斗鱼风控算法体系建设

分享嘉宾:龚灿 斗鱼 算法负责人
编辑整理:王彦磊 灵数科技
出品平台:DataFunTalk
导读: 直播行业在业务上面临运营安全、活动安全、流量安全、账号安全、交易安全、内容安全等风险问题,智能风控在技术方面主要有高频对抗、场景繁多、解释性弱等挑战。本文将分享斗鱼算法团队针对以上问题,如何构建风控算法体系,以及如何应对风控技术方面的挑战。
01 智能风控背景介绍

1. 直播风控面临的问题有什么?
目前黑产从业人数超过150万人,市场规模高达千亿级别,斗鱼主要的风控场景有运营安全、活动安全、流量安全、账号安全、交易安全、内容安全、风险联控等七大类。
2. 智能风控在技术上有哪些挑战?
- 风控是强对抗场景,策略效果很容易会衰减甚至失效
- 风控对抗场景繁多,每个风险场景单独建模工作量大
- 策略鲁棒性和模型可解释性顾此失彼
**面对问题,往往是先有目标,再有解决方案。**围绕风控业务上遇到的问题,我们采取的方案是先扎根业务,建立一套尽可能通用的算法体系架构,配合风控策略和风控运营一起,将业务上琐碎的工作流程化、流程化的工作自动化、纯人力不可解的工作智能化,以此来较好的完成日常风控场景中遇到的问题。
02 算法架构
1. 概述
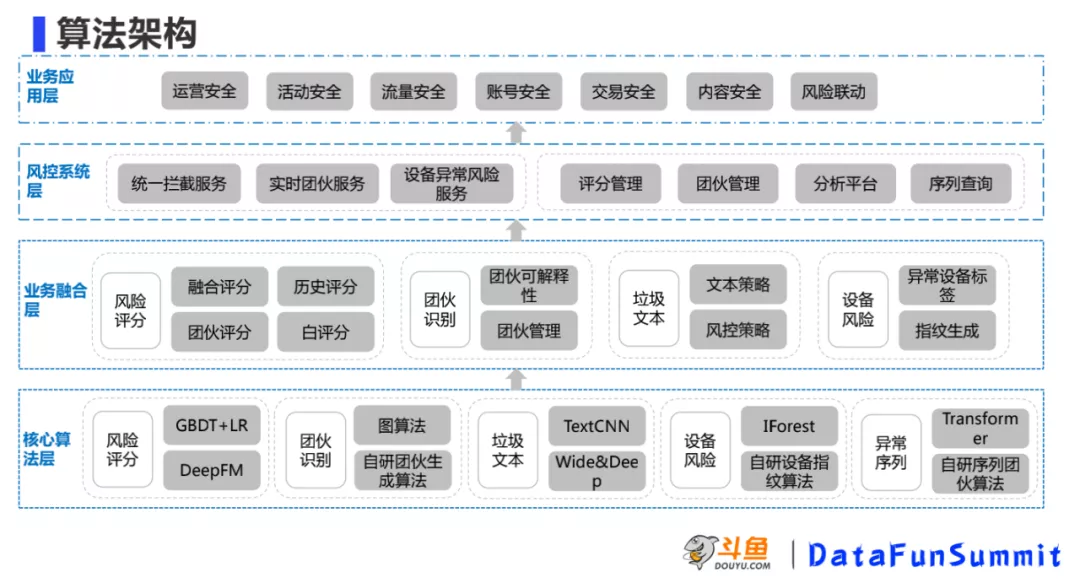
结合以上的技术问题,算法架构设计上基于现有的直播业务考量,将上述的七类风控场景的风险抽象为以下几类风险类型:
- 内容风险:内容风险主要包括图片、文本、视频(这里主要讨论文本)。比如用户在直播间发广告、色情信息等
- 用户行为风险:可通过UID维度指标发现的异常行为。比如某个UID单天登录某一个入口的次数较多等此类风险
- 团伙风险:针对类似“手机墙”等手段将行为风险分摊到多个ID上,此类风险通过用户行为风险是较难识别的,需要对团伙风控进行单独的识别
- 设备风险:前面三类都是基于UID的行为进行风控,最后需要通过从设备角度进行风险识别的补充
通过对以上四类风险的识别构建一套有效覆盖所有场景的智能风控解决方案。
2. 核心算法层
核心算法层包括风险评分、团伙识别、垃圾文本、设备风险和异常序列。
- 风险评分:由最初树模型逐渐演进到后来的DeepFM,主要考量风险评分在使用中的有序性,分数越高风险越高
- 团伙识别:基于传统的图算法在业务中效果不好,自研发了团伙生成算法
- 垃圾文本:由最开始的人工特征+浅层模型,过渡到TextCNN,再到融合文本信息和用户行为的Wide&Deep模型
- 设备风险:采用的是IForest 和自研设备指纹算法。
- 异常序列:作为前面算法识别风险行为的补充,对用户行为的序列进行了一层识别
3. 业务融合层
针对四类风险结合业务需要做一下模型的融合,与上一层核心算法模块划分相同。
- 风险评分:base模型为单天的风险评分,需要结合历史的评分进行加权得到融合的评分,对于当天没有数据的,通过团伙评分做补充(比如之前有风险,但近几天没有记录,风险会衰减,通过团伙评分可以将这些风险补上去),白评分主要是衡量评分的误杀。
- 团伙识别:团伙管理是因为数据量大,关系多,考虑到资源的合理利用,对这部分信息做了一些存储、关系方面的管理。团伙可解释性是针对业务述求提供的一个后台实时查询功能。
- 垃圾文本:分为模型和线上策略,因为模型有一定的滞后性,所以线上需要一个实时的对抗策略。
- 设备风险:自研设备生成算法,另外提供设备相似度、设备异常信息以及设备风险分等维度的异常设备标签。
4. 风控系统层
在业务融合层的上一层,包括统一拦截服务、实时团伙服务、设备异常风险,评分管理、团伙管理、分析平台、序列查询。
5. 业务应用层
最上层为应用层,即上面提到的七类风控场景。
03 模型实践
1. 实践中搭建风控算法体系主要遇到的问题挑战
- 如何与变体多、变化快的垃圾文本做对抗?:垃圾文本主要是通过各种手段生成变体逃过模型和策略的监控,属于强对抗的场景,导致策略很容易失效
- 如何构建一套全场景评分系统?:在实际运营中针对案例的及时反馈排查,对新风险行为的及时发现,给风控团队的分析和识别工作带来了很大挑战
- 如何解决单UID维度下的弱风险问题?:风险评分系统主要是基于UID 层面的风险识别,但是UID程度的风险主要都是基于单个ID聚合出来的,对于分散在各个结点上的风险怎么识别是需要解决的问题
- 如何识别异常行为序列?
- 如何识别设备维度风险?
- 识别结果如何做到可解释?
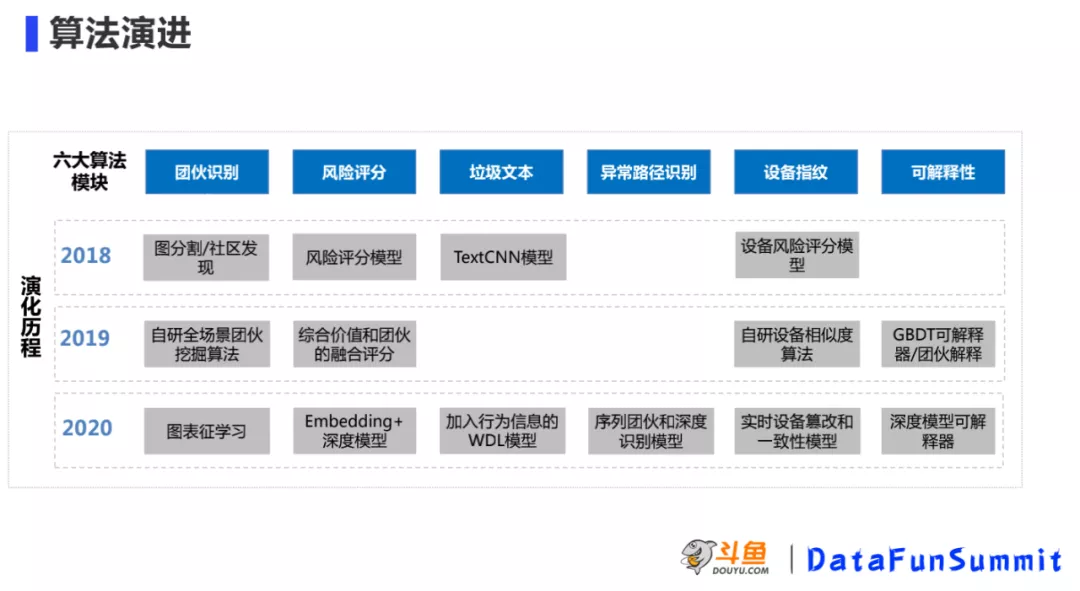
2. 算法演进
现有的模型主要是从2018年演进过来的,主要演进过程如下图所示:
① 垃圾文本
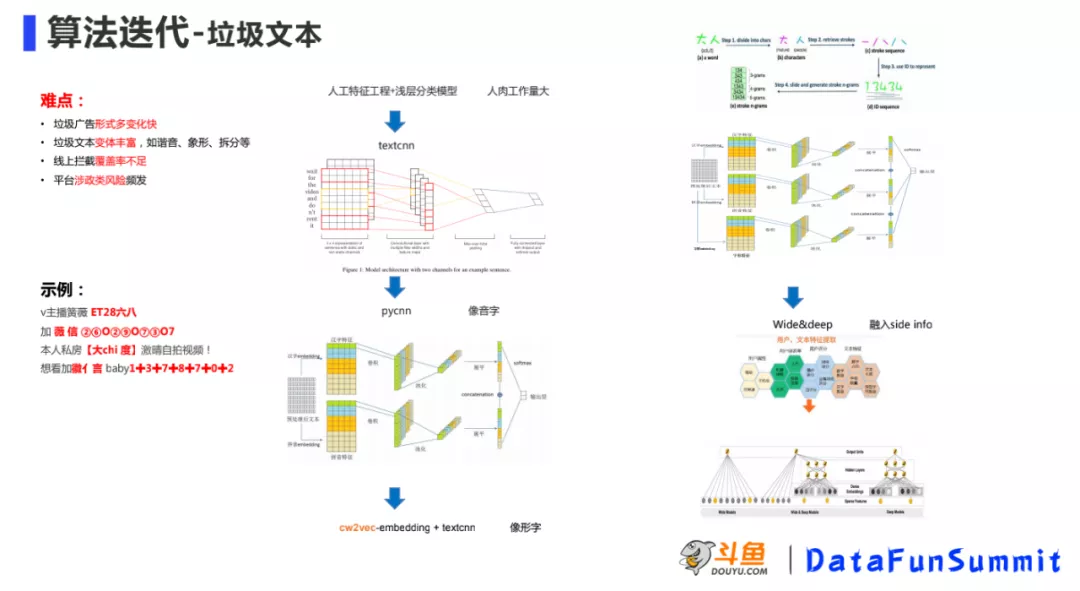
直播场景通常会存在大量各种形式的垃圾文本,我们的模型主要经历了以下几个迭代步骤:
- 最初采用人工特征工程+浅层分类模型,模型简单可控,模型可解释性强,但是需要做大量的 人工特征工程
- 模型更改为textcnn,特征工程工作量减少,模型召回率提升,但对像音字、像形字不能很好的识别
- 像音字、像形字识别:基于pycnn,把汉语的像音字转化成拼音,将拼音当做词输入到模型中,分别将汉字特征、拼音特征分别做卷积池化,然后拼起来输入到softmax;针对像形字问题,在pycnn基础上在embedding层使用cw2vec,对字的笔画进行编码输入到模型中去,然后卷积池化融合。
- 除了文本信息,将模型进一步融入用户信息(用户评分,用户信息,用户属性等):此处借鉴了推荐系统中的Wide&deep模型。
垃圾文本整个迭代思路大概是这样,可以参考下图:
② 风险评分
在风控场景,我们希望任何一个用户进来都可以立刻得到一个评判用户好坏的分值,对不同分值的用户采取不同策略。对于高危用户下发惩罚策略,对于中危用户重点关注,对于低危用户原则上尽量减少策略的调用,提高用户体验。总体要求是评分要有有序性,第二是模型的准确率、覆盖率,第三是模型的可解释性。
早期模型采用简单的二分类模型(树模型、逻辑回归),效果不太理想。树模型分类效果不错,但是不能保证分值的有序性;逻辑回归能保证分值有序性,但是特征工程特别复杂。所以第一版改进借鉴推荐系统的思路:GBDT+LR 的融合,GBDT做特征的自动提取,LR保证模型的评分有序性;第二版迭代采用dnn代替gbdt做高阶特征的自动提取,提升模型的泛化能力;第三版迭代是把Wide侧改为FM,进一步提升模型泛化能力。经过以上三版模型迭代,模型到达了一个ROI瓶颈期,所以再进一步的迭代重心从模型结构调整转为引入更多信息,于是将序列的embedding和图的embedding融合到模型中去。以上几版迭代均取得了不错的收益,迭代步骤可参考下图:
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%96%97%E9%B1%BC%E9%A3%8E%E6%8E%A7%E7%AE%97%E6%B3%95%E4%BD%93%E7%B3%BB%E5%BB%BA%E8%AE%BE/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


