来也技术向量检索使用场景和关键技术
深度学习可以对物理世界的人/物/场景所产生各种非结构化数据(如语音、图片、视频,语言文字、行为等)进行抽象,变成多维的表示向量。
物理世界的关系可以通过表示向量的距离数学运算得到。

一.向量检索的意义
深度学习最重要的作用就是“表示学习”【1】,简单来说,就是把对象通过深度模型表示成一个稠密的向量,这个向量可以可以反映出这个对象的核心特征。
举例来说:在NLP的任务“相似语义判断”中,传统的做法是对文本做各种特征工程如分词、N-Gram等将文本变成的Token集合,然后再计算不同文本的Token集合中相同Token数量占比作为文本语义相似度,更复杂一些可以根据Token的频率的权重等给Token赋予权值(如典型的TfIdf),这种做法最大的问题就是文本表示成的Token集合在很多情况下无法捕获对象的核心特征。
如以下三句话:
- “中国首都占地16410.54平方千米”
- “北京面积16410.54平方千米”
- “北京面积多少平方千米”
如果按照传统的分词为Token的表示方法,三句话的Token表示为:
- [“中国”,“首都”,“占地”,“16410.54”,“平方千米”]
- [“北京”,“面积”,“16410.54”,“平方千米”]
- [“北京”,“面积”,“多少”,“平方千米”]
很明显的是后两句相同Token占比更高,但是前两句语义更相似。由此可见,基于这种传统的特征表示的应用会如搜索引擎会碰到准确率不高等问题。
而在深度学习中,会这三句话表征为相同维度的稠密向量,基于足够的数据、训练和良好的模型设计,最终前两个向量的 L1距离 会小于后两个向量的 L1距离 ,也就是说通过向量的距离比较就得到语义相似的文本,如果在一个超大规模的表示向量上,搜索与输入距离最近的向量我们称为向量检索。
二.向量检索的使用场景
如果在一个技术方案中,存在寻找“相似”的场景,那么这个场景就有可能使用向量检索的技术方案,举例如下:
1.依图搜商品
现在很多购物应用如淘宝的拍立淘【2】,可以支持拍照搜索商品。底层的基本原理,先对商品库的商品SKU海报图片通过深度学习模型M编码成向量Vi [i∈N N所有图片],用户在线搜索时将用户的输入图片通过模型M编码得到x,从Vi中得到和x最相近的向量对应的SKU,就可以认为是搜索的物品。
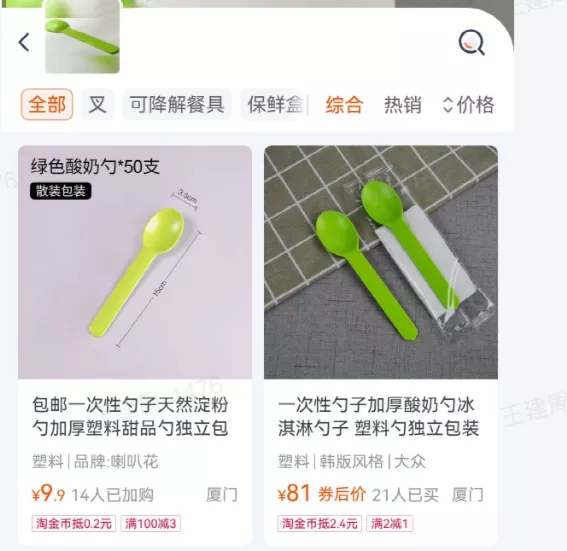
图片来源:淘宝App
2.依图搜索视频
现在一些视频应用可以支持用截图搜索视频(如有张电影的截图希望得到属于那部电影)。底层的基本原理,先对视频抽取关键帧,就可以将视频转为关键帧图片,然后做法和依图搜索商品一样,这里的SKU就是视频,关键帧就是SKU的多张海报图片。
3.文本检索
传统的搜索引擎基本上是基于关键词term的匹配策略做召回,很难做到语义上的匹配,基于深度学习和向量检索可以实现语义搜索引擎,底层的基本原理是,先将文档逐段、逐句拆分,对拆分的文本利用深度学习模型M编码成向量Vi [i∈N N所有拆分的文本],用户在线搜索时将用户Query通过模型M编码得到向量x,从Vi中得到和x最相近的向量对应的文档,就可以认为最相似的文档。
上边这三种检索,可以认为是同构物品检索(Query和检索的物品属于统一类,两类可以用同一个模型产生表示向量)。
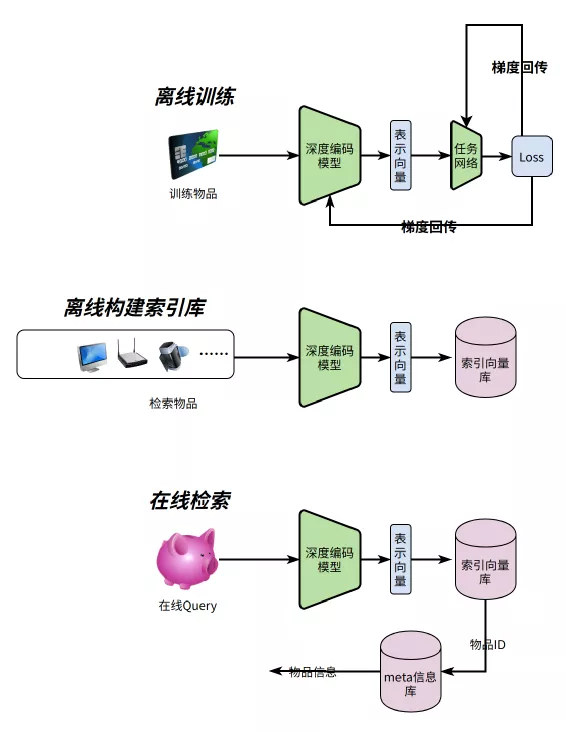
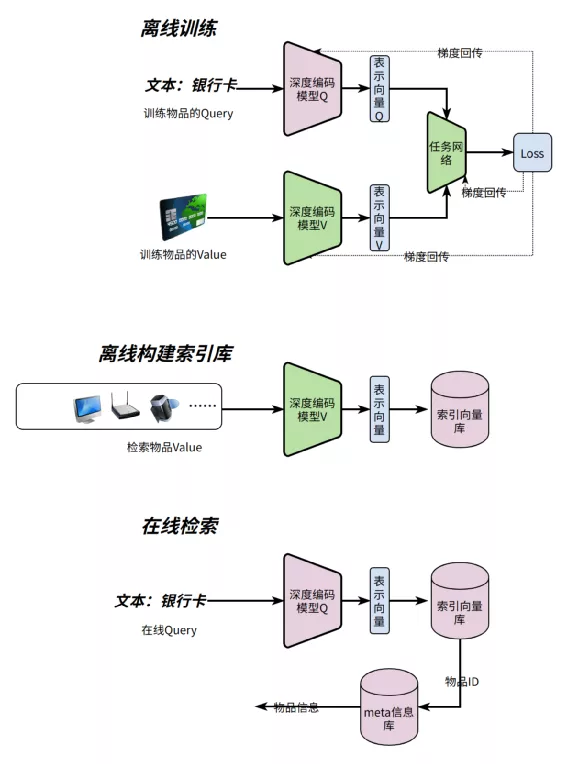
同构搜索的工作模式可以用下图表示,一般是三个步骤:
- 离线训练阶段 :主要是训练深度编码模型
- 离线构建索引库 :主要是用训练好的深度编码模型,对所有物品进行编码后保存到向量索引库
- 在线查询 :将Query通过深度编码模型得到编码向量,取编码向量与索引向量库中距离最近的向量对应的物品ID,再通过物品ID去物品Meta库查询业务需要的Meta信息
一般在步骤3中,距离计算采用L1算法【3】,所以计算的向量要经过L2归一化【4】,保证L1距离的公平性。
这三类的原理如下图:
除了同构物品检索,向量检索还可以用在异构物品检索场景,如下:
4.个性化推荐
在个性化推荐中Query 是用户,查询的对象是推荐物品(如商品、音乐、视频)。底层的原理是对用户采用深度学习模型Mu进行向量表示得到VUi [i∈N N所有用户],对物品采用深度学习模型Mp进行向量表示得到VPi [i∈M M所有物品],其中VUi和VPi维度一样, 在线推荐时查询VUi得到用户的表示x,从VPi中得到和x最相似的向量对应的物品作为推荐结果。
5.文本搜图
传统的用文本进行图像搜索,并没有对图像的真实内容做理解,而是利用图片的标题,图片所在文档中附加文本等,对这些信息和用户的Query进行第一节传统NLP计算得到搜索结果。这种做法有两个问题:一是图片附加文本信息可能是错误的,此外还有绝大多数图片都没附加文本从而无法被搜索。现在基于深度模型的文本搜图可以很大程度上解决这两个问题,底层原理如下:利用标注的图片和描述文本对,联合训练图片深度编码模型MI和文本编码模型Mt,两个模型输出的向量维度一样,利用训练好的MI将所有图片进行向量表示得到VIi [i∈M M所有图片],在线上搜索是将用户Query用Mt进行编码得到xt,从VIi 中得到和xt最相似的图片作为搜索结果。
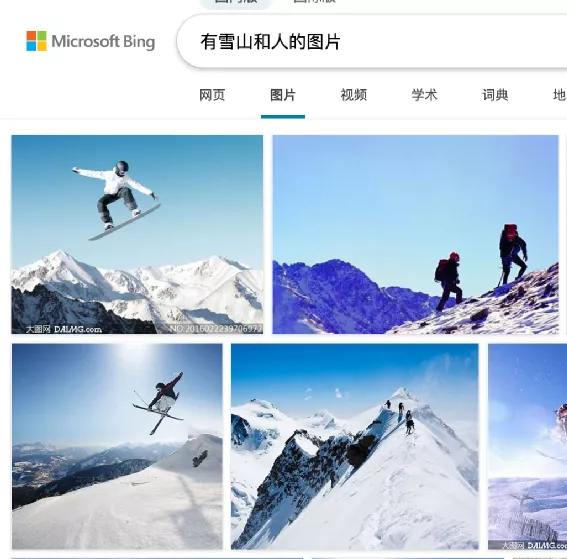
图片来源:微软Bing搜索
6.搭配搜索
不同于2.1提到的拍照搜SKU,在一些应用如Pinterest中【3】,用户的需求是搭配搜索,比如用户的输入可能是一个裤子的照片,希望的搜出的结果是和裤子搭配的鞋子、上衣等SKU。
底层原理如下:
利用标注配对SKU的图片分别用两个模型M和H联合训练,利用训练好的M将所有SKU图片进行向量表示得到Vi [i∈M M所有图片],在线上搜索是将输入图片用H进行编码得到xh,从V_i中得到和xh最相似的图片对应的SKU作为搜索结果。
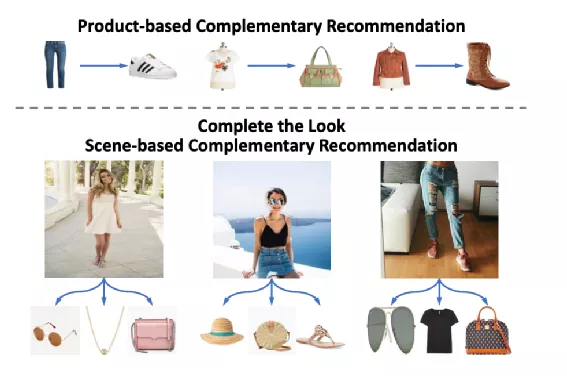
图片来源: https://arxiv.org/pdf/1812.01748.pdf
异构物品检索工作模式可以用下图表示,和同构召回不同的有3点:
- 对训练数据中的Query和Value采用两个不同的深度编码模型MQ和MV
- 离线构建索引时,采用深度模型MV编码所有需要被召回物品
- 在线查询时,Query采用深度模型MQ编码
三.向量检索需要解决的问题
通过第二节能看出,在业务场景使用向量召回,需要解决以下两个问题。
1.优秀的向量特征表示
需要设计出良好的深度表示模型,此模型对物品产生的向量需要满足相似物品的距离近,不相似物品的距离远,目前对物品进行一个良好的特征表示的方向称为”度量学习(metric learning)",无论在学术界还是工业界都是前沿的研究方向。
一般情况下,如果提供的数据带有标签信息,可以采用有监督模型,如分类模型,可以采用分类网络softmax前的输出向量作为表示:
考虑如下情况,一个N分类的模型,模型的最后一层是dXN(d为这层的输入向量维度)的矩阵,对于这层的所有行1xd向量,可以认为是N个分类的特征向量 。对于一个输入,这层输出的1XN Vi向量就可以认为是输入的物品和所有N类物品的N个相似度得分(向量点积得分),这个Vi就可以很好的表示出输入物品的特征。
也可以采用对比Loss如TripletLoss ,通过刻意拉近相似物品的向量L1距离来设计监督模型,TripletLoss 计算公式如下:
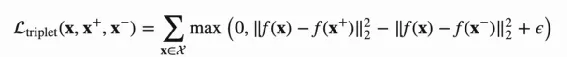
绝大多数情况下,大多数训练数据都是不带有标签数据的,在这种情况下,可以采用自监督网络,通过挖掘训练数据自身的特征关系,从而对物品进行一个良好的特征表示。
在向量表示的模型设计上,以前已经发布过两篇文章供学习:
本文不再做过多阐述。
2.高性能的向量检索算法
向量检索场景一般都是用于在线查询场景,需要满足高吞吐量、低延迟等目标,而向量的距离计算又是一个时间复杂度非常高的场景。
假设一个1亿的向量库,向量的维度为128维,那么简单通过L1距离求输入V的最近向量的计算量为:128X1亿。
虽然现代的硬件技术通过并行计算指令流来进行大幅加速,但是优化的时间复杂度和固定硬件的吞吐量依然无法满足在线查询的需求,所以各种高性能的向量检索算法成为一个研究的热点,本文将对常用的向量检索算法进行详述。
四.向量检索算法简介
目前在工业界被大规模用到的向量检索算法基本可以分为以下3类:
- 局部敏感性哈希(LSH)
- 基于近邻图
- 基于乘积量化
在寻找合适算法时,一般会用Top K的召回率来衡量检索算法的性能,召回率越高性能越好,假设通过全量计算得到距离最近的K个元素为集合M,通过检索算法召回距离最近的K个元素为集合N,那么召回率的计算公式如下:
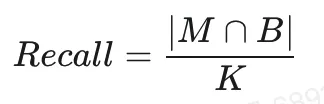
|*|代表求数量
1.局部敏感哈希算法(LSH)
LSH算法的核心思想是:找到一个Hash函数,希望以前空间相近的两个向量通过Hash函数得到签名一致(或者二进制表示下汉明距离很小【8】),不相邻的向量得到签名不一致。
LSH的算法较多,一般常用的有以下两种:
1.随机超平面投影
随机超平面投影基于一个原理:在欧式空间,距离相近的高维向量被投影到低维向量空间后,依然接近,当然不相近的向量投影后的向量可能会接近,如下图所示,红、绿、蓝、黑在二维空间分别被投影到三个一维空间直线上,符合上边的原理。
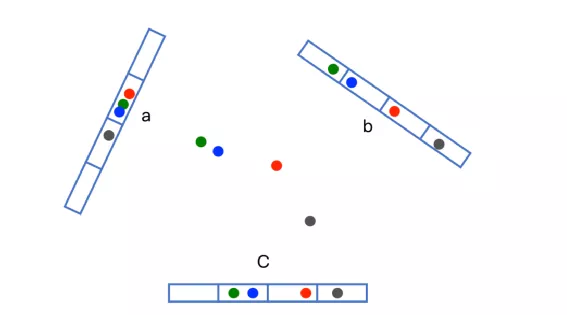
图片来源:极客时间:深度学习推荐系统实战
在数学上的计算公式如下:
对于原始高维向量v,假设向量维度为k,可以随机生成一个经过均值为0、标准差为1、k维的正态分布向量x作为新的低维投影向量,那么在这个新维度投影的结果可以通过以下公式计算:
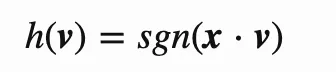
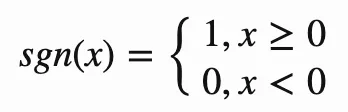
通过这个计算,将原始的向量变成一个bit,在实际使用中,为了有更好的召回率,一般会根据数据规模选择b个投影向量,这样原始的k维向量就会变成b维(在工程实现中, 为了利用现代硬件的并行计算能力,不是上述公式计算b次,x不再是一维,x而是一个b✖️k的矩阵,只需要经过一次矩阵乘法和一次非线性变化即可)。
在线使用时,将query经过同样变化,变换后新的b维向量和向量库的向量如果一样,那么可以认为原始的k维向量v很相似。
2.Simhash
Simhash 被人所知是google用在网页去重中,由于网页数据巨大,单纯比较原始内容计算量太大,所以需要通过hash算法得到一个较短的网页指纹,传统的hash算法会出现敏感度雪崩,如果两个网页内容有一个标点不一样,那么这两个网页的指纹签名相差会十分巨大,针对这个现象,google提出了Simhash算法,过程十分简单,可以通过下图描述清楚。
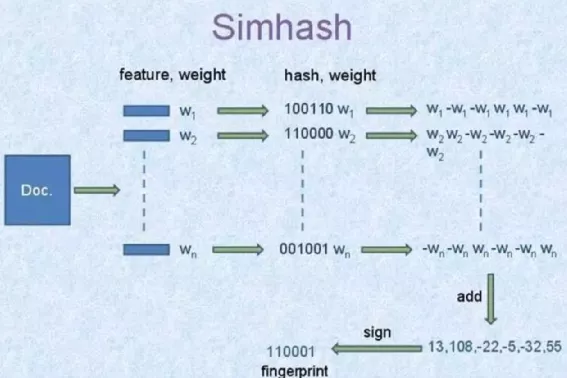
过程如下:
- 首先对原始的数据提前关键特征和特征对应的权重,在网页中特征就是关键词,权重就是tf-idf;
- 利用一个签名函数对一个原始数据的所有特征计算,得到二进制签名,这个签名函数就是一个普通的hash函数,比如crc16;
- 所有的特征签名逐位求差或和,若签名位是0则减去这个特征的权重,当签名位是1则加上这个特征的权重,最终得到一个和签名位数一样的一维向量;
- 将上步得到的向量转化为二进制,若向量某一维大于0,则最终二进制对应的bit为1,小于0对应的比特位为0
LSH可以做到无监督构建索引、无需重训练索引,可以做到在线实时添加;此外在线只需要做简单的哈希查表,效率也非常高,但是LSH在向量投影过程,会存在不少的信息损失,在目前深度学习进行表征的主要场景,这种损失会导致召回率不高。
2.近邻图算法
近邻图搜索在搜索前先需要构建一个近邻搜索图,其中最常用的有NSW和升级版HNSW算法,NSW图示如下:
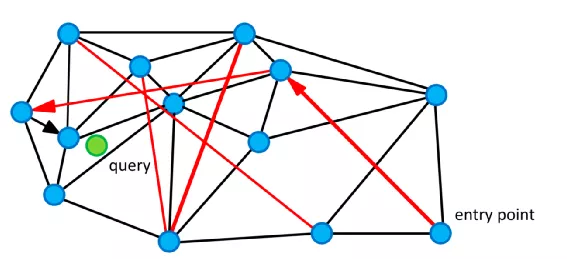
图片来源【11】
1.NSW算法
在NSW近邻图中,有两种边:
- short-link。用于搜索最近向量
- long-link。在搜索初期提高搜索效率
NSW的构图过程:
- 每次在图中插入节点v都寻找k个最近的节点x,让v和x之间产生边
- 插入时产生的边为为short-link
- 随着新的距离更近的节点逐渐加入,可能以前的short-link不再是距离最近的k个,这个时候short-link变成了long-link
NSW的朴素搜索过程如下:
对于一个查询节点q,准备三个集合:已经访问过的点V、结果集合R,候选集合:
- 在图上随机选一个节点加入C
- 计算C中所有节点与q的距离,假设距离最近的点为c(小写),距离为d,若d大于R中的最大距离(这个c称为局部最小点)或者C为空,则查询结束
- 从C中弹出c并将c加入V
- 令c的所有不在V的邻居节点集合为E,
- 将E中和q距离小于d的节点加入C和R,若R中元素已满,弹出R中距离最大的元素
- 循环2~5
如上图所示,要从构建好的近邻图中搜索和绿色节点query最近的节点,从随机挑选的entry points开始,一开始通过红色的long-link迅速到了query附近的节点,再通过黑色的short-link找到满足的点。
针对朴素搜索中的第二步获取的c可能不是最优点,改进的NSW搜索算法,这里取k个距离最近的点。
从构图上可以看出,越早插入的点冗余边越多,检索效率越低,针对这一点,新提出的HNSW针对NSW进行查询效率优化。
2.HNSW算法
HNSW借鉴了跳跃表的思想,为了在原始的链表进行快速检索,增加了更高的稀疏层,先从稀疏层查询起,符合条件的再逐级靠下向稠密层查询:
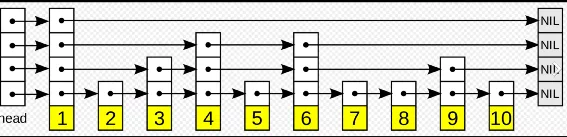
跳跃表图示
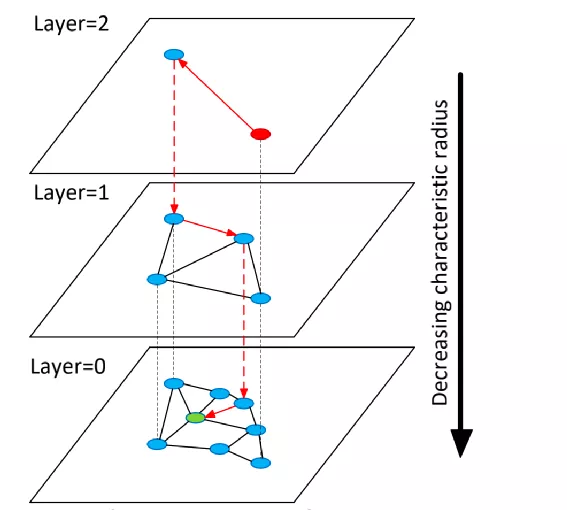
HNSW图示,图片来源 【12】
在HNSW构图过程简单描述如下:
- 根据概率选择一个当前节点要插入的最大层数,层数越高插入概率越低,假设HNSW的最大层是5,当前的要插入的最大层是3,那么这个节点会被插入0,1,2,3层(4,5层不插入);
- 从高层开始逐级向下搜索,在每一层找到距离最近的k个节点与插入节点建立边,每一层的搜索算法和NSW一样
- 对每一个节点,有一个最大边数emax,若进行步骤2后,旧的节点边超过emax,则删掉距离最大的边
- 搜索过程如下:
- 从最高层5开始
- 每一层通过NSW算法找到近邻点
- 下一层的开始搜索节点则为上一层搜索的近邻点
近邻图算法可以无需预训练,实时的增删节点,此外在保证非常好的召回率的情况下检索性能也非常好,不过近邻图的问题就是构图时要全图检索,很难分布式化。
3.乘积量化
乘积量化的核心思想是通过空间切分,将高维的向量通过预处理压缩到低维度,比较有代表性的有PQ算法,PQ和倒排索引结合的IVFPQ。
1.PQ算法
PQ算法过程可以用下图解释:
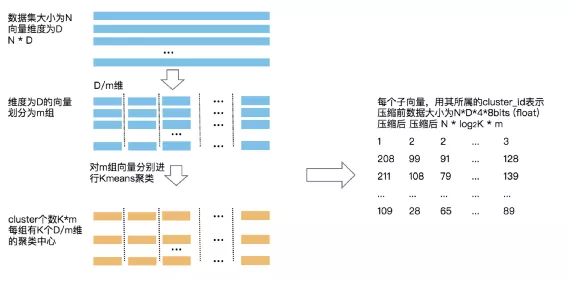
图片来源: https://www.aiuai.cn/aifarm1746.html
假设有N个1280维的向量,具体过程如下:
- 选定一个向量分段数K,假设为10,那么每一段的维度就为1280/10=128
- 对原始的N个向量每128位分为一组,那么一共有10组,每组有N个向量
- 对10组的向量分别进行聚类,假设聚类的个数是256个,每个类的中心称为积中心,对每一组的积中心打上依次打上编号0~255
- 对于一个向量每一段128维来说,和这组的那个积中心距离最近,就把这段用这个积中心编号表示,这样原始每个向量就被表示为一个10位的向量,每位取值0~255
对所有的乘积向量,对一个新的查询向量q来说,查询过程如下:
- 将这个查询向量通过上边的分段算法转成10端128维向量
- 每一段和这个段的256个积中心算出距离,会得到一个10*256的矩阵M
- 对于索引库的一个向量v,假设其量化向量为[255,1,210,……](10个元素)对于第i个元素值为j,可以认为第i段与q的距离为Mij(ij为矩阵M索引),比如对于第一个元素255可以认为距离是M的第0行第255列的值
- 将10个段经过步骤3查询的10个距离求和得到s,可以认为s是v到q的距离,从所有的向量距离中找出距离最近的k为查询结果
从上边的查询过程可以看出PQ的查询过程时间复杂度为O(M*K),当需要检索的向量数目变多时检索效率无法得到保证。针对PQ算法检索慢的问题,针对性将倒排索引和PQ结合起来,提出了新的IVFPQ:
2.IVFPQ算法
IVFPQ主要的改进思路如下:
- 预先对这N个向量聚类(原始向量上聚类),假设聚类数量为1000,那么每一个向量会归入自己所在的这个类
- 对每一聚类的向量进行PQ量化
- 在线查询来了先和每一类的中心比较,挑选距离较近的m个类,m至少为1,m越大速度越慢但是召回越高
- 从这个m个类中进行上边PQ查询
IVFPQ还可以进行优化,对每一聚类的向量进行PQ量化时,不再用原始向量,而是用原始向量减去这个聚类中心向量的残差进行计算,这样的召回率会更高。
乘积量化算法召回率很高,在工业界用的较多,但是量化算法也有较多缺点,如下:
- 首先要对原始向量进行聚类,没法做到从0开始插入数据
- 聚类后加入的向量若发生离群(离任何类中心都较远或者距离差不多),那么这些向量的召回会很低
- 量化因为主要原理是通过聚类将考得近的向量降维,所以如果原始向量分布很均匀,那么聚类效果很差所以最终的召回率很低
针对PQ量化算法,还有很多改进版本,这里不做具体阐述。虽然向量检索算法层出不穷,但是面对着工业界,超大规模的数据,要满足低延迟、低成本的进行向量搜索,依然会有很多挑战【13】。
五.向量检索工具简介
随着表示能力强大的深度学习发展,工业界的向量检索工具已经成为一个专门方向,有越来越多的团队投入其中,本小节对工业界常用的向量检索工具做简单介绍,并对优缺点进行对比分析。
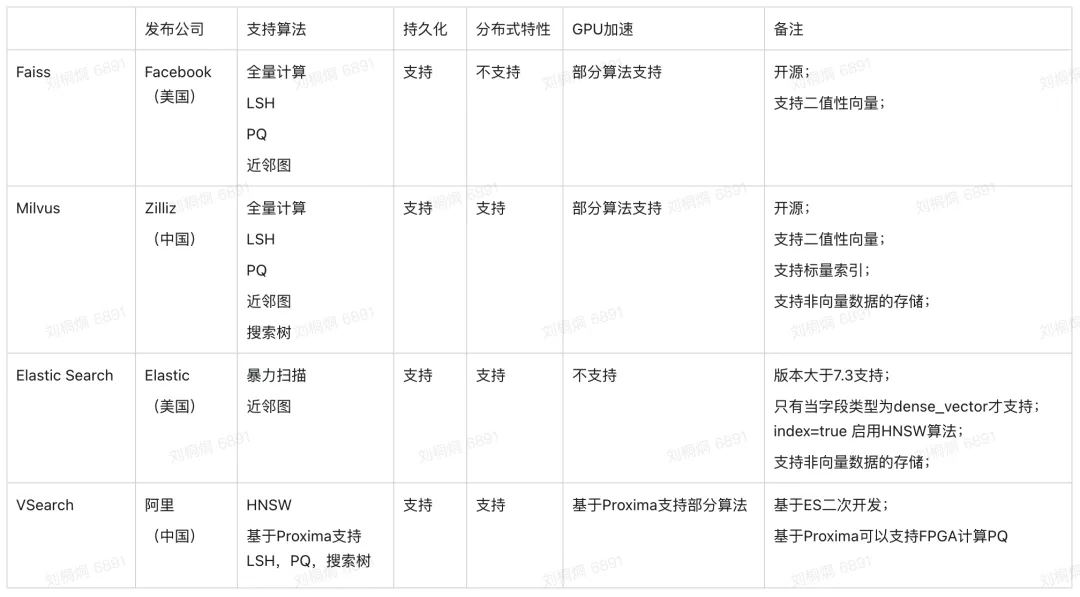
六.来也在向量检索上的实践
在来也科技,我们会通过人工智能技术和自动化技术去赋能各行业,从而提升效率,在这一节举两个例子简述向量检索在来也科技的落地
1.对话机器人召回
在来也的智能对话机器人产品上,非常关键的一个环节就是召回,在这个环节需要根据用户的query 召回最为接近的答案、意图等。
由于来也的对话机器人平台是一个多租户的SaaS系统,单个租户的数据量不足以微调Bert和Ernie等深度模型,在不进行微调的情况下,这些算法的召回性能和Sif(smooth inverse frequency)【16】 算法差不多少,而Sif几乎不消耗编码性能,所以在编码算法上我们采用优化的Sif算法,预训练词向量,并对每个租户的语料进行主成分分解。
在检索引擎上,我们直接采用阿里云的PostgreSQL,利用PASE插件和分区表的模式可以支持多租户下高效的向量检索。
在使用句向量召回后,在内部的多个评测集合上召回率有超过3.5%的提升,此外相比以前的term召回,有一些典型的case也可以被很好的处理,如下:
用户Query:有什么经济实惠的酒
召回结果:
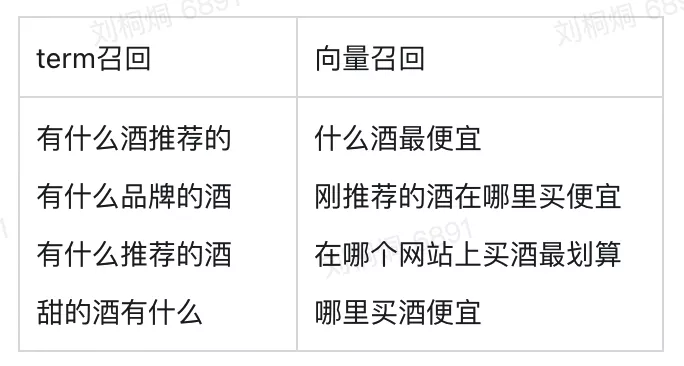
因为基于term的召回,在query的预分析阶段,经济和实惠被分成的两个关键词,而在索引中这两个词不存在,无法被召回;而基于向量的召回,query和召回答案的向量表示距离很近,可以被很好的召回。
2.依图搜索SKU
在来也的某项目上,需要根据化妆品的盒子进行SKU识别,从而做下游的分类回收,在这个项目上,因为要求的准确率高,我们采用基于分类模型训练,用softmax前的输出向量作为图片表征,在检索算法上采用LSH,效果如下:

七.参考资料
1.《周志华:关于深度学习的思考》 https://mp.weixin.qq.com/s/j1giWHZEfEPdD2eqC1qrsg
2.《拍立淘中的图像搜索和识别》https://codechina.gitcode.host/programmer/11-11/1-ali-pailitao.html
3.《曼哈顿距离》 https://baike.baidu.com/item/%E6%9B%BC%E5%93%88%E9%A1%BF%E8%B7%9D%E7%A6%BB/743092
4.《L2范数归一化概念和优势》 https://www.cnblogs.com/Kalafinaian/p/11180519.html
5.《Complete the Look: Scene-based Complementary Product Recommendation 》 https://arxiv.org/pdf/1812.01748.pdf
6.《NEON介绍》 https://zhuanlan.zhihu.com/p/432501307
7.《近距离看GPU计算》 https://www.eet-china.com/mp/a64248.html
8.《汉明距离百科》 [https://baike.baidu.com/item/%E6%B1%89%E6%98%8E%E8%B7%9D%E7%A6%BB/47517](https://zshipu.com/t?url=https%3A%2F%2Fbaike.baidu.com%2Fitem%2F%25E6%25B1%2589%25E6%2598
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%9D%A5%E4%B9%9F%E6%8A%80%E6%9C%AF%E5%90%91%E9%87%8F%E6%A3%80%E7%B4%A2%E4%BD%BF%E7%94%A8%E5%9C%BA%E6%99%AF%E5%92%8C%E5%85%B3%E9%94%AE%E6%8A%80%E6%9C%AF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


