标签平滑深度学习解释了为什么标签平滑有用以及什么时候使用它
作者:Less Wright
编译:ronghuaiyang
转载自 AI公园
导读
标签平滑算是一种常规技术了,但是这背后的原理不知道大家有没有深究过,Google brain给出了他们的解释,并给出了一些使用它的SOTA的建议。
来自谷歌 Brain 的 Hinton, Muller 和 Cornblith 发表了一篇题为“When does label smoothing help?”的新论文,深入研究了标签平滑如何影响深度神经网络的最终激活层。他们建立了一种新的可视化方法来阐明标签平滑的内部效果,并对其内部工作原理提供了新的见解。标签平滑经常被使用,本文解释了为什么和标签平滑如何影响神经网络,以及何时使用,何时不使用的有价值的洞见。

使用了标签平滑在广泛的深度学习模型中都有提升。
这篇文章是对论文观点的总结,帮助你快速地利用这些发现来进行自己的深度学习工作。建议对全文进行深入分析。
什么是标签平滑?
标签平滑是一种损失函数的修正,已被证明是非常有效的训练深度学习网络的方法。标签平滑提高了图像分类、翻译甚至语音识别的准确性。我们的团队用它来打破许多 FastAI 排行榜记录:
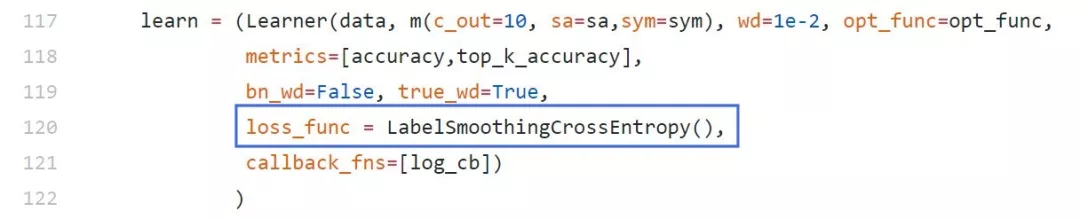
在我们的FastAI训练代码中调用了标签平滑
简单的解释是,它将神经网络的训练目标从“1”调整为“1-label smoothing adjustment”,这意味着神经网络被训练得对自己的答案不那么自信。默认值通常是 0.1,这意味着目标答案是 0.9(1 - 0.1)而不是 1。
例如:假设我们要将图像分类为狗和猫。如果我们看到一张狗的照片,我们训练 NN(通过交叉熵损失)向 1 表示狗,0 表示猫的方向移动。如果是一只猫,我们训练的方向正好相反,1 代表猫,0 代表狗。换句话说,这是一个 binary 或者说“hard”的答案。
然而,NN 有一个坏习惯,就是在训练过程中对预测变得“过于自信”,这可能会降低它们的泛化能力,从而在新的、看不见的未来数据上表现得同样出色。此外,大型数据集通常会包含标签错误的数据,这意味着神经网络在本质上应该对“正确答案”持怀疑态度,以减少一定程度上围绕错误答案的极端情况下的建模。
因此,标签平滑所做的就是通过训练 NN 向“1-adjustment”目标移动,然后在其余的类上除以这个 adjustment,从而使它对自己的答案不那么自信,而不是简单的设为 1。
对于我们的二分类猫/狗示例,0.1 的标签平滑意味着目标答案将是 0.90(90%确信)这是一个狗的图像,而 0.10(10%确信)这是一只猫,而不是先前的向 1 或 0 移动的结果。由于不太确定,它作为一种正则化形式,提高了它对新数据的预测能力。
可以看到,代码中的标签平滑有助于理解它如何比通常的数学运算更好地工作(来自 FastAI github)。ε 是标签平滑调整因子:

标签平滑的FastAI实现
标签平滑对神经网络的影响
现在我们进入文章的核心部分,直观地展示标签平滑对神经网络分类处理的影响。
首先,AlexNet 在训练中对“飞机、汽车和鸟类”进行分类。
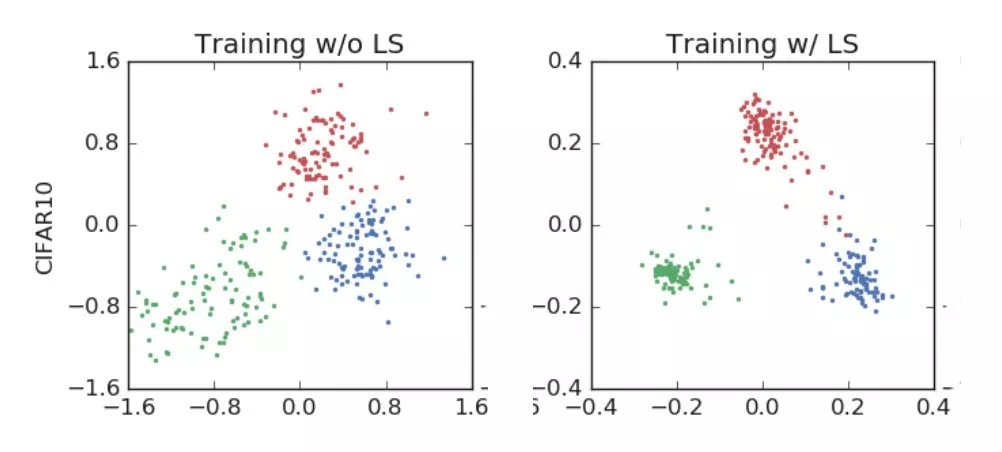
左:没有使用标签平滑进行训练,右:使用标签标签平滑进行训练
验证集上的表现:
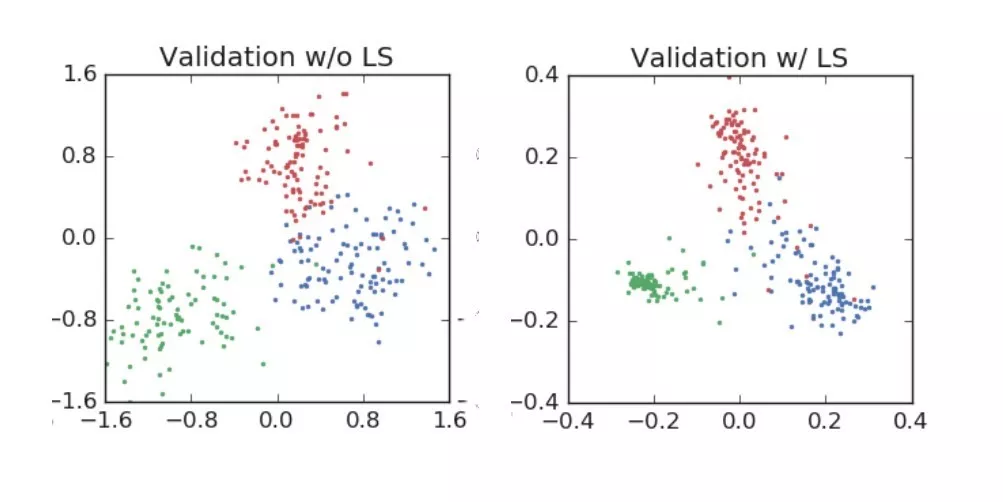
你可以看到的,标签平滑强制对分类进行更紧密的分组,同时强制在聚类之间进行更等距的间隔。
“河狸、海豚和水獭”的 ResNet 例子更能说明问题:
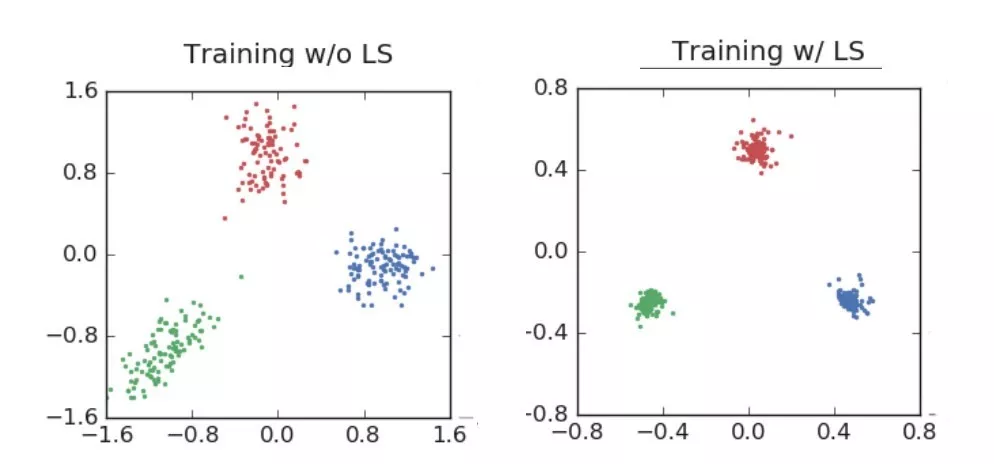
ResNet训练用于分类3个图像类别…请注意在聚类紧密性方面的巨大差异
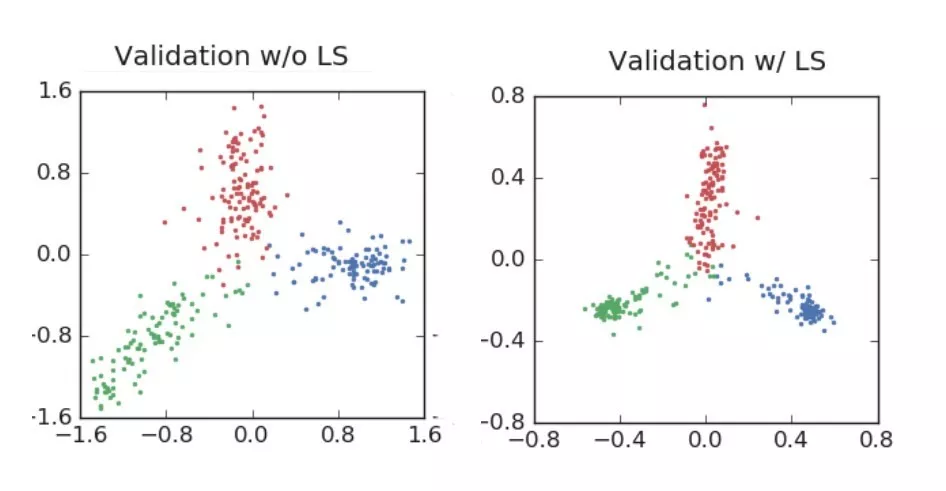
ResNet验证集结果,标签平滑提高了最终的精度。请注意,在训练中,标签平滑会将激活值驱动到紧密的簇中,而在验证集中,它会在中心周围传播,并充分覆盖了预测的置信度范围
正如图像所显示的,标签平滑为最终的激活产生了更紧密的聚类和更大的类别间的分离。
这是为什么标签平滑可以产生更多的正则化和鲁棒的神经网络的主要原因,重要的是趋向于更好地泛化未来的数据。然而,除了得到了更好的激活值的中心,还有额外的好处。
标签平滑的隐式网络校正功能
在本文中,Hinton 等人从可视化过程出发,展示了如何在不需要手动调节温度的情况下,自动校准网络,减少网络校准误差。
以前的研究(Guo et al)表明,神经网络常常过于自信,相对于它们的真实准确性校准得很差。为了证明这一点,Guo 等人开发了一种名为 ECE(预期校准误差)的校准度量。通过使用这种度量方法,他们能够使用一种称为温度缩放的训练后的修改器来调整给定神经网络的校准值,并使网络更好地与它的真实能力保持一致(减少 ECE),从而提高最终精度。(在传递给 softmax 函数之前,通过将最终 logits 与温度标量相乘来执行温度缩放)。
这篇论文展示了一些例子,但是最好的例子是在 ImageNet 上使用和不使用标签平滑训练的 ResNet,并将这两个网络与温度调整网络进行了比较。
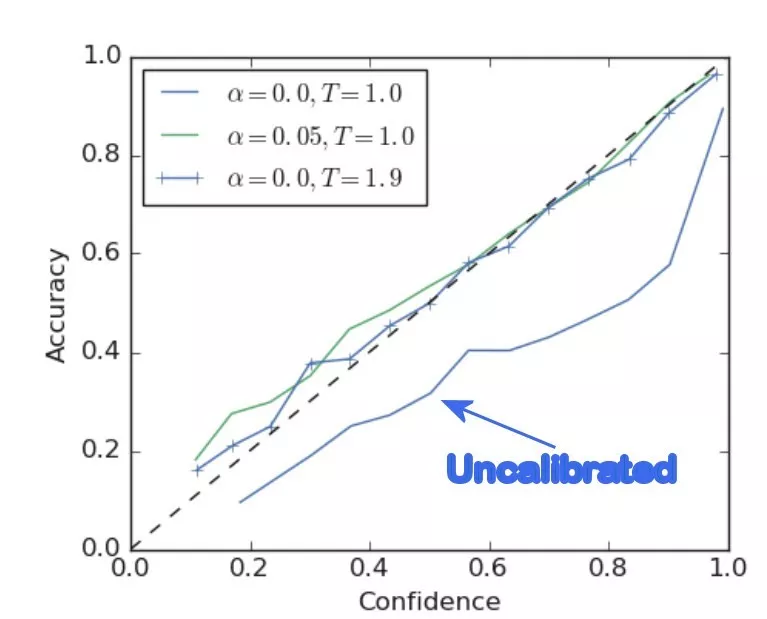
与未校准的网络相比,标签平滑极大地提高了置信度/准确率。其结果几乎与使用温度缩放进行手动调节相同。
正如你所看到的,使用标签平滑训练产生的网络具有更好的 ECE(预期校准误差),更简单地说,相对于它自己的精度有一个更理想的置信度。
实际上,经过平滑处理的标签网络并不是“过于自信”的,因此应该能够在未来的真实数据上进行泛化并表现得更好。
知识蒸馏(什么时候不使用标签平滑)
论文的最后一部分讨论了这样一个发现,即尽管标签平滑可以产生用于各种任务的改进的神经网络……如果最终的模型将作为其他“学生”网络的老师,那么它不应该被使用。
作者注意到,尽管使用标签平滑化训练提高了教师的最终准确性,但与使用“硬”目标训练的教师相比,它未能向学生网络传递足够多的知识(没有标签平滑化)。
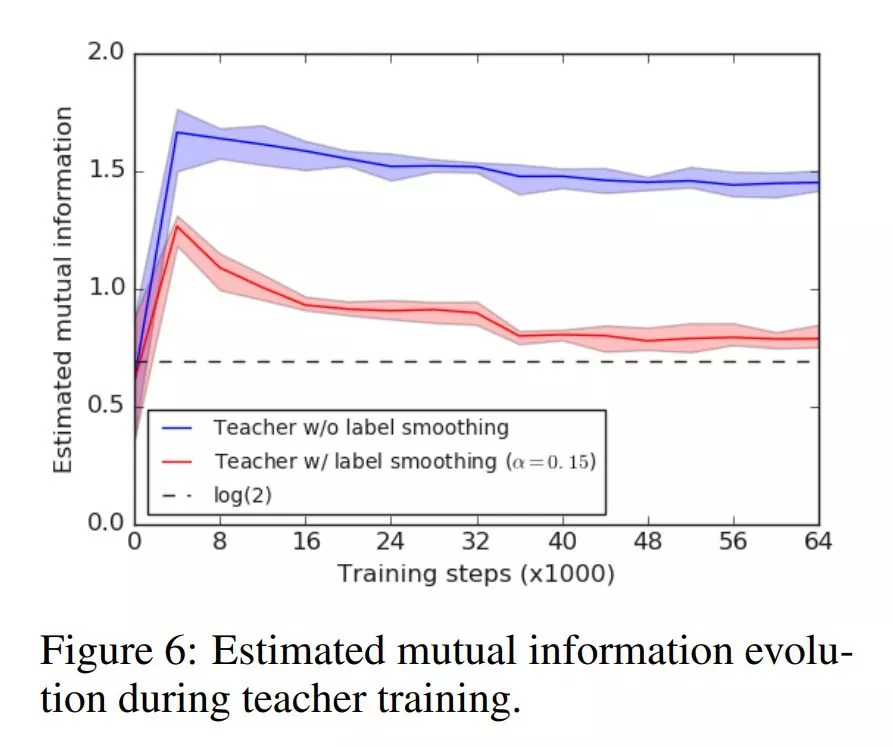
标签平滑“擦除”了在hard目标训练中保留的一些细节。这样的泛化有利于教师网络的性能,但是它传递给学生网络的信息更少。
标签平滑产生的模型是不好的教师模型的原因可以通过初始的可视化或多或少的表现出来。通过强制将最终的分类划分为更紧密的集群,该网络删除了更多的细节,将重点放在类之间的核心区别上。
这种“舍入”有助于网络更好地处理不可见数据。然而,丢失的信息最终会对它教授新学生模型的能力产生负面影响。
因此,准确性更高的老师并不能更好地向学生提炼信息。
总结
在几乎所有的情况下,使用标签平滑训练可以产生更好的校准网络,从而更好地泛化,最终对不可见的生产数据产生更准确的预测。因此,标签平滑应该是大多数深度学习训练的一部分。然而,有一种情况是,它对构建将来作为教师的网络没有用处,hard 目标训练将产生一个更好的教师神经网络。
英文原文: [https://medium.com/@lessw/label-smoothing-deep-learning-google-br
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%A0%87%E7%AD%BE%E5%B9%B3%E6%BB%91%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E8%A7%A3%E9%87%8A%E4%BA%86%E4%B8%BA%E4%BB%80%E4%B9%88%E6%A0%87%E7%AD%BE%E5%B9%B3%E6%BB%91%E6%9C%89%E7%94%A8%E4%BB%A5%E5%8F%8A%E4%BB%80%E4%B9%88%E6%97%B6%E5%80%99%E4%BD%BF%E7%94%A8%E5%AE%83/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


