文字识别在高德地图数据生产中的演进

导读: 丰富准确的地图数据大大提升了我们在使用高德地图出行的体验。相比于传统的地图数据采集和制作,高德地图大量采用了图像识别技术来进行数据的自动化生产,而其中场景文字识别技术占据了重要位置。商家招牌上的艺术字、LOGO五花八门,文字背景复杂或被遮挡,拍摄的图像质量差,如此复杂的场景下,如何解决文字识别技术全、准、快的问题?本文分享文字识别技术在高德地图数据生产中的演进与实践,介绍了文字识别自研算法的主要发展历程和框架,以及未来的发展和挑战。
一 背景
作为一个DAU过亿的国民级软件,高德地图每天为用户提供海量的查询、定位和导航服务。地图数据的丰富性和准确性决定了用户体验。传统的地图数据的采集和制作过程,是在数据采集设备实地采集的基础上,再对采集资料进行人工编辑和上线。这样的模式下,数据更新慢、加工成本高。为解决这一问题,高德地图采用图像识别技术从采集资料中直接识别地图数据的各项要素,实现用机器代替人工进行数据的自动化生产。通过对现实世界高频的数据采集,运用图像算法能力,在海量的采集图片库中自动检测识别出各项地图要素的内容和位置,构建出实时更新的基础地图数据。而基础地图数据中最为重要的是POI(Point of Interest)和道路数据,这两种数据可以构建出高德地图的底图,从而承载用户的行为与商家的动态数据。
图像识别能力决定了数据自动化生产的效率,其中场景文字识别技术占据了重要位置。不同采集设备的图像信息都需要通过场景文字识别(Scene Text Recognition,STR)获得文字信息。这要求我们致力于解决场景文字识别技术全、准、快的问题。在POI业务场景中,识别算法不仅需要尽可能多的识别街边新开商铺的文字信息, 还需要从中找出拥有99%以上准确率的识别结果,从而为POI名称的自动化生成铺平道路;在道路自动化场景中,识别算法需要发现道路标志牌上细微的变化,日处理海量回传数据,从而及时更新道路的限速、方向等信息。与此同时,由于采集来源和采集环境的复杂性,高德场景文字识别算法面对的图像状况往往复杂的多。主要表现为:
- 文字语言、字体、排版丰富:商家招牌上的艺术字体,LOGO五花八门,排版形式各式各样。
- 文字背景复杂:文字出现的背景复杂,可能有较大的遮挡,复杂的光照与干扰。
- 图像来源多样:图像采集自低成本的众包设备,成像设备参数不一,拍摄质量差。图像往往存在倾斜、失焦、抖动等问题。
由于算法的识别难度和识别需求的复杂性,已有的文本识别技术不能满足高德高速发展的业务需要,因此高德自研了场景文字识别算法,并迭代多年,为多个产品提供识别能力。
二 文字识别技术演进与实践
STR算法发展主要历程
场景文字识别(STR)的发展大致可以分为两个阶段,以2012年为分水岭,分别是传统图像算法阶段和深度学习算法阶段。
传统图像算法
2012年之前,文字识别的主流算法都依赖于传统图像处理技术和统计机器学习方法实现,传统的文字识别方法可以分为图像预处理、文字识别、后处理三个阶段:
- 图像预处理:完成文字区域定位,文字矫正,字符切割等处理,核心技术包括连通域分析,MSER,仿射变换,图像二值化,投影分析等;
- 文字识别:对切割出的文字进行识别,一般采用提取人工设计特征(如HOG特征等)或者CNN提取特征,再通过机器学习分类器(如SVM等)进行识别;
- 后处理:利用规则,语言模型等对识别结果进行矫正。
传统的文字识别方法,在简单的场景下能达到不错的效果,但是不同场景下都需要独立设计各个模块的参数,工作繁琐,遇到复杂的场景,难以设计出泛化性能好的模型。
深度学习算法
2012年之后,随着深度学习在计算机视觉领域应用的不断扩大,文字识别逐渐抛弃了原有方法,过渡到深度学习算法方案。在深度学习时代,文字识别框架也逐渐简化,目前主流的方案主要有两种,一种是文本行检测与文字识别的两阶段方案,另一种是端到端的文字识别方案。
1)两阶段文字识别方案
主要思路是先定位文本行位置,然后再对已经定位的文本行内容进行识别。文本行检测从方法角度主要分为基于文本框回归的方法[1],基于分割或实例分割的方法[2],以及基于回归、分割混合的方法[3],从检测能力上也由开始的多向矩形框发展到多边形文本[2],现在的热点在于解决任意形状的文本行检测问题。文本识别从单字检测识别发展到文本序列识别,目前序列识别主要又分为基于CTC的方法[4]和基于Attention的方法[5]。
2)端到端文字识别方案[6]
通过一个模型同时完成文本行检测和文本识别的任务,既可以提高文本识别的实时性,同时因为两个任务在同一个模型中联合训练,两部分任务可以互相促进效果。
文字识别框架
高德文字识别技术经过多年的发展,已经有过几次大的升级。从最开始的基于FCN分割、单字检测识别的方案,逐渐演进到现有基于实例分割的检测,再进行序列、单字检测识别结合的方案。与学术界不同,我们没有采用End-to-End的识别框架,是由于业务的现实需求所决定的。End-to-End框架往往需要足够多高质量的文本行及其识别结果的标注数据,但是这一标注的成本是极为高昂的,而合成的虚拟数据并不足以替代真实数据。因此将文本的检测与识别拆分开来,有利于分别优化两个不同的模型。
如下图所示,目前高德采用的算法框架由文本行检测、单字检测识别、序列识别三大模块构成。文本行检测模块负责检测出文字区域,并预测出文字的掩模用于解决文本的竖直、畸变、弯曲等失真问题,序列识别模块则负责在检测出的文字区域中,识别出相应的文字,对于艺术文本、特殊排列等序列识别模型效果较差的场景,使用单字检测识别模型进行补充。
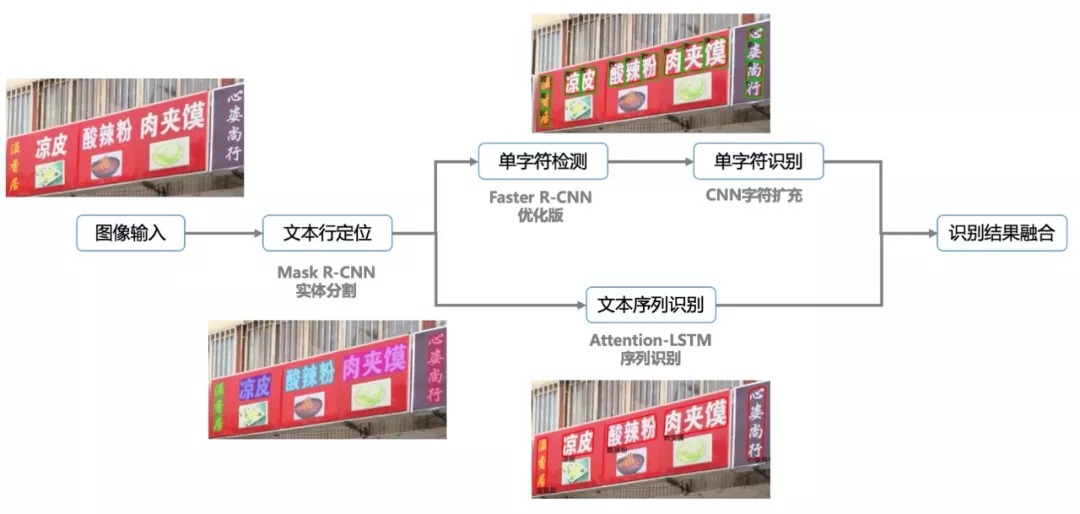
文字识别框架
文本行检测
自然场景中的文字区域通常是多变且不规则的,文本的尺度大小各异,成像的角度和成像的质量往往不受控制。同时不同采集来源的图像中文本的尺度变化较大,模糊遮挡的情况也各不相同。我们根据实验,决定在两阶段的实例分割模型的基础上,针对实际问题进行了优化。
文本行检测可同时预测文字区域分割结果及文字行位置信息,通过集成DCN来获取不同方向的文本的特征信息,增大mask分支的feature大小并集成ASPP模块,提升文字区域分割的精度。并通过文本的分割结果生成最小外接凸包用于后续的识别计算。在训练过程中,使用online的数据增广方法,在训练过程中对数据进行旋转、翻转、mixup等,有效的提高了模型的泛化能力。具体检测效果如下所示:

检测结果示例
目前场景文本检测能力已经广泛应用于高德POI、道路等多个产品中,为了验证模型能力,分别在ICDAR2013(2018年3月)、ICDAR2017-MLT(2018年10月)、ICDAR2019-ReCTS公开数据集中进行验证,并取得了优异的成绩。
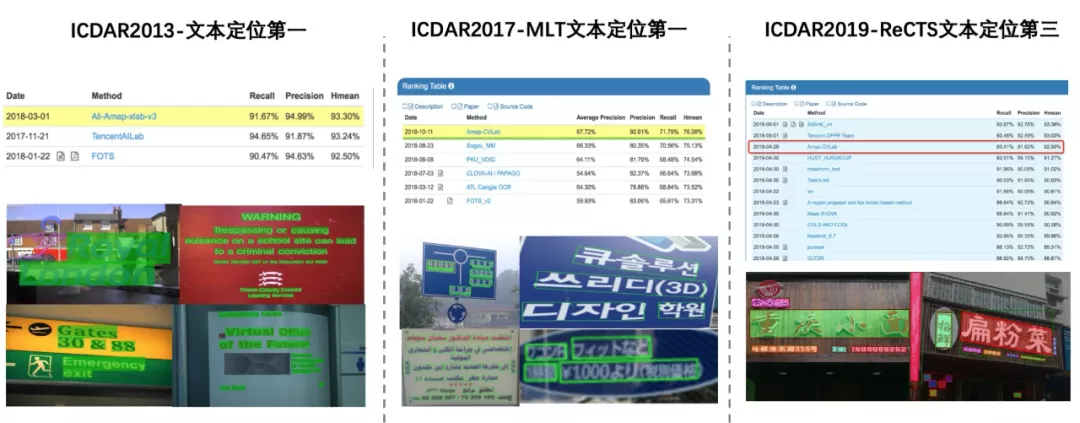
文本行检测竞赛成绩
文字识别
根据背景的描述,POI和道路数据自动化生产对于文字识别的结果有两方面的需求,一方面是希望文本行内容尽可能完整识别,另外一方面对于算法给出的结果能区分出极高准确率的部分(准确率大于99%)。不同于一般文字识别评测以单字为维度,我们在业务使用中,更关注于整个文本行的识别结果,因此我们定义了符合业务使用需求的文字识别评价标准:
- 文本行识别全对率:表示文字识别正确且读序正确的文本行在所有文本行的占比。
- 文本行识别高置信占比:表示识别结果中的高置信度部分(准确率大于99%)在所有文本行的占比。
文本行识别全对率主要评价文字识别在POI名称,道路名称的整体识别能力,文本行识别高置信占比主要评价算法对于拆分出识别高准确率部分的能力,这两种能力与我们的业务需求紧密相关。为了满足业务场景对文字识别的需求,我们针对目前主流的文字识别算法进行了调研和选型。
文字识别发展到现在主要有两种方法,分别是单字检测识别和序列识别。单字检测识别的训练样本组织和模型训练相对容易,不被文字排版的顺序影响。缺点在某些"上下结构",“左右结构"的汉字容易检测识别错误。相比之下序列识别包含更多的上下文信息,而且不需要定位单字精确的位置,减小因为汉字结构导致的识别损失。但是现实场景文本的排版复杂,“从上到下”,“从左到右"排版会导致序列识别效果不稳定。结合单字检测识别和序列识别各自的优缺点,采用互补的方式提高文字识别的准确率。
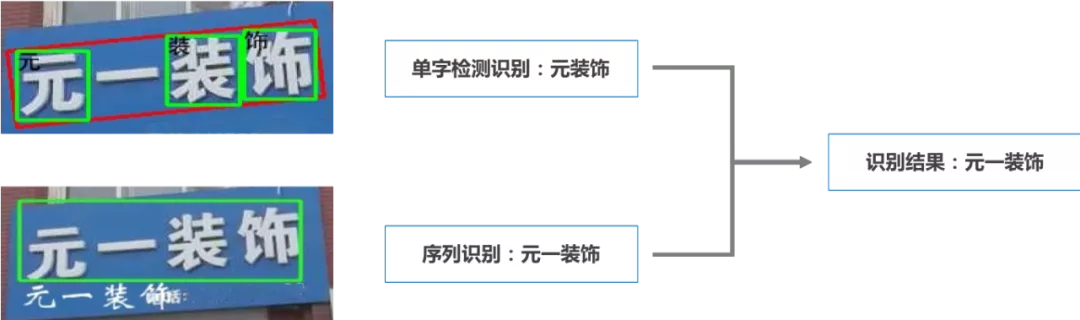
单字检测识别和序列识别结果融合
1)单字检测识别
单字检测采用Faster R-CNN的方法,检测效果满足业务场景需求。单字识别采用SENet结构,字符类别支持超过7000个中英文字符和数字。在单字识别模型中参考identity mapping的设计和MobileNetV2的结构,对Skip Connections和激活函数进行了优化,并在训练过程中也加入随机样本变换,大幅提升文字识别的能力。在2019年4月,为了验证在文字识别的算法能力,我们在ICDAR2019-ReCTS文字识别竞赛中获得第二名的成绩(准确率与第一名相差0.09%)。

单字检测识别效果图
2)文本序列识别
近年来,主流的文本序列识别算法如Aster、DTRT等,可以分解为文字区域纠正,文字区域特征提取、序列化编码图像特征和文字特征解码四个子任务。文字区域纠正和文字区域特征提取将变形的文本行纠正为水平文本行并提取特征,降低了后续识别算法的识别难度。序列化编码图像特征和文字特征解码(Encoder-Decoder的结构)能在利用图像的纹理特征进行文字识别的同时,引入较强的语义信息,并利用这种上下文的语义信息来补全识别结果。
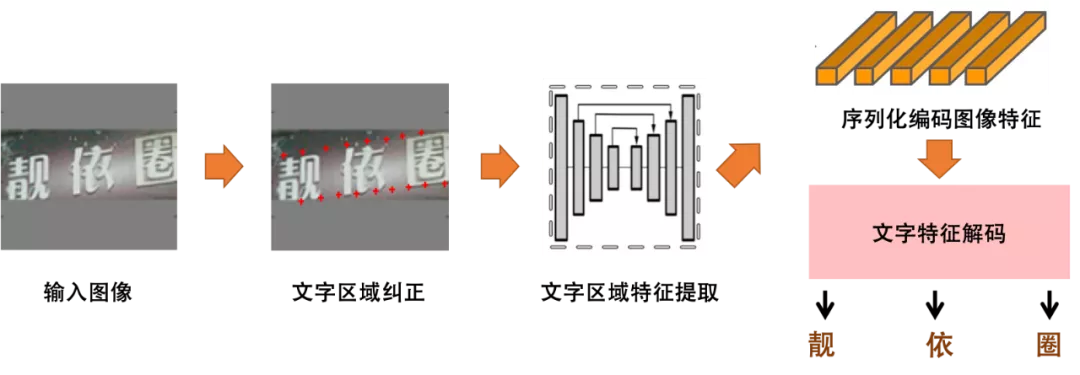
通用序列识别结构
在实际应用中,由于被识别的目标主要以自然场景的短中文本为主,场景文本的几何畸变、扭曲、模糊程度极为严重。同时希望在一个模型中识别多个方向的文本,因此我们采用的是的TPS-Inception-BiLSTM-Attention结构来进行序列识别。主要结构如下所示:
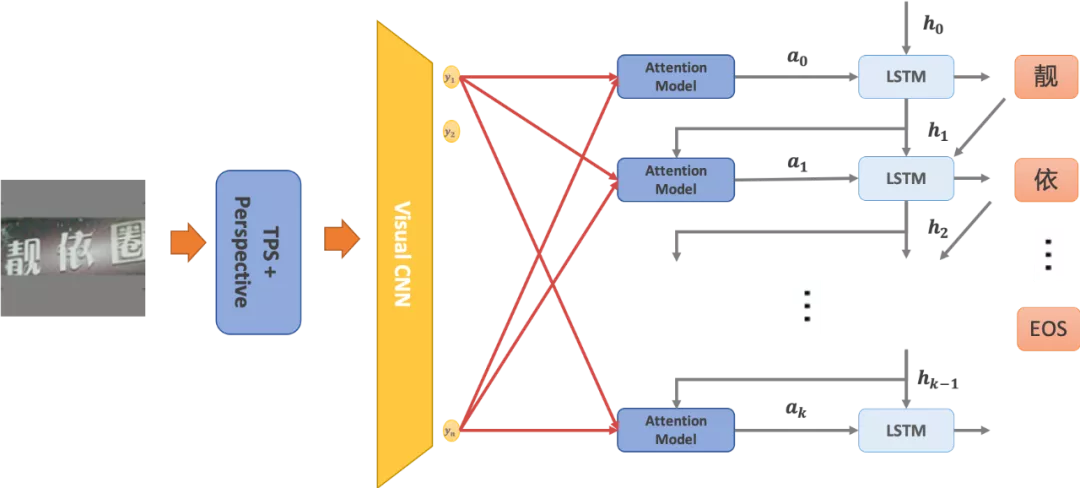
文本序列识别模型
对于被检测到的文本行,基于角点进行透视变换,再使用TPS变换获得水平、竖直方向的文本,按比例缩放长边到指定大小,并以灰色为背景padding为方形图像。这一预处理方式既保持了输入图像语义的完整,同时在训练和测试阶段,图像可以在方形范围内自由的旋转平移,能够有效的提高弯曲、畸变文本的识别性能。将预处理完成的图像输入CNN中提取图像特征。再使用BiLSTM编码成序列特征,并使用Attention依次解码获得预测结果。如下图所示,这一模型通过注意力机制在不同解码阶段赋予图像特征不同的权重,从而隐式表达预测字符与特征的对齐关系,实现在一个模型中同时预测多个方向文本。文本序列识别模型目前已覆盖英文、中文一级字库和常用的繁体字字库,对于艺术文本、模糊文本具有较好的识别性能。

序列识别效果
3)样本挖掘&合成
在地图数据生产业务中经常会在道路标志牌中发现一些生僻的地点名称或者在POI牌匾中发现一些不常见的字甚至是繁体字,因此在文字识别效果优化中,除了对于模型的优化外,合理补充缺字、少字的样本也是非常重要的环节。为了补充缺字、少字的样本,我们从真实样本挖掘和人工样本合成两个方向入手,一方面结合我们业务的特点,通过数据库中已经完成制作的包含生僻字的名称,反向挖掘出可能出现生僻字的图像进行人工标注,另一方面,我们利用图像渲染技术人工合成文字样本。实际使用中,将真实样本和人工合成样本混合使用,大幅提升文字识别能力。

样本挖掘和合成方案
文字识别技术小结
高德文字识别算法通过对算法结构的打磨,和多识别结果的融合,满足不同使用场景的现实需要。同时以文字识别为代表的计算机视觉技术,已广泛应用于高德数据自动化生产的各个角落,在部分采集场景中,机器已完全代替人工进行数据的自动化生产。POI数据中超过70%的数据都是由机器自动化生成上线,超过90%的道路信息数据通过自动化更新。数据工艺人员的技能极大简化,大幅节约了培训成本和支出开销。
三 未来发展和挑战
目前高德主要依赖深度学习的方式解决场景文字的识别问题,相对国外地图数据,国内汉字的基数大,文字结构复杂导致对数据多样性的要求更高,数据不足成为主要痛点。另外,图像的模糊问题往往会影响自动化识别的性能和数据的制作效率,如何识别模糊和对模糊的处理也是高德的研究课题之一。我们分别从数据,模型设计层面阐述如何解决数据不足和模糊识别的问题,以及如何进一步提高文字识别能力。
数据层面
数据问题很重要,在没有足够的人力物力标注的情况下,如何自动扩充数据是图像的一个通用研究课题。其中一个思路是通过数据增广的方式扩充数据样本。Google DeepMind在CVPR 2019提出AutoAugment的方法, 主要通过用强化学习的方法寻找最佳的数据增广策略。另一种数据扩充的解决办法是数据合成,例如阿里巴巴达摩院的SwapText利用风格迁移的方式完成数据生成。
模型层面
模糊文本的识别
模糊通常造成场景识别文本未检测和无法识别的问题。在学术界超分辨率是解决模糊问题的主要方式之一,TextSR通过SRGAN对文本超分的方式,还原高清文本图像,解决模糊识别的问题。对比TextSR,首尔大学和马萨诸塞大学在Better to Follow文中提出通过GAN对特征的超分辨率方式,没有直接生成新的图像而是将超分辨率网络集成在检测网络中,在效果接近的同时,由于其采用End-to-End的模式,计算效率大幅提高。
文字语义理解
通常人在理解复杂文字时会参考一定的语义先验信息,近年来随着NLP(Natural Language Processing)技�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%96%87%E5%AD%97%E8%AF%86%E5%88%AB%E5%9C%A8%E9%AB%98%E5%BE%B7%E5%9C%B0%E5%9B%BE%E6%95%B0%E6%8D%AE%E7%94%9F%E4%BA%A7%E4%B8%AD%E7%9A%84%E6%BC%94%E8%BF%9B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


