杨宇鸿腾讯多模态内容理解技术及应用

分享嘉宾:杨宇鸿 腾讯 内容理解高级工程师
编辑整理:吴祺尧
出品平台:DataFunTalk
导读: 搜索内容的理解贯穿了整个搜索系统。我们需要从多个粒度理解搜索内容,包括语义分块、核心要素提取、页面渲染等。多模态内容理解技术在其中扮演了重要角色,它可以从内容解析、内容质量检验、内容关系的挖掘以及内容属性的提取方面对候选内容进行更好的筛选与排序。今天分享的主题是多模态的内容理解技术在搜索中的应用。
今天的介绍会围绕下面七点展开:
- 通用搜索:内容理解体系
- 千亿规模大库的内容排序
- 细粒度图像语义向量的应用
- 多模态的内容质量识别技术
- 文档领域权威性识别
- 多模态的重复识别技术
- 未来展望
01 通用搜索:内容理解体系
首先和大家分享下在通用搜索的场景下如何做内容理解。
1. 内容理解体系
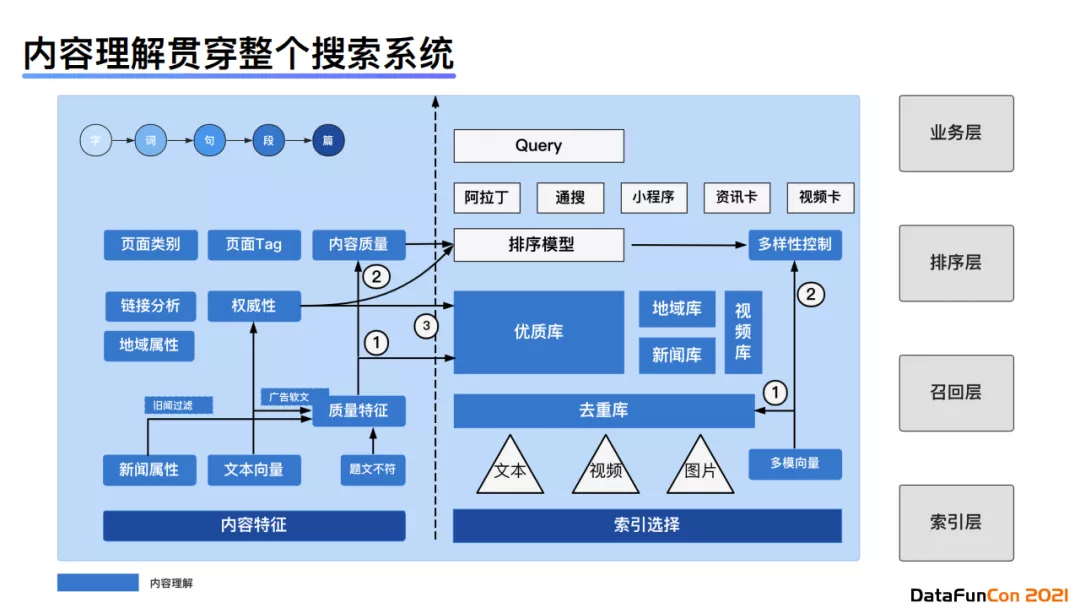
从上图我们可以看到,搜索内容理解可以分为两大块: 内容特征 和 索引选择 。我们会从千亿级别的大库中进行索引选择,形成一个去重的优质库、地域库、新闻库、视频库等。从内容特征出发,我们会分析字粒度、词粒度等从细到粗的分粒度建模,为排序模型提供多种特征。
比如,我们在构建内容时会使用语义表示来甄别相似内容,防止重复索引的建立。因为目前互联网上30%的内容都是重复的,我们没有必要在索引中浪费这种内存。其次,互联网中有20%的内容都是低价值的,我们也不需要对它们建立索引。那么从内容特征上来看,我们会构建标题和内容的匹配特征以及其他一些特征,建模判别图文不符或者题文不符的任务。
针对内容、属性和标签理解,我们会在篇章级别提取内容属性,比如我们可以用新闻属性构建新闻库,地域属性来构建地域库。通过页面的分类和页面tag的提取,我们可以将多个特征输入召回层和排序层。系统整体的目标是通过不同的内容特征保证优质内容的供给。
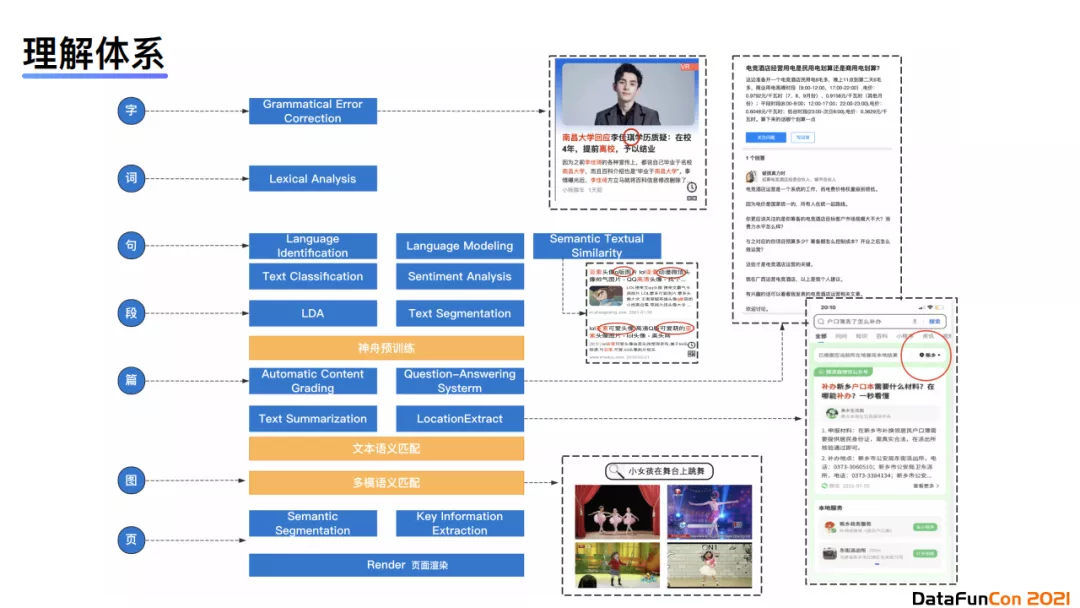
我们使用多个粒度对内容进行理解。
- 首先是 页面级别 的理解,它包含语义分块任务、核心要素提取任务以及页面旋绕任务。除了直接从文本或者html中做内容解析与内容提取,目前业界大部分会采用基于pattern或者基于正则表达式的方法,但是它们的泛化能力不够。所以就有人提出了基于视觉的方式做核心要素的提取。在不同页面上,核心要素的表现形式不一样,例如在问答页你需要提取问题,在通用页你需要提取页面的阅读数、点赞数、评论数等供排序阶段使用。
- 其次是 图片 的理解,主要是判断图片的质量、多模的语义匹配。我们通过深入理解图片和语义之间的关联关系,挖掘不同模态的互补性。
- 从 篇章级别 上,我们抽象出了几个NLP的任务,包括内容的分级、问答匹配、文本摘要抽取、文本属性提取、低于提取等。针对内容质量我们有一套详细的多维度评价方法,整体的目标是通过优化体验来提升用户对内容的评价。
- 对于 段落级别 ,由于多个段落通常会包含多种语义,所以我们建立了lda模型去理解每个段落的主题分布。我们也会使用序列标注模型来寻找文本中段与段之间的切分点。
- 接下来是 句子级别 的任务。在句子级别,我们会有小语种识别任务,因为搜索的内容来自于全网,会有一定可能会爬到如泰语等小语种网站。我们还有语句通顺度识别来判断内容质量,对那些机器生成的句子或者东拼西凑的内容进行剔除。文本相似度任务在搜索中也有相应的应用场景。比如在内容理解中,我们需要提出作弊标题,因为有些段落的分句与标题的分句十分相似。
- 在 字级别 的任务中,我们会有错别字检测任务,例如上图展示的例子中李佳琦的“琦”字就被写错了。我们可以通过基于BERT的序列标注模型进行识别。
2. 图文理解
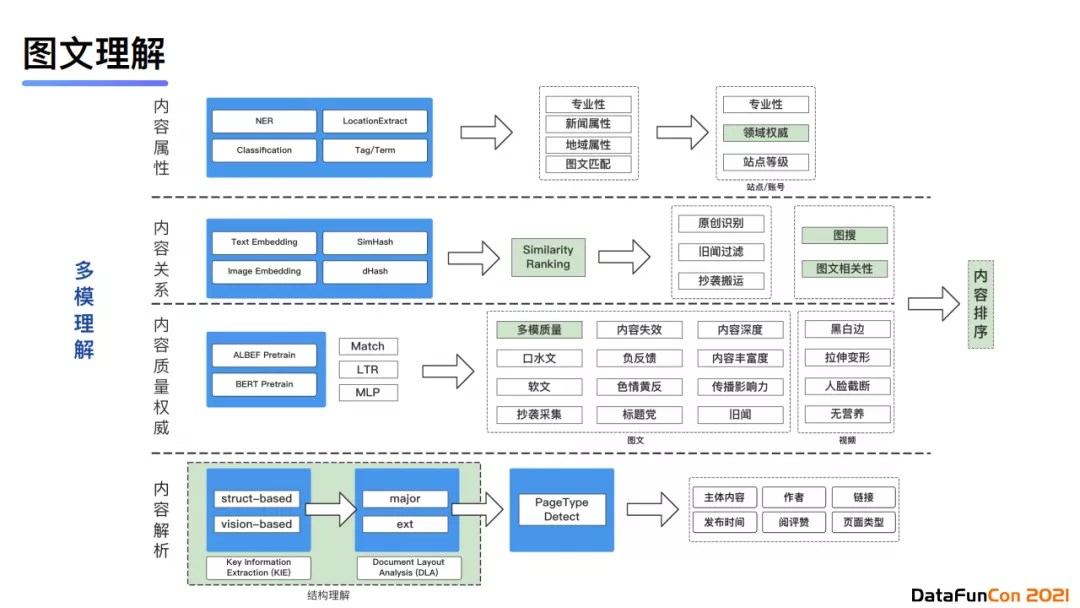
接下来我来介绍一下如何细化图文理解。首先,图文理解包含四个层次。
- 最底层是内容解析
它可以通过结构理解来实现。其中最典型的是KIE任务,即关键信息提取。另外,页面理解可以对应于Document LayoutAnalysis任务。在结构理解后,我们还需要对页面进行类型检测,比如判断这是一个资讯页,是一个问答页,是一个视频页还是一个论坛页。最后,我们会去提取页面的主体内容、名称、出链入链等。转评赞等信息可以在排序冷启动的时候进行使用,比如我们计算文档初始化的热度值。
- 第二层是内容质量权威性的预估
对于图文视频,我们会指定不同的质量标准来判断内容是优质文还是口水文,是否包含负反馈,是否包含软文,是否有违法内容,以及是否是“标题党”。在视频粒度下还会有黑白边识别、拉伸变形识别、人脸截断识别、无营养的识别等。
- 再上一层是内容匹配层次
我们进行图文匹配。比如标题和封面图、内容和封面图是否是匹配的。此外,我们还可以判断图片是否是一个最优封面图。我们还可以利用内容相似性进行排序。由于互联网上的内容会天然地将相似内容聚集在一起,使得排序的结果同质化严重,影响排序效率,进而影响NDCG指标。所以,我们会建立text embedding,image embedding以及其他一些浅层特征如图片的哈希,建立一个相似度预估模型。这一模型可以完成原创内容识别、旧文过滤、抄袭搬运的识别、投诉系统等任务。
- 最上是内容属性层面
我们会提取内容所属领域,比如识别内容的新闻属性、地域属性、站点权威性、站点等级等。
3. 视频理解
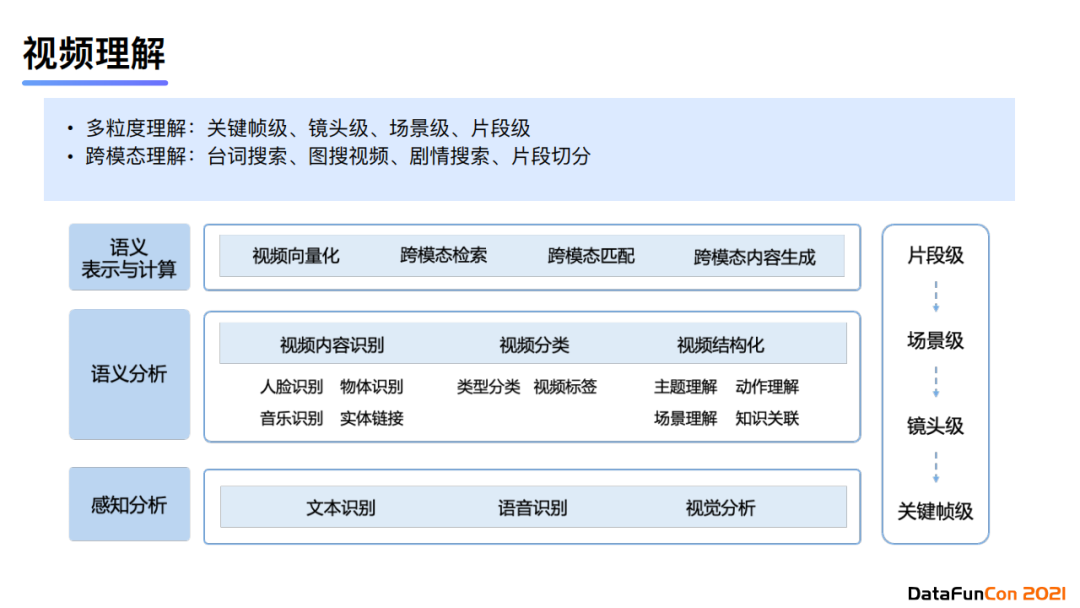
在视频理解中,我们也会多粒度、跨模态地进行内容理解。首先我们会细化理解粒度,分为关键帧级、镜头级、场景级、片段级。在跨模态层面可以分为台词搜索、图搜视频、剧情搜索、片段切分等。
4. 结构理解
接下来我重点介绍内容解析中结构理解的部分。

结构理解主要任务之一是页面解析,是一个非常重要的基础工作,它的主要目标是提取页面的关键部分,如正文、列表、问答等。常规的方法有基于模板的提取、基于html的提取以及基于css的提取,然后在后续处理中进行简单的数据清洗。目前比较前沿的方法是以计算机视觉模型为基础进行文档布局的理解。如果我们无法正确提取页面的文本内容,那么只做内容理解就会存在偏差。基于视觉的方法主要是用于模板匹配以及规则匹配失效的情况。目前有一个比较新的数据集,继承了约五十万条数据,可以用来训练辨别页面布局标注的模型。微软最近也发表了一篇文章,提出了LayoutLM,他们利用文本在页面布局下的普适性特征训练一个预训练模型。针对文档这种结构,模型会将其转化为一个序列。从上图左下角我们可以看到,数据集由类别C和文档D组成,模型的任务是将文档的token归类。预训练模型中会加入二维的位置嵌入,对应文本候选框的坐标。最后的输出和语言模型相似,会有一个CLS向量来表示整体的特征。
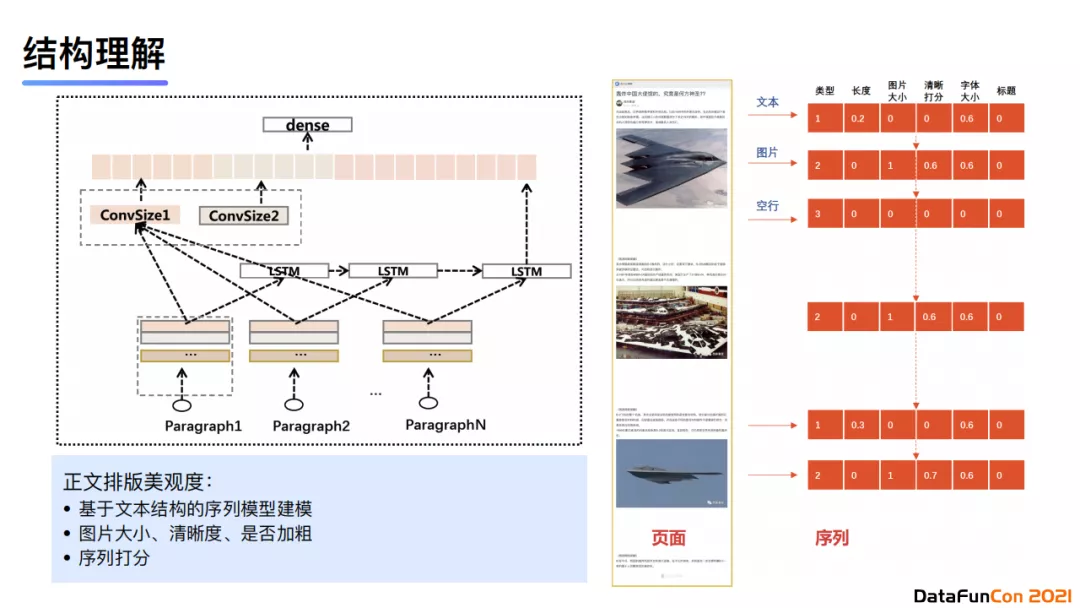
结构理解层面我们基于视觉模型做了正文排版美观度打分。我们使用LSTM+CNN进行建模,LSTM负责拟合文本序列的特征,使用CNN来提取局部特征。模型最后会将LSTM得到的特征和CNN得到的特征进行拼接,最后对序列依次进行打分。序列打分的维度有段落类型、长度、图片大小、清晰度、美观度等。通过这种方式,我们就可以尽量保证线上的内容排版质量,并且展现的尽可能是优质内容。
02 千亿规模大库的内容排序
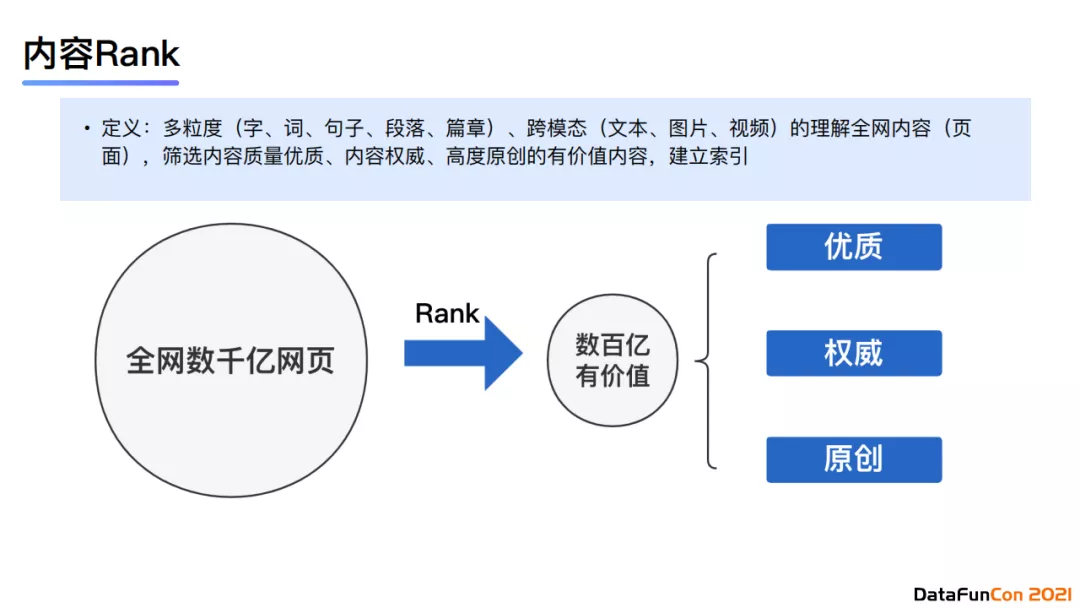
下面介绍一下我们如何在千亿规模的大库上做内容的排序。它属于多模理解这一层级,利用内容质量的权威性、内容关系以及大规模索引来筛选优质内容。内容排序是通过多粒度、跨模态地理解全网内容,筛选内容质量优质、内容权威、高度原创的有价值的内容,并对它们建立索引。上图展示了排序的流程图。排序的目标是筛选topN价值的内容,数量大约在数百亿的量级,全网候选内容则是在数千亿的量级。
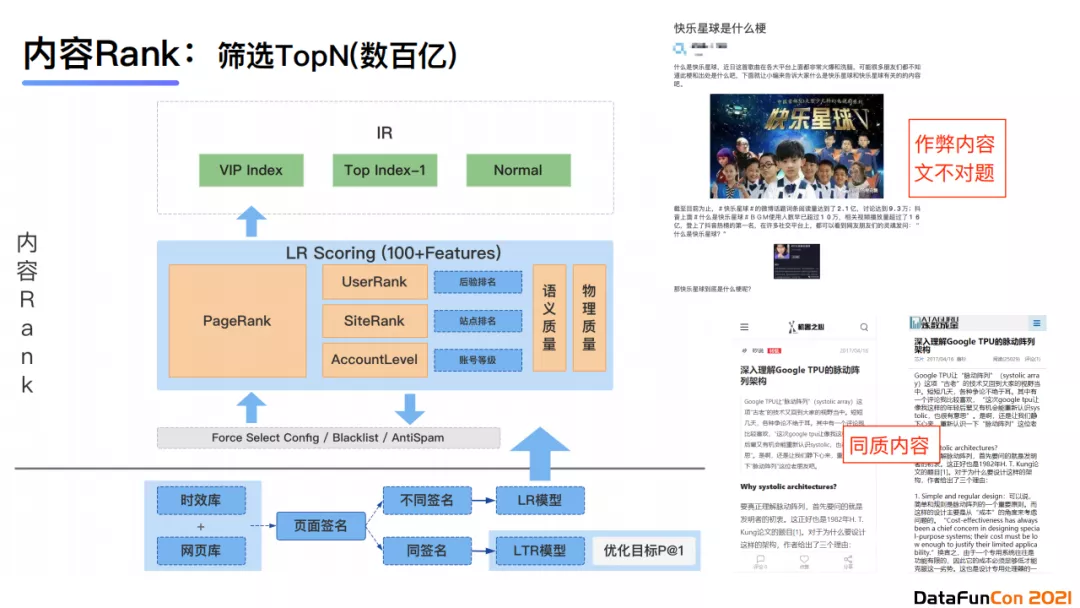
筛选的第一步是接入网页库。首先,面对千亿级别的网页,我们会进行内容前面计算,包括页面tag签名,最长句子签名等。对于同签名的内容我们会保留其中一条,使用的是LTR模型进行预估打分。具体地,我们使用优质内容作为正例,同一签名下的其他文档作为负样本,优化目标是整体的Top1准确率。对于不同签名的内容,它的优化目标则由页面多样性和查询满足性组成,构造的数据集来源于历史标注数据以及点击日志。我们使用LR模型,它接受的输入特征有约100维,其中较为重要的特征有page rank特征、user rank特征(后验排名)、site rank特征(整站排名)、站点排名等。这些特征联合内容质量和物理质量,使用LR模型对内容进行打分。最后我们可以选出排名靠前的数百亿内容,按比例放置在不同索引中。例如我们在索引召回时会先去使用VIP索引库,当VIP库已经满足召回数量时就不需要查询第二个库;只有当优质文档数量不满足要求时才会进一步查询二级库甚至三级库,最后是一个兜底库。我们从实验结果中可以发现,排序过程中剔除的典型页面时同质化且内容权威性不高的内容,以及一些文不对题的内容。针对文不对题的问题,我们也有一个大模型进行识别。
内容排序模型会根据不同的准确率需求来制定不同的策略。如果召回要求的准确率不是很高,例如80%以上,那么我们会对结果做体验评估。在满足体验且对相关性没有造成损失的情况下,模型就可以进行一次上线。
03 细粒度图像语义向量的应用

接下来给大家介绍细粒度图像语义向量在搜索中的应用。本质上来说,它属于内容理解体系中的内容关系层级。图像embedding可以用于检索,包括重复检索、实例检索和语义检索。它目前具有几点挑战。
首先,图片库的规模比较大,索引量从百万级上升至亿级别时,由于数据分布的变化,又因为基于空间的向量检索会对数据分布相当敏感,所以embedding的Top1准确率会有很明显的下降,不满足业务需求。
其次,检索需求是多样的,我们无法做到embedding的统一,即需要根据不同的业务建立不同的embedding。比如某些图片是语义相关的,另一些图片是风格相关的、局部相关的或者整体相关的。所以,我们建立了多标签粒度的图片语义来满足图像风格等不同的检索偏好。
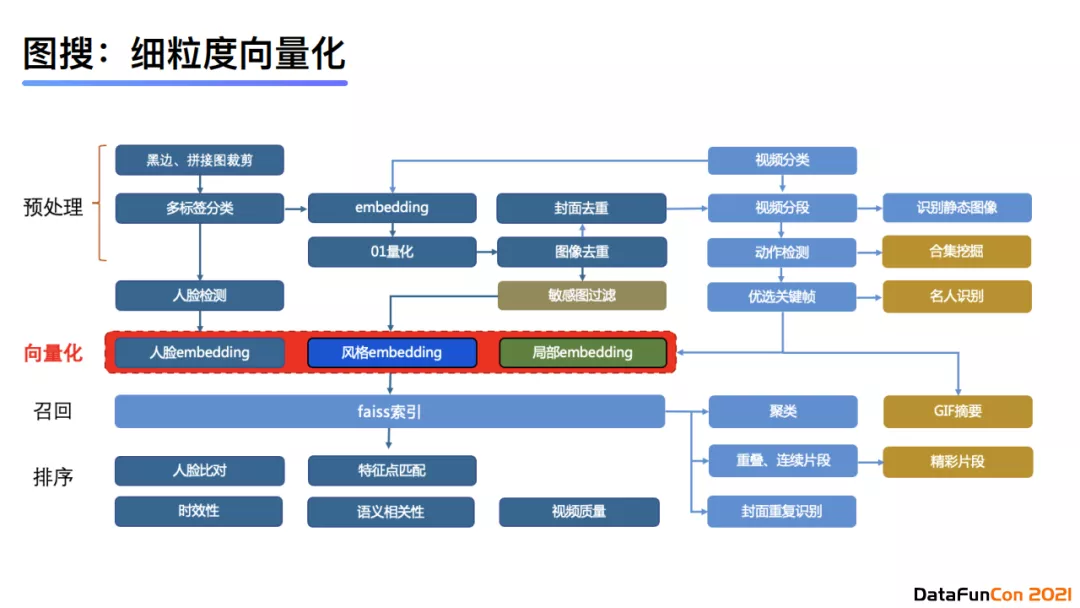
整体系统包含预处理阶段、向量化的索引、召回以及排序。预处理包括黑边、拼接图的裁剪、多样性的分类等。在线上使用时,我们会将embedding进行0-1量化来减少内存占用,但也会不可避免地导致表达embedding能力的下降。所以需要注意的是,我们会对成本与性能进行权衡,选择一个比较合适的应用方式。
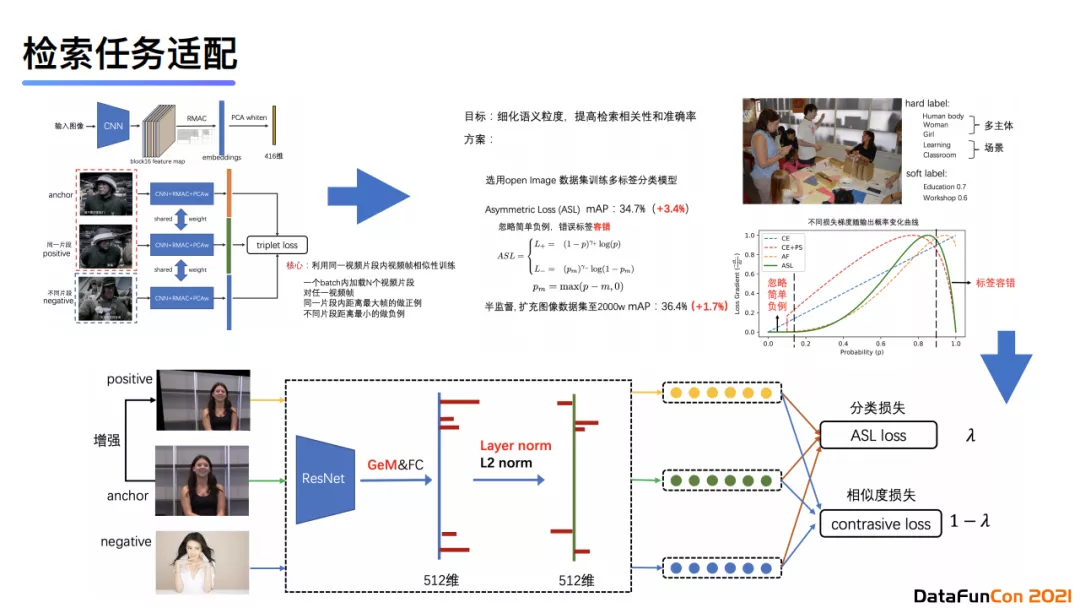
图像的检索embedding有两种技术路线:度量学习(即对比学习的方法)和传统的图像分类模型。我们的基线模型是基于ImageNet的预训练模型MobileNet。在对比学习中,我们是可以任意定义数据之间的相似标准的。在我们的案例中,训练数据中的正例来自于同一个视频片段,且这组图片是片段内距离最大的两帧;负例则来自于不同片段中距离最小的一组视频帧。

在使用ImageNet数据预训练了第一版模型后,我们发现由于ImageNet分类粒度低,会导致召回结果中人不区分男人、女人、老人、小孩,经常会出现男人召回女人,小孩召回成人的情况。此外,由于ImageNet只对主体进行分类,不区分背景场景,所以导致召回结果的场景差异很大。
基于上述问题,我们对模型进行了一次迭代。新模型基于Open Image数据集,其数据数量在千万级,总共包含两万多个标签,所以它与ImageNet相比规模更大、标签更为丰富,包含了多主体和场景信息。我们还对损失函数进行了优化,引入了非对称损失。当负例的输出概率超过一个较大的阈值时,损失函数的梯度会随概率的增大而减小,达到标签容错的目的。将分类任务运用至检索任务时,我们选择加入对比学习的方式对模型进行训练,那么整体的损失函数就包括了分类损失与相似度损失,兼顾分类精度以及检索任务中要求的embedding相似度。使用这种方法后得到的召回结果明显优于上一版的召回,比如从上图中可以看到多标签分类模型会在婚礼场景下召回正确的背景图。
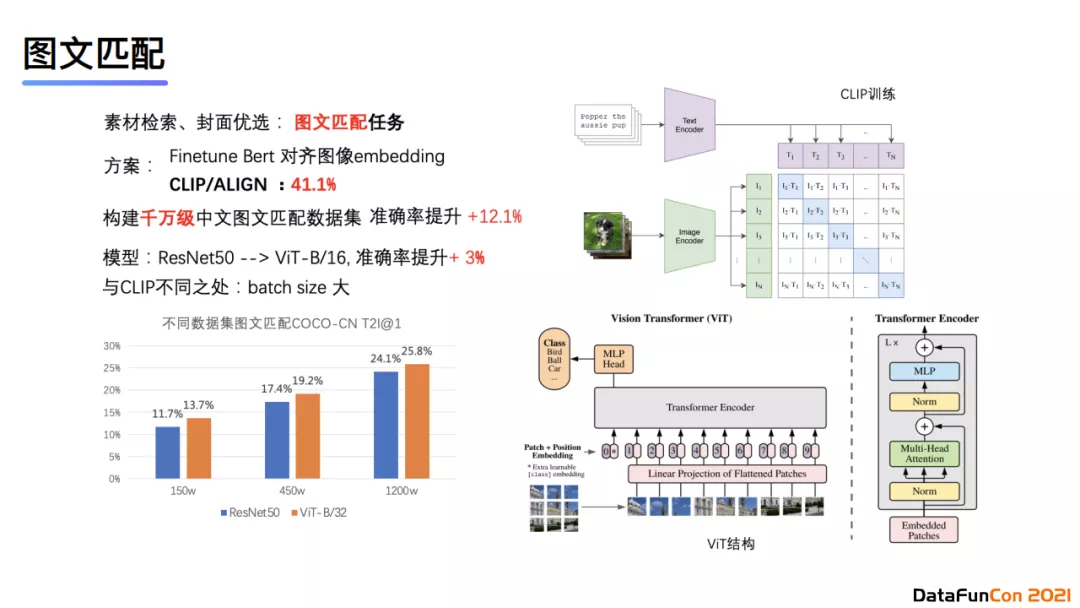
下面介绍有关图文匹配的工作。图文匹配任务适用于在素材检索、封面优选等应用。我们的第一版方案是对图片和文字分别进行特征提取,然后使用BERT将文字与图像embedding进行对齐。后面我们使用了VIT替换ResNet,并将训练数据集替换为千万级中文图文匹配数据集。使用自己构建的数据集的原因是目前业内还没有一个针对图文匹配的干净数据集,造成模型匹配效果不甚理想。经过改进后的模型的匹配准确率相较于第一版模型有很大的提升。
04 多模态的内容质量识别技术
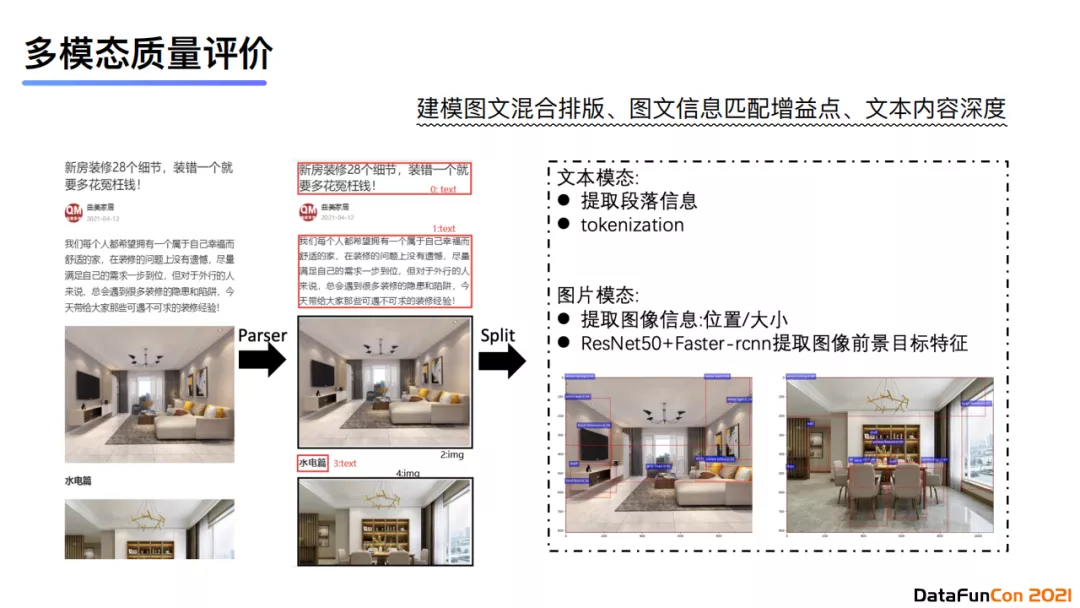
现在介绍我们在搜索中是如何应用多模态的内容质量识别技术的。首先,我们需要建模图文混合排版、图文信息匹配增益点以及文本内容深度。那么针对图片模态,我们使用比较大的RCNN来提取图像位置与大小信息,提取图像前景目标特征;对于文本模态,我们会提取段落信息并实现tokenization。
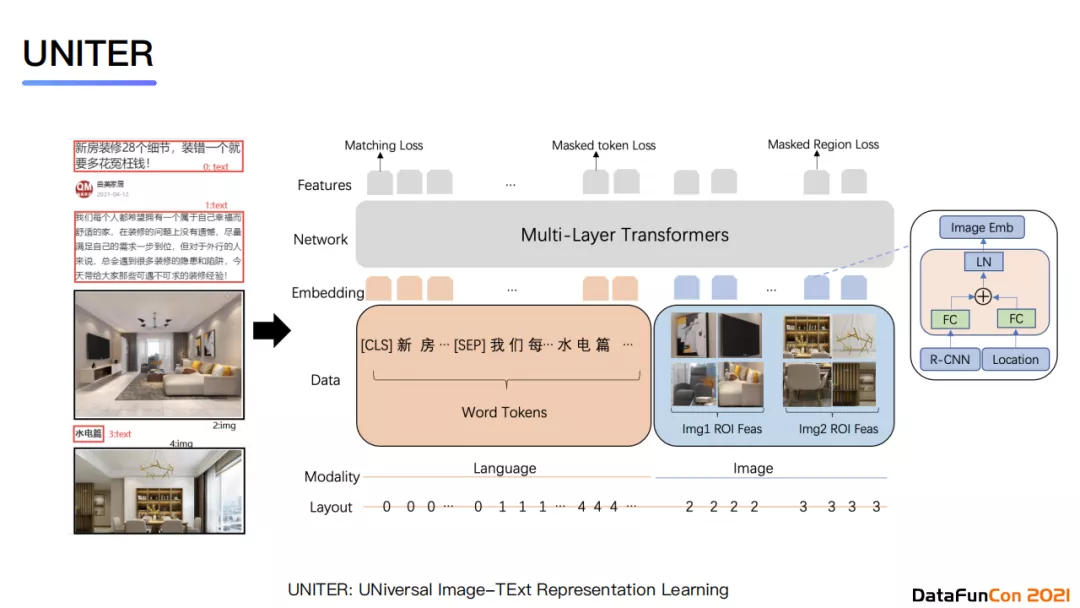
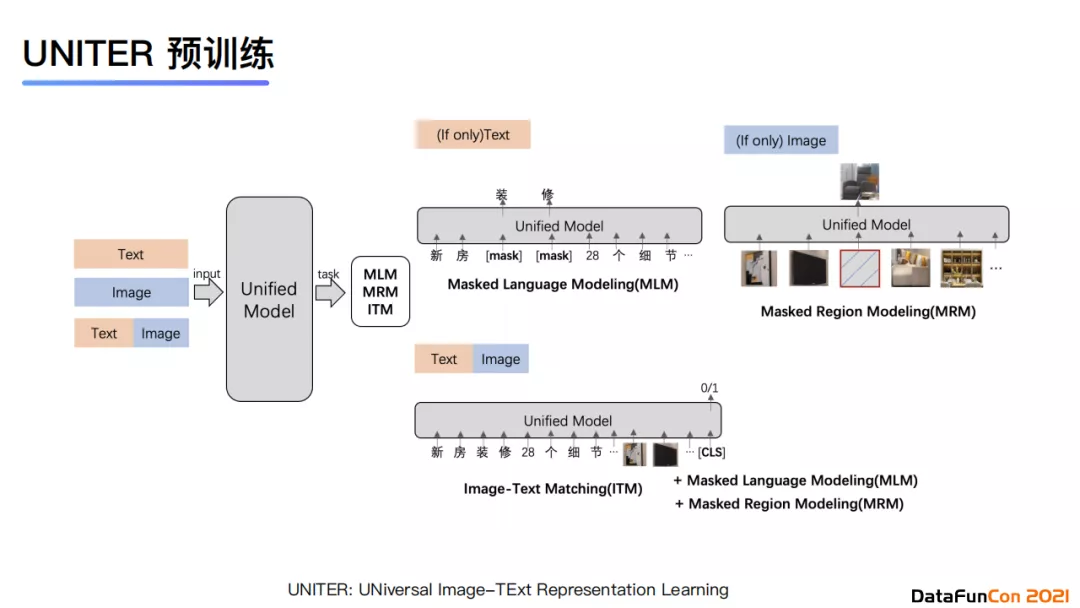
双模态联合建模使用的是UNITER模型,它的优化目标是多种损失函数的组合,包含图文匹配的matching loss、恢复图像像素的masked region loss以及恢复token的masked token loss。模型的输入包含图像与文字模态。其中文本会使用段落与标题,不同内容会使用[SEP]进行分隔,使用token的形式进行输入;图像则使用ROI特征。最终,图文匹配的输出会使用文本与图像部分的[CLS]输出向量进行计算。
在实验中,我们使用了约7000万的训练数据,包含纯文本数据、纯图片数据以及图片文本混合数据,其中图文数据约有5000万。从实验结果上来看,我们的模型相较于基线在AUC指标上有了12%左右的提升。
05 文档领域权威性识别
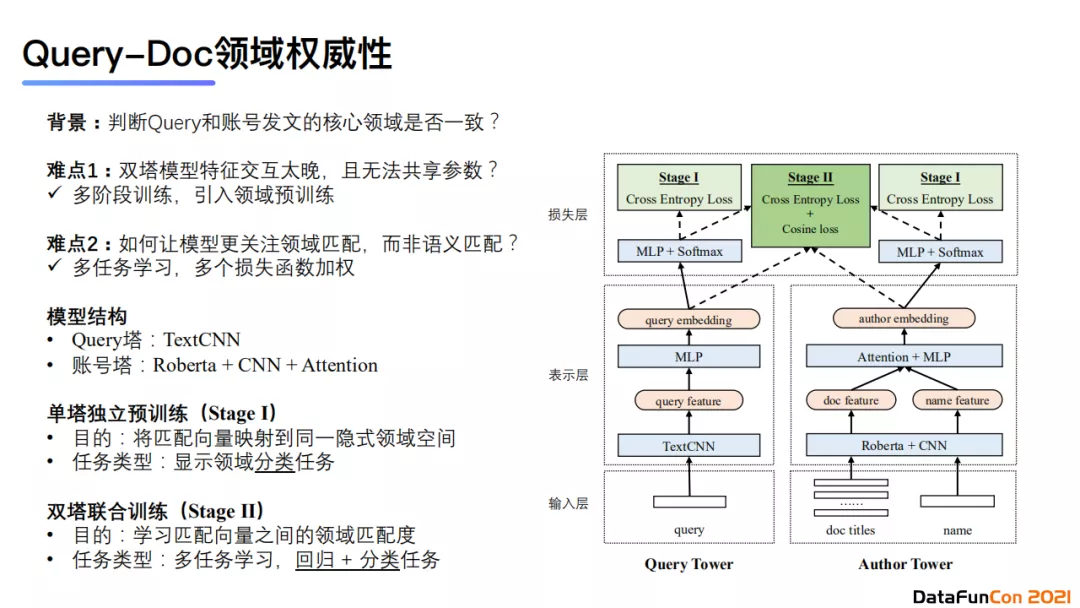
文档领域权威性识别属于内容理解中的内容属性层级。我们提出这一任务的背景是想判断query和账号发文的领域是否一致。这一任务有两大难点。首先,双塔模型特征交互太晚,无法共享参数。我们的解决方案是使用多阶段训练的方法,首先先对两个塔分别进行单独的预训练。具体地,query塔会使用TextCNN进行文本分类任务的预训练,而author塔会使用 Roberta + CNN + Attention 建模文本与作者的特征,对领域进行分类预训练任务。在第二阶段,我们会做双塔联合训练进行特征融合,目的是为了学习匹配向量之间的领域匹配度。
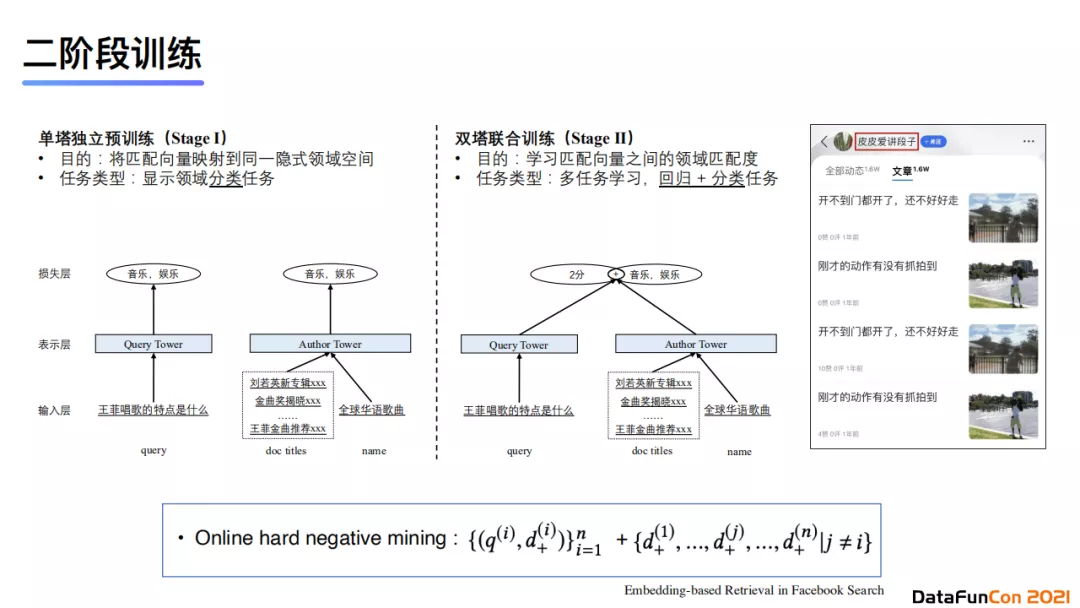
我们在训练中会借鉴online hard negative mining的方法,将负样本设置为得分与正样本最相近的几个doc,使得数据质量更加好,进而促使模型学习到更具区分度的特征。
06 多模态的重复识别技术
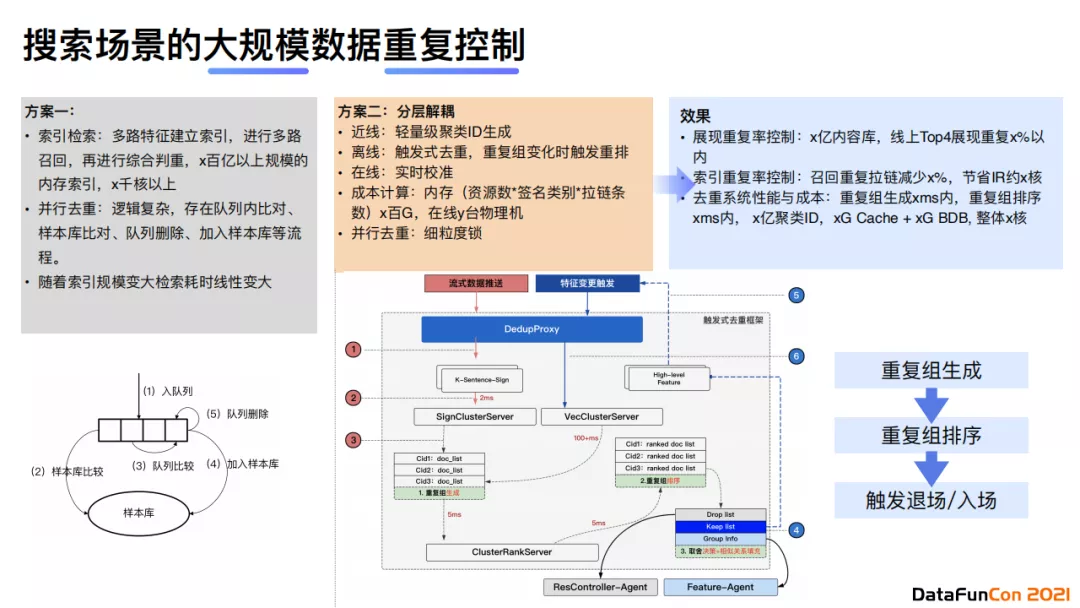
最后,我来介绍一下搜索场景下的大规模数据重复识别技术。它属于内容理解中的内容关系层级。我们建立了多种方案来解决大规模数据重复控制,整体流程包括:重复组生成、重复组排序、触发退场/入场。当特征发生变更的时候,我们会触发一次轻量级特征计算。如果我们在每次特征变化时都实时计算如图片向量等重量级特征并进行重排序的话,那么计算耗时非常大。具体地,我们的解决方案是一种二阶段范式,首先我们实时计算浅层轻量特征,再在第二阶段加入重量级特征进行召回,最后使用similarity ranking的方式进行排序。
最后我们需要判断哪些内容需要被淘汰。目前线上有30%的内容是重复的,我们的目标是控制展现重复率和索引重复率。经过线上实验,我们发现通过这样一个二阶段范式,系统的性能有了一定程度的提升,同时存储成本大大降低。
07 未来展望
从整体上来看,正如2018年图灵奖获得者Yann LeCun所说,深度学习的趋势是大规模无监督训练,它是“蛋糕”的本质,而强化学习或者监督学习只是“蛋糕”表面的一小部分。所以未来我们需要考虑无监督学习技术应该如何促进多模态场景下不同领域之间的知识的交互,从而进一步提升性能。
08 精彩问答
Q:对页面是如何做语义分块的?
A:首先可以基于css渲染来进行分块。因为页面经过css强渲染后我们是可以得到原生的页面分块形式,使用html结构分析就可以拿到文本数据。其次,我们还可以使用链接密度来衡量分块的类型,比如链接密度较大就有可能是索引列表。通常来说,强渲染的情况下分块准确率都比较高。当我们想要提取正文主体内容时,采用的是噪声标签排除法,余下的高密度的主体部分就会是我们的目标内容。另外一种比较前沿的方法是基于视觉模型进行语义分块,由于现有技术是基于传统的基于规则或机器学习方法提出的,其中大多数无法很好地泛化,因为它们依赖于手工制作的特征,可能对布局变化不稳健, Vision 极大地推动了基于图像的方法的文档布局分析,根据 OCR 获得的文本边界框,能获取文本在文档中的具体位置,结合坐标转化为虚�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%9D%A8%E5%AE%87%E9%B8%BF%E8%85%BE%E8%AE%AF%E5%A4%9A%E6%A8%A1%E6%80%81%E5%86%85%E5%AE%B9%E7%90%86%E8%A7%A3%E6%8A%80%E6%9C%AF%E5%8F%8A%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


