携程机器学习模型在携程海外酒店推荐场景中的应用
作者简介
Louisa,携程算法工程师,热爱前沿算法和技术在个性化推荐和广告建模等业务的性能优化和落地。
发表于: 2020年8月13日
导读
互联网企业的核心需求是“增长”,移动互联时代下的在线旅游业也不例外。随着大数据、云计算和人工智能等技术的不断进步, 通过算法和模型来实现增长已成为核心。
近年来推荐系统迅速崛起,主要解决在信息过载的情况下,帮助用户高效获取感兴趣的信息,同时帮助企业最大限度的吸引用户、留存用户、增加用户黏性、提高用户转化率。因此个性化的推荐服务对于在线旅游业也变得非常重要,通过推荐能够将用户从众多的旅行选择中解放出来,指导用户快速找到感兴趣的项目,大大简化用户的旅行计划和购买。
在线旅游服务商 (OTA)提供的应用中包含酒店、航班、旅游产品、攻略等各个环节和产品。其中酒店涉及到的推荐场景较多,例如城市热门酒店推荐、附近同类型酒店推荐、机票页酒店交叉推荐、Meta着陆页相似酒店推荐、信息流推荐等。大部分场景都实现了个性化的推荐服务,其核心就是一组酒店与一组用户相匹配的挑战。
推荐准确性取决于如何利用可用信息,这些信息主要包括物品信息(I)、用户信息(U)及上下文信息(C)等,例如给定的酒店特征、酒店的位置吸引力、用户的购买历史等。将这些信息构建一个函数 f(U,I,C),预测用户对特定候选酒店的喜好程序,再根据喜好程度对所有候选酒店进行排序,生成推荐列表。见图1推荐系统逻辑框架。
推荐系统排序模型在推荐系统中占据绝对核心的地位,很多公司也都在提出并尝试一些前沿的算法和推荐模型。而机器学习和深度学习模型正在变得越来越复杂,将这种复杂模型推上线,模型响应速度就可能变得很慢,因此对推荐系统的数据流和工程实现产生新的挑战。
**如何做到海量数据的实时处理、特征的实时提取、线上模型服务过程的数据实时获取以及工程能力与技术方案的平衡等,成为模型上线的重要挑战。**本文主要探讨OTA酒店推荐方面常用的在线部署模型以及技术架构,并从核心之外的角度审视推荐系统的不同技术模块及优化思路。
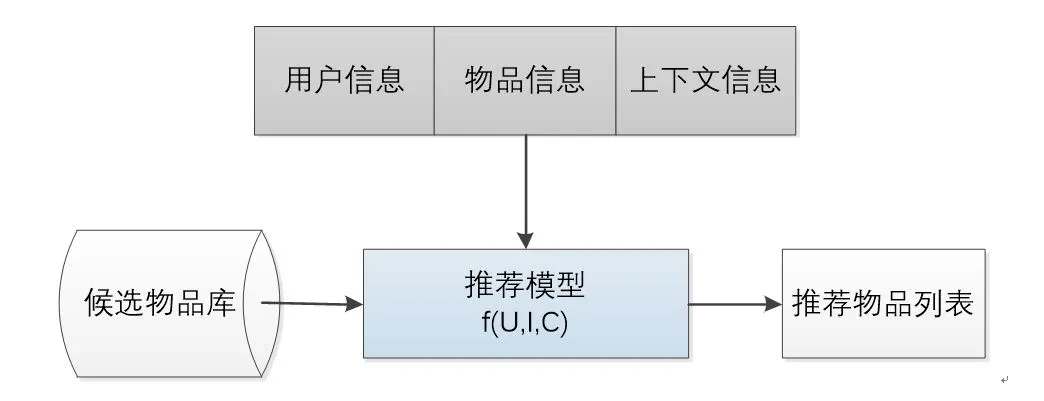
图1 推荐系统逻辑框架
一、酒店推荐系统的技术架构
实际推荐系统中主要解决的问题可以分为两类, 数据部分以及算法模型部分。其中数据部分融合了数据离线批处理、实时流处理的数据流框架。算法模型部分则是集训练 (training)、评估 (evaluation)、部署 (deployment)、线上推断 (online inference) 为一体的模型框架。目前通用的推荐系统技术架构如图2所示。
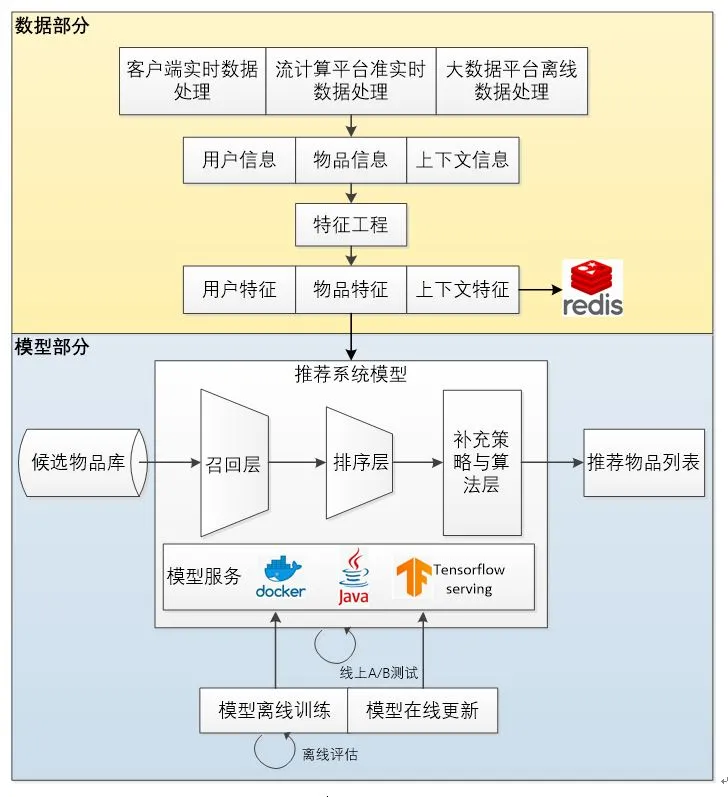
图2 推荐系统的技术架构示意图
1.1 数据部分
推荐系统的数据部分主要负责用户、物品、上下文的信息收集与处理。并且按实时性强弱,分别在三种平台上进行处理。客户端是最接近用户的环节,也是能够实时收集用户会话内行为及上下文特征的地方,这些特征随http请求一起到达服务器端是常用的请求推荐结果的方式。
随着Storm、Spark Streaming、Flink等流计算平台的日益成熟,利用流计算平台进行准实时的特征处理已经成为当前推荐系统的主要模式。流计算平台并非完全实时的平台,每次需要等待并处理一小批日志,以流的形式进行微批处理(mini batch),系统可能无法在3分钟内把session内部的行为历史存储到特征数据库(如Redis)中。但它的优势是能够进行一些简单的特征统计的计算,比如一个物品在该时间窗口内的曝光次数,点击次数、一个用户的页面浏览时长等。
大数据离线数据处理主要是利用Spark等分布式批处理计算平台对全量特征进行计算和抽取。主要用于模型训练和离线评估,以及将特征保存入特征数据库,供之后的线上推荐模型使用。
酒店推荐系统中的实时特征部分主要来源于用户的实时点击行为数据和一些上下文信息(如GPS获得的地点信息等),通过Storm或Flink进行准实时流处理,将用户实时行为数据解析入特征数据库Redis。
离线特征部分主要包含用户和酒店两部分的特征。其中用户离线特征主要由用户画像(CRM)提供,包含数据库中用户的订单和浏览历史信息等,并且严格遵守欧盟通用数据保护条例(GDPR)。酒店离线特征主要包含酒店的基础信息,如星级、评分等。由于特征维度及样本量较大,离线特征数据的清洗与预处理通常在Spark平台上进行,后将处理好的特征数据落入HDFS的Hive表并同步至Redis缓存中。离线特征与实时特征合并供线上模型使用。下面代码展示Hive表数据同步Redis的方法:

1.2 模型部分
模型部分是推荐系统的主体,一般由召回层、排序层、补充策略与算法层组成。召回层一般利用高效的召回规则、算法或者简单的模型,快速从海量的候选集中召回用户可能感兴趣的物品。排序层利用排序模型对筛选的候选集进行精排序。排序层是推荐系统产生效果的重点,后面部分将重点介绍一些主流推荐模型和酒店推荐上的应用。
补充策略与算法层也被称为再排序层,再将推荐列表返回用户之前,根据新鲜度、多样性等指标结合补充策略与算法进行一定调整,最终形成用户可见的推荐列表。从召回所有候选物品集,到最后产生推荐列表,这一过程一般称为模型服务过程。
在线环境进行模型服务之前,需要通过模型训练确定模型结构及参数值,并生成模型文件。另外,为了评估推荐模型的效果,方便模型的迭代优化,推荐模型部分有离线评估和线上A/B测试等多种线上线下评估模式。
二、酒店推荐系统的工程实现
如何将离线训练好的模型部署在线上的生成环境,进行线上实时推断,一直是业界难点。目前酒店推荐场景中主要用到两种部署推荐模型的主流方法,一是利用PMML转换并部署模型,二是Tensorflow Serving方式。
2.1 利用PMML转换并部署模型
酒店推荐场景中由于实时数据量较大,通常采用SOA框架实现分布式服务,完成模型服务过程。但绝大部分SOA框架都是Java或C++语言编写,而预测模型大多是基于Python语言。因此常用预测模型标记语言(Predictive ModelMarkup Language,以下简称PMML)重新实现算法模型,然后将模型封装成类,通过JAVA调用这个类来进行预测。由python封装的模型可以通过sklearn中的sklearn2pmml函数实现PMML文件转换。XGBoost模型需要JPMML-XGBoost命令行转换工具,转换命令为:

XGBoost模型需要生成.model模型文件和 .fmap特征映射文件。.model文件可以通过save_model函数生成。
2.2 Tensorflow Serving
上面的方法也适用于Tensorflow生成的模型,但由于Tensorflow模型文件往往较大,且PMML文件无法优化,使用起来比较麻烦。本质上讲,Tensorflow Serving的工作流程和PMML类工具的流程是一致的。不同之处在于,Tensorflow定义了自己的模型序列化标准。
利用Tensorflow自带的模型序列化函数可将训练好的模型参数和结构保存至某文件路径。路径下包括variables文件夹和saved_model.pbtxt文件。variable文件夹下包含各个变量的状态(断点),有*.data和*.index两类文件。 .data记录变量的内容。.index文件用于将变量名映射到*.data中的变量数据。.pbtxt文件是包含SavedModel、MetaGraphs、Graphs、签名等的二进制protobuf。模型文件通常由自身的Python API生成,然后由Tensorflow的客户端库(如JAVA或C++库)来加载模型并进行在线预测。以下代码展示了使用SavedModelBuilder 构建 SavedModel 的典型方法:

添加Tensorflow相关依赖后Java导入已保存的模型方法为:

具体的酒店实时推荐工程架构如图3所示。
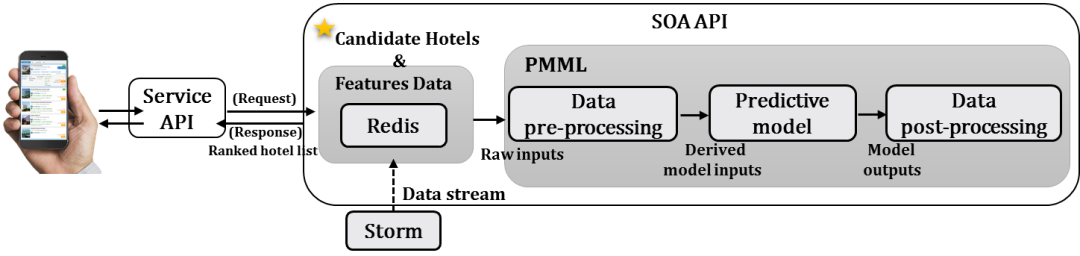
图3 酒店实时推荐工程架构
三、Embedding技术在酒店推荐中的应用
Embedding方法已成为应用最广泛的深度学习技术。通过低维的向量表示一个对象,可以同时表达对象之间的潜在关系,即向量之间的距离反应对象之间的相似性。该方法的流行始于自然语言处理领域对于词向量生成问题的研究,发展到其他应用领域的物品也可以通过某种方式生成其向量化表示,例如旅游领域对酒店进行Embedding,并对酒店进行相似度计算,因此成为常用的推荐系统召回层技术。
Embedding技术中最著名的就是Word2vec模型,用于生成对词的向量表达。而对于用户购买序列中的商品或者用户浏览序列中的酒店使用的Embedding方法称为Item2vec方法。
在酒店召回层我们采用了酒店Embedding技术计算相似度,召回候选酒店集。在Word2vec方法中词的上下文即为邻近词的序列,而词的序列其实等价于一系列连续操作的item序列。因此,我们将用户一次浏览会话中连续点击的酒店序列作为训练语料,学习酒店的向量表示。抽取用户的连续点击如表1所示。酒店间的共现为正样本,且按照酒店的频率分布进行负样本采样。
表1 用户在同一个会话下的酒店连续点击记录
uidsessionidhotelid00111701976, 480887, 1525866, 8468380024686430,1542818,993356,1525732,1525866,688217,1701976,1007025
酒店嵌入矩阵(Embeddingmatrix)的行数为酒店的总个数,列数为嵌入维度。酒店相似度使用余弦相似度。将相似度得分从高到低排序,选取TopN酒店做候选酒店。酒店向量生成使用的是Word2vec模型中的Skip-Gram模型。Skip-Gram神经网络模型训练一个带有单个隐含层的简单神经网络来执行某个预测任务,训练好的模型并不用于实际预测,其真正目的是获取输入层-隐含层的权重矩阵,将这些权重值视为词向量。
图4展示了当skip_window = 2时(即仅选输入词前后各两个词和输入词进行组合),训练样本是如何产生的(蓝色代表输入词,方框内代表位于窗口内的单词)。通过输入文本中成对的单词来训练神经网络,其输出概率代表着到词典中每个词有多大可能性跟输入单词同时出现。
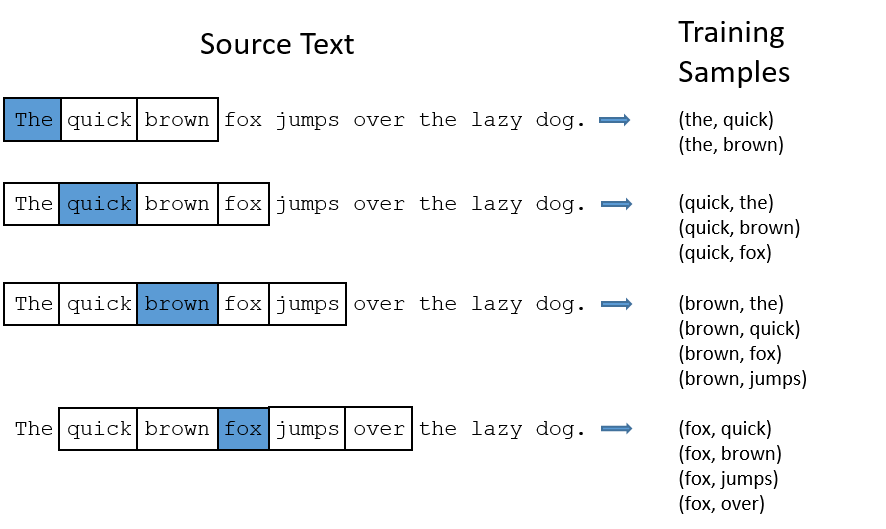
图4 训练样本生成
每个词wt都决定了wt+j,基于极大似然估计方法,希望所有样本的条件概率p(wt+j|wt)之积最大,这里使用对数概率。因此Word2vec的目标函数如公式(1)所示。
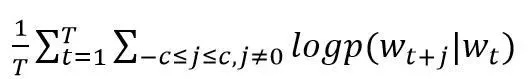 (1)
(1)
基于训练数据需要构建词汇表并对单词做one-hot编码。神经网络结构如图5所示。假设从训练数据中抽取出10000个唯一不重复的单词组成词汇表,则模型的输入为10000维的向量,输出也是10000维的向量。每一维输出都是一个概率,代表当前词是输入样本时输出词的概率大小。
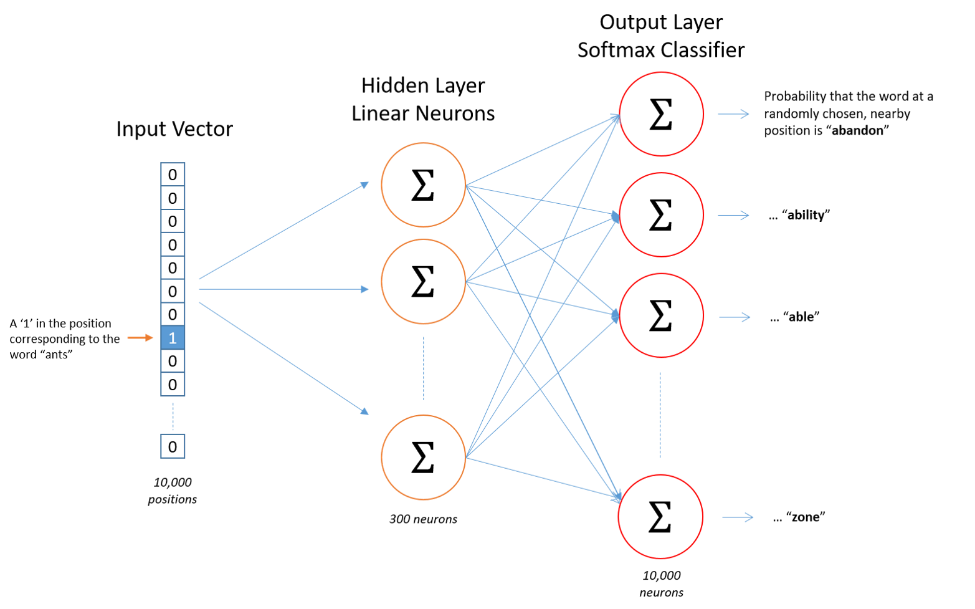
图5 Skip-Gram神经网络
隐含层不使用激活函数,输出层使用softmax计算输出概率。由于权重矩阵规模非常大,通过梯度下降更新权重是相当慢的,并且需要大量的训练数据避免过拟合。因此通常对优化目标采用负采样方法,即每个训练样本的训练只会更新一小部分的模型权重,从而降低计算负担。Skip-Gram模型的Tensorflow核心代码如下所示:

Word2vec和由其衍生出的Item2vec是Embedding技术的基础性方法,但都是建立在序列样本的基础上。在互联网场景下,数据对象之间更多呈现的是图结构。典型的场景是由用户行为数据生成的物品关系图,如图6(a)(b) 所示,以及由属性和实体组成的知识图谱,如图6(c)所示。
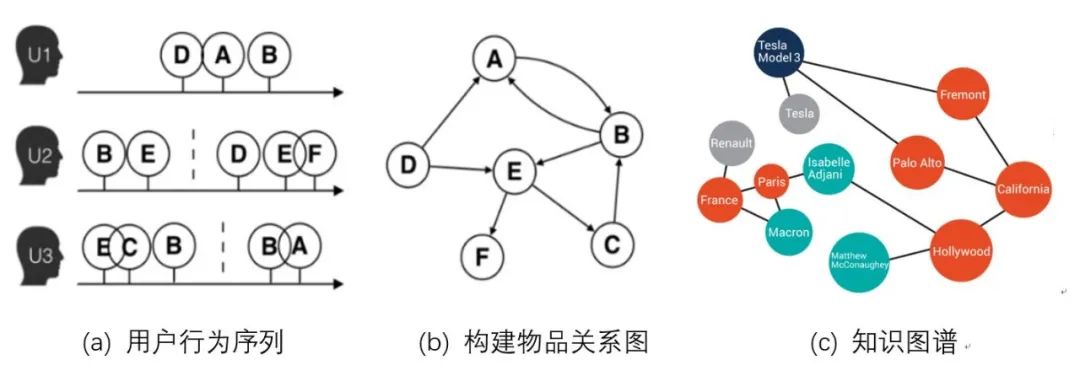
图6 物品关系图与知识图谱
由于用户浏览酒店的模式不一定呈现序列结构,而是一种关系图结构,我们后期尝试Graph Embedding中的DeepWalk方法对图结构中的节点酒店进行Embedding。即在由酒店组成的图结构上进行随机游走(如图7所示),产生大量酒店序列,然后将这些物品序列作为训练样本输入Word2vec进行训练,得到酒店的Embedding。在DeepWalk算法中,需要定义随机游走的跳转概率,即到达节点vi后,下一步遍历vi的邻接点vj的概率。见公式(2)。

图7 随机游走
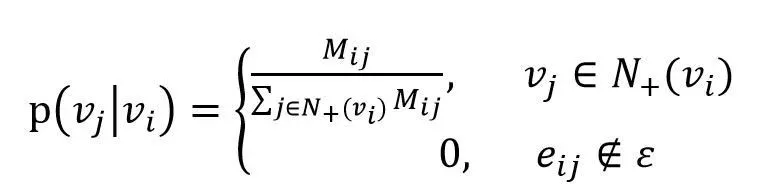 (2)
(2)
其中ε是物品关系图中所有边的集合。如果物品关系图是有向有权图,则N+(vi)是节点vi所有的出边集合,Mij是节点vi到节点vj边的权重。如果物品关系图是无向无权图,则权重Mij将为常数1,且N+(vi)是节点vi所有边的集合。酒店推荐场景采用无权无向图结构进行训练。
四、酒店推荐系统中的模型应用
深度学习之前传统的推荐模型发展主要由这几部分组成:协同过滤算法族、逻辑回归模型族、因子分解机模型族以及组合模型,思路演化主要是增强泛化能力、保留记忆能力、挖掘特征组合关系。
经典的协同过滤算法曾是推荐系统的首选模型,并且衍生出矩阵分解模型,能够更好的处理稀疏共现矩阵问题,增强模型的泛化能力。在酒店推荐中我们也常常将协同过滤作为召回层的算法使用。与协同过滤仅利用用户和物品之间的显式或隐式反馈信息相比,逻辑回归能够利用和融合更多用户、物品及上下文特征。并发展出来因子分解机模型FM,加入二阶部分,使模型具备进行特征组合的能力。在此基础上又发展出域感知因子分解机FFM,进一步加强因子分解机特征交叉的能力。
另外为了融合多个模型优点,将不同模型组合使用成为推荐模型常用的方法。Facebook提出的GBDT+LR[ 梯度提升决策树+逻辑回归 ] 组合模型是在业界影响力较大的组合方式。其中GBDT作为有监督的特征转换器,对于连续型特征和离散特征分别做离散化非线性变换和笛卡尔乘积的特征组合,将实数向量转换为简单的二进制值向量,构造新特征向量。LR用于新特征向量的训练,并取得比单独使用两个模型都好的结果。组合模型中体现的特征工程模型化的思想,成为深度学习推荐模型的主要思想之一。
酒店推荐系统仍然延续通常意义上的CTR(Click- through rate)预估类的优化目标,其任务核心衍生为把推荐问题当作分类问题对待,预测用户点击某个酒店的概率CTR,并且返回用户一组按CTR从高到低排序的酒店列表。因此也称为搜索排序系统。
酒店推荐场景亦属于高度稀疏数据,往往需要解决记忆/泛化问题及特征交互问题。因此深度学习模型的优势就展现出来,通过学习一种低维的特征向量表示(Dense Embedding),深度神经网络已经表现出自动学习复杂特征交互的潜力。并且通过较少的特征工程,可以从稀疏特征中更好的泛化去发现特征关联。深度学习推荐模型大量借鉴并融合了深度学习在图像、语音及自然语言处理方向的成果,在模型结构上进行了快速的演化。主要有以下几种演变方向。
(1)改变神经网络的复杂结构,从单层神经网络模型AutoRec到经典的Deep Crossing(深度特征交叉),增加了深度神经网络的层数和结构复杂度。
(2)改变特征交叉方式,例如NeuralCF(神经网络协同过滤)和PNN(基于积操作的神经网络)模型。
(3)组合模型,主要是指Wide&Deep模型及其后续变种Deep&Cross、DeepFM等,通过组合不同特点、优势互补的网络,提升模型的综合能力。
(4)注意力机制与推荐模型的结合,主要包括FM与注意力机制的AFM和DIN(深度兴趣网络)。
(5)其他结合方式(序列模型、强化学习与推荐模型的结合等)。
以下简单介绍几种在推荐模型演化过程中常用的模型结构和原理。
4.1 Factorization Machines(因式分解机)
对于一个给定的特征向量
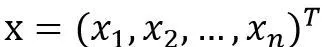 ,线性回归建模时采用的函数是
,线性回归建模时采用的函数是
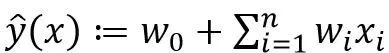 (3)
(3)
其中, W0和
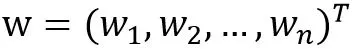 为模型参数。方程中各特征分量xi和xj (i≠j)之间相互独立,即
为模型参数。方程中各特征分量xi和xj (i≠j)之间相互独立,即
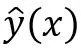 中仅考虑单个的特征分量,而没有考虑特征分量之间的相互关系。因此将
中仅考虑单个的特征分量,而没有考虑特征分量之间的相互关系。因此将
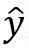 改写为:
改写为:
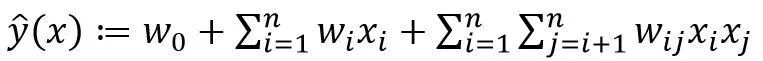 (4)
(4)
公式中增加了任意两个不同特征之间的关系。但是在稀疏数据中,这样的建模方式存在一个缺陷,对于训练数据中未出现交互的特征分量,不能对相应的参数进行估计。而在类似推荐这种高度稀疏数据场景中,样本中出现未交互的特征分量是很普遍的。
为了克服上面的缺陷,针对每个维度的特征分量xi引入辅助向量
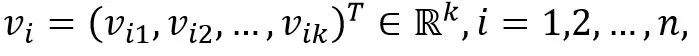
其中
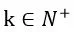 为超参数, wij改写为
为超参数, wij改写为
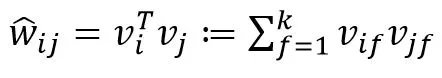
则
 模型方程可以改写为:
模型方程可以改写为:
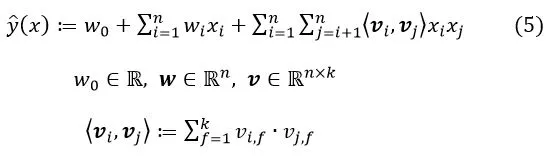
由于
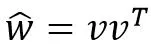 对应一种矩阵分解技术,因此模型方程的方法称为Factorization Machines。该模型方程可以证明在线性时间0(kn) 内计算,并且方程可以进一步推导为:
对应一种矩阵分解技术,因此模型方程的方法称为Factorization Machines。该模型方程可以证明在线性时间0(kn) 内计算,并且方程可以进一步推导为:
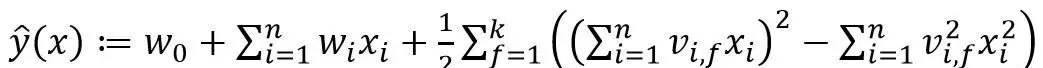 (6)
(6)
FactorizationMachines的Tensorflow核心实现代码如下:

4.2 Wide & Deep Learning
深度学习存在过度泛化的问题,当用户与物品交互较少即特征向量稀疏时推荐一些与用户不相关的项目(例如用户有特定的偏好或者一些小众项目),这种情况下大多数项目不应该被推荐,但是Dense Embedding会给出非0的预测,因此不相关的项目也会被推荐。而进行特征交叉乘积变换的线性模型能够记忆这些特殊情况或例外规则,并且使用更少的参数。Google在2016年提出了Wide& Deep模型,很好的结合了线性模型的记忆能力和深度神经网络的泛化能力,在训练过程中同时优化2个模型的参数,从而达到整体模型的预测能力最优。模型结构如图9所示。
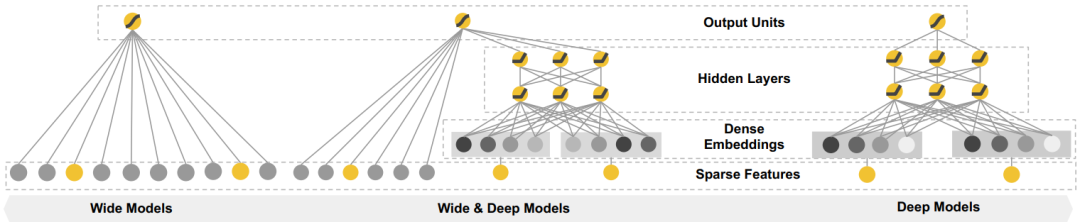
图9 Wide & Deep模型结构
Wide部分就是LR,输入特征包含了原始特征和交叉特征。Deep部分是MLP网络,隐含层的激活函数使用ReLUs=max(0,a),输入特征包含了连续的特征和embedding特征。对于一个逻辑回归任务Wide & Deep模型预测方程为:
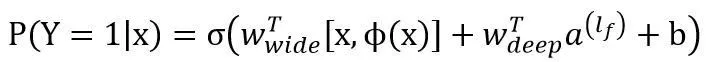 (7)
(7)
其中Y是二分类标签,σ(.)是sigmoid函数,∅(x)是原始特征的交叉乘积转换。Wwide是所有线性模型的权重向量,Wdeep是应用于最后激活层输出
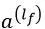 的权重。
的权重。
Wide& Deep建模可以使用Tensorflow高级API,建模步骤如下:
(1)选择Wide部分的特征(wide_columns):稀疏基础特征和交叉特征。
(2)选择Deep部分的特征(deep_columns):连续型特征、类别特征(编码)。
(3)将Wide & Deep特征合并输入模型(DNNLinearCombinedClassifier)。

4.3 FTRL 算法
Wide& Deep模型训练方面常使用结合 L1 正则的Follow-the-regularized-leader (FTRL) 算法进行Wide部分训练,而Deep部分使用AdaGrad算法进行训练。
其中FTRL算法可以实施于在线学习,对模型参数进行实时更新,在处理诸如逻辑回归之类的带非光滑正则化项的凸优化问题上性能非常出色。像Batch Gradient Descent 等优化算法,是对一批样本进行一次求解,得到一个全局最优解。而实际CTR预测需要更快速地更新模型,模型的参数需要针对每一个新来样本进行一次迭代。因此可以通过工程上实现FTRL算法,从而快速更新模型的参数。FTRL算法的特征权重更新公式为:
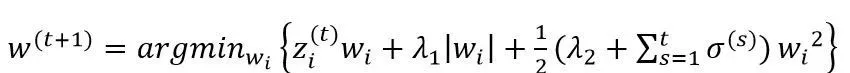 (8)
(8)
其中
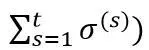 是针对每个特征维度的学习率。如果特征 A 比特征 B变化快,那么在维度 A 上面的学习率应该比维度 B 上面的学习率下降得更快。维度i的学习率定义为:
是针对每个特征维度的学习率。如果特征 A 比特征 B变化快,那么在维度 A 上面的学习率应该比维度 B 上面的学习率下降得更快。维度i的学习率定义为:
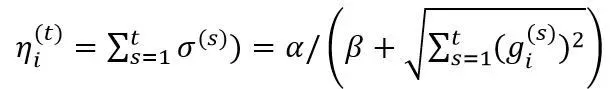 (9)
(9)
在Logistic Regression中,假设σ(a)=1/(1+exp(-a))是sigmoid函数,yt∈{0,1},需要预测Pt=σ(Wt),损失函数使用LogLoss函数:
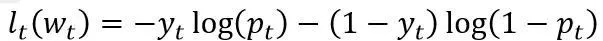 (10)
(10)
梯度
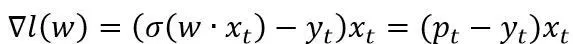 .Logistic Regression的FTRL算法为:
.Logistic Regression的FTRL算法为:

4.4 DeepFM
Wide & Deep 模型中需要宽度部分和深度部分两类不同的输入,而宽度部分仍然需要依赖大量的特征工程工作。2018年提出的DeepFM 模型结合了分解向量机(FM)和深度神经网络(DNN),既能学习复杂的低阶与高阶特征交互又不需要原始特征以外的特征工程,并且允许端到端的学习方式。模型结构如图10所示。嵌入层(Dense Embedding)将原始输入向量压缩到低维稠密向量,作为FM和深度部分的输入。因此不同于Wide & Deep 模型,DeepFM的FM部分和深度部分共享相同的输入向量,从而可以进行端到端的训练。
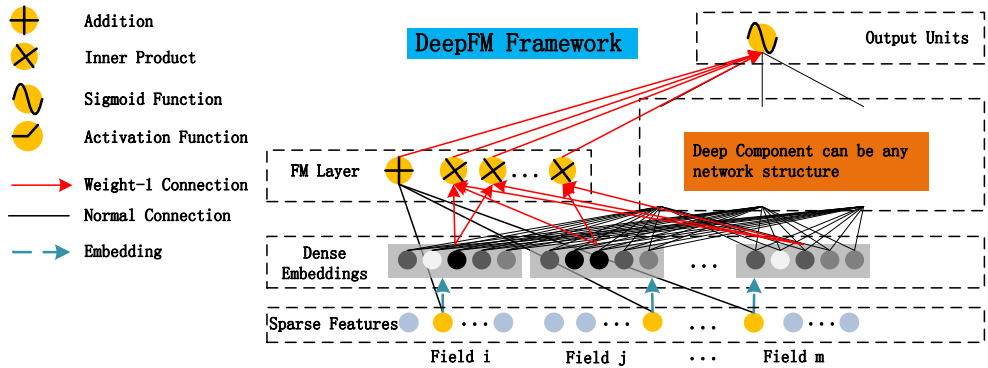
图10 DeepFM 模型结构
尽管不同Field的输入长度不同,但是Embedding之后的Dense vector的长度均为k。Dense vector其实就是输入层到Embedding层该神经元相连的k条线的权重,即
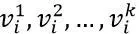 。这k个值组合起来就是我们在FM中所提到的辅助向量vi,即FM和深度神经网络的共享输入向量。其中深度部分可以使用不同的神经网络结构。如图所示DeepFM模型是一种并行结构,预测结果可以表示为:
。这k个值组合起来就是我们在FM中所提到的辅助向量vi,即FM和深度神经网络的共享输入向量。其中深度部分可以使用不同的神经网络结构。如图所示DeepFM模型是一种并行结构,预测结果可以表示为:
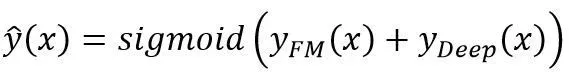 (11)
(11)
DeepFM 模型的Tensorflow核心实现代码如下:

五、酒店推荐系统评估
推荐系统一般分为离线评估和在线评估两部分。离线评估的指标主要是机器学习模型常用的一些评估指标,包括准确率、精确率与召回率、F1-Score、AUC值等。在线评估的主要方式是A/B测试,主要评估指标有点击率、转化率、点击排名等。
为了测试模型效果,我们选取了某一个酒店推荐场景,并抽取100万左右数据作为训练样本。其中正样本为用户点击,负样本为有露出但用户未点击,并对数据集做样本平衡处理。特征部分不赘述。模型离线表现如表2所示。
表2 模型离线表现对比
**Model****AUC (5000 iters)**Logistic Regression0.597Xgboost0.737XGBoost+LR0.75FM0.599Wide & Deep0.799DeepFM0.80
在线测试部分使用A/B测试,其中A版本为旧版本,推荐算法基于规则推荐,B版本为新版本,使用XGBoost模型进行酒店点击率预测并排序,同时使用基于酒店的协同过滤算法进行候选酒店召回。工程上线参考第三部分描述。A/B实验周期为一个月,使用的评估指标包括酒店平均点击率及酒店订单量等。其中酒店平均点击率增长25.35%,酒店订单量总增长率为27.31%,效果较显著。更多模型结构将会持续上线实验。
六、推荐系统中的一些问题
在构建推荐系统的过程中,推荐模型的作用是重要的,但并不是推荐系统的全部。推荐系统需要解决的问题是综合性的,包含特征选取和处理、召回层设计、实时性要求、模型在线学习以及冷启动和推荐多样性问题等。这里主要探讨一下冷启动和推荐多样性问题。
冷启动问题主要包括用户冷启动(新用户注册,无历史行为)、物品冷启动(新物品加入,无用户交互历史)和系统冷启动问题(无任何相关历史数据)三类。主流的冷启动策略是基于规则的冷启动过程,在这过程中可以丰富用户和物品特征,从而通过推荐模型进行个性化推荐。
另外也可以通过主动学习、迁移学习和探索利用机制。最经典的启发式探索利用方法为几个Bandit算法,如Thompson Sampling算法和UCB(Upper Confidence Bound)算法,二者都是利用了分布的不确定性作为探索强弱的依据。UCB算法流程如下:
(1)假设有K个老虎机,对每个老虎机进行随机摇臂m次,获得老虎机受益的初始化经验期望
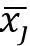 。
。
(2)用t表示至今摇臂的总次数,用nj表示第j个老虎机至今被摇臂的次数,计算每个老虎机的UCB值:
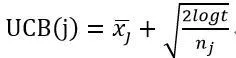
(3)选择UCB值最大的老虎机i摇臂,并观察其收益Xi,t。
(4)根据Xi,t更新老虎机i的收益期望值
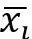 。
。
(5)重复第2步。
ThompsonSampling算法和UCB算法都是工程中常用的探索与利用方法,不但可以解决冷启动问题,还可以发掘用户新兴趣,增加推荐结果的多样性,减少大量同质化内容同时出现时用户的厌倦情绪。可以说探索与利用的思想是所有推荐系统不可或缺的补充。
参考文献
[1] 《深度学习推荐系统》,王喆
[2] H.B. McMahan, G. Holt, D. Sculley, M. Young, D. Ebner, J. Grady, L. Nie, T.Phillips, E. Davydov, D. Golovin, S. Chikkerur, D. Liu, M. Wattenberg, A. M.Hrafnkelsson, T. Boulos, and J. Kubica, “Ad click prediction: a view from thetrenches,” in ACM SIGKDD, 2013.
[3]X. He, J. Pan, O. Jin, T. Xu, B. Liu, T. Xu, Y. Shi, A. Atallah, R. Herbrich,S. Bowers, and J. Q. Candela, “Practical lessons from predicting clicks on adsat facebook,” in ADKDD, 2014, pp. 5:1–5:9.
[4] S.Rendle, “Factorization machines,” in ICDM.
[5]H. Cheng,
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%90%BA%E7%A8%8B%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%A8%A1%E5%9E%8B%E5%9C%A8%E6%90%BA%E7%A8%8B%E6%B5%B7%E5%A4%96%E9%85%92%E5%BA%97%E6%8E%A8%E8%8D%90%E5%9C%BA%E6%99%AF%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


