汽车之家湖仓一体架构实践

分享嘉宾:邸星星@汽车之家
编辑整理:DataFun、Flink中文社区
导读: 本文将介绍如何基于Apache Iceberg构建湖仓一体架构,将数据可见性提升至分钟级;从多维分析的角度来探讨引入Apache Iceberg带来的收益,以及未来还有哪些收益可以期待。
01 数据仓库架构升级的背景
1. 基于 Hive 的数据仓库的痛点
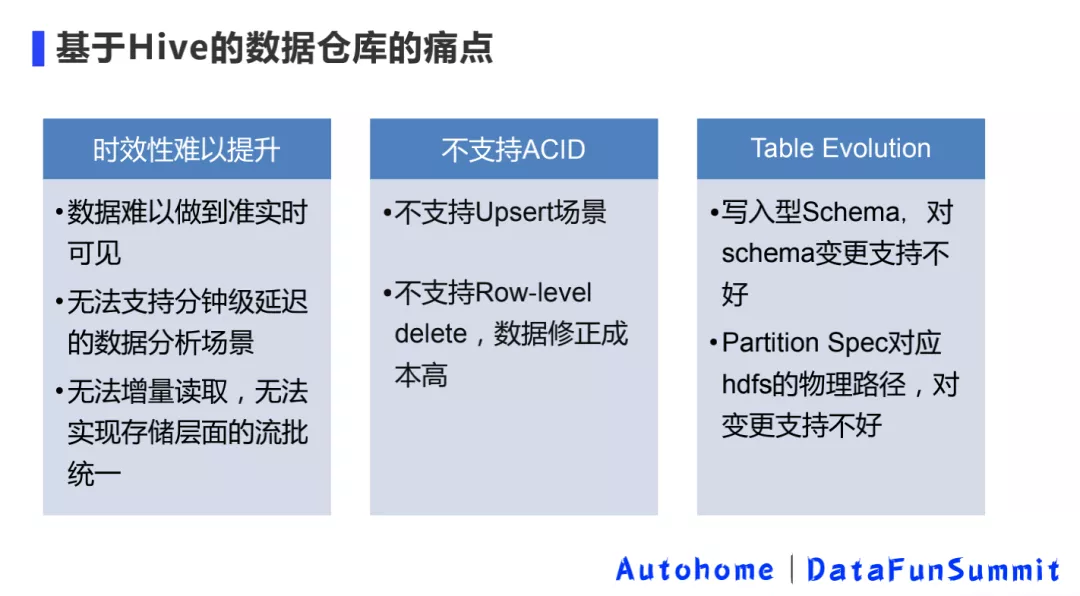
原有的数据仓库完全基于 Hive 建造而成,主要存在上述三大痛点。
2. Iceberg 关键特性

Iceberg 主要有四大关键特性:支持 ACID 语义、增量快照机制、开放的表格式和流批接口支持。
02 基于 Iceberg 的湖仓一体架构实践
湖仓一体的意义就是说我不需要看见湖和仓,数据有着打通的元数据的格式,它可以自由的流动,也可以对接上层多样化的计算生态。
——贾扬清
1. Append 流入湖的链路
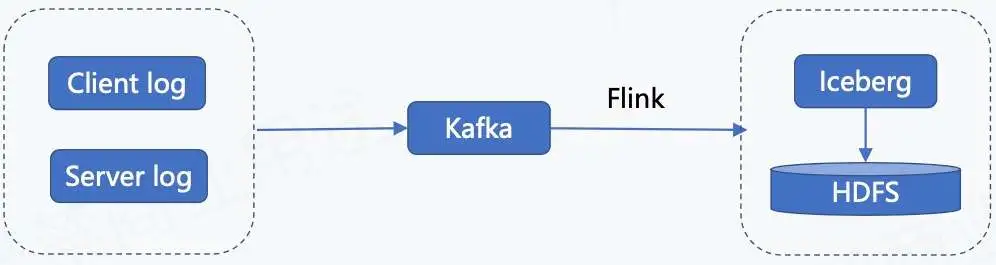
上图为日志类数据入湖的链路,日志类数据包含客户端日志、用户端日志以及服务端日志。这些日志数据会实时录入到 Kafka,然后通过 Flink 任务写到 Iceberg 里面,最终存储到 HDFS。
2. Flink SQL 入湖链路打通
我们的 Flink SQL 入湖链路打通是基于 “Flink 1.11 + Iceberg 0.11” 完成的,对接 Iceberg Catalog 我们主要做了以下内容:
- Meta Server 增加对 Iceberg Catalog 的支持;
- SQL SDK 增加 Iceberg Catalog 支持。
然后在这基础上,平台开放 Iceberg 表的管理功能,使得用户可以自己在平台上建 SQL 的表。
3. 入湖 - 支持代理用户
第二步是内部的实践,对接现有预算体系、权限体系。
因为之前平台做实时作业的时候,平台都是默认为 Flink 用户去运行的,之前存储不涉及 HDFS 存储,因此可能没有什么问题,也就没有思考预算划分方面的问题。
但是现在写 Iceberg 的话,可能就会涉及一些问题。比如数仓团队有自己的集市,数据就应该写到他们的目录下面,预算也是划到他们的预算下,同时权限和离线团队账号的体系打通。
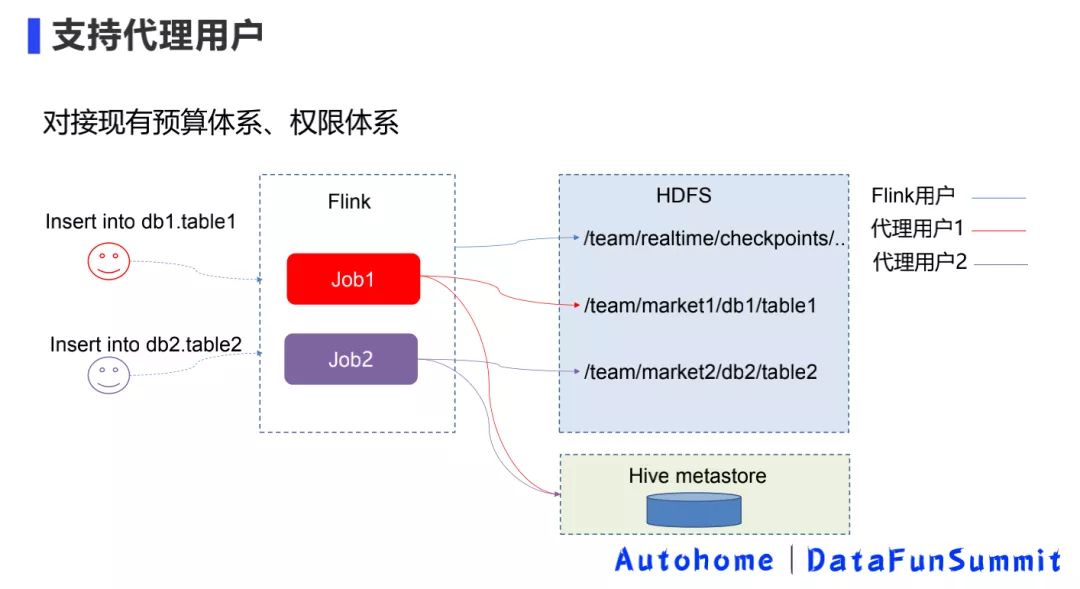
如上所示,这块主要是在平台上做了代理用户的功能,用户可以去指定用哪个账号去把这个数据写到 Iceberg 里面,实现过程主要有以下三个。

① 增加 Table 级别配置:‘iceberg.user.proxy’ = ’targetUser’
- 启用 Superuser
- 团队账号鉴权
② 访问 HDFS 时启用代理用户:
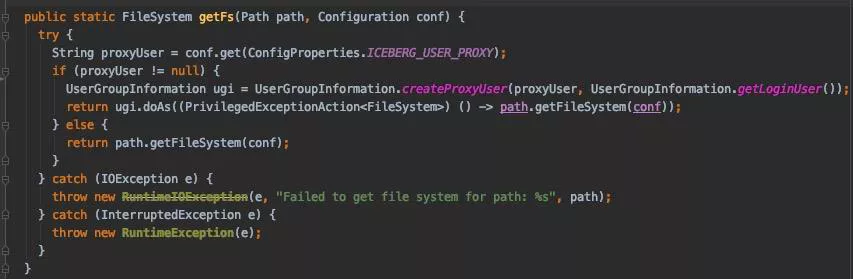
③ 访问 Hive Metastore 时指定代理用户
- 参考 Spark 的相关实现:
org.apache.spark.deploy.security.HiveDelegationTokenProvider
- 动态代理 HiveMetaStoreClient,使用代理用户访问 Hive metastore
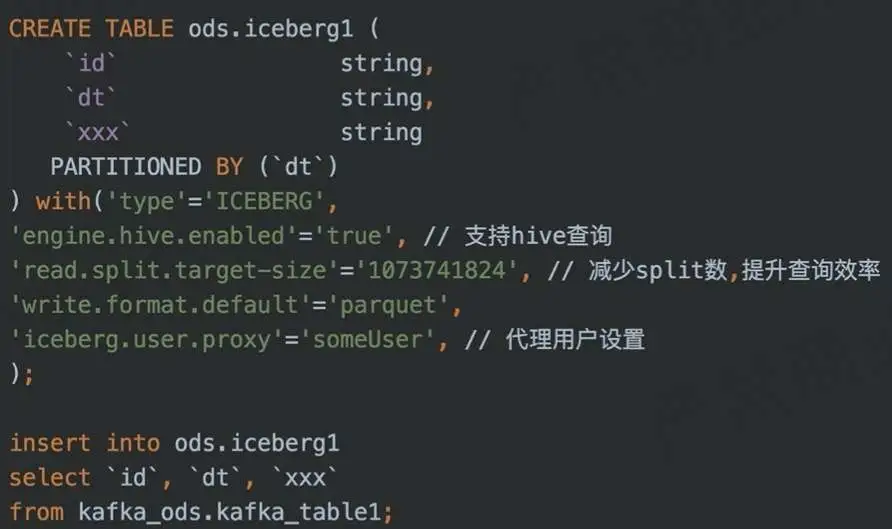
4. Flink SQL 入湖示例
DDL + DML
5. CDC 数据入湖链路
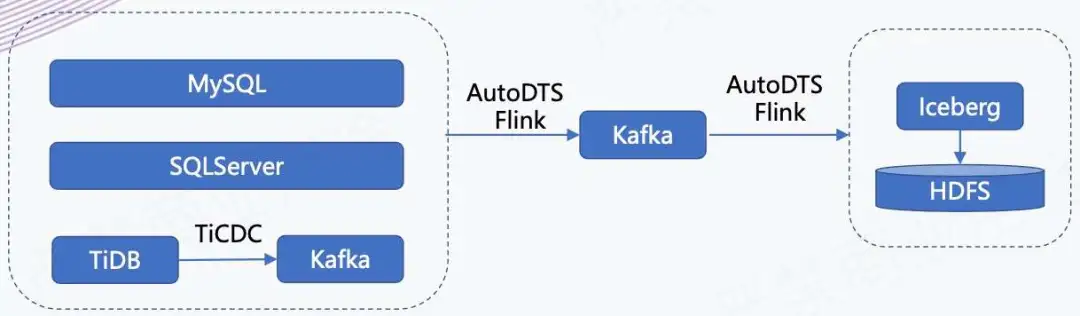
如上所示,我们有一个 AutoDTS 平台,负责业务库数据的实时接入。我们会把这些业务库的数据接入到 Kafka 里面,同时它还支持在平台上配置分发任务,相当于把进 Kafka 的数据分发到不同的存储引擎里,在这个场景下是分发到 Iceberg 里。
6. Flink SQL CDC 入湖链路打通
下面是我们基于 “Flink1.11 + Iceberg 0.11” 支持 CDC 入湖所做的改动:
改进 Iceberg Sink:
Flink 1.11 版本为 AppendStreamTableSink,无法处理 CDC 流,修改并适配。
表管理
- 支持 Primary key(PR1978)
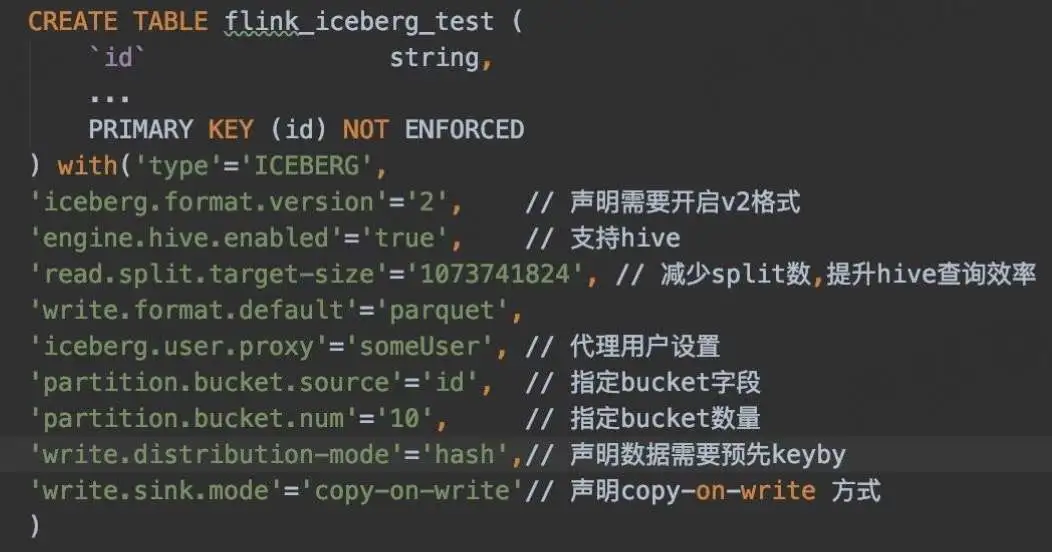
- 开启 V2 版本:‘iceberg.format.version’ = ‘2’
7. CDC 数据入湖
① 支持 Bucket
Upsert 场景下,需要确保同一条数据写入到同一 Bucket 下,这又如何实现?
目前 Flink SQL 语法不支持声明 bucket 分区,通过配置的方式声明 Bucket:
‘partition.bucket.source’=‘id’, // 指定 bucket 字段
‘partition.bucket.num’=‘10’, // 指定 bucket 数量
② Copy-on-write sink
做 Copy-on-Write 的原因是原本社区的 Merge-on-Read 不支持合并小文件,所以我们临时去做了 Copy-on-write sink 的实现。目前业务一直在测试使用,效果良好。
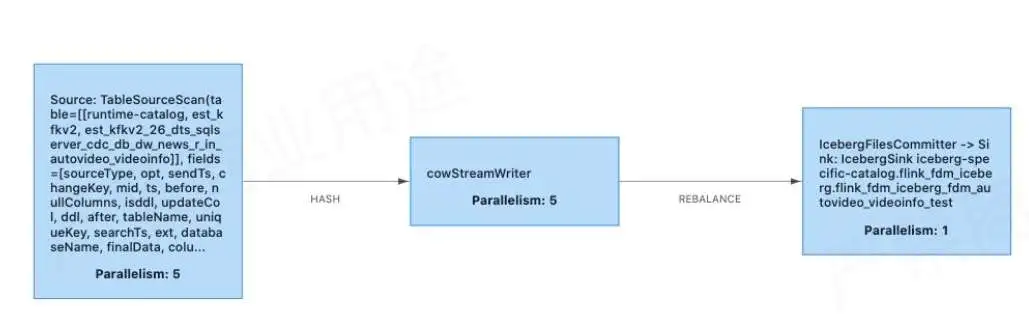
上方为 Copy-on-Write 的实现,其实跟原来的 Merge-on-Read 比较类似,也是有 StreamWriter 多并行度写入和 FileCommitter 单并行度顺序提交。
在 Copy-on-Write 里面,需要根据表的数据量合理设置 Bucket 数,无需额外做小文件合并。
StreamWriter 在 snapshotState 阶段多并行度写入
- 增加 Buffer;
- 写入前需要判断上次 checkpoint 已经 commit 成功;
- 按 bucket 分组、合并,逐个 Bucket 写入。
FileCommitter 单并行度顺序提交
- table.newOverwrite()
- Flink.last.committed.checkpoint.id
8. 示例 - CDC 数据配置入湖
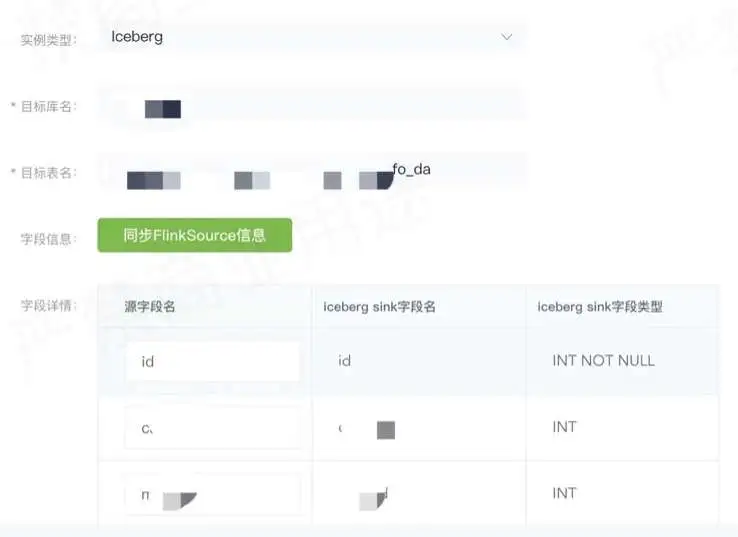
如上图所示,在实际使用中,业务方可以在 DTS 平台上创建或配置分发任务即可。
实例类型选择 Iceberg 表,然后选择目标库,表明要把哪个表的数据同步到 Iceberg 里,然后可以选原表和目标表的字段的映射关系是什么样的,配置之后就可以启动分发任务。启动之后,会在实时计算平台 Flink 里面提交一个实时任务,接着用 Copy-on-write sink 去实时地把数据写到 Iceberg 表里面。
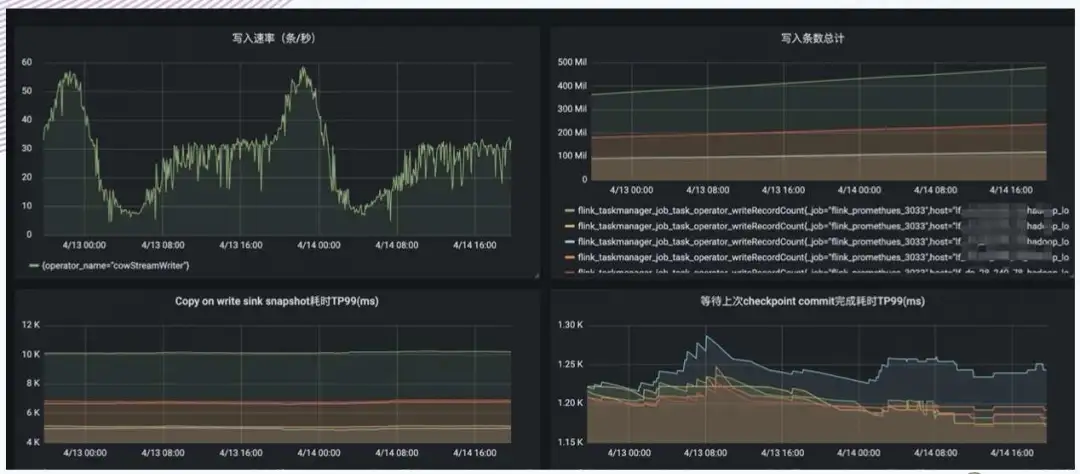
9. 入湖其他实践

10. 小文件合并及数据清理

11. 计算引擎 – Flink
Flink 是实时平台的核心计算引擎,目前主要支持数据入湖场景,主要有以下几个方面的特点。
数据准实时入湖:
Flink 和 Iceberg 在数据入湖方面集成度最高,Flink 社区主动拥抱数据湖技术。
平台集成:
AutoStream 引入 IcebergCatalog,支持通过 SQL 建表、入湖 AutoDTS 支持将 MySQL、SQLServer、TiDB 表配置入湖。
流批一体:
在流批一体的理念下,Flink 的优势会逐渐体现出来。
12. 计算引擎 – Hive
Hive 在 SQL 批处理层面 Iceberg 和 Spark 3 集成度更高,主要提供以下三个方面的功能。
定期小文件合并及 meta 信息查询:
SELECT * FROM prod.db.table.history 还可查看 snapshots, files, manifests。
离线数据写入:
- Insert into
- Insert overwrite
- Merge into
分析查询:
主要支持日常的准实时分析查询场景。
13. 计算引擎 – Trino/Presto
AutoBI 已经和 Presto 集成,用于报表、分析型查询场景。
Trino
- 直接将 Iceberg 作为报表数据源
- 需要增加元数据缓存机制: https://github.com/trinodb/trino/issues/7551
Presto
社区集成中: https://github.com/prestodb/presto/pull/15836
14. 踩过的坑

03 收益与总结
1. 总结
通过对�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B1%BD%E8%BD%A6%E4%B9%8B%E5%AE%B6%E6%B9%96%E4%BB%93%E4%B8%80%E4%BD%93%E6%9E%B6%E6%9E%84%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


