李茶虎牙直播推荐系统架构详解

分享嘉宾:李茶 虎牙直播
编辑整理:罗壮 Soul
出品平台:DataFunTalk
导读: 大家好,我叫李茶,来自虎牙直播的推荐工程组,主要负责虎牙直播的推荐架构工作。直播推荐是一个头部主播比较集中的场景,比较注重关系链、词语以及长期的价值,业务诉求可能和其他推荐场景有所不同,这一点在工程架构上也会有所体现。本文将和大家分享下虎牙直播的推荐架构,包括以下几方面内容:
- 业务背景
- 业务架构
- 向量检索
- 精排
- 总结和展望
01 业务背景
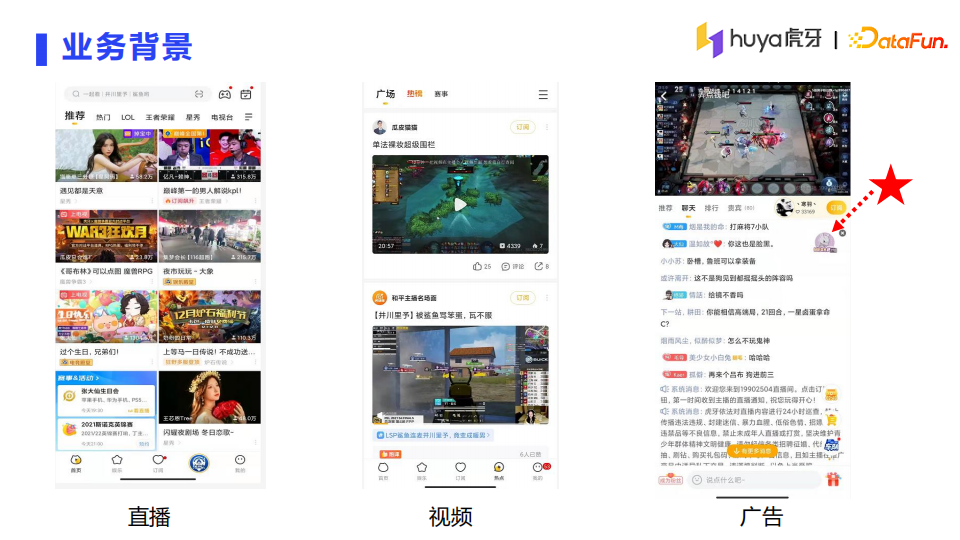
首先和大家分享下虎牙直播的业务背景。虎牙直播的推荐场景主要有以下三个:首页的直播推荐、广场的视频推荐以及直播间的广告推荐,当然还有很多小的场景,在这里就不展开讲了。
直播是一个头部主播比较集中的场景,比较注重关系链、词语以及长期的价值,业务诉求和其他推荐场景有所不同,在工程架构上会有所体现。但整体推荐模块和流程与业界主流推荐架构基本一致。
02 业务架构
接下来和大家介绍下虎牙直播的业务架构。
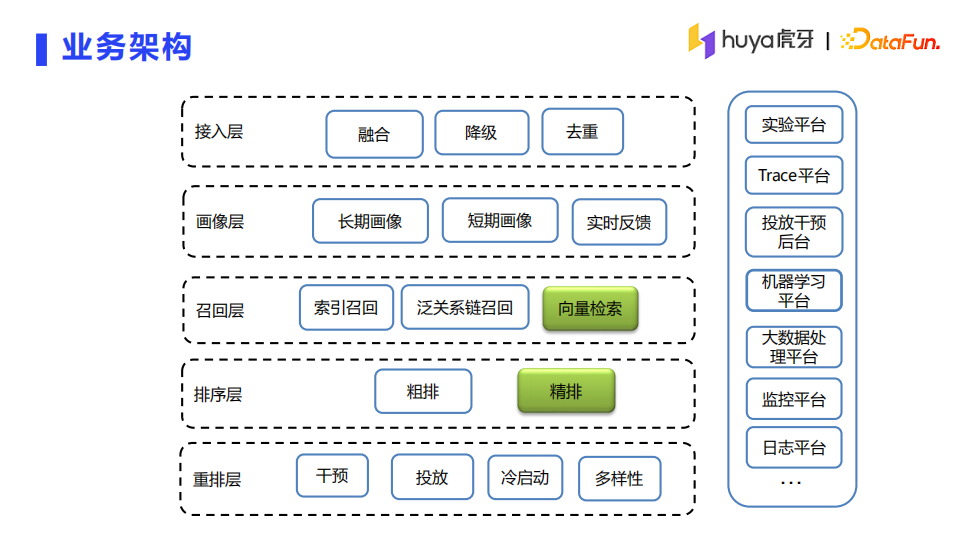
虎牙直播推荐架构中涉及的模块和流程与业界主流通用的一些推荐架构基本一致,部分模块会有一些定制化的设计。接入层用来做透传的工作,提供融合、降级、去重的功能;画像层提供用户和主播长期、短期以及实时特征的能力,还有一些召回、排序、重排模块以及一些周边的平台支持。
现在举例说明下虎牙直播的推荐业务特点以及和通常的图文、视频推荐业务的区别。拿接入层的去重来说,一般的图文、视频推荐业务有比较强的去重需求,比如用户看过了某篇文章、某个视频,大概率是不希望看到相同或者相似的内容。业界常用的做法是用一个布隆过滤器来做长期的去重。在虎牙直播推荐场景,主播的标签或信息会有比较大的不确定性,很多都是在开播的时候才能确定。例如打游戏的主播可能下一时刻会做才艺类型的直播。所以在这个场景下的去重对时效性的要求比较高,同时需要不断的优化调整。
在后面的分享中,我将会从向量检索和精排两个方向详细介绍下虎牙直播的推荐架构。这两块涉及到了推荐系统中的大部分技术点,并且它们之间联系得也比较紧密。
03 向量检索
1. 背景
2016年,谷歌分享了youtube视频推荐和搜索的向量检索架构,同时该架构的落地取得了比较不错的收益,目前很多推荐系统也都在尝试通过优化embedding来提升业务指标,实际效果也非常可观。
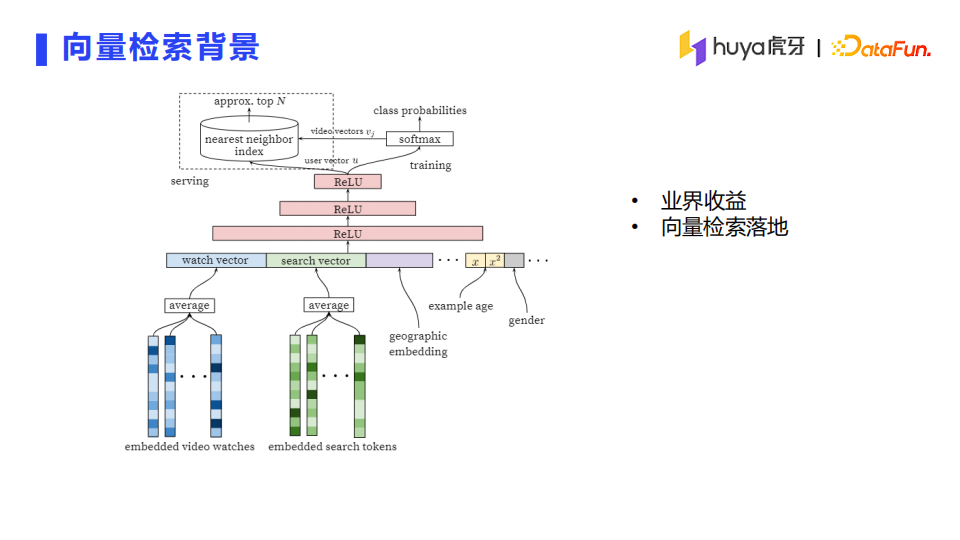
虎牙直播早期由于主播数量较少,主要是通过暴力检索。随着业务的发展,基于成本和性能的考虑,暴力检索已经没有办法满足业务需求,于去年年初开始投入人力进行向量检索方向的调研和落地。
我们调研了Facebook开源的向量检索框架Faiss和谷歌开源的向量检索框架ScaNN,ScaNN在算法上做了一些优化。
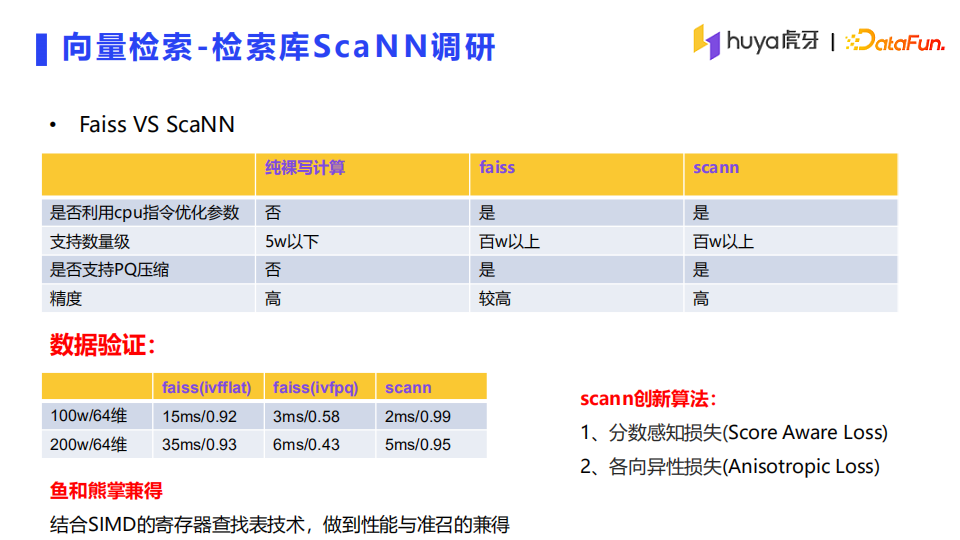
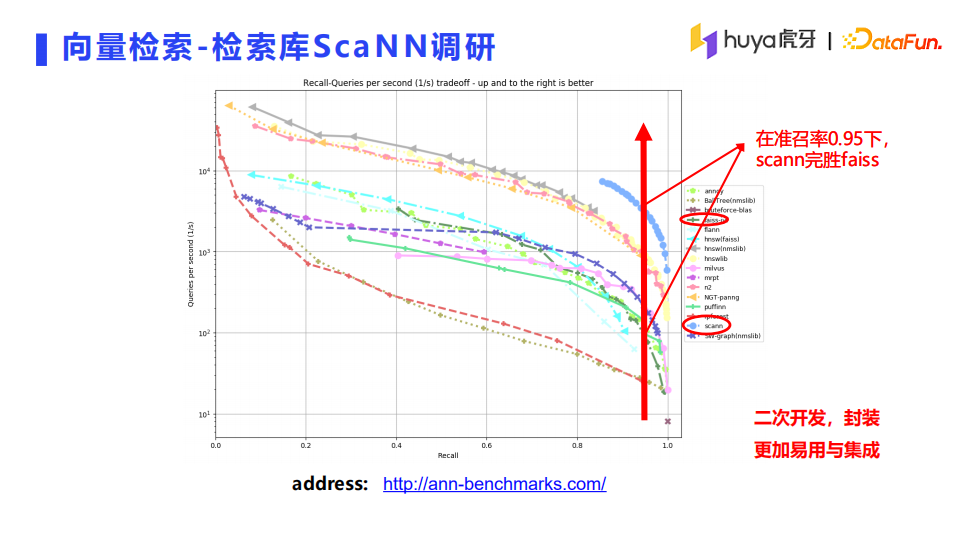
如上面两图所示,经过数据的验证以及ann-benchmarks的压测,ScaNN在性能和准召率都是表现较好的。由于ScaNN是相对较新的检索库,也很难找到其他企业开源的成功应用案例,但是经过部门同学的二次开发和封装,使ScaNN能够相对较好地集成到现有架构中去,方便使用。
2. 技术挑战
向量检索的技术挑战主要有以下三点:
- 生产环境需要一个高吞吐、低延时、高可用的系统;
- 结合向量检索的业务诉求,数据需要快速更新,系统需要具备一定的容错能力;
- 需要提升数据构建的效率,保证线上服务的质量。
3. 架构落地
基于前面提到的挑战,我们设计了如下的读写分离、文件化的架构:
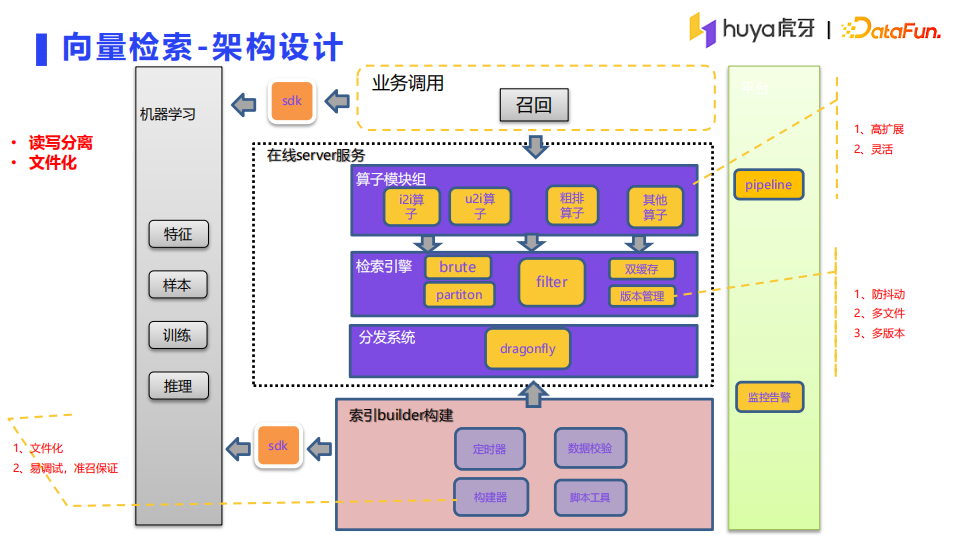
索引builder构建:文件化;易调试、准召保证。 索引builder构建主要负责向量的生产和索引文件的构建。使用npy二进制的文件格式,减少文件体积并易于调试。索引builder使用SDK与模型和特征进行交互,同时在调试时也可以使用,有比较好的可复用性。
分发系统使用了阿里开源的Dragonfly,支持P2P的分发,打通了公司的文件系统。
在线Server部分在架构上拆解为检索引擎和算子模块,使用SDK接入。
检索引擎:防抖动;多文件;多版本。 检索引擎目前支持ANN检索和暴力检索,采用通用的API执行流程,包含加载、卸载、双buffer切换等环节。开启实验时,实验组和新增的引擎做好关联即可,
算子模块组: 易扩展;灵活。 算子模块组是按照通用的算子执行逻辑设计的,使用的是标准的输入输出,比较方便扩展和复用。
上线流程通过管理平台来配置,提升了系统的迭代效率。
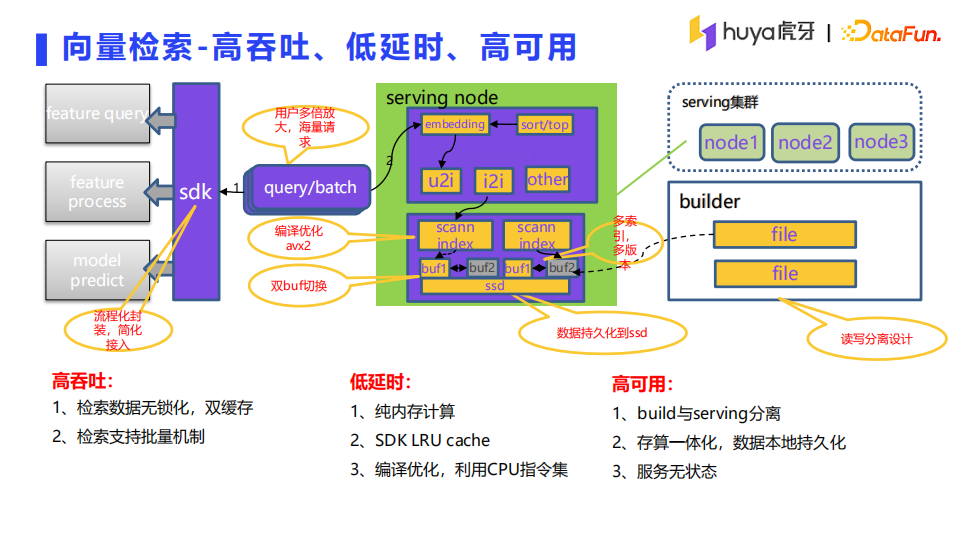
下面介绍下向量在线检索的过程,业务方集成的SDK通过用户的id信息进行画像的查询,同时进行一些特征处理,然后请求模型生成向量,最后通过向量来进行检索,根据请求的数量返回topk。SDK支持跳过以上的任意步骤,比如直接通过向量来进行检索。满足算法同学的调试需求和线上的实际使用需求。
在线检索的时候,通过索引文件双buffer的无锁加载,支持批量查询,保证了系统的高吞吐;通过纯内存计算、LRU cache以及指令集优化保证了系统的低延时;通过builder和server的分离、存算一体(启动速度加快)以及服务无状态(方便快速扩容)保证了系统的高可用。同时,在服务启动的时候也加了一些保护,比如:只有在数据加载完成后,才能注册到名字服务中,提供对外服务的能力。
向量检索系统的数据加载是非常快的,下面介绍下数据更新的相关逻辑。首先,在配置中指定数据源和模型名称,builder进行定时调度获取任务信息,关联公司其他平台的任务产出,利用SDK来生成向量、构建索引文件,并把文件推送到P2P的源数据节点。P2P的管理节点会定时检测源数据目录的文件产出。在线的server会启动dfagent进程,定时和P2P集群的管理节点同步心跳,获取管理节点上需要同步的资源列表。管理节点将需要同步的节点组成p2p集群,进行P2P的分发。200w数据集能在5s内完成内存化,在10s内完成分发。另外文件是以时间戳为版本,在线支持多版本,加载前会校验,和拦截告警,整体流程1分钟内生效。
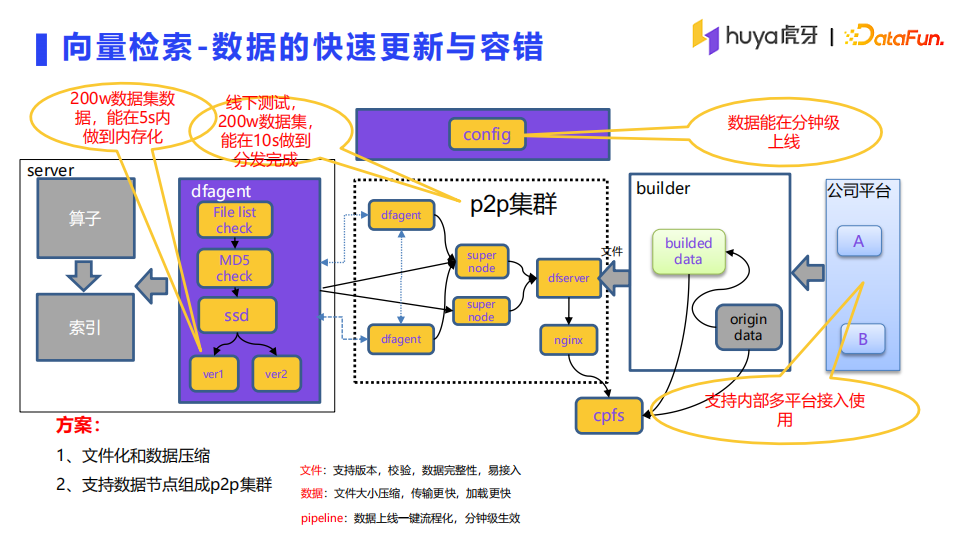
在离线构建部分也做了一些优化以实现效能提升和安全保障。为了保证性能和准召率,我们开发了一些半自动的寻参工具,通过设置少量的参数和一些我们预设的经验参数,进行自动化的评估,对比结果输出最优的参数来提供线上使用。不过目前这个工具是一个单独的离线工具,后续的话会集成到平台。builder节点支持横向扩展,通过分布式锁来进行任务的抢占和执行。单个builder节点支持多进程的并行构建,提升构建速度。针对每个构建任务的都支持一些定制化的一些指�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%9D%8E%E8%8C%B6%E8%99%8E%E7%89%99%E7%9B%B4%E6%92%AD%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AF%A6%E8%A7%A3/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


