揭秘升级版语义搜索技术
欢迎关注本人公众号" 蘑菇先生学习记 “,会定期分享算法最新进展以及工作实践感悟。
上一篇分享了 KDD'21 | 淘宝搜索中语义向量检索技术,今天分享Facebook在KDD'21上发表的又一篇EBR文章: Que2Search: Fast and Accurate Query and Document Understanding for Search at Facebook 。两篇文章的风格差异巨大。Facebook延续了其一贯的风格,文章字字珠玑,是真实问题驱动的研究,写作思路清晰,娓娓道来,值得精读。
提前预览下这篇文章的亮点:
- 提出了一种 query和商品的语义理解系统 ,即:Que2Search。该系统离线有5%的离线相关性指标提升;线上有4%的用户参与度指标提升。
- 引入 BERT模型XLM 做双塔语义表征,分享了引入BERT模型的 增益所在 以及如何做到 时延99线1.5ms 的超强性能。
- 在双塔结构上引入了 多任务学习 ,除了query-doc的匹配,在doc侧还引入了 辅助的分类问题 。
- 引入了多 模态图像表征 ,基于预训练模型来提取图像的特征,并融入到doc侧的向量表征过程中。
- 跨模态特征融合 ,提出了基于注意力机制的多模态融合方法以及基于梯度的多模态融合方法,不仅可以应用于多模态,也适用于多通道、分组特征的融合。
- 提出了 两阶段训练 范式,第一阶段先进行in-batch内的采样;第二阶段再进行课程学习。
- 分享了很多 调参炼丹 的经验,下文会用【炼丹经验】来标识。
整体的解读目录如下:

更多关于语义向量检索系列的文章也请参见:
1.Motivation
研究对象 :Que2Search,Facebook MarketPlace社交媒体 电商搜索 中的 查询理解和商品理解系统 。
研究目标 :在给定用户搜索query下,提升搜索结果的相关性和召回率,以满足用户需求。
研究动机 :传统的搜索引擎主要基于Term匹配。最近,Facebook在KDD 20上提出了新的向量检索系统[1],基于双塔结构,通过n-gram进行query侧的文本表征,每个塔的结构类似Wide & Deep。该模型的 缺点 有:
- 缺乏对自然语言进行有效的上下文表征 。由于高昂的计算代价,没有用到BERT类语言模型做语义表征,只是简单的用n-gram稀疏特征做嵌入。对于query或者商品描述等文本,缺乏足够的理解能力。
- 缺乏对图片的理解 。电商平台的图片和文字都非常重要。
研究挑战 :
- 商品的描述信息充满噪声 。 语法结构错误、拼写错误等情况很常见,质量参差不齐。
- 国际化需求 。需要支持跨语搜索。
- 多模态处理 。需要考虑多模态信息,商品的文本、图片等。
- 严格的延迟限制 。对性能要求极高,尤其是使用基于Transformer的语言模型,在时延上挑战更大。
核心贡献 :
-
1.提出了Que2Search模型 。该模型采用了 多任务学习 和** 多模态技术\\ 来训练query和product的向量表征。即:在跨语言BERT模型XLM/XLM-R基础上,融合了多模态技术。
-
2.在Facebook MarketPlace上的真实应用 。其中, 召回 :基于向量的检索,Query2Product。 排序 :作为排序的一个重要特征。取得的成果:
- 性能指标 :能够实现在CPU上实时推理的99线小于1.5ms。
- 质量指标 :在离线相关性指标上绝对提升5%;线上参与度指标提升4%。
-
3.介绍了模型/工程优化方面 的细节和宝贵经验,包括:
- 哪些 模型优化策略 有效(基于无数的离线实验和线上A/B测试)。
- 大规模BERT模型的 在线部署经验 ,如何取得 99线(99%的请求)小于1.5ms 的超强性能。
- 模型的 调参技巧 ,如何取得大幅度的指标提升。
2.Solution
整体预览下 模型架构 。典型的双塔结构。query侧的输入特征有多个通道,包括query本身的3-gram,国家和原始文本。doc侧的输入特征包括了title,description,title的3-gram,description的3-gram和图像的向量。二者通过attention做融合后分别得到query向量和doc向量,再进行点乘得到预测值。
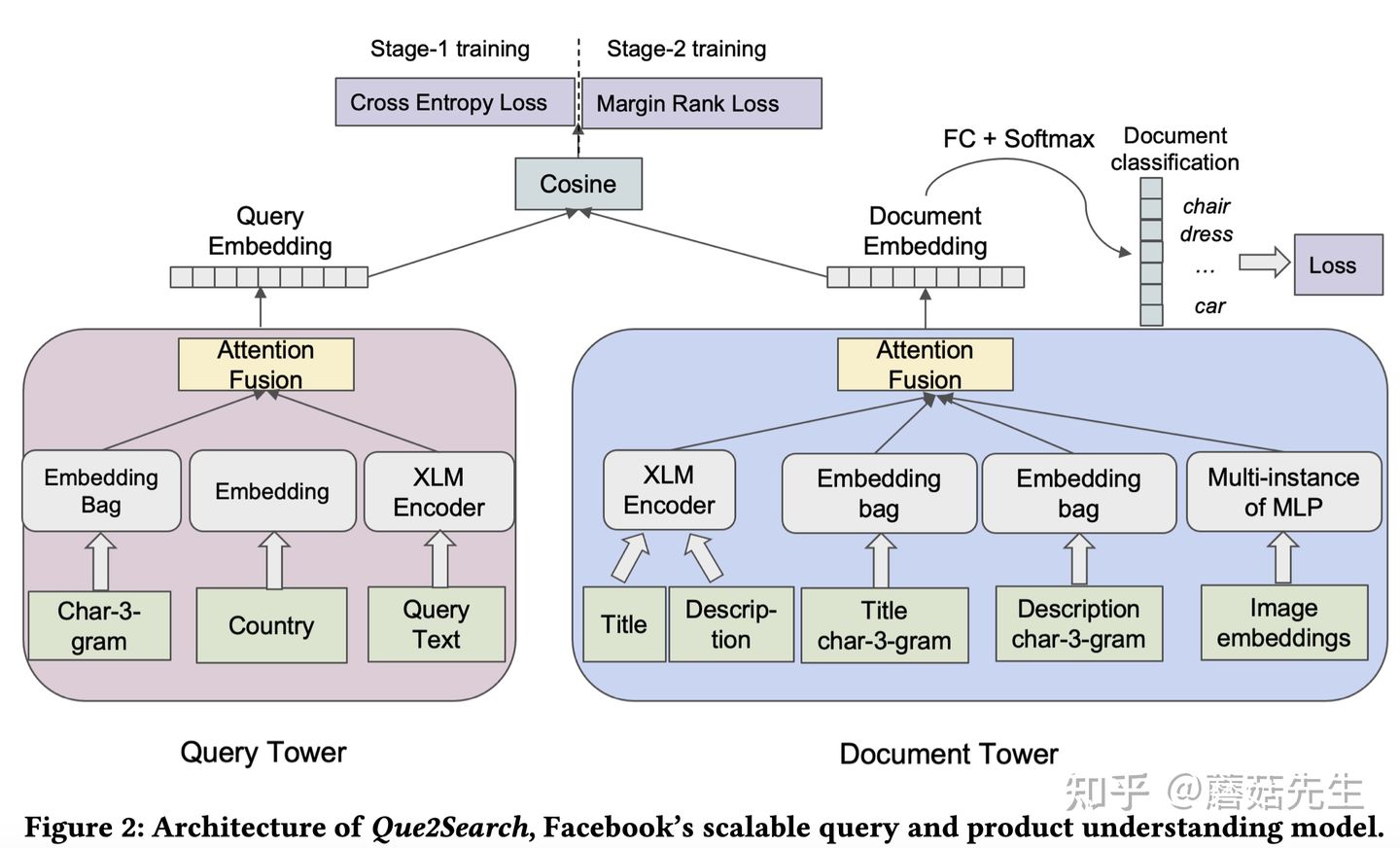
2.1 Query Tower
输入特征和表征方式如下 ,共3路的特征,
- query的 3-gram稀疏特征 ,即:在query上做步长为3的滑窗,然后加hash方法转为ID,如MurmurHash,这样1个query可以得到多个稀疏ID特征,分别进行嵌入,然后sum-pooling转成1个向量。
- 搜索用户所在的 国家 ,做嵌入后转成1个向量。
- 原始query文本特征 ,输入到2层的XLM编码器[2]来进行特征提取,[CLS]的向量接一个全连接成得到向量。
作者尝试过多种的 late-fusion 方法来融合上述不同路的向量表征,比如拼接+MLP,还比如简单的注意力机制。最后发现,简单的 注意力机制 融合反而效果是最好的。具体的,



其中,
 代表第
代表第
 路得到的 特征向量。
路得到的 特征向量。
 是拼接操作。即:各路向量全部拼接再一起,过一个全连接层+softmax,输出每一路向量的权重,即
是拼接操作。即:各路向量全部拼接再一起,过一个全连接层+softmax,输出每一路向量的权重,即
 ,最后加权求和输出融合后的 表征向量。
,最后加权求和输出融合后的 表征向量。
2.2 Document Tower
输入特征和表征方式如下 ,共4路的特征,
- 商品的标题和描述信息 原始文本 ,使用一个共享的 6层 XLM-R [3]编码器对标题和描述信息分别进行编码。
- 标题的 3-gram稀疏特征 ,方法同query tower。
- 描述信息的 3-gram稀疏特征 。
- 商品关联的图片 。1个商品会关联多个图片,使用[4]中的模型获取图片的预训练向量表征,再接一个共享的MLP层,最后用 Deep Sets 方法 [5]来融合多个图片向量得到融合后的 图片表征 。
最后,同样是基于 attention 加权融合上述三种向量,得到最终的document侧向量。
2.3 多任务学习
在 双塔 基础上,加了个 tower侧的分类任务 ,如图中右上角所示。这个分类的输入输出设计的挺巧妙,用document作为输入去预测query类别。
- 输入 :doc在document tower输出的向量表征。
- 输出 :从标注数据和电商搜索日志中收集了一批和 目标文档 相关的 用户文本query , 用user query来表示该document的类别 。总共使用了头部的4.5W个query,即:4.5W多分类任务。比如:某个裙子商品的query包括 短裙、红裙等,那么就用这些query来作为该商品的label,即:短裙、红裙。query描述了用户的搜索意图,相当于product2query,来推测该商品的用户搜索意图可能是什么。具体的做法,文档的多标签多分类任务,使用多标签交叉熵损失,1个商品可能关联多个query类别,比如有
 个类别,那么每个类别的label均摊,设置为
个类别,那么每个类别的label均摊,设置为
 。
。
这个多任务学习在输入输出上设计的挺有意思。用 query来作为document的label 。背后的动机是,强制让模型基于这些 document 来推测query,即基于商品来推测用户的搜索意图,这样能够让模型更好地发现商品和query的语义关系。
2.4 两阶段训练
训练数据 :原始训练样本只包括正样本,即:(query,document) pairs。负样本通过同一个batch内的其它query-docment pairs来采样得到。相关性正样本的收集要保证 尽可能相关,防止在正样本中引入 噪声 。因为人工标注的样本量太少,需要借助海量的用户弱监督行为数据。Facebook通过连续发生的事件来做 正样本的过滤筛选 ,即:
- 用户发起了某次搜索词,query
- 用户点击了某个商品,product
- 用户发消息给该商品的卖家进行商品的咨询
- 卖家回复了用户
只有在短时间(24h)内同时满足上述4个条件的query-product对,才属于 相关正样本 。作者称如上4个连续步骤的交互行为为 conversation 。
2.4.1 第一阶段:Batch内负样本 in-batch Negatives
记Batch大小为
 。在每个batch中,每个样本形如query-document pair,我们通过前面的双塔结构可以获得query侧
。在每个batch中,每个样本形如query-document pair,我们通过前面的双塔结构可以获得query侧
 维的embedding
维的embedding
 ,doc侧
,doc侧
 维的embedding
维的embedding
 。接着,计算cosine相似矩阵,即:
。接着,计算cosine相似矩阵,即:
 ,
,
 ,该 矩阵 表示了在同一个Batch内,所有可能的query-document pairs的相似性。其中,矩阵的行表示query,列表示document。可以把训练过程看成一个多分类的问题,类别为
,该 矩阵 表示了在同一个Batch内,所有可能的query-document pairs的相似性。其中,矩阵的行表示query,列表示document。可以把训练过程看成一个多分类的问题,类别为
 ,document
,document
 看做是query
看做是query
 的ground truth类别,而其它文档
的ground truth类别,而其它文档
 看做是该query
看做是该query
 的负样本。然后使用多分类交叉熵损失,对某个正样本
的负样本。然后使用多分类交叉熵损失,对某个正样本
 ,其损失为:
,其损失为:

其中,
 是个常数。实际上就是类似温度参数
是个常数。实际上就是类似温度参数
 。在文中,
。在文中,
 的取值为15到20。目的是拉大正样本和负样本之间的差距,能够收敛的更快。该损失函数称为 scaled multi-class cross-entropy loss 。此处没有做采样,拿所有B-1个document作为负样本。
的取值为15到20。目的是拉大正样本和负样本之间的差距,能够收敛的更快。该损失函数称为 scaled multi-class cross-entropy loss 。此处没有做采样,拿所有B-1个document作为负样本。
【 炼丹经验 】作者还提到,也尝试过Symmetrical Scaled Cross Entropy Loss,即:对称的scaled 交叉损失函数。上述是对目标query
 去取其它的
去取其它的
 作为负样本;同理,也可以针对目标document
作为负样本;同理,也可以针对目标document
 去取其它的
去取其它的
 作为负样本, 因此称为对称 。即:
作为负样本, 因此称为对称 。即:

Symmetrical Scaled Cross Entropy Loss同时优化了query-to-document检索和document-to-query检索。作者表示,该损失函数并没有对query to document的双塔模型有所增益。但是在另外的一个document-to-document检索场景中,应用在document-to-document双塔结构中,能够取得2%的ROC AUC指标提升。因此也是视情况而定。
2.4.2 课程训练 Curriculum Training
课程训练也即课程学习 (Curriculum Learning),这个概念是由Bengio教授在2009的ICML上提出的,主要思想是模仿人类学习的特点,由简单到困难来学习课程(在 机器学习 里就是容易学习的样本和不容易学习的样本),这样容易使模型找到更好的局部最优,同时加快训练的速度。
除了上述in-batch负样本思路之外,作者还提出了一种课程训练的范式,该训练范式在ROC AUC上能够提升1%。整个训练分成2个阶段:
-
第一个阶段,使用in-batch负样本训练, 直到收敛 (通过在验证集上做early stopping实现)
-
第二个阶段,喂更困难的负样本给模型来学习。 那么如何找到更困难的负样本呢 ?传统的方法,一般会设置一个独立的pipeline来挖掘困难负样本,再单独喂给模型学习。作者提出的方法仍然是使用batch内的负样本。
- 首先,同样去计算Batch内所有query-document pairs的
 相似矩阵。
相似矩阵。 - 对每行,即每个query
 ,抽取除了 对角线 正样本之外的 最高相似度分数的document ,记对应的列为
,抽取除了 对角线 正样本之外的 最高相似度分数的document ,记对应的列为
 ,进一步生成训练样本对,形如:
,进一步生成训练样本对,形如:
 ,即:query,正样本文档,困难负样本文档。 相当于拿最困难的那个样本再次训练一遍。
,即:query,正样本文档,困难负样本文档。 相当于拿最困难的那个样本再次训练一遍。 - 作者采用了scaled binary cross entropy二分类交叉熵损失(
 )和margin rank loss即最大间隔损失函数两种方法。最后发现margin设置为0.1~0.2的margin rank loss表现最好。对某条样本,该损失函数形如:
)和margin rank loss即最大间隔损失函数两种方法。最后发现margin设置为0.1~0.2的margin rank loss表现最好。对某条样本,该损失函数形如:
- 首先,同样去计算Batch内所有query-document pairs的

【 炼丹经验 】作者还提到,一开始使用困难负样本进行课程学习没有取得收益。通过实验发现,问题的关键在于必须先保证 第一阶段收敛 ,然后才能开始执行第二阶段的 课程学习 。除此之外,对所有样本对求总体的margin rank loss损失时,使用 sum 来做reduce比用mean更好。即:
 更好。
更好。
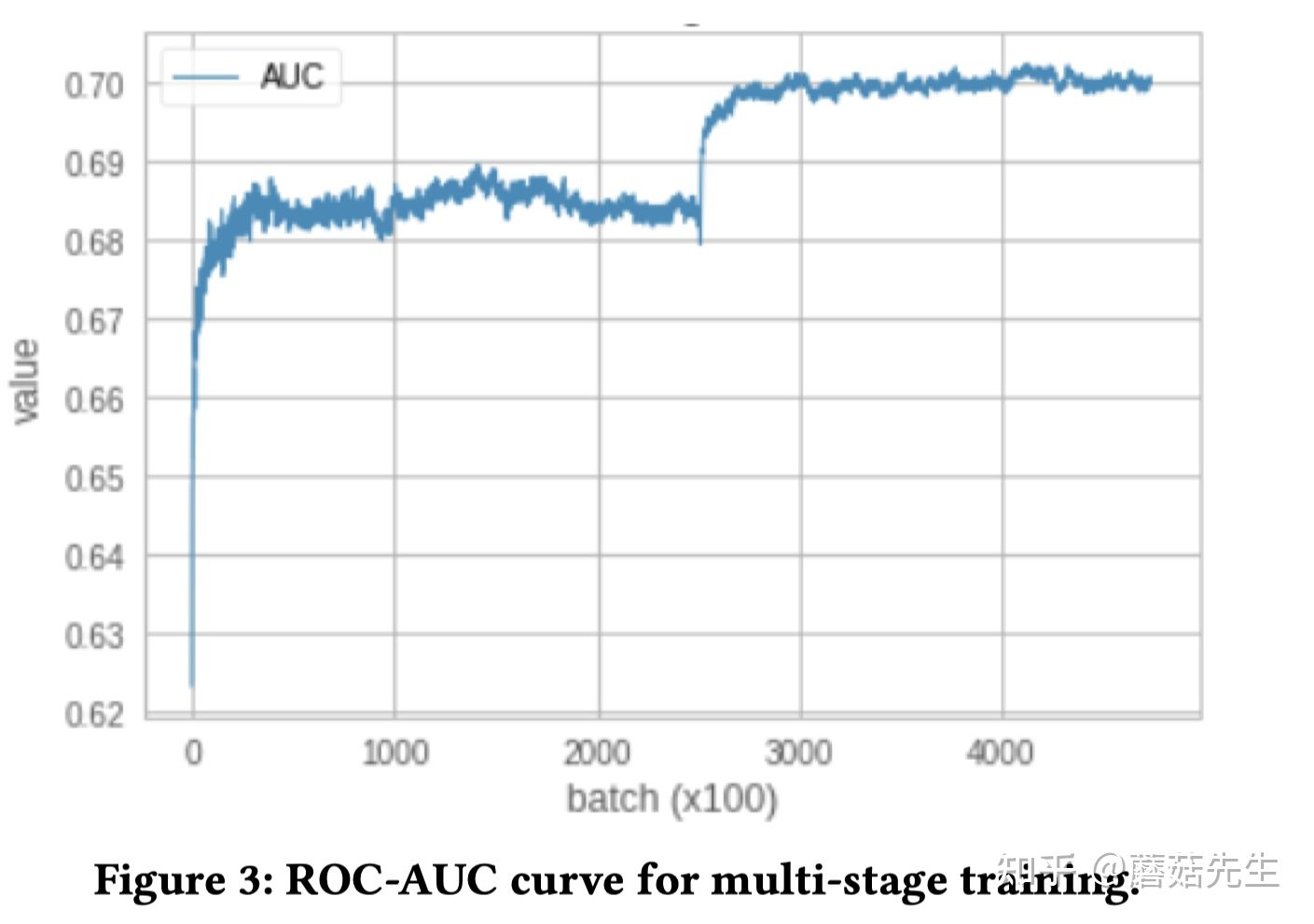
可以欣赏下两阶段训练指标曲线图,可以看到在第二个阶段有个很明显的 指标跳变 。
2.5 模型结构与系统架构
query tower需要实时推断得到query embedding,对性能要求比较高。作者实验了多种transfromer架构,在时延和准确率之间做权衡。
(1) query tower网络结构上, 【 炼丹经验 】
- XLM,2-layers,4 attention heads, query句向量维度128维,P99线时延为1.5ms。
- XLM,3-layers, 4 attention heads,query句向量维度256维,P99线时延3.5ms。
- query的最大长度取了99分位点,即99%的query的长度都小于该值。
- dropout的丢弃系数为0.1。
- 前向传播全连接层的向量维度数设置为输入query句向量维度数的 3倍 。
- 采用SentencePiece的词典,大小为150k,即15W。
- 采用Torch的Just-In-Time(JIT)编译器来加速推断。
后者性能提升很微弱,作者采用了前者。
(2) document tower网络结构上 ,【 炼丹经验 】
采用了Pytorch框架以及一些下游的库如:PyText,Fairseq和多模态框架MMF来实现该模型。主要的几个参数:
- Batch size=768
- Adam优化器
- 学习率=7e-4
- 预训练的XLM/XLM-R的学习率有所不同 ,为2e-4(该差异化学习率策略验证集上的ROC AUC指标提高了1%)
- Dropout,rate为0.1
- 梯度裁剪,阈值1.0
- early stopping,验证集上ROC AUC指标连续3个epoch不提升时做早停。
doc侧没有什么性能要求,离线计算好的;对于实时新增的内容,也可以近线(near real-time)算好。
工程上,
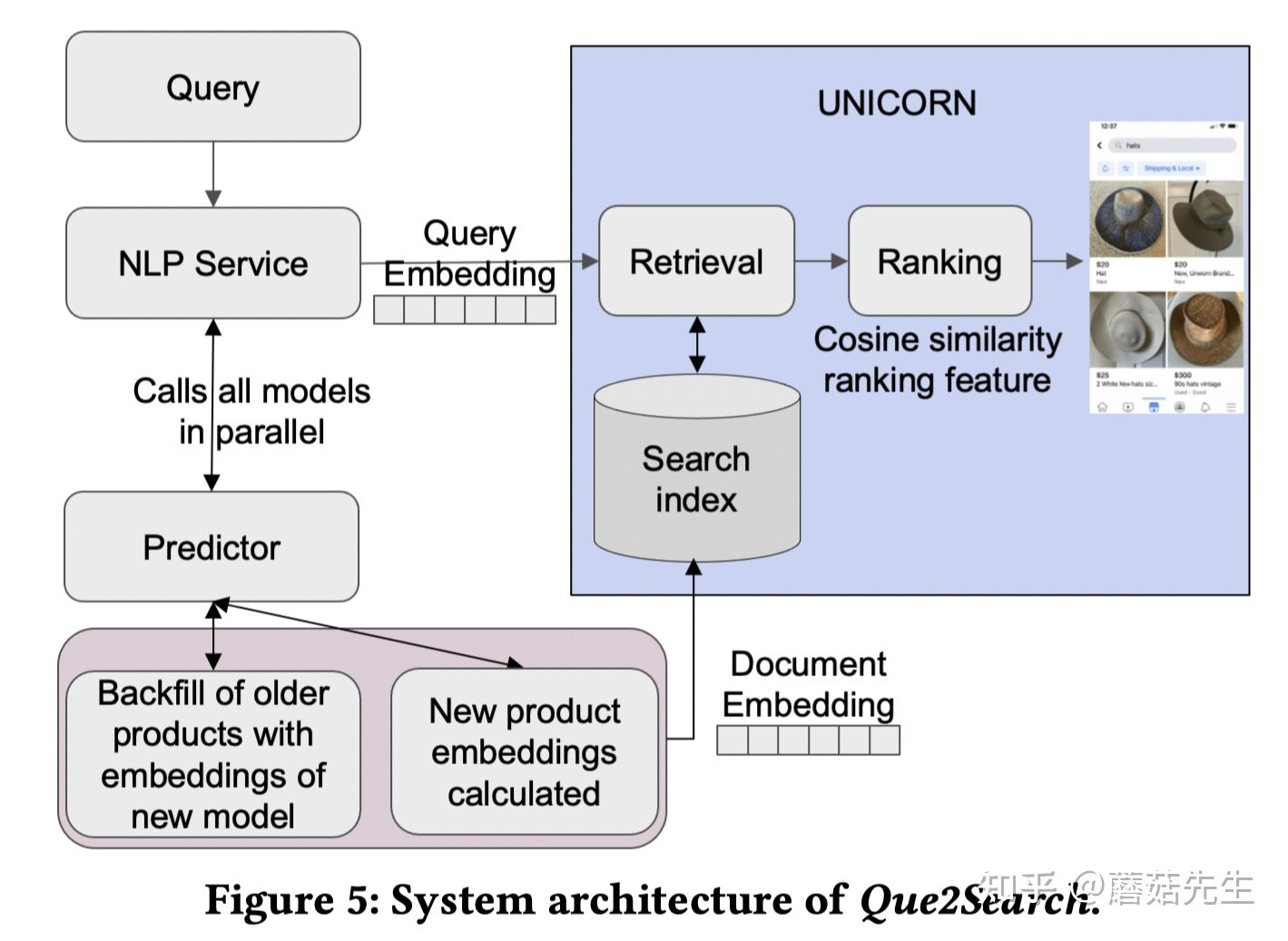 \* 当有query请求时, 会调用统一的NLP Service服务 ,NLP Service做两件事;
\* 当有query请求时, 会调用统一的NLP Service服务 ,NLP Service做两件事;
- 调用Facebook自研的 模型推断平台 Predictor[8],计算query的向量。
- 基于计算好的query向量,向 索引系统 :Unicorn [9]发起ANN检索请求,从而检索出头部的相关商品。
2.6 多模态融合
主要是对 文本和图片 的融合。前文提到了一种 基于注意力机制的 加权融合 ,可以看做是baseline。作者还分享了1种基于梯度的多模态融合方法。
梯度融合Gradient blending 。CVPR一篇工作[7]中提出的权衡多模态、防止某个模态主导和过拟合的方法。
具体的, 训练M+1个模型 ,M是模态的数量,其中M个模型分别用单个模态特征作为输入来训练,1个模型用所有 模态特征 作为输入来训练。先分别计算每个模型的损失,然后加权融合所有模型的损失,每个损失都有提前设定好的权重系数。 目的是让模型即使在模态缺失的时候也具备学习能力,更加鲁棒。
作者将梯度融合方法推广到了 双塔结构上 。如图1所示,query侧可以看做有2个模态,即query和country;document有3个模态,即:title,description和image。注意, 此处的模态不是严格定义的,每个通道的输入都可以看做是一种模态,因此也是一种多通道输入特征的融合方法。 比如document塔可以看做是5个模态,每个模态实际上可以看做是一组相关features的集合。
- 先计算m+n个单模态作为输入时的损失 。query塔的多模态输入记作
 , document塔的多模态输入记作
, document塔的多模态输入记作
 。
。
 上述式子是指query侧只用单模态特征
上述式子是指query侧只用单模态特征
 (比如query);document侧用所有模态特征(e.g,
(比如query);document侧用所有模态特征(e.g,
 为拼接);然后计算query和document的cosine相似性,再计算损失函数。
为拼接);然后计算query和document的cosine相似性,再计算损失函数。
同理,可以计算document侧只用单模态特征,query侧用所有模态特征时的损失。

- 计算所有模态作为输入时的损失 ,query侧和document侧都用所有模态特征。

- 再加权融合所有的损失函数。
 融合的系数是提前计算好的。
融合的系数是提前计算好的。
【 炼丹经验 】作者提到,单个特征作为单个通道进行上述的融合时,离线没有提升。 先进行特征分组,每个组内的特征作为单个通道 ,再进行上述融合时, 离线有+0.91%的ROC AUC提升 。同时要注意,单个模态作为输入求损失只在训练阶段会用到,线上推断的时候,只会用到所有模态特征作为输入得到的向量表征。
3. Evaluation
3.1 实验设定
- Batch Recall@K ,实际上就是Batch内的query-doc相似矩阵中,对每行的query
 ,对角线的正样本
,对角线的正样本
 是否在预测的
是否在预测的
 结果中
结果中
 。在训练的时候就能很方便地进行计算,且和离线模型优化目标比较一致。
。在训练的时候就能很方便地进行计算,且和离线模型优化目标比较一致。 - ROC AUC , 人工外包标注 的query-document数据,1为相关,0为不相关。
- KNN Recall@K , 用前文提到的若干周conversation数据 做训练,未来若干天做测试。基于Faiss做 全库召回 并评估Recall@K,该指标和 线上的实时向量检索指 标一致。
3.2 模型的解释性实验
这部分也是原文的亮点体现。讨论了BERT模型的增益以及 双塔模型 如何做特征消融实验。
3.2.1 XLM encoder的作用
主要想解答 XLM encoder是否对query tower的表征有增益 ? 实际上就是消融实验,即:用了XLM encoder和不用比,有什么好处。
通常的 质疑包括两点 :
- query一般都是 短词或短语 ,长度很短。
- 在电商平台中,query一般集中在一些 头部的词 。
这种情况下,character 3-gram已经足够表达query了,还需要用到复杂的BERT模型XLM吗?
作者用attention weights来探索该问题。在query tower中,character tri-gram channel和query XLM encoder channel之间有1组融合的权重系数,所有通道的权重系数和为1。可以 基于该系数来判断模型更关注哪个通道的表征。 作者发现XLM encoder得到的表征的平均权重系数为0.64,而tri-gram做pooling得到的表征的平均权重系数为0.36。由此可以看出XLM encoder的表征对模型学习的帮助更大。
进一步,作者还绘制了注意力权重和query长度的关系图,发现当query长度小于5时,模型确实是更关注character tri-gram channel,其权重更大;当query很长时,XLM的encoder的权重几乎为1,即:起到了主导作用。
3.2.2 特征重要度
作者提出了一种 面向双塔模型的特征重要度计算方法 ,可以认为是双塔模型的特征消融实验。具体而言,对于要消融的特征向量,使用默认的取值来替代,例如零向量或者用随机抽的其它样本的取值,然后计算指标的差异。
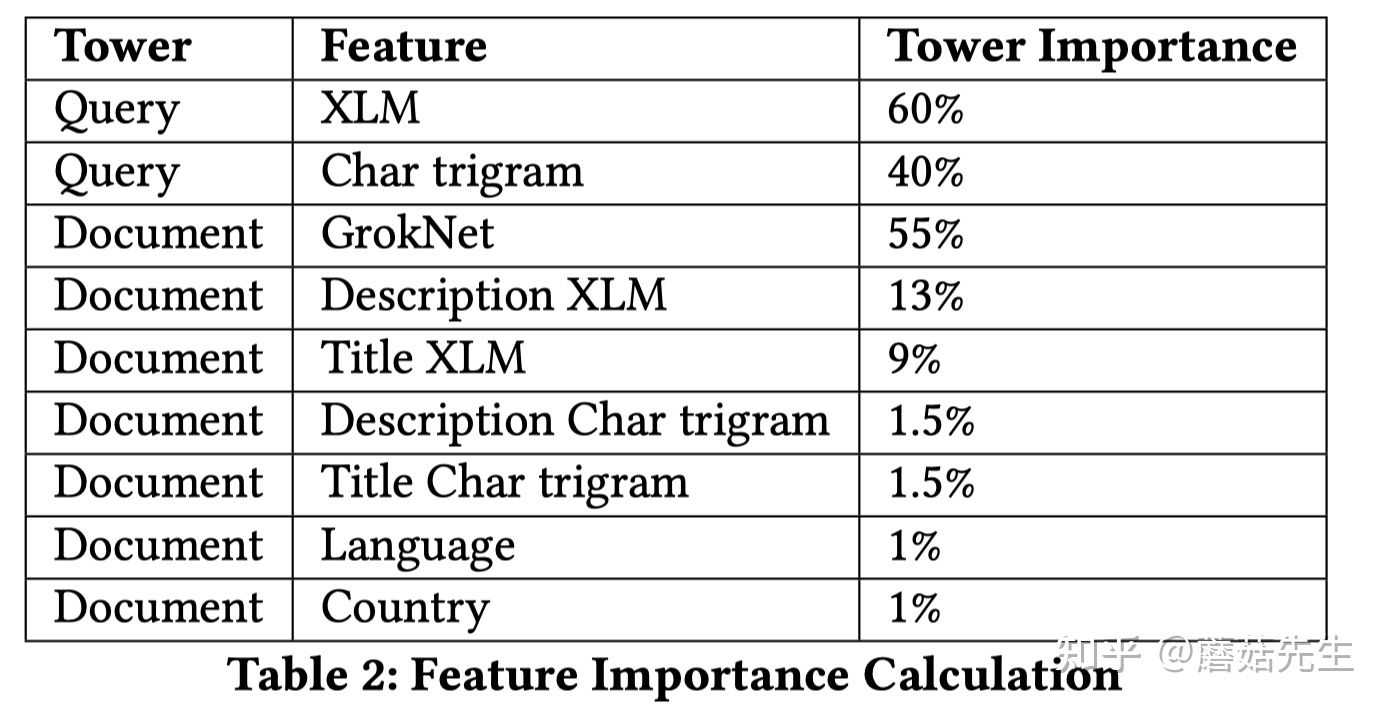 可以看出, XLM Encoder不管在query侧还是document侧都非常重要 。除此之外,作者在提取图片向量时,用的是预训练模型GrokNet[4],其重要度也非常高。即:跨模态的引入对于模型的提升非常重要。
可以看出, XLM Encoder不管在query侧还是document侧都非常重要 。除此之外,作者在提取图片向量时,用的是预训练模型GrokNet[4],其重要度也非常高。即:跨模态的引入对于模型的提升非常重要。
除此之外,作者还提到,引入deep sets[5]方法来融合多张图片,也对指标有挺大的贡献。
3.3 消融实验
分别对conversation数据集和外包标注数据集,都做了消融实验。主要做输入特征和模型结构上的消融实验。
在conversation数据上,
 \* baseline: wide & deep,输入特征用tri-gram,0.6788。
\* baseline: wide & deep,输入特征用tri-gram,0.6788。
- 引入原始文本特征+XLM/XLM-R作为编码器,提升的非常显著,0.7292。
- 引入图片特征,0.7237。
- 同时引入原始文本+图片特征,0.7445。
- 引入注意力融合,0.7456,略微提升。
- 共享title, description的表征,0.7459,略微提升。
在外包标注上也有很大的提升,
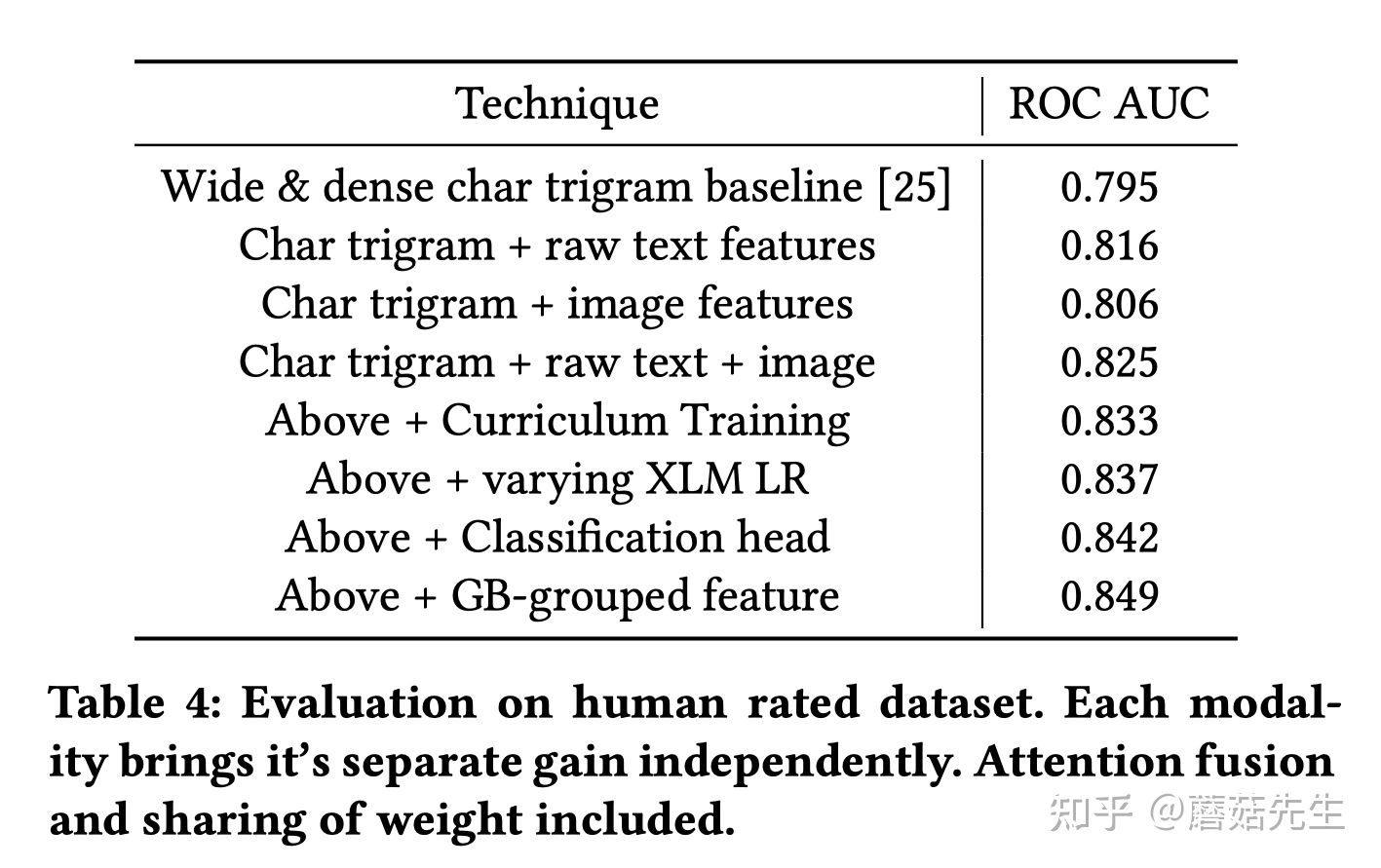 和上述相同的不做赘述。除此之外,可以看到,
和上述相同的不做赘述。除此之外,可以看到,
- 课程学习提了千分位8个点;
- 多目标也提了千分位5个点;
- 多通道特征梯度融合提了千分位7个点。
3.4 线上A/B实验
线上的主要用途是召回和排序,其中召回加一路向量检索;排序加一个query和doc的相似性特征。
 可以看到,EBR向量检索提升显著,2.8个点;排序提高了1.24个点。神奇的是,作为向量检索,只用tri-gram的EBR提升的幅度比完全态Que2Search的EBR多一些,作者没解释原因。
可以看到,EBR向量检索提升显著,2.8个点;排序提高了1.24个点。神奇的是,作为向量检索,只用tri-gram的EBR提升的幅度比完全态Que2Search的EBR多一些,作者没解释原因。
3.5 部署经验分享
在这一小节,作者分享了一些部署经验。
-
EBR向量检索系统部署 ,这个大同小异。可以参考Facebook 2020的文章[1]相应的工程解读: 语义向量召回之ANN检索;也可以参考淘宝2021向量检索的文章[11],相应的解读: 蘑菇先生:KDD'21 | 淘宝搜索中语义向量检索技术。
-
召回没有 银弹 :不要想着整个搜索检索都依赖EBR。EBR会面临着性能、相关性等问题,仍然要和传统的token-based的检索配合使用。
-
准召、CPU使用率和延迟的权衡 :
- ANN检索超参数:这个也是Facebook 2020文章里提到的EBR工程实现细节的老生常谈。做ANN检索的时候,有几个超参数n_prob, radius等,需要调参来权衡准召、CPU使用率等。详细可以参考我写的解读:。
- A/B测试超参数:线上做A/B时,超参数的选择也非常重要。作者希望即使参数选择很烂,也能够最小化对用户体验的影响。为了做这个事情,最好的办法是上线开流量前确定合适的超参数。为此,作者先选取了一个黄金query集合,是从真实搜索词里头通过层次抽样抽到的,然后离线模拟请求,人工观察结果;还有比如让外包进行相关性的标注,来观察准召情况。这样就能够提前通过调整不同的参数,离线观测结果,发现召回结果的好坏。
-
连续翻页优化 :用户会连续下滑翻页。但前提是第一个request得有结果,否则整个搜索结果是空窗的。因此对于第一个request的性能要求很高。作者采用了动态ANN参数的方式,第一个请求的时候关注性能,弱化准召,可以调整n_prob,radius实现;后续翻页的请求的时候,则可以在一定时延约束下,更关注准召。
-
搜索排序 :Facebook电商平台采用了两阶段的排序策略。首先用一个轻量的GBDT会在每个单独的索引机器上从每个分片中选择头部的结果;接着用一个深度模型来进一步选择更好的结果。为了应用Que2Search到排序,将 cosine相似性特征 同时应用到两阶段排序中。这个强特对排序的指标提升很显著。
-
失败的经验教训 :总结了一些比较反直觉的现象和经验。
- 在召回环节,离线的Precision同样很重要 。在很多机器学习任务中,直觉上很容易感觉Precision很重要。但是在召回里头,我们却缺少些直观理解为什么不能只用召回率作为唯一的指标。作者一开始为了优化召回率,放松了些ANN的搜索参数,提高了召回率,但是也引入了一些bad case,有不少差的结果进入了后续的精排,按理说,并没有影响和减少那些正确的召回结果数量,结果线上指标却很差。细致探索后发现是 召排不一致性 导致的。排序模型无法处理这些新召回方法引入的噪声结果。因此要么提高召排的一致性,要么结合线下线上指标来选择最佳的参数。
- 只保证相关性远远不够 。 提高召排一致性的一种方法是直接将召回的相似性分数用在排序中。期望的结果是,召回引入的相关性差的内容,排序能够将其排在后面。实际却不然,相关性的NDCG确实提升的,但是线上指标却下降了。可能是因为双塔模型主要关注相关性,而排序模型关注线上指标,将双塔模型输出作为排序模型的输入,也不一定对线上指标有帮助。因此需要关注多种指标。
个人感觉这部分的总结有点太空洞,不是1段篇幅就能够明确概括和传递给读者的。
4.Summarization
总结一下这篇文章的亮点:
- 提出了一种query和商品的语义理解系统,Que2Search。该系统离线有5%的离线相关性提升;线上有4%的用户参与度指标提升。
- 分享了 BERT模型 XLM做向量表征,如何拿到收益以及如何做到时延99线1.5ms的性能。
- 在双塔结构上引入了 多任务学习 。
- 提出了基于注意力机制的 多模态融合方法 以及基于梯度的多模态融合方法,不仅可以应用于多模态,也适用于多通道、分组特征的融合。
- 提出了 两阶段训练范式 ,第一阶段先进行in-batch内的采样;第二阶段再进行课程学习。
- 分享了很多 调参炼丹 的经验。
References
[1] Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano, and Linjun Yang. 2020. EmbeddingBased Retrieval in Facebook Search . In KDD.
[2] Guillaume Lample and Alexis Conneau. 2019. Cross-lingual Language Model Pretraining. arXiv:cs.CL/1901.07291
[3] Alexis Conneau, Kartikay Khandel wal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer,and Veselin Stoyanov. 2020. Unsupervised Cross-lingual Representation Learning at Scale. In ACL.
[4]Sean Bell, Yiqun Liu, Sami Alsheikh, Yina Tang, Edward Pizzi, M. Henning, Karun Singh, Omkar Parkhi, and Fedor Borisyuk. 2020. GrokNet: Unified Computer Vision Model Trunk and Embeddings For Commerce . In KDD.
[5] Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabás Póczos, Ruslan Salakhutdinov, and Alexander J. Smola. 2017. Deep Sets . CoRR abs/1703.06114 (2017). arXiv:1703.06114 http://arxiv.org/abs/1703.06114
[6] Bengio Y, Louradour J, Collobert R, et al. Curriculum learning [C]//Proceedings of the 26th annual international conference on machine learning. 2009: 41-48. **https://****dl.acm.org/doi/10.1145/** 1553374.1553380
[7] Weiyao Wang, Du Tran, and Matt Feiszli. 2019. What Makes Training MultiModal Networks Hard? CVPR (2019).
[8] K. Hazelwood, S. Bird, D. Brooks, S. Chintala, U. Diril, D. Dzhulgakov, M. Fawzy,
B. Jia, Y. Jia, A. Kalro, J. Law, K. Lee, J. Lu, P. Noordhuis, M. Smelyanskiy, L. Xiong, and X. Wang. 2018. Applied Machine Learning at Facebook: A Datacenter Infrastructure Perspective . In HPCA.
[9] Michael Curtiss, Iain Becker, Tudor Bosman, Sergey Doroshenk
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8F%AD%E7%A7%98%E5%8D%87%E7%BA%A7%E7%89%88%E8%AF%AD%E4%B9%89%E6%90%9C%E7%B4%A2%E6%8A%80%E6%9C%AF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


