携程上百个业务场景语义匹配技术在携程智能客服中的应用
作者简介
Kun Wang,携程资深算法工程师,专注于智能客服机器人相关NLP算法研究。
一、背景介绍
随着AI技术在各个领域的广泛应用,人机交互技术愈发成熟。包括电商、银行、电信等在内的很多领域开始建设智能客服的交互能力,为客人提供智能化自助服务,同时为客服人员的工作提供智能辅助。携程集团依靠强大的客服团队为国内外旅行者的出行提供了优质的服务保障,持续提升智能客服的交互能力,提高客服人员的生产效率显得尤为重要。
在携程智能客服的AI能力建设中,我们以百万级的对话数据为驱动力,利用深度学习算法解决用户问题,满足客户个性化的需求,致力于提升“猜你所想,答你所问”的算法能力。
携程智能客服已经在携程上百个业务场景提供了面向客人服务的客户端,以及面向客服员工问答的辅助客服端。用户进入智能客服对话页面,机器人小游会和客人进行对话,根据用户输入的内容,基于AI算法能力和底层知识库,回答用户的问题。本文主要介绍语义匹配技术在智能客服的语义理解和问答方面的实际应用。
二、问题分析
客服机器人使用的问答数据是业务运营的领域知识库,其中常见的标准问题及答案是知识库的数据基础。客服机器人通过对比分析用户话术和标准问题的相关性,通过排序后选择最可能的答案。这本质上是NLP(自然语言处理)领域的语义匹配问题,QA匹配模型作为一种基础模型,对匹配准确性要求较高。
现阶段的语义匹配技术经历了从词汇匹配到词义匹配,再到句义匹配的发展阶段。传统的BM25算法统计词粒度特征并计算相关性排序,需要维护大量的词库才能提供可靠的统计计算结果。词袋模型(Bag-of-Word)算法通过将句子映射到高维空间表示整体的语义,但缺点是词表维度高,存在很大的稀疏性。PLSA和LDA为代表的概率模型将文本映射到低维的连续空间上,在潜在语义空间上计算语义相似性的同时,提供了主题建模能力,虽然解决了高维表示的稀疏性问题,但匹配效果未必能超过经典的词汇匹配算法。
随着神经网络的发展,端到端的深度学习算法逐渐被应用到各个领域。基于神经网络训练的词向量模型,如Word2vec、Glove等被用来解决语义匹配问题,低维稠密的词向量可以更好的表示词汇的词义信息和一定的上下文相关性信息。
为了进一步解决短语、句子级别的语义匹配问题,以DSSM为典型代表的神经网络匹配模型被提出。按照句子建模的方式不同,一种是句子之间独立建模,无交互的匹配模型,如基于全连接层的DSSM、基于LSTM建模的Siamese网络等。这种网络架构的优势是,可以实现句子级别的文本语义表示,后置的文本相似度匹配运算比较灵活,大多数是余弦相似度运算,但缺点是文本相似度计算中缺乏交互性,没有充分建模和学习文本对之间的关系。
另外一种是有交互的匹配模型,如基于矩阵匹配的层次化匹配模型MatchPyramid[1]、基于交互注意力机制的ESIM模型[2]等,在这些模型的架构中,可以从文本对之间的词汇级别、句子级别等不同层面建模和学习相关性信息,但这种模型主要建模句对关系,并行处理能力差。虽然神经网络架构的变种很多,但大多数以全连接、CNN、LSTM等网络为编码器。
自2018年开始,注意力机制被广泛应用到自然语言处理的多项任务中,注意力机制可以充分的学习文本的上下文语义信息,并对这些信息的相关程度进行加权,从而区分文本中每个字词在语义理解过程中的重要程度。如图1所示,Self Attention机制通过对自身实现注意力加权学习句子中各个词汇的语义相关性。以Self Attention为基础的Transformer架构[3]实现了以Attention运算代替传统神经网络的变革。而随着Transformer架构的提出,以其为单元模块的预训练模型在众多NLP任务上均取得了SOAT的效果。预训练语言模型通过在大规模的无标注文本数据上进行自监督训练,学习到丰富的通用知识,随后在特定的下游任务上利用少量标注数据进行微调训练,即可获得的不错的效果,如BERT、GPT、XLNET等。
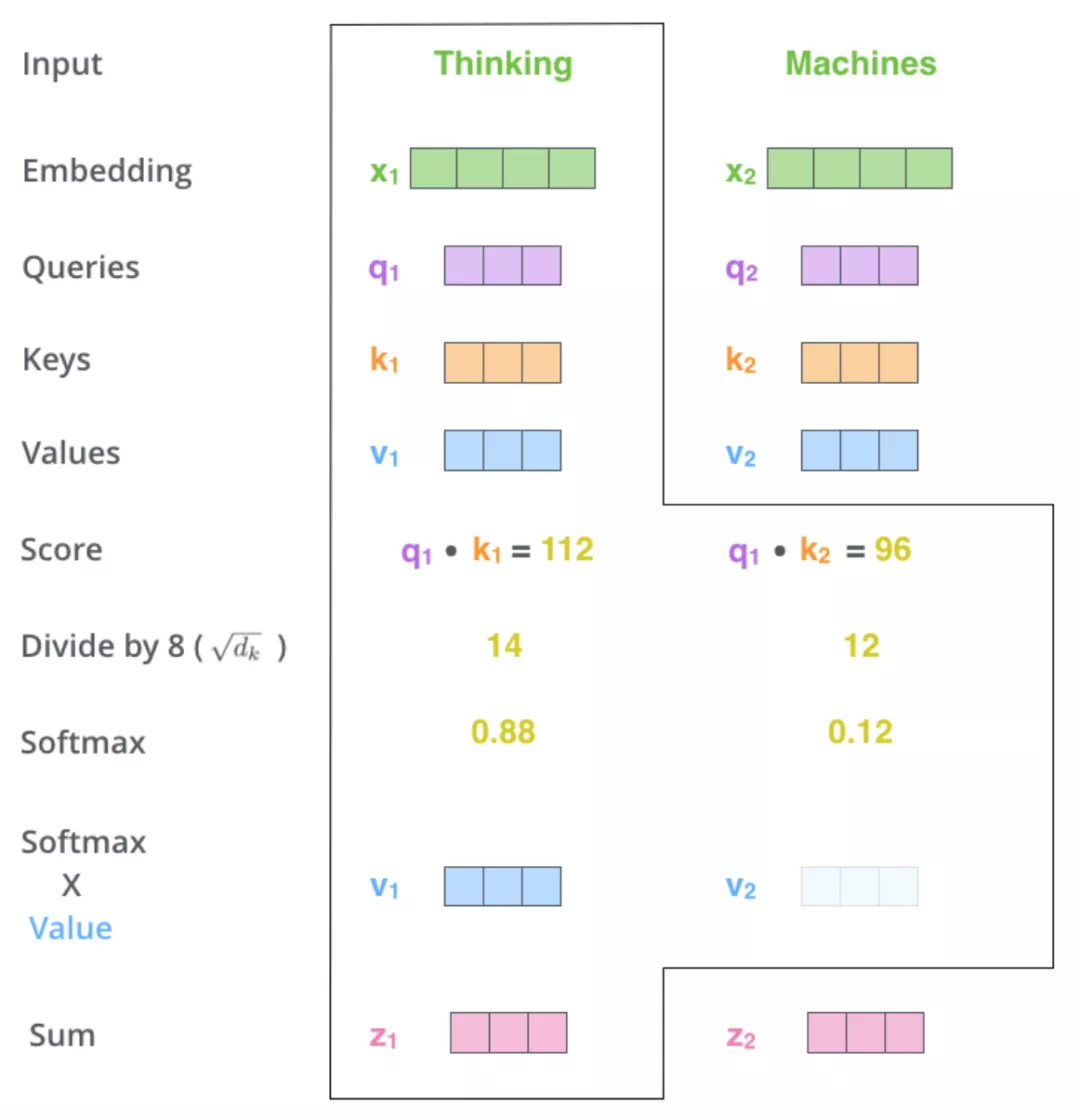
图1 Self Attention注意力加权计算过程
2018年10月份开源的BERT模型[4]是最经典的预训练语言模型。基本结构如图2所示,BERT模型以Transformer为基础,由多层的Transformer-Encoder组成了双向注意力编码的语言模型。BERT模型在GLUE的各项任务上长期占据榜首位置,其中包括推断句对关系的语义匹配任务。此外,多语言预训练模型的研究改变了依赖机器翻译的自然语言理解,对于跨语种的知识迁移具有很大的帮助。
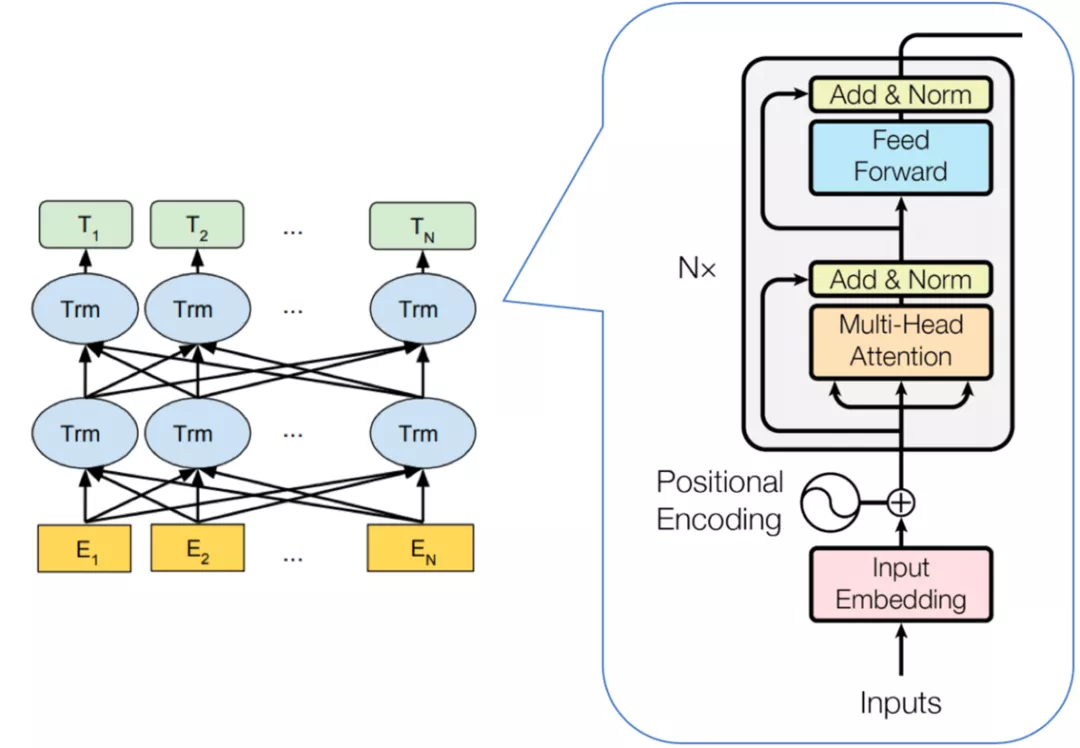
图2 BERT及Transformer网络结构图
三、语义匹配技术应用
语义匹配问题有两种框架:分类和排序。如图3所示,分类的方法是对用户输入做softmax多分类,将其归属到特定的类别。而排序问题是将用户输入与候选SQ(业务维护的FAQ知识库)进行对比学习,衡量之间的相关度。按照训练方式的不同,分为point-wise、pair-wise和list-wise三种类型。其中point-wise和pair-wise应用最广泛。
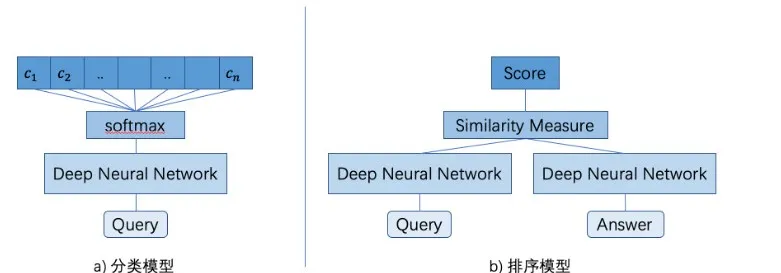
图3 语义匹配模型框架图
四、多阶段语义匹配
在智能客服机器人的服务过程中,我们以单轮交互的QA模型为基础,用户的输入(UQ)会经过匹配召回和点击精排的多个阶段,反馈给用户最可能想问的问题及答案,整体的计算流程如图4所示,其中匹配召回和点击精排阶段是本文介绍的重点。
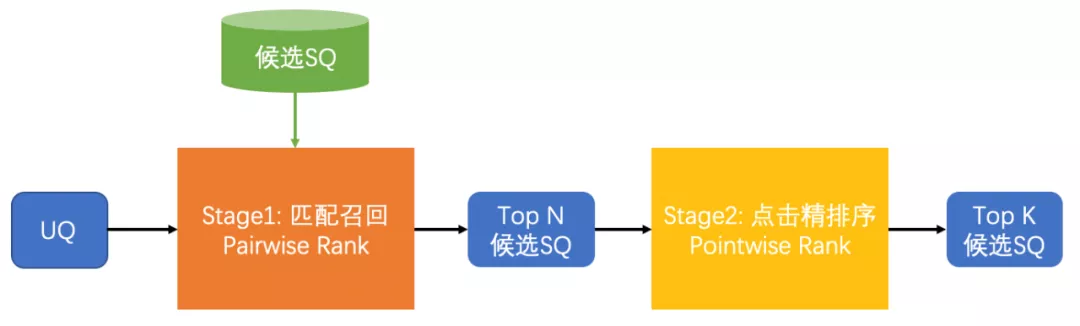
图4 多阶段语义匹配计算流程图
4.1 匹配召回
在匹配召回阶段,我们将语义匹配问题转化为对标准SQ的排序问题,通过pairwise的训练方式,学习两两之间的排序关系,训练的目标是最大化正例样本对 (UQ ,SQ+) 和负例样本对 (UQ ,SQ-) 之间的距离,如公式:
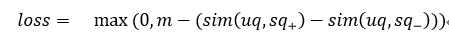
其中,sim(∙) 是一种距离度量方法,一般采用的是余弦相似度。
这种基于排序的模型结构如图所示,其中Encoder表示提取句义特征的编码器,可以从原始的文本输入映射到低维的稠密向量表示。一般的Encoder采用的是CNN或者RNN的网络模型。
随着BERT模型兴起后,BERT强大的学习能力和迁移学习能力,使得我们尝试将其嵌入到算法框架中。考虑到BERT模型的复杂度和线上推断速度的要求,我们没有采用BERT原生的point-wise训练方式,改为采用以BERT模型作为Encoder编码器,相比于LSTM等基础网络能够显著提升召回准确率。
4.2 点击精排
匹配召回能够对知识库中的全量候选标准SQ给出一个排序结果,如果直接将这个排序结果反馈给用户,对于知识库中存在语义很接近但存在细微差别的SQ难以给出一个最优的排序结果。如何利用好线上日志的用户反馈,对于难区分的样本给出正确的判断,是非常重要的。
因此,我们引入了点击重排序的精排范式,采用线上用户真实的点击反馈数据,训练一个强的排序模型,对语义相近的样本进行对比区分。在这一阶段,我们更加关注用户问题和候选标准问题之间的细粒度相关性,因此采用ESIM模型这种基于注意力机制进行细粒度语义交互的语义匹配模型。如图5所示,ESIM有两个LSTM编码层和一个注意力层组成。注意力层对两个输入文本的各个token进行相关性计算,并经过softmax后得到相似度权重。这种交互可以从更细的粒度学习到样本对之间的共性和差异。
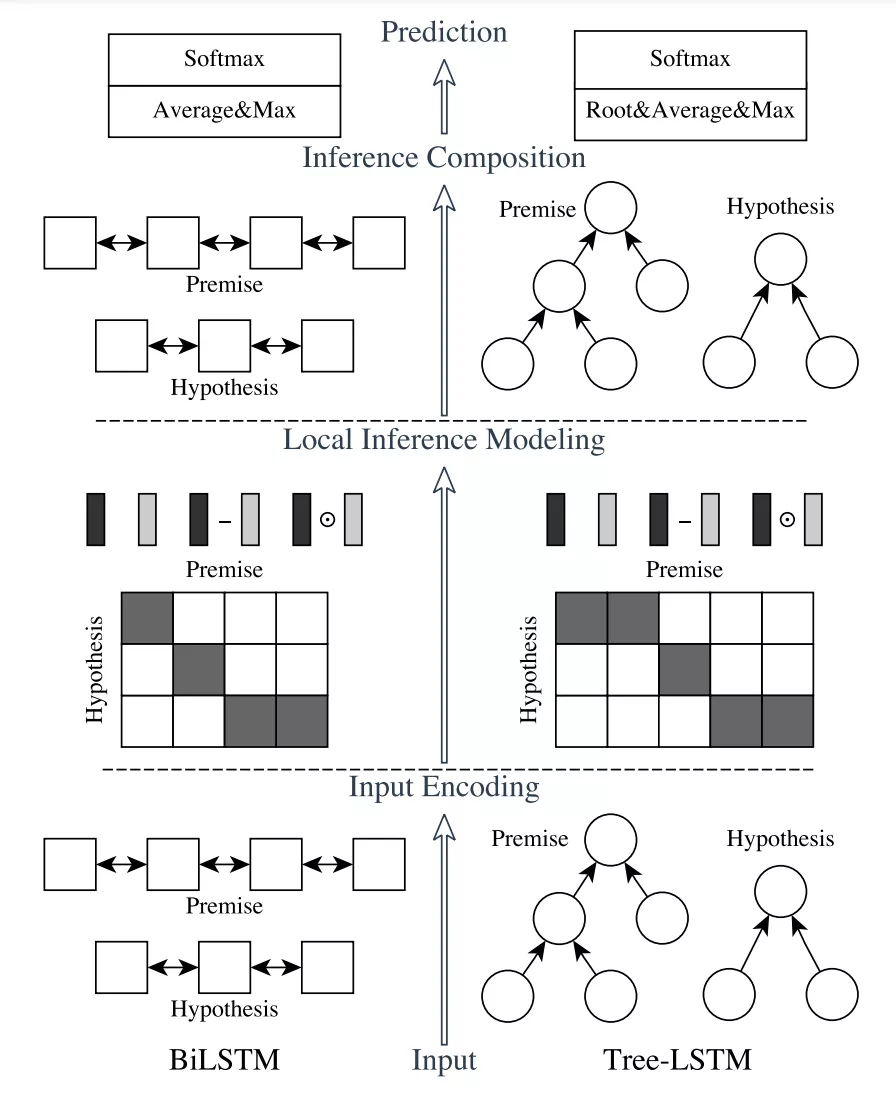
图5 ESIM模型架构图
从全量候选知识库中召回Top-K个标准SQ之后,通过构造K个句对样本,由点击重排序模型统一给出精排分数,之后作为线上预测的最终依据。
五、多语言迁移学习
全球存在数千种语言,分属于不同的语言体系。在携程的IBU国际化业务中,目前支持19种主要语种。一个语种上训练好的语言模型在另一个语种上几乎完全无效,导致很多标注语料严重不足难以取得良好的效果,因此需要跨语种的NLP研究。在携程国际化业务的开展中,我们非常注重多语言的语义理解能力,实现了预训练和迁移学习在小语种业务上的技术落地。
多语言预训练模型预训练阶段采用多个语种的数据一起训练,各个语言共用一套公共的模型参数。如谷歌开源的多语言BERT、Facebook开源的XLM、T5等模型。以多语言BERT模型为例,其训练数据是维基百科的100种语言数据,采用多语言BERT的wordpiece分词方法,共形成了110k的多语言词表。在多语种的XNLI数据集上取得良好的效果。
在携程多语言的业务中,不同语种之间的数据存在较大的不均衡性,存在一些小语种只有少量的标注样本,甚至无标注样本的冷启动场景。在这种情况下,利用好多语言BERT模型的迁移能力可以节省很大的人工标注成本。利用多语言BERT模型在标注语料充足的语言线上训练语义匹配模型,如中文、英语,然后在目标语线的任务数据上进行微调,如日语、泰语等。
以日语语言线冷启动场景为例,利用英语语言线的标注数据训练的Siamese BERT模型,在未使用日语数据微调的情况下,仍能取得60%以上的匹配准确率。再使用少量的日语线标注样本微调后,模型效果又可以提升20%。
六、KBQA
对于特定场景下用户的精细化信息咨询,我们结合NLU模块明确用户咨询意图,提取关键信息槽位(Slot),通过KBQA的推理能力提供精确答案。
智能客服通常可以分为闲聊Bot、单轮问答的QA Bot和多轮问答的Task Bot。单轮问答利用QA模型给出匹配结果,多轮问答由NLU模块处理用户问题,确定意图(intent)和抽取槽位(slot)DM模块控制会话流程并给出最终答案。
但是通常情况下,单轮问答仅依靠语义匹配技术难以覆盖全部的用户问题。举例说明,用户咨询“酒店到XX景点有多远?”,我们难以枚举全部的景点并配置问答数据,这种需要部分推理和查询的精确问题可以使用KBQA来解决。其中NLU模块需要确定用户的问题是否是KBQA可以解决的类型,其次需要抽取该问题类型的相关槽位,从而才能结合槽位属性去查询知识库和推理计算。
6.1 意图识别
意图实际上可以看作是用户问题的抽象,其本质上是和之前提到的标准SQ是等价的。在调研分析中发现,售前用户有很多会进入客服页面咨询酒店的相关信息,如酒店的位置、周边商场、景点美食、交通出行等。如用户输入“酒店到外滩景点有多远?”,这个问题属于用户咨询“酒店到某POI的距离”这个标准意图类别,利用现有业务线数据训练的召回模型仅能定位到知识库中配置的“酒店附近交通”这个标准SQ,难以继续精确到更细粒度的意图子类。
考虑到以继续新增标准SQ的形式并不能枚举用户所有的信息咨询问题,但可以在现有“酒店附近交通”下面再拆分成更细粒度的意图子类。如果采用分类模型去预测用户的意图,很多时候会因为业务的变化导致数据和模型的频繁变更。因此,我们继续采用语义匹配的排序方式实现意图识别,在保证业务意图匹配准确率的同时,支持业务意图的动态变更。此外,扩展新意图的同时,并不能提供大量标注样本用于训练,所以适应于小样本学习的匹配模型更适合我们的KBQA场景。
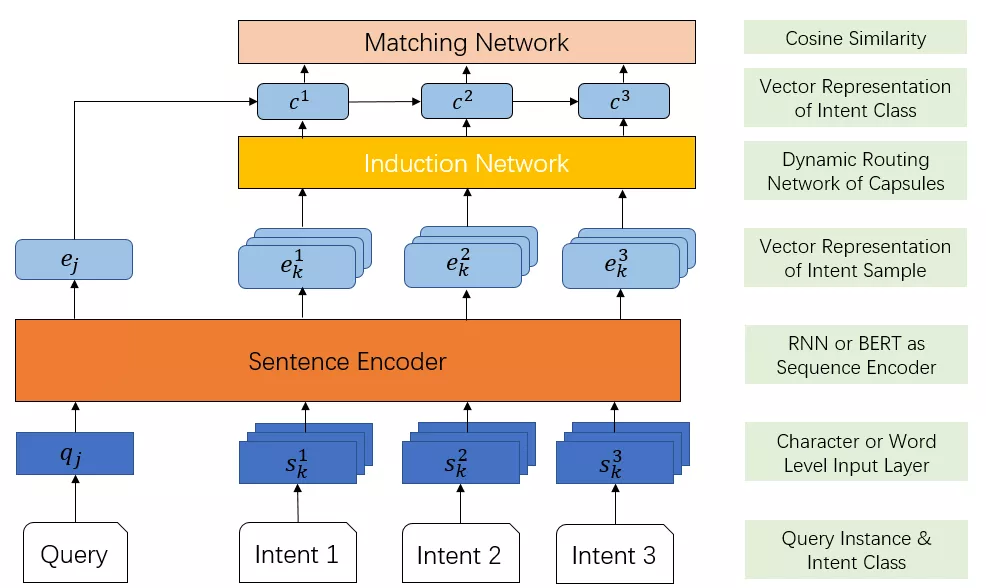
图6 意图识别匹配模型框架
如图6所示,意图识别模型采用的是学术界比较新颖的Induction Network模型[5],这是在经典Match Network基础上演变而来的匹配架构。在训练过程中,每个意图类别i,仅需要N条(20条-200条)的标注样本,选取K条样本经过Encoder模块编码得到句向量表示,之后由动态路由模块归纳得到该类别的向量表示。用户query经过句向量编码后得到,会和每个计算相似度,最后计算分类的交叉熵损失函数。在线上推理过程中,各个意图类别的向量可以预先计算和动态更新,仅需对用户query做实时编码和意图类别的相似度计算。
6.2 槽位提取
意图识别能够让机器人理解用户问题的主干,而细节理解则由槽位抽取模块完成。用户问题中的“外滩”是一个经典POI,只有确定了该POI的坐标,我们才能计算推理酒店到该POI的距离,并给用户推荐出行方式。发现用户query中的实体词汇并能够链接到知识库信息,是槽位抽取模块的主要工作。
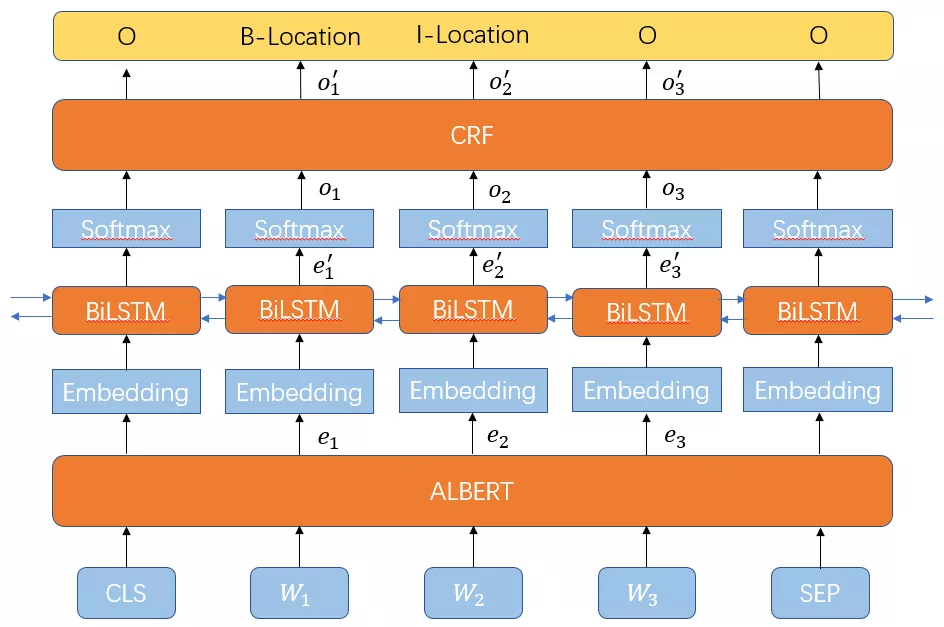
图7 NER模型框架
对于用户问题中描述准确的词汇以及常见的别名表述,都可以通过词典和规则的方法识别出正确的结果。但对于复杂实体的识别则需要NER模型来完成。我们将ALBERT+BiLSTM+CRF的模型应用到词槽抽取任务中,NER模型的整体框架如图7所示,用户query会先经过ALBERT和BiLSTM的特征编码层,获得每个token的向量表示,softmax层将映射到标注类别标签上,得到初步标注结果,CRF层以作为输入,通过维特比算法为每个token都重新被打上一个标注类别(B、I、O)。CRF层需要根据场景定制标注类别,但Albert的编码能力具有通用性。既保留了语言模型在少样本或零样本情况下强大的迁移学习能力,又能够在线上有一个更快的推理速度。
七、总结
文章首先介绍了携程智能客服机器人的背景,并从问题分析、语义匹配技术应用等方面详细介绍了NLP领域的语义匹配技术在携程智能客服场景中的实践。涵盖了语义匹配技术从统计机器学习到深度学习的演变过程,阐述了召回+精排序的语义匹配计算范式,介绍了我们在多语种迁移学习场景的实践,以及利用KBQA解决售前问题的探索。
未来的智能客服机器人还将继续推进更多场景的技术落地,并能够实现多语言方向的进一步拓展,实现文本、语音、图像等多模态的发展。以数据驱动、技术赋能、业务落地的生产方式,让智能客服机器人更加智能化、人性化,为客服人员提供更多技术支持,为用户提供更好的服务体验。
参考文献
【1】Liang P , Lan Y , Guo J , et al. Text Matching as Image Recognition. 2016.
【2】Chen Q , Zhu X , Ling Z , et al. Enhanced LSTM for Natural Language Inference[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016.
【3】Vaswani A , Shazeer N , Parmar N , et al. Attention Is All You Need[J]. arXiv, 2017.
【4】Devlin J , Chang M W , Lee K , et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.
【5】Geng R , Li B , Li Y
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%90%BA%E7%A8%8B%E4%B8%8A%E7%99%BE%E4%B8%AA%E4%B8%9A%E5%8A%A1%E5%9C%BA%E6%99%AF%E8%AF%AD%E4%B9%89%E5%8C%B9%E9%85%8D%E6%8A%80%E6%9C%AF%E5%9C%A8%E6%90%BA%E7%A8%8B%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


