构造对象一
来源: https://www.amazingkoala.com.cn/Lucene/Index/2019/1111/106.html
该系列文章将会介绍构造一个 IndexWriter 对象的流程,该流程总体分为下面三个部分:
- 设置索引目录 Directory
- 设置 IndexWriter 的配置信息 IndexWriterConfig
- 调用 IndexWriter 的构造函数
设置索引目录 Directory
Directory 用来维护索引目录中的索引文件,定义了 创建、 打开、 删除、 读取、 重命名、 同步(持久化索引文件至磁盘)、 校验和(checksum computing)等抽象方法,索引目录中不存在多级目录,即不存在子文件夹的层次结构(no sub-folder hierarchy),另外 Directory 的具体内容已经在 Directory 系列文章中介绍,这里不赘述。
设置 IndexWriter 的配置信息 IndexWriterConfig
在调用 IndexWriter 的构造函数之前,我们需要先初始化 IndexWriter 的配置信息 IndexWriterConfig,IndexWriterConfig 中的配置信息按照可以分为两类:
- 不可变配置(unmodifiable configuration):在实例化 IndexWriter 对象后,这些配置不可更改,即使更改了,也不会生效,因为仅在 IndexWriter 的构造函数中应用一次这些配置
- 可变配置(modifiable configuration):在实例化 IndexWriter 对象后,这些配置可以随时更改
不可变配置
不可变配置包含的内容有:OpenMode、IndexDeletionPolicy、IndexCommit、Similarity、MergeScheduler、Codec、DocumentsWriterPerThreadPool、ReaderPooling、FlushPolicy、RAMPerThreadHardLimitMB、InfoStream、IndexSort、SoftDeletesField,下面我们一一介绍这些不可变配置。
OpenMode
OpenMode 描述了在 IndexWriter 的初始化阶段,如何处理索引目录中的已有的索引文件,这里称之为旧的索引,OpenMode 一共定义了三种模式,即:CREATE、APPEND、CREATE_OR_APPEND。
- CREATE:如果索引目录中已经有旧的索引(根据 Segment_N 文件读取旧的索引信息),那么会覆盖(Overwrite)这些旧的索引,但注意的是新的提交(commit)生成的 Segment_N 的 N 值是旧索引中最后一次提交生成的 Segment_N 的 N 值加一后的值,如下所示:
图 1:
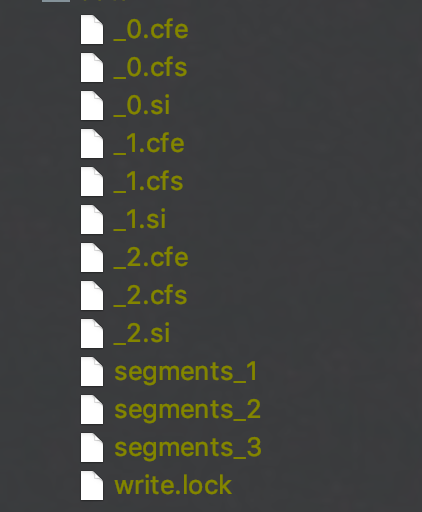
图 1 为索引目录中的旧的索引,并且有三个 Segment_N 文件,即 segments_1、segments_2、segments_3。
图 2:
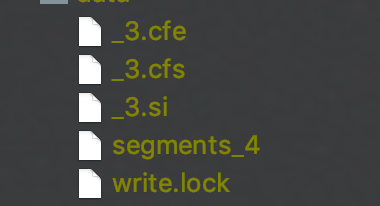
接着我们通过 CREATE 打开图 1 的索引目录,并且执行了一次 commit 操作后,可以看出旧的索引信息被删除了(_0.cfe、_0.cfs、_0.si、_1.cfe、_1.cfs、_1.si、_2.cfe、_2.cfs、_2.si 被删除了),并且新的提交(commit)生成的 Segment_N(segment_4)的 N 值是旧索引中最后一次提交生成的 Segment_N(segment_3)的 N 值加一后的值。
- APPEND:该打开模式打开索引目录会先读取索引目录中的旧索引,新的提交操作不会删除旧的索引,注意的是如果索引目录没有旧的索引(找不到任何的 Segment_N 文件),并且使用当前模式打开则会报错,报错信息如下:
throw new IndexNotFoundException("no segments* file found in " + directory + ": files: " + Arrays.toString(files));
上述的异常中,directory 即上文提到的索引目录 Directory,而 Arrays.toString(files)用来输出索引目录中的所有文件。
- CREATE_OR_APPEND:该打开模式会先判断索引目录中是否有旧的索引,如果存在旧的索引,那么相当于 APPEND 模式,否则相当于 CREATE 模式
OpenMode 可以通过 IndexWriterConfig.setOpenMode(OpenMode openMode) 方法设置,默认值为 CREATE_OR_APPEND。
IndexDeletionPolicy
IndexDeletionPolicy 是索引删除策略,该策略用来描述当一个新的提交生成后,如何处理上一个提交,在 文档提交之 commit(二) 的文章中详细介绍了几种索引删除策略,这里不赘述。
IndexCommit
执行一次提交操作(执行 commit 方法)后,这次提交包含的所有的段的信息用 IndexCommit 来描述,其中至少包含了两个信息,分别是 segment_N 文件跟 Directory,在 文档提交之 commit(二) 的文章中,我们提到了一种索引删除策略 SnapshotDeletionPolicy,在每次执行提交操作后,我们可以通过主动调用 SnapshotDeletionPolicy.snapshot()来实现快照功能,而该方法的返回值就是 IndexCommit。
如果设置了 IndexCommit,那么在构造 IndexWriter 对象期间,会先读取 IndexCommit 中的索引信息,IndexCommit 可以通过 IndexWriterConfig.setIndexCommit(IndexCommit commit) 方法设置,默认值为 null。
另外 IndexCommit 的更多的用法见 近实时搜索 NRT 系列文章。
Similarity
Similarity 描述了 Lucene 打分的组成部分,在 查询原理 系列文章中详细介绍了 Lucene 如何使用 BM25 算法实现对文档的打分,这里不赘述。
Similarity 可以通过 IndexWriterConfig.setSimilarity(Similarity similarity) 方法设置,默认使用 BM25。
MergeScheduler
MergeScheduler 即段的合并调度策略,用来定义如何执行一个或多个段的合并,比如并发执行多个段的合并任务时的执行先后顺序,磁盘 IO 限制,Lucene7.5.0 中提供了三种可选的段的合并调度策略,见文章 MergeScheduler。
MergeScheduler 可以通过 IndexWriterConfig.setMergeScheduler(MergeScheduler mergeScheduler) 方法设置,默认使用 ConcurrentMergeScheduler。
Codec
Codec 定义了索引文件的数据结构,即描述了每一种索引文件需要记录哪些信息,以及如何存储这些信息,在 索引文件 的专栏中介绍了所有索引文件的数据结构,这里不赘述。
Codec 可以通过 IndexWriterConfig.setCodec(Codec codec) 方法设置,在 Lucene7.5.0 版本中,默认使用 Lucene70Codec。
DocumentsWriterPerThreadPool
DocumentsWriterPerThreadPool 是一个逻辑上的线程池,它实现了类似 Java 线程池的功能,在 Java 的线程池中,新来的一个任务可以从 ExecutorService 中获得一个线程去处理该任务,而在 DocumentsWriterPerThreadPool 中,每当 IndexWriter 要添加文档,会从 DocumentsWriterPerThreadPool 中获得一个 ThreadState 去执行,故在多线程(持有相同的 IndexWriter 对象引用)执行添加文档操作时,每个线程都会获得一个 ThreadState 对象,DocumentsWriterPerThreadPool 以及 ThreadState 的具体介绍可以看文章 文档的增删改(中),这里不赘述。
如果不是深度使用 Lucene,应该不会去调整这个配置吧。。。
ReaderPooling
ReaderPooling 该值是一个布尔值,用来描述是否允许共用(pool) SegmentReader,共用(pool)可以理解为缓存,在第一次读取一个段的信息时,即获得该段对应的 SegmentReader,并且使用 ReaderPool(见 执行段的合并(二) 中关于 ReaderPool 的介绍)来缓存这些 SegmentReader,使得在处理删除信息(删除操作涉及多个段时效果更突出)、 NRT 搜索时可以提供更好的性能,至于为什么共用/缓存 SegmentReader 能提高性能见文章 SegmentReader(一)。
ReaderPooling 可以通过 IndexWriterConfig.setReaderPooling(boolean readerPooling) 方法设置,默认值为 true。
FlushPolicy
FlushPolicy 即 flush 策略,准确的说应该称为 自动 flush 策略,因为 flush 分为自动 flush 跟主动 flush(见 文档提交之 flush(一)),即显式调用 IndexWriter.flush( )方法,FlushPolicy 描述了 IndexWriter 执行了增删改的操作后,将修改后的索引信息写入磁盘的时机(实际是存入磁盘缓存,见 文档提交之 commit(一) 中关于 执行同步磁盘工作 的介绍)。
Lucene7.5.0 版本中,有且仅有一个 FlushPolicy:FlushByRamOrCountsPolicy,可以看文章 文档的增删改(中) 中关于 FlushByRamOrCountsPolicy 的详细介绍。
RAMPerThreadHardLimitMB
该配置在后面介绍
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%9E%84%E9%80%A0%E5%AF%B9%E8%B1%A1%E4%B8%80/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


