携程响应速度与智能化如何平衡携程酒店搜索系统实践
作者简介
mczhao,携程资深软件工程师,关注自然语言处理、搜索引擎和数据库内核开发。
概览
随着线上旅游业务的不断发展,携程酒店的数据量不断增加,用户对于搜索功能的要求也在不断提高。携程酒店搜索系统是一个基于Lucene开发的类似Solar的搜索引擎系统,本文将从四个部分描述对搜索引擎的优化。
第一部分,通过优化存储来降低响应时延,提升用户体验,降低硬件成本。第二三部分,通过召回和纠错的智能化来提升用户体验。第四部分,通过重新设计搜索DSL提高业务灵活性和研发效率。本文也描述了在优化过程中遇到的各种问题和解决方法。
一、存储优化
1.1 数据压缩
在Lucene 8中,long型的数据会被自动压缩存储。我们可以去除搜索shema中原有的byte、short、int类型,对整型字段统一使用long类型存储,而不用担心其占用多余的空间。这既降低了对内存和磁盘的需求,也降低了运维的人力成本。###
1.2 空间索引
在地理查询和存储这块,使用PointValues来替换原来的GeoHash索引。PointValues是从Lucene 6开始引入的一个新特性,使用kd树作为地理空间数据结构,来加速几何图形内点的过滤筛选。
踩过的坑
- 尽管Lucene官方极力宣传PointValues的性能优势,也许在二维地理搜索场景下是这样,但是在一维数据中其性能还是远逊于普通的倒排索引,甚至不如走逐个访问过滤。究其原因是PointValue中KD树的节点都是压缩存储,其CPU时间大部分消耗在对存储的解压和反序列化,造成浪费。
- 而对于高维空间的搜索,例如通过word2vec的词向量搜索某个词的相似词,无论是KD树还是VP树,其时间复杂度都会退化到不可忍受的地步。
1.3 KV存储
搜索流程不仅需要依靠倒排的索引,也需要正排的数据。在过滤和排序的搜索步骤中,需要根据主键来访问doc的一些维度信息,来判断该doc是否满足过滤条件,或者用来计算这个doc的排序分数。
在早期Solar版本中,使用了FieldCache——一种内存中SST来保存这些KV数据。从Lucene 4开始,DocValues作为KV数据的一种磁盘存储方案。在Lucene 7版本中,使用倒排索引中的DISI作为DocValues的索引,而FieldCache已经被移除。在Lucene 8版本中,DocVaues添加了jump table来增强其随机访问能力。
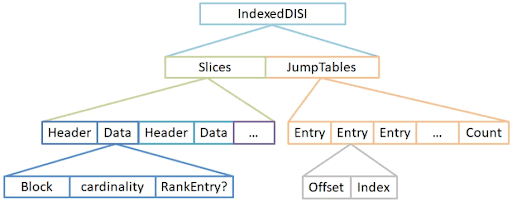
Lucene DocValues相对于FieldCache的优势是:
- 存储在磁盘,对内存需求减少。
- 存储经过压缩,消耗资源进一步减少。
Lucene内部的KV存储有一定局限性,例如:
- 使用磁盘的存储时,需要将byte数组反序列化,还是略慢于内存中直接存储的数据结构。
- 只能用docid作为key,如果使用业务id来访问,需要先查询倒排索引获取其docid,再访问正排数据获取值。
- DISI存储的docid范围只能在32位整型内,当遇到单点几十亿级别的数据,就无法存储了。
在某些场景下,给酒店打排序分时,需要获取酒店到POI之间的关联分数,此类分数不仅仅是通过直线距离计算得来,还需要考虑驾车步行距离的时间,以及距离筛选的酒店点击量等等因素,所以需要一个酒店到POI之间关联的KV存储。酒店和POI数据量各自是百万级别,而一个POI周边的酒店数平均是千级别,这样他们之间关联数据条数可达数十亿。
为此,我们自研了一种Java内嵌KV存储,和Lucene的索引中"mmap"模式一样,利用JDK自带的MappedDirectedBuffer,将数据存储在磁盘上,将磁盘和内存的交换交给操作系统托管,也不会给堆内存造成压力。不同于Lucene的DISI和LevelDB的SST,考虑到减少磁盘和内存的交换,已经提高TLB的命中率,其索引是固实化(compacted)的BTree,也就是一棵用数组表示的完全n叉树,其查询的时间复杂度为对数,索引合并时间复杂度为线性。相比使用排序数组的SST,空间占用一样,优势是查询时内存页跳转减少,劣势是compact的时候需要随机访问磁盘,而不是顺序访问。
踩过的坑
- 虽然Lucene DocValues是一种磁盘存储,但由于其实现和FieldCache有着诸多相似特性,部分元数据甚至是数据本身还是需要加载到内存的,这个加载的过程在DocValues的API中是懒加载的,并且会消耗一定的时间,需要注意其争用引起的线程阻塞。最好在初次加载索引和之后,或者写线程每次flush和compact之后,触发一次DocValues的数据加载,再让读线程可见。
- 虽然Lucene DocValues支持随机访问,但其API的实现还是相对滞后。在一次请求中,不允许访问的docid大于或等于上次访问的docid,强制整个打分过程是顺序访问的。这自然有他的道理:顺序访问的性能更好。但排序过程可能依据多个分数,多个分数的计算公式中可能引用同一维度的字段,这样会造成重复访问同一doc的同一字段的DocValues,使得API报错。解决的方法是将之前查询到的字段值缓存入当期的context中,下次访问时直接获取缓存。另外一种解决方案,直接修改Lucene源代码,消除这个不必要的限制,代码位置在MultiDocValues.NumericDocValues.advanceExact和MultiDocValues.SortedNumericDocValues.advanceExact。
- 虽然可以使用MappedDirectedBuffer将存储移出JVM堆,减轻了堆GC的压力,但是当堆外内存脏块超过一定阈值,操作系统还是会触发阻塞整个进程的flush工作。解决方法是将磁盘映射文件打开为read-only,用作append-only数据库的存储。没有对现有块的修改就不会存在脏块,而内部异步compact来实现增量更新。这样,只会存在缺页加载的IO操作,被淘汰的页可以立即丢弃,而不用刷回磁盘。
二、查询智能化
当今搜索系统中,单纯的文本召回已经不能满足用户的要求。搜索引擎需要根据用户的输入,识别用户输入的语义和意图,进而修改召回和排序方式。
2.1 语义查询生成流程
- 第一步是实体标注。将实体名称作为词库给用户输入分词以后,给分出的每一个词标注实体,识别其类型和对应ID。
- 第二步是提取核心语义。例如,用户 输入” 浙江杭州西湖希尔顿”,需要识别出浙江是杭州的上级、杭州是西湖的上级,从而忽略掉” 浙江” 和” 杭州”,其核心语义就是” 西湖” 和” 希尔顿”。
- 第三步是查询生成。根据上面的核心语义” 西湖” 和” 希尔顿”,通过规则系统,生成查询,优先查找西湖周边的希尔顿集团下的酒店,即使这些酒店文本中,看不出包含” 浙江”、” 杭州”、”西湖”、”希尔顿” 中的任意一个。
2.2 语义分析的常用算法
2.2.1 上下文无关句法分析(CFG)
- 优点:可以转化为自动机,计算速度快
- 缺点:语法规则固定,不适合分析比较灵活的自然语言
2.2.2 依存句法分析
依存图的主要思想是连接短语的中心词与其依存词。用有向边把中心词与依存词连接起来。依存分析中一个重要的概念是投射性,是由单词之间依存的线性词序决定的一种约束。投射性的的依存句法等价于CFG,非投射的依存句法的描述范围比 CFG更广。
- 优点:较为灵活,规则简单
- 缺点:有的情形,时间复杂度会退化到指数级别
2.2.3 酒店联想引擎中使用的语义分析
为了克服上述经典语法分析的一些弱点,酒店联想使用一种依据知识图谱分类分层的简化依存分析方式。根据酒店的业务场景,将标注后的实体词性放入不同的bucket中,进而进一步查询bucket内部实体和bucket之间实体的关联关系,进而去除修饰词,提取核心语义。同一bucket中的实体类型可以进一步分层,例如区域类型中省份、国家、城市、景区都可以分为单独的一层,再去获取彼此之间的关系。从而避免算法复杂度的爆炸。
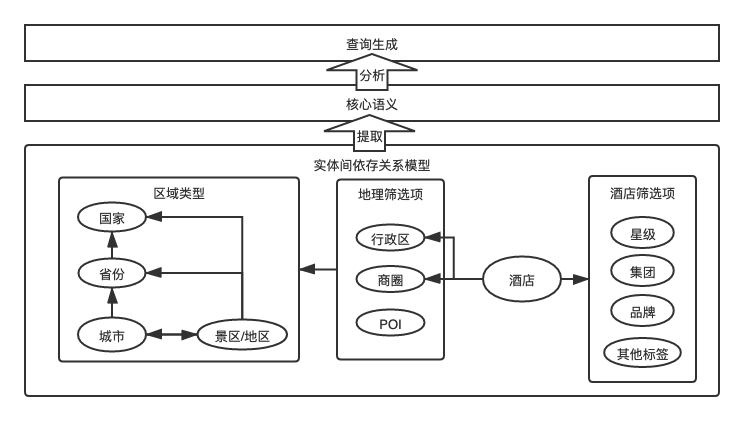
三、智能纠错
Lucene自带的英文单词相似度纠错,是通过ngram分词索引召回,从词库中粗筛出候选词,进一步使用Levenshtein编辑距离精筛出相似度高的词。
我们在Lucene纠错的基础上,做了更多的优化,我们的纠错会考虑上下文,纠错词库的数据来源也更加多元化,目标是使得我们的英文纠错可以媲美Bing或者Google。
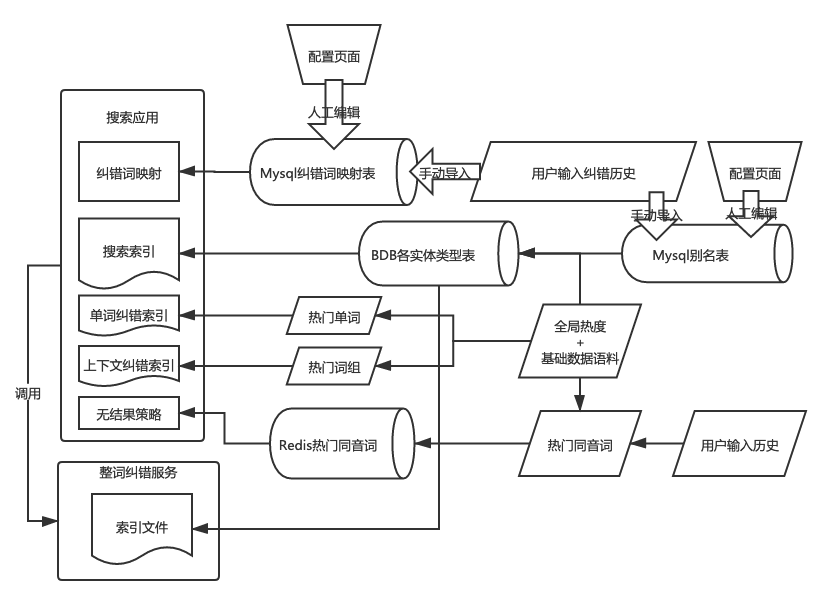
3.1 LSH 局部敏感哈希
随着业务增长,作为基础语料的实体数量也在增长,纠错词库的数据量随之增长,Lucene默认的ngram召回的候选词集合开始变得不那么准确,很多的用户目标词在粗筛过后就不在候选集内,导致无法正确纠出。我们需要考虑加入不同的维度作为Hash桶,来进一步缩小粗筛的范围,比如词长是一个比较好的维度;并且调整ngram中参数n的大小,以及分词以后的查询交并关系,使有限的粗筛召回结果更加精确。
3.2 上下文纠错
只考虑单词而不考虑上下文的纠错,就像只考虑单词热度而不考虑上下文的分词,有诸多局限性。例如真词纠错case,用户输入把le meridien(艾美酒店)错输入为let meridien,单看let这个单词是并没有错的,即使认为它是错的,那么let和le直接的相似度最高也只有66.7%,看起来也不高,不一定能达到精筛过滤的相似度阈值。
所以我们在纠错的时候也需要考虑上下文。通过现有实体语料以及其热度,统计出热门的二元词组及其热度。然后在纠错词,将二元词组作为单词来进行纠错。这样也可以对用户少输入或者多输入的空格进行纠错,并且可以解决空格问题和拼写错误同时存在的场景。例如:用户输入southcoase,通过一次纠错就可以纠出south coast这个词组。
通过二元词组库的纠错,只能往前/后多看一个词的上下文,有的情况下这么短的上下文并不能判断出最佳的纠错词。这时候可以将所有实体名称作为词库来纠错,由于其数据量庞大,粗筛的桶参数调整难度更大。另一方面,由于Lucene倒排索引下都是按docid排序的,docid是按数据插入顺序自增,所以我们可以先按热度排好序建入索引,再使用totalHitsThreshold=n限制召回的匹配条数,确保粗筛召回的是最热的n条记录。
3.3 优化编辑距离算法
经典的Levenshtein编辑距离算法,其状态转移发生在矩阵的2x2的范围内,无法识别出字符交换的操作。如果我们把其状态转移方程扩充到3x3的方格内,根据行和列上各自前两个字母来计算本单元格内的距离,即可识别出字符交换的操作。除此以外还能识别出字符双写漏写为单写,以及单写漏写为双写等场景,分别根据不同场景配置不同的距离权重,可以更加精细地计算两个词的相似度。
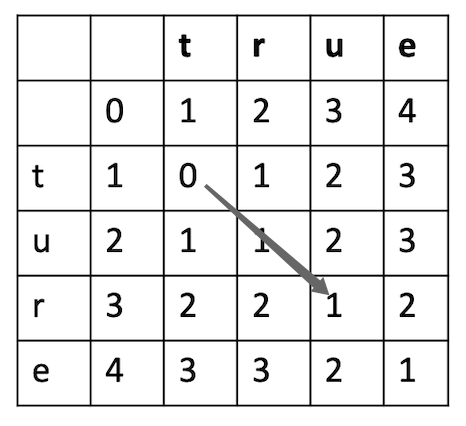
如果把根据前两个字母算的编辑距离称为2阶编辑距离,那么2阶可以扩展到n阶,n越大,能覆盖的情形越丰富,相似度越准确,纠错效果更好。但是算法的时间复杂度也随着n几何增加。实际使用时,按场景需求选择n。这种扩充到n阶的想法来自于Damerau-Levenshtein编辑距离,Damerau-Levenshtein编辑距离是一种2阶编辑距离。
编辑距离加权的思想也是在很多NLP论文中有提到,除了处理双写、调换等场景以外,也可以处理音近词特别是一些从别的语言翻译而来的音近词,特别是旅游业务背景下,很多地名都是按当地语言翻译过来的。举个中文的例子,从英文翻译而来的亚马逊和亚马孙,从"逊"到"孙"的编辑距离权重几乎可以配置为0,意味着亚马逊和亚马孙相似度100%,类似的case在作为表音语言的韩文和俄文的翻译文本中更多。
四、搜索DSL
DSL(Domain Specific Language),中文翻译为领域特定语言,相对于GPL(General Purpose Language)通用编程语言,DSL指的是专注于某个应用程序领域的计算机语言。
James Gosling曾经说过:每个配置文件最终都会变成一门编程语言。搜索系统的复杂化导致其配置的复杂化,根据不同的用户输入核心语义、不同的用户偏好、不同的搜索上下文,生成搜索查询和排序,这样的规则系统需要复杂的配置。Lucene原本也有自带的查询语言,类似SQL,可以定义召回、排序、分页等逻辑,但这样的查询语言已经不能满足我们日益复杂的需求,严重制约了开发效率,我们需要将搜索语言扩展甚至重写,就像从SQL扩展到PL/SQL那样。
4.1 设计考量
4.1.1 降低学习成本
设计查询语言的时候,需要尽量向SQL语言看齐。SQL是大家已经广泛熟知的查询语言,语法越和SQL一致,越是降低学习难度。
在ElasticSearch的结构化DSL中,使用的是must、should、must not查询方式,这样的查询方式虽然贴合lucene底层查询方式,但是从一个没有接触过类似搜索产品的开发看来需要学习成本。在Lucene自带的查询语言中,虽然可以使用AND、OR这些交并条件,但其实现是有bug的,其运算符优先级有问题,导致一些场景优先执行OR再执行AND,需要开发小心翼翼地给所有的子表达是添加合适的括号,更不幸的是,lucene的查询语言编译器通过JavaCC自动生成,不是人手写的代码,可读性很差,很难修改。
SQL和其他GPL相比,最显著的特征是其逻辑运算符的优先级,需要低于比较运算符。另外一个特征是两个整型相除,一般数据库实现默认返回的是浮点型数据,而不是整型,对于整数相除,另外使用内置函数实现。
除了向SQL看齐,其数字类型和字符串类型的表达方式向EMCAScript看齐,因为当前JSON作为最常用的序列化方式被大家广泛熟知,JS的字符串转义也比Java更加方便。当然,EMCAScript不支持64位整型,而我们需要支持,特别是当日期时间转化为long参与计算的时候。
4.1.2 面向高性能场景
一次搜索请求中需要对召回的数以万计的doc去做过滤和计算排序分,但又对响应时间比较敏感,特别是在联想推荐的场景中,用户每输入一个字,就要立时修改推荐的内容。所以在设计语言时,需要保留对CPU和内存友好的特性:
- 基于性能考虑保留primitive type,借鉴基于C的脚本语言lua,只保留两种数值类型——整型的long和浮点型的double,并且强转系统。基础类型是现阶段ElasticSearch script的诸多实现中仍没有实现的功能。
- 查询过滤,比较字段和值时,使用lucene列式存储,即DocValues,而不是去获取行数据。
- 去除CBO(基于成本的优化器)。如果开发对执行计划了然于胸,就会发现在一些复杂场景下传统数据库中的CBO经常帮倒忙,导致我们不得不使用use index这种语法。去除CBO的同时,用不同的语法让开发可以自定义执行计划是走索引还是走过滤,降低执行计划的不确定性,也可以降低查询编译期的耗时。而RBO(基于规则的优化器)中的一些规则可以保留,比如任何条件和false取交集,默认就返回false,而不是真的去执行�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%90%BA%E7%A8%8B%E5%93%8D%E5%BA%94%E9%80%9F%E5%BA%A6%E4%B8%8E%E6%99%BA%E8%83%BD%E5%8C%96%E5%A6%82%E4%BD%95%E5%B9%B3%E8%A1%A1%E6%90%BA%E7%A8%8B%E9%85%92%E5%BA%97%E6%90%9C%E7%B4%A2%E7%B3%BB%E7%BB%9F%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


