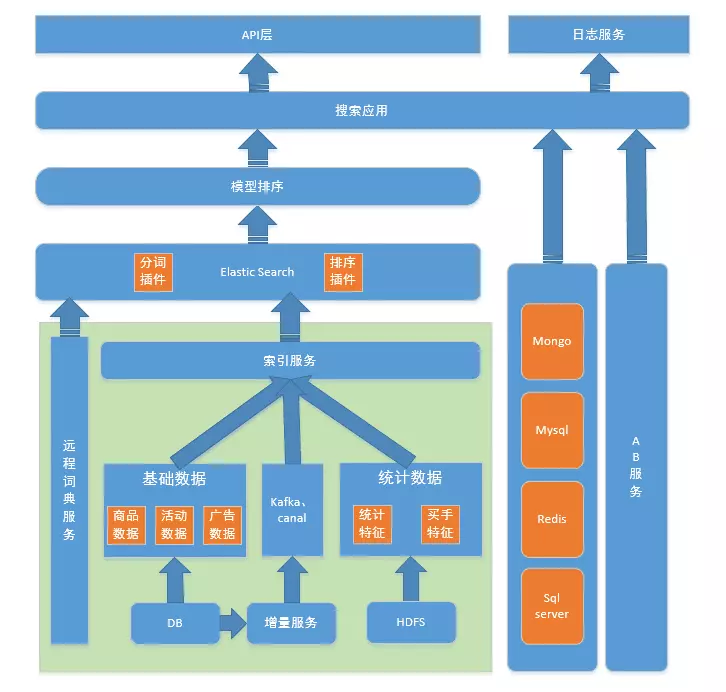
图1 - 总体架构图
下面我概括性地介绍下一些细节和要点:
2. 索引构建
一方面,搜索需要接入多业务方复杂的业务逻辑,另一方面,新增业务以及业务迭代均需要体现在搜索中。基于复杂性和扩展性需求,我们设计了一套抽象的主从表结合消息订阅的索引框架。主表和从表是抽象意义上的表,可以指定底层数据源,可以来自数据库、第三方API、消息队列等。主从表包含获取增量数据、获取全量数据在内的通用功能。对于商品索引,商品表即主表,其他各个维度表以从表的方式提供数据,最终经索引服务Join以及添加相关业务规则,得到完整的ES的DOC。
因而对于新的业务扩展,则只需构造相关从表,并制定Join和生成DOC的业务规则即可完成。为了做到场景上的隔离,码头的集群和索引分多套部署,而这个过程中,则有消息的重复生成和订阅,对数据库和接口API造成压力,因而在后续的迭代过程中,我们抽取了增量服务。增量服务负责订阅所有的增量消息,生成消息写入Kafka,而索引服务作为消息的消费者,消费消息,并将消息写入ES,从而缓解了数据库和接口API的压力。后续,对于复杂网络环境引发的数据丢失问题,我们引入了Monitor组件的概念,负责对增量丢失进行填充。同时,结合Cat监控点,我们对数据丢失原因进行分析,用于迭代和完善索引逻辑。例如,某些分布式场景下,集群主节点切换,导致的部分增量数据未写入索引,还有一些主从表时序问题,导致的更新问题等,通过这些数据的分析,进一步优化主从表框架的细节问题。
同时,索引服务起到了写入速度控制的作用,对于一些业务端的刷数据问题,以及大批量的数据清洗,可以控制增量速度,进而保证集群的稳定性,防止由于数据量过大,对ES造成压力。
整体而言,经过主从表框架的不断迭代,我们已形成一个高可靠、高实时、易扩展的索引框架,把开发人员从大量的业务中解脱出来,进而可以使用更多的时间,用于排序的优化和迭代,系统性能的优化与迭代。
简单流程如下:
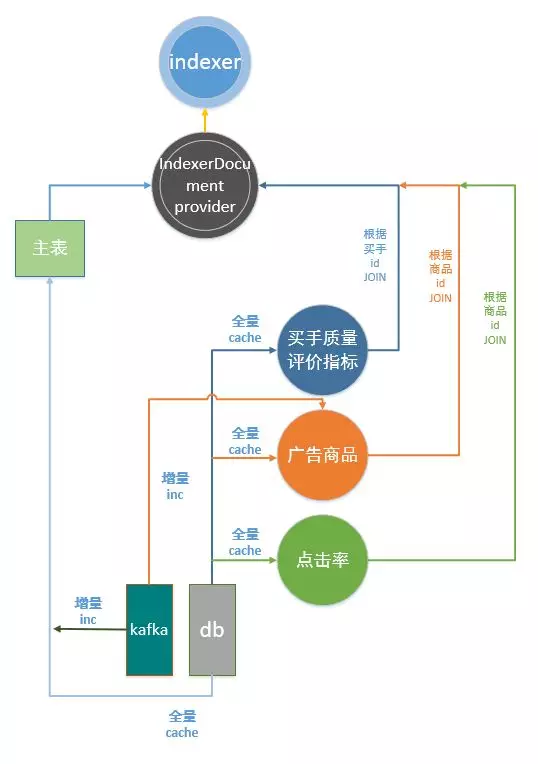
图2 - 索引构建数据流图
3. 分词策略
目前常用的分词方案包括基于词典的分词方案和基于统计的分词方案,两种方案各有优缺点。基于词典的分词出现较早,易于实现,工程上应用广泛,但是在歧义处理和未登录词方面效果一般。而基于统计的分词方案,具有良好的歧义处理和新词识别能力,但是存在算法复杂、语料库限制、case处理等问题。结合当前使用场景,通过源码分析,了解到IK应用了多个基于规则的消歧策略,包括次元个数、有效文本长度、次元位置,而后我们结合一些统计学结论和大量的Case测试与排查,选取IK作为底层分词框架。
在搜索词切分和索引构建过程中,我们采取了不同粒度的分词策略,搜索词切分使用粗粒度的IK_SMART,索引构建过程使用IK_MAX_WORD,保证召回率和语义性。
我们做了以下几点改动以满足业务场景需求:
-
扩展并实现了远程词典,用于IK插件词典的热更新。定时同步新增品牌到词库。后续考虑进一步通过一些外部新词表,进一步扩充词库,以便优化新词发现功能。对于消歧,后续会通过细化规则,进一步优化消歧过程。
-
通过修改源码,解决了IK_SMART和IK_MAX_WORD的不包含问题。
4. 搜索策略
搜索是一种有目的的用户行为,搜索模式主要包括全文搜素、精准匹配、组合搜索和字段聚合。搜索场景的整体逻辑是,依据指定条件召回并按照特定排序规则返回召回内容。不同的条件组合,对应不同的业务场景,同时针对不同的业务场景,也需要定制不同的排序策略。召回过程中,除了常规的全文匹配和精准匹配,我们还结合场景,进行了进一步的定制。这些场景主要包括无结果改写、候选集过大。
针对无结果的场景,我们进行了Query改写。Query改写的整个候选集是热搜词库。通过子串、编辑距离、同拼音等策略,筛选出可能的候选集,依据热搜次数进行排序,最终返回替补词,以改善无结果的体验。后续我们会考虑针对不同的用户进行个性化处理,以便进一步提升用户体验。
针对结果集过大的搜索词,我们会进行分次召回。以商品搜索为例,我们将搜索商品按买手分区,针对每个分区选出商品综合分靠前的一部分打上flag,用于第一轮召回。这样,大大减小了这种搜索词的结果集(因为大部分用户的请求集中在前20页),进而在保证公平流量分发的基础上,减少召回,缓解了ES的压力。后续,我们会进一步尝试通过用Query扩展词进行Query改写,结合用户行为,合理限制搜索范围,并依据一些个性化策略进行定制,以便更好地改善用户体验。
5. 结果集排序
针对命中结果集,我们进行了搜索层面的粗排,而后通过离线训练的模型进行精排。
5.1 基础排序
搜索初期,我们的排序策略是对各个指标进行人工经验加权。主要包括商品维度、买手维度、Query维度、运营规则和业务规则。 加权指标包括:
1) 基于用户的点击、收藏、加购、下单,统计出商品各个维度下的分数,加权得出商品的综合分。后续通过一些排序的case,我们发现不同类目的商品综合分分布相差较大。而某些场景下,多个类目会同时出现在候选集中,导致类目分布过于密集。我们针对上述问题,对商品综合分进行了类目归一化,点击率和转化率得到了大幅提升。
2) 基于买手的销量、服务、粉丝等指标,以及按地区和国家聚合出一些买手指标,统计加权得出买手综合分。使用一些运营目标对买手进行划分,进行加权、优选和淘汰等,用于排序。
3) 基于活动、运营规则、优惠券等各种指标,对优质商品进行适当加权。
4) 针对某些入门买手未能按平台规定,错挂或者漏挂品牌、类目的场景,以及为了更好的识别用户意图,我们加入了Query理解,包括品牌预测、类目预测。品牌预测,目前策略主要通过文本匹配完成,通过文本内容片段匹配品牌库,对命中的商品进行加分加权。类目预测,则通过用户反馈实现。我们统计用户中,Query维度的类目点击分布,设定阈值,取大于指定阈值的类目作为Query命中类目,进行加分加权,并最终用于广告等多个场景。通过类目和品牌预测,很好的解决了挂错类目和挂错品牌的问题,提升了用户体验。
5)点击反馈。为了更好地将用户的点击行为体现在排序中,我们做了简化的点击模型用于点击反馈。依据query下商品的点击率,进行威尔逊平滑和归一化处理,用于对商品加权。后来,我们发现一些无点击的商品将永远得不到展示,为了解决这个问题,我们引入了Query维度的平均点击率,作为bias,保证了点击模型分的合理性,点击和转化得到了大幅提升。
6) 广告和活动插入策略。广告和活动商品,我们采取在固定页面固定位置插入的方式进行处理,进一步提升广告和活动的流量曝光。针对广告和活动与原始搜索结果列表重复的场景,我们进行了特定策略的调整,以便在用户感知不到重复的基础上,进一步推荐更多物美价廉的商品给用户。广告本身是个性化策略排序的,因而搜索结果集不再需要做特殊处理。
7)个性化方案。初版的个性化方案,我们是通过用户画像的品牌、类目和点击商品等,召回相似商品,并匹配场景条件,以插入的方式加入结果列表。通过ABTest对比,点击率和转化率取得了一定幅度提升。
结合不同的场景,使用不同的维度,进行结果打散,保证流量分配的合理性,减少重复的可能性,进一步提升用户体验。
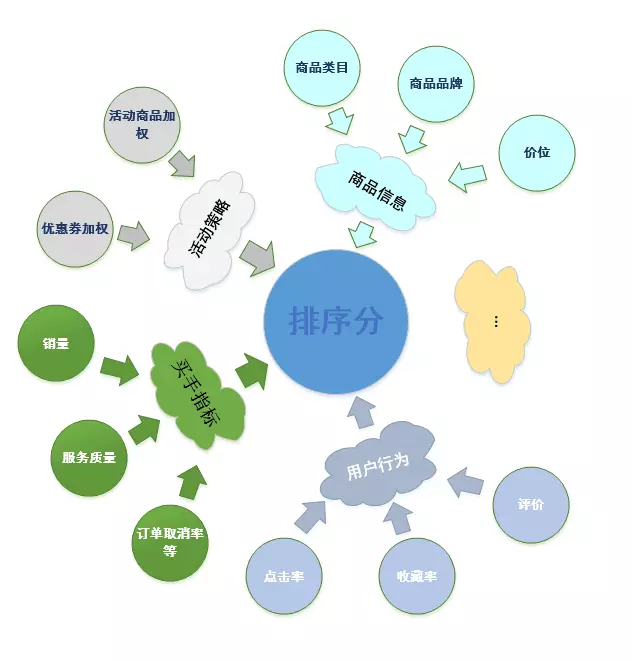
图3 - 影响排序的因素
5.2 个性化模型排序
后续,我们对搜索排序的个性化进行了迭代。综合各个维度数据包括用户维度、商品维度、买手维度和Query维度,进行数据清洗和特征编码,结合用户行为,生成样本数据,使用LR训练出CTR模型,用于对初排结果的重排。之后,进一步结合一些业务规则、置底、打散等逻辑,最终呈现给用户重排后的结果。重排后,点击率有一定的提升。后续,我们会进一步优化模型,加入更多的特征,并加入一些先验因素作为正样本,以便进一步提升用户体验。
综上,码头搜索服务在提升用户体验方面做了很多探索,也取得了很大的提升。索引方面,我们满足了复杂场景的增量和全量,但是后续随着码头业务的扩展,我们将会进一步将框架分层,以便更好的应对数据量激增的场景。热搜词层面,我们已经可以给到用户大多数用户的选择,我们会进一步加入个性化因素,更好地满足用户需求。搜索层面,我们已经可以公平的分配流量,并将大部分用户好评的商品展示给用户,后续我们会进一步探究更详细的流量分发,探究进一步的个性化,满足不同场景的搜索需求,优化不同场景的用户体验。
6. 热搜词服务
结合用户搜索行为,通过对搜索词进行清洗、处理和合并等,并进一步聚合出用户的搜索行为数据,最终得到按照用户实际搜索行为排序的热搜词。我们将热搜词和商品标题抽取出的核心词作为整个候选集,生成词矢量,结合用户画像的一段时间搜索行为召回候选词集,结合热搜次数以及词性特征等,进行排序、打散,使用Blume filter进行历史数据去重,进一步丰富了热搜词的覆盖度。
搜索词扩展主要应用于搜索列表页、分类列表页和买手主页。我们主要采用下列手段提取扩展词列表:
-
依据不同场景搜索条件聚合商品核心词
-
采用词性过滤、清洗数据等方式合并某些相近的核心词
7. 结语
我们的搜索服务还不能够和几大热门引擎相提并论,但也走出了自己的特点,在提升用户搜索服务质量、提供个性化搜索结果集、提升页面转化率等方面的贡献也是可圈可点。今后我们的业务将继续朝着这个方向迭代,在提升用户满意度的同时也体现出整个搜索系统的应用价值。
全文完
历史分享:
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B4%8B%E7%A0%81%E5%A4%B4%E6%90%9C%E7%B4%A2%E5%BA%94%E7%94%A8%E6%9E%B6%E6%9E%84/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


