文本相关性在蘑菇街搜索推荐排序系统中的应用

作者:美丽联合集团 算法工程师 琦琦 ,公众号关注:诗品算法
0、引言
好久不见。十月最后一天,居然也是十月的第一篇,脸疼。今天我们来聊聊相关性吧。如何巧妙地将NLP相关知识应用于搜索推荐系统呢?且往下看。
PS:笔者在本篇文章中所提及的算法,全部在真实的生产环境中实践过,均有收益,且全部落地!这篇文章在市面上独一无二,你认真看完,会有收获的! 大家可以多点赞多收藏~~蟹蟹。
笔者16年初入职场时,从事的是广告搜索相关性的优化工作。后来相继做过基于多目标的商城gmv效率最大化排序、基于reweight的直播排序、基于增量学习的视频流推荐系统,目前在探索基于切片视频的多目标推荐系统。纵观不同场景的不同业务目标,无外乎就是推荐 & 搜索两家争鸣。
搜索和推荐本不分家,但两者之间也有一些本质区别。搜索的首要准则是相关性,结果集中,且在各垂直领域是独立的,比如你搜索毛衣,我不可能给你推荐袜子,突出一个“人找物”的理念。推荐的首要准则是用户兴趣,讲究的是多样性、新鲜度、丰富性,相对应的,检索结果也较为丰富,跨类目更是常见,突出“物找人”。但目前市面上很多视频APP的推荐内容极易陷入一个同品类的怪圈圈,久而久之,难免让用户心生厌倦。人性本身就是猎奇的、爱追求新鲜感,若一直给用户推荐同一类视频,用户短期可能会沉迷于此,但长期来看,当用户无法在app上获取更多信息,产生“审美疲劳”后,今后很可能就不再回访。
有时候,我们在进行模型优化时,若找不到思路和方向,不要总是盯着模型结构看,不要总盯着loss曲线和AUC看,跳出来分析数据,站在用户的角度思考问题,往往会有意想不到的收获。废话不多说,下面进入正题。
我们将从以下几个方面,对文本相关性在推荐搜索排序中的应用展开详述。
- 低维稠密的相关性数值特征
- SimRank/SimRank++/点击二部图
- 通过历史点击构建文本序列
- 如何巧妙应用N-Gram语言模型?
- ** 如何通过TD-IDF筛选文本序列?
1、低维稠密的相关性数值特征
根据query和商品中的term进行各种匹配和计算。计算方式有:频率、tf-idf、BM25、布尔模型、空间向量模型、语言模型等。由此可得到一系列低维稠密的相关性数值特征,这类特征特别适用于xgboost/GBDT这类模型。
一般来说,我们会先对query侧和商品item侧的文本进行切词,当然,对文本的预处理也至关重要,比如字符规范化(全角半角,大小写,简繁体等转换)、拼写纠错、过滤中英文标点符号,去除停用词和连接词等。query一般由商品品牌/产品词 + 商品属性(颜色、材质、款式)/修饰词/度量单位 构成,比如“粉色外套”中的粉色是商品的颜色属性,外套则属于产品词。通常来说,我们需要提取中心词/产品词/修饰词,eg:“2020年外套女宽松韩版”可以提取出“外套女宽松”,“小白鞋新款女百搭”可以提取出“小白鞋女”,我认为,“2020年“、“韩版”、”新款“、”百搭“均属于无意义的”停用词“,至少在电商场景,对于我们训练模型而言,这类词是没有任何信息增益的。任意一款商品的标题都可以加上“2020新款百搭”。
query既可以指代搜索场景当前的搜索词,也可以泛指推荐/搜索场景,用户的历史搜索词。
词命中率:我们首先需要对query侧或item侧进行单边扩词,即同义词扩展。其中,同义词挖掘可使用word2Vec等方式,通过相似度分数截断及人工review后,得到一个同义词词典。之后将query/item(待排侧)扩词后的文本分别按照词粒度/字粒度进行切分,经过unigram/bigram/trigram组合后,计算两侧重合term/交叉产品词/交叉修饰词的数量,占query侧/item侧term总数量的比例。
反向词:反向词也是一类重要特征,我们需要维护一个反向词词典,训练时,检测query侧和item侧是否存在反向词。
对上述特征进行处理后,加入xgboost模型中训练,以广告ctr为优化目标,离线AUC+2.1%,线上ctr/广告收入+2%。
2、SimRank/SimRank++/点击二部图
SimRank是一种基于图的推荐算法。思想与协同过滤算法相似:如果两个用户相似,则与这两个用户相关联的物品也类似;如果两个物品类似,则与这两个物品相关联的用户也类似。
SimRank——利用query和商品之间的点击关系建立二部图(bipartite graph),其中,Query和商品分别是两种节点。边表示点击关系,可以无权重,也可用点击次数/点击率作为权重。
SimRank++——在SimRank的基础上进行了改进。构造转移矩阵时,考虑不同边的不同权值。进行节点相似度修正,将共同相连的边作为置信度。
几年前,Yahoo有一篇paper提出,将点击日志构成二部图,通过二部图进行向量传播,收敛之后,query和doc(类比item)将在同一空间上生成词向量,如此一来,就可以通过相似度的计算方式得到文本相关性。对于未曾有过点击行为的query和doc,也可以进行该空间词向量的估计。这是SimRank及其衍生算法与文本相结合的一个很新奇的思路。
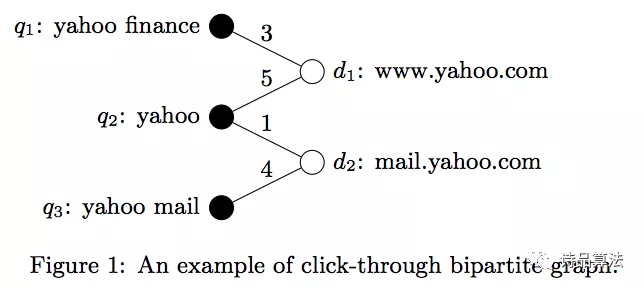
假设语料库长度为
 ,则Query构成的矩阵为:
,则Query构成的矩阵为:
 ,Doc构成的矩阵为
,Doc构成的矩阵为
 ,我们的目标是计算这两个矩阵。这里的语料指的就是Query和Doc共处的向量空间,由Query分词后的term,或者Doc中的title/content分词后的term集合构建。
,我们的目标是计算这两个矩阵。这里的语料指的就是Query和Doc共处的向量空间,由Query分词后的term,或者Doc中的title/content分词后的term集合构建。
向量传播模型步骤:
- 我们可以任意选择一侧进行向量初始化。若从Query侧开始,将Query向量初始化为
 ,0表示第一次迭代。迭代公式如下:
,0表示第一次迭代。迭代公式如下:

- 若从Doc侧开始迭代,公式如下:
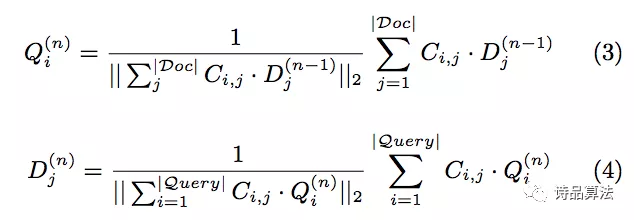
实践中,有一些注意事项和优化点(下文中的item指代论文中的doc):
- 只需要对query/item中的重要term进行表示。如第一部分所述,对文本的预处理/提取核心term至关重要。
- 由于计算量较大,进行每一轮迭代后,都需要对结果进行剪枝。当我们的训练样本从1天增加至5天时,最终<query, item>pair对的数据量达到几百亿,存储代价极大。通过动态阈值截断(前几轮迭代时,阈值较小,保留足够信息到后期迭代;最后一次迭代时,增大阈值,加大剪枝力度)、建立文本term到query/item的倒排链(无交叉时不计算)等手段,大大降低了计算量。
- 若将该二部图模型产出的相似度分数应用于另外一个模型,如果出现train AUC涨很多,test AUC下降很多的现象时,就要特别注意了,99%的可能性是出现了特征穿越。
- 计算query-item相似度的步骤从二部图模型迁移到另外一个模型(比如xgboost):保存二部图模型训练出的query/item向量。在xgboost训练过程中,根据保存的query/item向量,逐条计算每条样本的query-item相似度分数。由此可以在二部图训练过程中,增加样本数量,拉长样本天数,因为二部图的训练瓶颈就在query-item的相似度计算上。
- 二部图的边是click,我们可以对click添加position因子进行柔和衰减,缓解position bias。
效果:广告APP搜索,线下AUC+0.7%,线上收入+1%。
3、通过历史点击构建文本序列
这部分的尝试源于18年,基于wide模型。我称之为query term sequence。当时基于点击序列wide模型的AUC:0.684,在此基础上,我对<query,item>交叉特征从多个维度进行探索,分别尝试了以下策略:
- 对query的历史商品点击序列建模,用item表达query,同item交叉。AUC:0.702
- 从商品维度,对产生历史点击的query序列进行建模,即,对于当前的商品来说,那些使该商品产生点击的query。用query表达item,同query交叉。AUC:0.704
- 从商品维度,提取使商品产生历史点击的query序列中的核心term(按照历史点击量和词频计算),对这些term序列进行建模,用query表达item,同query交叉。AUC:0.706
- 同3,与分词后的query term做笛卡尔积交叉。AUC:0.709
- 是收益最大化的策略。
总结一下,我们从历史点击反馈日志的角度,对query-item信息进行建模。得到term_term的pair对,经模型训练后,得到这些pair对的权重。这里有个强假设,query-item之间的历史点击行为越丰富,query-item的相关性越高。用query表达item,与query交叉,使query侧和item侧的文本处于同一空间内,query侧与item侧的term与term之间进行笛卡尔积交叉,该思路受到二部图算法的启发。
实验效果:广告APP搜索/类目场景,ctr+4.58%,ppc+5.97%,收入+10.7%,RPM+11.1%。
4、如何巧妙应用N-Gram语言模型?
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成长度为N的字节片段序列。每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。trigram复杂度较高,我们借鉴的是一元unigram和二元bigram思想。
n-gram模型一般用于评估语句是否合理,那么,我们是怎样将其应用在query-item匹配上的呢?我们首先对query进行以下操作:分词(包含char粒度切词和term粒度切词)、去除stop word,精准扩词(人工review同义词表 + word2Vec挖掘出term2term词表(top3)),抽取核心词/产品词+ 修饰词,得到由m个词组成的query序列。
举个栗子,原始query:“2020年新款百搭连帽紫色短款韩版外套秋季”,通过term粒度切词后,得到[“2020年”,“新款”,“百搭”,“连帽”,“紫色”,“短款”,“韩版”,“外套”,“秋季”],过滤stop word后,得到:[“连帽”,“紫色”,“短款”,“外套”](unigram词序列)。在此基础上得到的char粒度切词结果:[“连”,帽",“紫”,“色”,“短”,“款”,“外”,“套”](unigram字序列)。假设我们的语料库长度为
 ,对于前者,我们可以计算每个一元词的概率:
,对于前者,我们可以计算每个一元词的概率:
 ,依此类推,全局算完后,需要最后确定一个截断阈值,据此过滤掉大部分不常见的词。同样的,我们可以得到二元集合
,依此类推,全局算完后,需要最后确定一个截断阈值,据此过滤掉大部分不常见的词。同样的,我们可以得到二元集合
 :[“连帽紫色”,“连帽短款”,“连帽外套”,“紫色短款”,“紫色外套”,“短款外套”](bigram词序列),如何得到每个bigram的概率呢?这就需要用到n-gram概率公式了,但需要在原始概率公式上进行修改。在翻译/自然语言处理领域,term的前后向关系至关重要,交换了两个term的位置,其含义可能完全不同。比如,“我喜欢猫咪”和“猫咪喜欢我”是两个含义完全不同的句子。但是,在电商场景,query搜索词的词序对于我们理解这个query毫无影响:“短款外套”和“外套短款”的含义完全相同。因此,在计算
:[“连帽紫色”,“连帽短款”,“连帽外套”,“紫色短款”,“紫色外套”,“短款外套”](bigram词序列),如何得到每个bigram的概率呢?这就需要用到n-gram概率公式了,但需要在原始概率公式上进行修改。在翻译/自然语言处理领域,term的前后向关系至关重要,交换了两个term的位置,其含义可能完全不同。比如,“我喜欢猫咪”和“猫咪喜欢我”是两个含义完全不同的句子。但是,在电商场景,query搜索词的词序对于我们理解这个query毫无影响:“短款外套”和“外套短款”的含义完全相同。因此,在计算
 时,既要考虑当“短款“出现时,”外套“出现的概率;又要考虑当”外套“出现时,“短款”出现的概率。称之为backward-bigrams模型,公式如下:
时,既要考虑当“短款“出现时,”外套“出现的概率;又要考虑当”外套“出现时,“短款”出现的概率。称之为backward-bigrams模型,公式如下:

因此,
 ,这个公式其实等同于:
,这个公式其实等同于:
 。通过计算出的概率,对二元bigram短语进行筛选,过滤不常见的组合。
。通过计算出的概率,对二元bigram短语进行筛选,过滤不常见的组合。
对于字粒度(char)序列的处理同上。使用字粒度处理query的好处是,避免错误分词造成term信息有误,且可以降低对于同义词典/分词词典的依赖。比如,item中的标题是“A字裙”,搜索query是“裙子”,若两者均采用词粒度分词的方式,这个item就不可能被召回。但若使用字粒度进行切分,搜索query:[“裙”, “子”],item:[“A”,“字”,“裙”],就可以成功匹配上了。
通过词粒度和字粒度处理后,我们将得到四个序列:unigram词序列,unigram字序列,bigram词序列,bigram字序列。使用这些序列信息表达query,与item侧进行交叉。
实验效果:广告APP搜索场景,离线AUC+0.8%。ctr+7.07%,ppc+3.8%,收入+9.46%,RPM+11.1%。
5、如何通过tf-idf筛选文本序列?
19年,我们尝试将query & item 的文本信息加入wide & deep模型。在搜索场景,用户当前搜索query的文本信息和item的标题包含了用户意图和待排商品的属性信息。通过在wide & deep中新增query & item交叉,离线AUC+1.08%。
query侧:对用户当前搜索词(类目或推荐场景,可通过用户历史搜索词替代)分词后构建的序列;title侧:待排商品标题,经过数据清洗、停用词过滤、分词、扩词后,为了提取标题中的核心词,使用TF-IDF计算每个term词的分数,按照该分数进行降序排列后,取top20。
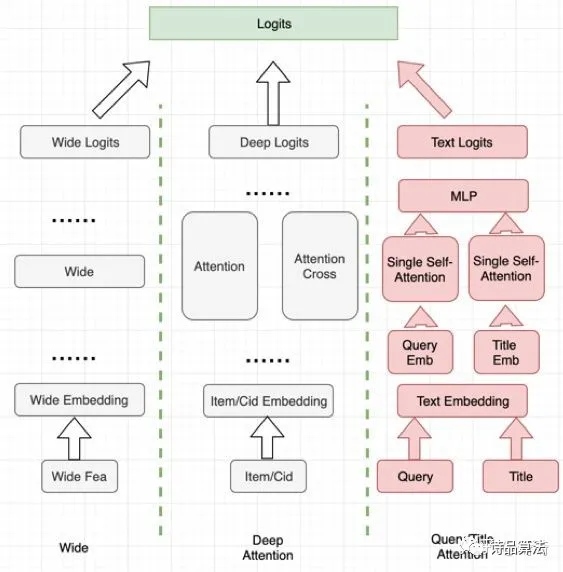
Wide模型:增加当前Query分词和Title分词筛选词的交叉特征。Deep模型:增加当前Query分词和Title分词筛选词的attention交叉。
结构上,在保证原有的wide模块不变的情况下,deep侧平行新增Text Attention模块,具体结构见下图红色部分,用于强化文本信息的表达。
那么问题来了,为何要通过tf-idf提取标题中的核心词呢?在电商场景,为了增加召回率,商家极其擅长堆砌标题,这就让算法工程师们很苦恼了。标题中不同term贡献的信息量是完全不同的,出于模型复杂度考虑,我们不可能将这些term尽数保留。观察以下的例子:“2020年新款女长袖韩版百搭宽松学生套头卫衣连帽外套女ulzzang秋冬时尚学院风”(不得不惊叹于商家词汇量的丰富),对标题分词后,我们需要对每个term进行扩词,每个词可以扩展到3~5个同义词,最终得到的标题序列长度可能超过50。我们当然可以通过去除停用词的方式筛选出一批信息量贡献大的词,但�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%96%87%E6%9C%AC%E7%9B%B8%E5%85%B3%E6%80%A7%E5%9C%A8%E8%98%91%E8%8F%87%E8%A1%97%E6%90%9C%E7%B4%A2%E6%8E%A8%E8%8D%90%E6%8E%92%E5%BA%8F%E7%B3%BB%E7%BB%9F%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


